Предлагается пошаговое руководство по дообучению Whisper для любого многоязычного набора данных ASR с использованием Hugging Face ???? Transformers. Эта заметка содержит подробные объяснения модели Whisper, набора данных Common Voice и теории дообучения, а также код для выполнения шагов по подготовке данных и дообучению. Для более упрощенной версии с меньшим количеством объяснений, но со всем кодом, см. соответствующий Google Colab.
Содержание
Введение
-
Дообучение Whisper в Google Colab
Подготовка среды
Загрузка набора данных
Подготовка извлекателя признаков, токенизатора и данных
Обучение и оценка
Создание демо
Заключительные замечания
Введение
Whisper - это предварительно обученная модель для автоматического распознавания речи (ASR), опубликованная в сентябре 2022 года авторами Alec Radford и др. из OpenAI. В отличие от многих своих предшественников, таких как Wav2Vec 2.0, которые предварительно обучаются на неразмеченных аудиоданных, Whisper предварительно обучается на огромном количестве размеченных аудиоданных с транскрипцией, 680 000 часов, если быть точным. Это на порядок больше данных, чем неразмеченные аудиоданные, используемые для обучения Wav2Vec 2.0 (60 000 часов). Более того, 117 000 часов этих данных для предварительного обучения - это многоязычные данные ASR. Это приводит к тому, что контрольные точки могут быть применены к более чем 96 языкам, многие из которых считаются малоресурсными.
Это количество размеченных данных позволяет Whisper предварительно обучаться непосредственно на задаче распознавания речи, изучая отображение речи в текст из размеченных аудиоданных с транскрипцией. Название Whisper происходит от аббревиатуры "WSPSR", что означает "Web-scale Supervised Pre-training for Speech Recognition" (Масштабное веб-обучение с учителем для распознавания речи). В результате Whisper требует мало дополнительного дообучения, чтобы дать производительную модель ASR. Это в отличие от Wav2Vec 2.0, который предварительно обучается на задаче без учителя - маскированном предсказании. Здесь модель обучается изучать промежуточное отображение от речи к скрытым состояниям из неразмеченных аудиоданных. Хотя предварительное обучение без учителя дает высококачественные представления речи, оно не изучает отображение речи в текст. Это отображение изучается только во время дообучения, поэтому требуется больше дообучения, чтобы добиться конкурентоспособной производительности.
При масштабировании до 680 000 часов размеченных данных для предварительного обучения модели Whisper демонстрируют сильную способность обобщать на многие наборы данных и домены. Предварительно обученные контрольные точки достигают конкурентоспособных результатов по сравнению с передовыми системами ASR, с почти 3% показателем ошибок слов (WER) на подмножестве test-clean LibriSpeech ASR и новым рекордом на TED-LIUM с 4,7% WER (см. таблицу 8 статьи Whisper). Обширные многоязычные знания ASR, полученные Whisper во время предварительного обучения, могут быть использованы для других малоресурсных языков; благодаря тонкой настройке предварительно обученные контрольные точки могут быть адаптированы для конкретных наборов данных и языков, чтобы еще больше улучшить эти результаты.
Whisper - это модель на основе трансформера с encoder-decoder, также называемая моделью sequence-to-sequence. Она отображает последовательность признаков спектрограммы речи на последовательность текстовых токенов. Сначала исходные аудиовходы преобразуются в логарифмическую спектрограмму Мела с помощью извлекателя признаков. Затем трансформерный кодировщик кодирует спектрограмму, формируя последовательность скрытых состояний кодировщика. Наконец, декодер авторегрессивно предсказывает текстовые токены, условно как на предыдущих токенах, так и на скрытых состояниях кодировщика. Рисунок 1 иллюстрирует модель Whisper.
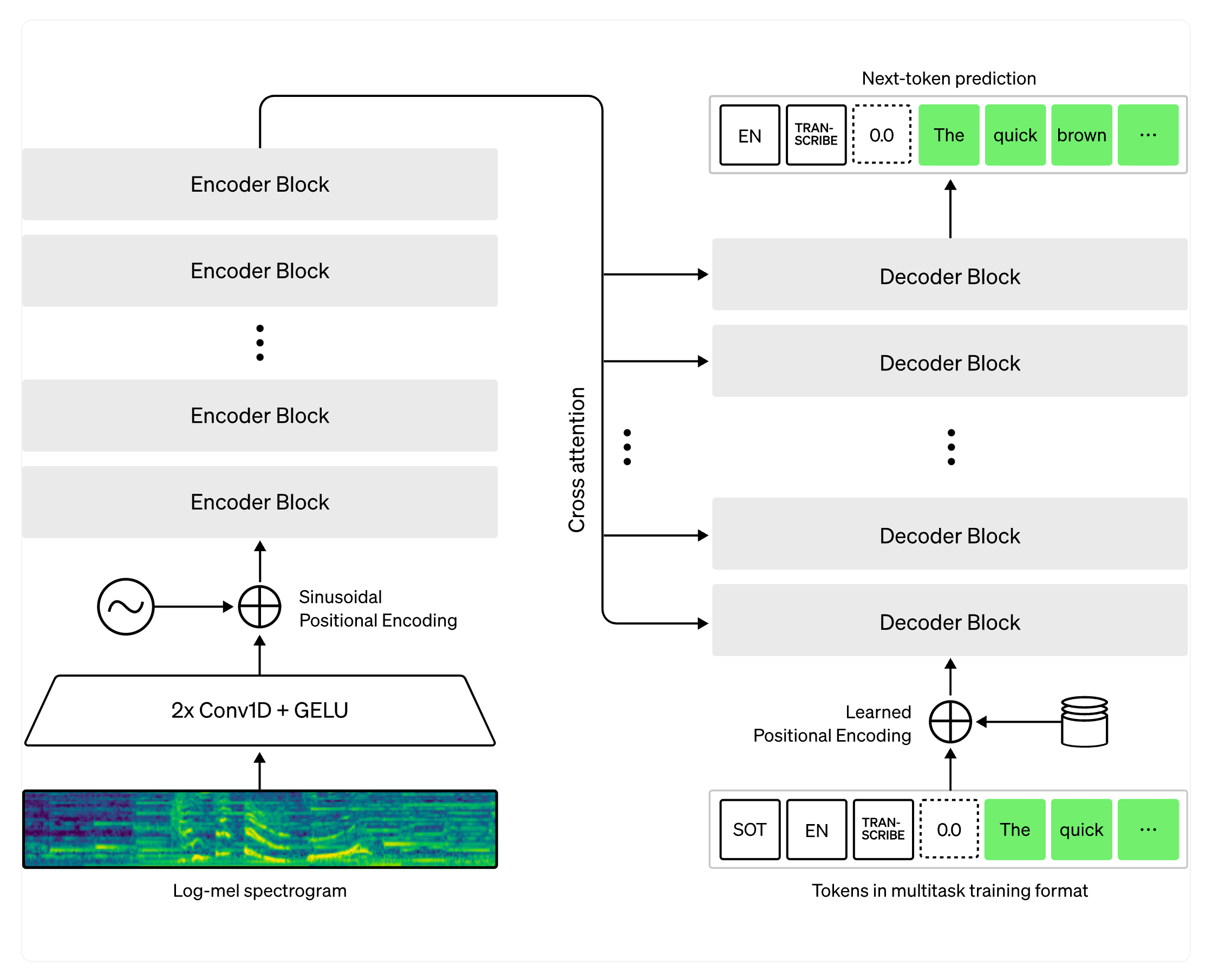
Figure 1: Модель Whisper. Архитектура следует стандартной модели encoder-decoder на основе трансформера. На вход кодировщика подается лог-Мел спектрограмма. Последние скрытые состояния кодировщика передаются на вход декодера через механизмы внимания. Декодер авторегрессивно предсказывает текстовые токены, совместно зависящие от скрытых состояний кодировщика и предыдущих предсказанных токенов. Источник рисунка: OpenAI Whisper Blog.
В модели sequence-to-sequence кодировщик преобразует аудиовходы в набор представлений скрытых состояний, извлекая важные признаки из произнесенной речи. Декодер играет роль языковой модели, обрабатывая представления скрытых состояний и генерируя соответствующие текстовые транскрипции. Включение языковой модели внутри системной архитектуры называется глубоким слиянием. Это противопоставляется поверхностному слиянию, при котором языковая модель комбинируется внешне с кодировщиком, например, с CTC + n-граммами (см. Оценка внутренней языковой модели). При глубоком слиянии вся система может быть обучена end-to-end с одними и теми же данными и функцией потерь, что дает большую гибкость и, как правило, лучшую производительность (см. ESB Benchmark).
Whisper предобучается и дообучается с использованием функции потерь перекрестной энтропии, стандартной функции потерь для обучения систем sequence-to-sequence на задачах классификации. Здесь система обучается правильно классифицировать целевой текстовый токен из предопределенного словаря текстовых токенов.
Для модели Whisper существует пять контрольных точек различных размеров. Четыре самых маленьких обучены либо только на английском, либо на многоязычных данных. Самая большая контрольная точка является многоязычной. Все девять предобученных контрольных точек доступны на Hugging Face Hub. Контрольные точки суммированы в следующей таблице:

В качестве демонстрации мы будем дообучать многоязычную версию маленькой контрольной точки с 244M параметрами (~= 1GB). Что касается наших данных, мы будем обучать и оценивать нашу систему на языке с низкими ресурсами, взятом из набора данных Common Voice. Мы покажем, что с всего лишь 8 часами данных для дообучения, мы можем достичь высокой производительности на этом языке.
Дообучение Whisper в Google Colab
Подготовка среды
Мы будем использовать несколько популярных пакетов Python для дообучения модели Whisper. Мы будем использовать datasets для загрузки и подготовки наших обучающих данных, а также transformers и accelerate для загрузки и обучения нашей модели Whisper. Нам также потребуется пакет soundfile для предварительной обработки аудиофайлов, evaluate и jiwer для оценки производительности нашей модели, и tensorboard для записи наших метрик. Наконец, мы будем использовать gradio для создания яркой демонстрации нашей дообученной модели.
$ pip install --upgrade pip
$ pip install --upgrade datasets transformers accelerate soundfile librosa evaluate jiwer tensorboard gradio
Мы настоятельно рекомендуем вам загружать контрольные точки модели прямо на Hugging Face Hub во время обучения. Hub предоставляет:
Интегрированный контроль версий: вы можете быть уверены, что ни одна контрольная точка модели не будет потеряна во время обучения.
Логи Tensorboard: отслеживайте важные метрики в течение обучения.
Карты моделей: документируйте, что делает модель и ее предполагаемые варианты использования.
Сообщество: простой способ поделиться и сотрудничать с сообществом!
Связывание блокнота с Hub очень просто - достаточно ввести ваш токен аутентификации Hub при запросе. Найдите свой токен аутентификации Hub здесь:
from huggingface_hub import notebook_login
notebook_login()
Ответ:
Login successful
Your token has been saved to /root/.huggingface/token
Загрузка набора данных
Common Voice - это серия наборов данных, созданных с помощью краудсорсинга, где дикторы записывают текст из Википедии на разных языках. Мы будем использовать последнюю версию набора данных Common Voice (версия 11). Что касается нашего языка, мы будем дообучать нашу модель на хинди, индоарийском языке, который говорят на севере, в центре, на востоке и западе Индии. Common Voice 11.0 содержит примерно 12 часов размеченных данных на хинди, 4 из которых являются тестовыми данными.
Давайте перейдем к Hub и посмотрим страницу набора данных Common Voice: mozilla-foundation/common_voice_11_0.
В первый раз, когда мы просматриваем эту страницу, нас попросят принять условия использования. После этого нам будет предоставлен полный доступ к набору данных.
После того, как мы предоставили аутентификацию для использования набора данных, нам будет представлен предварительный просмотр набора данных. Предварительный просмотр набора данных показывает нам первые 100 образцов набора данных. Более того, он загружен аудиообразцами, которые мы можем слушать в реальном времени. Мы можем выбрать подмножество Common Voice на хинди, установив подмножество на hi с помощью выпадающего меню (hi - это код идентификатора языка для хинди):

Если мы нажмем кнопку воспроизведения на первом образце, мы сможем послушать аудио и увидеть соответствующий текст. Просмотрите образцы для обучающих и тестовых наборов, чтобы лучше понять аудио- и текстовые данные, с которыми мы работаем. Вы можете сказать по интонации и стилю, что записи взяты из озвученной речи. Вы также, вероятно, заметите большое разнообразие дикторов и качества записи, общую черту данных, собранных с помощью краудсорсинга.
Используя ???? Datasets, загрузка и подготовка данных чрезвычайно проста. Мы можем загрузить и подготовить разделы Common Voice всего в одну строку кода. Поскольку хинди является языком с очень низкими ресурсами, мы объединим обучающие (train) и проверочные (validation) разделы, чтобы получить примерно 8 часов обучающих данных. Мы будем использовать 4 часа тестовых (test) данных в качестве отложенного тестового набора:
from datasets import load_dataset, DatasetDict
common_voice = DatasetDict()
common_voice["train"] = load_dataset("mozilla-foundation/common_voice_11_0", "hi", split="train+validation", use_auth_token=True)
common_voice["test"] = load_dataset("mozilla-foundation/common_voice_11_0", "hi", split="test", use_auth_token=True)
print(common_voice)
Ответ:
DatasetDict({
train: Dataset({
features: ['client_id', 'path', 'audio', 'sentence', 'up_votes', 'down_votes', 'age', 'gender', 'accent', 'locale', 'segment'],
num_rows: 6540
})
test: Dataset({
features: ['client_id', 'path', 'audio', 'sentence', 'up_votes', 'down_votes', 'age', 'gender', 'accent', 'locale', 'segment'],
num_rows: 2894
})
})
Большинство наборов данных ASR предоставляют только входные аудиообразцы (audio) и соответствующий транскрибированный текст (sentence). Common Voice содержит дополнительную информацию метаданных, такую как акцент (accent) и местоположение (locale), которую мы можем игнорировать для ASR. Стараясь сделать блокнот максимально универсальным, мы рассматриваем только входное аудио и транскрибированный текст для дообучения, отбрасывая дополнительную информацию метаданных:
common_voice = common_voice.remove_columns(["accent", "age", "client_id", "down_votes", "gender", "locale", "path", "segment", "up_votes"])
Common Voice - это только один из многоязычных наборов данных ASR, которые мы можем загрузить с Hub - у нас есть гораздо больше доступных наборов данных! Чтобы просмотреть диапазон доступных наборов данных для распознавания речи, перейдите по ссылке: ASR Datasets on the Hub.
Подготовка извлекателя признаков, токенизатора и данных
Конвейер ASR можно разложить на три компонента:
Извлекатель признаков, который предварительно обрабатывает входные аудиоданные
Модель, которая выполняет отображение sequence-to-sequence
Токенизатор, который обрабатывает выходные данные модели в текстовый формат
В ???? Transformers, модель Whisper имеет связанный с ней извлекатель признаков и токенизатор, называемые соответственно WhisperFeatureExtractor и WhisperTokenizer.
Мы подробно рассмотрим извлекатель признаков и токенизатор!
Загрузка WhisperFeatureExtractor
Речь представляет собой одномерный массив, который меняется со временем. Значение массива в любой данной точке времени - это амплитуда сигнала в этой точке. Исходя только из информации об амплитуде, мы можем восстановить спектр частот аудио и восстановить все акустические признаки.
Поскольку речь непрерывна, она содержит бесконечное количество значений амплитуды. Это вызывает проблемы для компьютерных устройств, которые ожидают конечные массивы. Таким образом, мы дискретизируем наш речевой сигнал, выбирая значения из нашего сигнала с фиксированными временными шагами. Интервал, с которым мы выбираем наше аудио, известен как частота дискретизации и обычно измеряется в выборках/сек или Герцах (Гц). Выборка с более высокой частотой дискретизации приводит к лучшему приближению непрерывного речевого сигнала, но также требует хранения большего количества значений в секунду.
Крайне важно, чтобы мы согласовали частоту дискретизации наших аудиовходов с ожидаемой частотой дискретизации нашей модели, поскольку аудиосигналы с разными частотами дискретизации имеют очень разные распределения. Аудиообразцы должны обрабатываться только с правильной частотой дискретизации. В противном случае это может привести к неожиданным результатам! Например, если взять аудиообразец с частотой дискретизации 16 кГц и прослушать его с частотой дискретизации 8 кГц, звук будет воспроизводиться как будто на половинной скорости. Точно так же передача аудио с неправильной частотой дискретизации может сбить с толку модель ASR, которая ожидает одну частоту дискретизации и получает другую. Извлекатель признаков Whisper ожидает аудиовходы с частотой дискретизации 16 кГц, поэтому нам нужно согласовать наши входы с этим значением. Мы не хотим случайно обучить систему ASR на замедленной речи!
Извлекатель признаков Whisper выполняет две операции. Сначала он дополняет/обрезает пакет аудиообразцов так, чтобы все образцы имели длину входа 30 секунд. Образцы, короче 30 секунд, дополняются до 30 секунд путем добавления нулей в конец последовательности (нули в аудиосигнале соответствуют отсутствию сигнала или тишине). Образцы, длиннее 30 секунд, обрезаются до 30 секунд. Поскольку все элементы в пакете дополняются/обрезаются до максимальной длины во входном пространстве, нам не требуется маска внимания при передаче аудиовходов в модель Whisper. Whisper уникален в этом отношении - с большинством аудиомоделей вы можете ожидать предоставления маски внимания, которая детализирует, где последовательности были дополнены, и, следовательно, где они должны быть проигнорированы в механизме самовнимания. Whisper обучен работать без маски внимания и напрямую выводить из речевых сигналов, где игнорировать входы.
Вторая операция, которую выполняет извлекатель признаков Whisper, - это преобразование дополненных аудиомассивов в логарифмические спектрограммы Mel. Эти спектрограммы - визуальное представление частот сигнала, похожее на преобразование Фурье. Пример спектрограммы показан на рисунке 2. Вдоль оси y находятся каналы Mel, которые соответствуют определенным частотным корзинам. Вдоль оси x - время. Цвет каждого пикселя соответствует логарифмической интенсивности этой частотной корзины в данное время. Логарифмическая спектрограмма Mel - это форма ввода, ожидаемая моделью Whisper.
Каналы Mel (частотные корзины) являются стандартными в обработке речи и выбраны для приближения к человеческому слуховому диапазону. Все, что нам нужно знать для дообучения Whisper, - это то, что спектрограмма - это визуальное представление частот в речевом сигнале. Для получения более подробной информации о каналах Mel обратитесь к Mel-frequency cepstrum.

Рисунок 2: Преобразование выборочного аудиомассива в логарифмическую спектрограмму Mel. Слева: выборочный одномерный аудиосигнал. Справа: соответствующая логарифмическая спектрограмма Mel. Источник рисунка: Блог Google SpecAugment.
К счастью для нас, извлекатель признаков Whisper от ???? Transformers выполняет как дополнение, так и преобразование спектрограммы всего в одну строку кода! Давайте загрузим извлекатель признаков из предварительно обученной контрольной точки, чтобы подготовить его для наших аудиоданных:
from transformers import WhisperFeatureExtractor
feature_extractor = WhisperFeatureExtractor.from_pretrained("openai/whisper-small")
Загрузка WhisperTokenizer
Теперь давайте посмотрим, как загрузить токенизатор Whisper. Модель Whisper выводит текстовые токены, которые указывают индекс предсказанного текста среди словаря элементов словаря. Токенизатор отображает последовательность текстовых токенов на фактическую текстовую строку (например, [1169, 3797, 3332] -> "the cat sat").
Традиционно, когда мы используем модели только с кодировщиком для ASR, мы декодируем с использованием классификации по временной связности (CTC). Здесь нам требуется обучить токенизатор CTC для каждого набора данных, который мы используем. Одно из преимуществ использования архитектуры encoder-decoder состоит в том, что мы можем напрямую использовать токенизатор из предварительно обученной модели.
Токенизатор Whisper предварительно обучен на транскрипциях для 96 предварительно обученных языков. Следовательно, он имеет обширный byte-pair, который подходит для почти всех многоязычных приложений ASR. Для хинди мы можем загрузить токенизатор и использовать его для дообучения без каких-либо дальнейших модификаций. Нам просто нужно указать целевой язык и задачу. Эти аргументы информируют токенизатор о том, что нужно добавить токены языка и задачи в начало закодированных последовательностей меток:
from transformers import WhisperTokenizer
tokenizer = WhisperTokenizer.from_pretrained("openai/whisper-small", language="Hindi", task="transcribe")
Совет: блог-пост можно адаптировать для перевода речи, установив задачу на "
translate" и язык на язык целевого текста в предыдущей строке. Это добавит соответствующие токены задачи и языка для перевода речи при предварительной обработке набора данных.
Мы можем проверить, что токенизатор правильно кодирует символы хинди, закодировав и декодировав первый образец набора данных Common Voice. При кодировании транскрипций токенизатор добавляет "специальные токены" в начало и конец последовательности, включая токены начала/конца транскрипта, токен языка и токены задач (как указано в аргументах на предыдущем шаге). При декодировании идентификаторов меток у нас есть возможность "пропустить" эти специальные токены, что позволяет нам вернуть строку в исходной форме ввода.
input_str = common_voice["train"][0]["sentence"]
labels = tokenizer(input_str).input_ids
decoded_with_special = tokenizer.decode(labels, skip_special_tokens=False)
decoded_str = tokenizer.decode(labels, skip_special_tokens=True)
print(f"Input: {input_str}")
print(f"Decoded w/ special: {decoded_with_special}")
print(f"Decoded w/out special: {decoded_str}")
print(f"Are equal: {input_str == decoded_str}")
Ответ:
Input: खीर की मिठास पर गरमाई बिहार की सियासत, कुशवाहा ने दी सफाई
Decoded w/ special: <|startoftranscript|><|hi|><|transcribe|><|notimestamps|>खीर की मिठास पर गरमाई बिहार की सियासत, कुशवाहा ने दी सफाई<|endoftext|>
Decoded w/out special: खीर की मिठास पर गरमाई बिहार की सियासत, कुशवाहा ने दी सफाई
Are equal: True
Объединение для создания WhisperProcessor
Для упрощения использования извлекателя признаков и токенизатора мы можем объединить оба в один класс WhisperProcessor. Этот объект процессора наследуется от WhisperFeatureExtractor и WhisperProcessor и может использоваться на аудиовходах и прогнозах модели по мере необходимости. Таким образом, нам нужно отслеживать только два объекта во время обучения: processor и model:
from transformers import WhisperProcessor
processor = WhisperProcessor.from_pretrained("openai/whisper-small", language="Hindi", task="transcribe")
Подготовка данных
Давайте распечатаем первый пример набора данных Common Voice, чтобы увидеть, в какой форме находятся данные:
print(common_voice["train"][0])
Ответ:
{'audio': {'path': '/home/sanchit_huggingface_co/.cache/huggingface/datasets/downloads/extracted/607848c7e74a89a3b5225c0fa5ffb9470e39b7f11112db614962076a847f3abf/cv-corpus-11.0-2022-09-21/hi/clips/common_voice_hi_25998259.mp3',
'array': array([0.0000000e+00, 0.0000000e+00, 0.0000000e+00, ..., 9.6724887e-07,
1.5334779e-06, 1.0415988e-06], dtype=float32),
'sampling_rate': 48000},
'sentence': 'खीर की मिठास पर गरमाई बिहार की सियासत, कुशवाहा ने दी सफाई'}
Мы видим, что у нас есть одномерный входной аудиомассив и соответствующая целевая транскрипция. Мы много говорили о важности частоты дискретизации и о том, что мы должны согласовать частоту дискретизации нашего аудио с частотой дискретизации модели Whisper (16 кГц). Поскольку наше входное аудио дискретизируется с частотой 48 кГц, нам нужно уменьшить ее до 16 кГц перед передачей в извлекатель признаков Whisper.
Мы установим аудиовходы на правильную частоту дискретизации с помощью метода cast_column набора данных. Эта операция не изменяет аудио на месте, а скорее сигнализирует наборам данных (datasets) о ресемплировании аудиообразцов на лету при первой загрузке:
from datasets import Audio
common_voice = common_voice.cast_column("audio", Audio(sampling_rate=16000))
Перезагрузка первого аудиообразца в наборе данных Common Voice приведет его к желаемой частоте дискретизации:
print(common_voice["train"][0])
Ответ:
{'audio': {'path': '/home/sanchit_huggingface_co/.cache/huggingface/datasets/downloads/extracted/607848c7e74a89a3b5225c0fa5ffb9470e39b7f11112db614962076a847f3abf/cv-corpus-11.0-2022-09-21/hi/clips/common_voice_hi_25998259.mp3',
'array': array([ 0.0000000e+00, 0.0000000e+00, 0.0000000e+00, ...,
-3.4206650e-07, 3.2979898e-07, 1.0042874e-06], dtype=float32),
'sampling_rate': 16000},
'sentence': 'खीर की मिठास पर गरमाई बिहार की सियासत, कुशवाहा ने दी सफाई'}
Отлично! Мы видим, что частота дискретизации была уменьшена до 16 кГц. Значения массива также изменились, так как теперь у нас примерно одно значение амплитуды на каждые три, которые были раньше.
Теперь мы можем написать функцию для подготовки наших данных для модели:
Мы загружаем и ресемплируем аудиоданные, вызывая
batch["audio"]. Как объяснялось выше, ???? Datasets выполняет все необходимые операции ресемплирования на лету.Мы используем извлекатель признаков для вычисления входных признаков логарифмической спектрограммы Mel из нашего одномерного аудиомассива.
Мы кодируем транскрипции в идентификаторы меток с помощью токенизатора.
def prepare_dataset(batch):
# load and resample audio data from 48 to 16kHz
audio = batch["audio"]
# compute log-Mel input features from input audio array
batch["input_features"] = feature_extractor(audio["array"], sampling_rate=audio["sampling_rate"]).input_features[0]
# encode target text to label ids
batch["labels"] = tokenizer(batch["sentence"]).input_ids
return batch
Мы можем применить функцию подготовки данных ко всем нашим обучающим примерам, используя метод .map набора данных:
common_voice = common_voice.map(prepare_dataset, remove_columns=common_voice.column_names["train"], num_proc=4)
Отлично! Теперь у нас есть полностью подготовленные данные для обучения! Давайте продолжим и посмотрим, как мы можем использовать эти данные для дообучения Whisper.
Примечание: В настоящее время наборы данных (datasets) используют как torchaudio, так и librosa для загрузки аудио и ресемплирования. Если вы хотите реализовать свою собственную настройку загрузки/выборки данных, вы можете использовать столбец "path" для получения пути к аудиофайлу и игнорировать столбец "audio".
Обучение и оценка
Теперь, когда мы подготовили наши данные, мы готовы погрузиться в процесс обучения. ???? Trainer выполнит большую часть работы за нас. Все, что нам нужно сделать, это:
Определить сборщик данных: сборщик данных берет наши предварительно обработанные данные и подготавливает тензоры PyTorch, готовые для модели.
Метрики оценки: во время оценки мы хотим оценить модель с использованием метрики ошибки на словах - word error rate (WER). Нам нужно определить функцию
compute_metrics, которая обрабатывает этот расчет.Загрузить предварительно обученную контрольную точку: нам нужно загрузить предварительно обученную контрольную точку и правильно настроить ее для обучения.
Определить аргументы обучения: они будут использоваться ???? Trainer при построении графика обучения.
После того, как мы дообучили модель, мы оценим ее на тестовых данных, чтобы убедиться, что мы правильно обучили ее транскрибировать речь на хинди.
Определить сборщик данных
Сборщик данных для модели речи sequence-to-sequence уникален тем, что он обрабатывает input_features и labels независимо: input_features должны обрабатываться извлекателем признаков, а labels - токенизатором.
Следует заметить, что input_features уже дополнены до 30 секунд и преобразованы в логарифмическую спектрограмму Mel фиксированного размера, поэтому все, что нам нужно сделать, это преобразовать их в пакетные тензоры PyTorch. Мы делаем это с помощью метода .pad извлекателя признаков с return_tensors=pt. Обратите внимание, что здесь не применяется дополнительное дополнение, поскольку входы имеют фиксированный размер, input_features просто преобразуются в тензоры PyTorch.
С другой стороны, labels не дополнены. Сначала мы дополняем последовательности до максимальной длины в пакете с помощью метода .pad токенизатора. Затем токены дополнения заменяются на -100, чтобы эти токены не учитывались при вычислении потерь. Затем мы вырезаем токен начала транскрипта из начала последовательности меток, так как мы добавляем его позже во время обучения.
Мы можем использовать WhisperProcessor, который мы определили ранее, для выполнения операций как извлекателя признаков, так и токенизатора:
import torch
from dataclasses import dataclass
from typing import Any, Dict, List, Union
@dataclass
class DataCollatorSpeechSeq2SeqWithPadding:
processor: Any
def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
# split inputs and labels since they have to be of different lengths and need different padding methods
# first treat the audio inputs by simply returning torch tensors
input_features = [{"input_features": feature["input_features"]} for feature in features]
batch = self.processor.feature_extractor.pad(input_features, return_tensors="pt")
# get the tokenized label sequences
label_features = [{"input_ids": feature["labels"]} for feature in features]
# pad the labels to max length
labels_batch = self.processor.tokenizer.pad(label_features, return_tensors="pt")
# replace padding with -100 to ignore loss correctly
labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
# if bos token is appended in previous tokenization step,
# cut bos token here as it's append later anyways
if (labels[:, 0] == self.processor.tokenizer.bos_token_id).all().cpu().item():
labels = labels[:, 1:]
batch["labels"] = labels
return batch
Давайте инициализируем коллатор данных, который мы только что определили:
data_collator = DataCollatorSpeechSeq2SeqWithPadding(processor=processor)
Метрики оценки
Далее мы определяем метрику оценки, которую будем использовать на нашем наборе данных для оценки. Мы будем использовать метрику ошибки на словах (WER), "де-факто" метрику для оценки систем ASR. Для получения дополнительной информации обратитесь к документации WER. Мы загрузим метрику WER из ???? Evaluate:
import evaluate
metric = evaluate.load("wer")
Затем нам просто нужно определить функцию, которая принимает наши прогнозы модели и возвращает метрику WER. Эта функция, называемая compute_metrics, сначала заменяет -100 на pad_token_id в label_ids (отменяя шаг, который мы применили в сборщике данных, чтобы правильно игнорировать дополненные токены при потерях). Затем он декодирует предсказанные идентификаторы меток в строки. Наконец, он вычисляет WER между прогнозами и эталонными метками:
def compute_metrics(pred):
pred_ids = pred.predictions
label_ids = pred.label_ids
# replace -100 with the pad_token_id
label_ids[label_ids == -100] = tokenizer.pad_token_id
# we do not want to group tokens when computing the metrics
pred_str = tokenizer.batch_decode(pred_ids, skip_special_tokens=True)
label_str = tokenizer.batch_decode(label_ids, skip_special_tokens=True)
wer = 100 * metric.compute(predictions=pred_str, references=label_str)
return {"wer": wer}
Загрузка предварительно обученной контрольной точки
Теперь давайте загрузим предварительно обученную контрольную точку Whisper small. Опять же, это тривиально с использованием ???? Transformers!
from transformers import WhisperForConditionalGeneration
model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-small")
У модели Whisper есть идентификаторы токенов, которые принудительно выводятся как выходы модели перед началом авторегрессивного генерирования (forced_decoder_ids). Эти идентификаторы токенов контролируют язык транскрипции и задачу для ASR с нулевым выстрелом. Для дообучения мы установим эти идентификаторы в None, так как мы будем обучать модель предсказывать правильный язык (хинди) и задачу (транскрипцию). Есть также токены, которые полностью подавляются во время генерации (suppress_tokens). Эти токены имеют свои логарифмические вероятности, установленные в -inf, так что они никогда не выбираются. Мы переопределим эти токены в пустой список, что означает, что никакие токены не подавляются:
model.config.forced_decoder_ids = None
model.config.suppress_tokens = []
Определение аргументов обучения
На последнем шаге мы определяем все параметры, связанные с обучением. Ниже объясняется подмножество параметров:
output_dir: локальный каталог, в котором сохраняются веса модели. Это также будет название репозитория на Hugging Face Hub.generation_max_length: максимальное количество токенов для авторегрессивного генерирования во время оценки.save_steps: во время обучения промежуточные контрольные точки будут сохраняться и асинхронно загружаться на Hub каждыеsave_stepsшагов обучения.eval_steps: во время обучения оценка промежуточных контрольных точек будет выполняться каждыеeval_stepsшагов обучения.report_to: где сохранять журналы обучения. Поддерживаются платформы "azure_ml", "comet_ml", "mlflow", "neptune", "tensorboard" и "wandb". Выберите свою любимую или оставьте "tensorboard", чтобы вести журнал на Hub.
Для получения более подробной информации о других аргументах обучения обратитесь к документации Seq2SeqTrainingArguments.
from transformers import Seq2SeqTrainingArguments
training_args = Seq2SeqTrainingArguments(
output_dir="./whisper-small-hi", # change to a repo name of your choice
per_device_train_batch_size=16,
gradient_accumulation_steps=1, # increase by 2x for every 2x decrease in batch size
learning_rate=1e-5,
warmup_steps=500,
max_steps=4000,
gradient_checkpointing=True,
fp16=True,
evaluation_strategy="steps",
per_device_eval_batch_size=8,
predict_with_generate=True,
generation_max_length=225,
save_steps=1000,
eval_steps=1000,
logging_steps=25,
report_to=["tensorboard"],
load_best_model_at_end=True,
metric_for_best_model="wer",
greater_is_better=False,
push_to_hub=True,
)
Примечание: если вы не хотите загружать контрольные точки модели в Hub, установите push_to_hub=False.
Мы можем передать аргументы обучения в ???? Trainer вместе с нашей моделью, набором данных, коллатором данных и функцией compute_metrics:
from transformers import Seq2SeqTrainer
trainer = Seq2SeqTrainer(
args=training_args,
model=model,
train_dataset=common_voice["train"],
eval_dataset=common_voice["test"],
data_collator=data_collator,
compute_metrics=compute_metrics,
tokenizer=processor.feature_extractor,
)
И с этим мы готовы приступить к тренировкам!
Обучение
Чтобы начать обучение, просто выполните команду:
trainer.train()
Обучение займет примерно 5-10 часов в зависимости от вашего GPU или того, который выделен в Google Colab. В зависимости от вашего GPU, возможно, вы столкнетесь с ошибкой "out-of-memory" CUDA при начале обучения. В этом случае вы можете уменьшить per_device_train_batch_size инкрементно на множители 2 и использовать gradient_accumulation_steps для компенсации.

Наш лучший WER составляет 32,0% - неплохо для 8 часов обучающих данных! Большой вопрос в том, как это сравнивается с другими системами ASR. Для этого мы можем просмотреть hf-speech-bench, таблицу лидеров, которая классифицирует модели по языку и набору данных, а затем ранжирует их в соответствии с их WER.

Наша модель, прошедшая тонкую настройку, значительно превосходит по производительности "нулевой выстрел" small контрольной точки Whisper, что подчеркивает сильные возможности передачи обучения Whisper.
Мы можем автоматически отправить нашу контрольную точку на доску лидеров, когда мы отправляем результаты обучения на Hub - нам просто нужно установить соответствующие ключевые аргументы (kwargs). Вы можете изменить эти значения в соответствии с вашим набором данных, языком и названием модели.
kwargs = {
"dataset_tags": "mozilla-foundation/common_voice_11_0",
"dataset": "Common Voice 11.0", # a 'pretty' name for the training dataset
"dataset_args": "config: hi, split: test",
"language": "hi",
"model_name": "Whisper Small Hi - Sanchit Gandhi", # a 'pretty' name for your model
"finetuned_from": "openai/whisper-small",
"tasks": "automatic-speech-recognition",
"tags": "hf-asr-leaderboard",
}
Результаты обучения теперь можно загрузить на Hub. Для этого выполните команду push_to_hub.
trainer.push_to_hub(**kwargs)
Теперь вы можете поделиться этой моделью с кем угодно, используя ссылку на Hub. Они также могут загрузить ее с идентификатором "ваше-имя-пользователя/выбранное-вами-имя", например:
from transformers import WhisperForConditionalGeneration, WhisperProcessor
model = WhisperForConditionalGeneration.from_pretrained("sanchit-gandhi/whisper-small-hi")
processor = WhisperProcessor.from_pretrained("sanchit-gandhi/whisper-small-hi")
Хотя дообученная модель дает удовлетворительные результаты на тестовых данных Common Voice на хинди, она отнюдь не оптимальна. Цель этого блокнота - продемонстрировать, как предварительно обученные контрольные точки Whisper могут быть дообучены на любом многоязычном наборе данных ASR. Результаты, вероятно, могут быть улучшены путем оптимизации гиперпараметров обучения, таких как скорость обучения и исключение, а также использования более крупной предварительно обученной контрольной точки (medium или large).
Создание демо
Теперь, когда мы дообучили нашу модель, мы можем создать демо, чтобы продемонстрировать ее возможности в области ASR! Мы будем использовать конвейер (pipeline) ???? Transformers, который заботится обо всем конвейере ASR, начиная от предварительной обработки аудиовходов и заканчивая декодированием прогнозов модели. Мы создадим наше интерактивное демо с помощью Gradio. Gradio, возможно, самый простой способ создания демонстраций машинного обучения; с Gradio мы можем создать демо всего за несколько минут!
Запуск приведенного ниже примера сгенерирует демо Gradio, где мы сможем записывать речь через микрофон нашего компьютера и вводить ее в нашу дообученную модель Whisper для транскрибации соответствующего текста:
from transformers import pipeline
import gradio as gr
pipe = pipeline(model="sanchit-gandhi/whisper-small-hi") # change to "your-username/the-name-you-picked"
def transcribe(audio):
text = pipe(audio)["text"]
return text
iface = gr.Interface(
fn=transcribe,
inputs=gr.Audio(source="microphone", type="filepath"),
outputs="text",
title="Whisper Small Hindi",
description="Realtime demo for Hindi speech recognition using a fine-tuned Whisper small model.",
)
iface.launch()
Заключительные замечания
Мы рассмотрели пошаговое руководство по дообучению Whisper для многоязычного ASR с использованием ???? Datasets, Transformers и Hugging Face Hub. Обратитесь к Google Colab, если вы хотите попробовать дообучение самостоятельно. Если вас интересует дообучение других моделей Transformers, как для английского, так и для многоязычного ASR, обязательно ознакомьтесь с примерами скриптов в examples/pytorch/speech-recognition.
comerc Автор
На faster-whisper есть утилитка для конвертации whisper-моделей:
Перепробовал всё, что нашёл. Печалька:
Что ещё можно сделать? Научиться тюнить самому! Прикрутить GOLOS и SILERO.