Если у вас возникала идея получить доступ к метрикам операционной системы и оборудования компьютера из PostgreSQL, то теперь у вас есть инструмент для этого. Я не претендую на его зрелость и готовность к эксплуатации. Это просто прототип, позволяющий получить результаты запросов из osquery в PostgreSQL в виде табличных данных/JSON. Дальше с которыми можете использовать все привычные средства этой базы данных.
osquery
Кросплатформенный open source проект, который позволяет выполнять запросы к событиям и метрикам операционной системы, как к виртуальным таблицам в SQLite, построен на основе этой embedded базы, с присущими ей ограничениями на типы данных.
osquerydдемон, по конфигурации собирающий результаты запросов, отправляющий эти данные, а также умеющий подписываться на события операционной системы об изменениях;osqueryiинтерактивная консоль, позволяющая отлаживать запросы, получать результаты их выполнения и не взаимодействующая сosqueryd;
Для получения результатов запросов можно использовать Thrift API, либо запуск osqueryiв командной строке с текстом запроса и форматом результата json/csv. В свое время я использовал сериализацию Thrift API через транспорт UNIX domain socket что было совсем не просто. В этот раз, решил что запуска процесса и парсинга stdout будет достаточно. Так и появился postgres_osquery. Раньше было еще расширение pgosquery и это не интеграция с osquery, а попытка написать его "с нуля", с предсказуемым результатом - возможности минимальны и проект заброшен.
postgres_osquery
Реализовал интеграциюrun_osquery как хранимку в PostgreSQL на Python, которая получает на вход строку запроса к osquery, а на выходе выдает JSON, заменяя пустые строки на null.
CREATE OR REPLACE FUNCTION run_osquery(query text) RETURNS json AS $$
def replace_empty_strings_with_null(json_obj):
if isinstance(json_obj, dict):
for key, value in json_obj.items():
if isinstance(value, str) and value == "":
json_obj[key] = None
elif isinstance(value, (dict, list)):
replace_empty_strings_with_null(value)
elif isinstance(json_obj, list):
for i, item in enumerate(json_obj):
if isinstance(item, str) and item == "":
json_obj[i] = None
elif isinstance(item, (dict, list)):
replace_empty_strings_with_null(item)
import subprocess
import plpy
import json
try:
process_output = subprocess.check_output(['osqueryi', '--json', query ]).decode('utf-8')
process_json = json.loads(process_output)
replace_empty_strings_with_null(process_json)
return json.dumps(process_json, indent=4)
except subprocess.CalledProcessError as e:
plpy.error('External process failed: ' + str(e))
except Exception as e:
plpy.error('An error occurred: ' + str(e))
$$ LANGUAGE plpython3u;И казалось бы - вот оно решение, но чтобы превратить json в табличную форму, приходится вручную определять тип записи, который возвращает PostgreSQL функция json_to_recordset. Это многословно и неудобно, например:
SELECT * from json_to_recordset(run_osquery($$ SELECT * FROM routes $$)) as
(destination text, flags text, gateway text, hopcount text, interface text, metric text, mtu text, netmask text, source text, type text);Хотелось бы не печатать для типовых виртуальных таблиц osquery портянку полей и их типов. И получилось это с помощью автогенерации типов определяемых пользователем(UDT) и функции json_populate_recordset, которая первым параметром принимает этот тип записи.
Для прошлого примера. Создаем тип в базе PostgreSQL:
CREATE TYPE osquery_routes AS (
"destination" text,
"netmask" integer,
"gateway" text,
"source" text,
"flags" integer,
"interface" text,
"mtu" integer,
"metric" integer,
"type" text,
"hopcount" integer);Вызываем функцию:
SELECT * FROM json_populate_recordset(
null::osquery_routes,
run_osquery('select * from routes'));И получаем результат запроса select * from routes в виде таблицы:

Чтобы не печатать это ручками, примеры запросов для основных таблиц доступны в репозитарии, перед использованием которых надо создать типы для используемых в функциях записей.
И конечно же можете работать просто с JSON результатом:
SELECT run_osquery($$
SELECT p.pid, name, p.path as process_path, pf.path as open_path
FROM osquery_info i
JOIN processes p ON p.pid = i.pid
JOIN process_open_files pf ON pf.pid = p.pid
WHERE pf.path LIKE '/dev/%' $$);
Можно получить шаблон для типов строки с помощью моей функции get_common_json_record и с помощью этого шаблона преобразовать JSON в табличную запись:
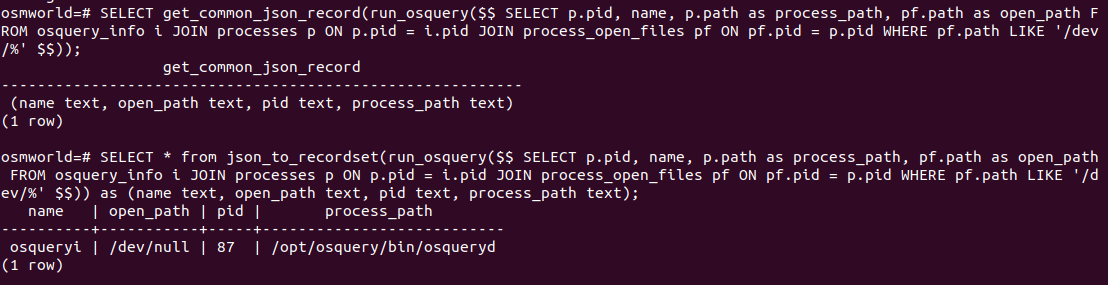
Полезные ссылки
https://osquery.readthedocs.io/en/stable/introduction/sql/
https://osquery.io/schema/5.9.1/osqueryi
https://fleetdm.com/guides/osquery-evented-tables-overview
https://github.com/jmpsec/osctrl
https://github.com/fleetdm/fleet
https://docs.elastic.co/en/integrations/osquery_manager
https://github.com/citusdata/pg_cron
Итоги
Результаты работы функции run_osquery можно сохранять в таблицы с помощью pg_cron по расписанию или же запускать на каждом узле кластера CitusDB с помощью run_command_on_all_nodes().Или построить свое SIEM( Security information and event management) решение для хостов базы данных, используя только PostgreSQL.
Надеюсь, что помог с созданием новой "игрушки" для администраторов PostgreSQL. Ведь когда работаешь с osquery из PostgreSQL, понимаешь сколько еще полезных и забавных расширений может написать сообщество для этой базы данных.
sshikov
Так ведь неудобно же поди потом будет? Тот же прометеус — он ведь не зря держит метрики не в обычной базе — потому что на них смотрят как на time series как правило, а time series db это тот случай, когда специализированные БД не просто бывают, а вполне себе неплохи.
igor_suhorukov Автор
Согласен, что будет уступать специализированной tsdb. Хотя есть TimescaleDB расширение, которое работает на PostgreSQL.
sshikov
Понял. Уследить за многообразием расширений не представляется возможным :)
igor_suhorukov Автор
О, да! В сфере time series database сейчас основная борьба идет в базах данных. Поскольку я поучаствовал в QuestDB в свое время, то немного погружался в этот рынок. Там как в религии) Битва clickhouse за эту же нишу и десятки специализированных open source решений.
Из интересного, жду когда допишут и запустят полноценно influxdb_iox.