Перед нами стояла задача организовать переобучение моделей таким образом, чтобы можно было вести несколько процессов параллельно, а также оптимизировать трудозатраты и время на валидацию и поддержку ML-моделей.
Нетривиальность задачи была в том, что автоматизировать переобучение моделей нам нужно с соблюдением условий регуляторки. В связи с этим нам важно поддерживать особый workflow жизненного цикла СУМО — системы управления машинным обучением. Для этого нужно завести модель в реестр и отвалидировать её согласно рекомендациям ЦБ, т.е. пройти трудоёмкий и затратный по времени этап, далее проверить её на уязвимости, недокументированные возможности (это уже требования ИБ банка) и уже потом катить её в прод на Kubernetes. Причём сканирование и проверку на безопасность проходят код и веса модели, а документация модели и её воспроизводимость контролируется центром независимой валидации. Мы придумали, как сократить время переобучения моделей и сделать процесс валидации более быстрым и удобным.

Как мы поступали раньше, или В чём проблема?
Раньше при переобучении модели мы тратили в среднем до месяца, так как веса модели были частью docker-образа, а значит для workflow это был совершенно новый объект. При том, что код самой обвязки кода для скоринга на этих весах редко менялся (только в случаях, когда мы переходили на более продвинутый алгоритм). Каждый раз нужно было заново проходить все этапы, связанные с перевыводом модели согласно нашему ML System Design. На сбор свежей выборки, переобучение весов (на том же ML-алгоритме) уходила 1, максимум 2 недели, а в остальное время начиналось всё по кругу: перерегистрация в реестре, валидация, сканирование, тестирование, выкатка в прод.
Общепринятая практика для обычного банковского процесса — разместить всё, что нужно для запуска модели (код + веса), в Git-репозиторий и каким-нибудь инструментом типа Teamcity билдить сборку в прод. Но вот проблема: а как управлять потом этим кодом и зачем его сканировать каждый раз при переобучении, по сути, при изменении только весов? В связи с этим мы пришли к девопсам со следующим тезисом: если между весами модели и её кодом большая разница — веса должны меняться при переобучении модели, а сам код, как правило, оставаться неизменным.
Изящное решение в условиях наших ограничений
Мы решили изменить архитектуру: разделить веса и код модели для деплоя. Ниже расскажу, как мы это сделали и какие плюсы/минусы это дало. Но прежде, чем перейдём к сути наших ноу-хау, давайте рассмотрим, из каких этапов состоит процесс переобучения моделей. Важное уточнение, Git LFS позволяет это сделать почти из коробки, но, почему мы им не воспользовались, скажу далее.
На выходе хотим сократить time to market:
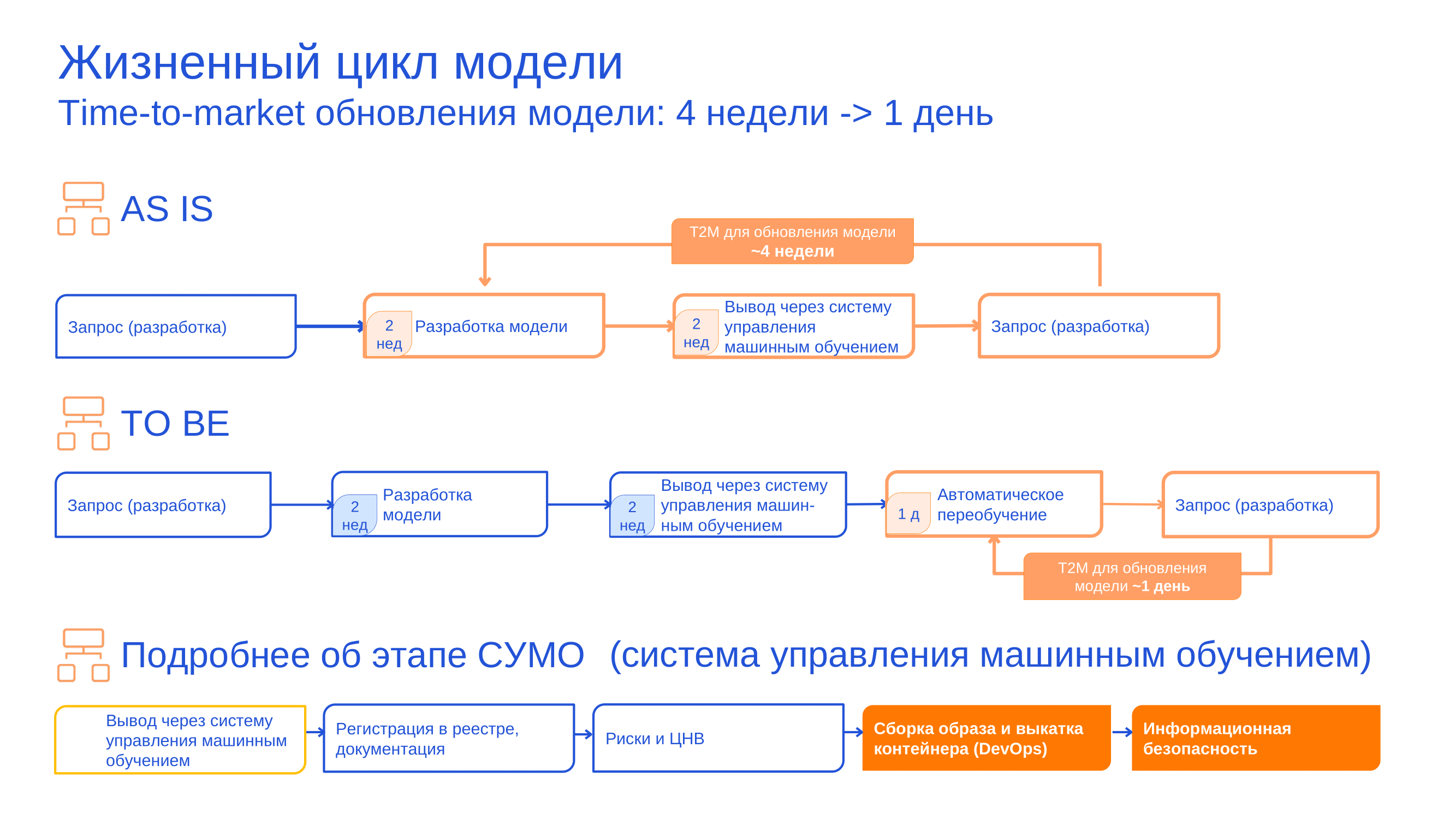
Путь переобучения
Автоматическое переобучение ML-моделей в нашем случае строится следующим образом.
Начинаем с расчёта единой витрины данных, которую собираем в Hadoop — программной платформе для сбора, хранения и обработки данных. По сути, для нас разработчиков моделей — это просто распределённая СУБД, которая обеспечивает надёжное хранение файлов больших размеров, почанково распределённых между узлами вычислительного кластера.
Много слышал, что Hadoop умер, но для нас он жив и идеально закрывает наши задачи по созданию очень большого числа признаков. На нём мы делаем витрины (feature store) по основным бизнес-направлениям, рассчитываем историю по ним, собираем самые значимые факторы. И по этим показателям обучаем модели на глубокой истории клиентского поведения.
Вторым шагом отбираем самые значимые факторы под конкретную модель. Поскольку речь идёт о банке, это будут агрегаты бюро кредитных историй, анкеты, транзакции, бонусы, депозиты и всё в том же духе. После чего занимаемся сбором целевых событий. Делаем регламентный расчёт определённой витрины таргетов, учитывая продуктовые изменения и изменения в бизнес-процессе на основе справочников с конфигами.
Допустим, задача — получить данные по откликам. Целевое событие — взятие потребительского кредита под воздействием какого-то из каналов активных коммуникаций (push, SMS, email и т.д.). Используем настроечную таблицу Postgres (Hadoop не очень любит update в табличках), откуда можно оперативно управлять параметрами применения и переобучения модели (например, какими-то фильтрами для определения целевого события и как их правильно сджоинить с фичами), присваиваем по определённой методике таргеты и фичи и получаем витрину, на которой можно регулярно переобучать одну или несколько моделей и параллельно их мониторить.
Контейнеризация

Все знакомы с концепцией контейнеризации, с докер-контейнером, знают, зачем он нужен. В нашем подходе процессы применения, переобучения и мониторинга (самой модели) представляют собой отдельные контейнеры как разные изолированные приложения, запускаемые как REST API в случае онлайн-применения и как ETL по регламенту в случае батча (запускаем контейнер только на время отработки батча без применения REST). Соответственно, контейнер переобучения как раз и переобучает модель, а другие контейнеры уже работают всегда со свежей версией весов модели.
Ключевая особенность автоматического переобучения модели
Мы разделили и сделали параллельным процесс сканирования и выкатки кода по CI/CD-процессу банка, благодаря архитектурному разграничению весов модели и самого кода как разных сущностей сборки. Пришлось так делать из-за ограничений в технологии контейнеризации и нашей инфраструктуры, так как каждое переобучение модели требовало пересборки образа, а это значит, надо было проходить все этапы сборки, сканирования на уязвимости, валидации и прочее, как было сказано ранее.
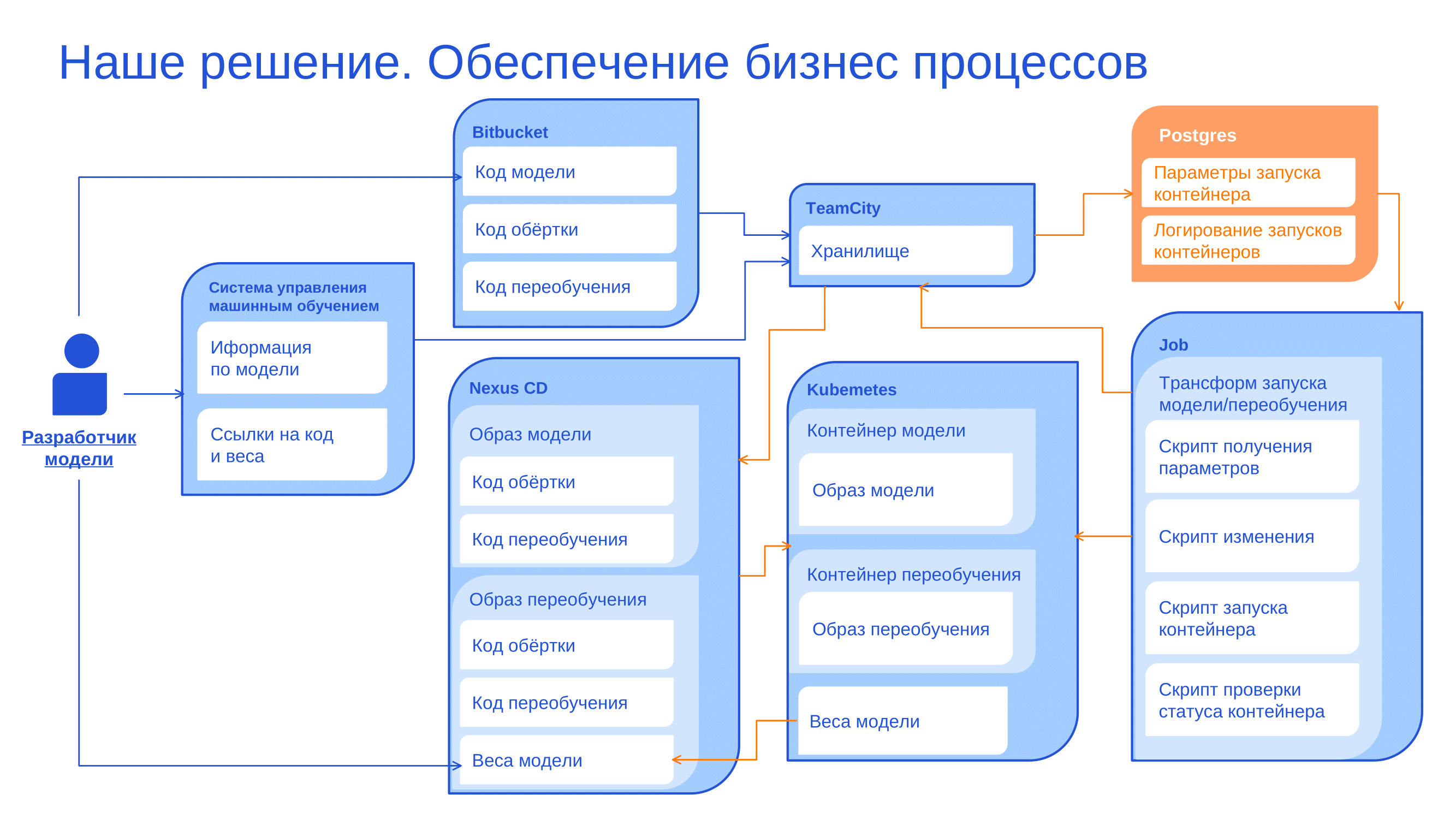
Сейчас, когда мы публикуем модель в Kubernetes, её веса монтируются в докер-контейнер, а не хранятся в самом образе. Исходная версия весов модели располагается в хранилище артефактов Nexus. Там же лежат все её следующие версии, полученные при переобучении, и переменные параметры, важные для изолированной среды. Данные и витрины собираются в Hadoop, как уже говорилось ранее. Самим процессом переобучения управляет настроечная таблица Postgres, где аккумулируются все логи, которые идут в Kibana. В настроечной таблице мы храним связку между самим контейнером и текущей версией весов, а также другие параметры запуска (количество ядер, RAM, входные параметры для модели и т.д.).
Верхнеуровнево процесс выглядит примерно так:
Резонно спросить: а зачем все эти веса хранить? Почему бы не переобучать модель сразу в контейнере при запуске её инференса? Тут надо вспомнить, что мы работаем в банке и у нас есть определённые нюансы. Например, бывают кейсы, когда новую версию модели нужно раскатывать на разные сегменты поэтапно.
По требованиям информационной безопасности мы не можем использовать Git LFS. А поскольку мы должны иметь возможность откатить модель до любой предыдущей версии (а ещё и протестить одну версию модели против другой на честном A/B-тесте), то изобрели свой вариант Large File Storage с функционалом специально под наш ML System Design.
Автоматическая версионность всего процесса
Итак, у нас есть исходная версия ML-модели, которая работала стабильно уже какое-то время, и тут ЦБ поднимает ставку рефинансирования.
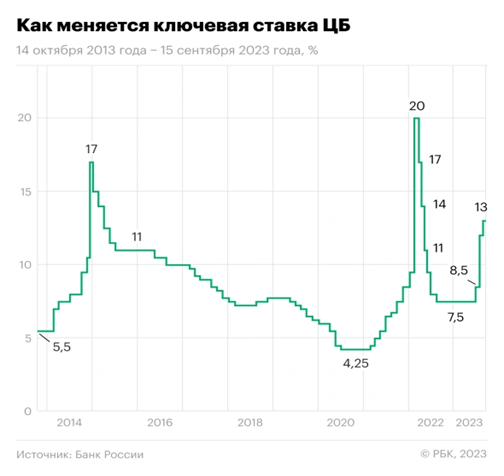
Такие значительные макроэкономические события явно влияют на входящий поток клиентов.
А значит, мы уже не можем гарантировать заявленные метрики нашей ML-модели, стало быть, пора запускать автоматический процесс. Стартует обучение модели конкурента на train-выборке, которое завершается сравнением с текущей моделью на test-выборке, отложенной во времени. Мы фильтруем по качеству (сейчас в базовом сценарии это превышение порога 0,05 Gini от последней модели), выбирая наилучшую модель, чтобы обучить, а затем откалибровать (привести среднее значение скора к актуальной вероятности целевого события) её на новых данных. Процесс калибровки очень значим, поскольку у нас есть проекты, для которых требуется вычислить матожидание нашей будущей доходности от решения на основе модели (например, матожидание доходности для маркетинговой оптимизации коммуникаций).
После прохождения всех процессов мы получаем финальную модель, параметры и веса которой записываются в Nexus. Работает система сквозной версионности, благодаря которой валидаторы получают отчёт о переобучении модели и другую документацию в автоматическом режиме.
Особенности переобучения, с точки зрения моделиста. Параметры
При автоматическом переобучении моделей имеет смысл выносить параметры работы самой модели вовне и вести их через настроечную таблицу (в нашем случае в Postgres), о которой было сказано ранее. Мы выносим вовне параметры настройки контейнера, среды и параметры запуска самой модели.

Что это за внешние параметры модели? Начнём с target_percent. Проблема в том, что, если доля проникновения продукта в клиентскую базу низкая, в обучающую выборку может не попасть ни одного целевого события (единички) при семплировании обучающей выборки.
Параметр target_percent как раз позволяет нам управлять минимальным процентом необходимых таргетов для обучения на уровне генерации запросов для выборки.
Другой параметр n_rows (размер выборки в абсолюте) помогает сделать выборку действительно репрезентативной: чем более популярный продукт, тем меньше примеров надо для обучения и наоборот.
Такой параметр как количество итераций подбора гиперпараметров управляет временем поиска качественной модели через количество итераций байесовской оптимизации.
Ещё один параметр calibration_params отображает количество данных, которые могут обеспечить корректную калибровку. Feature_step — количество итераций подбора оптимального количества переменных, на которых будет работать финальная модель. Нам обычно хватает 40–50 переменных для одной модели. Корректный отбор переменных влияет на скорость модели и эксплуатацию памяти.
Плюс мы применяем такой параметр как penalty — штраф за переобучение, который помогает подстраховаться от чрезмерного усложнения моделей.
Целью всего этого было по максимуму не вмешиваться в код, когда уже модель на проме, но что-то вовне меняется, например, растёт наша клиентская база.
Преимущества нашего подхода
Собственная разработка процесса переобучения с пересмотром архитектуры деплоя моделей позволила согласовать с информационной безопасностью и DevOps весь жизненный цикл моделей. На выходе получился собственный аналог Large File Storage под ML-модели, который работает на Nexus, обеспечивает нас возможностью запускать контейнер с кодом модели по расписанию ETL, в случае батчевого применения моделей, и мапить к ней любую версию весов на лету. Для онлайн-применения история плюс-минус аналогична, только API работает постоянно и на лету подтянуть новые веса не так просто.
Доработка привела к расширению применения open source и в части управления, применения и развития системы управления машинным обучением.
Главное завоевание — мы получили больше свободы и возможностей для развития. Так как проверенный код с точки зрения информационной безопасности создаёт доверенные веса, то мы прозрачно для ИБ разделили результаты переобучения в виде новых весов от кодовой обёртки для самой модели, одновременно разделив ответственность через внешние параметры, к которым разработчик модели получил доступ напрямую. А задача ИТ теперь управлять только входными и выходными векторами (витринами), а также связкой весов с образом, где хранится код обёртки.
Требования к инфраструктуре
Инфраструктура для наших целей должна была соответствовать определённым бизнес-требованиям. Помимо контроля за кодом модели и её весами, нужно было на тестовой среде воспроизвести валидно входные данные, чтобы модель прошла все тест-кейсы и образ перешёл на этап сканирования уязвимостей. Причём эти данные должны быть обезличены и дополнительно проверены соответствующим подразделением. Поэтому мы сначала гоняем модель на малом числе наблюдений в тестовом контуре, которые нам просто проверить и гарантировать их деперсонализацию, и уже после сканирования образа с помощью специальных скриптов от ИБ банка мы получаем разрешение работать с продовскими данными.
Все этапы, которые модель проходит до прода, должны быть понятными и прозрачными: состояния всех изменений должны быть записаны, чтобы было легко отследить, что и как функционировало в каждом из процессов.
Kubernetes и другие технологии
Если говорить о технической части, то прежде всего мы используем Jupyter — комбинацию JupyterHub и JupyterLab — в качестве IDE для экспериментов и разработки моделей. Но тут есть особенность, Jupyter не совсем хорош для оформления кода обвязки модели на прод, на этом этапе приходится переходить на VSCode или PyCharm (кому как удобнее). Многие инженеры поймут боль, когда к ним приходит Data Scientist со словами: «У меня есть юпитер-тетрадка, и она работает, вот её нужно запустить в проде».
Код, созданный в удобном для разработчика IDE, помещаем в Bitbucket, а оркестратором может быть любой фреймворк, например, Airflow. Сборка и развёртывание кода выполняются Teamcity. Артефакты хранятся в Nexus, включая image и веса конкретных моделей с учётом версионности. И чтобы всё это корректно запустить в работу на единой платформе, нужен Kubernetes.
Техническая часть решения: детали
Получив задачу по разработке или изменению моделей, разработчик открывает Jupyterhub, где выбирает специальный образ с версией Python (Scala или R) и набором необходимых библиотек, на котором будет работать. Дальше создаёт модель, тестирует её самостоятельно.
По итогам «контрольного запуска» получает первую версию её весов. Код обёртки модели для запуска модели с конкретными весами, как правило, унифицированный, его мы храним в Bitbucket (Git).
Следующим шагом в реестр вносит информацию о модели и указывает, где хранится код этой модели и какие веса, предварительно положенные в Nexus, здесь нужно использовать.
Ориентируясь на эти значения, workflow запускает определённый скрипт в Teamcity, который собирает образы применения, переобучения и мониторинга самих моделей. Эти значения параллельно пишутся в соответствующие настроечные таблицы Postgres. Вот как это выглядит в интерфейсе нашего реестра:
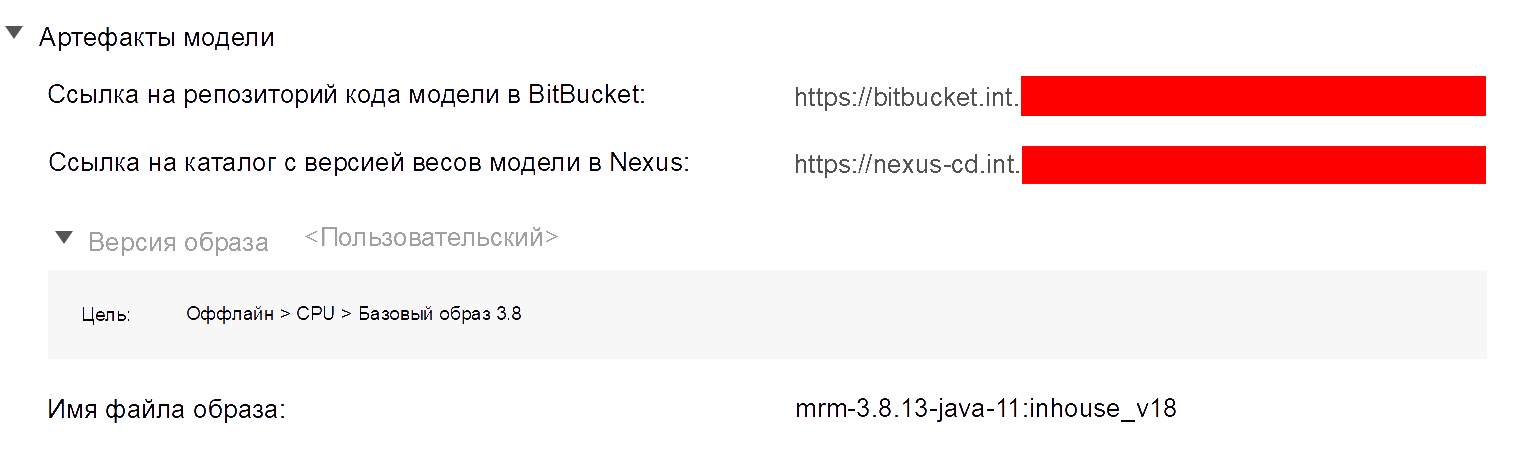
Тут я на всякий случай затёр адреса, работа в банке заставляет перестраховываться :)
Когда приходит момент переобучения, Teamcity забирает данные из настроечной таблицы Postgres, чтобы создать образ переобучения модели, использующий текущую версию весов (для сравнения с будущей версией), генерирует параметры для запуска этого контейнера, кладёт новые веса в Nexus и переобучает модель. А затем добавляет в Postgres новую связку между переобученной моделью (новой версией её весов) и образом с кодом обвязки. Очень сильно упрощённо логическая схема данных процесса выглядит так:
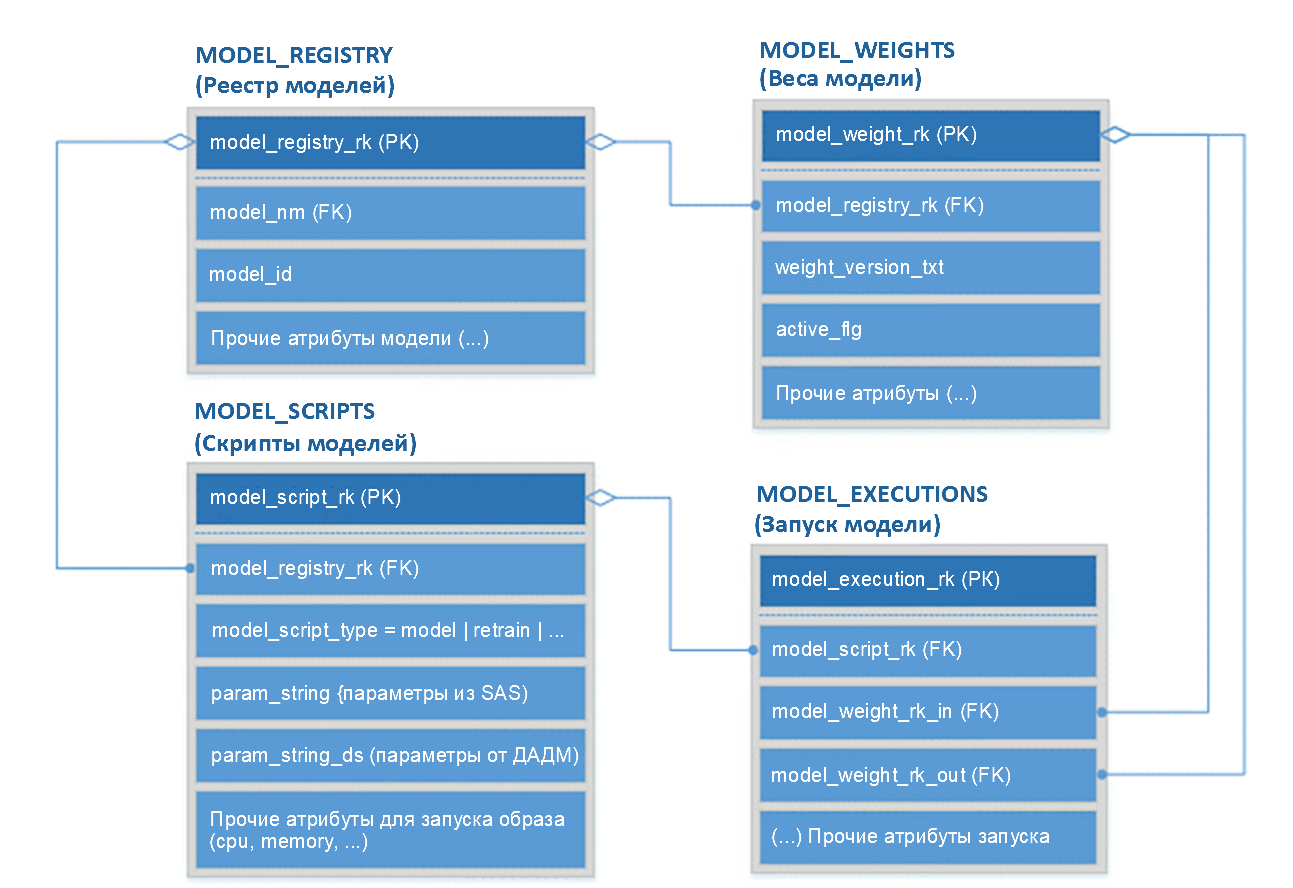
Ещё потребуется создать ETL job в нашем оркестраторе, который будет формировать необходимый пул данных или витрину. Когда данные сформированы, через Teamcity начинает работу скрипт, который запускает в Kubernetes контейнер переобучения, а после — контейнер применения.
Дождавшись окончания переобучения, специальный скрипт сверяет полученные веса с предыдущими. Если всё прошло удачно, то, как уже говорилось ранее, по workflow добавляются новые веса модели в Nexus, актуализируется ссылка на них в настроечной таблице в Postgres.
Эта итерация должна периодически повторяться. Оркестратор имеет расписание проверок: с определённой периодичностью сканируются новые данные, новые веса, но этот «круговорот контроля» не касается изменений кода модели.
Зачем нужны контейнеры?
Контейнеризация, которую мы используем, преследует несколько целей.
1. Изоляция
Поскольку в работе у дата-сайентистов одновременно переобучаются множество моделей, нужно изолировать их запуски. Чтобы никто не мешал друг другу: сеть, файловая система, процессы (словом, все составляющие) изолируются с помощью контейнеризации. Есть одно но: полностью исключить влияние на CPU и память нельзя, т.к. невозможно заранее просчитать, сколько ресурсов понадобится. Чтобы отрегулировать этот процесс, у нас продумана дополнительная логика в Jupyterhub и образах, которая позволяет ограничивать ресурсы для разработки.
2. Идентичная работа на разных средах
Единый блок инфраструктуры и кода экономит ресурсы: стоит один раз всё это разработать и зафиксировать, как внесённые изменения и при тестировании, и при запуске на проме (уже с реальными данными) будут совпадать. Критичный момент — с точки зрения проверки этих изменений.
3. Возможность быстрой автоматической проверки
Мы используем приложения, которые автоматически проверяют на предмет безопасности код и image — операционную систему, на базе которой запускается код. Супертяжеловесная проверка.
Если веса складывать внутрь образа и каждый раз создавать новый образ, то, принимая во внимание количество новых моделей, их доработок и изменений, было бы просто нереально всё проверять с необходимой периодичностью.
Минусы подхода с применением контейнеризации
Рассмотрим оборотную сторону.

Для использования этого подхода недостаточно просто контейнеров, нужно правильно распределять ресурсы и следить за их доступностью, иметь возможность быстро вносить исправления и изменения, поэтому необходим оркестратор, и как наиболее подходящий под все наши бизнес-требования был выбран Kubernetes. В итоге получается достаточно тяжеловесная и сложная инфраструктура, для поддержки которой необходимы значительные ресурсы.
Моделист работает с таким образом, который позволяет разрабатывать огромное количество разных вариантов моделей. Отсюда возникает второй минус: необходим шаблон OS, который включает в себя все возможные сочетания необходимых системных библиотек и модулей Python. И если с Python можно отчасти решить вопрос организацией набора разных виртуальных окружений, расположенных изначально вне образа, то с приложениями, установленными в ОС, так просто не справиться.
Размеры образов и последствия
Если говорить об образе, который уходит в продакшен, его размер варьируется от 2,5 до 35 Гб в зависимости от того, на чём будут выполняться расчёты (CPU или GPU) и требуемых приложений ОС и модулей Python.
Но есть ещё образ для разработки моделей в Jupyterhub, который может достигать размера в 50 Гб. Старая версия образа для создания GPU-модели насчитывала 70 Гб. Нам удалось уменьшить её до 23 Гб — но это тоже заметный вес.
Тут важно прокомментировать: у нас есть образ для разработки моделей, который включает в себя по максимуму библиотек, например, для отрисовки графиков. Но в прод мы идём с образом, где включены только пакеты, чтобы подключиться к базе, вычитать датафрейм и отскорить базу, никаких графиков нам на проде рисовать не надо.
В первых версиях наших образов для разработки хранился полный набор библиотек, который может потребоваться разработчику модели, и, соответственно, весили они очень много — до 70 Гб. Из-за огромных размеров проверка занимала много времени, к тому же такие «тяжёлые» образы неудобно таскать. Но сейчас мы согласовали новый подход. Мы перешли к концепции сбора образа для разработки моделей с минимальным набором «джентльменских» библиотек и возможностью докинуть новые материалы через virtual environment в Python, которые монтируются в каждый контейнер отдельно.
Kubernetes. Нюансы применения
У нас есть два разных вида моделей.
Онлайн-модели — доставляются в пром и работают для предоставления какого-то конкретного результата. Допустим, когда нужно обработать некую заявку. В них помещают нужный сет данных, и на выходе они дают конкретный результат. Это, по сути, деплойменты, объекты в Kubernetes, которые доступны извне. Причём онлайн-модели должны быть доступными постоянно.
Офлайн-модели — обрабатывают огромный пул данных и результат выдают в виде многочисленных данных. Это джобы, которые представляют собой запуск кода по расписанию.
Периодичность запусков критически важна для бизнеса, пропуски недопустимы.
Kubernetes позволяет поддерживать требуемый уровень надёжности и доступности.
Представим, что у нас деплоится три реплики моделей. Каждая реплика располагается на отдельном сервере. Даже если один или два сервера недоступны, модель продолжает функционировать для других наших автоматизированных систем. Kubernetes отслеживает доступность наших ресурсов и распределяет и деплойменты, и джобы на подходящих нодах, где есть ресурсы для выполнения задач без каких-либо проблем.
Кроме того, Кubernetes даёт возможность задать дополнительный уровень изоляции, который ограничивает используемые ресурсы в кластере (CPU и Memory), так как модель потенциально может взять в работу слишком много ресурсов и их может не хватить на исполнение других моделей.
По сути, Kubernetes позволяет нам создавать единую централизованную платформу с удобными инструментами для управления и оркестрации. Стоит нам один раз настроить или изменить мониторинг для любой новой модели, как он уже автоматически доступен на всех этапах жизненного цикла модели.
Для просмотра логов и мониторинга мы пользуемся такими системами, как Prometheus, Elasticsearch, Kibana. Мы настроили промежуточные части через системы, которые отправляют метрики и логи, но основная часть поддерживается и развивается другими командами банка.
Это позволяет нам сосредоточиться на надёжности самих моделей.
Разграничение весов и кода самой модели позволило ускорить процесс сканирования на уязвимости безопасности, поддерживать версионность и автоматически получать обновление весов модели. Оптимизация переобучения привела к сокращению времени и повышению эффективности работы.
В целом процесс управления переобучением и поддержание модели в надёжном работоспособном состоянии стал удобнее и стабильнее. Вот в чём именно:
- Стало больше open source в банке (не надо ничего импортозамещать).
- Есть согласованный с ИБ и DevOps жизненный цикл.
- Налажено взаимодействие моделистов и ИТ в цикле разработки и применения, разделена ответственность.
- Стало быстрее заводить в процесс новые версии Python, библиотек.
- Уменьшилась бюрократия в жизненном цикле модели.
- Есть возможность откатиться к любой версии модели и прозрачно все мониторить.
- Разработчик модели не зависит от ИТ в управлении применением модели.
- Есть очень большой задел на развитие.
Комментарии (4)

dimnsk
17.10.2023 17:06-2"Мы решили изменить архитектуру: разделить веса и код модели для деплоя. "

подскажите дальше стоит читать ?


IvanProvinciaTver
17.10.2023 17:06>В связи с этим мы пришли к девопсам со следующим тезисом: если между весами модели и её кодом большая разница — веса должны меняться при переобучении модели, а сам код, как правило, оставаться неизменным.
Апельсин большой, а кожура ещё больше.
Это вроде всем известно. Делить код и веса не проблема, это давно делается в том же питорче.>Почему бы не переобучать модель сразу в контейнере при запуске её инференса? Тут надо вспомнить, что мы работаем в банке и у нас есть определённые нюансы.
Нюансы в том, что вы как те учёные, которые открыли дверь. Обучение - это обучение, а инференс - это инференс. Это по умолчанию медленный и быстрый процесс. Если вы обучаете во время инференса, то вас можно поздравить и уволить.
>Главное завоевание — мы получили больше свободы и возможностей для развития.
Какими метриками вы оценили свободу и возможности для развития?
Уважаемый Денис.
Вы в своей статье рассказали много мишуры о преимуществах девопс подхода к разработке; обсервабилити; о типах моделей; о жутких безопасниках, которые суют свой нос даже в веса, а то вдруг там закладка, в цифрах?...
Хотелось бы узнать ответ на две категории вопросов:Сколько (хотя бы приблизительно) онлайн и офлайн моделей используется? Какая нагрузка на каждую из моделей в количестве запросов в секунду? (можно свёрнуто)
Вы считали экономическую эффективность всех этих приседаний? Вы уверены, что нейронка (ну раз вы говорите про веса) даёт значительно более качественные результаты чем обычная регрессия? Вы точно уверены, что всё это не разработка ради разработки?

podsyp Автор
17.10.2023 17:06Ответ
Иван, добрый день. Благодарю за внимание к нашей статье. Про мишуру - это ваше оценочное суждение, а вот вопросы в конце, действительно конструктивные и я с радостью на них отвечу.
К сожалению, работая в банке, я очень ограничен в дискуссиях о цифрах. Скажу так, в онлайне это только десятки на розницу (не считая каких-то сервисных api), в батче это под сотню в одном только cvm направлении. Нагрузку, в принципе, можно как-то из этого прикинуть и без разглашения мной nda. Взять с банки ру объемы кредитования, и по статистике цб прикинуть объем одобрений и выдач. Плюс накинуть какой-то ctr. Тут же важен порядок цифр скорей вам для понимания.
-
Нейронок у нас в процессах, как раз, не так много. Значительно больше бустингов. Я в статье писал, зачем бизнесово мы калибруем модели… так вот веса калибровки большой базы какой-нибудь изотонической регрессией над бустингом весят за 100 мб. Конечно, можно и лог регом откалиброваться, но в конкретных сегментах мат ожидание может поехать. А 100 мб уже накладно каждый раз в чистом гите перезаписывать на большом скоупе моделей, и это пример только одного из кейсов. По накладным расходам чистый бустинг и лог рег (на структурированных данных) примерно равны. Но есть класс задач, например, NLP или сегментация изображений, где лог реги не справятся, вы это знаете лучше меня) тут это больше рнд, которое мы ранее окупили бустингами и лог регами.
Эффекты мы регулярно замеряем и подверждаем на пилотах (в форматах: старая VS новая модели или модель VS бизнес руллы), это хорошие деньги и команду с подобными проектами они окупают многократно, к тому же наши эффекты от моделей периодически аудируют;) Добавлю, что с резким ростом ставки, данная доработка была как никогда актуальна, поэтому главная метрика это ТТМ выкатки новых весов и скорость реакции на волатильность.
Еще раз спасибо, ваши вопросы мне понравились.
EugeneRomanov
Очень познавательная статья