Я уже не раз порывался написать что‑то общее про бранчинг; про некогда распиаренный GitFlow, который запиаривают обратно; про trunk‑based development (умеренно распиаривают), про то, как это увязать с разработкой бэкенда. И вот я затираю очередной забуксовавший черновик своей заметки с целью всё упростить и не гоняться за чрезмерным обобщением опыта. Давайте я просто поделюсь рецептом, а вы его оцените.
Обозначим ситуацию. Под небольшой апп нужно разработать небольшой бэк. Пара дизайнеров, от двух до пяти мобильщиков/фронтендеров, от двух до пяти человек на бэке, РП, аналитик, девопс, какое‑нибудь начальство — средний проект на полгода‑год‑два, короче. Я таких повидал уже несколько, и в половине подключался на середине жизненного цикла. И может, я не самый везучий и/или не самый опытный, но с бранчингом и средами всегда была какая‑то пускай не задница, но ложка дёгтя. Типа вроде всё нормально, но вот эту полную фигню мы обсуждать и исправлять не будем.
Фигнёй этой было назначение «нижних» общих сред. Если с самой верхней средой всё понятно (это святой продакшен), то с самой нижней всё очень мутно. Обзывают общие среды по‑разному, но я приведу самый частый паттерн: production, staging, development. Вот, например, даже целый Микрософт этот паттерн в своём фреймворке признаёт:

IsEnvironment уже не про конкретную средуИ вот приходишь ты на очередной проект и спрашиваешь у ребят: как бранчуемся? Или не спрашиваешь если в репе лежит BRANCHING.md, но такой документ я лишь сам составлял. И тебе отвечают что‑то в духе «у нас GitFlow, мы делаем бранчи от develop, а дальше смотри вот эту пикчу если ещё не видел». Ну и дальше ты видишь в сотый раз эту пикчу.

И конечно же выясняется, что ветка develop соответствует нижней среде, ниже которой ничего нет. Соответствует в том смысле, что попадающие туда коммиты улетают в облака и проливаются над какой‑нибудь зоной типа https://api.dev.chebur.net.example/... (поэтично, да?)
Но постойте! Братцы! Если любой новый кодинг идёт от develop и это же ваша самая нижняя среда, то где вы экспериментируете? Где вы ловите баги за пределами юнит‑тестов? Ах да, я надеюсь, что у вас есть юнит‑тесты (naïve). И как вы поддерживаете стабильность develop? куда вы деваете недоделанную хрень, попавшую в develop, если вы потом от него пляшете? Извините, накипело.
В ответ звучит что‑нибудь про непонимание GitFlow, про заморозку кода перед релизом, про ещё какую‑нибудь тропинку огородами да гаражами оправдывающую ветвление от бранча, который завязан на экспериментальную по своей природе среду. Ну или отрицание самой идеи latest‑среды с недотестированными фичами.
Однажды меня осенило. Ну, в рамках своих проектов, конечно же; не претендую на открытие формулы всего: никакой ложки нижней среды на вон той диаграмме не существует, и она вообще не отвечает на вопрос долгоживущих сред. И лишь по недоразумению development‑среда оказывается develop‑бранчем под протухшим соусом GitFlow. Та пикча вообще не про бэкенд, который не сильно‑то тяготеет к версионированию.
Оставалось признать очевидное: нужна песочница, playground, workbench — как хотите называйте — которая и станет самой нижней средой. Если запретить ветвление от неё (в неё — можно), если запретить целиком выкатывать её в staging и дальше в production, то всё встаёт на свои места. Появляется общий энв со свежайшим кодом, который разблокирует фронтендеров, который позволяет самому увидеть свой код in action (апихи живые постманом подёргать), и который никого ни к чему не обязывает. Он по определению нестабилен. Точнее, стабилен ровно настолько, насколько позволяет юнит‑тестирование и насколько вообще может быть стабильна свежая фича.
Но если нельзя бранчеваться от dev|elop|ment потому что это какой‑то инкубатор, то откуда и как это делать? Давайте проследим через постепенное усложнение. Допустим, у нас есть только продакшен в облаках и единственный долгоживущий бранч в репозитории — main — на который продакшен и завязан. И пропустим вариант, где мы тупо фигачим все коммиты в main не создавая веток. Итак, простейший workflow:

Перфекшен! Если бы все всё делали идеально, то большего не нужно. И trunk‑based development как раз проповедует: никаких долгоиграющих веток! фигачим всё в ствол, понемногу и часто! любые сомнения заметаем под ковёр из фича‑тогглов! Но что если мы не готовы так радикально перестраиваться? Что если у нас не всё хорошо с тестами? Что если реальность требует где‑то вне продакшена проверять изменения?
Окей, добавим staging, где будем эти изменения копить и проверять. Почковаться разрешим хоть от main, хоть от staging. Типа если хочешь хотфикс сделать и проверить его на staging, то работай от main — так ты сможешь вмёрджить хотфикс в прод не утаскивая туда весь недоваренный staging. Ну а если в staging много почти готового накопилось, а тебе поверх этого надо новую фичу пилить — бранчуйся от staging, всё равно в конце спринта это всё вместе выкатывать.

Но тут приходит фронт и говорит, что им нужна свежая апиха, над которой ты ещё работаешь, чтобы вживую всё проверить. Или приходит бэк (может даже ты сам) и говорит, что подкрутил чего‑то в инфраструктурных скриптах и локально это не проверить вообще никак, надо накатить куда‑то. Этим «куда‑то» и становится development.
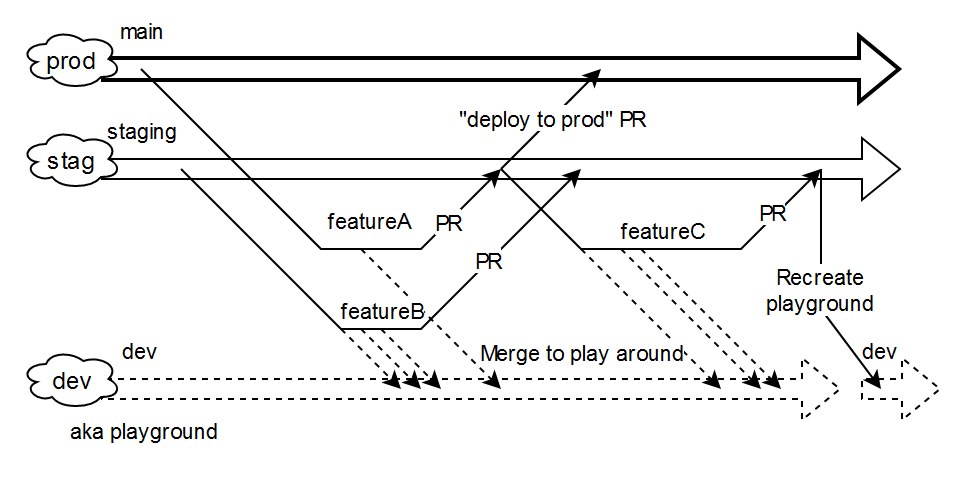
В этой диаграмме важно то, что она вообще никак не изменила предыдущую. Она просто объявила среду совместной разработки (в плане доступности свежего кода в живой среде). Общий верстак, на котором можно допиливать полуготовый код. И эта среда по умолчанию нестабильно, и двигать её целиком вверх на staging или prod нельзя, и вообще можно с неё всё смахнуть (договорившись с командой) и начать с чистого листа — ну мало ли чего там брошенного накопилось.
Бардак? Ну да, можно смотреть как на бардак. Но можно смотреть как на компромисс и реальный способ обуздать косячную реальность. Да‑да, лучше сразу не косячить и всё такое. Где вы это видели? Возьмите меня туда учиться.
Идею можно развивать дальше и вместо одной песочницы объявить эфемерные среды, где можно поднять свою маленькую изолированную песочницу из любой ветки.

В теории это даже позволяет отказаться от staging, потому что проверять всё можно независимо и потом лить в продакшен тоже независимо.

Но это уже фантазии, до воплощения которых я не добирался. Предвижу, что это потребует качественного генератора тестовых данных и очень генерализованного CI/CD. Тестировщики, привыкшие к фиксированным средам, тоже спасибо не скажут. Оставим эту тему на другой раз.
Активирую режим подытоживающей интроспекции. Писать про то, как ты раз за разом сталкивался со стрёмными паттернами, неловко и обидно — что же это за работа такая грязная. Разбавлять это какими‑то компромиссными решениями неловко вдвойне. Но мне норм; и даже моя команда не против описанного подхода. Признав песочницу песочницей, мы перестали спорить о её стабильности. Да, она имеет свойство засоряться, но теперь это блокирует только её саму, а не возможность выкатить обновления в прод.
Комментарии (17)

PashaPash
22.11.2023 19:53+1Но что если мы не готовы так радикально перестраиваться? Что если у нас не всё хорошо с тестами? Что если реальность требует где-то вне продакшена проверять изменения?
Если вы не готовы радикально перестраиваться - то вы будете терять время на интеграции изменений друг с другом, на кодфризах, поездах релизов и прочих эффектах накопления изменений. Потому что каждый мерж чужих изменений в вышестоящее окружение требует ретеста нижестоящих. И чем больше слоев - тем больше накладных расходов на ретест и на интеграцию.
Перестраиваются не ради процесса, а ради улучшения конкретных метрик. Если у вас цель "сверхпротестированные релизы раз в год" - то дополнительные стадии между кодингом и релизом - это хорошо. Если цель - быстрые небольшие релизы и вам нужно Dora улучшать - то это шаг в обратном направлении.

ritorichesky_echpochmak
22.11.2023 19:53+1Берём последнюю картинку из статьи и пусть feature/ бранч станет тем самым тестовым бранчем который будет раскатываться на тестовое окружение. Он всегда создаётся их актуального мастера, но не всегда возвращается в мастер (отменили фичу). Над ним работает команда, в которой каждый участник создаёт dev/ бранч под каждую выполняемую им задачу.
При мерже dev/ в feature/ всегда проходят автотесты и только после их прохождения будет code review, затем всё разворачивается на тест по которому долбит QA и automated QA. feature/ бранч регулярно актуализируется как новыми фиксами разработчиков, так и из мастера и по сути представляет из себя мастер к которому добавили новую фичу, а не зоопарк для всех несвязанных между собой штук. Тестируется фича и всё что она может зааффектить (ну и всё до чего Automated QA дотянулся).
Затем, когда всё готово, делается merge request в мастер, опять проходят все автотесты, в часы наименьшей нагрузки всё это вот раскатывается на прод, отдел тестирования пинает прод во всю мощь. В этот момент раскатываемый feature-бранч и мастер полностью соответствуют друг другу (т.е. версия которую тестировали полностью соответствуюет релизной).
Код из актуального мастера становится основой для следующей фичи, а так же подтягивается во все ещё разрабатывающиеся фичи. Таким образом актуальный мастер становится точкой истины, это актуальный рабочий релиз от которого и должны плясать все изменения, все бранчи, все команды. Если у кого-то из ещё готовящих новые фичи что-то вдруг не срослось после изменений в мастере - об этом узнают на этапе тестирования и эту часть допилят в feature/ ветке.
Никакого постоянного заливания мастера сырыми неоттестированными фичами и прочими косяками.
Количество тестовых серверов соответствует количеству команд пилящих независимые фичи

abulanov
22.11.2023 19:53А у нас прямо вот так все и есть ) И это вопрос скорее не откуда куда какие ветки плодить, а именно про разделение сред для исполнения: каждый разработчик может на свой стенд затащить нужные версии/ветки нужных ему для разработки сервисов, а все остальное будет смотреть на стейдж.

smirnfil
22.11.2023 19:53Все что нужно для работающего GitFlow - возможность деплоить случайные бранчи. Как только это проблема решена проблема с песочницей исчезает - в dev мержится код, который должен быть стабильным. Если хочется экспериментов - создаешь себе feature branch и делаешь с ней что хочешь. Туда же идут долговременнные проекты, которые требуют большего внимания чем dev.


ch4t5ky
Тоже был вопрос как организовать такую среду, где можно будет поиграться с кодом и в итоге сделал так, что в любой feature/* ветке есть возможность по нажатию кнопки раскатать себе окружение, но при MR эта среда обязательно создается, чтобы проверить работу сервиса перед выкаткой на staging.
funca
Microsoft продвигают trunk -based из-за своих масштабов. Когда у вас тысячи разработчиков и десятки тысяч микросервисов, то идея разворачивать на каждую фичу отдельное окружение со всем этим добром упирается в ограниченные ресурсы и нерезиновый бюджет.
Чтобы бесконечное количество фич различной степени готовности уместить в ограниченном количестве окружений, используют не бранчи, а feature flags (toggles). Каждая фича закрывается флажком и в каждом из окружений включается свой набор.
В мелких проектах с небольшим количеством лёгких сервисов ситуация может быть иной.
Atorian
Вообще там во всех окружениях для разрботки(все что не прод) все изменения должны быть включены - нет "в каждом из окружений включается свой набор". Свой набор только в проде. Иначе невозможно протестить свое изменение с другими.
Бранчи вообще зло. Не надо их использовать для управления окружениями.
funca
Вы правы в том, что конкретные тактики управления FF определяются принятыми релизными циклами и требованиями тестирования. Например, может быть ситуация, что релиз фич у вас планируется на несколько версий вперёд, но тестировать какие-то детали нужно уже сейчас, а не в самый последний момент.
Для сервисов часто используется схема окружений Dev, QA, UAT-DR-Prod. Для нестабильной функциональности к FF добавляются conditions, включающие их лишь при определенных условиях (допустим, для конкретных пользователей, тенантов и т.п.). Это позволяет тестировать свои изменения с минимальными рисками для других команд. Поэтому в общем случае наборы отличаются. Но могут быть ситуации, когда и совпадают.
YegorP Автор
С фиче-тогглами проблема, что либо код ими обрастает, либо приходится тратить время на их вычищение. А если онлайновые фиче-тогглы встраиваются в мобильное приложение, то всё становится вообще плохо, потому что удаление неактуального тоггла превращается в многомесячный ритуал (приходится поддерживать пользователей, по разным причинам не обновляющих приложение).
funca
Полностью согласен, FF добавляют заметный кусок работы, которая отчасти пересекается с вопросами сохранения обратной совместимости и удаления неиспользуемого кода. Хотя в каком-то плане даже упрощают, когда у вас есть аналитика по использованию тоглов из которой видно, что можно безболезненно удалить.
PashaPash
А в чем конкретно проблема с организацией среды? Зависит от окружения, конечно, но мы, например, используем на trunk-based с небольшими app-specific костылями:
Приложение с multi-tenancy, 30+ мелких сервисов, k8s (Azure, AKS, мелковато нарезано).
У всех, и разработчиков, и QA, есть свой namespace, по умолчанию пустой. У каждого свой tenant (условно, внешний url vasya.dev.company.com или dev.company.com/vasya).
Есть общий нейспейс dev, куда настроен автодеплой по мержу в мастер (он же настроен и для production)
На дев кластере есть сервер-роутер, который ловит и входящие и кросс-сервисные запросы, и роутит их или по tenantid в нейсмпейс разработчика, если там нужный сервис есть. Или в общий dev, если в неймспейсе разработчика нужного сервиса нет.
QA в свои неймспейсы льют merge-ревизии c github (т.е. то, что будет в мастере после мержа) и тестируют по схеме "все как на проде + один измененный сервис"
Девелоперы - точно так же, но с возможностью отдебагать залитый сервис через bridge to kubernetes (telepresence, etc.)
по мержу все это улетает в мастер, и автодеплоем в dev и prod. Стейджинга нет (зачем? тестировать еще раз уже протестированное?).
для фронта та же схема, но с заливкой tenant-specific статики вместо бэка.
ну и да, все изменения под feature flags, потому что деплой фич на прод != доступность фич реальным пользователям. После деплоя делаются туры, какие-то тенанты получают фичи раньше/позже, feature flag management - это отдельная ниша, под нее есть всякие devcycle.com и launchdarkly.com. И это не бэкэнд стори.
Чтобы это работало нужны unit tests, code review до отдачи в тест и возможность задеплоить сервис куда угодно в один клик. Ну еще мониторинг и вера в команду :)
Цена вопроса - до гига памяти в общем кластере на девелопера/QA (на дев окружении реквесты/лимиты меньше можно выставить).
Есть еще более агрессивные модели - тот же github flow, где деплой в прод делается из PR до мержа, и мерж проходит только если прод не упал. Но это мерж-экстремизм :)
PrinceKorwin
Видимо разработка не на Java? На Go пишете? Ибо что-то подобное как у вас строили, но код на Java (springboot). По ресурсам становилось уже дорого.
Статью об этом не хотите написать? Думаю многие бы с удовольствием почитали.
PashaPash
Пишем на asp.net core / C#, Linux + легаси часть на asp.net / Windows. Чтобы было дешево - нужны хорошо разделяемые ресурсы (k8s) и container-friendly framework (== возможность запустить приложение как консольку, без обвеса в виде IIS/Tomcat/Application Server, )
Да, стоимость надо считать заранее. Гиг памяти сейчас около 5$ в месяц, если брать на Azure по полной цене, 2$ по предзаказу. Футпринт фреймворка примерно 150Mb на инстанс.
Статью хочу, но нужно время на написание, а его нет :)
Atorian
Не могли бы вы пояснить, как у вас вышел trunk-based с merge? Ведь merge - это значит что есть бранчи. Не то чтобы их совсем нельзя в TBD, но у них должен быть тогда специфичный жизненный цикл.
PashaPash
В trunk-based есть бранчи, со своим workflow, просто они short living и они не используются в качестве основного способа работы над фичами (понятно что есть исключения, но если что-то можно сделать от мастера - то это делается от мастера). Это стори-бранчи от мастера. Основной юнит кодинга/интеграции/тестирования это бранч/стори, а не фича целиком.