Переход к микросервисам помогает многим компаниям решать проблемы кастомизации и легче масштабироваться. В итоге это может стать важным шагом для создания более конкурентоспособного продукта.
В чем же основная проблема монолитов? При монолитной архитектуре мы создаем единое приложение, в котором все компоненты интегрированы в один блок. Чтобы внести изменений, приходится пересобирать и развертывать его целиком. Это снижает гибкость и оперативность. При таком подходе все части зависят друг от друга, поэтому масштабировать проект сложнее, как и изменять его.
Когда используется микросервисная архитектура, приложение разбивается на отдельные части. Каждый сервис занимается своей задачей, это значит, что вносить изменения можно быстро и точечно.
В этой статье мы расскажем, как приняли решение о переходе и рассмотрим, как к нему подготовиться и успешно осуществить.
Ограничения исходной монолитной архитектуры
Итак, дано: платформа для создания программ лояльности — изначально для разработки мы использовали традиционную модель. Основная проблема была в том, что из-за отсутствия грамотного проектирования и из-за сложной бизнес-логики в приложении, в коде было много ошибок. Постепенно это привело к микроменеджменту и постоянной смене разработчиков бэкенда.
Были и другие сложности:
1. Сложности при внесении изменений
Из-за тесной связанности всех компонентов, даже небольшие изменения в программе лояльности могли вмешаться в бэкенд, вызывая сбои в работе всей платформы.
2. Длительные тестирования
Внесение изменений в монолитные системы требовало длительных и глубоких тестов, это замедляло процесс разработки и внедрения новых функций.
3. Низкая производительность
Оптимизация в монолитных системах — задача непростая, а это влияет на скорость развития продукта в целом.
4. Проблемы кастомизации
Предположим, клиенту нужна возможность добавлять бонусы за рекомендации друзей. Для этого нам пришлось бы внести изменения не только в базу данных рефералов, но и в код для расчета бонусов, а также в пользовательский интерфейс.
Планирование и подготовка к переходу
Прежде чем начать миграцию, мы занялись ее подготовкой — в первую очередь оценили готовность бизнеса и технологического стека. Это включало в себя несколько этапов.
Перед миграцией мы провели детальный анализ требований и сформировали понимание, как они соотносятся с текущими бизнес-процессами. Затем был выбор инструментов (инфраструктура: Docker, Kubernetes, Istio), внешний API и т.д.)
После этого перешли к интеграции с текущим стеком. Убедились, что переход к новой архитектуре не приведет к конфликтам с уже существующим стеком. И, конечно, работали с командой: распланировали обучение и подготовку, которые могли потребоваться для внедрения микросервисов.
Весь процесс подготовки к переходу на микросервисы занял около года.
Domain-Driven Design и микросервисы
В итоге мы остановились на принципах Domain-Driven Design или предметно-ориентированного проектирования.
В Domain-Driven Design, эксперты из определенной предметной области активно участвуют в процессе разработки, ведь они лучше всех понимают, как работают те бизнес-процессы, которые предстоит моделировать.
Важно отметить, что в процессе общения экспертов и разработчиков формируется, так называемый, ubiquitous language. Это значит, что обсуждение происходит в терминах одного и того же, понятного всем языка.ТЗ и код пишутся на нем же.
Кроме использования единого языка DDD включает и другие принципы, как уже отмечали, это использование терминов предметной области в коде, защита независимости предметной области от других областей, технических аспектов и т. д.
У DDD есть много преимуществ. Во-первых, он упрощает взаимодействие между командами. Благодаря применению ubiquitous language, разработчики и команды маркетинга, например, могут использовать общепринятые и понятные всем термины.
Основные понятия в Domain Driven Design — это домен, поддомен и контекст. Домен — это та предметная область, в которой бизнес зарабатывает свои деньги. В нашем случае это создание программ лояльности. Домен делится на поддомены, обособленные логические процессы, которые взаимодействуют между собой на более высоком уровне. Для нашей платформы это — управления бонусами, обработка транзакций, аналитика, взаимодействие с партнерами и т.д.
Доменная модель и ubiquitous language ограничены контекстом, который в Domain-Driven Design называется bounded context. Он ограничивает доменную модель таким образом, чтобы все понятия внутри него были однозначными, и все понимали, о чём идёт речь.
Использование DDD позволило нам сделать бизнес-логику проекта более гибкой и помогло ограничить зоны ответственности команд и приложений.
Процесс миграции
Итак, после подготовки и планирования, мы начали миграцию. Ниже шаги, которые мы предприняли, чтобы разделить платформу на микросервисы с учетом доменных границ и бизнес-логики.
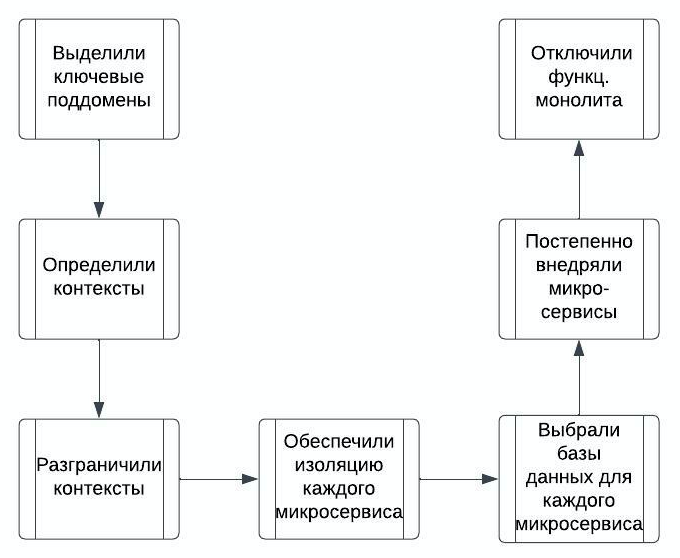
Трудности перехода на мультисервисы
Одним из самых сложных моментов для нас стало само деление на микросервисы, мы понимали, что если это будет сделано неправильно, то обойдется нам достаточно дорого и исправлять это будет сложно. Избежать такой ситуации помогло использование Domain-Driven Design и тот факт, что на подготовку к переходу, мы выделили достаточное время.
Еще один момент, который важно учитывать, это переходный период между полной готовностью микросервисов и доступностью монолита. Важно не отключать функциональность монолита, до того, как все микросервисы начали отлажено работать.
Результаты и преимущества перехода
Несмотря на основательную подготовку, миграция была непростая, а трудности, с которыми мы столкнулись и которые преодолели, достойны отдельной статьи. Теперь же хочется рассказать про результаты. Итак, чего мы добились в итоге:
1. Увеличили гибкость
Теперь можем внедрять изменения быстрее, поскольку каждый микросервис разрабатывается и обновляется отдельно от других.
2. Повысили масштабируемость
Каждый микросервис масштабируется независимо, это дает возможность более эффективно распределять нагрузки, когда возрастают объемы запросов.
3. Упростили обслуживания системы
Во-первых, изолировали проблемы и теперь их можно решать по отдельности. Во-вторых, упростили тестирование. Каждый микросервис тестируем независимо, благодаря этому сам процесс проходит легче и быстрее.
4. Создали и внедрили стандарты разработки
Мы создали подробную документацию для бизнес-аналитиков, разработчиков и DevOps-инженеров. Для этого использовали формат ASCII doc, дополненный диаграммами Plantuml. Так как теперь мы пользуемся подходом "документация как код", документация остается живым артефактом на протяжении всего цикла жизни продукта.
5. Улучшили качество кода
Благодаря тому, что мы задокументировали стандарты, у разработчиков появилось единое понимание, как организовывать файлы, отступы, комментарии, объявления, операторы и прочее. Код стал заметно чище и понятней.
6. Уменьшили текучку кадров
Команды разработчиков получили больше свободы и ответственности одновременно, это хорошо повлияло на мотивацию и на взаимоотношения внутри команд.
Кроме всего прочего, мы ускорили релиз новых фич и повысили CSI (Customer Satisfaction Index).
Выводы
Хочется отметить, что микросервисы не должны являться самоцелью. Они подходят далеко не всем. В нашем случае переход к микросервисной архитектуре был обоснован, так как монолитная архитектура приводила к проблемам. Как мы уже отмечали, в результате всех изменений нам удалось улучшить продукт технически и с точки зрения бизнеса. Мы улучшили качество кода и снизили рост расходов на поддержку платформы. Бонусом получили более мотивированную команду, так как появился четкий задокументированный регламент и более ясное понимание задач.
Комментарии (14)

SpiderEkb
18.12.2023 15:06Не оспариваю и не критикую ваш подход, но, как мне кажется, у вас слишком все упрощено - вот есть монолит (такой огромный-преогромный модулище, который делает все), а вот микросервисы - такие маленькие модульки, каждый из которых вертится в своем контейнере и (условно) считает свою цифирьку.
Но в реальности все намного разнообразнее. Есть т.н. "модульный монолит" (хоть это и оксюморон своего рода) - набор функций (процедур) - модулей, каждая из которых является независимым программным объектом и может быть вызвана из любого другого модуля (программного объекта) как синхронно (в рамках того же процесса (или задания - job на "больших машинах"), так и асинхронно - запускаться отдельным процессом (в отдельном фоновом задании - 100% изолировано от остальных), например функцией spawn. И тут все отличие от привычных вам микросервисов прежде всего в том, что вместо контейнеров тут задания, а для коммуникации используются ABI, а не более затратные (на распаковку-запаковку) JSON'ы. Хотя и там есть варианты - например, использование бинарных дейтаграмм. И да. Любой модуль может разрабатываться, тестироваться и внедряться независимо от всех остальных (на каких-то этапах он может быть временно заменен "заглушкой"). И в любой модуль можно вносить любые изменения логики независимо от всех остальных. Главное - сохранять контракт модуля (его можно расширить, но не сократить или изменить).
Еще момент - у вас на картинке есть позиция "база данных для микросервиса". Как решается ситуация, когда данные в базах разных микросервисов должны дублироваться? Лишние затраты ресурсов на синхронизацию и репликацию? Вообще-то достаточно нетривиальная задача...

sshikov
18.12.2023 15:06вот есть монолит (такой огромный-преогромный модулище, который делает все), а вот микросервисы - такие маленькие модульки, каждый из которых вертится в своем контейнере и (условно) считает свою цифирьку.
А вы лучше вспомните - вы хоть раз видели, чтобы микросервисы рекламировали как-то иначе? По-моему, такого не бывает - всегда вот такое же преувеличение, всегда картинки, очень далекие от реальности. А в реальности я таких монолитов не вижу скажем с начала 21 века, если не раньше.
Ну и в итоге, читаю я все вот это вот в сотый наверное раз, и думаю: нет, автор, так ты слона не продашь.

ArkadiyShuvaev
18.12.2023 15:06А поделитесь, пожалуйста, ссылкой, как реализовывать "модульный монолит".
То, что я видел, выглядело как-то не очень. Там были какие-то наколеночные решения по отслеживанию зависимостей одного модуля от другого. Выглядело как винигрет, загружаемый в ту же память.
SpiderEkb
18.12.2023 15:06Выглядело как винигрет, загружаемый в ту же память.
Что имеется ввиду под "той же памятью"?
Если говорить конкретно о нас, то это банк. Еще конкретнее - АБС, работающая на центральном сервере (нескольких серверах) банка. Сами понимаете, что никаких облаков тут нет и не будет. Все локально и сильно изолировано от внешнего мира.
Наша система работает на ... ну не мейнфрейм еще, но уже и не Win/*nix - middleware сервера. Платформа IBM i - тут любая программа работает в рамках своего изолированного задания (можно считать его неким аналогом контейнера) - job - со своей изолированной памятью, своим joblog. Каждое задание полностью независимо от остальных - падение задания никак не скажется на всем остальном. "Случайно залезть" в память чужого задания не получится никак. Специально получить доступ через shared memory можно, случайно нет. Мы практически не пользуемся shared memory - слишком много заморочек. Есть иные каналы межпроцессной коммуникации - сокеты (обычные, именованные локальные UNIX sockets, socket pairs...), пайпы, очереди (не те что Rabbit или Kafka, а системные - на нашей платформе есть такие объекты как data queue или user queue - быстрые и простые в работе)
Любая программа может вызвать любую программу как синхронно (в рамках своего задания), так и асинхронно - запустив ее в новом фоновом задании, например, через С-шную функцию spawn или системную команду sbmjob (submit job) с указанием имени программы и ее аргументов.
Синхронный вызов будет "в той же памяти", асинхронный - в изолированной памяти другого задания.
Любую процедуру, которая что-то принимает на вход и что-то отдает на выход можно реализовать тремя способами:
Обычная процедура внутри программы
Отдельная программа
Процедура внутри сервисной программы (сервисная программа - аналог динамической библиотеки тут)
Разница будет лишь в описании прототипа внутри вызывающей программы - просто прототип, прототип с ключевым словом extpgm и указанием имени программы, прототип со словом extproc и указанием биндеру (линкеру) имени сервисной программы где находится эта процедура.
2-й и 3-й способы позволяют вынести процедуру "наружу" и дают возможность разрабатывать и модифицировать ее отдельно от всего остального. 3-й вариант предусматривает только синхронные вызовы, 2-й - как синхронные, так и асинхронные (исключительно на усмотрение вызывающего).
Там были какие-то наколеночные решения по отслеживанию зависимостей одного модуля от другого.
Что есть зависимость? В нашем случае зависимость - это имя программного объекта и список его аргументов (и их типов) - контракт. Все.
Ну вот простой пример. У нас у каждого клиента есть такой параметр как "дата последней актуализации клиентских данных" (ДА). И есть таблица этих дат где содержится идентификатор клиента, ДА и время изменения записи. Причем, таблица историческая - каждая процедура актуализации добавляет туда свою запись с указанием ДА и времени добавления. Для этой (как и для остальных таблиц у нас) есть т.н. "модуль внешнего ввода" - любые изменения в таблице делаются только через него и никак иначе - на вход передается образ записи и режим - добавление/изменение/удаление, а вся логика записи в таблицу уже реализована внутри модуля (там все может быть достаточно сложно - какие-то расчетные значения полей, запись в связанные таблицы и т.п.).
Также на эту таблицу есть т.н. "ретривер" - программа, получающая на вход идентификатор клиента и возвращающая ДА, соответствующую записи с последней датой изменения. Этот ретривер вызывается очень много откуда (сам параметр ДА используется достаточно широко).
В процессе оптимизации пришли к выводу, что изменения в таблицу ДА вносятся достаточно редко, зато очень часто - получение текущей ДА. И есть смысл в пару к исторической таблице добавить т.н. "витрину" - таблицу, где на каждого клиента будет всего одна запись - текущая ДА. Тогда не надо будет каждый раз искать в исторической таблице запись с последней датой обновления, достаточно просто прочитать из витрины запись по уникальному индексу.
Для реализации достаточно внести изменения в модуль внешнего ввода - после успешной записи в основную таблицу изменить запись в витрине, и в ретривер - переделать его с поиска в исторической таблице на чтение из витрины. Контракты (интерфейсы) модулей остались неизменными. Т.е. все модули которые вызывают модуль внешнего ввода или ретривер не требуют никаких изменений. Итого, поставка содержит собственно таблицу-витрину, пару индексов к ней, скрипт первоначального заполнения витрины (чтобы она заполнилась текущими значениями в процессе развертывания поставки) и, собственно, новыми версиями двух программных объектов - модуля внешнего ввода и ретривера. Все это начинает работать сразу после развертывания поставки для всех потребителей данных сервисов (строго говоря, нас тут вообще не интересует кто, откуда и когда его вызывает т.к. имя модуля и его интерфейс не меняется, только внутренняя логика). У нас есть заголовочный файл с описанием контракта ретривера:
Dcl-DS t_dsHDA len(512) qualified template; DAT zoned(7:0) inz(0); USID char(4) inz(' '); UNAM char(35) inz(' '); BRNM char(4) inz(' '); BRN char(35) inz(' '); CRD timestamp inz(*loval); MBN char(2) inz(' '); MBND char(35) inz(' '); SQN zoned(3:0) inz(0); End-DS; Dcl-PR getDatInfo extpgm('GETDA1R'); CUS char(6) const; CLC char(3) const; Typ char(3) const; dsHDA likeds(t_dsHDA); dateOnly ind options(*omit: *nopass); Error char(37) options(*nopass); End-PR;который используется его потребителями. При необходимости мы можем его расширять дополнительными параметрами (с модификатором options(*nopass) - необязательный параметр), но не сокращать или изменять уже существующее. Ну и нельзя менять ссылку на программный объект - extpgm('GETDA1R') т.к. это тоже неотъемлемая часть контракта.
Так же мы можем добавить какие-то дополнительные поля в возвращаемую структуру dsHDA т.к. ее размер (512 байт) выбран с запасом и больше суммарной длины полей. Фактически это буфер размером 512 байт в котором в настоящий момент размечено (используется) только первые 151 байт.
Т.о. при необходимости мы можем разметить в этой структуре какие-то новые поля (в рамках общей длины в 512 байт), реализовав их заполнение в новой версии ретривера равно как и добавить какие-то дополнительные *nopass аргументы (с проверкой переданы они или нет реально внутри ретривера). При этом все старые потребители про это ничего не узнают и будут по прежнему пользоваться старым контрактом, а новые смогут использовать уже его расширенную версию.
Собственно, это уже было сделано в последней модификации - до нее контракт выглядел как
Dcl-PR getDatInfo extpgm('GETDA1R'); CUS char(6) const; CLC char(3) const; Typ char(3) const; dsHDA likeds(t_dsHDA); End-PR;Последние два параметра были добавлены при добавлении витрины. Естественно, внутри ретривера делается проверка - переданы нам эти параметры или нет (можно ли их использовать). При этом интеграция со старыми потребителями (использующими старую версию контракта) не нарушилась т.к. новый контракт поддерживает обратную совместимость со старым.
Другой пример. Один из каналов связи с внешним миром на нашем сервере - очередь IBM MQ. Есть некий процесс - движок HMQ, который мониторит появление в очереди новых сообщений. В заголовке каждого сообщения есть поле, указывающее на его тип. Движок определяет тип сообщения, потом по своим настроечным таблицам находит имя модуля, отвечающего за обработку сообщений данного типа и вызывает его (асинхронно) в с передачей ему тела сообщения. Контракт всех обработчиков одинаковый и стабилизированный. Если у нас появляется новый тип сообщения, мы просто пишем новый модуль-обработчик и добавляем его в настроечные таблицы движка HMQ. С этого момент все сообщения данного типа начинают обрабатываться новым модулем.
Т.о. все это не микросервисы в привычном понимании, но и не монолит, каким нас так любят пугать апологеты микросервисов. Это набор модулей с возможность как синхронного, так и асинхронного запуска, каждый из которых может разрабатываться, тестироваться, изменяться и вводиться в эксплуатацию независимо от остальных и которые связаны через ABI или с использованием межпроцессных каналов связи (сокеты-пайпы-очереди).
Вообще, подход сей не нов. Модель акторов была разработана еще в 70-х годах прошлого столетия.
Кстати, до банка, я занимался разработкой Системы Мониторинга Инженерного Оборудования Зданий. И там тоже использовались похожие (в какой-то степени) подходы. Но это совсем другая история :-)

Nurked
18.12.2023 15:06Ребят, не ведитесь. Эта статья написана на ЧатГПТ.
Причём написана всё тем же набором ботов, которые подписаны на одни и те же компании.
Тут просто карму фармят, для того, чтобы потом быстро перепрофилироваться в компанию, и стричь себе рекламу.
@BoomburumАлексей, может пора вводить "Написано ГПТ" и позволять их отфильтровывать? Я вижу всё больше и больше примера попыток фарминга кармы на подобных какашках, которые выдают за статьи.

microuser
18.12.2023 15:06Монолит медленный потому что монолит, а микросервисы быстрые потому что микросервисы. Ничего что взаимодействие in process всегда быстрее чем out of process?

hVostt
18.12.2023 15:06А какой смысл разносить логику по разным (микро)сервисам, если взаимодействие между компонентами является самым узким местом? Т.е. я к тому, что это явный саботаж, не оправдывается никакой догмой.
Что если, это разный бизнес? Акционка, со своей командой разработки. Поиск, тегирование, контент -- другой аспект и другая команда или даже подразделение разработки. Финансовая, маркетинговая логика, клиентский профиль, целевое таргетирование, прокладывание маршрутов и построение расписаний, генерация отчётов и массовые рассылки... и т.д. и т.п. В каждом свои требования и ограничение, где-то повышенные требования ИБ, где-то нужно много вычислительных мощностей, где-то нужно много ОЗУ, где-то нужно быть по-ближе к клиентам (CDN).
Когда начинают о каких-то аспектах рассуждать в вакууме, в отрыве от реальных кейсов, это просто не имеет смысла. Out of process, in process, быстро, медленно... Какую задачу решаем? :) Нет ничего плохого ни в монолитах, ни в МСА, если они применяются уместно под свои задачи.
microuser
18.12.2023 15:06Эти вопросы надо не мне задавать, а автору. Там явно написано что микросервисы быстрее, при этом ни замеров не пояснения нет.
При этом я ни о чем не рассуждал, просто немного "пошутил" над распиляторами монолитов которые на ложных предпосылках начинают что-то там делить сами не знают зачем.

Batalmv
18.12.2023 15:06Мне кажется, что изначальна біла просто проблема с архитектурой. Монолит - просто "форма", которую приняло проблемное приложение
Ну смотрите:
1. Сложности при внесении изменений
Из-за тесной связанности всех компонентов, даже небольшие изменения в программе лояльности могли вмешаться в бэкенд, вызывая сбои в работе всей платформы.
Loose coupling - классический принцип проектирования. Я не уверен, что монолит как-то на это влияет, равно как и микросервисы. Ви одинаково успешно можете построить монолит, которому это присуще, так и "кастрюлю со спагетти" из микросервисов.
2. Длительные тестирования
Внесение изменений в монолитные системы требовало длительных и глубоких тестов, это замедляло процесс разработки и внедрения новых функций.
Прямое следствие предыдущего фактора. Без углубления во всякие теории очевидно, что чем меньше связей между компонентами, тем легче определить те компоненты, на которые ОТСУТСТВУЕТ влияние в результате изменений. А если у вас снова "кастюля спагетти" - шансов нет. Надо тестить все.
И еще ... если вы строите конструктор, т.е. приложение, которое дает большую свободу пользователям - этот фактор почти не победим. Либо вы делаете большую платформу, которая продается клиентам с возможностью кастомизации.
Просто в силу того, что функциональные требования к вашему решению - это требования к Low-code инструменту
3. Низкая производительность
Оптимизация в монолитных системах — задача непростая, а это влияет на скорость развития продукта в целом.
Ну тут как раз можно поспорить. Монолит дает одно преймущество - "дешевые" связи между компонентами. Я б даже сказал максимально дешевые. У вас нет проблем с безопасностью (все внутри). У вас нет проблема с пулами коннекторов. У вас вообще мало с чем проблемы, когда компонента "А" хочет дернуть компоненту "Б".
Другой вопрос, если у вас "кастрюля" и трудно понять, какая из спагетинок вносит весомый негативный вклад в общий response time. Но это все проблемы кастрюли :)
4. Проблемы кастомизации
Предположим, клиенту нужна возможность добавлять бонусы за рекомендации друзей. Для этого нам пришлось бы внести изменения не только в базу данных рефералов, но и в код для расчета бонусов, а также в пользовательский интерфейс.
Ну снова, "кастрюля"
Вы правильно написали. Монолит однозначно прогрывает на этапе сборки и связанных "фич", типа возможности тестить разные версии микросервисов, собирать гибридные варинаты среды (часть у меня крутится локально, часть в "облаке"). Тут да - это однозначное и весомое преимущество микросервисов.
В любом случае, хорошо что у вас получилось!
hVostt
18.12.2023 15:06Так, какой сейчас год? А-а.., 2023-й, год хейта МСА.
Loose coupling - классический принцип проектирования. Я не уверен, что монолит как-то на это влияет, равно как и микросервисы. Ви одинаково успешно можете построить монолит, которому это присуще, так и "кастрюлю со спагетти" из микросервисов.
Loose coupling это принцип проектирования приложения. Является ли приложение монолитом или микросервисом, не имеет значения. Поэтому не в кассу.
Если каждый из микросервисов является обособляемым решением со своим небольшим, но гордым бизнесом, то выражение "кастрюля из спагетти" на это натягивается также плохо, как выражение "свиное корыто, куда свалены все объедки и продукты" на монолит.
Прямое следствие предыдущего фактора. Без углубления во всякие теории очевидно, что чем меньше связей между компонентами, тем легче определить те компоненты, на которые ОТСУТСТВУЕТ влияние в результате изменений. А если у вас снова "кастюля спагетти" - шансов нет. Надо тестить все.
Такие тезисы обычно применимы к случаем совершенно неуместного применения МСА. Т.е. когда бизнес просто порезали на куски, и ни один кусок без других не может функционировать и даже иметь какой-то смысл. А уж строить далеко идущие выводы на основе неудачного опыта, или неудачных примеров -- такое себе.
3 года забивал гвозди микроскопом, и знаете что я вам скажу? Полное фуфло этот ваш микроскоп, не понятно откуда такой хайп был, вернулся к молотку, всё стало хорошо.
По теме, микросервисы (уточняю, уместные и правильные!) действительно сильно проще тестировать. Речь не про юнит-тесты разумеется. А тестировать полностью завершённую самодостаточную логику, автоматизировать тестирование и поддерживать действительно проще. По крайне мой опыт это подтверждает многократно.
Ну тут как раз можно поспорить. Монолит дает одно преймущество - "дешевые" связи между компонентами. Я б даже сказал максимально дешевые. У вас нет проблем с безопасностью (все внутри). У вас нет проблема с пулами коннекторов. У вас вообще мало с чем проблемы, когда компонента "А" хочет дернуть компоненту "Б".
Другой вопрос, если у вас "кастрюля" и трудно понять, какая из спагетинок вносит весомый негативный вклад в общий response time. Но это все проблемы кастрюли :)Нет никакого преимущества, если связи не являются действительно узким горлышком. Что же касается вычислительной ресурсоёмкости, то как раз таки микросервисы здесь сильно выигрывают:
Каждому сервису свои ресурсы, по их потребностям, кому-то больше, кому-то меньше. Для монолита, придётся давать ресурсов под самый жадный компонент, да ещё и конкурировать за ресурс с ним (память, CPU, сеть).
Каждый сервис может быть размещён максимально близко к своему контексту, к своим данным. Например, поисковый компонент может быть размещён вплотную к своим индексным базам и т.д.
Про масштабирование тут итак всё понятно и 100500 раз об этом говорилось. Да-да, песни "вам это не надо, вы не гугл, и монолиты тоже масштабируются" я тоже слышал, и лично проходил через это. Вопрос только в цене и времени, как обычно.
Ну снова, "кастрюля"
Множество пасов про "кастрюлю", это видимо флешбеки от неудачного опыта, на котором возможно и были построены ваши выводы.
Если честно, в какой-то момент для меня слово "монолит" стало синонимом "легаси". Просто потому, что нет проблем собрать все микросервисы как одно приложение с внутрипроцессной коммуникацией, и какой же это монолит? Если оно действительно легко разбирается на части? На самом деле нет конечно, монолит, при всех Loose coupling, обычно ничерта не разбирается, и при всех стараниях, абстракции протекают, связанность местами сильнее чем надо, нельзя писать идеальный код.
Другое дело, зачем разный бизнес и разные задачи пихать в одно приложение, если этого можно не делать? Точно также, а зачем разделять один бизнес на разные куски?
Да, встречал сущий ад, когда чуть ли не каждая таблица БД обслуживалась своим "микросервисом", это смачный плевок в сторону МСА и яркий материал для хейтеров. Ваша "кастрюля". Но зачем так делать?
Выбирайте подходящую и эффективную архитектуру для своих систем. Кто говорит, что правильно это монолит или правильно это МСА -- эти люди просто не имеют ни опыта, ни знаний, либо набили одну шишку и возвели её в абсолют.
Batalmv
18.12.2023 15:06Loose coupling это принцип проектирования приложения. Является ли приложение монолитом или микросервисом, не имеет значения. Поэтому не в кассу.
Так я про это и пишу. Если вы его не придерживаетесь - получаете проблемы при внесении изменений в виде сложно отслеживаемых связей и увеличенного объема тестирования. И также считаю, что это "перпендикулярно" к тому, как собрано приложение: монолитом или отдельными сервисами.
Мы вроде об одном и том же, не?
По теме, микросервисы (уточняю, уместные и правильные!)
Так опять же. Правильный "монолит" или "правильные" микросервисы обладают этим свойством, а именно удобством тестирования. Я о опять не понял, вы "за" или "против" :)
Множество пасов про "кастрюлю", это видимо флешбеки от неудачного опыта, на котором возможно и были построены ваши выводы.
Либо от созерцания всякого legacy :)
Другое дело, зачем разный бизнес и разные задачи пихать в одно приложение, если этого можно не делать? Точно также, а зачем разделять один бизнес на разные куски?
В данном примере автор участвовав в разработке "модуля" лояльности. С точки зрения enterprise архитектуры - это одно, не очень большое приложение. Да, оно может быть интересным, так как с одной стороны в него прилетает много data flow и pipeline'ов для загрузки в свою модель "мира", с другой - надо мгновенный ответ "сикоко можно скинуть" для этой транзакции либо какую "плюшку" можно добавить, а посередине скорее всего конструктор бизнес логики (админка + engine). Делить его на большее число частей ... ну такое. Тут надо уже сидеть и детально смотреть на логику в данном конкретном случае.
Для использования его для разных бизнесов проще им внутри логические группы нарезать :)
Нет никакого преимущества, если связи не являются действительно узким горлышком. Что же касается вычислительной ресурсоёмкости, то как раз таки микросервисы здесь сильно выигрывают:
Ну смотрите. Во-первых, сервисам ресурсы не дают, они сами берут :) Т.е. уже давно, если говорить о CPU либо дисках/сети, доступные ресурсы шарятся на изи между сотнями потребителей. С памятью сложнее, так как обычно "сервисы" ее не любят отдавать назад. Т.е. если взяли, то за нее "держаться".
Задача масштабирования сводится к тому, чтобы если у нас растет нагрузка - надо поднять больше нод. У тут без разницы, даже с монолитом проще.
Про размещение "вблизи" я вообще не понял. Сорян, но это за гранью моего понимания. Если вы держите приложение на одном сервере (не важно, виртуальный, либо вообще нода для контейнеров), а базу на другом - между ними все равно сеть, топологию которой вы строите сами.
------------
Простой вопрос. У вас 4 виртуалки, по 4 ядра в каждой. Какая разница, монолит или микросервисы. Ядра ж отдаются под рабочие threads, а их столько сколько нагрузки. Н разве что в микросервисах их будет больше, так как там где монолит "дернет" метод класса в том же адресном пространстве Java-машины, тамодин микросервис дернет другой :)
-----------------------------
В принципе, мне подход автора более понятен с DDD, который позволяет взглянуть на систему с "правильной" точки зрения и минимизировать связи, чем абстрактные утверждения "микросервисы" лучше масштабируются :)
Сорян, если что
SpiderEkb
18.12.2023 15:06Вы знаете, у меня порой складывается впечатление, что в подобных статьях речь не идет о всей системе в целом. Только об ее одном каком-то кусочке. И там да - был "монолит" (в нашем понимании - один программный модуль который реализовывал всю бизнес-логику процесса), а его взяли и попилили еще на более мелкие кусочки.
Но при этом вся система целиком и так уже не является монолитом (ну я не могу себе представить - не хватает воображения - сколь бы то ни было большую монолитную систему).
Дробить кусок системы на еще более мелкие куски (что неизбежно повлечет за собой увеличение накладных расходов на коммуникацию между этими кусками, а при большой плотности вызовов это может стать заметным) - не знаю. В каждом конкретном случае нужно этот вопрос рассматривать отдельно.
Рассуждать о ядрах, потоках можно лишь в том случае, когда на вашей физической (!!!) машине работает одно ваше приложение. А когда там кроме вашего процесса крутится еще 1000 - все эти рассуждения теряют какой-либо смысл - система сама по своему усмотрению, руководствуясь общей картиной (и, возможно, какими-то настройками приоритетов задач, буде таковые доступны), распределит вычислительные ресурсы между задачами. И сделает это наилучшим образом. И вас при этом не спросит.
vagon333
У каждого свой опыт. Поделюсь своим (не претендую, просто делюсь):
- выносить в микросервисы часто-меняющийся, ресурсоемкий или сложный функционал.
- не плодить микросервисный клубок связей там, где достаточен монолит с внутренними зависимостями, проверяемыми на уровне компиляции.
Ограничения монолита 1-4 словно под копирку.
Все 4 ограничения при грамотной архитектуре весьма спорны, включая производительность.
Насчет архитектурных решений:
- Модульные решения.
С 90х практикую для более-менее крупных проектов, когда deploy не обязательно всем пакетом модулей.
Кстати, тоже финтех: банки (кредитование) и страхование (урегулирование страховых случаев).
- Последнее десятилетие практирую монолит с использованием микросервисов.
Веб-приложение тыркает микросервисы. Прекрасно уживаются вместе.
SpiderEkb
Именно так у нас (например) работает АБС банка. Десятки тысяч независимых модулей, каждый может вызываться из другого модуля как синхронно, так и асинхронно. Но все работают с единой БД (т.е. всегда актуальные данные, не требующие отдельной репликации и синхронизации).