
Привет, Хаброжители! Я Саша, Go-разработчик в компании СберМаркет. Я со своей командой работаю над созданием инструментов PaaS.
В предыдущих статьях мои коллеги делились интересными деталями о нашей платформе:
Дима провел обзор инструментов, которые используются в нашей платформе.
Рома рассказал о нашей полезной утилите, придающей легкость повседневной жизни - sbm-cli.
Никита поделился опытом локальной разработки и тем, как мы гармонично соединяем все наши сервисы.
Сегодня я приглашаю тебя в увлекательный мир мозга нашего PaaS, который мы с любовью окрестили Huginn.
Почему такое название? Все дело в том, что мы, PaaS’овцы, находим вдохновение в скандинавской мифологии, а Хугин — это именно тот ворон, который свободно мчится по миру, собирает ценную информацию и предоставляет ее… верно, всей нашей PaaS-платформе!

PaaS для нас — это не просто микросервисная архитектура. Это целый мир, в котором с самого начала мы почувствовали потребность в создании эффективного хранилища для всех сервисов, чтобы все было наглядно. Именно так началась наша увлекательная история…
Мы автоматизировали процесс регистрации сервисов при их деплое. Теперь каждый раз, когда новый сервис запускается, он регистрируется в нашей системе. Более того, мы расширили этот процесс, чтобы Huginn собирал важные данные о каждом сервисе, такие как манифест приложения при каждом деплое. Вдруг что-то изменится — мы об этом сразу же узнаем и отображаем!
Итак, мы автоматизировали сбор ключевых метрик и метаданных о каждом сервисе в единую систему Хугин. Теперь давайте разберёмся, что именно она умеет и какие проблемы решает.
Хугин состоит из нескольких ключевых компонентов:
В конце поделюсь выводами, что нам даёт Хугин. Теперь — обо всём по порядку.
Карточка сервиса
Карточка сервиса — это что-то вроде профиля, аккумулирующего ключевую информацию о каждом сервисе в одном месте.
Во-первых, здесь представлена базовая метаинформация о сервисе — данные из манифестов, helm values и так далее.
Во-вторых, карточка отображает важные взаимосвязи сервиса — его контракты, зависимости от других сервисов.
В-третьих, она интегрирует механизмы взаимодействия разработчика с сервисом — это интерфейс Swagger UI для тестирования API и визуальный конструктор API.
Таким образом, карточка сервиса предоставляет централизованный доступ к критически важной информации для разработки, тестирования и мониторинга.
Предлагаю взглянуть на первый скрин нашей PaaS-платформы, где мы собрали всю необходимую информацию о наших сервисах в одном месте.

Здесь представлена обширная информация о каждом сервисе. Можно фильтровать данные по различным параметрам: оценить актуальность зависимостей и контрактов, посмотреть версии манифестов и ключевых библиотек.
Также для каждого сервиса выставлена оценка (Scoring), о котором расскажу позже.
Давай взглянем на карточку конкретного сервиса, там будет намного больше информации, которую можно получить:

Начнем сверху. У каждого сервиса есть тэги, в которых указана важная информация:
Язык разработки (golang, ruby, python, js и т. д.)
Версия приложения
Кластер, на котором развернут сервис (как стейдж, так и прод)
Домен, к которому относится сервис
Команда, ответственная за сервис
Критичность сервиса (tier)
Ссылка на GitLab-репозиторий
Также в карточке есть несколько вкладок, каждая содержит значимую информацию.
Readme: Это файл Readme.md каждого проекта, где разработчик может найти важную информацию, такую как особенности запуска сервиса или что нужно сделать, чтобы запустить интеграционные тесты локально.
Контракты: Согласно нашему API-first подходу, контракт стоит в основе, а код идет после. Эта вкладка предоставляет полную информацию о контрактах сервиса, включая openapi, proto контракты. Если контракт представлен в формате openapi, то тут же есть Swagger для наглядности.
Особенно интересен столбец «Клиенты», где отображаются связи с клиентами по определенному контракту. Это важно, поскольку сервис-поставщик может видеть, кто является клиентом по определенному контракту. Эти связи, хранятся в манифесте приложения, они влияют на проверку контракта и его обратную совместимость при деплое.
Если, к примеру, у контракта есть клиент, если делаются обратно несовместимые изменения, то такой фокус не пройдет. На этапе CI инструменты PaaS валидируют изменения контрактов и не допускают merge ветки в мастер с обратно несовместимыми изменениями.
Мой коллега Никита дал более подробный обзор работы с контрактами в своей статье.
Если у контракта еще нет клиентов, то владелец контракта может провести любые изменения... пока он не получит своих первых клиентов, дальше за таким провайдером будет глаз да глаз!
Здесь можно смотреть, кто уже пользуется контрактами, а кто нет по всему PaaS.
Зависимости
Мы рассмотрели, от кого зависим мы в предыдущей вкладке, а что насчет того, от кого зависит наш сервис?

Здесь мы можем оценить наши зависимости, и не только в виде других сервисов, но и инфраструктурных компонентов, таких как базы данных, очереди и другие.
Отметим, что мы также можем видеть предупреждение о том, что контракты устарели, и сервису требуется обновление. Все это выполняется с использованием утилиты sbm-cli, о которой мы писали ранее.
При щелчке по предупреждающему знаку мы быстро можем увидеть, какие контракты устарели, а также моментально перейти к их описанию в GitLab. Это позволяет нам оперативно реагировать и поддерживать наши контракты в актуальном состоянии.

Staging деплои
Я не люблю тратить время на бесконечные поиски нужного пайплайна в GitLab, перебирать десятки джоб и погружаться в запутанную информацию... всё это так утомительно.
Работа над задачей в Git сопряжена с рядом сложностей:
В репозитории параллельно ведётся разработка сразу по нескольким веткам: по разным сервисам и фичам.
Отслеживать, какая из этих веток сейчас задеплоена в какое из окружений Kubernetes — крайне трудозатратный мануальный поиск.
Часть веток со временем «замораживаются» и перестают быть актуальными.
Мы взяли данные о ветках разработки из Git, CI/CD пайплайнов из GitLab и информацию о деплоях из Kubernetes. И предоставили всё это в одном окне с возможностью мгновенно увидеть статус любой ветки. При этом отображаются только активные ветки.

Получается вот такая консолидации контекста разработки:
Сама задача (MR или Branch) с ссылкой в Jira.
Данные из Kubernetes, включая namespace в стейджинге.
Информацию из GitLab с отображением текущего статуса выполнения деплоя. В этом интерфейсе можно перейти к ретраю или остановке деплоя, а также провалиться к нужному пайплайну в GitLab. Быстрый доступ к MR также всегда под рукой. Кроме того, мы внедрили удобную функцию, предупреждающую о «новых коммитах, которые ещё не были задеплоены», чтобы было видно, что есть изменения в коде, которые еще не были задеплоены и на это нужно обратить внимание.
Информация о времени последнего деплоя и времени жизни неймспейса.
По каждому неймспейсу можем получить детали, такие как: деплойменты неймспейа и сетевую доступность сервиса (svc, ingress)

Теперь мы получаем данные из Kubernetes, в частности, информацию о деплойментах и их адресах.
Но как насчет подов? Какие у нас поды в данный момент запущены, и каковы их статусы?
Я бы пошел в kubectl и спросил… Но! Подожди.
У нас и это есть:

Мы уже обладаем многими данными, чтобы понять, как прошел деплой. Однако, если все еще хочется проверить что-то вручную или подключить к БД, например, у нас уже подготовлены команды — просто копируй и вставляй

Список деплоев
Жизнь сервиса — это постоянное движение, новые фичи, исправление ошибок, постоянные изменения, и конечно же, регулярные выкатывания в продакшн.
Эта страница предоставляет полный список деплоев, позволяя нам узнать, когда происходили последние выкатки. Здесь мы можем быстро перейти к релизному тегу, определить коммит, с которого сделан релиз, моментально перейти к соответствующей джобе в GitLab и даже изучить pipeline релиза. Также здесь отображается точное время деплоя.

Эта информация полезна, особенно для NOC-инженеров. Когда объявляется фича-фриз или возникает инцидент и релизы временно приостанавливаются, эта страница становится незаменимой. Она помогает выявить любые попытки обойти ограничения, так что даже самые хитрые айтишники не останутся незамеченными.
Важный инструмент для поддержания порядка и безопасности в разработке. Настоятельно рекомендую внедрить и использовать!
Нагрузочное тестирование
В СберМаркете каждый сервис готовится к высокому сезону в конце календарного года. Об этом недавно записали подкаст на HighLoad++ наши tech-менеджеры. Одним из важных этапов подготовки является нагрузочное тестирование (НТ).
Для НТ мы используем k6 в качестве бэкенда. Это позволяет проводить тестирование в отдельном поде, в неймспейсе сервиса.
Управление всем процессом тестирования реализовано через UI в Хугине. Здесь можно сразу запускать тесты или запланировать запуск на нужное время.
Особое внимание уделяется тому, что НТ может проводиться не только в стейджинге, но и на продакшен-окружениях. Это позволяет выявлять и решать потенциальные проблемы еще на этапе разработки, обеспечивая стабильную работу сервисов в период пиковой нагрузки.
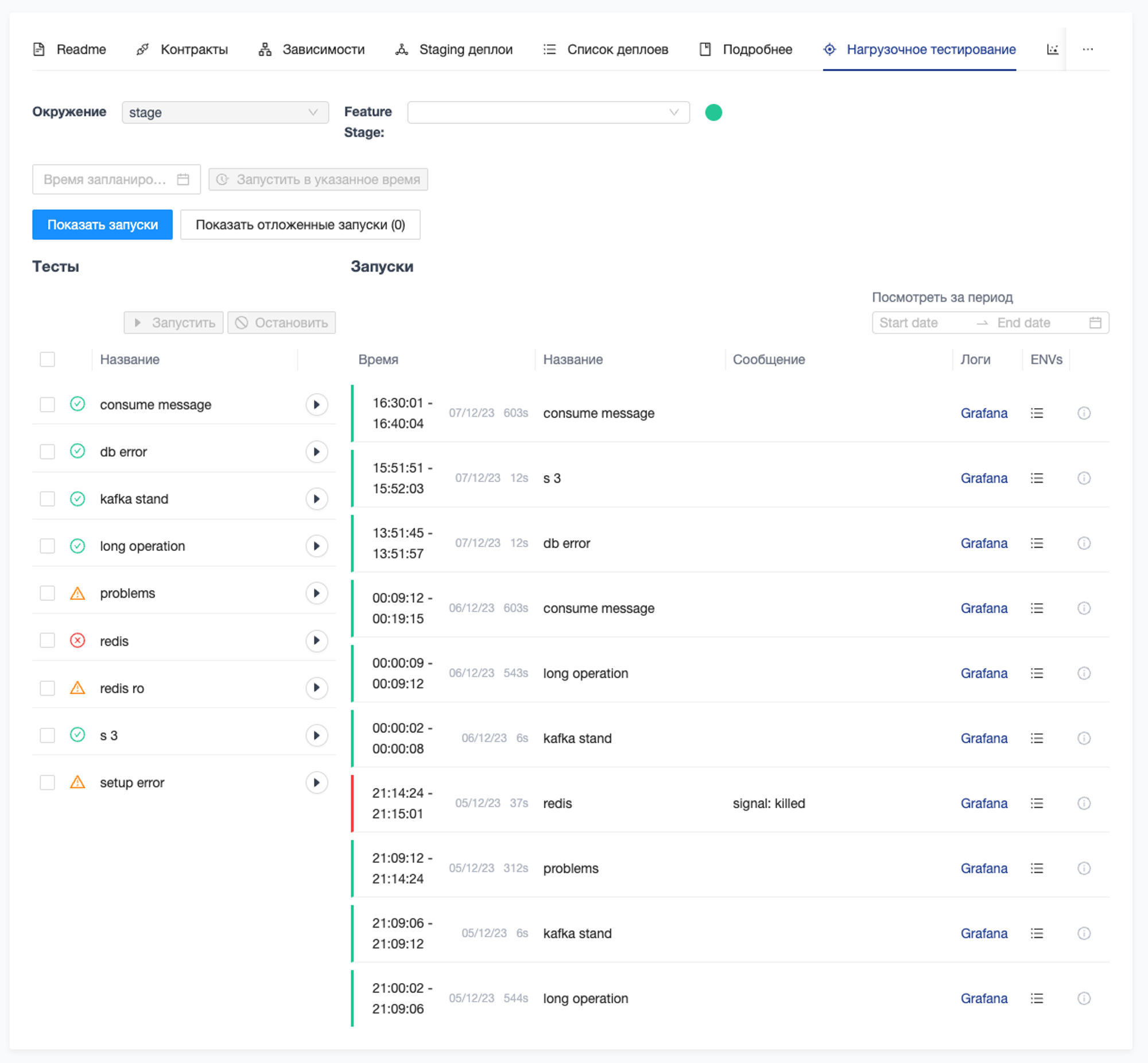
Помимо запуска, мы также можем в режиме реального времени мониторить результаты НТ — насколько успешными они получаются или возникают ли ошибки. Эти метрики позволяют оперативно анализировать ситуацию и принимать необходимые меры по оптимизации сервисов.
Поскольку эта статья носит обзорный характер возможностей Хугин, мы не углубляемся в тонкости реализации НТ. Но если вы заинтересованы в более детальном погружении в эту тему — пишите комментарии, и мы обязательно рассмотрим её в следующих публикациях!
Scoring. Улучшения через метрики
Система скоринга — инструмент помощи разработчикам, для поддержания качества своих сервисов. Она анализирует сервисы по различным параметрам качества и выдаёт четкие рекомендации по улучшению кода, оптимизации архитектуры, повышению надежности.
Благодаря скорингу можно быстро узнать об уязвимых версиях библиотек, качестве и количестве покрытия кода тестами, эффективности используемых ресурсов и т.д. Вся эта информация — ни что иное, как полезные подсказки по развитию сервиса.
Используя эти данные, разработчики повышают качество своих сервисов. А значит, растёт их стабильность и надёжность.

Метрики, используемые при оценке:
Код
Покрытие тестами: Оценивает, насколько код покрыт тестами, обеспечивая высокое качество кодовой базы.
Использование директив nolint: Анализирует применение директив nolint для исключения ложных срабатываний линтера.
-
Версии библиотек: Проверяет актуальность используемых библиотек и зависимостей в проекте.
Инфраструктура
Утилизация RAM и CPU: Анализирует эффективное использование оперативной памяти и процессора в инфраструктуре.
Kafka
Соотношение консьюмеров и партиций: Оценивает, насколько равномерно распределены консьюмеры по партициям в Kafka.
База данных
Использование кэша: Проверяет эффективность использования кэша для оптимизации доступа к данным.
Утилизация соединений: Анализирует эффективность использования соединений к базе данных.
Среднее потребление CPU: Измеряет средний уровень потребления процессора базой данных.
Зависшие транзакции: Выявляет наличие транзакций, которые длительное время находятся в ожидании.
Долгие транзакции: Оценивает, насколько быстро завершаются транзакции в базе данных.
Распухание таблиц БД: Анализирует изменения размеров таблиц в базе данных.
Безопасность
Наличие секретов в репозитории: Проверяет, отсутствуют ли секреты и конфиденциальная информация в репозитории.
Уязвимости в библиотеках: Анализирует используемые библиотеки на предмет известных уязвимостей.
Уязвимости в репозиториях, уязвимости найденные SAST
Качество обслуживания
Наличие настроенного LivenessProbe: Проверяет, насколько корректно настроены LivenessProbe в приложении.
Количество запусков нагрузочного тестирования: Оценивает частоту проведения нагрузочного тестирования в течение последних 4 недель.
Соблюдение правил SLO: Проверяет соответствие сервиса установленным правилам Service Level Objectives.
Это не весь список метрик, но большая его часть. Если команда обнаружит проблему, она может найти ее на своей странице скоринга. Если оценка не является самой высокой, то система подсказывает как ее улучшить и, после внесения изменений, пользователь может запросить пересчет метрики через Хугин.
Система обеспечивает выявление потенциальных недостатков в функционировании сервиса, что существенно снижает вероятность возникновения инцидентов и повышает уровень ответственности разработчиков за качество своего продукта.
Карта сервисов всея PaaS
Хугин, наш надежный проводник по миру сервисов, предоставляет нам визуальное отображение сложных взаимосвязей и структуры PaaS-платформы. Если тебе нужно понять физическую карту микросервисов, Хугин может помочь.
Вот как выглядит интерактивная карта:

Карта позволяет приближаться и рассматривать связи, а также обеспечивает поиск. Если ты ищешь конкретный сервис, просто введи его название, и карта автоматически сфокусируется на нем, подсвечивая его связи:

На карте мы отображаем: PaaS сервисы и Gateway.
Цвета сервисов на карте отражают их здоровье:
Зеленый — полностью здоров.
Желтый — чуть приболел (испытывает небольшие сложности при обработке запросов, но еще поддерживает функциональность).
Красные — требуется оперативное вмешательство.
Серый — цвет по умолчанию (алертов нет).
Мы отображаем связи между микросервисами и API шлюзами (gateways). Каждый сервис имеет свою карточку с важными метриками и алертами.

Если мы рассмотрим API Gateway, то увидим информацию об endpoints, выставленных на нем.

Карта сервисов — это не только инструмент визуализации, но и способ оперативно получить всю ключевую информацию о сервисах и их взаимосвязях.
Журнал событий платформы
Журнал событий платформы собирает в хронологическом порядке информацию о ключевых изменениях в системе: сбоях сервисов, аномалиях, обновлениях конфигураций, релизах кода.
Таким образом, когда возникает инцидент, журнал становится главным источником для первоначальной диагностики.
Анализируя последовательность событий, мы можем быстро определить, какое действие или изменение предшествовало проблеме — скорее всего это и стало пусковым фактором. Например, недавний деплой какого-то сервиса или поступивший по нему алерт мониторинга. Благодаря этому мы оперативно реагируем на инциденты и разбираемся в причинах.
Журнал событий — это наш инструмент для быстрого выявления и анализа возможных проблем, обеспечивая стабильность и бесперебойную работу платформы.
С какими сущностями мы работаем?
сработка алертов;
деплой (запуск, остановка, ошибка);
kubernetes события;
переключение фича-флагов;
запуск и остановка нагрузочного теста;
инциденты.
Алерты
Журнал фиксирует моменты, когда какой-либо из наших мониторинговых инструментов обнаруживает аномалию или превышение порогов.
Записи сработки алертов позволяют оперативно реагировать на потенциальные проблемы, предостерегая нас от возможных инцидентов.
Мы анализируем детали алерта, проводим диагностику и предпринимаем необходимые меры для восстановления нормального состояния.
Деплой (запуск, остановка, ошибка)
Этот раздел содержит информацию о каждом деплое нашего сервиса.
Записи о запусках, остановках и возможных ошибках позволяют отслеживать изменения в приложении. Мы фиксируем успешные деплои, чтобы отметить успешные релизы, а также регистрируем сбои, чтобы оперативно принимать меры по их устранению.
Этот журнал поддерживает прозрачность процесса развертывания и позволяет быстро реагировать на непредвиденные ситуации.
Kubernetes
Этот раздел отражает события, связанные с нашими кластерами Kubernetes.
Здесь мы фиксируем изменения в конфигурации, важные моменты в жизненном цикле подов и сервисов.
Записи в этом разделе помогают нам отслеживать, какие ресурсы используются, а также оперативно реагировать на события, влияющие на стабильность и производительность приложения.
Переключение фича-флагов
Этот раздел содержит информацию о включении и выключении фича-флагов в наших сервисах.
Мы фиксируем моменты изменения состояния фича-флагов, чтобы иметь четкое представление о внесенных изменениях.
Эта информация важна для контроля за внедрением новых функциональностей, а также для обеспечения возможности быстрого возвращения к предыдущему состоянию в случае необходимости.
Запуск и остановка нагрузочного теста
Этот раздел журнала событий фиксирует моменты запуска и остановки нагрузочных тестов наших сервисов.
Записи об этих событиях предоставляют нам важную информацию о поведении приложения под нагрузкой, его производительности и устойчивости.
Мы можем отслеживать результаты тестов, а также реагировать на любые проблемы, выявленные в процессе тестирования. Этот раздел позволяет нам проводить детальный анализ влияния изменений на производительность приложения и обеспечивает контроль за его способностью обработки высоких нагрузок.

Мы постоянно наращиваем число событий, которые отслеживает журнал - это деплои, инциденты, изменения конфигураций.
В перспективе появится возможность визуализировать хронологию всех этих событий на графиках Grafana. Это позволит проводить удобный анализ изменений и оперативно реагировать на возможные инциденты.
Статусы сервисов
Забота о здоровье сервисов в PaaS — неотъемлемая часть обеспечения бесперебойной работы бизнеса.
Ценность Страницы «Статусы сервисов»:
Быстрый обзор: Мы предоставляем наглядный обзор здоровья каждого сервиса в одном месте. Это позволяет оперативно оценивать текущую обстановку и реагировать на потенциальные проблемы.
Реальное время: Статусы обновляются в реальном времени, что позволяет моментально получать актуальную информацию о работе сервисов. Это дает возможность оперативно выявлять и решать проблемы.
Простота анализа: Предоставляем доступ к ключевым метрикам здоровья сервисов в понятном и структурированном виде. Это упрощает анализ и понимание текущего состояния каждого сервиса.
Оповещения и тревоги: Система предупреждений и тревог моментально реагирует на изменения статуса сервисов. Это обеспечивает немедленное уведомление и возможность оперативного вмешательства.

Золотые Метрики для каждого сервиса:
Error Rate (Уровень Ошибок): Показывает процент ошибочных запросов. Наблюдение за этой метрикой помогает выявлять и решать проблемы в работе сервиса, уменьшая влияние ошибок на пользователей.
Latency (Задержка): Измеряет время, которое требуется сервису для обработки запросов. Отслеживание задержек позволяет поддерживать высокую производительность и предупреждать возможные сбои.
Uptime (Время Безотказной Работы): Отображает процент времени, в течение которого сервис был доступен. Это важная метрика для обеспечения непрерывной работы и управления качеством предоставляемых услуг.
RPS (Запросы в Секунду): Показывает количество запросов, обрабатываемых сервисом в секунду. Наблюдение за этой метрикой помогает предварительно выявлять возможные узкие места в работе сервиса и оптимизировать его производительность.
Страница «Статусы сервисов» становится центральным местом для визуализации и анализа работы каждого сервиса, обеспечивая команде мгновенный доступ к ключевым показателям и ускоряя процессы принятия решений.
Конструктор Стендов
Разработка новой фичи в условиях микросервисной архитектуры имеет свои сложности. Я могу внести нужные изменения в код своего отдельного сервиса и протестировать этот код без проблем. Однако настоящий вызов начинается, когда необходимо проверить взаимодействие изменённого сервиса с соседними сервисами архитектуры.
Во-первых, изменённый сервис должен общаться с нужной «фича-веткой» сервиса, а не с его основной версией в master-ветке. Это усложняет конфигурацию и требует больше усилий по настройке.
Во-вторых, реальные задачи зачастую требуют проверить слаженную работу сразу нескольких (5 и более) изменённых веток разных сервисов.
Ручная настройка такой конфигурации из множества нужных версий взаимозависимых сервисов занимает массу времени. Именно для автоматизации этого процесса и был разработан Конструктор стендов.

Сначала мы указываем первый сервис и выбираем ветку кода в нём, с которой будет происходить интеграция. Далее определяем прямые зависимости этого сервиса от других в архитектуре и выбираем нужные целевые ветки кода этих зависимых сервисов. По аналогии задаём целевые ветки и для зависимостей второго уровня. И так далее по всей цепочке сервисов, участвующих в задаче.
Как только все сервисы и их версии определены, достаточно нажать кнопку «Деплой». Конструктор полностью автоматически разворачивает и настраивает тестовый стенд из выбранных версий сервисов. Это экономит массу усилий разработчиков по ручной настройке множества зависимостей между сервисами. Весь процесс запускается один раз по нажатию одной кнопки.
Основные функции:
Создание связок сервисов: Легкий выбор необходимых сервисов, веток/MR’ов и быстрый запуск стенда в несколько кликов.
Автоматическое подтягивание переменных: Конструктор автоматически внедряет синхронные и асинхронные (Kafka) переменные, обеспечивая удобную настройку связей между сервисами. Пользователю (разработчику, тестировщику, и др.) не требуется беспокоиться о деталях, но, при необходимости, есть возможность вручную указать нужные переменные.
Отслеживание статусов: Мгновенный доступ к информации о ходе выполнения GitLab-пайплайнов и текущем состоянии деплоементов в Kubernetes. Вся необходимая информация о статусах джоб и деплоев - все в одном месте, без необходимости переключения между разными платформами.
Гибкое управление: Простое передеплоение всего стенда или отдельных его элементов, гибкое управление временем жизни стенда, продление или освобождение ресурсов по мере необходимости.

Какие выгоды приносит Конструктор стендов?
Эффективность: Создание стендов теперь занимает минимум времени. Разработчики и тестировщики могут полностью сосредоточиться на своих задачах, минуя утомительные этапы рутины.
Конфигурация по требованию: Позволяет формировать стенды в соответствии с конкретными требованиями. Процесс настройки окружений и переменных становится легким и гибким.
Самообслуживание: Каждый участник команды может создавать стенды при необходимости, без лишней административной нагрузки. Это поощряет самообслуживание и ускоряет процесс разработки и тестирования.
Надежность и Повторяемость: Сохранение и повторное использование созданных стендов обеспечивают надежность тестирования и разработки, уменьшая вероятность ошибок в интеграции.
Быстрые Изменения и Обновления: Позволяет мгновенно внести изменения в существующие стенды. Если команда выпустила новый код или внесла изменения, их легко и быстро интегрировать в текущий стенд. Это дает возможность оперативно тестировать изменения в реальных условиях до внедрения в продакшн.
Теперь, благодаря Конструктору стендов, создание и настройка стендов становятся удивительно простыми и быстрыми процессами, позволяя команде эффективнее использовать свое время и фокусироваться на критически важных задачах.
В ближайшем будущем мы планируем опубликовать отдельную статью, где мой коллега Рома подробно расскажет о том, как работает одна из наших наиболее востребованных функций - "Конструктор Стендов".
Конструктор играет ключевую роль в обеспечении гибкости, оперативности и эффективности процессов разработки и тестирования микросервисов, что делает ее неотъемлемой частью нашей платформы.
Kafka топики
В СберМаркет мы придаём особое значение Kafka — это ключевой элемент нашей инфраструктуры. Наш выбор в пользу Kafka обусловлен его высокой производительностью, отказоустойчивостью и эффективностью передачи сообщений между сервисами.
Каждый наш сервис декларирует топики, что создает прозрачную систему обмена данными. Однако возникали вопросы: где посмотреть список всех топиков, и как узнать, кто в какой пишет и кто из какого читает? Ранее у нас не было подходящего инструмента для решения этих вопросов.
Теперь у нас есть страница, предоставляющая полную информацию. Мы отслеживаем все топики и определяем, какие сервисы пишут в определенный топик, а какие извлекают из него данные. Эта страница стала важной частью нашей инфраструктуры, обеспечивая прозрачность и эффективность в управлении данными.

Особенности инструмента:
Автоматическая инвентаризация: Инструмент собирает информацию о топиках автоматически из инфраманифеста сервиса, освобождая команду от рутинных процессов.
Поиск и фильтрация: Интерфейс инструмента предоставляет возможность легко находить и фильтровать топики по различным параметрам, упрощая работу с обширным списком.
Визуализация взаимосвязей: Мы предоставляем возможность не только изучать каждый топик отдельно, но и просматривать взаимосвязи между сервисами и топиками, обеспечивая более глубокое понимание обмена сообщениями в системе.

Визуализация взаимосвязей между сервисами и Kafka-топиками
В стремлении к совершенству в управлении нашими сервисами и данными, мы разработали инструмент визуализации, предназначенный специально для отображения связей между сервисами и Kafka-топиками. Этот инструмент не только улучшает понимание взаимодействия между сервисами и топиками, но и предоставляет более глубокий взгляд на потоки данных в нашей платформе.
Как это работает?
Когда речь идет о визуализации связей, мы стремимся предоставить возможность легкого и наглядного представления о том, какие сервисы взаимодействуют с какими Kafka-топиками, а также какие Kafka-топики взаимодействуют с какими сервисами. Давайте подробно разберем, как это происходит:
-
Выбор сервиса:
Выбираем конкретный сервис, который нас интересует.
-
Определение направления потока данных:
Выбираем направление потока данных: хотим ли мы увидеть топики, в которые пишет выбранный сервис (producer), топики, из которых читает (consumer), или, возможно, оба варианта одновременно?
-
Построение связей:
Динамически строятся связи с учетом направлений передачи сообщений, что делает понимание того, кто куда пишет и откуда читает, наглядным и удобным.
-
Интерактивный анализ топиков:
Интерфейс инструмента предоставляет возможность выбирать конкретные топики для изучения, например, выявляя, кто в них пишет и кто из них читает.

Почему это важно?
-
Прозрачность данных:
Инструмент обеспечивает команду легким и точным пониманием, как данные передаются между сервисами через Kafka.
-
Оптимизация потоков данных:
Визуальное представление взаимодействия сервисов с конкретными топиками позволяет выявлять возможности для оптимизации и улучшения производительности.
-
Анализ зависимостей:
Понимание того, от каких топиков зависит каждый сервис, и наоборот, позволяет эффективно управлять зависимостями в системе.
Итоги: что дает Хугин
Изначально перед нами стояла амбициозная задача — создать собственную PaaS, интегрированную с нашими системами. И это удалось воплотить в решении Хугин.
Хугин позволяет собирать и структурировать метаинформацию о каждом сервисе, предоставляя различные способы визуализации.
Реализованы механизмы для отслеживания и управления связями между сервисами в единой среде.
Это возможности по нагрузочному тестированию, помощь в расследовании инцидентов, а также инструменты «поверхностного» мониторинга.
Хугин — это не просто набор утилит, а комплексный подход к разработке и эксплуатации микросервисов. Мы формируем интегрированную среду, которая ускоряет процессы и повышает надёжность на всех этапах жизненного цикла.
Есть опыт или инструменты, которые ты успешно используешь, но у нас их нет? Дай знать в комментариях.
Есть интересная идея или вопрос? Пиши, и мы расскажем подробнее. Твой запрос может стать следующей темой для статьи! Good Luck!
Tech-команда СберМаркета ведет соцсети с новостями и анонсами. Если хочешь узнать, что под капотом высоконагруженного e-commerce, следи за нами в Telegram и на YouTube. А также слушай подкаст «Для tech и этих» от наших it-менеджеров.