

Путешествуя по просторам Kaggle, я встретила обычный, на первый взгляд, датасет с результатами письменной части языкового экзамена IELTS. Так как недавно я сама активно готовилась к сдаче подобного экзамена, тема меня чрезвычайно заинтересовала и я решила попробовать создать модель, способную предсказывать оценку на основе текста эссе.
Итак, сначала определимся с постановкой задачи. Результаты экзамена оцениваются по шкале от 0.0 до 9.0, с шагом 0.5, поэтому я рассматривала задачу как многоклассовую классификацию.
initial_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1435 entries, 0 to 1434
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Task_Type 1435 non-null int64
1 Question 1435 non-null object
2 Essay 1435 non-null object
3 Examiner_Commen 62 non-null object
4 Task_Response 0 non-null float64
5 Coherence_Cohesion 0 non-null float64
6 Lexical_Resource 0 non-null float64
7 Range_Accuracy 0 non-null float64
8 Overall 1435 non-null float64
9 Unnamed: 9 0 non-null float64
dtypes: float64(6), int64(1), object(3)
memory usage: 112.2+ KBВ датасете присутствуют:
отметка о типе задания;
текст вопроса;
тест ответа, написанного кандидатом;
комментарий экзаменатора;
итоговая оценка.
К сожалению, оценки текста по каждому из 4 критериев (Task Response, Coherence/Cohesion, Lexical Resource и Grammatical Range and Accuracy) отсутствуют, поэтому мы не сможем имитировать процедуру оценки по всем критериям и выведение средней итогового результата, как это происходит в реальности, и не сможем “подсмотреть” в каком критерии мы ошибаемся больше.
Если говорить о распределении данных по типу задания, то оно практически равномерное. Однако, я дополнительно решила проверить к какому варианту экзамена относятся задания первого типа, потому что академический IELTS предполагает описание графика или рисунка, а общий – написание письма. Данные оказались однородными и все ответы относятся только к академической версии.

Настало время рассмотреть распределение целевой переменной.
plt.figure(figsize=(5,3))
sns.histplot(data=data['Overall']);
plt.show()
data.groupby('Overall').nunique()
Видно, что некоторые классы представлены слабо. Более того, классы 1.0 и 3.0 имеют 1
и 2 представителя соответственно. Очевидно, что данных для обучения недостаточно, поэтому исключим эти 2 класса из данных.
Чтобы как-то оценить отдельные аспекты ответа, я решила сгенерировать дополнительные признаки.
Во-первых, попробуем отразить лексическое разнообразие ответа. Для этого соберем списки слов разных уровней по классификации CEFR с сайта Кембриджского словаря и посчитаем количество слов каждого уровня, встретившихся в тексте ответа. Кроме того, я использовала список из 570 часто встречающихся академических слов, разработанный Школе лингвистики и прикладных языковых исследований Университета Виктории в Веллингтоне (Новая Зеландия).
Во-вторых, для отражения степени соответствия ответа вопросу, я вычислила cosine_similarity между эмбеддингом вопроса и суммарным эмбеддингом каждого абзаца, полученного суммой эмбеддингов их предложений. При этом эмбеддинги были получены с помощью предобученной модели Word2Vec (‘GoogleNews-vectors-negative300.bin.gz’) из Gensim. Соответственно, для каждого текста ответа получился ряд значений cosine_similarity, соответствующий количеству абзацев в тексте. Я вычислила максимальное, минимальное и среднее значения и добавила их к признакам.
И, наконец, третий источник дополнительных признаков – это библиотека readability. В ней содержится реализация метрик удобочитаемости, основанных на поверхностных характеристиках текста (линейные регрессии, основанные на количестве слов, слогов и предложений). Примерами характеристик, которые можно найти в этой библиотеке, могут служить среднее количество букв в слове, автоматический индекс удобочитаемости (ARI) или индекс удобочитаемости LIX. Все характеристики разбиты на несколько секций, я объединила их в один список, скомбинировав названия секции и признака.
['readability grades-Kincaid',
'readability grades-ARI',
'readability grades-Coleman-Liau',
'readability grades-FleschReadingEase',
'readability grades-GunningFogIndex',
'readability grades-LIX',
'readability grades-SMOGIndex',
'readability grades-RIX',
'readability grades-DaleChallIndex',
'sentence info-characters_per_word',
'sentence info-syll_per_word',
'sentence info-words_per_sentence',
'sentence info-sentences_per_paragraph',
'sentence info-type_token_ratio',
'sentence info-characters',
'sentence info-syllables',
'sentence info-words',
'sentence info-wordtypes',
'sentence info-sentences',
'sentence info-paragraphs',
'sentence info-long_words',
'sentence info-complex_words',
'sentence info-complex_words_dc',
'word usage-tobeverb',
'word usage-auxverb',
'word usage-conjunction',
'word usage-pronoun',
'word usage-preposition',
'word usage-nominalization',
'sentence beginnings-pronoun',
'sentence beginnings-interrogative',
'sentence beginnings-article',
'sentence beginnings-subordination',
'sentence beginnings-conjunction',
'sentence beginnings-preposition']После генерации признаков получилось суммарно 48 колонок данных; если отбросить сильно скоррелированные, то их останется 29.Теперь пришло время лемматизировать текстовые данные. Лемматизацию и токенизацию проведем с помощью spacy.
def lemmatize_column(data, column_name):
nlp = spacy.load("en_core_web_sm", disable=['parser', 'ner'])
new_columns = pd.Series(dtype='object')
new_item = ''
for item in tqdm(data[column_name]):
item = re.sub(r'(?<=\d)\.(?=\d)', ':', item)
for sentence in multiple_split(item, ['\n', '!', '?', '.']):
doc = nlp(sentence.lower())
new_item = ' '.join([new_item, ' '.join([token.lemma_ for token in doc])])
new_columns = pd.concat([new_columns, pd.Series(new_item)], ignore_index=True)
new_item = ''
return pd.DataFrame(new_columns, columns=['Lemmatized'])Далее разбиваем данные на train, test и validation в соотношении 70:15:15. В дальнейшем я использовала validation для подбора параметров, а test для сравнительного тестирования моделей. При построении моделей векторизация проводилась с помощью TfidfVectorizer. Оптимальные параметры векторизации я подбирала 1 раз для базовой модели и использовала их во всей работе.
questions_params = dict(norm = None, max_features = 800,
ngram_range=(1, 3), max_df=0.95, min_df=0.010)
essays_params = dict(norm = None, max_features = 450,
ngram_range=(1, 4), max_df=0.85, min_df=0.016)В качестве baseline была построена логистическая регрессия, обученная на данных представленных в датасете изначально, то есть колонках 'Essay', 'Question', 'Task_Type'. На валидационной выборке accuracy_score получился 0.395, а на тестовой – 0.381. Представленные ниже данные показывают, что показатели модели сильно различаются для разных классов, что в общем то неудивительно, учитывая распределение имеющихся данных по классам.
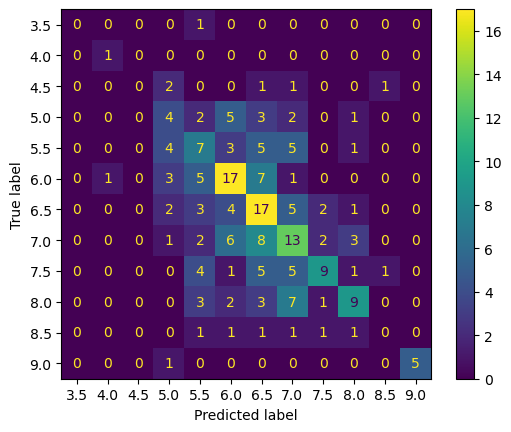
precision recall f1-score support
3.5 0.00 0.00 0.00 1
4.0 0.50 1.00 0.67 1
4.5 0.00 0.00 0.00 5
5.0 0.24 0.24 0.24 17
5.5 0.25 0.28 0.26 25
6.0 0.44 0.50 0.47 34
6.5 0.34 0.50 0.40 34
7.0 0.33 0.37 0.35 35
7.5 0.60 0.35 0.44 26
8.0 0.53 0.36 0.43 25
8.5 0.00 0.00 0.00 6
9.0 1.00 0.83 0.91 6
accuracy 0.38 215
macro avg 0.35 0.37 0.35 215
weighted avg 0.39 0.38 0.37 215Далее мне было интересно влияние дополнительно сгенерированных признаков. Для этой проверки я использовала всю ту же логистическую регрессию, обучив её на двух наборах признаков: все признаки и уменьшенный набор, без сильно скоррелированных признаков. Результаты получились даже хуже baseline. Но, возможно, логистическая регрессия просто не может разделить данные лучше, поэтому вернемся к этому вопросу позднее.
baseline |
все данные |
без скоррелированных данных |
|
validation_set accuracy_score |
0.395 |
0.395 |
0.391 |
test_set accuracy_score |
0.381 |
0.367 |
0.367 |
Теперь я взяла уменьшенный набор данных (без признаков с сильной корреляцией) и протестировала как на них ведут себя разные модели. При этом, при подборе оптимальных параметров для градиентного бустинга, случайного леса и SVC я использовала optuna и валидационной набор данных, а CatBoost взяла с параметрами по умолчанию. Результаты получились неравномерные: модели, показавшие наилучшие результаты, показали большую разницу в точности для тестовой и валидационной выборок.
baseline |
LogisticRegression |
Gradient Boosting |
Random Forest |
SVC |
CatBoost |
|
train time |
6.03s |
4.51s |
2min 12s |
2.75s |
2.23s |
36.2s |
accuracy_score |
||||||
validation_set |
0.395 |
0.391 |
0.423 |
0.433 |
0.395 |
0.405 |
test_set |
0.381 |
0.367 |
0.386 |
0.451 |
0.386 |
0.479 |
Более того, я заметила, что даже модели с одинаковыми значениями accuracy_score имеют разные матрицы ошибок.
")
")
Тогда я решила попробовать составить ансамбль всех этих пяти моделей, чтобы они компенсировали ошибки друг друга. Для этого я применила VotingClassifier с подбором оптимальных весов для моделей. В результате получилась модель со средней точностью, но меньшей разницей между результатами тестовой и валидационной выборок.
VotingClassifier |
|
train time |
2min 40s |
accuracy_score |
|
validation_set |
0.405 |
test_set |
0.414 |
Итак, я выбрала. Получились 2 лучших модели: RandomForestClassifier и VotingClassifier. Первая показала лучшую точность, а вторая более стабильный результат.
Теперь пришло время проверить их поведение на разных наборах данных и определить насколько удачные признаки мы сгенерировали. Сравнение я провела на 5 наборах данных:
изначально представленные в датасете (1);
все признаки, вместе со всеми сгенерированными (2);
все признаки, без сильно скоррелированных (на них проводился отбор наиболее эффективной модели ранее) (3);
начальные признаки + “простые” признаки (сгенерированные первыми 2 путями: количество слов разных уровней и “похожесть” вопроса на ответ) (4);
начальные признаки + “сложные” признаки (полученные с помощью readability) (5).
|
Начальные признаки (1) |
Все признаки (2) |
Без скоррелированных (3) |
Начальные + “простые” (4) |
Начальные + “сложные” (5) |
|
RandomForestClassifier |
|||||
validation_set |
0.381 |
0.386 |
0.433 |
0.386 |
0.391 |
test_set |
0.367 |
0.465 |
0.451 |
0.437 |
0.442 |
VotingClassifier |
|||||
validation_set |
0.409 |
0.428 |
0.405 |
0.414 |
0.391 |
test_set |
0.405 |
0.423 |
0.414 |
0.409 |
0.437 |
По полученным accuracy_score видно, что дополнительные признаки, практически во всех случаях не ухудшили качество моделей. Однако, нельзя сказать однозначно какие признаки оказались решающими для повышения эффективности. Кроме того, необходимо отметить, что если случайный лес показал наилучшую эффективность на данных под которые он подбирался, то VotingClassifier лучше отработал на полном датасете со всеми сгенерированными признаками. Вероятно, какая-то модель из ансамбля лучше использовала информацию из всех данных. В финал, таким образом, выходят RandomForest, обученный на нескоррелированных данных и VotingClassifier, обученный на всех данных.
Итак, настало время итогового теста. В связи с небольшим количеством данных, я решила провести тестирование лучших моделей с помощью “независимого” теста. Проверка заключалась в использовании сервиса Write & Improve от Cambridge. В нем предлагается написать эссе на предложенную тему и система его оценивает. Однако, здесь выставляется общая оценка за пару из задания первого и второго типов, поэтому в моем эксперименте я считала, что обе части имеют одинаковый балл. Моя тестовая пара текстов была оценена в 7.0 баллов. Когда я предложила эти тексты моим финалистам, то RandomForestClassifier оценил тестовые образцы в 6.0 и 7.0 баллов, а VotingClassifier – в 7.0 и 6.5. Я считаю, у обеих моделей вышла хорошая точность, хотя VotingClassifier мне нравится больше, так как он в целом дает более равномерные результаты.
Таким образом, в результате работы у меня получились 2 модели, которые без использования нейронных сетей способны прогнозировать итоговый балл с приемлемой точностью. Безусловно, необходимо учесть, что класс 7.0, использованный для теста, имел достаточное количество данных для обучения, но для сравнительно простых моделей этот результат все равно неожиданно высокий. Это подтверждает идею, что при достаточном количестве данных можно и сложные задачи успешно решать простыми моделями.
На этом все, а подробнее о курсе Machine Learning. Professional, обучаясь на котором я подготовила данный проект, вы можете узнать на сайте OTUS.
QtRoS
Не пробовали свести задачу к регрессии? Кажется, что здесь этот вариант намного более уместен, ибо предсказание оценки 1 при целевой оценке 9 это катастрофа, а можешь классификации как будто бы ничего об этом не знает. С другой стороны регрессия вероятно будет ошибаться ближе к таргету, а за большие ошибки можно явно штрафовать.