Привет, Хабр! Меня зовут Степан Родионов, я из Х5 Digital. Сегодня расскажу о поиске в интернет-магазине — типовой задаче для e-commerce, которая в теории имеет типовое решение, но на практике оказывается сложнее.
Я запускал около десятка e-commerce проектов, и в каждом из них делал поиск. Этот опыт постарался обобщить в инструкцию по созданию подобного рода систем.
Эта статья написана на основе моего доклада для конференции Онтико. В статье не будет какого-то жесткого хайлоада, потому что все проекты, скорее, относятся к средним размерам, а не к таким гигантам, как Ozon или Яндекс Маркет.
Рассказывать буду на примере проекта Vprok.ru — это мой текущий, самый крупный проект. Он входит в Х5 Digital и занимает на российском рынке третье место: 10 регионов присутствия, более 72 тысяч товаров, примерно 300 RPS на товарные запросы и около 700 тысяч комбинаций товар+склад.
Что такое фасетный и полнотекстовый поиск
Фасетный поиск предполагает категории, фильтры, которые вы накликиваете и получаете результат. Можно представить это в виде визуализации:

Весь слайд — это молоко, есть какие-то фильтры, и на пересечении — товары, которые подпадают под все условия.

При полнотекстовом поиске вы набираете запрос текстом, и система пытается угадать, какие товары под него подходят.
Проектирование
Vprok начинал со стартапа. На этапе проектирования системы поиска были запросы на ORM Lavarel. Это решение не было оптимальным с точки зрения пользовательской нагрузки и надёжности, поэтому мы очень быстро накрыли всё решением на Sphinx.
У Sphinx был ряд недостатков.
Только поисковый индекс, в нём хранились данные непосредственно для поиска. А перед тем, как отдавать на витрину, их надо было обогащать прямо из мастер-базы. Нагрузку с неё толком не сняли, и каждый каталожный запрос нагружал основную базу данных.
Проблемы с заменами. Мы так и не научились обновлять в Sphinx документы по одному. Вы можете только перезалить весь поисковый индекс со всеми товарами, но не можете заменить какие-то отдельные документы.
Трудности с масштабированием. Масштабирование в Sphinx — задача сложная, и вызывает огромное количество проблем.
В итоге встал вопрос о том, чтобы сделать что-то новое. Встал он в 2020 году, когда нагрузка на онлайн резко выросла, и мы стали выбирать варианты.
Выбор новой платформы
У нас было несколько вариантов.
Реализовать механики поиска вручную. Чтобы реализовать механику поиска вручную, нужно было бы взять команду хороших гоферов и пару кварталов времени. Звучит страшно, но так делают, в этом нет ничего сверхъестественного. Наверное, все крупные компании однажды к этому приходят. Это самый дорогой способ сделать систему поиска, но у него есть существенный плюс.
В случае, если вы берёте какую-то платформу, она вас ограничивает. Причём, вы, как правило, не эксперт в этой платформе, и сталкиваетесь с этими ограничениями тогда, когда уже поздно. В случае разработки системы с нуля, вы сами выбираете, какими будут эти ограничения, и можете сделать их под себя. И, таким образом, система будет чуть лучше удовлетворять вашим требованиям. Но, повторюсь, это очень дорого.
Взять сторонние решения, работающие по API. Это диаметрально противоположный способ — вообще ничего самим не разрабатывать и подключиться к системам SAAS, которые будут искать за вас. Я сейчас не говорю о том, чтобы запустить поиск Яндекса на своём сайте, но так тоже делали. Есть компании, которые предоставляют услугу поиска. Вы им — товарный фид, подключаетесь к ним по API, кидаете свои поисковые запросы, они вам возвращают ответ.
Плюс такого решения — это очень быстро, то есть задача 1-2 недель одного разработчика. Понадобится лишь сделать фид и подключиться по API к другой платформе. Минусов тоже вагон. Вы не управляете этой системой вообще, вы не знаете, как её масштабировать и насколько она устойчива, не знаете, как её доработать — обычно никак. Если вы не большой бизнес, все ваши пожелания попадут в далёкий бэклог и, скорее всего, никогда не будут реализованы. За каждое из них придётся платить. И деньги эти вы будете тратить не на развитие своего сервиса, а вкладывать в развитие чужого проекта.
Но что это решение вам даст? Если у вас вообще ничего нет, буквально за неделю вы можете получить более-менее сносный поиск на вашем сайте.
Совершенствовать Sphinx или использовать Мантикору. Их можно было начать тюнинговать, подстраивать под себя, залезть прямо во внутренности. Если бы мы со Sphinx глубоко укоренились, то, может быть, и переделали бы его под себя, вариант рабочий. Но специалистов на рынке не так много и технология с кривой хайпа уже слетела. Я не знаю, использует ли кто-то Sphinx в новых проектах. Кажется, что он остался только в легаси.
Искать новую платформу и делать сервис на ней. Мы так и поступили и выбрали ElasticSearch. ElasticSearch — это выбор по умолчанию. Если отбросить всякие битриксы, то 8 из 10 e-comm-проектов, может быть, даже 9 будут на ElasticSearch.
Почему ElasticSearch
Простое масштабирование из коробки: есть шардинг и репликация. Тогда как в традиционных SQL-хранилищах это довольно сложные истории.
Люди читают доклады на Highload, проходят курсы, получают сертификаты, что они умеют со всем этим работать. В случае с ElasticSearch количество шардов, реплик — это два интовых параметра. Вы их просто задаёте, и всё работает. Естественно, есть свои подводные камни, но задача на порядок более лёгкая, нежели при настройке аналогичных вещей в традиционных хранилищах.
Богатое и хорошо задокументированное API, покрытое прекрасной документацией. Пожалуй, любой ваш продуктовый запрос, любая фича, которую вы захотите реализовать, будет делаться с помощью API, доступной из коробки без боли, и у вас будут отличные примеры того, как это должно работать. В частности, будут языковые пакеты для русского языка, то есть, если говорить про полнотекстовый поиск, всё, что вам нужно, уже там есть.
Сильное комьюнити. Вы никогда не столкнётесь с тем, что по вашей проблеме есть один единственный вопрос на Stack Overflow, который написали в 2017 году и по нему нет ни одного ответа, а больше вообще ничего не гуглится. На вопросы много отвечают, даже разработчики в GitHub. Нам, например, закрыли баг буквально через две недели после открытия.
Команда разработки умела и хотела работать с этим проектом. Если вы встраиваете в свою архитектуру что-то, с чем ваши ребята работать не хотят, то столкнётесь с тем, что они начнут увольняться, грустить, а новые люди на собеседованиях начнут вертеть носом. С Elastic вам это не грозит и не будет грозить ещё довольно долго.
Минусы ElasticSearch
Не может быть плюсов без минусов. Ведь это платформа, у которой есть свои ограничения. Вы с ними обязательно столкнётесь.
У ElasticSearch нет встроенного индексатора. Ведь ваши данные где-то лежат, вам их оттуда надо поместить в Elastic. Чтобы эту процедуру провести, нужен индексатор. А в данном случае вам придётся пилить его руками. Не могу сказать, что это большой минус. Задача не очень сложная, но надо её учитывать.
Elastic довольно прожорлив. Вам нужно быть готовым к тому, что даже на не очень большой каталог вам придётся тратить довольно много ресурсов. Гораздо больше, чем на аналогичные другие хранилища. Ваш каталог, размещённый в SQL-базе, наверное, будет потреблять на порядок меньше ресурсов, чем размещённый в Elastic.
И маленькая ремарка: мы не смотрели OpenSearch. Он появился после того, как мы сделали принципиальный выбор. Но сегодня я бы настоятельно рекомендовал как минимум подумать об этом.
Что такое OpenSearch? Это тот же Elastic, но от AWS. Однако ребята обещают, что фичи, которые в Elastic доступны в платной версии, а, стало быть, недоступны для нас с вами, у них есть в публичной версии. Именно поэтому они Elastic и форкнули, потому что не были согласны с тем, что в эластике начинают новые фишки делать платными.
В результате у нас получилась вот так простая архитектура:

Слева — монолит, в котором лежат мастер-данные, по центру — система поиска. Тот самый Indexer, про который я вам говорил, ElasticSearch, в котором лежат данные, и Finder — приложение, которое обрабатывает клиентские запросы с витрин. А витрины — это мобильное приложение, интернет-магазин. Обрабатывает запросы с витрин, ищет товары, отдаёт их на витрины. Приложения написаны на Go, это тоже выбор по умолчанию. Особенно для тех, кто начинал на РНР, то есть стандартный переход с РНР на Go тоже произошёл у нас на поиске.
Сейчас все приложения, как и в большинстве компаний, не живут на одном дата-центре. Все ваши приложения должны уметь по умолчанию жить на нескольких дата-центрах. Они стейтлесс, а на каждом дата-центре лежат просто независимые копии.
Но что делать с Elastic? Это какой-то стейт, и вы можете захотеть его растянуть на несколько дата-центров или, например, не растягивать. Мы выбрали не растягивать, потому что это базово сложная история. Межсерверная репликация гораздо сложнее, чем сделать два независимых кластера и обновлять их по отдельности, что нам не особо что-то даёт.
Нам может захотеться растягивать Elastic не потому, что мы можем, а потому, что хотим чего-то добиться, например, консистентности данных. Потому что, если мы не растянули, то, естественно, в двух независимых кластерах данные будут разъезжаться. Но в нашем случае это казалось не критично. Да, данные важные, да, клиент видит их каждый день, но нет требования, чтобы они идеально совпадали на нескольких дата-центрах. Более того, если всё сделать правильно, то сильно данные разъезжаться не будут.
И, наконец, независимые инсталляции, независимые кластеры нам дали возможность очень легко вводить новые дата-центры. Не пришлось ничего дотягивать, растягивать, перетягивать. Просто запускаете новый кластер, наливаете на него товар и точно так же гасите, например, если в каком-то дата-центре вы перестали работать. И их можно горизонтально размножать почкованием до бесконечности. Главное – только вовремя наливать в них данные.
Ещё один вопрос, который мог возникнуть при взгляде на предыдущую схему: делаем мы одно приложение для поиска или два?

Мы говорили вначале, что поисков у нас два типа. Это две очень разные задачи. Фасетный поиск — это история простая. Она сводится к числу-дробилке. У вас есть массивы ID товаров, привязанные к каждому фильтру, вы находите их интерсект. Задача очень простая. Полнотекстовый же поиск — задача на порядок сложнее. Вам нужно обработать строку, разбить её на токены, отбросить окончания, стоп-слова, синонимы. По тому, что происходит в квадратике Full Text Search, люди пишут диссертации. Это по-настоящему сложный вопрос.
Более того, эти два поиска имеют разный профиль нагрузки. В нашем случае это, например, 10% запросов полнотекста, и 90% — фасетного. Соответственно, ещё одна лампочка загорается — мы можем хотеть независимо их масштабировать. Звучит так, как будто надо делить, но мы всё равно сделали одно приложение. Почему так? Так проще. Два разных приложения — это два деплоймента, два мониторинга, две разные базы данных, потому что они у вас не могут делить одну базу данных, если делать правильно. Это примерно вдвое больше геморроя.
В то же самое время мы понимали, что хотим запуститься быстро. Что в этот момент надо сделать, если вы приняли такое решение? Так как приложение однажды вы всё-таки можете захотеть разделить по причинам, озвученным ранее, надо наметить шов, по которому этот микромонолит Finder будет разрезан, когда до этого дойдёт. Так мы и сделали.
Начинаем работать с ElasticSearch
Как можно использовать ElasticSearch:
Search Engine — просто как поисковый движок, так же, как мы до этого использовали Sphinx. Загоняете туда только те данные, по которым хотите фильтровать, искать, а все остальные не поисковые данные храните где-то ещё. Перед тем, как отдать ответ на витрину, оттуда обогащаетесь, или витрина сама обогащается. Возможны разные варианты, даже BFF.
Search Engine + Data Storage. Тогда в вашем Elastic будет всё, что нужно витрине — как поисковые данные, так и не поисковые. И в тот момент, когда приложение сходит в поисковый сервис, в ответ получит уже полный набор данных и сможет начать с ними работать, больше никуда за ними не обращаясь. Это означает чуть меньше точек отказа, чуть более высокую скорость за счёт меньшего количества запросов.
Мы выбрали второй вариант. Он избавлял нас от необходимости делать ещё один микросервис, потому что обогатителей не было, а из мастер-базы мы обогащаться по условиям задачи не могли, хотели её разгрузить, и получить быстрый старт.

Как бы выглядела архитектурная схема, если бы мы всё-таки решили сделать такой сервис? Всё то же самое, но добавился бы ещё один кубик — микросервис, в котором есть своё хранилище с этими непоисковыми данными. Почему такой сервис всё-таки может понадобиться? Потому что, если у вас его нет, может возникнуть ситуация, при которой поиск станет тем самым сервисом-обогатителем. Мы с этим столкнулись. В какой-то момент поняли, что люди к нам ходят за уже найденными товарами, потому что мы можем быстро их обогатить. Ситуация во всех смыслах неприятная. Потому что поиск — это поиск, он должен искать, он не должен обогащать. Обогащение в интернет-магазине нужно в очень большом количестве мест: на витрине, на карточках товара, каких-то подборках. Там, где вам не надо искать товары, где вы точно знаете, какие они. Есть набор идентификаторов, и нужно показать по ним данные.
Создание такого сервиса кажется хорошей идеей. И если вы не сделали его на старте, одной из первых оптимизаций может быть отделение непоисковых данных товарного каталога.
Создаём схему данных
Elastic не может работать без схемы. Даже если вы думаете, что Elastic работает без схемы, он работает со схемой. Просто эту схему создали не вы, а Elastic, на основании своих предположений о том, как выглядят ваши данные. А он про них не знает ничего: вы собираетесь с ними работать и какой их формат. Он просто получает первую запись в пустой индекс, в котором уже есть какие-то поля, какой-то формат, и создает под неё индекс. Если вторая запись будет отличаться от первой — неудача. Она в уже сформировавшийся индекс не влезет.
Поэтому схемы данных мы создаём руками. Мы про свои данные знаем всё. Соответственно, за схему отвечать нам, а не Elastic. Возникает вопрос: что с обратной совместимостью при миграциях?
В традиционных хранилищах мы обычно носимся с обратной совместимостью, запрещаем переименовывать колонки, удалять — вообще табу.
В Elastic в системе поиска мастер-данных быть не должно, никто их там и не хранит. Поэтому я бы предложил не обращать внимания на обратную совместимость. Мы в своей компании раз пять переделывали индекс полностью с нуля, потому что понимали, что текущая его версия не удовлетворяет потребности бизнеса. Они либо менялись, либо мы их плохо предугадывали, как это стандартно бывает. В этот момент вы просто переливаете данные целиком, и миграция ваших данных — это создание нового индекса с нуля и переключение на него.
Чтобы это всё работало, каждая версия приложения знает точно версию индекса, с которой будет работать. И она зашита прямо в его названии. У нас не индекс-продукт, а индекс продукт и хэш. Этот хэш — это как раз версия. Одновременно может жить несколько разных продуктов, несколько разных версий и разные инстансы приложения. Каждый знает, в какой индекс ему идти, поэтому всё происходит без даун тайма. А чтобы работала отладка, используем alias product-vbm2213mm33d → product.
Чтобы всё заработало, нужно, чтобы запись происходила быстро. Поэтому по каждому требованию берём и переналиваем индекс целиком. Это довольно долгая история. Если это будет длиться час, даже полчаса, это плохо, потому что изменения будут происходить долго.
Тут есть стандартные советы:
Не пишем ничего лишнего. Если вы не следуете этому совету, вам вообще ничего не поможет. В любом случае, у вас есть диск, сеть, и они вас будут ограничивать, как бы вы круто ни затюнили Elastic.
Используем Bulk Update.
И на время каких-то больших интеграций увеличиваем рефреш интервал, чтобы тоже ускорить запись.
Строим схему товарного индекса
Первое решение «в лоб». Мы решили, что у нас Data Storage и много данных. Создали большой 50-килобайный JSON, в котором содержались все данные о товаре, его атрибуты, картинки, категории и так далее. Естественно, не файлы, а ссылки на них. Получился большой документ. С большими документами Elastic работает плохо. На нашей стандартной, нормальной нагрузке без всяких load тестов получилось 200 миллисекунд по 90-му перцентилю. Хотелось бы вдвое меньше.
Что с этим можно сделать? Отказаться от данных мы не можем, у нас Data Storage, нам их хранить всё равно придётся. Поэтому мы нормализовали схему Elastic. Не знаю, насколько это применимо к документо-ориентированному хранилищу. У нас есть в документе товара вложенные документы, так называемые словарные сущности. Это категории, свойства, бренды. Их много — около десятка типов — и они дублируются. Если залить их в каждый товар, получится огромное количество дублирующейся информации в индексе, которая не нужна. Оставляем от словарных сущностей в индексе только идентификаторы, выносим их в отдельные индексы, индексы засовываем в память и обогащаемся данными оттуда уже на последнем этапе перед тем, как отдать ответ на витрину. Получилось очень здорово.
Улучшаем схему
Чтобы нормализовать схему ElasticSearch, вынесем словари в отдельные индексы и загрузим их в RAM. Результат налицо:
вдвое уменьшился объём индекса;
смогли независимо обновлять вложенные сущности;
ускорились на 30%.
При этом мы вынесли не все объекты, а только часть. Вот здесь можно посмотреть на визуализацию до и после:

Улучшаем чтение и запись
Я видел с десяток проектов с Elastic, разные команды, разных лидов. В каждом проекте были нарушены какие-то правила из документации. Случаев, когда это был осознанный трейд офф, я помню два. Всё остальное — это просто непрочитанная документация. Не надо изобретать велосипед, ребята-разработчики сделали набор крутых чертежей. Можно просто по чертежам собрать проект. И эту мысль я хочу донести: самый просто способ заставить Elastic работать хорошо — сделать так, как советуют его разработчики.
Обновление данных
В этом месте у нас есть рабочий сервис. На него пошли первые запросы, сервис начал зарабатывать деньги для компании. Он в проде. Отлично — победа. Как мы обновляем данные? Схема не меняется.

По красной стрелке раз в четыре часа прокатывается весь каталог товаров. Их порядка 100 000, плюс 10 складов — по документу на каждый. Весь этот набор данных прокатывается по красной стрелке, заливает в ElasticSearch. Число 4 — условно. Вместо него можно поставить 2, можно поставить час, можно даже 30 минут. Всегда будет какое-то окно, когда данные могут протухнуть. И они будут протухать обязательно, если это окно есть.

К чему это может привести. Запустили акцию — молоко по 49 рублей. Таких цен давно нет. Я думаю, многие из вас ходят в магазин, знают, сколько стоит молоко, и понимают, что надо брать. Наш клиент тоже это понимает и, не раздумывая, добавляет в корзину максимальное количество товара. Но может произойти такое: молоко закончилось, его раскупили, либо закончилась акция.

Есть ещё третий вариант: клиент ничего не заметил, всё купил и потом в чеке увидел, что у него молоко было по сотке. Это самый плохой вариант, потому что в этот момент мы клиента потеряли. Он понял, что его обманули и что покупать у нас никогда ничего нельзя, и всем друзьям расскажет, что Vprok — это обманщики.
Как этого избежать? Надо научиться обновлять данные по событиям — как только что-то изменилось в мастер-системе или в поисковом индексе. Желательно сразу.
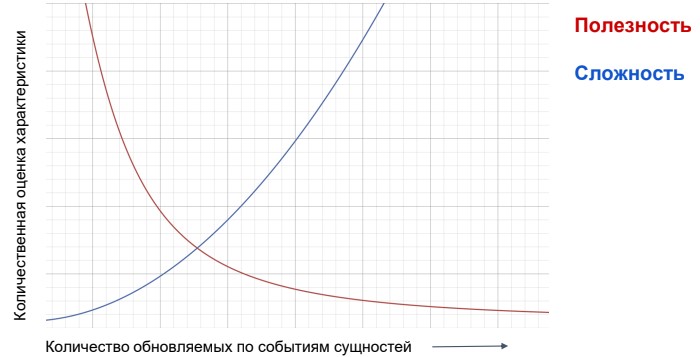
Что будем обновлять? Обновлять можно всё. Берёте тюринг-полный язык, на нём можно сделать что угодно. Но нужно ли? Я считаю, что нет. Выше изображен график, он не претендует на научность: в нём нет ни нуля, ни осей. Это некая визуализация правила Парето. Он иллюстрирует, что вам будет очень легко и полезно обновить наиболее чувствительные данные. Но по мере того, как вы будете двигаться дальше в изменении ваших данных по событиям, вы будете понимать, что это сделать всё сложнее, а пользы всё меньше.
Вы точно захотите менять цены и наличие сразу, как только это изменилось в мастер-системе. Возможно, вы захотите менять название, описание. И наверняка вы не захотите менять в Real-time рейтинг товара, потому что он меняется редко, и от него мало что зависит.
Потому предлагаю сконцентрироваться на наиболее чувствительных и горячих данных, а остальные менять уже по мере необходимости.

Чтобы менять данные, нужен консьюмер, продюсер, шина данных (Kafka). Берём шину данных, продюсер располагаем там, где данные меняются. В нашем случае — в монолите. Консьюмер — в индексере. Как только что-то меняется, сообщение попадает в шину данных, обрабатывается индексером и сразу же переиндексируются изменённые данные.
Для этого шлём обновленные данные или сигнал о необходимости переиндексации.

Отправляем данные целиком. Если что-то изменилось, то шлём всю сущность или какой-то diff. Можно послать сигнал, что обновился товар с таким-то ID и нужно скачать новую версию, так как в ней что-то поменялось.
Оба таких подхода имеют право на жизнь, но нужно выбрать один. Ведь мы не можем запустить оба одновременно.
Почему стоит отправлять сигнал
Отправку сигнала проще реализовать на клиенте. Не нужно рассчитывать никакой diff, есть ID изменённой сущности, который можно направить в шину, и индексатор сам разберётся.
Не важен порядок событий. Если 10 раз у вас одна и та же сущность изменилась, вам нужно 10 раз в том же порядке изменения обработать. В случае с сигналом это неважно. Почему? Каждый раз, когда вы обрабатываете сигнал, вы автоматически скачиваете самую новую версию документа. И даже если он между получением сигнала и получением вами данных успел ещё 10 раз поменяться, вы всё равно скачали самую последнюю.
Можно объединять обработку событий. Можно вообще все 10 не обрабатывать, а обработать только одно. Ровно по той причине, что вы автоматически получите самую новую версию.
Недостаток сигнала — дополнительный вызов, дополнительная точка отказа. Если у вас, например, какая-то жирная интеграция, можно DoS-нуть вашу мастер-систему этими запросами. Особенно если она шлёт много событий.
Почему стоит слать контент
Все данные есть в сообщении, их нужно просто вставить в индекс. Никаких сетевых вызовов, никакого DoS, никаких дополнительных точек отказа.
Из минусов то, что у вызова в плюсах: надо следить за порядком сообщений. Есть способы, как это победить. Можно использовать версионность, таймстемпы. Но в целом это геморрой, с которым вам придётся поработать.
Отправлять контент сложнее в реализации. То, что шлёт сообщение, должно уметь обработать этот Diff. А у нас, как вы помните, монолит, и в семи разных местах могут меняться данные. Они могут меняться даже какими-то сложными триггерами, не везде и всегда будет удобно и даже возможно собрать diff. И объединять несколько сообщений по одной сущности не получится, потому что вы не знаете заранее, какой в них контент. Он может очень сильно отличаться, и тогда вам придётся обработать все сообщения.
Вот визуализация объединения событий:

У вас есть какой-то поток постоянных событий из мастер-системы, вы их не обрабатываете, а буферизуете. Например, размер страницы — 10 штук или копим буфер 5 секунд. Буферизуете, оставляете только уникальные и обрабатываете пачку уникальных сигналов.
Итого я предлагаю слать сигнал.

Мы шлём сигнал. Эта история гораздо легче в реализации и в ней гораздо меньше подводных камней. Конкретно в нашем случае такой вариант оказался гораздо лучше, нежели отправлять все данные целиком.
И ещё один момент, связанный с переиндексацией — частичная переиндексация.
Как переиндексировать фрагменты документов:

Индекс по-прежнему состоит из нескольких сущностей, которые меняются независимо. Это данные о товаре, ценах, наличии и ещё о ряде сущностей. Поиск должен быть способен работать со всеми этими данными, поэтому они должны быть включены в индекс. Для этого он и был создан. И всегда будет необходимость обновить не весь документ целиком, а какой-то его кусочек. Но ElasticSearch не умеет частичную переиндексацию, вам придётся переиндексировать весь документ сразу.
Что с этим делать? В принципе, можно ничего не делать. Если это не создаёт какой-то значительной нагрузки, если вы на своих мониторингах видите, что никаких проблем нет, то и решать ничего не надо. Но если проблема возникла и событий много, возрастает нагрузка на Elastic, и нужно что-то решать.
Как переиндексировать фрагменты документов
Частичную переиндексацию можно сделать с помощью скриптов. Есть в Elastic возможность не просто писать декларативные запросы, а выполнять в нём какие-то скрипты. Вот пример, как такое может выглядеть:

Вы пишете скрипт на языке Painless. Это что-то типа Java. Горькая ирония зашита в этом названии, потому что боли с подобного рода решением как раз достаточно. Зато с помощью этого инструмента можно сделать с индексом практически всё, что угодно. В данном случае — переиндексировать кусок документа.
Какие здесь нюансы? Во-первых, если вы не джависты, то будьте готовы к тому, что у вас новый язык в стеке. Это суть Java. Во-вторых, отлаживать и тестировать такие скрипты очень сложно. В коде приложения вы имеете дело просто со строкой. Исполняется она прямо в Elastic, и тестировать и отлаживать вы можете это только в Elastic. Но в нашем случае сложности оправдались тем, что мы смогли с помощью этой технологии сделать частичную переиндексацию наших данных без необходимости весь гигантский JSON (а помните, что он у нас большой) переиндексировать целиком.
Индексация: пилим монолит
Какая проблема со всеми предыдущими схемами? Монолит. У кого вообще сейчас есть монолит? Вот прям целый, первозданный и нетронутый? Мало у кого. И у нас он тоже не такой. Сейчас картина выглядит как-то так:

Есть какие-то недобитые остатки монолита, а есть куча сервисов, которые из него выделили, и местами работа с мастер-данными ведётся уже в них. Это гораздо сложнее, чем все предыдущие картинки. Потому что налить данные из одного источника больше нельзя, этого источника больше нет. Они теперь лежат в разных сервисах, в разных местах и форматах. Мы должны, когда наливаем индекс, клеить их из нескольких источников.
Здесь появляется множество неприятных моментов, связанных с тем, что нарушается целостность данных. Например, пришли вам данные по ценам, пришли данные по наличию, а по товару данных нет. Или наоборот. Миграция индекса — ещё одна большая боль, потому что вам надо прямо с нуля налиться, сходить во все четыре сервиса, все их целиком скачать, поклеить эти данные и заложить в индекс. Это сложно. Более того, некоторые сервисы вообще не поддерживают подобного рода операции. Я прихожу к ребятам из сервиса остатков, говорю, что нам нужно делать вот так, на что получаю ответ: «Мы, вообще-то, не для того сервис делали, чтобы раз в четыре часа нас досили и скачивали 300 метров данных. Давайте вы не будете так делать никогда».
Что с этим всем делать? Как в предыдущем примере, не делать ничего не получится. К счастью решение есть и здесь.

Если у вас нет монолита, вы можете симулировать его. Чтобы это работало и не упало, предлагаю решение — сервис Fake Monolith. Это база, которая агрегирует данные из микросервисов, работает с ними по их протоколам, с кем-то по старинке, скачивая всё сразу по расписанию, с кем-то только по событиям. Она в себе это агрегирует, следит за целостностью данных, а индексер работает с фейк-монолитом, как будто ничего не поменялось. У него просто поменялся url, на который надо ходить. Таким образом, в фейк монолите инкапсулируется сложность по работе со всем этим многоцветным зоопарком, который у нас на слайде представлен слева.
Единственный момент, который надо не забыть: когда в шину данных попадает какое-то событие, мы его обрабатываем, сразу прокидываем в поисковый индекс, нам надо не забыть ещё поместить его в фейк монолит. Иначе при следующей переиндексации этих данных там не будет.
Заключение
В статье мы охватили небольшую часть огромной предментой области, рассмотрев решения, которые так или иначе придётся принять при построении внутренней системы поиска. Вообще поиск — тема сложная, в е-коме, наверное, это вообще самое сложное. Поэтому всё, конечно же, охватить не удалось, но, надеюсь, эта статья поможет вам наступить на меньшее число граблей, когда вы будете делать свой поиск.
Комментарии (8)

9982th
13.10.2023 10:00В чем минусы распила монолита вы рассказали, а в чем плюсы?

StepanRodionov Автор
13.10.2023 10:00Для системы поиска плюсов как таковых нет. Сущности отдельно обновлять мы умели уже с монолитом, а полный пролив данных гораздо удобнее делать из одного источника.
Что это дает проекту в целом и компании - совсем другая история и она сильно выходит за рамки этой темы. Там есть и плюсы и минусы и тех и других достаточно много.
У меня кстати есть на эту тему немного холиварный доклад с одной региональной конференции

andreypaa
13.10.2023 10:00Про Manticore упомянули и по факту в ней устранены все минусы, о которых вы написали и к тому же она не такая прожарливая как Elastic, но не написали, почему ее не пробовали, хотя цена такой пробы минимальна, т.к. запросы практически были би идентичны.

nataliya_apl
13.10.2023 10:00На текущий момент в Эластике уже есть новый функционал Enterprise Search, он правда плохо документирован, некоторые вещи пришлось подсмотреть у Кибаны.
Как минимум позволяет:
Выполнять для автозаполнения
Выполнять поиск без указания уже каких-то своих конструкций
Настраивать точность поиска в самом интерфейсе
Добавляет поиск по синонимам
Синонимы это как раз то чего не хватало.
Вот только остается проблема - как автоматизировать процесс наполнения базы синонимов по товарам?
Например тот-же iPhone может же написано по разному:
iPhone
Айфон
В первом случае найдет просто Эластик, во втором - нет. Но если добавить синоним, найдет в обоих.
StepanRodionov Автор
13.10.2023 10:00Конкретно пример с iPhone-Айфон решается через использование фонетического анализатора. Это тоже не панацея, он тоже ошибается, но с простыми кейсами позволяет справиться без ручного прописывания синонимов.
Что до синонимов, они есть в базовой коробке, можно подложить на VM с эластиком файл со списком синонимов и сослаться на него в настройках. Вот тут описано https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-synonym-tokenfilter.html#_solr_synonyms
Также синонимы можно сделать костыльно (этот пусть тоже проходили), закидывая в документы в какое-нибудь поле а-ля synonyms список того, по чему он тоже должен находиться. Это довольно плохой путь, потому что если их много, обилие ключевых слов ломает TF/IDF алгоритмы. У нас в какой-то момент с этим произошла проблема, когда контент-редакторы стали заниматься "SEO-оптимизацией" поиска через наваливание синонимов товарам, которые хотели поднять повыше. Пришлось бить по рукам
TyVik
Пример с молоком показательный, что все врут (c) В описании 950г, а цена 99.90 за кг, а итоговая не пересчиталась. Но покупатель же не заметит...
StepanRodionov Автор
Вообще там цена стоит "р/шт", а не "р/кг". Но да, странно, что в корзине выводится килограмм. Посмотрим, спасибо за внимательность!
StepanRodionov Автор
А вот и ответ коллег подоспел. В корзине пишут вес брутто, чтобы клиент понимал общий вес доставки. Это особенно хорошо заметно, если что-нибудь в стекле положить в корзину, там раза в два может вес расходиться с весом продукта.
С молоком просто неудачный пример, потому что уменьшение упаковки всех уже достало :)