В первом материале из этой серии была объяснена работа механизма Copy‑on‑Write (CoW, копирование при записи). Там были упомянуты некоторые ситуации, в которых при выполнении кода осуществляется копирование данных. В этой статье речь пойдёт об оптимизации, направленной на то, чтобы копирование не ухудшило бы средних показателей скорости работы кода.

Мы используем подход, применяемый внутри pandas для того, чтобы избежать копирования всего объекта DataFrame в тех случаях, когда это не нужно. Этот подход позволяет повысить производительность системы.
Избавление от защитного копирования
Начнём с улучшения, которое вносит наибольший вклад в повышение производительности. Многие методы pandas применяют защитное копирование для того чтобы избежать побочных эффектов и защитить объекты от последствий непосредственных изменений, выполняемых позже.
df = pd.DataFrame({"a": [1, 2, 3], "b": [4, 5, 6]})
df2 = df.reset_index()
df2.iloc[0, 0] = 100Тут нет нужды копировать данные в reset_index, но возврат среза может привести к появлению побочного эффекта при модификации результата. Такая модификация может привести и к модификации df. В результате в reset_index выполняется защитное копирование.
При включении CoW защитное копирование не применяется во множестве методов, в которых оно применялось ранее. Полный их список можно найти здесь.
Кроме того, выбор подмножества столбцов DataFrame теперь всегда будет возвращать срез, а не копию данных, как это было раньше.
Теперь, скомбинировав некоторые из этих методов, разберёмся с тем, что это означает для производительности:
import pandas as pd
import numpy as np
N = 2_000_000
int_df = pd.DataFrame(
np.random.randint(1, 100, (N, 10)),
columns=[f"col_{i}" for i in range(10)],
)
float_df = pd.DataFrame(
np.random.random((N, 10)),
columns=[f"col_{i}" for i in range(10, 20)],
)
str_df = pd.DataFrame(
"a",
index=range(N),
columns=[f"col_{i}" for i in range(20, 30)],
)
df = pd.concat([int_df, float_df, str_df], axis=1)Тут создаётся объект DataFrame с 30 столбцами, с данными трёх разных типов и с 2 миллионами строк. Выполним следующую цепочку методов на этом датафрейме:
%%timeit
(
df.rename(columns={"col_1": "new_index"})
.assign(sum_val=df["col_1"] + df["col_2"])
.drop(columns=["col_10", "col_20"])
.astype({"col_5": "int32"})
.reset_index()
.set_index("new_index")
)Если механизм CoW не включён — все эти методы выполняют защитное копирование данных.
Замеры производительности без CoW:
2.45 s ± 293 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)Замеры производительности при включении CoW:
13.7 ms ± 286 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)Тут видно улучшение производительности примерно в 200 раз. Я выбрал этот пример специально для того чтобы показать потенциальные преимущества использования CoW. Не каждый метод получит такую же прибавку к скорости выполнения при применении CoW.
Оптимизация копирования, вызванного непосредственным изменением данных
В предыдущем разделе продемонстрировано множество методов, которые больше не нуждаются в защитном копировании данных. CoW гарантирует невозможность одновременного изменения двух объектов. Это означает, что нам нужно инициировать копирование в том случае, если два объекта DataFrame ссылаются на одни и те же данные. Посмотрим на приёмы, позволяющие сделать такое копирование как можно более эффективным.
В предыдущем материале было показано, что следующая операция может вызвать копирование данных:
df.iloc[0, 0] = 100Копирование инициируется в том случае, если на данные, лежащие в основе датафрейма df, ссылается другой объект DataFrame. Мы предполагаем, что датафрейм имеет n столбцов, в которых содержатся целые числа, то есть — в его основе лежит единственный объект Block.
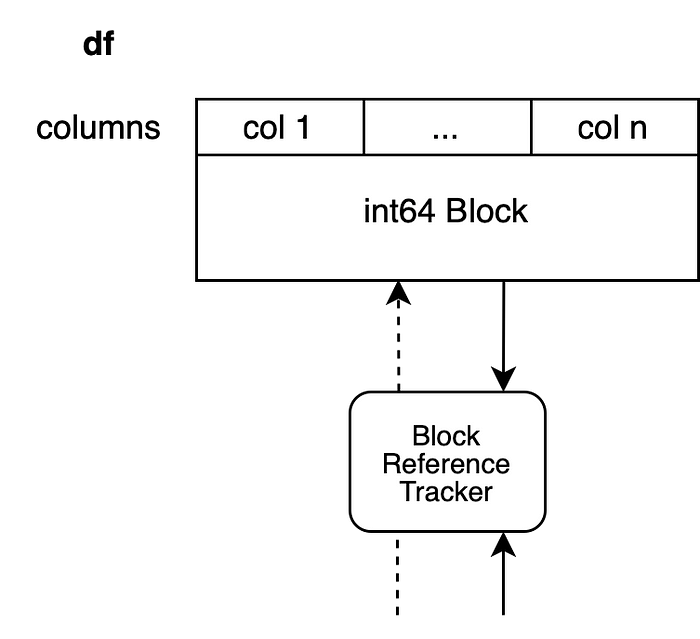
Объект для наблюдения за ссылками хранит ссылку и на другой объект Block, поэтому мы не можем модифицировать DataFrame непосредственно, не модифицируя другой объект.
Тут можно было бы применить бесхитростный подход с копированием всего объекта Block и на этом остановиться.
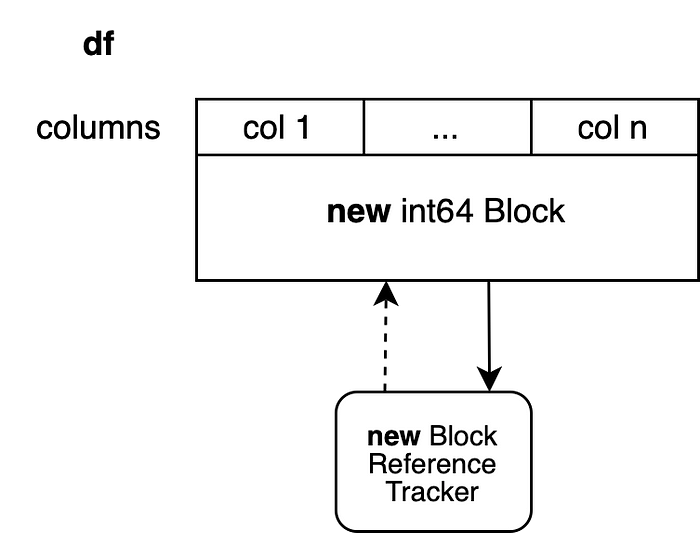
Это привело бы к созданию нового объекта для наблюдения за ссылками и к созданию нового объекта Block, в основе которого лежал бы новый массив NumPy. Этот объект Block больше ни на что не ссылается, поэтому в ходе выполнения другой операции можно было бы снова модифицировать его непосредственно. Применение этого подхода приводит к копированию n-1 столбцов, в копировании которых нет особой необходимости. Для того чтобы избежать подобного, мы используем подход, называемый разделением объекта Block.
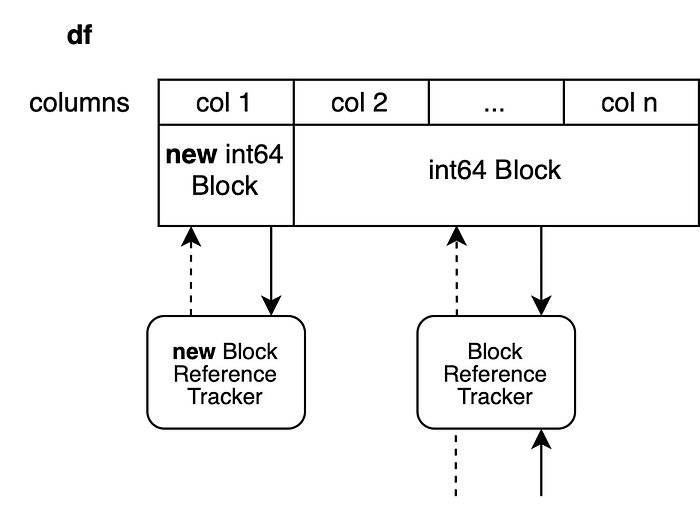
Внутри системы осуществляется копирование лишь первого столбца. Все другие столбцы воспринимаются как срезы предыдущего массива. Новый объект Block не связан с другими столбцами. А на старый объект Block ссылаются и другие объекты, так как это — лишь срез уже существующих значений.
У этого приёма есть один недостаток. В исходном массиве имеется n столбцов. Мы создали срез от столбца 2 до столбца n, но весь исходный массив при этом остался таким же, каким был. Мы, кроме того, добавили новый массив с одним столбцом, хранящий данные первого столбца исходного массива. Это приведёт к тому, что будет занято немного больше памяти, чем это реально нужно.
Такую систему работы с данными можно напрямую перенести на объекты DataFrame, хранящие данных разных типов. Все объекты Block, которые не были модифицированы, возвращаются в исходном виде, а разделению подвергаются лишь блоки, подвергшиеся непосредственному изменению.
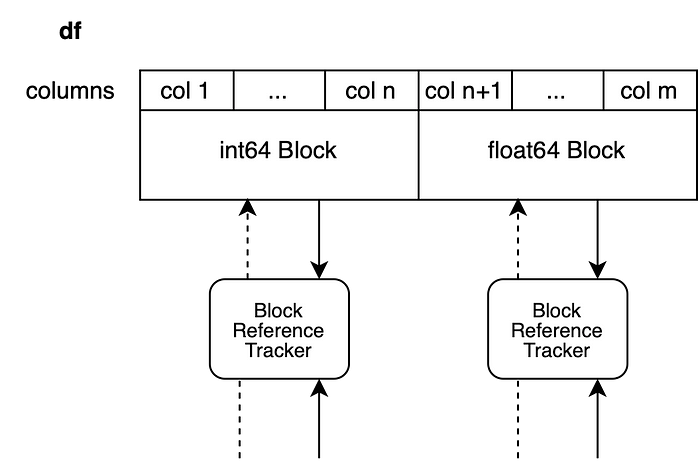
Теперь мы записываем новое значение в столбец n+1 объекта Block с типом данных float64 чтобы создать срез столбцов от n+1 до m. Новый блок будет содержать лишь данные столбца n+1.
df.iloc[0, n+1] = 100.5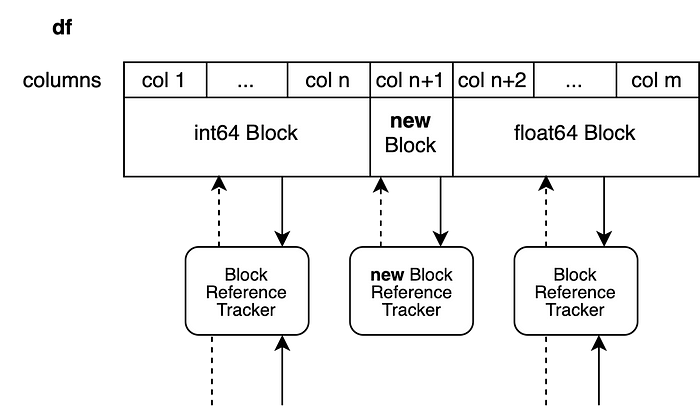
Методы, которые могут работать с данными непосредственно
Операции индексирования, о которых мы говорили, обычно не создают новые объекты. Они модифицируют существующие объекты непосредственно, в том числе — данные этих объектов. Другая группа методов pandas совершенно не притрагивается к данным объекта DataFrame. Один из ярких примеров — метод rename. Этот метод лишь меняет метки объектов. Подобные методы могут использовать механизм ленивого копирования, упомянутый выше.
Есть и ещё одна, третья группа методов, которые, на самом деле, могут выполняться непосредственно на объектах. Среди них — replace и fillna. Их использование всегда приводит к вызову копирования.
df2 = df.replace(...)Непосредственная модификация данных без вызова копирования приведёт к модификации df и df2, что нарушает правила CoW. Это — одна из причин того, что мы рассматриваем возможность сохранения параметра inplace для подобных методов.
df.replace(..., inplace=True)Такой подход позволит избавиться от данной проблемы. Но это — всё ещё открытое предложение, реализация которого может пойти в другом направлении. Таким образом, это имеет отношение только к столбцам, которые подверглись изменениям. Все остальные столбцы, в любом случае, возвращаются в виде среза. Это значит, что если значение обнаруживается лишь в одном столбце — копируется только этот единственный столбец.
Итоги
Мы исследовали то, как CoW меняет поведение внутренних механизмов pandas, и то, как это приведёт к улучшениям в обычном коде. Многие методы при применении CoW станут работать быстрее, но при этом мы столкнулись с замедлением нескольких методов, связанных с индексированием. Ранее соответствующие операции всегда выполнялись непосредственно на объектах, что могло привести к появлению побочных эффектов. С появлением CoW эти побочные эффекты исчезли. Модификация одного объекта DataFrame больше никогда не приведёт к воздействию на другой объект.
В следующем материале из этого цикла я расскажу о том, как вы можете адаптировать свой код в расчёте на особенности CoW. Там мы, кроме того, поговорим о том, каких паттернов стоит избегать тем, кто будет пользоваться pandas в будущем.
О, а приходите к нам работать? ???? ????
Мы в wunderfund.io занимаемся высокочастотной алготорговлей с 2014 года. Высокочастотная торговля — это непрерывное соревнование лучших программистов и математиков всего мира. Присоединившись к нам, вы станете частью этой увлекательной схватки.
Мы предлагаем интересные и сложные задачи по анализу данных и low latency разработке для увлеченных исследователей и программистов. Гибкий график и никакой бюрократии, решения быстро принимаются и воплощаются в жизнь.
Сейчас мы ищем плюсовиков, питонистов, дата-инженеров и мл-рисерчеров.
VladBalalaykin
Если выбран Python, то скорость не важна.
Если скорость важна, берите Rust с Polar и не корячьтесь с технологиями, которые по своей природе не подходят для таких требований