Ручные изменения в кластере доставляют одну лишь головную боль. А чтобы от них избавиться, используются операторы, в частности K8s. Что это такое? И самое главное, как его написать?
Меня зовут Дмитрий Самохвалов, я архитектор в компании КРОК. Пробовал себя в разработке, инфраструктуре и тимлидерстве. Расскажу про архитектуру и внутреннее устройство оператора и покажу как создать свой оператор на Go. Все остальные вопросы можно задать мне в Телеграм.

Что такое облачный сервис-провайдер?
Один из проектов, над которыми работаем мы с коллегами, это облачный сервис-провайдер. Он позволяет клиенту заказать себе любое количество Kubernetes-кластеров динамически, но все их нужно администрировать. Это большое количество рутинных задач, day 2 операций, таких как резервное копирование и восстановления после аварий. Также это SaaS-приложения, которые часто поставляются в Kubernetes-кластер. Причём многие из них обладают сложным стэйтом. Например, так выглядит типичный Routine hell, эксплуатация большого количества динамически создаваемых кластеров:

Для эксплуатации и типичных операций используется, как правило, достаточно большой зоопарк инструментов. Многие из них зачастую legacy. В их число входят bash-скрипты, ansible-сценарии, всевозможные cron job’ы и самое неприятное — ручные манипуляции с кластером.
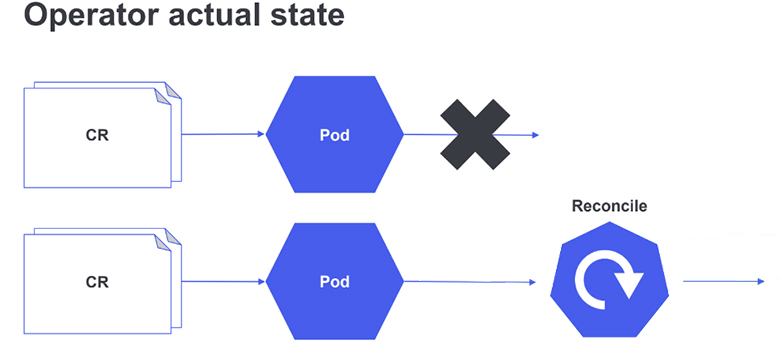
Конечно, их стараются избегать, но бывают кейсы, когда это невозможно. То есть обязательно найдется тот, кто сделает что-то не так руками.
Когда необходимо деплоить в кластер Stateful приложения, нужно также задеплоить и то, как это приложение поставляется:

Например, к Saas-сервису нужно задеплоить кэш-систему, очередь, обернуть всё это в какую-то haa и поставить прокси. А когда нужно деплоить в Kubernetes базу данных есть специальные операторы.
Польза операторов
Если суммировать все перечисленные проблемы динамически создаваемых кластеров без оператора, придется мониторить состояние ресурсов в кластере. Причём речь идёт не только про поды, но и про актуальность уже существующих в кластере манифестов и конфигураций. А это может быть больно.
Нужно по возможности избегать ручных изменений. А в случае нежелательного изменения, максимально быстро на это отреагировать и откатить обратно. Для этого тоже полезны операторы. Лучше один раз проинвестировать ресурсы в разработку и ресурсы на дальнейшую эксплуатацию кластеров с оператором значительно сократятся. Потому что большая часть логики переедет в оператор и его можно будет деплоить прямо в кластер.
Тогда количество ресурсов, которые нужно поддерживать и следить за их актуальностью сокращается до кастомных ресурсов для оператора:

Если суммировать все кейсы, для которых необходимы операторы, их можно поделить на две большие группы:
Рутинные задачи эксплуатации, которые всегда удобнее переложить на плечи Kubernetes, потому что он сам знает, что у него в кластере установлено и может за этим следить. Это операции первого, второго дня, всевозможные операции со вспомогательными ресурсами, например сертификатами.
Приложения со сложным стейтом и топологией. Просто обычными ресурсами эксплуатации следить за ними и эксплуатировать их очень сложно. Гораздо удобнее переложить эту работу на команду разработки, а в дальнейшем на плечи Kubernetes-кластера.
Анатомия оператора
Оператор — это под в Kubernetes-кластере, приложение которое по большому счету, следит за установкой и изменениями кастомных ресурсов. Его сила в том, что он может взаимодействовать как с API кластера, так и с внешними ресурсами. А самое главное, он может приводить систему в нужное состояние своими собственными силами. От разработчиков требуется только декларативное описание нужного стейта.

Самая важная часть кастомного ресурса в Kubernetes-операторе — это контроллер. Он осуществляет всю логику взаимодействия и работает по принципу бесконечной петли, поэтому помечен символом круговой стрелки. Контроллер следит за изменениями в ресурсах и приводит систему в желаемое состояние.
Контроллер удобен тем, что в нём один раз описывается логика и дальше вся ручная работа ложится на плечи встроенных средств Kubernetes-контроллера и самого кластера.
Как создаются кастомные ресурсы?
Согласно документации Kubernetes, они определяются ещё одним встроенным ресурсом, который называется CustomResourceDefinition. Он содержит описание спецификаций и мета-даты кастомного ресурса:

На примере видно, что описано название самого ресурса, его правила именования. Спецификация сильно больше, но она не настолько интересна, потому что представляет собой просто объекты на языке Go.
В дальнейшем мета-данные превращаются в два поля: типа и объекта.

Самое интересное — это спецификация, где описывается структура кастомного ресурса: какие у него будут поля, какого типа, как они будут определяться.
Статус нужен, если, например, разработчик деплоит приложение. Тогда ему нужно в статус поставить, что приложение создаётся, деплоится или в процессе удаления.
API
Для дальнейшего понимания, как работать с оператором, очень важно знать API Conventions самого Kubernetes’а:

Он достаточно простой, можно выделить непосредственно ресурс, то есть именно тот объект, который мы описываем. Он называется kind. Все ресурсы одной группы, одного назначения, либо близкого назначения объединяются в группы. Согласно API Conventions и Kubernetes, они чаще всего определяются доменом владельца и названием группы, которая по смыслу наиболее отражает эту группу kind. Группа имеет одну или более версий. Это нужно будет при создании своего собственного оператора.
Сердце оператора

Сердце контроллера состоит из трёх элементов: Informer, Indexer и рабочая очередь.
Informer хранит в себе кэш набора состояний. Он получает их из Kubernetes API. В целом Informer — это своего рода обёртка на watch API Kubernetes. Чтобы не создавать дополнительные нагрузки на Kubernetes API, Informer имеет свой собственный кэш и использует Indexer для ускорения доступа к кэшу. Таким образом, все ресурсы, которые пользователь получает из контроллера берутся из кэша Informer’а.
Когда в Kubernetes API что-то меняется, контроллер использует ресурс хендлеров, которые модифицируют состояния: создают (create), изменяют (change) или удаляют (delete).
Далее они помещаются в рабочую очередь, которая исполняет все хендлеры по порядку.
Как написать свой оператор?
Для написания собственного оператора с нуля, потребуется много кода, потому что K8s — штука сложная, и помимо него нужно также написать код работы с типами, функции копирования и листинга.
К счастью, есть замечательные инструменты, которые могут облегчить это дело. Самый распространённый — оператор SDK от RedHat. Это чуть более расширенная версия опенсорсной библиотеки Kubebuilder. Кроме того, Kubebuilder имеет отличную документацию: Kubebuilder Book. Всем, кто интересуется созданием оператора, Дмитрий рекомендует это почитать.
1. Генерация Boilerplate

Первым делом нужно сгенерировать скелет проекта и необходимый Boilerplate. Это делается командой init Kubebuilder’a. Важно что, репозиторий обязательно должен быть пустым. Потому что Kubebuilder проверяет структуру первоначального репозитория и в зависимости от этого генерирует структуру папок.
Дальше нужно создать API контроллера и оператора. Здесь пригодятся знания API Conventions Kubernetes. Вот код создания API:
-> kubebuilder create api
Потом нужно создать CRD и контроллер с указанной версией ресурса и контроллера:
--group kafka.group version v1 --kind Topic
По итогу Kubebuilder генерирует такой скелет:

В этом скелете содержится ресурс API в папке API соответствующей версии, контроллер, вспомогательные функции. CustomResourceDefinition в папке конфиг, хелперы и мейк файл с полезными командами для сборки и генерации дальнейших манифестов. Остается лишь написать бизнес-логику.
2. Кастомизация ресурса
Скелет нужно наполнить данными кастомного ресурса. Делается это в spec’е метаданных.

Самое интересное здесь — следующие аннотации:

Это встроенные аннотации в Kubebuilder’е, которые определяют, что и когда можно генерировать этим инструментом. Например, правила валидации. Все аннотации начинаются с двойного слеша, плюс Kubebuilder, двоеточие и далее название той директивы, которую нужно использовать. Есть дефолтные аннотации, которые генерят основной костяк нашего оператора.
Операторы прячут всю необходимую подкапотную работу за одну простую функцию — Reconciler:

Естественно, сам Reconciler при сложной логике тоже становится большой и сложный, поэтому его лучше есть по частям.
3. Финалайзер

Очень часто бывает так, что тот или иной ресурс работает не сам по себе, а, например, с внешним ресурсом: Kafka Topic. Поэтому при удалении ресурса топик из Kubernetes-кластера нужно также удалять топик из Kafka.
Как можно догадаться, все эти операции — асинхронные, и осуществляются в бесконечной петле контроллера. Значит, просто кинуть обращение на удаление в Kafka неправильно. Вместо этого нужно, во-первых, сделать удаление идемпотентным, а во-вторых — с правильной обработкой логики. Для этого используется финалайзер. Это поле в мета-дате ресурса, которое вешается в момент его создания.
Логика создания — довольно проста. Намного интересней обновление, потому что нужно выяснить, если ресурс действительно изменился. То есть нужно сравнивать настоящее и прошлое состояние. Но Kubernetes контроллер содержит в себе только информацию на текущий момент. Можно, конечно, хранить предыдущий стейт и сравнивать его с текущим через DeepEqual или что-то подобное. Однако, есть инструмент гораздо проще и удобней. Достаточно лишь взять кэш из актуальной спецификации и приклеить его в виде лейбла к ресурсу. В дальнейшем можно будет просто сравнить актуальный кэш с этим лейблом.

Тем не менее, если создать ресурс динамически и попытаться получить его из кластера, то ничего не выйдет, потому что ресурс не попал в кэш и не обновился. Чтобы правильно отработать эту ситуацию, нужно сначала создать ресурс, а потом перезапустить цикл, то есть вернуть результат работы контроллера. Только после этого из кэша можно достать динамически созданный ресурс.
Leader election
Когда в кластере складываются несколько операторов, они могут упасть или операторы будут разных версий, так как оператор — это под. Нужно иметь какую-то отказоустойчивость от этого. Здесь на помощь приходит инструмент Leader election.
Он бывает в двух вариантах. Чаще всего используют тот, который отбирает одного лидера, а остальные контроллеры ставит в очередь.

В другом варианте лидеры обновляются с заданной периодичностью. Тут может быть Split-brain, но зато временной лаг будет сильно меньше.
RBAC
Важный аспект при работе и создании оператора — это Role-based access control. В Kubebuilder, к счастью, есть аннотация, которая позволяет сгенерировать необходимый набор прав, роллеров, ролл билдингов и прочего. Идея RBAC в том, чтобы не делать оператор кластера админом.

Как докатить оператор до кластера?

После того как оператор готов, необходимо сгенерировать все необходимые манифесты, код. Если что-то изменяется в кастомном ресурсе, нужно запустить директивы мейк манифеста, чтобы перегенерировать все спецификации: CustomResourceDefinition, функции хелпера и прочее.
В Kubebuilder’е есть парочка встроенных функций. Можно создать свой докер-образ оператора на основании того файла, который сгенерил Kubebuilder или на основании своего собственного образа. После чего нужно задеплоить его в кластер, который указан в конфиге. Естественно, для деплоя в продакшен окружения нужно использовать другие инструменты. Чаще всего пользуются Helm или Lifecycle manager, но таких случаев сильно меньше.
Итог
При создании операторов стоит обратить внимание на следующее:
Самое главное — идемпотентность оператора;
На каждую группу ресурсов использовать только один контроллер;
Для чистки внешних ресурсов брать финалайзер.
Профит от операторов получается значительный:
Сокращается количество кода, который находится на руках поддержки. Больше кода переходит разработчикам, но для них это состояние нормальное. Если это сложный код пусть лучше его делают разработчики на удобном языке программирования, нежели от этого будет страдать команда эксплуатации.
Получается настоящее декларативное описание, то есть эксплуатационные ресурсы максимально освобождаются от какой-то логики.
Управление жизненным циклом приложения перекладывается на плечи Kubernetes-оператора.
Получается более простая реализация disaster’ов, cover’ов, autoscale’ов, failover’ов и прочего.
И, наконец, появляется возможность развернуть ресурсы на любом Kubernetes-кластере. Это позволяет деплоить собственные решения, что очень полезно для мультитенантных инфраструктур.