После того, как вы настроили KoboldAI и запустили SillyTavern, о чем описано в первой части, надобно и настроить их!
Дисклеймер: Большая часть статьи будет пересказом документации SillyTavern и кучи маленьких и разрозненных англоязычных источников с моими дополнениями, так что формально это можно назвать сбором информации в одном месте на русском языке, нежели полностью самостоятельным творением.
Также я не буду расписывать об абсолютно всех функциях. Некоторые очевидны, такие как фон задника, а некоторые вы с вероятность 99% не будете трогать, даже если будете знать, что они делают. Только более важные, для всего остального есть документация.

Настройка вашего персонажа
Вы можете добавить контекста в ваш ролеплей, если расскажете ИИ, за кого вы играете. Настройки персоны производятся во вкладке со смайликом:

Нажимаете плюсик, и расписывайте все, что считаете нужным для персонажа:
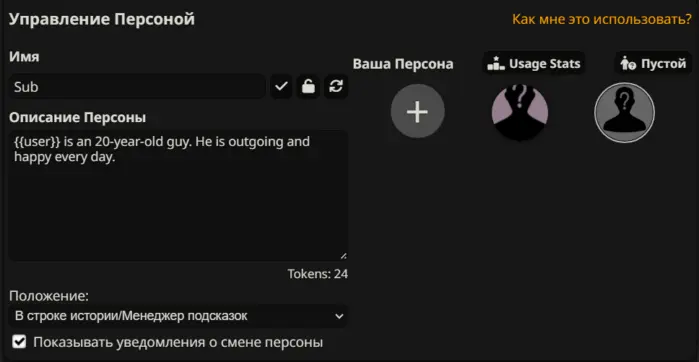
Синтаксис вы видите на картинке. Если что, ваш персонаж — {{user}}, а персонаж, с которым вы играете — {{char}}. Положение лучше оставить по умолчанию. Синтаксис вы видите на картинке.
Настройки ответа ИИ
Эти настройки напрямую отвечают за ваш опыт взаимодействия с персонажем, так что их я разберу максимально подробно.
Давайте по порядку:
Длина ответа — максимальная длина сообщения от ИИ. Это не количество знаков, а токенов. Токены — это слова, или даже части слов, такие как суффиксы, окончания и т. д. Не обязательно ИИ будет генерировать ровно то количество, которые вы укажете, но больше заданного количества — нет. Чем больше значение, тем медленней генерация ответа.
Размер контекста — это количество токенов, которые будет захватывать ИИ в свой обработчик, чтобы составить вам ответ. В него входит и описания мира из лорбука (будет позже), и описание вашего и игрового персонажа, а все оставшееся количество — прошлые сообщения, которые уже есть в текущем чате. Чем больше размер контекста — тем медленнее генерация ответа. В большинстве случаев модели гарантированно поддерживают длину контекста до 2048 токенов, но можно и выйти за пределы в большую сторону. Коротко: чем больше модель, тем больше контекста она сможет обрабатывать.
Неограниченное количество токенов - лично я не нашел моделей, которые поддерживают данный режим. Вероятно, плохо искал, ибо моя машина такие большие модели просто не потянет.
Температура — значение, которое отвечает за «креативность« модели. Меньшее значение дает более спокойные и более предсказуемые ответы, а большее значение дает более креативные, а в некоторых случаях даже немного »безумные». Среднее значение для комфортной игры, которое я для себя вывел — 0.65.
Rep. Pen. — Повторяемость слов. Чем больше это значение, тем больше ИИ контролирует самоповторы. Если он зациклилсяЕсли он зациклилсяЕсли он зациклился, то стоит увеличить это значение. Обычно достаточно 1.0-1.15
Диапазон Rep. Pen. — значение токенов, которые ИИ будет проверять на самоповторы.
Top P — Вероятности выбора ИИ следующего слова в предложении. Если залезть в строение ИИ модели, то можно увидеть, что это грубо говоря очень большая паутина из нейронов и весов. У каждого нейрона есть ответвления, и у каждого из них есть вес: чем он больше, тем он более «связан» с родительским нейроном. При уменьшении этого значения вы ранжируете выбор следующего слова. Чем меньше значение Top P — тем более вероятным с точки зрения логики ИИ оно выберет следующее слово. Значение 1 отключает эффект.
Top a — значение, похожее на Top P, но тут следующие слова выбирает рандом, и выставив ограничение, по сути, веса, ИИ выбирает более вероятное следующее слово. Чем больше значение, тем логичнее будет ответ. Значение 0 отключает эффект.
Top K — Из скольких слов выбирать. Это значение определяет, сколько весов взять для выборки. Например, выставив значение 10, при генерации ответа, ИИ будет даваться 10 слов, из которых посредством Top P будет выбираться наиболее вероятное. Значение 0 отключает эффект.
Типичная выборка — значение, которое дает ИИ рандомные слова с равными весами, и он рандомно выбирает, какое подставить. Чем меньше значение, тем более разнообразные слова он будет выбирать, что скажется на «читабельности» всего текста. Значение 1 отключает эффект.
Бесхвостовая выборка — отметает значения с наименьшими весами. Значение 1 отключает эффект.
Rep. Pen. Склон — усилитель значения Rep. Pen. Попробуйте поиграть с этими значениями в связке друг с другом. Значение 0 отключает эффект
Режим одной строки — в большинстве случаев генерирует одно-два предложения. Ускоряет генерацию, но уменьшает длину ответа.
Заблокировать EOS-токен — End-Of-Stream токеном ИИ показывает, что он закончил говорить, и останавливает генерацию. При включении этого параметра ИИ будет использовать все токены, которые ему доступны (Длина ответа). На практике, я не заметил разницы с включенным и отключенным EOS.
Также интерфейс позволяет выбрать предустановки. Вы можете выбрать из предложенных или создать свою:

Не вижу смысла обозревать каждую по отдельности, лучше вам поэкспериментировать с ними и выбрать ту, которая вам по душе. Обычно я использовал Godlike или Mayday, пока не узнал о следующей фишке KoboldAI:
Mirostat
Mirostat — настройки ответа ИИ нового поколения. Это новый алгоритм обработки генерации ответов, и он может действительно улучшить качество ответов ИИ, но несколько замедлит генерацию. Если хотите разобраться, как эта технология работает, тут статья от разработчиков Mirostat. Его настройка:
Mirostat Mode — значение 0 отключает его, 1 — Mirostat 1.0, 2 — Mirostat 2.0. Сильных отличий между первой и второй версиями нет.
Mirostat Tau — «энтропия», контролирует значение Top K. Mirostat делает это динамически.
Mirostat Eta — Контролирует возвращение Top K к первоначальному значению, то есть чем больше значение, тем он консервативнее.
Параметры персонажа
Теперь, когда вы примерно понимаете, как работает KoboldAI, можно и разобраться в строении персонажа:

Персонаж — тоже набор токенов, и ИИ, анализируя их, выстраивает диалог с вами
Описание персонажа — обычно авторы помещают сюда все характеристики: внешность, черты характера, примеры диалогов и т. д. что я считаю не очень правильным, так как на картинке слева есть отдельные поля для нужных параметров.
Первое сообщение - очевидно, приветственное сообщение, которое вы видите при выборе персонажа.
Личная сводка - тоже самое что и описание персоны во вкладке со смайликом.
Сценарий - ИИ будет стараться придерживаться вокруг него, если вы не отыграете как-то совершенно в другую сторону. Небольшое отступление: ИИ практически никогда не будет вам перечить, и будет следовать строго тем поворотам, которые вы отыграете.
Разговорчивость - процент его сообщений в групповых чатах, о них немного позже.
Примеры диалога - правила стиля общения и действий персонажа.
Promt Overrides — переопределения для персонажа. Вы можете написать «правила«, которым будет следовать ИИ в своем ответе. Главные инструкции отвечают за обязательное следование этим »правилам», JailBreak — то, что ни в коем случае не должен делать или говорить персонаж.
Персонаж и токены
Групповые чаты
Групповые чаты — интересная, но по моему мнению, не очень работающая фишка. Вы можете общаться сразу с несколькими персонажами!

Необходимо выбрать персонажа, и нажать на кнопку в его описании, которая подсвечена на картинке. Выбираете название чата, и персонажей, которые будут в него входить:
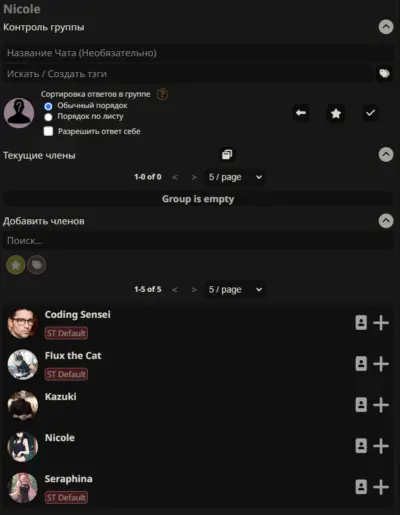
Как только выберете персонажей, нажимаете на галочку, и развлекаетесь.
По моему мнению, это функция не очень хорошо работает на слабых моделях даже с персонажами, созданными специально для групповых чатов. Они все равно говорят все о своем и не двигают сюжет. С мощными моделями по типу GPT-4 я не пробовал. Напишите в комментариях, если у вас получилось хорошо отыграть группу персонажей!
Формат сообщений
Собственно, с основными понятиями мы закончили, теперь наконец можно общаться и получать удовольствие:)
Некоторые специальные символы для общения:
Прямая речь
*Действие*
«Цитата»
[Инструкция для ИИ]
Но спустя некоторое время я понял, что эти символы особо и не работают, тем более инструкции для ИИ. Если вы будете писать и без спецсимволов, то ИИ вас поймет и ответит также. Так что считайте, что они для красоты.
Расширенное форматирование
Эти настройки отвечает за формат передачи контекста ИИ модели, они скрываются во вкладке "А":

Шаблон контекста позволяет выбрать формат передачи всего контекста ИИ при каждой генерации. В случае KoboldAI хватает и Default настроек, но можете поэкспериментировать, я не нашел сильных отличий генерации между режимами.
ЛОР
Для расширения контекста и раскрытия персонажа, существуют Лорбуки. Они описывают окружающий мир. Лорбук подключаемый и также состоит из токенов.
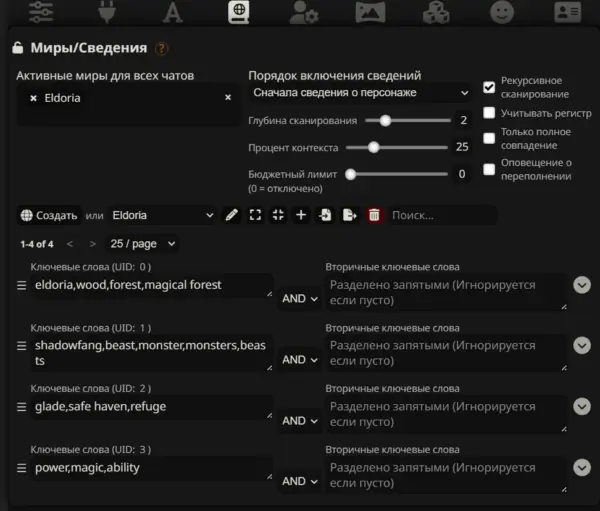
Как только ИИ видит определенные ключевые слова в вашем сообщении, он сопоставляет их со значениями в Лорбуке и может добавить в свой ответ контекст из него.
Глубина сканирования — сколько ваших последних сообщений ИИ будет просматривать на ключевые слова
Процент контекста — вероятность того, что ключевое слово стриггерит обращение к Лорбуку
Бюджетный лимит — Сколько токенов в генерации отведено лору. По умолчанию 0 — лимит отключен.
SillyTavern Extras
Extras позволяют вам разнообразить и расширить SillyTavern, например заставить персонажей говорить с помощью TTS или генерировать изображения с помощью Stable Diffusion
Для установки вам требуется дополнительно установить Miniconda
Как только установите:
Запускаете Anaconda Prompt (miniconda3) и выполняете команды
conda create -n extras
conda activate extras
conda install python=3.11 git
git clone https://github.com/SillyTavern/SillyTavern-extras
cd SillyTavern-extras
pip install -r requirements-complete.txt
Запускаете из папки, где лежат Extras, и пишете python server. py --enable-modules=caption, summarize, classify, sd
В этой строке вы запускаете сервисы caption, summarize, classify, sd
Stable Diffusion работает… странно. Вы вписываете промты сами в SD Promt Templates и SD генерирует и отправляет картинку в чат. И это так в любом режиме.
TTS уже более интересный, но он читает оригинальный английский текст, а не русский. Как это исправить, я не нашел.
Character Expressions показывает эмоции персонажа, если вы загрузите его картинки. Можете протестировать со стандартным персонажем Seraphina.
Перевод я освещал в первой части.
Заключение
Искусственному интеллекту далеко от идеала, и он не может заменить реального общения, но он активно стремится к нему. Думаю, это все, что вы должны знать для комфортного отыгрыша. Считайте, что это обзорная статья, а не полное пособие. Для «полного погружения» есть документация и десятки веток на Reddit.
Спасибо за внимание!