public NewArticle() {
Console.WriteLine("Author: https://github.com/paulbuzakov")
Console.WriteLine("Hi, There!!!");В этой статье я хотел бы затронуть тему хранения кода в Git, контроля версий, релизов и в целом как этим всем управлять в команде.
Существует множество моделей хранения кода, но многие из них не имели место на существование заранее, так как решали довольно конкретные задачи, или не масштабировались, или были слишком неудобными, или вообще состояли из одной ветки. Судя из названия статьи, я хочу рассмотреть GitFlow модель в контексте того, как мы применяем ее на практике в нашем проекте.
GitFlow Workflow подробно описал еще в 2010 году Vincent Driessen в своем блоге. С тех пор прошло много времени, созданы более модные «магистральные» модели доставки. Их принято считать более простыми с точки зрения простоты доставки на прод, но я уверен — они подойдут не для всех проектов.
Что бы не быть просто «диванным специалистом» из интернета немного расскажу о себе. Я.Net программист, немного касающийся React, TypeScript (сейчас фронтовая разработка мне нравится больше), а так же тим лид команды в одной из федеральных фармацевтических компаний. У меня 14 лет коммерческого опыта разработки, в том числе создание облачных сервисов и программных продуктов для федеральных банков, фарм компаний, фондового рынка, иностранных компаний, гос органов и тд.
На этапе проектирования абсолютно нового проекта у нас, как раз, возник вопрос хранения кода. В такие моменты хочется сделать все идеально и поэтому мы погрузились в этот вопрос. Входные данные были не очень — в других проектах компании был Svn, мы были первой командой которая перетащит всю кодовую базу в Git (пора бы, как никак 2020 год был уже =)) и по началу мы решили сами выдумать модель версионирования (ее я рисовал в этой статье), но выдумка была сложной.
Почему GitFlow?
… выдумка была сложной!!!» — поэтому мы обратились к интернету — он все знает и ведает. GitFlow Workflow стал для нас оптимальной моделью.
У нас было 12 разработчиков и мы часто пересекались в задачах друг с другом. Одной большой задачей могли заниматься до 3х человек, и без комита от каждого из них мы не могли заливать задачу в целом на тестирование — это попросту не имело смысла.
У нас была не потоковая сдача функционала, а итеративная — двух‑трех недельная.
У нас были задачи очень привязанные к сроку релиза в гос органах, то есть фича ветки могли просто лежать по месяцу без движения в прод.
У нас попросту не была реализована эта потоковая доставка функционала на последующих этапах.
Что же такое GitFlow?
GitFlow — это определенная надстройка над моделью ветвления Git, которая включает в себя использование фича веток и несколько основных веток. По сравнению с разработкой на основе «магистрали», GitFlow имеет многочисленные, более долгоживущие ветки и более крупные фиксации. В рамках этой модели разработчики создают фича ветку и откладывают ее слияние с основной веткой до тех пор, пока функционал не будет завершен. Эти долгоживущие фича ветки требуют большего сотрудничества для слияния и имеют более высокий риск отклонения от ветви магистрали. Они также могут вводить противоречивые обновления.
Давайте рассмотрим схему веток и их взаимодействие межде друг другом из самого первоисточника, как это представлял сам автор.
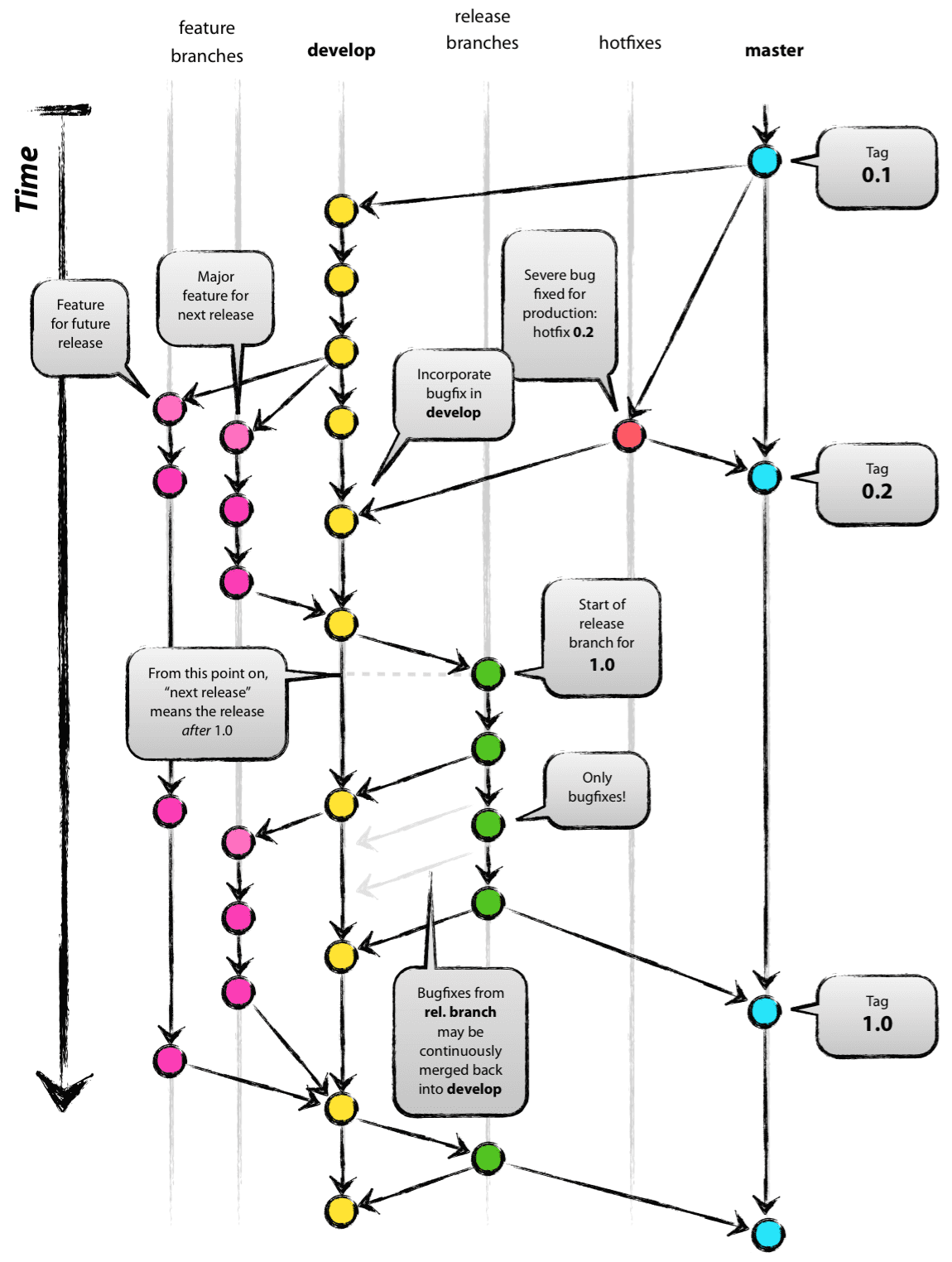
В нашей версии модели начинают фигурировать еще и разработческие ветки, созданные от фича веток, то есть у фича веток может быть много разработческих ветвлений и существовать они будут до тех пор пока фича не сольется куда-то дальше по процессу.
feature/task-1 => dev/task-1/buzakov
Но по сути, если отбросить все условности, то модель разработки GitFlow заключается между 2х постоянных веток:
master (стабильно работающая или продакшен версия кода)
develop (последняя или «nightly»-версия кода)
master branch (main branch)
После определенных событий в мире - ветку master переименовали в main.
main — это основная ветка кода, продакшен версия кода, то есть все сборки для реальных клиентов собирают как раз из этой ветки. Ветка может быть помечена тегами, в которых есть информация о версии и часто к тегу еще привязываются релизы. Любая новая задача взятая в работу начинается с мастер ветки. Немного позже, я раскрою наши поведенческие паттерны работы с веткой main.
Суть этой ветки хранить самую последнюю работоспособную версию кода.
develop branch
Я бы назвал эту ветку, как основная ветка кода для тестировщиков, но меня закидают камнями.
Исходя из практического опыта программисты не часто работают с этой веткой, а большую часть времени с ней проводят, как раз тестировщики анализирую функционал на работоспособность и наличие багов, а программеры просто сливают в нее новый код.
Суть этой ветки просто хранить в себе самую последнюю кодовую базу проекта.
Работа с ветками
Сейчас я бы хотел рассмотреть некоторые стандартные кейсы в GitFlow процессе разработки:
Разработка нового функционала
Исправление ошибки в новом функционале после тестирования
Создание новой версии релиза
Исправление критической ошибки на продакшене
Разработка нового функционала
Допустим у нас на проекте есть некая новая задача (MW-1234). Давайте рассмотрим этапы работы с этой задачей от взятия в работу и до релиза.
Создаем фича ветку из main (main ⇒ feature/MW-1234). Если над этой задачей работают еще программисты, то я бы посоветовал от фича ветки создать еще разработческие ветки на каждого разраба (main ⇒ feature/MW-1234 ⇒ dev/MW-1234/buzakov). Это важно особенно в тех случая, когда ваш комит в фича ветку бесполезен без комитов других разработчиков.
Разрабатываем функционал и заливаем комиты в фича ветку или разработческую ветку, созданную от фича ветки.
Проверяем код и тестируем функционал в фича ветке.
Создаем pull‑request в develop ветку.
Когда тестировщики проверили функционал в дев ветке создаем релиз и мержим в мастер
Выпускаем новую версию кода
Бранч менеджмент:
main(tag: 0.1.0)
=> feature/mw-1234
=> dev/mw-1234/buzakov
=> feature/mw-1234
=> dev
=> release/0.1.1
=> master(tag: 0.1.1)
Исправление ошибки
Если тестировщик в процессе проверки задачи находит ошибки, то программист исправляет их в dev/mw-1234/buzakov ветке и заливает дальше по веткам, как при мерже веток в предыдущем варианте, то есть бранч менеджмент у нас такой:
dev/feature/mw-1234/buzakov
=> feature/mw-1234
=> develop
=> дальше по процессу...
Исправление критической ошибки
Ну вот мы и выпустили новую версию, посидели порадовались и поехали домой, но звонит начальник и говорит, что нашли критичную ошибку, а последний код уже в main ветке.
Что делать?
Мы создаем из main ветки hotfix («быстрофикс») ветку, то есть main ⇒ hotfix/error-123. Исправляем ее и заливаем комит в эту «быстрофикс ветку», тестируем еще раз, что не наломали еще больше дров и сливаем в main. Получается следующая схема:
main(tag: 0.1.1)
=> hotfix/error-123
=> main (tag: 0.1.2)Хотфикс — залит в мастер.
Прод — работает.
Все хорошо.
Выводы
«GitFlow процесс очень трудоемкий и местами запутанный» — я соглашусь с многочисленными хейтерами оного, но он позволяет закрыть 2 пунка стабильности: 1. продакшен версия кода более стабильна, чем при водопадных слитиях; 2. тестовый стенд работает стабильнее, так как программисты сливают свой код в фича ветки, и случаев типа «Ой, я думал ты слил, а Я думал ты не слил уже» практически не бывает. При магистральных поставках осознанность и компетентность команды должна быть на высоком уровне, что в текущих реалиях вообще не возможно. За последний год у меня было 90 собеседований с программистами разного уровня паршивости — и я уже давно не встречал трушных программистов, которые имеют знания на высоком уровне.
В заключении этой статьи еще хочется напомнить поговорку «научи дурака молиться — он себе лоб расшибет». К чему это я? GitFlow, или магистралая доставка, или GitHub Flow, или еще тысяча другая подобных схем разработки и доставки кода на прод — все хорошо работают, не надо усложнять там где можно сделать проще и всегда думайте перед началом работы над новой задачей, но не упарывайтесь в бессоные ночи и поиски идеала.
В любой из перечисленных моделей разработки есть, как плюсы, так и минусы. Идеальная модель для большого проекта может совсем на подойти маленькому стартапу.
return 1;
}Референсы:
Комментарии (36)
Leopotam
14.10.2023 06:47+172010 - перевод оригинальной статьи https://habr.com/ru/articles/106912/
2020 - опровержение оригинальной статьи https://habr.com/ru/companies/flant/articles/491320/
альтернативы - https://habr.com/ru/companies/infopulse/articles/345826/
и практика - https://habr.com/ru/articles/705032/
На хабре точно была нужна еще одна подобная статья про gitflow, да еще и с картинками из старых статей?
paulbuzakov Автор
14.10.2023 06:47За последние 4 года я участвовал в семи разных проектах и ни один я бы не назвал маленьким, но нигде не было нормального git менеджмента, соответственно стоит потрогать информацию снова. Мне очень симпатичен процесс изучения от истоков к современности. Какой git менеджент предпочитаете вы?

f0rk
14.10.2023 06:47+1GitFlow имеет смысл только если нет простого механизма отката изменений из прода (читай "мобильная разработка"). В остальных случаях GitHub Flow проще и стабильнее. Для обеспечения стабильности, катить в прод нужно до того как слили в мастер, и сливать только после того как убедились, что ничто не сломано. Если сломано - rollback на последний мастер в общем случае.
paulbuzakov Автор
14.10.2023 06:47Хранение кода в любом случае это вопрос творческий. Катить в препрод и проверять там до мастера я согласен, а в сам прод до мастера - звучит неправильно. Спасибо, я обязательно разберу github flow в следующей статье, как один из современных подходов.

inkelyad
14.10.2023 06:47Хранение кода в любом случае это вопрос творческий.
И не обязан быть в одном репозитарии.
Хотелось бы увидеть статью, посвященную методов, когда репозитариев - много (на машинах разработчиков, для стенд(ов) тестирования, архивный итд) и ветки из одного в другой перекидываются в процессе разработки.
f0rk
14.10.2023 06:47"звучит неправильно" - так себе аргумент. Код в ветке после ребейза на мастер ничем не отличается от кода в мастере после мержа. Разница между этими подходами только в том, что сливая в мастер до выкатки мы увеличиваем вероятность получить сломанный коммит в мастере.
paulbuzakov Автор
14.10.2023 06:47Я не очень понимаю о чем вы. При любом мерже или ребейсе, есть вероятность получить конфликт. То есть где-то в какой-то ветке у вас код рабочий, а в мастере конфликт неправильно решен, но создавать фича ветки вы будете из мастера. ИТОГ? Код не будет правильно работать в след версиях.
f0rk
14.10.2023 06:47+1При чем тут конфликты? Если мы ребейзнули ветку на последний мастер, то мерж этой ветки в мастер будет fast-forward, master и feature-branch будут указателями на один и тот же коммит.
Снепшот кода который мы деплоим будет одинаковым в обоих вариантах флоу:
# flow 1 git fetch git rebase origin/master deploy to prod git checkout master git merge feature-branch # flow 2 git fetch git rebase origin/master git checkout master git merge feature-branch deploy to prodПонятно что в реальности есть куча нюансов, если команда большая, то возможно будет нужно настроить merge queue и тд., но думаю, общий смысл понятен.
paulbuzakov Автор
14.10.2023 06:47+2Если бы все были такими умными и грамотными, как вы =)
Я когда уходил с одного из проектов, вместо меня релизы делать поставили Джуна, а он «ребейс» слово такое не слышал.
Точно так же и в самих программах прослойках (условно гитхаб подобных системах) есть баги.
Если есть вероятность на какой-то из точек упасть или ошибиться, то это плохо.
f0rk
14.10.2023 06:47+2Мы же особенности flow обсуждаем, причем тут джуны и ошибки?
Как раз с точки зрения риска и сложности gitflow проигрывает, если мы говорим о типичной backend разработке.
Зачем рисковать возникновением эмерджентных багов при интеграции фич , усложнять цикл разработки и размывать ответственность введением таких ролей как релиз-инженер и тд, когда можно быстро катить фичи атомарно?
Научить людей ребейзить - не очень сложная задача.
paulbuzakov Автор
14.10.2023 06:47+1Я бы с удовольствием почитал о вашем варианте бранч менеджмента.
f0rk
14.10.2023 06:47+2В общем и целом - https://githubflow.github.io/
Выкатка в прод немного отличается. Алгоритм следующий:
1. Lock master branch
2. Rebase on origin/master
3. Deploy to production
4. Track metrics
5. Merge to master
6. Unlock master
Если на 4-м шаге возникли какие-то проблемы то просто откатываем на последний мастер.
Разработчик полностью отвечает за весь цикл разработки фичи и сам катит ее в прод. Каждая фича катится атомарно, то есть нет необходимости выяснять кто и что сломал в ветке где идет интеграция при подготовке релиза, так как "релизов" по сути нет. При таком флоу нормальная продуктивная команда из 5-7 человек катит в прод 2-3 раза в день.

dsoastro
14.10.2023 06:47А что если другая команда выпустила свою фичу и раньше влила ее в мастер и merge с мастером имеет конфликты?
paulbuzakov Автор
14.10.2023 06:47-5Технически такая ситуация не возможна, обычно разные команды пишут код в разных репах.
f0rk
14.10.2023 06:47Расскажите это ребятам из google или yandex :)
paulbuzakov Автор
14.10.2023 06:47-1Я сторонник обособленного командного проектирования. Вопрос у человека был конкретный(как я его понял): Пришла другая команда, слила что-то нашей команде в репу, а у твоей команды потом конфликт из-за этого. Такое программирование я не приемлю потому, что каждая сепарированная команда должна сама отвечать за свои репы и функциональные блоки.
Вы соседям можете диктовать что им делать только снаружи их територии, но не внутри!
Опять же я считаю такой подход правильным, как минимум из-за "межкомандной дельты" в распределении обязанностей.
inkelyad
14.10.2023 06:47+1<Глядим на (в который раз повторяющейся) картинки.>
И пытаемся объяснить/нарисовать.
Как будет выглядеть граф коммитов и тегов, когда у нас выпускается хотфикс, который приводит к появлению версий 0.3 и 1.1 Все на main поставить уже не получится, если я ничего не путаю.
Какой цели вообще ветка main служит? Хранит 'рабочие/продовские' версии? Ну так у нас теги 0.3, 1.0 итд есть, которые можно с успехом поставить на коммитках веток release-*
Это я к тому, что master ветка как таковая тут практически лишняя и тащится из объяснения к объяснению просто по инерции.

saboteur_kiev
14.10.2023 06:47+4Мастер ветка нужна для того, чтобы там были исключительно релизные коммиты-теги, от которых отпочковываться в случае хотфиксов (которые затем назад вливаются одним коммитом).
Очень чистая ветка, один коммит - один релизДевелоп ветка содержит чистые вливания готовых и законченных фич, и от нее отпочковываются релизные ветки. Это нужно в том случае, если у вас в разработке может быть сразу несколько релизов с разными набором фич, которые еще допиливаются, и надо ближайший релиз уже отрезать от девелопмента, чтобы в него непопадали новые фичи следующих релизов.
А вот релизные ветки как таковые хранить не нужно, в них просто всякий "мусор" - вливания фич, багфиксы в процессе тестирования, срочные довливания и заметание под ковер перед релизом, это все в деталях хранить не обязательно.
Поэтому в git workflow стабильные ветки это только мастер и девелопмент. ВСЕ остальные удаляются после мержа или после мержа с небольшой задержкой.
Но вообще, перед тем как выбирать воркфлоу, автору следовало в первую очередь подумать именно над релизами, именно от политики релизов и разработки следует отталкиваться при выборе своего флоу (или кастомизации любого популярного)
paulbuzakov Автор
14.10.2023 06:47+1Да, вы правы, Я тоже за чистоту в ветках!
В моем "розовом мире" есть только две постоянные ветки мастер и девелоп. После того как все действия с задачей произведены и задача слита в девелоп или мастер(зависит от статуса задачи) любая другая ветка должна быть удалена.
Согласен, при выборе метода для бранч менедждмента, схема и частотность релизов один из главных критериев. В моем случае магистральная доставка вообще не имела быть, потому что проект разрабатывался с нуля, и релизить каждую новую таблицу или функцию не имело практичекского смысла.
inkelyad
14.10.2023 06:47Мастер ветка нужна для того, чтобы там были исключительно релизные коммиты-теги, от которых отпочковываться в случае хотфиксов (которые затем назад вливаются одним коммитом).Очень чистая ветка, один коммит - один релиз
Для чего нужна ветка. Релизных коммит-тегов, поставленных там где надо - достаточно же вроде? То что там между этими тегами пачки коммитов будут - вроде ничему не мешает.
А так же смотрим у меня первый пункт. Версию 0.3 как на main помещать придется?
А вот релизные ветки как таковые хранить не нужно, в них просто всякий "мусор" - вливания фич, багфиксы в процессе тестирования, срочные довливания и заметание под ковер перед релизом, это все в деталях хранить не обязательно.
И тут уже успешно запутались, что именно релизными ветками называется и их предназначение.
Вот есть у нас у PostgreSQL версии 16.* и он же 10.* -- неужели эти ветки 'хранить не нужно'? (Я про картину мира gitflow. Мое собственное мнение - что таки да, не нужно. Те же аргументы, что про main выше, и к ним применимы -- расставляем теги где надо и все)
paulbuzakov Автор
14.10.2023 06:47Хранить ветки релизов и хотфиксов, где проставляется тег новой версии - тоже один из подходов, но для меня это точно так же как и не мыть посуду после еды =))
Я считаю, что все версии стоит хранить в одной коробке (main), что бы не нарушать принцип консистентности данных. Да и остальные 100 - 500 веток релизов и фиксов - нужно удалить.
Зачем все это тащить в новый мир?
saboteur_kiev
14.10.2023 06:47+1Для чего нужна ветка. Релизных коммит-тегов, поставленных там где надо - достаточно же вроде? То что там между этими тегами пачки коммитов будут - вроде ничему не мешает.
Очень даже мешает.
Лишние коммиты мешают и просмотру истории нормальной и отпочковыванию. Если в вашем проекте релиз в полгода-год и коммитов 50-60 в месяц, то представьте проект где релизы идут каждую неделю, а коммитов столько, что даже фича бренчей за полгода накапливается пару тысяч.
Зачем это все хранить, менеджить?
Как автоматизировать релиз ноты, если в коммитах куча мусора, а не аккуратное JIRA-1000 feature blabla, JIRA-2000 bugfix blablaА так же смотрим у меня первый пункт. Версию 0.3 как на main помещать придется?
Хотфикс это тоже релиз. Просто слово хотфикс обозначает и фикс конкретного ишью, и релиз, когда в продакшен это изменение выводится А ведь одним релизом можно несоклько ишью поправить поэтому в данном случае хотфикс - это именно релиз, минорный, без новыйх фич, просто багфиксы/хотфиксы. И он должен быть в майн ветке, поскольку версию 2 нужно отпочковывать уже не от 2.0, а от 2.03 хотфикса, как последнего в этой версии.
И тут уже успешно запутались, что именно релизными ветками называется и их предназначение.
Релизная ветка - это ветка, которая готовится для релиза ДО того как он выведен в продакшен.
Раньше делали code freeze - замораживали всю разработку и тестировали эту версию, внося багфиксы перед релизом. Сейчас можно сделать релизную ветку и фиксить в ней, при этом все фиксы для эотго релиза мержатся и в релизную ветку и в девелоп. А новые фичи - уже только в девелоп - они пойдут в следующий релиз. После того как релиз произошел, релизная ветка больше не нужна - в мастер можно ее замержить или перед релизом и взять билд с мастер ветки, или даже после релиза, важна не столько дата, сколько коммит.
А бывает что в разработке сразу релиз 1, который в конце недели выйдет, релиз 2, который планируется на следующий месяц и релиз три, который на следующий квартал. И тут без чистоты в ветках будет просто гроб.Вот есть у нас у PostgreSQL версии 16.* и он же 10.* -- неужели эти ветки 'хранить не нужно'? (Я про картину мира gitflow. Мое собственное мнение - что таки да, не нужно. Те же аргументы, что про main выше, и к ним применимы -- расставляем теги где надо и все)
У вас просто постгрес. А не 100 полунезависимых микросервисов, где для релиза надо еще их как-то между собой синхронизировать, и тут semver не сильно помогает.
Еще раз, проекты бывают разные. Бывает когда проект пишет одна команда, а бывает когда десять. А бывает когда это 5 команд сишников, 2 команды дба, пару команд UI и вообще отдельная команда QA. ИЛи наоборот универсальные команды, которым попадают разные наборы фич или как-то еще делится. И этим всем нужно управлять, чтобы люди не простаивали и не тратили больше времени на бюрократию чем на код.классический git workflow очень неплох для ентерпрайзов с множественными командами. А постгрес, несморя на свой вклад в ИТ мире, не совсем ентерпрайз компания, им такое не нужно. Бизнес фичи не падают с неба за неделю до релиза, технические джиры имеют хороший приоритет, ибо это в первую очередь технологический продукт. В общем вы не то сравниваете. Сравните да хотя бы такой проект, как "панели настройки виндовс", когда в 11 винде для одного настройки можно найти 3-5 панелей с ней от разных версий, плюс реестр, повершелл и может быть что-то еще.
inkelyad
14.10.2023 06:47+1И он должен быть в майн ветке, поскольку версию 2 нужно отпочковывать уже не от 2.0, а от 2.03 хотфикса, как последнего в этой версии.
Не понял возражения. Вот на стандартной картинке есть приложение версии 0.2 оно у кого-то стоит. И есть приложение/сервис/библиотека версии 1.0, более новое. Оно тоже у кого-то стоит. Одновременно с версией 0.2, Потому что люди, пользующиеся 0.2, еще на 1.0 не смогли переехать.
И тут находится критический баг в версии 0.2. Которого, возможно, в 1.0 уже нет просто потому что соответствующий код уже давно весь переписан.
Мы делаем исправленную версию 0.3, ответвляясь от 0.2. Ставим тег, отгружаем клиенту..
Все хорошо и понятно.
Вот только эта процедура ломает концепцию main-а. Потому что релизного коммита 0.3 на ней нет.
saboteur_kiev
14.10.2023 06:47Вот только эта процедура ломает концепцию main-а. Потому что релизного коммита 0.3 на ней нет.
Так я вам повторяю, постгрес - это не ентерпрайз. Это продукт, который продается разным клиентам. А в ентерпрайзе пишется своя система для себя, свой складской учет, свой банкинг. Единственному клиенту. И там поддержка предыдущих версий нужна только пока в релиз не выйдет более новая версия, ну и для отчетности/бюрократических моментов на случай аутсорс разработки и передачи кода.
То есть опять таки, отталкиваемся от релизов.inkelyad
14.10.2023 06:47И там поддержка предыдущих версий нужна только пока в релиз не выйдет более новая версия, ну и для отчетности/бюрократических моментов на случай аутсорс разработки и передачи кода.
Это очень оптимистичный энтерпрайз. Если он большой и толстый, то может быть и так:
Сборка 2.17 сейчас эксплуатируется с набором конфигурационных параметров версии 13.7
Сегодня будут эту же сборку будут внедрять с набором конфигурационных параметров версии 14.0 (Потом что полнолунье и нужно включить фичу, которую мы для этого дня приготовили пару месяцев назад)
На полном интеграционном тестировании находится сборка 3.11 (полное - все сервисы в сборе максимально близко к эксплуатационной конфигурации)
На частичном интеграционном тестировании находится сборка 4.17 (частичная - вместо внешних сервисов стоят тестовые эмуляторы)
А пишем мы сейчас то, что будет сборкой 5.3
Ну и вот дефект разной степени критичности может может прилететь с любого места в этой цепочке. Т.е. нам может потребоваться чинить любую версию кода из (2.17, 3.11, 4.17), потом вливать этот фикс во все затронуты версии (можем получить 2.18, 3.12, 4.18 в различных сочетаниях) собирать их, пускать тестирование либо совсем заново либо по укороченному пути... И так далее.
В общем, разных "предыдущих" версий по отношению к тому, что мы вот прямо сейчас кодим - может быть небольшая кучка.
То есть опять таки, отталкиваемся от релизов.
Оно в обе стороны влияет в разной степени. Когда выбирают релизный цикл - приходится смотреть, какой вариант получится сделать (и не запутаться), а какой нет.
saboteur_kiev
14.10.2023 06:47Сборка 2.17 сейчас эксплуатируется с набором конфигурационных параметров версии 13.7
Вот это для меня непонятно. Конфигурация должна быть совместима, и собственно сборка и версия это одно и тоже?
Никто же не мешает сделать релиз, в котором только конфиги отличаются?
Что по поводу мержа фиксов в разные версии:Стандартный git flow предполагает, что в продакшене сейчас только одна версия.
Поэтому для мержа нужно просто взять продакшен релиз из main, сделать от него хотфикс ветку, замержить все необходимое туда, зарелизиться и замержить хотфикс назад в main с новой версией.
Параллельно хотфикс надо замержить в девелоп.
Все.
Ну если прямо сейчас идет подготовка к новому релизу, то замержить в его релизную ветку. При этом может быть даже не нужно делать хотфикс для старой ветки, если исправление бага не срочное и оно может просто выйти с этим новым релизом.
Если у вас продукт может стоять в нескольких экземплярах разных версий, то ЕСТЕСТВЕННО нужно хранить релизные ветки для каждой актуально, и тогда main теряет смысл.
То есть мы спорим ни о чем. Я изначально говорил, что flow в первую очередь зависит от ваших релизов.
inkelyad
14.10.2023 06:47+1Зачем это все хранить, менеджить?
Вот именно. Зачем мучать себя мержем чего-то в main и хранить его, когда можно этого не делать?
Как автоматизировать релиз ноты, если в коммитах куча мусора, а не аккуратное JIRA-1000 feature blabla, JIRA-2000 bugfix blabla
По текстам тегов. Которые "толстые". Именно потому что в коммиты постоянно попадает всякий мусор и редактировать их текст не очень удобно, когда ветка успела убежать.
А теги - редактируются легче. Плюс их ставить может совсем другой человек.
inkelyad
14.10.2023 06:47+1классический git workflow очень неплох для ентерпрайзов с множественными командами.
Я не спорю. Мой тезис - что main там достаточно лишний, т.к. ничего слишком полезного не добавляет и скорее запутывает и усложняет.
И да, когда я писал 'Вот есть у нас у PostgreSQL' - я имел в виду, что в индустрии есть, а не то что я к нему отношения имею. Прошу прощения за неудачность выражения мысли.
nin-jin
paulbuzakov Автор
GitHub Flow, так же как и другие виды бранч менеджмента могут решить, а могут и не решить задач конкретной команды. Стоит подбирать метод под свои задачи, а не под веление современности. Не люблю смотреть на вопрос однобоко - наверно это и была цель статьи.
Все равно начинать изучать вопрос стоит сначала, в дальнейшем я хочу рассмотреть GitHubFlow, как один из современных подходов, а так же опишу свои мысли на эту тему.
В любом случае спасибо за активность и отзыв о проделанной работе!!!
Благодарю!!!
nin-jin
GitHub Flow сто лет в обед.
paulbuzakov Автор
Благодарю за мнение, оно очень важно для меня.
nin-jin
Это не мнение, а восполнение пробела в ваших знаниях. Не стоит благодарности.
Krasnoarmeec
Это Вы о чём?
C++ ещё старше.
И? Какой Вы сделаете вывод? C++ не нужен? Устарел?
nin-jin
С++ устарел, когда появился D.