Привет, Хабр! Меня зовут Никита, я backend-разработчик команды клиентских сервисов. В Selectel мы строим и поддерживаем IT-инфраструктуру для компаний, которые развивают свои цифровые продукты. В нашем департаменте около 20 приложений, большая часть из которых работает на Flask и Gunicorn. Чтобы отслеживать их производительность, мы мониторим параметры системы с помощью Prometheus.
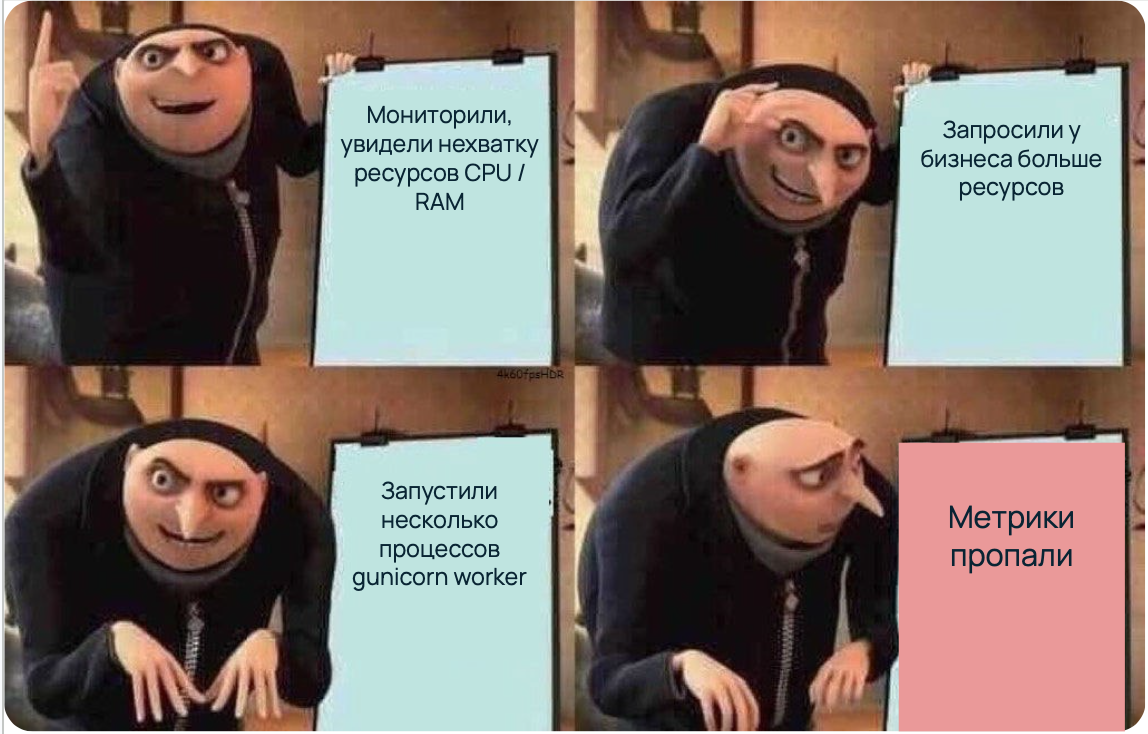
С развитием бизнеса нагрузка на приложения возрастает, один из способов масштабировать его под большее количество запросов — запустить Gunicorn-сервер с несколькими worker-процессами в мультипроцессном режиме. Однако при таком подходе клиент Prometheus не выводит нужные нам метрики CPU и RAM. В статье расскажу, как мы решили эту проблему, сохранив метрики и организовав мониторинг в мультипроцессном режиме.
Используйте навигацию, чтобы выбрать интересующий блок:
→ Для чего нужен мониторинг
→ Как работает мониторинг при помощи Prometheus
→ Как мы организовали мониторинг в мультипроцессном режиме
→ Заключение
Для чего нужен мониторинг
Представьте: вы backend-разработчик. Вам нужно регулярно контролировать состояние приложения: например, были ли в системе проблемы после нового релиза. Чтобы отвечать на подобные вопросы за пару секунд, не изучая сотни строк логов, необходимо настроить мониторинг.
Конечно, вы можете организовать базовый доступ к логам приложения. Однако вручную выискивать ошибки и считать количество определенных сообщений — неудобно. Поэтому мы используем наглядные графики с историческими данными, обновляющиеся в режиме реального времени.

Пример графика Grafana.
Метрики CPU и RAM
При мониторинге веб-приложений чаще всего отслеживают количество поступающих HTTP-запросов, длительность их обработки, а также расход ресурсов процессора (CPU) и оперативной памяти (RAM). Последние две — это системные метрики, с их помощью мы можем:
- следить за потреблением ресурсов в час пик,
- контролировать поведение приложения после релиза,
- увеличивать выделенные ресурсы при возрастании нагрузки,
- освобождать ресурсы при необходимости.
Для мониторинга мы используем библиотеку prometheus-flask-exporter. Если прочитать ее документацию, в самом конце можно найти врезку, что в мультипроцессном режиме Prometheus не будет собирать метрики CPU и RAM.
Please also note, that the Prometheus client library does not collect process level metrics, like memory, CPU and Python GC stats when multiprocessing is enabled. See the prometheus_flask_exporter#18 issue for some more context and details.
Текст из документации.
Может возникнуть ситуация, когда с помощью мониторинга вы понимаете, что текущих ресурсов в приложении не хватает. Вы заказываете более мощную виртуальную машину и запускаете веб-сервер в несколько процессов. В результате ваши CPU- и RAM-метрики, с помощью которых вы узнали о проблеме, пропадают.
У этой проблемы есть четыре пути решения.
- Смириться с отсутствием метрик CPU и RAM. Этот вариант для нас нежелательный, поскольку мы активно используем их показания.
- Разработать с нуля библиотеку или найти другой вариант. Разработка займет много времени и ресурсов компании, а подходящих альтернатив для связки мониторинга Flask при помощи Prometheus еще не нашли.
- Использовать внешний мониторинг с хост-машины или Kubernetes.Иногда это приемлемо, но есть свои тонкости — о них будет ниже.
- Доработать текущее решение. На этом варианте мы и остановились.
В третьем варианте есть несколько минусов. Во-первых, управление хост-машинами и их контроль — это чужая зона ответственности в продуктах. Во-вторых, не все метрики можем собрать с хост-машины. Так, статистика Python Garbage Collector находится только внутри приложения. Этот вариант нам не подошел: мы стремимся к более общему и гибкому решению за счет внутренних ресурсов нашей команды.
Как работает мониторинг при помощи Prometheus
Мы выбрали четвертый путь решения проблемы и взялись за доработку Prometheus — текущей системы мониторинга. Для начала нам нужно было разобраться, как сейчас происходит сбор метрик и почему отсутствуют показания по CPU и RAM.
В Prometheus есть внешний агент, который раз в несколько секунд приходит и запрашивает метрики. Они хранятся у нас на веб-сервисе в виде счетчиков. Их значанения доступны либо в эндпоинте (адресе, на который отправляется запрос) основного приложения, либо из отдельного веб-сервера на соседнем TCP-порту — кому как удобнее.

Под счетчиками я имею в виду некие обертки над каждым показателем. Если вы хотите мониторить, например, количество HTTP-запросов, вы создаете под это новый счетчик. Если хотите мониторить время запросов, создаете другой. Важно понимать, что счетчики — это переменные, значение в них не обновляется само по себе. Необходимо, чтобы некий участок кода изменил значение этого счетчика. Для этого код должно что-то вызвать, некое триггерное событие.
Триггерные события в системе
Приведем пример двух событий в системе, которые могут быть триггером для обновления счетчика.
Обновление счетчика после подсчитываемого события. Триггером может быть сам HTTP-запрос к эндпоинту: во время его обработки мы вызываем участок кода, который инкрементирует значение счетчика после каждого HTTP-запроса. К тому моменту, когда приходит внешний агент, значение будет актуальным.

Обновление счетчика побуждается неким триггером в системе.
Запрос метрик от агента. Если рассматривать триггерное события для сбора CPU- и RAM-метрик в однопроцессном режиме, необходима другая схема.
Схема: внешний агент запрашивает у приложения показатели CPU и RAM; приложение считывает метрики их и включает в ответ агенту.

Показания расхода CPU и RAM считываются тогда, когда приходит запрос от внешнего агента.
Мультипроцессный режим

Схема работы Gunicorn-сервера (master) с несколькими воркерами (worker).
Рассмотрим, какие проблемы возникают при сборе метрик расхода CPU и RAM в мультипроцессном режиме.
Сбор данных с дочерних процессов. Нас интересуют показатели ресурсов по worker-процессам — именно там находятся счетчики CPU и RAM. Дочерние процессы имеют изолированную память, поэтому нужно просуммировать показатели и сделать их доступными для чтения с Gunicorn master-процесса.
Триггер сбора данных в дочерние процессы. Запрос агента (триггера) приходит к мастер-процессу, тогда как счетчики находятся на воркерах. Нужно довести триггерные события до последних, чтобы инициировать считывание показателей CPU и RAM аналогично однопроцессному режиму.
Ниже расскажем, как мы решили эти проблемы, доработав текущее решение на базе библиотеки flask-prometheus-exporter.

Как мы организовали мониторинг в мультипроцессном режиме
Подготовка к мониторингу
Наши приложения работают на Flask под Gunicorn. Чтобы настроить в них мониторинг, устанавливаем open source-библиотеку prometheus-flask-exporter:
pip install prometheus-flask-exporter
Интегрируем ее в Flask-приложение с помощью несколько строк кода из документации. Коробочное решение предоставляет количественные показатели HTTP-запросов (сколько их всего), временные (продолжительность обработки), расход CPU и RAM в приложении для однопроцессного режима.
В комплекте с библиотекой есть дашборд от Grafana. Он позволяет создавать наглядные графики в режиме реального времени. Пригодится, если нужно быстро оценить состояние приложения.

Стандартный дашборд Grafana для библиотеки flask-prometheus-exporter.
Рассмотрим, как мы решили обозначенные выше проблемы мультипроцессного режима.
Сбор данных из дочерних процессов
Библиотека flask-prometheus-exporter основана на prometheus_client, официальном Python-клиенте Prometheus. Находим класс Gauge, который умеет работать в мультипроцессном режиме (он записывает показания счетчиков в отдельные файлы на диске). Главный master-процесс, в котором запущен сервер метрик, читает показания из отдельных файлов и агрегирует их согласно одному из методов. Доступны функции суммирования, поиска минимумов и максимумов.

Доступные функции агрегирования показаний от отдельных процессов.
Для наших целей нужно суммировать показатели с воркеров. В качестве режима для расхода памяти выбираем livesum. Приставка live- означает, что будем учитывать еще существующие процессы, исключая те, которые уже завершились (даже если они записывали метрики). В режиме sum, напротив, учитываются все процессы, которые записывают метрики на диск. Его используем для отслеживания расхода CPU, поскольку система считывает функцию как показатель неубывающей величины — период времени, когда работал CPU с момента старта процесса.
Триггерное событие для считывания данных
Здесь есть два варианта. Первый — каноничный. В нем мы используем методы межпроцессного взаимодействия — например, linux-сигнал или pipe — и доводим триггерное событие с master-процесса до воркера. Однако такой метод индуцирует зависимость от используемого сервера для наших доработок, то есть от Gunicorn.

Передача триггерного события от master к worker.
Второй — генерировать события сразу в worker-процесс. Для этого мы создаем событие с помощью запущенного в отдельном потоке таймера. Раз в несколько секунд он побуждает обновление значений счетчика. Такой метод вносит «лаг» в несколько секунд, но на временных промежутках не разрушает общую картину. Мы выбрали этот вариант, потому что он не привязывает нас к Gunicorn-серверу и позволяет доработать решение, не изменяя его исходный код.

Обновление данных по срабатыванию таймера в каждом worker-процессе.
Агрегация метрик с дочерних процессов
Рассмотрим master-процесс Gunicorn. Внутри него в отдельном потоке запущен сервер метрик. Он использует 9001 порт (TCP/UDP), откуда внешний агент запрашивает показания счетчиков. Чтобы его запустить, воспользуемся фрагментом кода из документации.

def when_ready(server):
port = 9100
GunicornPrometheusMetrics.start_http_server_when_ready(port)
def child_exit(server, worker):
GunicornPrometheusMetrics.mark_process_dead_on_child_exit(worker.pid)
Далее в worker-процессах определяем счетчики для отслеживания расхода оперативной памяти и ресурсов процессора.
vmem = Gauge(..., registry=registry, multiprocess_mode="livesum")
rss = Gauge(..., registry=registry,multiprocess_mode="livesum")
cpu = Gauge(..., registry=registry,multiprocess_mode="sum")
Там же запускаем таймер с помощью стандартной библиотеки Python. При каждом срабатываниии таймера обновляем значение в счетчиках — показания расхода CPU и RAM.
class IntervalTimer(Timer):
def run(self):
while not self.finished.wait(self.interval):
self.function(*self.args, **self.kwargs)
def collect_proc_metrics():
vmem_val, rss_val, utime, stime = read_proc_metrics()
vmem.set(vmem_val)
rss.set(rss_val)
cpu.set(utime + stime)
interval = IntervalTimer(collect_interval_sec, collect_proc_metrics)
interval.daemon = True
interval.start()
Разберемся, какие шаги происходят в системе.
- Мы запускаем таймер, который срабатывает через определенные промежутки времени и обновляет значения счетчиков.
- Класс Gauge записывает показания счетчиков на диск в виде файлов для каждого worker-процесса.
- Параллельно этому на master-процесс приходит запрос от внешнего агента, который хочет узнать о состоянии нашего сервера. Как мы выяснили ранее, сервер метрик читает все файлы из определенной директории и агрегирует показания — в данном случае, суммирует их по одному из выбранных режимов. Полученные показатели можем вывести в виде графиков на дашборд Grafana.

Заключение
Мы доработали библиотеку flask-prometheus-exporter — выделим преимущества нашего решения.
Программа позволяет отслеживать метрики CPU и RAM в мультипроцессном режиме. Решение строится поверх используемых библиотек и не требует модификации их исходного кода. Его легко внедрить в другие приложения на аналогичном стеке.
Расширяется для мониторинга других внутренних метрик. Мы можем мониторить другие внутренние метрики, например, количество retries, состояние circuit breaker и другие. Для этого достаточно создать экземпляр класс Gauge и добавить код, обновляющий показания нового счетчика.
Независимость от Gunicorn. Поскольку наше решение не зависит от исходного кода Gunicorn, мы избежали двух загвоздок. Во-первых, у нас нет необходимости поддерживать и синхронизировать с актуальными версиями измененный код. Во-вторых, отвязались от Gunicorn, поэтому запросто можем перенести мониторинг на другие pre-forked веб-серверы.
Пишите в комментариях о своем опыте мониторинга метрик на Python, будет интересно почитать!
Интересные материалы по теме
Комментарии (6)

Yuribtr
19.12.2023 12:49Класс Gauge записывает показания счетчиков на диск в виде файлов для каждого worker-процесса.
Как по мне немного странное решение разработчика библиотеки - хранить постоянно обновляемую статистику в файлах. Наверно проще было бы в ОЗУ хранить, чтобы не прожигать ячейки SSD. К тому же надо учесть что у Gunicorn можно установить максимальное время жизни воркера - и возникнет вопрос не будет ли забиваться рабочая директория? Или библиотека подчищает за собой мусор?

mn4 Автор
19.12.2023 12:49Спасибо за комментарий!
Я бы сказал, что файлы на диске используются в библиотеке как способ передать информацию между процессами операционной системы.
Касательно расхода места на диске - исторические данные в файлах не хранятся, только последние показания счетчиков.
Могут образовываться файлы от уже завершившихся процессов - библиотека их не чистит. У нас приложение развернуто в docker, и достаточно часто контейнер обновляется, поэтому от этих файлов не испытываем проблем. Для приложений, развернутых без контейнера, я бы использовал что-то наподобие logrotate или cron для чистки старых файлов.

kalbas
19.12.2023 12:49Но если у вас все равно приложения в докере, не проще ли масштабироваться увеличивая количество контейнеров, в которых по одному процессу? Тогда ведь и делать бы ничего не пришлось.

Zagrebelion
Рассматривали ли вы вариант с opentelemety collector-ом, в который пушатся метрики из воркеров, и из которого prometheus выгребает сразу всё одим запросом?
mn4 Автор
Спасибо за комментарий!
Да, мы рассматривали возможность использования push-модель для сбора метрик. В некоторых случаях это может оказаться отличным, и даже единственным возможным решением - о таком кейсе рассказывал мой коллега в своем докладе: https://www.youtube.com/live/ZKUV1WzScDw?feature=shared&t=3216
Мы же решили придерживаться pull модели, т.к. именно в этой парадигме уже был настроен мониторинг в нашем продукте. Для этого и разработали представленное в статье решение, которое позволило без глобального пересмотра подхода к сбору метрик и запуска новых сервисов собирать показания. Все необходимые доработки выполнялись исключительно в исходном коде наших приложений.