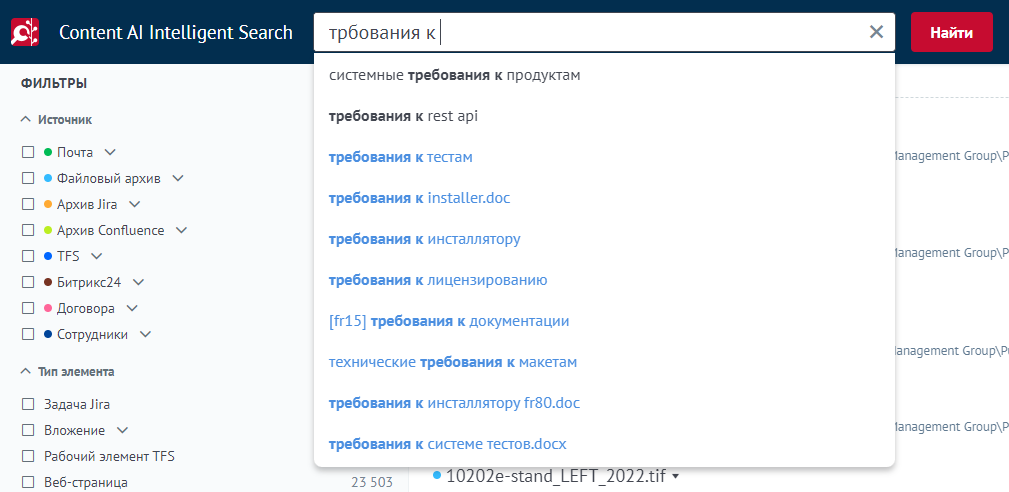
Казалось бы поисковые подсказки (автокомплит) простая и понятная вещь, реализованная во множестве проектов и работающая из коробки.
Как бы не так.
Под катом расскажем про существующие подходы, их ограничения, и как мы вышли из положения для реализации подсказок в продукте для корпоративного поиска Content AI Intelligent Search.
Сначала пара слов о продукте. Content AI Intelligent Search – решение для создания корпоративного поискового портала. Оно позволяет объединить все источники хранения данных в компании и осуществлять по ним интеллектуальный поиск. Для понимания сразу обозначим, что продукт реализован на базе ElasticSearch.
Требования
Для начала опишем, какие требования выдвигались к реализации этой функции:
поисковые подсказки должны строиться на основе ранее выполненных запросов и заголовков документов
слово из запроса может быть в любом месте подсказки: в начале, в середине и в конце
каждое слово из запроса может содержать не более двух опечаток, при этом первая буква слова должна быть введена верно
необходимо выделять в подсказках введенные пользователем слова, даже если они введены с опечатками
не показывать подсказки в случае, если они совпадают только по стоп-словам (предлогам, союзам и прочим частотным терминам)
при отображении в подсказках заголовков документов должны учитываться права доступа
Основной проблемой стало требование по учету опечаток, но к этому мы вернемся чуть позже. А пока давайте кратко рассмотрим, какие в принципе существуют подходы для реализации поисковых подсказок.
Подходы
Prefix Query
Использовать для поиска подсказок prefix query по требуемому полю.
Плюсы:
никакие дополнительные данные не хранятся
Минусы:
не работает с опечатками
не работает, если подсказка содержит введенное слово в середине значения
возможны дубли в результатах (но их можно отфильтровать после)
Edge Ngrams
При индексации и поиске задействованы разные анализаторы. При индексации используется edge n-gram фильтр, который разбивает слова по разделителями и сохраняет N-gram-ы для начала слов. Например, для слова «тест» будут сформированы N-gram-ы «т», «те», «тес» и «тест».
При поиске используется стандартный анализатор. Тогда по мере набора пользователем запроса будет находиться искомая часть поисковой подсказки.
Плюсы:
работает со словами в середине запроса
Минусы:
не работает с опечатками
нужно хранить дополнительно N-gram-ы
Completion Suggester
Вариант автокомплита из коробки.
Плюсы:
работает из коробки
Минусы:
не работает с опечатками
не работает со словами в середине запроса
нужно хранить отдельное поле типа completion
Наша реализация
Обзор существующих подходов говорит о том, что серебряной пули не существует, и ни одно из решений не удовлетворяет всем требованиям. Выделения введенных пользователем слов в подсказке и учета опечаток нет ни в одном из них.
Поэтому было решено сделать свою реализацию так, как нужно нам.

Ранее выполненные поисковые запросы и заголовки документов хранились в строковых полях с дефолтным анализатором. Дополнительно для запросов и заголовков есть отдельное поле с типом keyword с таким же значением. Второе поле нужно для обеспечения уникальности подсказок (см. ниже).
Для поиска используем следующую комбинацию: для каждого слова в запросе применяем Fuzzy Query (нечеткий поиск) по целевым полям + для последнего слова, которое находится в процессе ввода, Prefix Query (префиксный поиск) и объединяем в Bool Query (логическое И/ИЛИ).
Плюс добавляем фильтрацию по правам доступа при поиске по именам документов, чтобы не показывать лишнего.
В таком случае обеспечивается нечеткий поиск и в начале, и в середине фразы. Префиксная часть запроса нужна для поиска слов, начинающихся с введенных символов.
Если по сформированному запросу просто запросить список найденных запросов/заголовков документов, то в общем случае среди них может быть много дублей. При этом пользователю нужно показать все уникальные (но не более 10). Запрос большого числа найденных документов (с запасом на фильтрацию дублей) выглядит ненадежным решением и неизбежно вызовет заметную задержку в отображении подсказок.
Поэтому вместо результатов поиска мы запрашиваем агрегацию по полю с типом keyword. В этом случае ответ будет всегда состоять из уникальных значений. Из нюансов такого подхода — нужно самостоятельно реализовать подсветку найденных терминов, чтобы было понятно, почему нашлась конкретная подсказка. Для этого находим в подсказке в следующем порядке: полное совпадение – по префиксу – самые похожие на запрос слова (по алгоритму Левенштейна). Там же отбрасываем подсказки, совпадающие только по стоп-словам.
Результаты

У нас получилось выполнить все требования, хотя и ценой хранения одного дополнительного поля для каждого поля, которое используется для формирования подсказок.
Проверка на индексе из нескольких миллионов документов показала, что визуальной задержки при формировании списка подсказок с такой реализацией не наблюдается. По мере ввода запроса список подсказок оперативно обновляется.
MaxPro33
Каковы были основные трудности при реализации поисковых подсказок в продукте Content AI Intelligent Search, основанном на Elasticsearch? Что стало ключевым решением для учета опечаток в запросах, удовлетворяя при этом другие сложные требования, такие как выделение введенных слов и учет прав доступа при отображении заголовков документов в подсказках? Как ваша реализация справляется с поиском слов в середине запроса и избеганием дублей в результатах подсказок?