Мы хотим дать вам возможность экспериментировать с LLM, разрабатывать приложения и открывать ранее неизвестные предметные области. Поэтому совместно с Alireza Goudarzi, страршим исследователем Машинного Обучение и Albert Ziegler, ведущим инженером по Машинному Обучению, оба из GitHub, мы решили обсудить формирующиеся подходы к архитектуре приложений, использующих LLM.
В этом посте мы рассмотрим пять наиболее важных этапов, который нужно пройти при разработке собственного приложения на основе LLM, формирующиеся общепринятые подходе к разработке таких приложений и предметные области, на которые стоит обратить внимание.
Пять шагов по созданию приложения с LLM
Разработка приложения с LLM или любой другой моделью Машинного Обучения отличается от разработки приложения без них по ряду фундаментальных свойств. Например, вместо компиляции исходного кода в бинарный код, выполняющий последовательности команд, разработчикам приходится управлять наборами данных, эмбеддингов и параметрами моделей, чтобы получить согласованный результат. Кроме того, выход LLM имеет вероятностный характер — эти модели не выдают один и тот же предсказуемый результат.

Давайте рассмотрим, высокоуровнево, шаги по разработке современного приложения с LLM ????
Сконцентрируйтесь на одной задаче
В чем суть? Найдите задачу подходящего масштаба. Она должна быть достаточно узкой, чтобы можно было быстро тестировать возможные решения и демонстрировать прогресс, но с другой стороны — достаточно большой, чтобы, чтобы её решение могло поразить пользователей.
Например, вместо того, чтобы решать все проблемы разработчиков с помощью ИИ, команда GitHub Copilot сконцентрировалась на одном из элементов жизненного цикла ПО: функциональности написания кода в IDE.
Выберите подходящую LLM
Вы пытаетесь уменьшить издержки, разрабатывая приложение, использующее предобученную модель, но как выбрать правильную? Вот пара вещей, которые надо учесть.
Лицензия. Если вы рассчитываете продавать ваше приложение, вам нужно использовать модель, API которой допускает коммерческое использование. Для начала, вот список LLM с открытым кодом, лицензии которых допускают коммерческое использование.
-
Размер модели. Размер LLM может изменяется в пределах от 7 до 175 миллиардов параметров. Некоторые, вроде Ada, могут быть еще меньше и иметь 350 миллионов параметров. Но большинство LLM (на момент написания этого поста) имеют от 7 до 13 миллиардов параметров.
Здравый смысл подсказывает, что чем больше у модели параметров (то есть переменных, которые можно менять, чтобы улучшить её результаты), то тем лучше она будет изучать новую информацию и генерировать ответы. Но результаты, показанные небольшими моделями противоречат этому предположению. Кроме того, небольшие модели, как правило, работают быстрее и их эксплуатация обходится дешевле, так что последние достижения в повышении качества их ответов делают их хорошим выбором в сравнении с моделями с громкими именами, которые могут просто не подойти для некоторых приложений.
Ищете LLM с открытым кодом?
Ознакомьтесь с нашим руководством для разработчиков по LLM с открытым кодом, который включает модели вроде OpenLLaMA и модели семейства Falcon
Производительность модели. Прежде чем дообучать модель используя подходы вроде fine‑tuning или in‑context learning (о них будет чуть ниже), протестируйте, насколько хорошо, быстро и связно модель генерирует тот ответ, который вы от неё ожидаете. Для измерения этих качеств модели можно воспользоваться offline evaluations.
Что такое offline evaluations?
Это тесты, которые оценивают модель прежде чем её переведут на следующий уровень взаимодействия с человеком. Эти тесты измеряют время ответа, точность и соответствие контексту. При тестировании модели задают вопросы, для которых человеку известен верный или неверный ответ.
Также бывает подмножество таких тестов, которое предназначено для оценки двусмысленных ответов. Эти тесты называются incremental scoring. Эти тесты позволяют оценивать ответы модели не с позиции верен он или не верен целиком, а допуская частичную (скажем, на 80%) правильность.
Дообучение LLM
При обучении LLM вы формируете модель общего назначения. Когда вы дообучаете модель, вы адаптируете её к конкретным задачам, вроде генерации текста на заданную тему или в конкретном стиле. Раздел поста ниже целиком посвящён этому вопросу. Для адаптации модели под ваши потребности, вы можете использовать in‑context learning, reinforcement learning from human feedback (RLHF) или fine‑tuning.
In‑context learning, также известный как prompt engineering, это подход, при использовании которого вы даёте модели конкретные инструкции или примеры во время генерации ответа и просите модель определить что вы хотите, и сгенерировать подходящий по контексту ответ. In‑context learning можно выполнять разными способами, например, предъявляя примеры, перефразируя свои вопросы или явным образом добавляя инструкции о том, чего вы хотите.
RLHF вводит понятие награждающей модели для предобученной LLM. Награждающая модель учится предсказывать, понравится ли пользователю ответ предобученной LLM. Обе модели взаимодействуют между собой, что заставляет LLM изменять свой ответ в соответствии с предпочтениями пользователя. Преимущество RLHF в том, что этот подход является обучением без учителя, и, как следствие, позволяет расширить критерии того, что является допустимым ответом. Имея достаточно обратной связи, LLM может выучить, что, если пользователь примет ответ с вероятностью 80%, то этот ответ можно предложить. Хотите попробовать сами? Ознакомьтесь с этими ресурсами для RLHF, включающими исходный код.
Fine‑tuning это подход, когда генерированные моделью ответы сравниваются с заранее известными или желаемым ответами. Например, вы знаете, что модель должна оценить утверждение вроде «Суп слишком солёный» как негативно окрашенное. Для оценки модели вы подаёте ей это утверждение и просите оценить его как позитивно или негативно окрашенное. Если модель помечает его как позитивно окрашенное, вы изменяете параметры модели и пытаетесь снова проверить, оценит ли модель его как негативно окрашенное. Fine‑tuning позволяет получить очень кастомизированную модель, демонстрирующие отличные результаты в некоторой конкретной задаче. Но он относится к методам обучения с учителем и требует больших трудозатрат на разметку данных. Другими словами, нужно чтобы каждый пример был проанализирован классифицирован верно. В итоге фактический ответ модели можно сравнить с известным и затем изменить веса модели соответствующим образом. Преимущества RLHF в том, что, как было отмечено выше, ему не требуется знать точный ответ заранее.
Сформулируйте архитектуру самого приложения
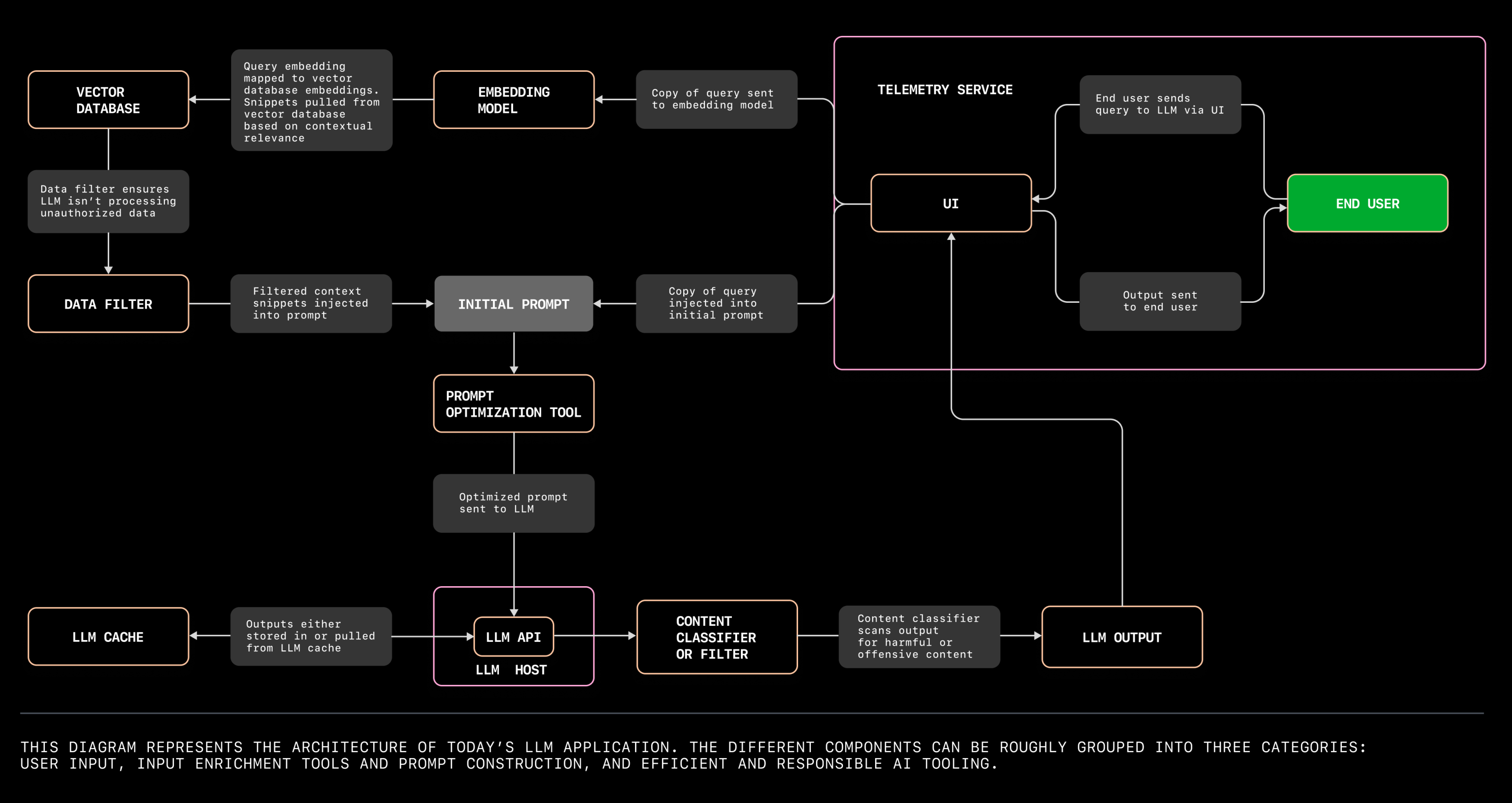
Компоненты, которые вам потребуются для построения приложения можно разделить на три группы.
Пользовательский ввод, что подразумевает UI, LLM и вычислительную платформу для работы приложения.
Инструменты для обогащения ввода и конструирования запроса. Сюда относятся ваши наборы данных и эмбеддингов, векторная база данных, инструменты для конструирования и оптимизации запросов к модели и фильтр её ответов.
Инструменты для обеспечения эффективности и надежности ИИ, то есть кеш LLM, классификатор (фильтр) ответов LLM и телеметрия для оценки работы модели.
Проведите тестирование модели во время эксплуатации
Эти тесты проводятся во время эксплуатации приложения потому что они оценивают работу LLM во время взаимодействия модели с реальными пользователями. Например, такое тестирование GitHub Copilot предполагает измерение частоты принятий пользователями ответов модели (то есть насколько часто разработчик расценивает ответ модели как подходящий) и измерение частоты правок (то есть насколько части и в какой мере разработчик исправляет ответ модели, который он перед этим принял).
Почему такое тестирование важно?
Хотя модель может легко пройти все внутренние тесты, качество её ответом может меняться, когда она попадает в руки пользователей. Причина в том, что трудно предсказать, как пользователи будут взаимодействовать с UI, и это взаимодействие трудно смоделировать во время внутреннего тестирования.
Современная архитектура приложений с LLM
Теперь перейдём к архитектуре. Мы собираемся снова обратиться к Дейву, чей Wi‑Fi вышел из строя в день вечеринки по совместному просмотру Кубка Мира. К счастью, Дейв смог всё наладить вовремя, благодаря ассистенту на основе LLM.
Мы будем использовать этот пример и диаграмму ниже чтобы пройти по приложению на основе LLM и понять, инструменты какого типа вам понадобятся, чтобы его создать.

Инструменты для пользовательского ввода
Когда Wi-Fi Дейва выходит из строя, он звонит своему провайдеру и попадает к ассистенту на основе LLM. Этот ассистент просит Дейва рассказать, что стряслось и Дейв отвечает: "Мой телевизор подключен к моему Wi-Fi, но я задел тумбу телевизора и Wi-Fi-роутер упал и отключился. И теперь мы не можем посмотреть игру.".
Чтобы Дейв смог взаимодействовать с LLM, нам потребуются четыре инструмента.
API для LLM и сервер с моделью. Где мы считаем ответ модели -- на локальном сервере или в облаке? В случае интернет-провайдера, модель, скорее всего, развёрнута в облаке, чтобы обработать весь объем звонков, вроде звонка Дейва. Vercel и более ранние проекты, вроде jina-ai/rungpt, стремятся предоставить облачное решение для развертывания и масштабирования приложений на основе LLM. Но если вы хотите повозиться чуть больше, то развертывание модели на собственном железе может оказаться более дешёвым подходом, так как вам не придётся платить за развертывание облачной среды каждый раз, когда вы захотите поэкспериментировать с моделью. Вы можете найти обсуждения требуемого аппаратного обеспечения для моделей вроде LLaMA на GitHub Discussions, например тут и тут.
UI: клавиатура телефона Дейва и есть, в общем-то, UI, но чтобы Дейв мог использовать эту клавиатуру для перемещения по меню линии технической поддержки, UI должен включать и какой-то механизм маршрутизации.
Инструмент для преобразований Speech-to-text. Голосовой запрос Дейва нужно пропустить через инструмент для преобразования речи в текст, который запущен в фоне.
Инструменты для обогащения ввода и конструирования запроса
Вернёмся к Дейву. LLM может проанализировать слова, произнесённые Дейвом, классифицировать его обращение как жалобу на техническую проблему и предоставить соответствующий контексту ответ (LLM способна на это потому, что была обучена на корпусе текстов из интернета, который включает и документацию по технической поддержке).
Инструменты для обогащения ввода стремятся преобразовать пользовательский ввод и насытить его контекстом, чтобы помочь модели сгенерировать наиболее полезный ответ.
Вы можете использовать векторную базу данных для хранения эмбеддингов или индексировать векторы большой размерности. Эта база данных также повышает вероятность того что ответ LLM окажется полезет, предоставляю дополнительную информацию о контексте пользовательского запроса. Пусть ассистент на основе LLM имеет доступ к корпоративной поисковой системе для пользовательских обращений и эмбецдинги этих обращения хранятся в векторной базе данных. Поэтому LLM-ассистент использует не только оказавшуюся в обучающем корпусе информацию из интернета, но и информацию, специфичную для обращений на линию техподдержки интернет-провайдера.
Но чтобы получить из базы данных информацию, релевантную запросу пользователя, нам нужна модель для генерации эмбеддингов, чтобы преобразовать запрос в вектор. Так как эмбеддинги, лежащие в векторной базе данных, и запрос Дейва преобразованы в векторы большой размерности, эти векторы содержат информацию о смысле и цели обращения, а не только о его синтаксисе, как предложения на естественном языке.
Вот список моделей эмбеддингов с открытым исходным кодом, OpenAPI и Hugging Face также такое предоставляют.
Расширенный запрос Дейва может принять вид вроде следующего примера.
// удели внимание следующей полезной информации
цвет лампочек и то, как они мигают
// удели внимание следующей полезной информации
// это обращение от Дейва Андерсона, IT-специалиста
Ответы на вопросы Дейва должны быть примером высокого
качества поддержки, предоставляемой интернет-провайдером его клиентам.
*Дейв: О, это ужасно! Сегодня день большой игры. Мой телевизор подключен
к моему Wi-Fi, но я задел тумбу телевизора и Wi-Fi-роутер упал и отключился.
И теперь мы не можем посмотреть игру.Эта дополнительная информация не только привносит контекст в обращение Дейва, но и извлекает контекст из базы данных пользовательских обращений. Этот контекст включает наиболее распространённые проблемы с интернетом и их решения.
MongoDB представили Vector Atlas Search, который индексирует векторы большой размерности, хранящиеся в MongoDB. Qdrand, Pinecone и Milvus также предоставляют векторные базы данных бесплатно или с открытым исходным кодом.
Хотите узнать больше о векторных базах данных?
Прочтите как команда GitHub Copilot экспериментирует с с ними, чтобы создать персонализированный опыт написания кода.
Фильтр данных поможет убедиться, что LLM не обрабатывает данные, которые не надо, вроде личных данных. Проекты вроде amoffat/HeimdaLLM работают над тем, чтобы гарантировать что LLM используют только разрешённые данные.
Инструмент оптимизации запроса поможет сформировать единый запрос, объединив то, что сказал пользователь, с контекстом. Другими словами, этот инструмент поможет расставить приоритеты, чтобы обозначить, какие эмбеддинги более важны и релевантны, в каком порядке они должны быть расположены, чтобы помочь LLM сформировать наиболее подходящий ответ. Этот тот этап, который ML-инженеры называют prompt engineereing, когда несколько алгоритмов помогают сформировать запрос (обратите внимание, это отличается от того prompt engineering'а, который используют пользователи, также известный как in-context learning). Инструменты оптимизации запросов, вроде langhain-ai/langchain, помогают конечным пользователям формировать запросы. В противном случае вам понадобятся самодельные алгоритмы, который будут запрашивать эмбецдинги из векторной базы данных, подбирать подходящий контекст и располагать их в правильном порядке. Если вы пойдете по второму пути, вам могут помочь GitHub Copilot Chat или ChatGPT.
Узнайте больше о том, как команда GitHub Copliot использует коэффициент Жаккара чтобы понять, какие части контекста более соответствуют запросу пользователя.
Инструменты для обеспечения эффективности и надежности ИИ
Чтобы убедиться в том, что Дейв не разозлиться от необходимости ждать ответа от LLM, мы можем быстро извлечь его из кеша. И если Дейв вышел из себя, мы можем использовать контентный фильтр, чтобы модель не грубила в ответ. Сервис сбора телеметрии также проанализирует процесс взаимодействия Дейва с интерфейсом пользователя, чтобы вы, как разработчик, могли улучшить пользовательский опыт на основе поведения Дейва.
Кеш LLM хранит ответы модели. То есть, вместо того чтобы генерировать ответ по-новому на тот же самый запрос (посколько Дейв далеко не первый, у кого упала сеть), LLM может извлечь из кеша ответ, который уже использовался в подобных случаях. Использование кеша может уменьшить задержку до получения ответа, затраты на генерацию ответа и снизить вариативность ответов в похожих ситуациях. Для кеширования ответов вашей модели вы можете попробовать zillitech/GPTcache.
Контентный классификатор или фильтр не даст вашему автоматическому ассистенту ответит грубо или оскорбительно (если пользователь решит выместить свое недовольство на вашем приложении). Инструменты вроде derwiki/llm-prompt-injection-filtering и laiyer-ai/llm-guard хотя и находятся на ранней стадии разработки, но стремятся к тому, чтобы предотвратить подобные инциденты.
Сервис сбора телеметрии позволит вам оценить, насколько хорошо ваше приложение решает проблемы реальных пользователей. Сервис, который прозрачно и ответственно отслеживает активность пользователей (например, как часто они принимают предложенный ответ или меняют его) могут предоставить полезные данные для того чтобы улучшить ваше приложение и сделать его более удобным. Например, есть OpenTelemetry -- открытый фреймворк, который дает разработчикам стандартизированные способы по сбору, обработке и экспорту телеметрии.
Узнайте, как GitHub использует OpenTelemetry для измерения производительности git.
Ищете инструменты для более ответственного ИИ?
Разработчики создают на GitHub проекты по темам ответственного ИИ, честного ИИ, ответственного Машинного Обучения, и этичного ИИ.
Ура! ???? Ваш LLM-ассистент успешно ответил на все вопросы Дейва. Его роутер снова работает и он готов к вечеринке по просмотру Кубка Мира. Миссия выполнена!
Влияние LLM на реальный мир
Ищете вдохновение или предметную область для своего исследования? Вот список идущих прямо сейчас проектов, где приложения на основе LLM влияют на реальный мир.
NASA и IBM недавно опубликовали открытую большую геопространственную модель, чтобы упростить доступ к научным данным NASA. Они надеются ускорить исследование и понимание климатических эффектов.
Лаборатория Прикладной Физики института Джонса Хопкинса разрабатывает диалогового ИИ-агента, который предоставляет, на понятном языке, инструкции солдатам в поле по оказанию первой помощи.
Duolingo и Mercado Libre используют GitHub Copilot чтобы помочь большему числу людей изучать иностранные языки (бесплатно) и демократизировать рынок электронной коммерции в Латинской Америке, соответственно.