
Вчера (8.11.2023) мы выпустили релиз фреймворка компьютерного зрения Savant с номером 0.2.6. Этот выпуск включает в себя множество исправлений ошибок, семь новых демонстрационных пайплайнов и ряд других улучшений, включая документацию, улучшения производительности и поддержку Nvidia Jetson Orin Nano.
Savant пересек отметку в 300 звезд на GitHub, и Discord наконец-то стал более активен, что нас сильно радует. Работа над релизом заняла 1.5 месяца. В следующих разделах мы подробно рассмотрим основные части релиза.
Что такое Savant
Savant - это высокоуровневый фреймворк с открытым кодом для построения пайплайнов компьютерного зрения и видеоаналитики на базе Nvidia DeepStream SDK. Фреймворк фокусируется на готовности для продуктива и одинаковой работе на широком спектре оборудования Nvidia. Возможно, вы захотите узнать подробнее о преимуществах фреймворка - можно прочитать статью на английском.
Если коротко, Savant быстрее PyTorch и OpenCV CUDA и проще DeepStream. Кроме того, вы можете использовать в Savant PyTorch, OpenCV CUDA, CuPy, если вас устраивает пониженная производительность, но хочется переносить готовые пайплайны.
Чем примечателен текущий релиз
Данный релиз фокусируется на двух основных блоках задач:
исправление ошибок, обнаруженных в 0.2.5;
улучшения, направленные на работу с видео-данными на GPU без поддержки NVENC.
Релиз 0.2.5 пошел в продуктив у ряда пользователей, в результате нам навалили багов (чему мы сильно рады), которые на наших сэмплах ранее не проявлялись - в итоге мы исправили 22 бага разной степени серьезности: начиная от защищающих от стрельбы в ноги и заканчивая "ничего не работает".
Что такое NVENC
NVENC - аппаратный кодировщик видео, выделенный блок на dGPU Nvidia и их устройствах Nvidia Jetson. Это самый эффективный способ кодировать видео - фреймы кодируются прямо из памяти GPU без переноса их в память CPU и без участия процессора. К сожалению, Nvidia решила выпускать ряд устройств с обрезанным NVENC, а часть устройств вообще без NVENC, например:
GeForce, NVENC есть, но максимум 5 одновременно кодируемых потоков, а раньше было вообще 3 (видимо, по просьбе геймеров подняли);
V100/A100/H100/A30 - вообще нет NVENC;
Jetson Orin Nano - вообще нет NVENC (на предыдущем Nano был).
Вопрос, почему такая история с NVENC сложный, возможно, связано с энергетическим бюджетом чипа или сегментированием рынков. В общем, есть устройства без NVENC.
Как мы раньше жили
Экосистема Savant считает, что для целей компьютерного зрения NVDEC и NVENC бесплатны. Под "бесплатны" понимается то, что они работают всегда быстрее чем работает инференс, поэтому можно без замороча декодировать видео в начале пайплайна и кодировать видео в конце и это никак на производительность не влияет.
Поскольку V100/A100/H100 для инференса видео и компьютерного зрения редко используется, мы фокусировались на T4/A10 и серии Quadro (RTX N000, RTX AN000), а так же устройствах Nvidia Jetson Xavier (NX, AGX).
Однако, к пользователям приходят A30 и Jetson Orin Nano, без NVENC. Nvidia говорит - кодируйте на CPU, если надо. Однако, проблема в том, что передача сырых фреймов между памятью GPU и CPU - это реальный joy killer, поскольку производительность падает очень сильно.
Например, представим себе FullHD RGBA фрейм с цветом 8 бит: 1920 x 1280 x 4 = 9.37 MB. Это один фрейм, если мы хотим обрабатывать 1000 FPS, что вполне себе реально на современных GPU для инференса, то мы приходим к 9.37 GB/sec передачу по PCI-E в одну сторону. А если еще обратно надо передать, то это еще 9.37 GB/sec. В общем, не каждая PCI-E уже протянет. При этом, внимание, ResNet-50 (int8) на Nvidia A10 может работать на скорости около 5000 FPS. В общем, без NVDEC/NVENC никак.
А теперь, с приходом A30, Orin Nano, или V100/A100/H100 обратный перенос фреймов из видеопамяти в CPU для кодирования (если требуется) стал очень дорогим.
А зачем кодировать вывод в системах компьютерного зрения?
Кодировать нужно, потому что люди хотят видеть что пайплайн производит на выходе, рисовать всякие аналитические дашборды и делать аугментацию видео. Впрочем, часто и не надо кодировать.
Для тех случаев, когда кодировать не надо, мы реализовали в этом релизе функцию Video Pass-Through. Теперь Savant пропускает исходное кодированное видео и аугментирует его метаданными. Само собой, что в случае такой настройки ничего нарисовать на кадре нельзя.
Если же хочется все же кодировать на устройствах без NVENC, у нас есть программный энкодер, стандартный для экосистемы GStreamer. С ним можно рисовать на фреймах и видеть результат. Для целей разработки подойдет, для продуктива - сомнительное решение. Лучше вынести отрисовку на отдельное устройство, тем более, что Savant позволяет соединять пайплайны по сети в цепочку с помощью протокола на базе Rkyv и ZeroMQ или Kafka.
Декодировать все еще надо, само собой, однако, NVDEC идет во всех устройствах NVIDIA и он реально "бесплатный" для задач инференса видео.
Что еще в релизе для устройств без NVENC?
Always-On RTSP Sink Adapter. У нас в Savant есть классный RTSP-адаптер Always-On RTSP. Чем он хорош, так этом тем, что позволяет выводить RTSP-поток независимо от того, есть к нему входящий поток или нет: если поток умер, выводится stub, как на картинке ниже (можно свой подставить).

Этот адаптер так же реализован на базе NVDEC/NVENC и "бесплатный" для правильных GPU. Однако, пользователи используют разные GPU и Jetson Orin Nano, поэтому в релизе мы сделали возможным работу данного адаптера с помощью CPU-кодеков. Особо с производительностью не работали - пока позиционируем как инструмент для разработки, но не продуктива.
Kafka/Redis Sink Adapter. Этот адаптер в режиме Pass-through теперь поддерживает дедупликацию видео-данных. Для выходного потока видео не загружается в KVS заново (если настроено), а используется ссылка на предыдущий хранимый элемент - только TTL может исправляться. Если же используется только Kafka (без Redis), видео всегда складывается в Kafka.
Это самые значимые функциональные фичи релиза.
Демки и сэмплы
Всего в Savant 22 демки на все случаи жизни (детекция, классификация, сегментирование, архитектурные, утилитарные). В этом релизе мы сделали семь новых демок. Вот что мы сделали.
Сэмпл про распознавание номеров машин. Использует модели YOLOV8, NGC LicensePlateDetector, NGC LicensePlateRecognition. Модели LPD/LPR заточены под американские номера, поэтом на армянских косячат - нужно дообучение. Однако, несколько людей одновременно начали создавать с помощью Savant нечто подобное, поэтому мы решили сделать такой сэмпл. Подробнее о сэмпле здесь.
E2E производительность (с рисовкой на фреймах):
92 FPS on Nvidia A4000;
25 FPS on Jetson NX.
Person body keypoints detection. Классический сэмпл про определение и отрисовку суставных точек. Используется YOLOV8N-POSE. Можно использовать как базу для реализации распознования действий. Подробнее о сэмпле здесь.
E2E производительность (с рисовкой на фреймах):
178 FPS on Nvidia A4000
56 FPS on Jetson NX
67 FPS on Jetson Orin Nano
Advanced traffic meter sample. Трекает машины по направлениям на сложном участке дороги (перекресток), результаты складывает в Grafana, где их можно смотреть (с минимальными допилами можно делать госконтракты на мониторинг трафика, не благодарите; товарищи из Индии собрали на базе этого за пару недель e2e систему для мониторинга трафика и измерения скорости). Сделан на базе YOLOV8M. Подробнее здесь.
E2E производительность (с рисовкой на фреймах):
93 FPS on Nvidia A4000
21 FPS on Jetson NX
Object counting by areas. Простенькая демка для начинающих, кто хочет считать очереди всякие и прочую толпу (тоже понравится любителям госконтрактов и прочих искателей дешевой популярности). Сделана на NGC PeopleNet.
E2E производительность (с рисовкой на фреймах):
116 FPS on Nvidia A4000
30 FPS on Jetson NX
Странные демки. Более того, мы сможем их оптимизировать только в следующем релизе, пока что sub-optimal. Они показывают как вы можете применять Savant иначе.
Video super-resolution. Делаем апскейлинг с NinaSR. Эта демка появилась потому что мы никогда раньше не игрались с апскейлом, вот решили поиграться. Делает x3 увеличение.
Разница на глаз не очень заметна, но тут уж претензии к NinaSR. В чем проблема с этой демкой? Фреймы копируются в CPU внутри пайплайна - это некрасиво и неоптимально. Мы сейчас делаем интеграцию с CuPy и доступ к сырым тензором после Nvinfer - когда сделаем, улучшим.
E2E производительность (с рисовкой на фреймах):
49 FPS on Nvidia A4000
AnimeGANv2 demo. Это еще одна "странная" демка для подурачиться (импортозамещение с такой не сделаешь), которая генерирует видео в стиле Хаяо Миядзаки по вашему обычному видео.
E2E производительность (с рисовкой на фреймах):
4 FPS on Nvidia A4000
Архитектурная демка для video pass-through. Демка показывает как соединить гуськом несколько пайплайнов, например, для реализации архитектуры обработки, включающей как edge так и дата-центр, разнеся вычисления между узлами с использованием Video pass-through.
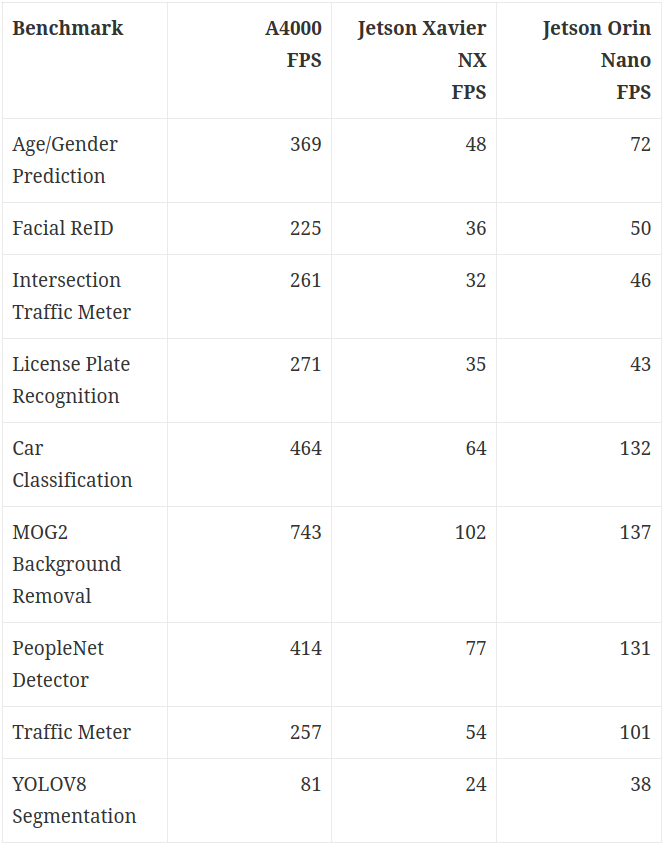
А вот скорость некоторых из сэмплов без отрисовки. Результаты получены с помощью системы бенчмаркинга Savant, можно воспроизвести на своем железе.
Демонстрация работы с Etcd
В Savant можно динамически реконфигурировать пайплайны с помощью Etcd. Мы улучшили демку, показывающую условную обработку потока так, что теперь она позволяет еще модифицировать поведение обработки через Etcd.
Что будет в следующем релизе
В 0.2.7 мы планируем:
представить новый строительный блок - дисковый буффер, для тех, кто не хочет морочиться с адаптером Kafka/Redis, но хочет нормально переживать берсты, чтобы адаптеры доступа к потокам видео реального времени не страдали (RTSP, USB/CSI, GigE Vision);
попробуем реализовать новый инференс блок, основанный на чистом TensorRT с полностью управляемым pre/post-процессингом (нужно для ВИ типа Super-resolution, AnimeGANv2);
сделаем интеграцию и покажем как использовать PyTorch GPU inference в Savant;
сделаем интеграцию с CuPy.
Заключение
Если вам понравился Savant и вы хотите поддержать нашу команду, поставьте нам ⭐ на GitHub. У нас есть документация и Discord (eng) - мы помогаем начинающим со всей силы.
Еще, нас можно нанять на обучение моделей, разработку пайплайнов, оптимизацию инференса и прочие задачи компьютерного зрения.