Доброго времени суток!
Представляю вашему вниманию чек-лист из 100 вопросов по Data Science. Вопросы покрывают 5 областей: SQL, Python, Machine Learning, статистику и собственно саму DS.
Кому это вообще может быть полезно:
желающему получить оффер в сфере DS
тому, кто уже давно дата-сайнтист, но хочется освежить какие-то алгоритмы/темы
кто хочет поменять стек на что-то в области анализа и присматривается к DS
Собрал здесь самые частые вопросы с собесов на позицию джуна Data Science, получился так сказать 95% доверительный интервал всех возможных вопросов. Так что если разобраться в этих вопросах, с большой вероятностью Авито, Тинькофф и что у нас там ещё делает DS примет вас к себе на борт.
А если с синдромом самозванца проблем нет, то смело пробивайтесь в FAANG* (*MAANG), успехов)
Ну и в качестве интерлюдии, гениальная схема о том, как изучать DS. Нет, ну правда же)
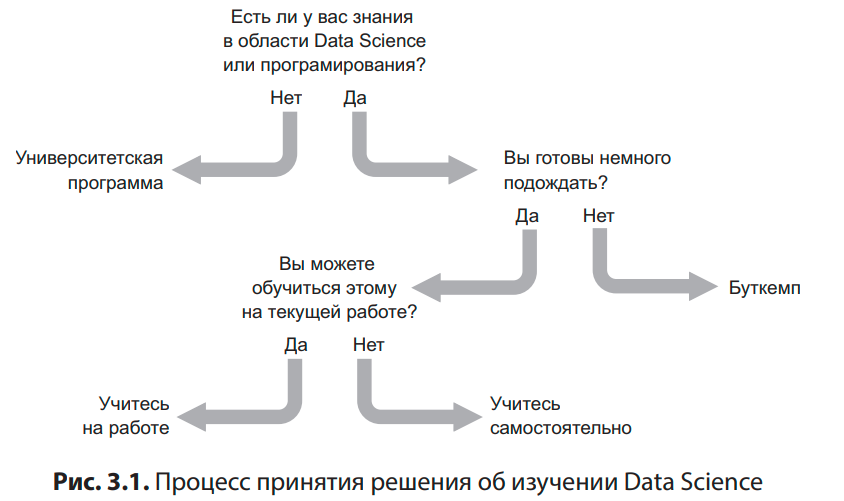
Кстати, если вам реально хочется изучать Data Science, массу годного контента вы найдёте в моём тг канале — это разборы заданий с собесов и масса полезных инструментов. А вот телеграм канал для тех, кто хочет изучить машинное обучение — нейронные сети, машинное обучение, Python. Вот ещё папка с годными ресурсами по Python и МО — поможет в подготовке к собесу и работе в области DS.
Параллельно к этой статье я запилил ролик с разбором части этих вопросов (в основном по Python), прошу — https://youtu.be/6Pk4OgdNxXQ
Тут посты с вопросами по машинному обучению.

Ок, переходим к вопросам. Поехали!
Содержание
Секция "Статистика"
Что такое нормальное распределение?
Средняя проектная оценка в группе из 10 учеников получилась 7, а медиана 8. Как так получилось? Чему больше доверять?
Какова вероятность заражения пациента, если его тест позитивен, а вероятность заболевания в его стране составляет 0.1%?
Что такое центральная предельная теорема? В чем заключается ее практический смысл?
Какие примеры набора данных с негауссовым распределением вы можете привести?
Что такое метод максимизации подобия?
Вы баллотируетесь на пост, в выборке из 100 избирателей 60 будут голосовать за вас. Можете ли вы быть уверены в победе?
Как оценить статистическую значимость анализа?
Сколько всего путей, по которым мышь может добраться до сыра, перемещаясь только по линиям клетки?
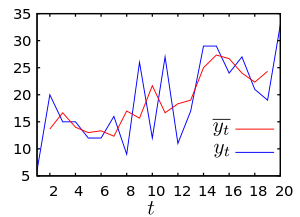
В чем разница между линейной и логистической регрессией?
Приведите три примера распределений с длинным хвостом. Почему они важны в задачах классификации и регрессии?
Суть закона больших чисел
Что показывает p-значение (значимая вероятность)
Что такое биномиальная формула вероятности?
Счетчик Гейгера записывает 100 радиоактивных распадов за 5 минут. Найдите приблизительный 95% интервал для количества распадов в час.
Как рассчитать необходимый размер выборки?
В каких случаях вы бы использовали MSE и MAE?
Когда медиана лучше описывает данные, чем среднее арифметическое?
В чём разница между модой, медианой и матожиданием
Секция "SQL"
В чем заключается разница между MySQL и SQL Server?
Что делает UNION? В чем заключается разница между UNION и UNION ALL?
Как оптимизировать SQL-запросы?
Выведите список сотрудников с зарплатой выше, чем у руководителя
Какие оконные функции существуют?
Найдите список ID отделов с максимальной суммарной зарплатой сотрудников
В чём разница между CHAR и VARCHAR?
Выберите самую высокую зарплату, не равную максимальной зарплате из таблицы
Чем отличаются SQL и NoSQL?
В чём разница между DELETE и TRUNCATE?
Пронумеруйте строки в таблице employee
Пронумеруйте строки в таблице в разрезе отдела по зарплате
Какие есть уровни изоляции транзакций?
Секция "Python"
Какие отличия есть у Series и DataFrame в Pandas?
Напишите функцию, которая определяет количество шагов для преобразования одного слова в другое
В чём преимущества массивов NumPy по сравнению с (вложенными) списками python?
В чём отличие между map, apply и applymap в Pandas?
Самый простой способ реализовать скользящее среднее с помощью NumPy
Поддерживает ли Python регулярные выражения?
Продолжи: "try, except, ..."
Как построить простую модель логистической регрессии на Python?
Как выбрать строки из DataFrame на основе значений столбцов?
Как узнать тип данных элементов из массива NumPy?
В чём отличие loc от iloc в Pandas?
Напишите код, который строит все N-граммы на основе предложения
Каковы возможные способы загрузки массива из текстового файла данных в Python?
Чем отличаются многопоточное и многопроцессорное приложение?
Как можно использовать groupby + transform?
Напишите финальные значения A0, ..., A7
Чем отличаются mean() и average() в NumPy?
Приведите пример использования filter и reduce над итерируемым объектом
Как объединить два массива NumPy?
Напишите однострочник, который будет подсчитывать количество заглавных букв в файле
Как бы вы очистили датасет с помощью Pandas?
array и ndarray — в чём отличия?
Вычислите минимальный элемент в каждой строке 2D массива
Как проверить, является ли набор данных или временной ряд случайным?
В чём разница между pivot и pivot_table?
Реализуйте метод k-средних с помощью SciPy
Какие есть варианты итерирования по строкам объекта DataFrame?
Что такое декоратор? Как написать собственный?
Секция "Data Science"
Что такое сэмплирование? Сколько методов выборки вы знаете?
Чем корреляция отличается от ковариации?
Что такое кросс-валидация? Какие проблемы она призвана решить?
Что такое матрица ошибок? Для чего она нужна?
Как преобразование Бокса-Кокса улучшает качество модели?
Какие методы можно использовать для заполнения пропущенных данных, и каковы последствия невнимательного заполнения данных?
Что такое ROC-кривая? Что такое AUC?
Что такое полнота (recall) и точность (precision)?
Как бы вы справились с разными формами сезонности при моделировании временных рядов?
Какие ошибки вы можете внести, когда делаете выборку?
Что такое RCA (root cause analysis)? Как отличить причину от корреляции?
Что такое выброс и внутренняя ошибка? Объясните, как их обнаружить, и что бы вы делали, если нашли их в наборе данных?
Что такое A/B-тестирование?
В каких ситуациях общая линейная модель неудачна?
Является ли подстановка средних значений вместо пропусков допустимым? Почему?
Есть данные о длительности звонков. Разработайте план анализа этих данных. Как может выглядеть распределение этих данных? Как бы вы могли проверить, подтверждаются ли ваши ожидания?
Секция "Machine Learning"
Что такое векторизация TF/IDF?
Что такое переобучение и как его можно избежать?
Вам дали набор данных твитов, задача – предсказать их тональность (положительная или отрицательная). Как бы вы проводили предобработку?
Расскажите про SVM
В каких случаях вы бы предпочли использовать SVM, а не Случайный лес (и наоборот)?
Каковы последствия установки неправильной скорости обучения?
Объясните разницу между эпохой, пакетом (batch) и итерацией.
Почему нелинейная функция Softmax часто бывает последней операцией в сложной нейронной сети?
Объясните и дайте примеры коллаборативной фильтрации, фильтрации контента и гибридной фильтрации
В чем разница между bagging и boosting для ансамблей?
Как выбрать число k для алгоритма кластеризации «метод k-средних» (k-Means Clustering), не смотря на кластеры?
Как бы вы могли наиболее эффективно представить данные с пятью измерениями?
Что такое ансамбли, и чем они полезны?
В вашем компьютере 5Гб ОЗУ, а вам нужно обучить модель на 10-гигабайтовом наборе данных. Как вы это сделаете?
Всегда ли методы градиентного спуска сходятся в одной и той же точке?
Что такое рекомендательные системы?
Объясните дилемму смещения-дисперсии (bias-variance tradeoff) и приведите примеры алгоритмов с высоким и низким смещением.
Что такое PCA, и чем он может помочь?
Объясните разницу между методами регуляризации L1 и L2.
Секция "Статистика"
Вообще, если вы думаете, что матаном, производными и вычислением градиента мучают только свежеиспечённых выпускников-стажёров, то это не совсем так.
Вот, гляньте на задания с собеседования в ВТБ (спасибо Вадим) на позицию Data Science.

В целом, задания простые, но из-за отсутствия практики с ними могут быть проблемки. Так что на всякий случай перед собеседованием вспомните подобные базовые штуки из анализа, линейки, теорвера и прочих.
Да и вообще, учите матан — не зря же Миша Ломоносов говорил, что это ум в порядок приводит)
Перед тем, как перейти к разным вопросам по статистике и т.д. можно пройти вот такой замечательный тест, насколько в голове ещё сохранились основы (тест позаимствован из статьи)


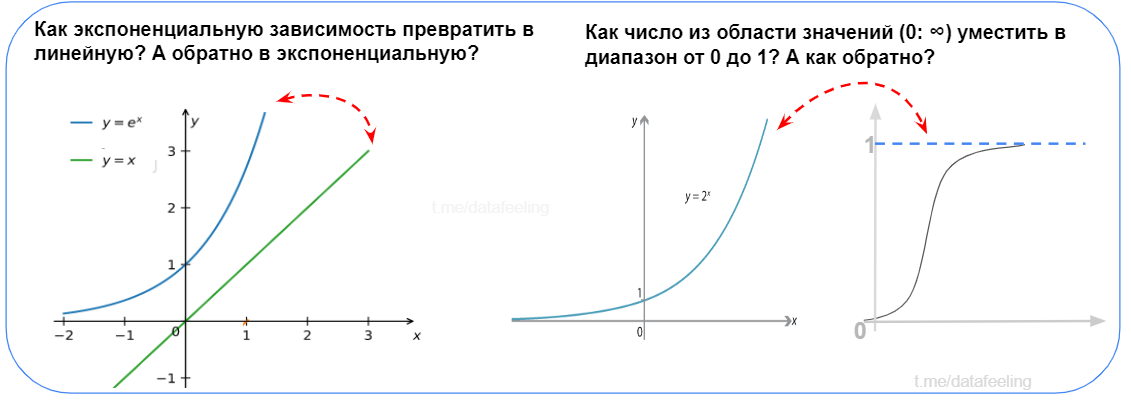


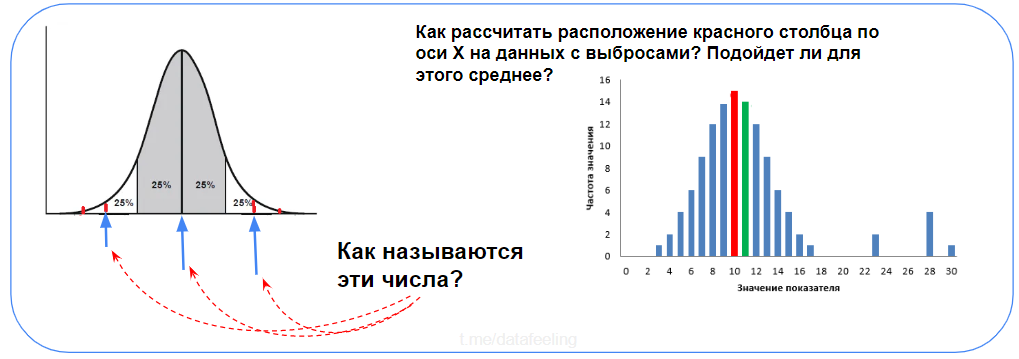
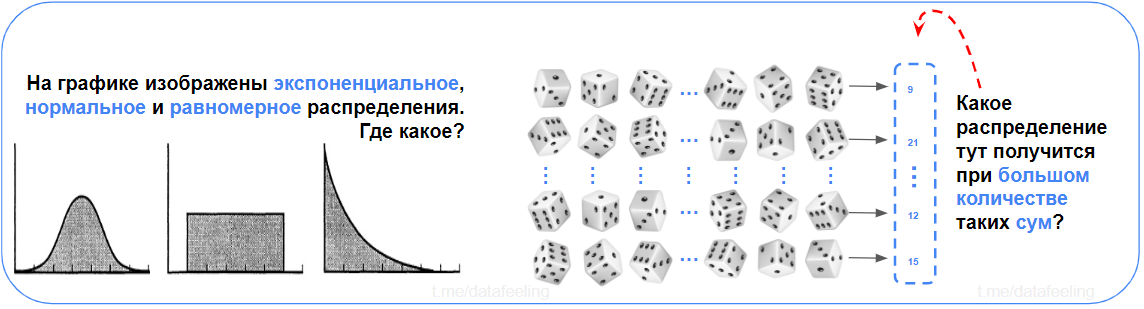
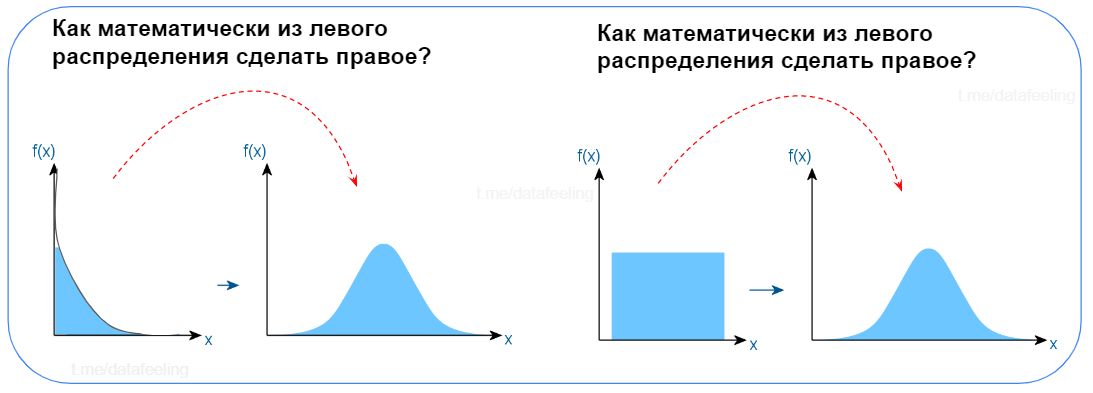


Что такое нормальное распределение?
А что, вдруг кандидат не знает ¯\_(ツ)_/¯

Нормальное распределение (Гаусса) задаётся такой функцией плотности вероятности:
тут параметр — математическое ожидание (среднее значение), медиана и мода распределения, а параметр
— среднеквадратическое отклонение,
— дисперсия распределения.
А это график нормального распределения и процент попадания случайной величины на отрезки, равные среднеквадратическому отклонению.

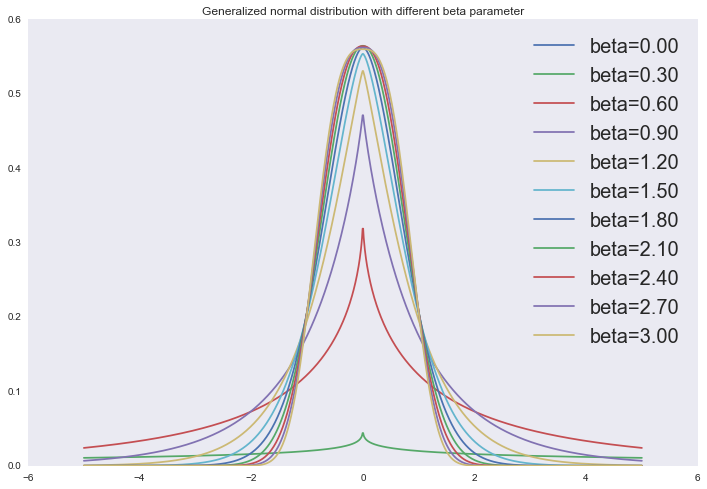
Кстати, если хочется блеснуть на собесе, можно упомянуть обобщённую формулу нормального распределения:
Отрисовать это можно так:
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import gennorm
x = np.linspace(-5, 5, 1000)
for beta in np.linspace(0, 3, 11):
plt.plot(x, gennorm.pdf(x, beta=beta), label='beta=%0.2f' % beta)
plt.legend(loc='upper right', prop={'size': 10})
plt.title('Generalized normal distribution with different beta parameter')
plt.show()
Средняя проектная оценка в группе из 10 учеников получилась 7, а медиана 8. Как так получилось? Чему больше доверять?
Это простой вопрос.
Если средняя оценка в группе – 7, а медиана – 8, это может означать, что в группе есть несколько учеников, которые получили довольно низкие оценки, что снизило среднюю оценку, но при этом большинство учеников получили более высокие оценки, что повысило медиану.
Доверять в данном случае можно обоим показателям, но важно учитывать их интерпретацию. Средняя оценка подвержена влиянию крайних значений, так что если в группе есть несколько учеников с низкими оценками, это существенно снизит среднюю оценку. Медиана же отражает значение, которое разделяет выборку на две равные части, и не подвержена такому влиянию крайних значений.
Чему больше доверять - зависит от цели анализа данных. Если интересует общая картина и средний уровень успеваемости группы, то лучше использовать среднюю оценку. Если же интересует типичный уровень успеваемости учеников, то лучше использовать медиану.
Какова вероятность заражения пациента, если его тест позитивен, а вероятность заболевания в его стране составляет 0.1%?
Для решения этой задачи нам нужно знать чувствительность и специфичность теста. Чувствительность теста - это вероятность того, что тест даст положительный результат у зараженного пациента. Специфичность теста - это вероятность того, что тест даст отрицательный результат у незараженного пациента.
Допустим, что у нашего теста чувствительность 95% и специфичность 99%. Это означает, что из 100 зараженных пациентов тест правильно определит 95, а из 100 незараженных пациентов тест правильно определит 99.
Теперь мы можем использовать формулу Байеса для вычисления вероятности заражения при положительном тесте:
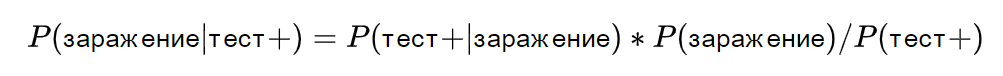
где - вероятность получить положительный тест при наличии заражения,
- вероятность заражения в популяции,
- общая вероятность получить положительный тест.
Подставляя значения, получаем:
Таким образом, вероятность заражения пациента при положительном тесте составляет около 8.7%.
Что такое центральная предельная теорема? В чем заключается ее практический смысл?
Пока не далеко ушли от нормального распределения, обсудим центральную предельную теорему (ЦПТ).
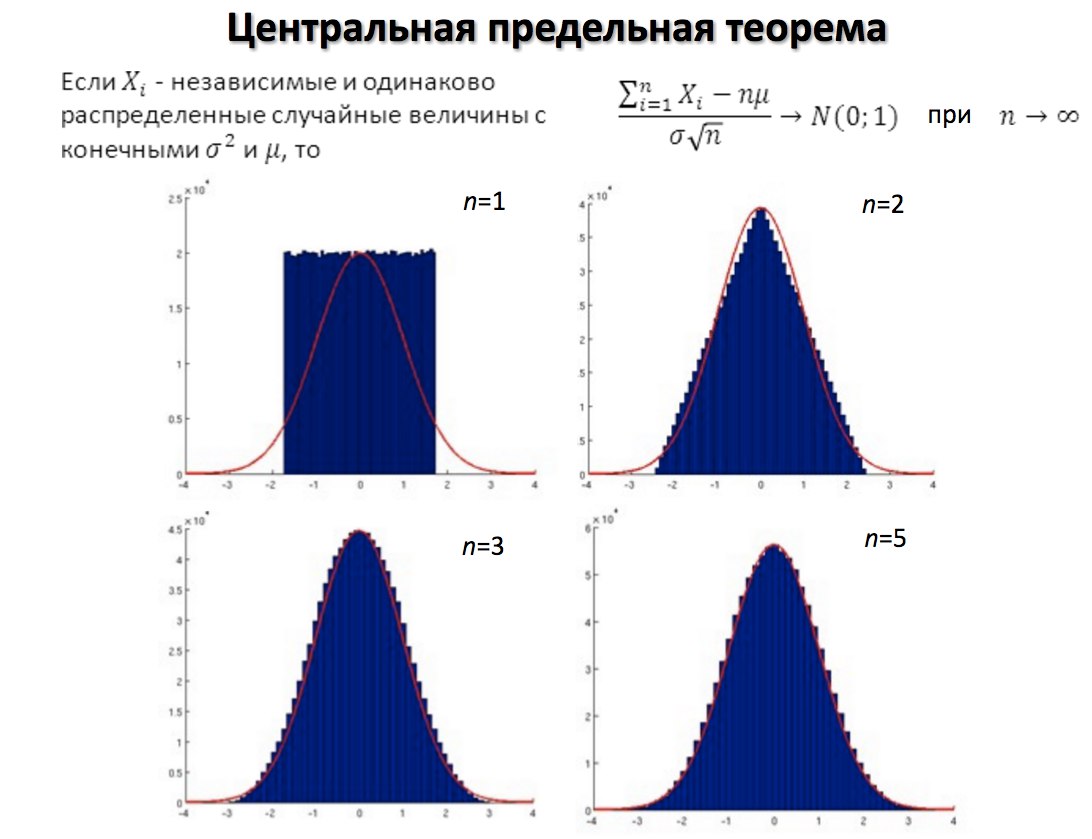
В общем, центральная предельная теорема (ЦПТ) говорит о том, что сумма достаточно большого количества слабо зависимых случайных величин с примерно одинаковыми масштабами имеет распределение, близкое к нормальному.
Центральная предельная теорема важна, поскольку она используется при проверке гипотез и расчете доверительных интервалов.
Практическая мощь ЦПТ в том, что она позволяет использовать нормальное распределение для аппроксимации суммы случайных величин при любом распределении величин. Это облегчает анализ и позволяет делать выводы о средних значениях и доверительных интервалах.
Нет точного ответа, насколько большим должен быть размер выборки, чтобы можно было применить ЦПТ, но в целом это зависит от асимметрии распределения выборки:
если распределение симметрично, иногда достаточно размера выборки всего 15
если распределение асимметрично, обычно требуется размер выборки не менее 30
если распределение крайне асимметрично, может потребоваться размер выборки 40+
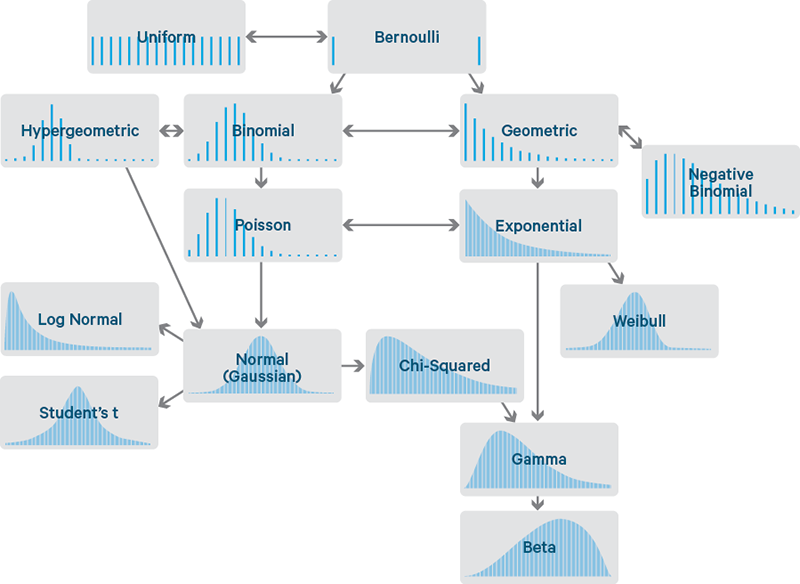
Какие примеры набора данных с негауссовым распределением вы можете привести?
Можно сразу привести такие примеры:
Любые категориальные данные не будут иметь ни гауссова, ни логнормального распределения.
Экспоненциальные распределения. Например, количество времени, которое продержится автомобильный аккумулятор или время до следующего землетрясения.
Количество несчастных случаев — часто это распределение Пуассона
Срок службы продуктов обычно соответствует распределению Вейбулла
А вообще, если подробнее, то существует множество распределений, которые отличаются от нормального:
Бета-распределение
Гамма-распределение (Обратное гамма-распределение)
Логистическая дистрибуция
Распределение Максвелла-Больцмана
Распределение Пуассона
Перекошенное распределение
Симметричное распределение
Равномерное распределение
Унимодальное распределение
Распределение Вейбулла
Что такое метод максимизации подобия?
Во-первых, это один из методов оценки параметров статистической модели. Он основан на максимизации функции подобия, которая измеряет, насколько хорошо модель соответствует наблюдаемым данным.
Метод используется для оценки параметров модели путем выбора таких значений параметров, которые максимизируют вероятность получения наблюдаемых данных при условии данной модели.
Всё это держится на принципе максимального правдоподобия — «оценки параметров модели должны быть выбраны так, чтобы вероятность получения наблюдаемых данных была максимальной»
Метод используется для оценки таких параметров моделей, как линейная регрессия, логистическая регрессия, скрытые марковские модели и другие.
А вот так выглядит сам процесс максимизации подобия:
Формулировка статистической модели, которая описывает зависимость между наблюдаемыми данными и параметрами модели.
Определение функции подобия, которая измеряет, насколько хорошо модель соответствует наблюдаемым данным.
Максимизация функции подобия путем выбора таких значений параметров модели, которые максимизируют вероятность получения наблюдаемых данных.
Оценка параметров модели на основе найденных значений, которые максимизируют функцию подобия.
Вы баллотируетесь на пост, в выборке из 100 избирателей 60 будут голосовать за вас. Можете ли вы быть уверены в победе?
Примем для простоты, что у вас только один соперник.
Также примем, что желаемый доверительный интервал составляет 95%. Это даст нам z-оценку 1.96.
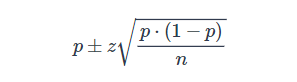
В нашей задаче p = 0.6, z = 1.96, n = 100, что дает доверительный интервал [50.4, 69.6].
Таким образом, при доверительном интервале 95% вы можете расслабиться, только если ничего не имеете против победы с минимальным перевесом. В противном случае придется добиться 61 голоса из 100 опрошенных, чтобы не беспокоиться.
Как оценить статистическую значимость анализа?
Суть статистической значимости состоит в определении того, существует ли реальное основание в разнице между выбранными для исследования показателями, или это случайность? С данным понятием тесно связаны «нулевая» и «альтернативная» гипотезы.
Нулевая гипотеза гласит, что внесение коррективов ничего не поменяет, то есть сравниваемые объекты равнозначны в своих свойствах и нет смысла что-либо менять. Суть исследования заключается в опровержении гипотезы.
Альтернативная (исследовательская) гипотеза подразумевает сравнение, в результате которого один объект показывает себя эффективнее, чем другой.
Одним из распространенных методов оценки статистической значимости является использование t-теста. t-тест позволяет сравнить средние значения двух групп и определить, есть ли статистически значимая разница между ними. Результаты t-теста представляются в виде значения t-статистики и p-значения.
t-статистика - это мера разницы между средними значениями двух групп. Чем больше значение t-статистики, тем больше разница между группами.
p**-значение** - это вероятность получить наблюдаемую разницу между группами, если на самом деле разницы нет. Если p-значение меньше заданного уровня значимости (обычно 0,05), то разница считается статистически значимой.
Для оценки статистической значимости анализа можно использовать следующие шаги:
Сформулировать нулевую гипотезу (H0) и альтернативную гипотезу (H1). Нулевая гипотеза предполагает, что разницы между группами нет, а альтернативная гипотеза предполагает наличие разницы.
Выполнить соответствующий статистический тест, например, t-тест.
Получить значения t-статистики и p-значения.
Сравнить полученное p-значение с уровнем значимости (обычно 0,05). Если p-значение меньше уровня значимости, то разница считается статистически значимой.
Сделать выводы на основе результатов теста. Если разница статистически значима, то можно считать, что результаты анализа не являются случайными.
Итак, для оценки статистической значимости нужно провести проверку гипотезы. Сначала определяют нулевую и альтернативную гипотезы. Затем рассчитывают p – вероятность получения наблюдаемых результатов, если нулевая гипотеза верна. Наконец, устанавливают уровень значимости alpha. Если p < alpha, нулевая гипотеза отвергается – иными словами, анализ является статистически значимым.
Сколько всего путей, по которым мышь может добраться до сыра, перемещаясь только по линиям клетки?
Внезапно задача, да ещё какая-то странная. Есть идеи, как можно посчитать все пути?

Это задание удивительно напоминает одно из задание ОГЭ по информатике. Решается просто, ничего особенного. Отмечаем узлы, мышь использует 2 команды: вправо и вверх, в каждом узле отмечаем число — сумму чисел из других узлов, откуда можно попасть в этот. Таким образом мы первый раз получаем число 2 — потому что в текущий узел можно попасть из узлов с числами 1, поэтому 1+1.
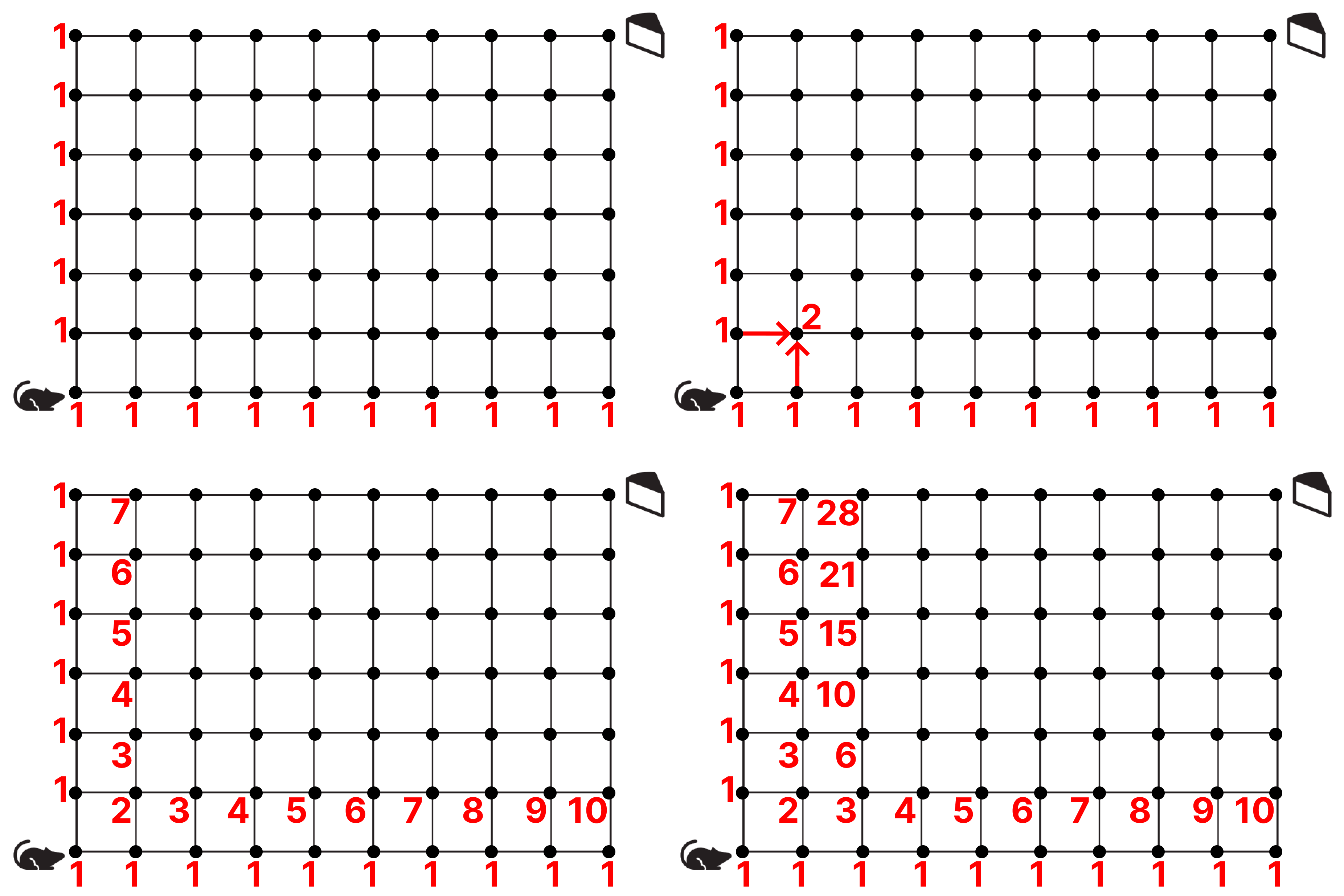
И так мы делаем, пока не дойдём до последнего узла, получаем 5005.
Задание, кстати, позаимствовано из «Data Science для карьериста»)
В чем разница между линейной и логистической регрессией?
Если сразу к ответу — линейную регрессию можно использовать для прогнозирования непрерывной зависимой переменной по шкале значений. Логистическая регрессия используется, когда ожидается результат бинарной операции (например, «да» или «нет»).
Линейная регрессия |
Логистическая регрессия |
|
|---|---|---|
Что это |
Статистический метод прогнозирования выходного значения по набору входных значений. |
Статистический метод прогнозирования вероятности принадлежности выходного значения к определенной категории по набору категориальных переменных. |
Зависимость |
Линейная зависимость, представленная прямой линией. |
Логистическая или сигмоидальная зависимость, представленная S-образной кривой. |
Уравнение |
Линейное. |
Логарифмическое. |
Тип обучения под наблюдением |
Регрессия. |
Классификация. |
Тип распределения |
Нормальное/гауссовское. |
Биномиальное. |
Лучше всего подходит для |
Задач, требующих прогнозирования непрерывной зависимой переменной по шкале. |
Задач, требующих прогнозирования вероятности появления категориальной зависимой переменной из фиксированного набора категорий. |
Линейная регрессия – это статистический метод, в котором линия (или n-мерная плоскость в случае множества параметров) подстраивается под данные. Он используется для регрессии – когда целевое значение представляет собой действительное число.
К линейной регрессии допускается 4 основных допущения:
Есть линейная зависимость между зависимой переменной и регрессорами, то есть модель, которую вы создаете, соответствует имеющимся данным.
Ошибки или остатки данных обычно распределяются и независимы друг от друга
Существует минимальная мультиколлинеарность между объясняющими переменными
Гомоскедастичность. (короче, дисперсия вокруг линии регрессии одинакова для всех значений предикторной переменной).
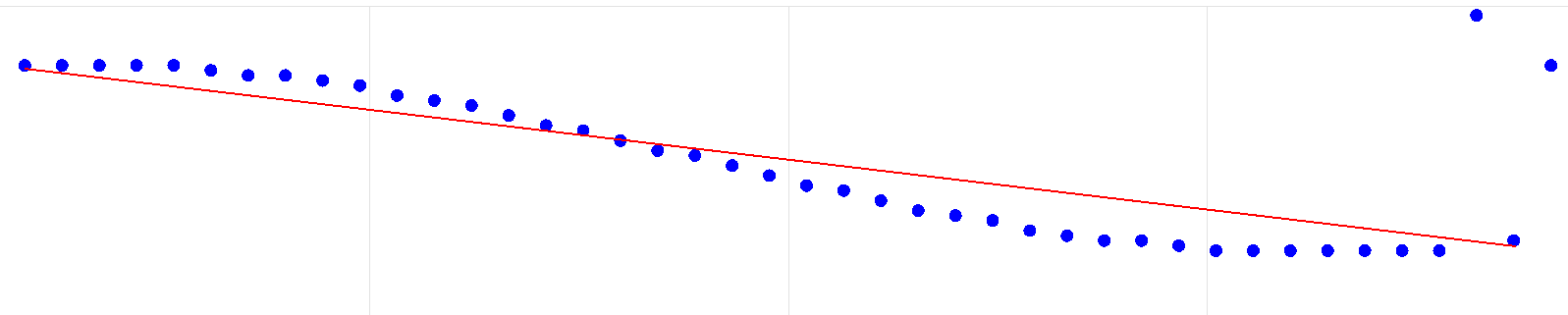
Логистическая регрессия – это метод классификации. Это трансформация линейной регрессии посредством функции сигмоиды, возвращающей вероятность соответствия входного набора классу 0 или классу 1.
Приведите три примера распределений с длинным хвостом. Почему они важны в задачах классификации и регрессии?

Три практических примера: степенной закон, закон Парето и продажи продуктов (например, продукты-бестселлеры против обычных).
При решении задач классификации и регрессии важно не забывать о распределении с длинным хвостом, поскольку редко встречающиеся значения составляют существенную часть выборки. Это влияет на выбор метода обработки выбросов. Кроме того, некоторые методики машинного обучения предполагают, что данные распределены нормально.
Вообще, выбрать нужное распределение не проблема, ведь их существует уйма:
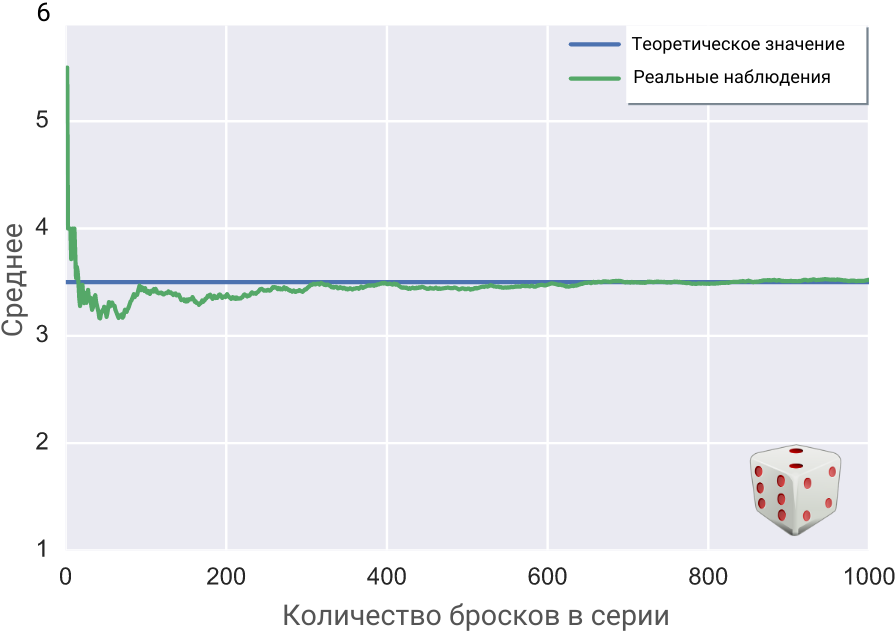
Суть закона больших чисел
Если очень просто — при увеличении количества реальных попыток случайная величина стремится к своему теоретически вычисленному ожидаемому значению (к матожиданию).
Бросим игральный кубик десять раз. Затем запишем среднее значение всех десяти бросков: сложим все выпавшие очки и поделим на 10.
После этого подбросим снова, но теперь уже серией из двадцати бросков, и также запишем среднее. Сумму выпавших очков поделим на 20.
Закон больших чисел утверждает, что при увеличении количества бросков от серии к серии среднее арифметическое всех выпавших в ней очков будет стремиться к определённому числу, которое называется математическим ожиданием.
Для игрального кубика оно равно среднему арифметическому очков на его шести гранях:
Что показывает p-значение (значимая вероятность)

Значимая вероятность — это величина, применяемая при статистической проверке гипотез. Представляет собой вероятность того, что значение проверочной статистики используемого критерия (t-статистики Стьюдента, F-статистики Фишера и т.д.), вычисленное по выборке, превысит установленное p-значение.
Другими словами, p-значение – это наименьшее значение уровня значимости (т.е. вероятности отказа от справедливой гипотезы), для которого вычисленная проверочная статистика ведет к отказу от нулевой гипотезы. Обычно p-значение сравнивают с общепринятыми стандартными уровнями значимости 0,005 или 0,01.
P-значение используется для проверки значимости результатов после статистического теста гипотезы. P-значения помогают анализирующему делать выводы и всегда находятся в диапазоне между 0 и 1.
P-значение, превышающее 0.05, обозначает недостаточные доказательства против нулевой гипотезы – а это значит, что нулевая гипотеза не может быть отвергнута.
P-значение, меньшее 0.05, обозначает сильные доказательства против нулевой гипотезы – это значит, что нулевая гипотеза может быть отвергнута.
P-значение, равное 0.05, находится на границе, то есть мы не можем сделать уверенного вывода о том, можно ли отвергнуть нулевую гипотезу.
Итак, если p-value — это вероятность получить такие или более выраженные различия при условии, что в генеральной совокупности никаких различий на самом деле нет, то какое, на ваш взгляд, верное утверждение:
Компьютерные игры — причина агрессивного поведения с вероятностью 96%.
Вероятность того, что агрессивность и компьютерные игры не связаны, равна 0.04.
Если бы мы получили p-уровень значимости больше, чем 0.05, это означало бы, что агрессивность и компьютерные игры никак не связаны между собой.
Вероятность случайно получить такие различия равняется 0.04.
Все утверждения неверны.
Давайте разберём все ответы по порядку:
1 утверждение — пример ошибки корреляции: факт значимой взаимосвязи двух переменных ничего не говорит нам о причинах и следствиях. Может быть, это более агрессивные люди предпочитают проводить время за компьютерными играми, а вовсе не компьютерные игры делают людей агрессивнее.
2 утверждение. Всё дело в том, что мы изначально принимаем за данное, что никаких различий на самом деле нет. И, держа это в уме как факт, рассчитываем значение p-value. Поэтому правильная интерпретация: «Если предположить, что агрессивность и компьютерные игры никак не связаны, то вероятность получить такие или еще более выраженные различия составила 0.04».
3 утверждение. А что делать, если мы получили незначимые различия? Значит ли это, что никакой связи между исследуемыми переменными нет? Нет, это означает лишь то, что различия, может быть, и есть, но наши результаты не позволили их обнаружить.
4 утверждение. Это напрямую связано с самим определением p-value. 0.04 — это вероятность получить такие или ещё более экстремальные различия. Оценить вероятность получить именно такие различия, как в нашем эксперименте, в принципе невозможно!
Вот такие подводные камни могут скрываться в интерпретации такого показателя, как p-value. Поэтому очень важно понимать механизмы, заложенные в основании методов анализа и расчета основных статистических показателей.
Подробное объяснение, что такое p-value
Что такое биномиальная формула вероятности?
Биномиальная формула вероятности — используется для вычисления вероятности того, что определенное количество событий произойдет в серии независимых испытаний с 2 возможными исходами. Формула выглядит следующим образом:

Биномиальный закон распределения широко используется в Data Science для моделирования случайных событий с 2 исходами. Вот примеры генерации чисел и построения графика.
Генерация случайных чисел с биномиальным распределением. Этот код генерирует 100 случайных чисел с биномиальным распределением с параметрами n=10 и p=0.5:
import numpy as np
n = 10 # количество испытаний
p = 0.5 # вероятность успеха
random_numbers = np.random.binomial(n, p, 100)
print(random_numbers)
Визуализация биномиального распределения. Биномиальное распределение с параметрами n=10 и p=0.5 можно воспроизвести так:
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import binom
n = 10 # количество испытаний
p = 0.5 # вероятность успеха
x = np.arange(0, n+1)
y = binom.pmf(x, n, p)
plt.bar(x, y)
plt.xlabel('Количество успехов')
plt.ylabel('Вероятность')
plt.title('Биномиальное распределения')
plt.show()

Счетчик Гейгера записывает 100 радиоактивных распадов за 5 минут. Найдите приблизительный 95% интервал для количества распадов в час.
Поскольку это задача на распределение Пуассона, среднее = лямбда = дисперсия, что также означает, что стандартное отклонение = квадратному корню из среднего.
Доверительный интервал 95% соответствует z-оценке 1.96.
Одно стандартное отклонение = 10.
То есть, доверительный интервал равен 100 +/- 19.6 = [964.8, 1435.2].
Как рассчитать необходимый размер выборки?
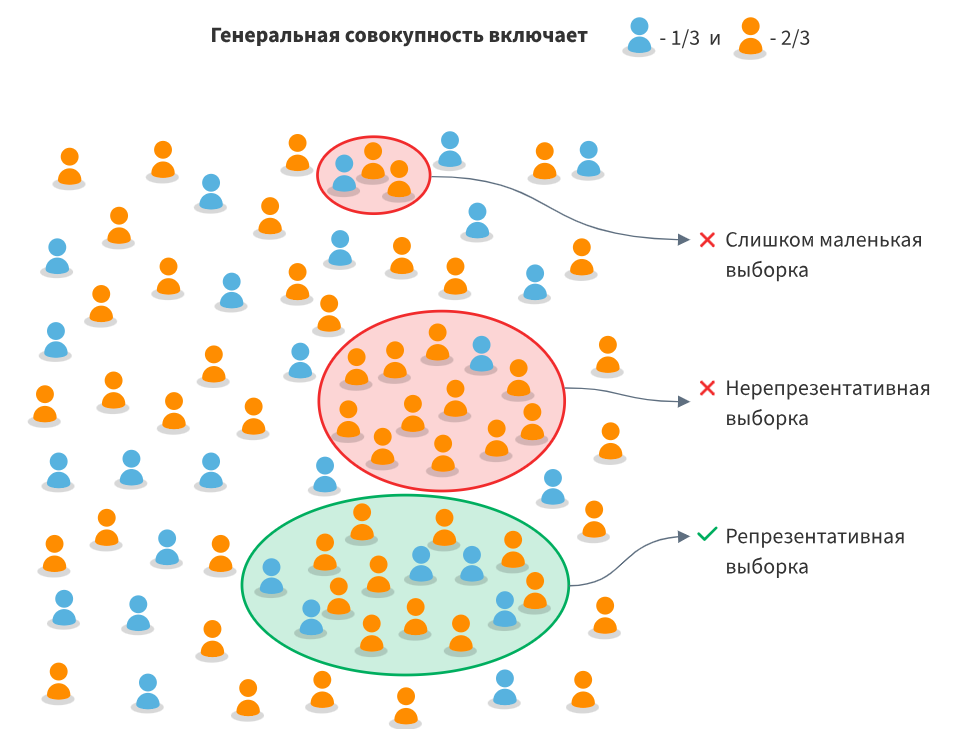
Вспомним пару терминов для начала.
Генеральная совокупность – множество всех объектов, среди которых проводится исследования.
Выборка – подмножество, часть объектов из всей популяции, которая непосредственно участвует в исследовании.
Ошибка первого рода — (α) вероятность отвергнуть нулевую гипотезу, в то время как она верна.
Ошибка второго рода — (β) вероятность не отвергнуть нулевую гипотезу, в то время как она ложна.
1 — β — статистическая мощность критерия.
и
— средние значения при нулевой и альтернативной гипотезе.
При неизвестной величине генеральной совокупности, когда результат отражается в виде показателя относительной доли, число элементов выборки, обеспечивающее количественную репрезентативность, может быть вычислено по формуле:
где — доверительный коэффициент, показывающий, какова вероятность того, что размеры показателя не будут выходить за границы предельной ошибки,
— доля единиц наблюдения, обладающих изучаемым признаком,
— доля единиц наблюдения, не обладающих изучаемым признаков,
— допустимая ошибка выборки.
Если используется выборка без возврата и размер генеральной совокупности известен, то для определения необходимого размера случайной выборки при использования относительных величин (долей) применяется формула:
где — число наблюдений генеральной совокупности
Неплохая статья на Хабре — Как определить размер выборки?
В каких случаях вы бы использовали MSE и MAE?
MSE (средняя квадратичная ошибка) — это оценка среднего значения квадрата ошибок, различие между предсказанием и фактическим значением. Эту метрику удобно использовать для выявления аномалий. MSE применяется в ситуациях, когда нам надо подчеркнуть большие ошибки и выбрать модель, которая дает меньше больших ошибок прогноза. Грубые ошибки становятся заметнее за счет того, что ошибку прогноза мы возводим в квадрат. MSE сильнее штрафует за большие отклонения по сравнению со MAE, и поэтому более чувствителен к выбросам.
MAE (средняя абсолютная ошибка) — это оценка того, насколько близки предсказания к фактическим значениями. Эта метрика менее чувствительна к выбросам и может дать общее представление о качестве модели. А ещё она выдает результат, который проще интерпретировать.
Итог: если у нас сильные аномалии в значениях, то используем MAE; если аномалий мало, можно использовать MSE.
Неплохая лекция от ИТМО — Оценка качества в задачах классификации и регрессии
Когда медиана лучше описывает данные, чем среднее арифметическое?
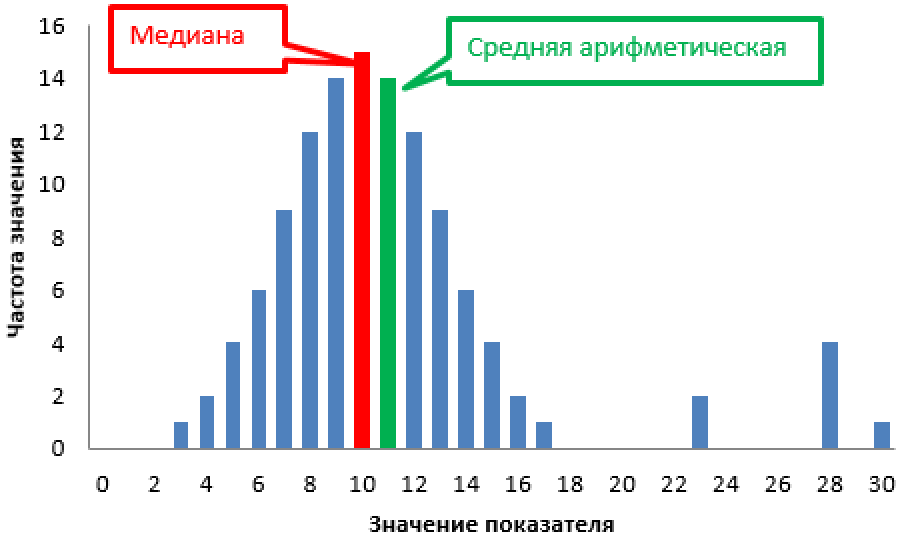
Сильные стороны среднего арифметического:
среднее арифметическое учитывает все значения в наборе данных.
это интуитивно понятная метрика, которая широко используется во многих областях.
Минусы:
среднее арифметическое очень чувствительно к выбросам — отдельным значениям, которые значительно отличаются от других в этом датасете, в большую или меньшую сторону. Выбросы могут искажать среднее значение, давая тем самым неверное представление о центральной тенденции в данных.
Медиана — это мера центральной тенденции, которая представляет собой серединное значение набора данных, расположенного в порядке от меньшего к большему. Например, в наборе данных {3, 7, 12, 16, 19} медианой будет 12.
Плюсы:
медиана менее чувствительна к выбросам, чем среднее арифметическое, и более устойчива к влиянию нескольких экстремальных значений.
медиану легче посчитать для больших датасетов, особенно если база данных проиндексирована и отсортирована правильно. Например, при анализе времени отклика веб-сайта с миллионами пользователей найти медианное значение будет быстрее и эффективнее, чем считать среднее арифметическое.
Минусы:
медиана не дает никакой информации о разбросе данных или о том, насколько изменчивы эти значения.
В общем, отдавать предпочтение медиане или среднему — это зависит от качества выборки. Когда в данных значительное количество выбросов в положительную или отрицательную сторону, медиана искажается не так сильно, как среднее значение. Ну и медиана в некоторых случаях считается быстрее.
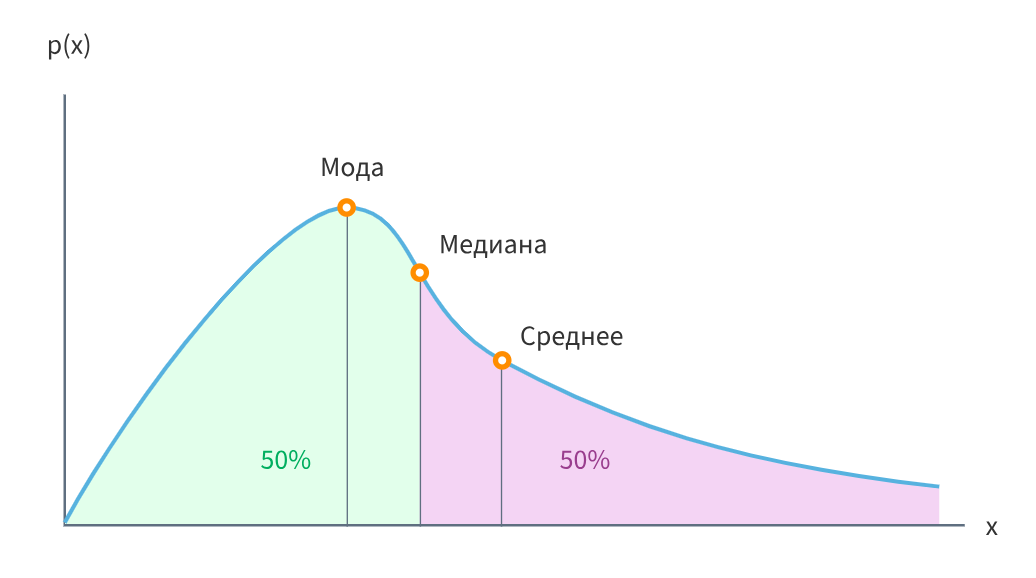
В чём разница между модой, медианой и матожиданием
Мода - это значение, которое встречается наиболее часто в наборе данных. Если есть несколько значений, которые встречаются одинаковое количество раз и чаще всего, то набор данных считается мультимодальным. Мода полезна для определения наиболее типичного значения в наборе данных.
Медиана - это среднее значение, которое разделяет набор данных на две равные части. Для нахождения медианы, данные сортируются по возрастанию или убыванию, и значение, находящееся посередине, выбирается в качестве медианы. Если набор данных имеет четное количество значений, то медиана будет средним значением двух центральных значений.
Математическое ожидание (среднее значение) - это сумма всех значений в наборе данных, деленная на количество значений. Математическое ожидание представляет собой среднее значение, которое можно использовать для оценки центральной тенденции данных. Оно чувствительно к выбросам и может быть искажено экстремальными значениями.
Предположим, у нас есть следующий набор данных: {2, 4, 6, 6, 8}
Мода — 6, так как оно встречается наиболее часто в наборе данных.
Медиана — отсортируем данные по возрастанию: 2, 4, 6, 6, 8. Значение, находящееся посередине, является медианой, это 6.
Математическое ожидание — суммируем все значения и делим на их количество: (2 + 4 + 6 + 6 + 8) / 5 = 5.2 — это и есть математическое ожидание.
Если распределение симметричное, то мода, математическое ожидание и медиана совпадают. А вот при асимметрии распределения медиана смещается от моды в сторону более длинного «хвоста». При этом медиана всегда меньше математического ожидания.
Секция "SQL"

В чем заключается разница между MySQL и SQL Server?
Давайте сразу к сути, вот в этой табличке можно увидеть все важные отличия:
MySQL |
SQL Server |
|
|---|---|---|
Что это |
Система управления реляционными базами данных с открытым исходным кодом от Oracle. |
Собственная система управления реляционными базами данных от Microsoft. |
Поддержка различных платформ |
MySQL поддерживает больше платформ, чем SQL Server. |
Microsoft SQL Server поддерживает меньше платформ, чем MySQL. |
Поддержка языков программирования |
MySQL поддерживает больше языков программирования, чем SQL Server, например Perl и Haskel. |
SQL Server поддерживает меньше языков программирования, чем MySQL. |
Возможности |
В MySQL имеется более широкий спектр коннекторов и интеграций от сторонних производителей. |
SQL Server позволяет фильтровать сразу несколько баз данных. Можно также остановить запрос, не завершая весь процесс. |
Возможности масштабирования |
В MySQL предусмотрены функции, которые делают его масштабируемым, но не в такой степени, как SQL Server. |
SQL Server использует сжатие, расширенное разделение и технологию in-memory для обеспечения высокомасштабируемой среды. |
Производительность |
MySQL использует пул соединений и кэширование запросов для обеспечения высокой производительности. |
При работе в масштабируемой среде SQL Server реагирует лучше, чем MySQL. |
Язык и синтаксис запросов |
MySQL использует SQL в качестве языка запросов и употребляет в своем синтаксисе обратные кавычки. |
SQL Server использует SQL в качестве языка запросов и употребляет двойные кавычки в своем синтаксисе. |
Коннекторы и интеграции |
Для MySQL предусмотрено большее количество интеграций, чем для SQL Server. |
В SQL Server существует больше интеграций с продуктами Microsoft. |
Поддержка и документация по продукту |
MySQL – это система с открытым исходным кодом. |
SQL Server – это собственное платное программное обеспечение. |
Возможности безопасности |
С помощью MySQL можно редактировать базы данных во время выполнения. |
В SQL Server нельзя редактировать файлы или получать к ним доступ во время выполнения. |
Ну вот и всё, собственно, это самые основные различия между MySQL и SQL Server.
Что делает UNION? В чем заключается разница между UNION и UNION ALL?
В языке SQL операция UNION применяется для объединения двух наборов строк, возвращаемых SQL-запросами. Оба запроса должны возвращать одинаковое число столбцов, и столбцы с одинаковым порядковым номером должны иметь совместимые типы данных.

Скажем, у нас есть вот такие 2 таблицы sales2005 и sales2006.
При выполнении такого SQL-запроса
(SELECT * FROM sales2005)
UNION
(SELECT * FROM sales2006);
получается результирующий набор, однако порядок строк может произвольно меняться, поскольку ключевое выражение ORDER BY не было использовано:

В результате отобразятся две строки с Иваном, так как эти строки различаются значениями в столбцах. Но при этом в результате присутствует лишь одна строка с Алексеем, поскольку значения в столбцах полностью совпадают.
Применение UNION ALL дает другой результат, так как дубликаты не скрываются. Выполнение запроса:
(SELECT * FROM sales2005)
UNION ALL
(SELECT * FROM sales2006);
даст следующий результат, выводимый без упорядочивания ввиду отсутствия выражения ORDER BY:

Итак, подводя итог, между UNION и UNION ALL такие отличия
UNION:
Оператор UNION объединяет результаты запросов и удаляет дублирующиеся строки из результирующего набора.
Если два запроса в операторе UNION возвращают одинаковые строки, то в результирующем наборе будет только одна копия этих строк.
UNION ALL:
Оператор UNION ALL также объединяет результаты запросов, но не удаляет дублирующиеся строки.
Если два запроса в операторе UNION ALL возвращают одинаковые строки, то в результирующем наборе будут присутствовать обе копии этих строк.
Как оптимизировать SQL-запросы?
Если сразу перейти к ответу, то вот пара практических приёмов.
Используйте индексы: Убедитесь, что у вас есть индексы на столбцах, которые часто используются в условиях WHERE и JOIN. Использование правильных индексов может значительно ускорить выполнение запросов.
Избегайте использования символьных функций в условиях: Использование функций, таких как LIKE, с паттернами, начинающимися с символов, может замедлить выполнение запросов из-за невозможности использования индексов.
Ограничение выборки: Получайте только те столбцы, которые действительно нужны. Используйте SELECT только для необходимых столбцов, а не для всех.
Избегайте использования подзапросов, где это возможно: Иногда, использование JOIN может быть более эффективным, чем подзапросы.
Используйте EXPLAIN: Используйте инструменты, такие как EXPLAIN (в зависимости от вашей СУБД), чтобы понять, как СУБД выполняет запрос, и узнать, где возможны улучшения.
Вот ещё несколько советов, часть перекликается с приёмами выше.
1. Выберите правильный тип данных для столбца
Каждый столбец таблицы в SQL имеет связанный тип данных. Вы можете выбирать из целых чисел, дат, переменных, логических значений, текста и т.д. При разработке важно выбрать правильный тип данных. Числа должны быть числового типа, даты должны быть датами и т.д. Это чрезвычайно важно для индексации. Взглянем сюда:
SELECT employeeID, employeeName
FROM employee
WHERE employeeID = 13412;
Этот запрос извлекает идентификатор и имя сотрудника с идентификатором 13412. Что, если тип данных для employeeID — строка? Вы можете столкнуться с проблемами при использовании индексации, поскольку это займет много времени, когда это должно быть простое сканирование.
2. Табличные переменные и объединения
Когда у вас есть сложные запросы, такие как получение заказов для клиентов, вместе с их именами и датами заказа, вам нужно нечто большее, чем простой оператор выбора. В этом случае мы получаем данные из таблиц клиентов и заказов. Вот где вступают в силу объединения. Глянем на пример соединения:
SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderDate
FROM Orders
INNER JOIN Customers ON Orders.CustomerID=Customers.CustomerID;
Табличные переменные — это локальные переменные, которые временно хранят данные и обладают всеми свойствами локальных переменных. Не используйте табличные переменные в объединениях, как SQL видит их как одну строку. Несмотря на то, что они быстрые, табличные переменные плохо работают в соединениях.
3. Используйте условное предложение WHERE
Условные предложения WHERE используются для подмножества. Допустим, у вас есть такая ситуация:
- if SEQ_VAR in (1, 2, 3) & diff(DATE_VAR2, DATE_VAR1) ≥ 0
— elif SEQ_VAR in (4, 5, 6) & diff(DATE_VAR2, DATE_VAR1) ≥1
— else diff(DATE_VAR2, DATE_VAR1) ≥2
С условным предложением WHERE это будет выглядеть так:
SELECT
DAT.ID_VAR,
DAT.SEQ_VAR,
DAT.NUM_VAR,
DATE_VAR1,
DATE_VAR2,
TRUNC(DATE_VAR2) - TRUNC(DATE_VAR1) AS LAG_IN_DATES
FROM
CURRENT_TABLE DAT
WHERE
(TRUNC(DATE_VAR2) - TRUNC(DATE_VAR1)) >= CASE WHEN SEQ_VAR IN (1,2,3) THEN 0 WHEN SEQ_VAR IN (4,5,6) THEN 1 ELSE 2 END
ORDER BY ID_VAR, SEQ_VAR
4. Используйте SET NOCOUNT ON
При выполнении операций INSERT, SELECT, DELETE и UPDATE, используйте SET NOCOUNT ON. SQL всегда возвращает соответствующее количество строк для таких операций, поэтому, когда у вас есть сложные запросы с большим количеством соединений, это может повлиять на производительность.
С SET NOCOUNT ON SQL не будет подсчитывать затронутые строки и улучшить производительность.
В этом примере ниже мы предотвращаем отображение сообщения о количестве затронутых строк.
USE AdventureWorks2012;
GO
SET NOCOUNT OFF;
GO
-- Display the count message.
SELECT TOP(5)LastName
FROM Person.Person
WHERE LastName LIKE 'A%';
GO
-- SET NOCOUNT to ON to no longer display the count message.
SET NOCOUNT ON;
GO
SELECT TOP(5) LastName
FROM Person.Person
WHERE LastName LIKE 'A%';
GO
-- Reset SET NOCOUNT to OFF
SET NOCOUNT OFF;
GO
5. Избегайте ORDER BY, GROUP BY и DISTINCT
Использование ORDER BY, GROUP BYи DISTINCT только в случае необходимости. SQL создает рабочие таблицы и помещает туда данные. Затем он организует данные в рабочей таблице на основе запроса и затем возвращает результаты.
6. Полностью уточняйте имена объектов базы данных
Цель использования полностью определенных имен объектов базы данных — устранить двусмысленность. Полное имя объекта выглядит так:
DATABASE.SCHEMA.OBJECTNAME.
Когда у вас есть доступ к нескольким базам данных, схемам и таблицам, становится важным указать, к чему вы хотите получить доступ. Вам не нужно этого делать, если вы не работаете с большими базами данных с несколькими пользователями и схемами, но это хорошая практика.
Поэтому вместо использования такого оператора:
SELECT * FROM TableName
Вам следует использовать:
SELECT * FROM dbo.TableName
7. Узнайте, как полностью защитить свой код
Базы данных хранят всевозможную информацию, что делает их основными целями атак. Распространенные атаки включают SQL-инъекции, когда пользователь вводит инструкцию SQL вместо имени пользователя и извлекает или изменяет вашу базу данных. Примеры SQL-инъекций:
textuserID = getRequestString("userID");
textSQL = "SELECT * FROM Users WHERE userID = " + textuserID;
Допустим, у вас есть это, вы textuserIDполучите ввод от пользователя. Вот как это может пойти не так:
SELECT * FROM Users WHERE userID = 890 OR 1=1;
Поскольку 1=1 всегда верно, он будет извлекать все данные из таблицы Users.
Вы можете защитить свою базу данных от SQL-инъекций, используя параметризованные операторы, проверки ввода, очистку ввода и т. Д. Как вы защищаете свою базу данных, зависит от СУБД. Вам нужно будет разобраться в своей СУБД и ее проблемах безопасности, чтобы вы могли писать безопасный код.
8. используйте LAG и LEAD для последовательных строк
Функция LAG позволяет запрашивать более одной строки в таблице одновременно без необходимости присоединяться к таблице. Она возвращает значения из предыдущей строки таблицы.
LAG(expression [,offset[,default_value]]) OVER(ORDER BY columns)
Функция LEAD делает то же самое, но и для следующей строки.
LEAD(expression [,offset[,default_value]]) OVER(ORDER BY columns)
Отказ от использования самостоятельных соединений повышает производительность, поскольку уменьшается количество операций чтения. Но, вы должны проверить, как LEAD и LAG влияют на производительность запросов.
Хорошая статья по оптимизации SQL-запросов
Выведите список сотрудников с зарплатой выше, чем у руководителя
Сразу напишем этот SQL-запрос:
SELECT a.*
FROM employee a, employee b
WHERE b.id = a.chief_id
AND a.salary > b.salary
Данный SQL-запрос выбирает все столбцы из таблицы "employee" для записей, где зарплата сотрудника больше зарплаты его начальника. Запрос использует две таблицы "employee a" и "employee b", где "b.id" равно "a.chief_id".
Этот запрос позволяет найти сотрудников, у которых зарплата выше, чем у их начальников. Он использует связь между таблицами "employee a" и "employee b" по полю "chief_id", чтобы сравнить зарплаты сотрудников и их начальников.
Например, если у нас такая таблица "employee":
id |
name |
chief_id |
salary |
|---|---|---|---|
1 |
John |
2 |
5000 |
2 |
Peter |
3 |
4000 |
3 |
Sarah |
NULL |
3000 |
4 |
Emily |
2 |
4500 |
то результатом выполнения данного запроса будет:
id |
name |
chief_id |
salary |
|---|---|---|---|
1 |
John |
2 |
5000 |
4 |
Emily |
2 |
4500 |
Таким образом, запрос выбирает сотрудников, у которых зарплата выше, чем у их начальников, и возвращает все столбцы для этих сотрудников.
Неплохое видео в тему, кстати — Карьера в DATA SCIENCE: TOP-50 Вопросов на собеседовании // PART 1
Какие оконные функции существуют?
В SQL есть пара оконных функций; они позволяют выполнять вычисления и агрегирование данных внутри определенного окна или группы строк. Их 3 группы: агрегирующие (сумма, количество, минимум...), ранжирующие, функции смещения. Вот основные:
-
ROW_NUMBER(): присваивает уникальный номер каждой строке внутри определенного окна
SELECT ROW_NUMBER() OVER (ORDER BY column_name) AS row_number, column_name FROM table_name;тут
ROW_NUMBER()присваивает уникальный номер каждой строке в столбцеcolumn_name, сортируя строки по возрастанию значения столбцаcolumn_name -
RANK(): присваивает ранг каждой строке внутри определенного окна на основе заданного порядка сортировки
SELECT RANK() OVER (ORDER BY column_name) AS rank, column_name FROM table_name;здесь функция
RANK()присваивает ранг каждой строке в столбцеcolumn_name, сортируя строки по возрастанию значения столбцаcolumn_name -
DENSE_RANK(): тоже присваивает ранг каждой строке внутри определенного окна на основе заданного порядка сортировки, но без пропусков в рангах
SELECT DENSE_RANK() OVER (ORDER BY column_name) AS dense_rank, column_name FROM table_name;тут
DENSE_RANK()присваивает ранг каждой строке в столбцеcolumn_name, сортируя строки по возрастанию значения столбцаcolumn_nameбез пропусков в рангах -
COUNT(): используется для подсчета количества строк внутри определенного окна
SELECT COUNT(column_name) OVER (PARTITION BY partition_column) AS count, column_name FROM table_name;здесь
COUNT()подсчитывает количество строк в столбцеcolumn_nameвнутри каждого раздела, заданного столбцомpartition_column -
SUM(): считает сумму значений столбца внутри окна
SELECT SUM(column_name) OVER (PARTITION BY partition_column) AS sum, column_name FROM table_name;тут
SUM()вычисляет сумму значений столбцаcolumn_nameвнутри каждого раздела, заданного столбцомpartition_column -
MAX(): используется для нахождения максимального значения столбца внутри определенного окна
SELECT MAX(column_name) OVER (PARTITION BY partition_column) AS max, column_name FROM table_name;тут
MAX()находит максимальное значение столбцаcolumn_nameвнутри каждого раздела, заданного столбцомpartition_column -
MIN(): используется для нахождения минимального значения столбца внутри окна
SELECT MIN(column_name) OVER (PARTITION BY partition_column) AS min, column_name FROM table_name;тут мы находим минимальное значение столбца
column_nameвнутри каждого раздела, заданного столбцомpartition_column
Вообще, это не все оконные функции, их больше. А какие ещё функции вы знаете?)
Найдите список ID отделов с максимальной суммарной зарплатой сотрудников
Нужный SQL-запрос выглядит так:
WITH sum_salary AS
(SELECT department_id,
SUM(salary) salary
FROM employee
GROUP BY department_id)
SELECT department_id
FROM sum_salary a
WHERE a.salary = (SELECT MAX(salary)
FROM sum_salary)
Этот SQL-запрос выполняет несколько действий.
Первая часть с ключевым словом WITH создает временную таблицу sum_salary, которая содержит результаты агрегации. В данном случае она вычисляет сумму зарплат сотрудников для каждого отдела. Таким образом, во временной таблице будут два столбца: department_id и salary, где department_id - это идентификатор отдела, а salary - сумма зарплат всех сотрудников в этом отделе.
Затем осуществляется основной запрос:
SELECT department_id
FROM sum_salary a
WHERE a.salary = (SELECT MAX(salary)
FROM sum_salary)
В этой части запроса выбираются department_id из временной таблицы sum_salary, где salary равна максимальной зарплате, найденной во временной таблице sum_salary.
Вот в принципе и всё, этот SQL-запрос возвращает идентификаторы отделов, у которых сумма зарплат всех сотрудников является максимальной среди всех отделов.
В чём разница между CHAR и VARCHAR?
CHAR и VARCHAR - это два разных типа данных для хранения символьных строк в SQL. Вот их отличия:
CHAR:
CHAR используется для хранения фиксированной длины символьных строк.
Поэтому длина строки для CHAR всегда остается постоянной и занимает фиксированное количество памяти, даже если реальная строка короче.
Неиспользуемое пространство в конце строки заполняется пробелами или нулевыми символами. То есть, если определить столбец с типом CHAR(10) и внести в него значение "Hello", то оно будет сохранено как "Hello " (с пятью пробелами в конце).
VARCHAR:
VARCHAR используется для хранения переменной длины символьных строк.
Длина строки для VARCHAR может изменяться в зависимости от реальной длины внесенных данных.
Занимает только столько места, сколько нужно. Скажем, если определить столбец с типом VARCHAR(10) и внести в него значение "Hello", то оно будет сохранено как "Hello" (точно так же, никаких пробелов в конце)
Итого, разница между CHAR и VARCHAR:
Основное отличие в способе хранения данных. CHAR занимает фиксированное количество памяти, VARCHAR занимает только столько места, сколько нужно.
А вот так это можно использовать, простецкий пример:
CREATE TABLE users (
id INT,
name CHAR(10),
email VARCHAR(50)
);
INSERT INTO users (id, name, email) VALUES (1, 'John', 'john@example.com');
INSERT INTO users (id, name, email) VALUES (2, 'Jane', 'jane@example.com');
Тут мы создаем таблицу users с тремя столбцами: id типа INT, name типа CHAR(10) и email типа VARCHAR(50). И вставляем две строки данных в эту таблицу.
Выберите самую высокую зарплату, не равную максимальной зарплате из таблицы
Запрос, который нам нужен будет выглядеть как-то так:
SELECT MAX(salary)
AS Second_Highest_Salary
FROM employee
WHERE salary !=
(SELECT MAX(salary)
FROM employee)
Разберём, что тут происходит. Запрос выполняет поиск второй по величине зарплаты среди сотрудников в таблице employee. Запрос состоит из двух частей:
-
Внешний запрос:
Используется функция
MAX(salary)для нахождения максимальной зарплаты среди всех сотрудников.Результат этого запроса будет называться "Second_Highest_Salary"
-
Внутренний запрос:
Используется функция
MAX(salary)для нахождения максимальной зарплаты среди всех сотрудников.Этот запрос используется в условии
WHERE salary != (SELECT MAX(salary) FROM employee), чтобы исключить сотрудников с максимальной зарплатой из результата внешнего запроса.
Таким образом, результатом выполнения данного запроса будет вторая по величине зарплата среди всех сотрудников в таблице employee.
Ну а работает запрос как-то так. Скажем, в таблице employee такие записи:
employee_id |
salary |
|---|---|
1 |
5000 |
2 |
6000 |
3 |
4000 |
4 |
7000 |
5 |
3000 |
Тогда результат будет:
Second_Highest_Salary |
|---|
6000 |
Чем отличаются SQL и NoSQL?
Зачем этот вопрос тут? Ну, это очень здорово, когда разраб не привязан к одной технологии и понимает, что не SQL единым. В некоторых ситуациях лучше использовать NoSQL-решения, гибкость и умение выбирать стек с учётом задачи поднимает разработчика в топ.
Начнём пожалуй с плюсов SQL:
Базы данных SQL просты в использовании. Даже люди, не имеющие опыта работы с базами данных, могут научиться использовать базы данных SQL, пройдя небольшое обучение.
Они очень универсальны и могут использоваться для любых целей - от небольших персональных до крупных корпоративных баз данных, нуждающихся в хранении данных.
Базы данных SQL надежны. Они предназначены для обработки больших объемов данных и транзакций без потери или повреждения базы данных. Если в них используется распределенная база данных, это может обеспечить безопасность. В распределенной базе данных подобные базы данных находятся в разных местах.
Их можно масштабировать. Их можно легко расширить, чтобы вместить больше данных и пользователей по мере необходимости. Вы получаете больше места для хранения данных.
Большинство крупных поставщиков баз данных поддерживают базы данных SQL. Это означает, что у предприятий есть много вариантов, когда дело доходит до выбора базы данных SQL.
Их поддерживает сильное сообщество разработчиков. Это сообщество обеспечивает поддержку и ресурсы для предприятий и частных лиц, использующих базы данных SQL.
Какие же отличия между SQL и NoSQL?
Базы данных SQL - это реляционные базы данных. Это означает, что данные организованы в таблицы, и каждая таблица имеет определенную структуру. Таблицы связаны друг с другом посредством отношений. Это делает базы данных SQL очень мощными для хранения данных, доступ к которым должен осуществляться определенным образом.
Базы данных NoSQL - это нереляционные базы данных. Это означает, что данные хранятся в виде набора документов. У этих документов нет определенной структуры, и они не связаны друг с другом отношениями. Таким образом, они больше подходят для хранения данных, к которым не нужно обращаться определенным образом.
Одно из основных различий между базами данных SQL и NoSQL заключается в способе масштабирования. Базы данных SQL используют вертикальное масштабирование, то есть они масштабируются за счет увеличения мощности сервера. Базы данных NoSQL используют горизонтальное масштабирование, то есть они масштабируются путем добавления большего количества серверов.
Еще одно различие заключается в том, что базы данных SQL обычно дороже в обслуживании, чем базы данных NoSQL. Базы данных SQL требуют большего администрирования, например, создания и поддержки индексов и представлений. Базы данных NoSQL зачастую менее затратны, так как требуют меньше администрирования.
Базы данных SQL также обычно более сложны, чем базы данных NoSQL. Это связано с тем, что базы данных SQL должны следовать правилам ACID (атомарность, согласованность, изоляция и долговечность), что может сделать их более медленными и сложными. С другой стороны, базы данных NoSQL часто более просты и могут быть быстрее, поскольку им не нужно следовать правилам ACID.
С SQL-решениями все знакомы, поэтому приведу примеры популярных NoSQL БД:
MongoDB - популярная база данных NoSQL. Это документо-ориентированная база данных, простая в использовании и масштабируемая. MongoDB также очень гибкая, позволяющая хранить широкий спектр типов данных. Они могут работать с большими данными.
Cassandra - еще одна популярная база данных NoSQL. Это база данных, ориентированная на столбцы, которая разработана для обеспечения высокой доступности и масштабируемости. Cassandra часто используется для хранения больших объемов данных.
HBase - это база данных, ориентированная на столбцы, построенная на основе файловой системы Hadoop. HBase разработана для масштабируемости и производительности. HBase часто используется для анализа данных в режиме реального времени.
Redis - это надежная база данных in-memory, которая часто используется для кэширования. Redis быстра и может использоваться для многих приложений.
Неплохое сравнение SQL и NoSQL на Хабре
В чём разница между DELETE и TRUNCATE?
И DELETE, и TRUNCATE используются для удаления данных из таблицы. Но они имеют большие отличия.
DELETE используется для удаления одной/нескольких строк из таблицы. Она является частью языка DML (Data Manipulation Language) и позволяет удалить строки, удовлетворяющие определенному условию.
DELETE FROM employees WHERE department = 'HR';
Здесь все строки из таблицы employees, где значение столбца department равно 'HR', будут удалены.
Команда TRUNCATE используется для удаления всех строк из таблицы. Она является частью языка DDL (Data Definition Language) и выполняет операцию над всей таблицей, а не над отдельными строками.
TRUNCATE TABLE employees;
Тут все строки из таблицы employees будут удалены.
И ещё различия между DELETE и TRUNCATE
Скорость выполнения: TRUNCATE выполняется быстрее, чем DELETE, потому что она не записывает каждую удаленную строку в журнал транзакций и не сохраняет возможность отката операции удаления. Это делает TRUNCATE более эффективным при удалении больших объемов данных.
Восстановление данных: DELETE можно отменить с помощью операции отката транзакции, в то время как TRUNCATE не может быть отменен. После выполнения TRUNCATE, данные будут потеряны без возможности их восстановления.
Ну и с связи с отличиями выше использование ресурсов: DELETE использует больше ресурсов, так как записывает каждую удаленную строку в журнал транзакций и может вызвать фрагментацию данных. TRUNCATE не записывает каждую удаленную строку и не вызывает фрагментацию данных.
Пронумеруйте строки в таблице employee
Нам нужен вот этот запрос:
SELECT ROW_NUMBER() over(ORDER BY id)
as id_num
FROM employee
Что же тут происходит?
Выбираем все строки из таблицы
employeeПрименяем функцию
ROW_NUMBER()для присвоения каждой строке уникального номера в порядке, определенном выражениемORDER BY idПереименовываем столбец с номерами строк в
id_numс помощью выраженияas id_num
Таким образом, данный запрос возвращает все строки из таблицы employee с дополнительным столбцом id_num, содержащим уникальные номера строк, отсортированные по значению столбца id
Вот в целом и всё.
Пронумеруйте строки в таблице в разрезе отдела по зарплате
Сразу напишем нужный SQL-запрос, вот он:
SELECT ROW_NUMBER() over (PARTITION BY department ORDER BY salary) salary_num FROM employee
Этот SQL-запрос выполняет нумерацию (назначает номера) для каждой записи в таблице employee в зависимости от их зарплаты внутри каждого отдела.
-
ROW_NUMBER() over (PARTITION BY department ORDER BY salary):ROW_NUMBER()- это оконная функция, которая назначает уникальный номер (последовательный) для каждой строки в каждой группе результатов.OVER- используется для определения оконной рамки для функции.PARTITION BY department- это указывает, что операцияROW_NUMBER()будет выполняться отдельно для каждого уникального значения в столбцеdepartmentORDER BY salary- определяет порядок, в котором будут назначены числа внутри каждой группы - зарплаты будут упорядочены по возрастанию.
-
salary_num FROM employee:salary_num- это название, под которым будут возвращены назначенные номера.FROM employee- указывает, что данные берутся из таблицыemployee
Таким образом, данный запрос вернет таблицу, в которой каждая строка будет содержать уникальный номер (последовательный) для каждой записи в каждом отделе в зависимости от их зарплаты, упорядоченной по возрастанию.
В целом, запрос довольно простой и несложный, думаю, с ним всё понятно.
Какие есть уровни изоляции транзакций?

Что ж, в SQL официально существуют различные уровни изоляции транзакций, которые определяют, как одна транзакция видит изменения, внесенные другими транзакциями. Вот они:
Read Uncommitted (Чтение неподтвержденных данных): Этот уровень изоляции позволяет транзакции видеть изменения, внесенные другими транзакциями, даже если они еще не были подтверждены. Это самый низкий уровень изоляции и может привести к проблемам, таким как "грязное чтение" и "неповторяющееся чтение".
Read Committed (Чтение подтвержденных данных): Этот уровень изоляции позволяет транзакции видеть только подтвержденные изменения других транзакций. Это означает, что транзакция не будет видеть изменения, которые еще не были подтверждены другими транзакциями. Однако, другие транзакции могут вносить изменения в данные, которые уже были прочитаны текущей транзакцией, что может привести к проблеме "неповторяющегося чтения".
Repeatable Read (Повторяемое чтение): Этот уровень изоляции гарантирует, что транзакция будет видеть одни и те же данные при повторном чтении в рамках той же транзакции. Другие транзакции не смогут вносить изменения в данные, которые уже были прочитаны текущей транзакцией. Однако, другие транзакции могут вносить новые данные, которые будут видны текущей транзакции.
Serializable (Сериализуемость): Этот уровень изоляции обеспечивает полную изоляцию транзакций. Он гарантирует, что транзакция будет видеть данные так, как если бы она работала в изоляции, то есть так, как если бы она была единственной транзакцией, работающей с данными. Это предотвращает проблемы "грязного чтения", "неповторяющегося чтения" и "фантомного чтения".
Каждая СУБД может иметь свои собственные реализации и названия для этих уровней изоляции. Например, в SQL Server они называются "Read Uncommitted", "Read Committed", "Repeatable Read" и "Serializable".
В PostgreSQL они называются "Read Uncommitted", "Read Committed", "Repeatable Read" и "Serializable".
Давайте перейдём к практике. Вот пример использования уровня изоляции транзакций в SQL Server:
SET TRANSACTION ISOLATION LEVEL <уровень изоляции>
BEGIN TRAN
-- Ваш код транзакции
COMMIT
Скажем, чтобы установить уровень изоляции "Read Uncommitted", можно написать такой запрос:
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
BEGIN TRAN
-- Ваш код транзакции
COMMIT
Attention: уровень изоляции может быть установлен только в начале транзакции и будет действовать до ее завершения.
Это была самая суть по уровням изоляции, а вообще тема довольно глубокая.
Годнота с Хабр — Уровни изоляции транзакций с примерами на PostgreSQL
Секция "Python"
Кто знает, откуда картинка?

Как ни крути, рабочая лошадка для Data Science — это Python (вообще ещё есть R с Julia). Поэтому понимать свой рабочий инструмент крайне важно. Недавно я опубликовал статью 100 вопросов для подготовки к собесу Python — если вы ориентируетесь во всех этих вопросах, то скорее всего проблем с Python у вас нет.
Разумеется, в DS используется не сырой питон — он уже давно оброс классными библиотеками: NumPy, Pandas, SciPy, Matplotlib, Seaborn, Plotly, Scikit Learn. Ну и всякие TensorFlow и PyTorch для Machine Learning. Овладевание этими либами сильно упростит работу и повысит ваш уровень дата-сайнтиста.
Ну а здесь, в этой секции, давайте затронем более специализированные вопросы по Python, вопросы, довольно сильно связанные с DS.
Какие отличия есть у Series и DataFrame в Pandas?
Сперва пару слов о Series.
Тип данных Series в библиотеке Pandas представляет собой одномерный массив с метками, который может содержать данные различных типов, таких как числа, строки, булевы значения и т.д. Series похож на простой словарь типа dict, где имя элемента будет соответствовать индексу, а значение – значению записи.
Ну и вот так мы можем работать с Series.
Создание Series из списка:
import pandas as pd
data = [10, 20, 30, 40, 50]
series = pd.Series(data)
print(series)
# вывод
# 0 10
# 1 20
# 2 30
# 3 40
# 4 50
# dtype: int64
Создание Series из словаря:
import pandas as pd
data = {'a': 10, 'b': 20, 'c': 30}
series = pd.Series(data)
print(series)
# вывод
# a 10
# b 20
# c 30
# dtype: int64
Для Series существует множество разных методов:
head() — возвращает первые несколько элементов
tail() — возвращает последние несколько элементов
describe() — возвращает основные статистические характеристики Series, такие как среднее значение, стандартное отклонение и т.д.
value_counts() — возвращает количество уникальных значений
sort_values() — сортирует значения
mean() — возвращает среднее значение
sum() — возвращает сумму
max() — возвращает максимальное значение
min() — возвращает минимальное
Теперь про DataFrame.
DataFrame - это одна из основных структур данных в библиотеке Pandas для анализа данных на языке Python. Это двумерная таблица с метками строк и столбцов, где каждый столбец может содержать разные типы данных.
Создавать DataFrame можно например так:
Создание DataFrame из списка списков:
import pandas as pd
data = [['Alice', 25], ['Bob', 30], ['Charlie', 35]]
df = pd.DataFrame(data, columns=['Name', 'Age'])
print(df)
# вывод:
# Name Age
# 0 Alice 25
# 1 Bob 30
# 2 Charlie 35
Создание DataFrame из словаря:
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie'], 'Age': [25, 30, 35]}
df = pd.DataFrame(data)
print(df)
# вывод:
# Name Age
# 0 Alice 25
# 1 Bob 30
# 2 Charlie 35
Для DataFrame есть масса методов, вот основные:
head() — возвращает первые несколько строк DataFrame
tail() — возвращает последние несколько строк
info() — выводит информацию о DataFrame, включая типы данных и количество ненулевых значений
describe() — возвращает статистическую сводку для числовых столбцов DataFrame
shape — возвращает размерность DataFrame в виде кортежа (количество строк, количество столбцов).
columns — возвращает список названий столбцов
index — возвращает индексы строк
loc[] — индексация по меткам строк и столбцов
iloc[] — индексация по целочисленным позициям строк и столбцов
dropna() — удаляет строки или столбцы с отсутствующими значениями
fillna() — заполняет отсутствующие значения определенным значением или стратегией
groupby() — группирует данные по заданному столбцу или набору столбцов
merge() — объединяет два DataFrame по заданному столбцу или набору столбцов
Ну и наконец, сравним Series и DataFrame:
Series |
DataFrame |
|
|---|---|---|
Структура данных |
Одномерный массив с метками (индексами) |
Двумерная таблица с метками (индексами) для строк и столбцов |
Размерность |
Одномерный |
Двумерный |
Индексация |
Имеет только один индекс, который может быть задан явно или автоматически создан |
Имеет два индекса: индекс строк и индекс столбцов, которые могут быть заданы явно или автоматически созданы |
Структура данных в памяти |
Хранит только один столбец данных и индексы |
Хранит несколько столбцов данных и два индекса |
Создание |
Можно создать из списка, массива, словаря или другой Series |
Можно создать из списка, массива, словаря или другого DataFrame |
Применение функций |
Можно применять функции к каждому элементу Series |
Можно применять функции к каждому столбцу или строке DataFrame |
Объединение данных |
Нельзя объединять несколько Series в один объект без создания DataFrame |
Можно объединять несколько DataFrame в один объект |
Кроме того, в DataFrame есть дополнительные возможности, такие как группировка данных, агрегирование, сортировка, фильтрация и многие другие, которых нет в Series.
Если остались вопросы, я отсылаю к замечательной документации
Напишите функцию, которая определяет количество шагов для преобразования одного слова в другое
Интересное задание, наша функция должна принимать на вход 3 аргумента:
begin_word = "same"
end_word = "cost"
word_list = ["same", "came"," case", "cast", "lost", "last", "cost"]
И при таких аргументах наша функция shortest_transformation должна возвращать 5, потому что на основе данного списка получить 'cost' из 'same' можно минимум за 5 шагов.
def shortest_transformation(begin_word, end_word, word_list) -> 5
Поскольку последовательность преобразования будет такой:
'same' -> 'came' -> 'case' -> 'cast' -> 'cost'
Что ж, осталось запилить эту функцию. Какие есть варианты? Пишите)
В чём преимущества массивов NumPy по сравнению с (вложенными) списками python?

Основное преимущество массивов NumPy перед списками Python заключается в том, что NumPy использует более оптимизированную память и имеет более эффективные методы работы с массивами (из-за реализации на C), что делает его подходящим выбором для работы с большими объемами данных и научных вычислений.
Например, с NumPy вы можете выполнять бродкастинг (broadcasting), матричные операции и другие векторизованные вычисления с более высокой производительностью, чем при использовании вложенных списков.
Некоторые из основных преимуществ NumPy:
Более оптимизированная память, что позволяет NumPy работать быстрее с большим объемом данных
Встроенные методы для выполнения арифметических операций, таких как сумма и произведение, которые могут работать сразу над всеми элементами массивов.
Возможность выполнять матричные операции и другие векторизованные вычисления.
Простой синтаксис для выполнения операций над массивами.
Возможность конвертировать массивы NumPy в другие формы данных, такие как списки Python или таблицы Pandas.
Eсли вы работаете с массивами данных, над которыми нужно выполнять научные вычисления, то использование NumPy будет более предпочтительным вариантом, чем использование списков Python.
Вообще, это довольно большая тема, но на этом пока остановимся.
В чём отличие между map, apply и applymap в Pandas?
В библиотеке Pandas есть 3 метода: map(), apply() и applymap(), которые используются для модификации данных в DataFrame или Series. Отличие в том, как они работают с данными: целиком или строчно/постолбцово. Ещё отличие между ними в том, к чему можно их применять.
map() — только к Series
apply() и к Series, и к DataFrame
applymap() только к DataFrame.
map()- применяется только к объекту Series и выполняет операции поэлементно. Он принимает в качестве аргумента словарь, объект Series или функцию и применяет ее к каждому элементу Series.
import pandas as pd # 0 1
s = pd.Series([1, 2, 3]) # 1 2
print(s) # 2 3
# dtype: int64
print(s.map(lambda x: x * 2)) # 0 2
# 1 4
# 2 6
# dtype: int64
apply()- может быть применен как к объекту Series, так и к объекту DataFrame. При применении к объекту Series, он работает построчно или постолбцово и применяет функцию к каждому элементу или ряду/столбцу. При применении к объекту DataFrame, он также работает построчно или постолбцово, но применяет функцию к каждой строке или столбцу
import pandas as pd
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
print(df)
# A B
# 0 1 4
# 1 2 5
# 2 3 6
# построчное применение # A B
print(df.apply(lambda x: x * 2)) # 0 2 8
# 1 4 10
# 2 6 12
# постолбцовое применение
print(df.apply(lambda x: x.max())) # A 3
# B 6
# dtype: int64
applymap()- Этот метод применяется только к объекту DataFrame и выполняет операции поэлементно. Он принимает в качестве аргумента функцию и применяет ее к каждому элементу.
Кстати, applymap() скоро has been deprecated, поэтому use map instead, говорит Python.
import pandas as pd
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
print(df)
# A B
# 0 1 4
# 1 2 5
# 2 3 6
print(df.applymap(lambda x: x * 2)) # A B
# 0 2 8
# 1 4 10
# 2 6 12
Таким образом, map() применяется только к Series, apply() может быть применен как к Series, так и к DataFrame, а applymap() применяется только к DataFrame.
Самый простой способ реализовать скользящее среднее с помощью NumPy
Скользящее среднее (moving average, MA) — функция, значения которой равны некоторому среднему значению исходной функции за предыдущий период.
Вот например график исходной функции (синий) и его скользящая средняя (красная) с шириной окна n = 2
Самый простой способ реализовать скользящее среднее с помощью NumPy - использовать функцию np.convolve() для вычисления скользящего среднего. Как-то так:
import numpy as np
def moving_average(x, n):
weights = np.ones(n) / n
return np.convolve(x, weights, mode='valid')
x = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
n = 3
result = moving_average(x, n)
print(result)
# [2. 3. 4. 5. 6. 7. 8. 9.]
Тут мы определяем функцию moving_average(), которая принимает массив x и размер окна n. Функция использует np.convolve() для вычисления скользящего среднего с весами, равными 1/n. Режим 'valid' гарантирует, что результат будет иметь ту же длину, что и исходный массив.
Attention, в этом примере мы используем режим 'valid', который означает, что выходной массив будет иметь меньшую длину, чем исходный массив. Если вам нужно сохранить длину исходного массива, вы можете использовать режим 'same', но это потребует небольшой модификации кода.
Поддерживает ли Python регулярные выражения?
...если вы решили проблему при помощи регулярных выражений — теперь у вас две проблемы ©
Да, Python поддерживает использование регулярных выражений (regex). В стандартной библиотеке Python имеется модуль re, который предоставляет множество функций для работы с регулярными выражениями. Этот модуль позволяет выполнять различные операции, такие как поиск, замена, разбиение текста на подстроки и проверку совпадений с шаблоном регулярного выражения.
Вот, кстати, основные компоненты регулярных выражений, лично я довольно часто ими пользуюсь:
\w- соответствует всем символам "слов". Символы слов являются буквенно-цифровыми (a-z, A-Z символы и подчеркивание).\W- соответствует символам "не слов". Все, кроме буквенно-цифровых символов и подчеркивания.\d- соответствует символам "цифр". Любая цифра от 0 до 9.\D- символы "не цифр". Все, кроме с 0 до 9.\s- символы пробела, в т.ч. символы табуляции и разрывы строк.\S- всё, кроме пробелов..- любой символ, кроме разрыва строки.[A-Z]- символы в диапазоне; например,[A-E]будет соответствовать A, B, C, D и E.[ABC]- символы в заданном наборе; например,[AMT]будет соответствовать только A, M и T.[^ABC]- символы, отсутствующие в заданном наборе. Например,[^A-E]будет соответствовать всем символам, кроме A, B, C, D и E.+- одно или несколько вхождений предыдущего символа. Например,\w+вернет ABD12D в виде единственного соответствия вместо шести разных совпадений.*- ноль или более вхождений предыдущего символа. Например,b\w*соответствует полужирным частям в фразе b, bat, bajhdsfbfjhbe. В целом, он соответствует нулю или более символам "слова" после "b".{m, n}- не менее m и не более n вхождений предыдущего символа.{m,}будет соответствовать не менее m вхождений, и верхнего предела для совпадения не будет.{k}будет соответствовать точно k вхождениям предыдущего символа.?- ноль или одно вхождение предыдущего символа. Например, это может быть полезно при поиска двух вариантов написания для одной и той же работы. Например,/behaviou?r/будет соответствовать как behavior, так и behaviour.|- соответствует выражению до или после "pipe" символа. Например,/se(a|e)/соответствует как see, так и sea.^- ищет регулярное выражение в начале текста или в начале каждой строки, если включен многострочный флаг.$- ищет регулярное выражение в конце текста или в конце каждой строки, если включен многострочный флаг.\b- предыдущий символ соответствует, только если это граница слова.\B- предыдущий символ соответствует только в том случае, если граница слова отсутствует.(ABC)- это сгруппирует несколько символов вместе и запомнит подстроку, соответствующую им, для последующего использования. Это называется скобочной группой.(?:ABC)- это также объединяет несколько символов вместе, но не запоминает совпадение. Это незапоминаемая скобочная группа.\d+(?=ABC)- это будет соответствовать символу(-ам), предшествующему(?=ABC), только если за ним следуетABC. ЧастьABCне будет включена в массив совпадений. Часть\d- это всего лишь пример. Это может быть любая строка регулярного выражения.\d+(?!ABC)- это будет соответствовать символу(-ам), предшествующему(?!ABC), только если за ним не следуетABC. ЧастьABCне будет включена в массив совпадений. Часть\d- это всего лишь пример. Это может быть любая строка регулярного выражения.
Для работы с регулярными выражениями в Python обычно используются строковые литералы с префиксом r (raw string), которые позволяют использовать специальные символы без экранирования. Например, регулярное выражение для поиска слов, начинающихся на "a" и заканчивающихся на "b", может быть записано так:
import re
text = "apple and banana are fruits, but apricot is not"
pattern = r"\ba\w*b\b"
matches = re.findall(pattern, text)
print(matches) # output: ['apple', 'apricot']
Здесь функция re.findall() выполняет поиск всех совпадений с шаблоном регулярного выражения pattern в строке text и возвращает список найденных подстрок.
Продолжи: "try, except, ..."
Существует try — except — finally и есть try — except — else. И даже можно объединить:
try:
... # попробует сделать это
except:
... # обработка исключения
else:
... # выполнится, если не выполнился except
finally:
... # выполнится всегда
Ну вот собственно и всё
Как построить простую модель логистической регрессии на Python?
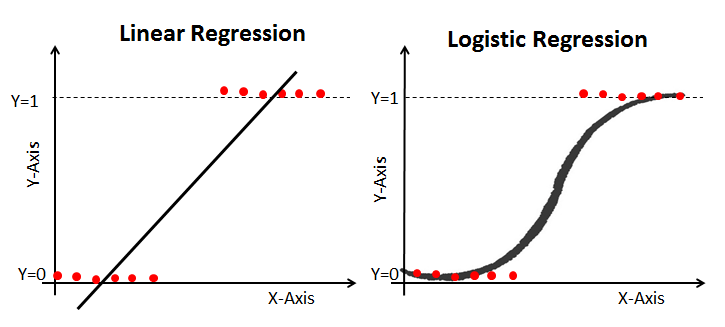
Логистическая регрессия - это метод машинного обучения, используемый для классификации данных. Он использует логистическую функцию для оценки вероятности принадлежности объекта к определенному классу.
Что ж, давайте применим логистическую регрессию для классификации тех самых ирисов.
Импортируем нужные библиотеки и грузим датасет:
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
# Загружаем набор данных Iris
iris = load_iris()
X = iris.data[:, :2] # берем только первые 2 признака
y = iris.target
Затем мы создаем экземпляр модели логистической регрессии с помощью LogisticRegression() и обучаем ее на наших данных с помощью fit()
# Создаем экземпляр модели логистической регрессии
clf = LogisticRegression(random_state=0)
# Обучаем модель на данных
clf.fit(X, y)
Теперь мы можем использовать обученную модель для предсказания класса новых данных:
# Предсказываем классы новых данных
new_data = np.array([[5.0, 3.0], [6.0, 4.0]])
print(clf.predict(new_data))
Здесь мы создаем массив new_data с двумя новыми наблюдениями и используем метод predict() для предсказания их классов.
Также мы можем визуализировать результаты, чтобы увидеть, как модель разделяет классы:
import matplotlib.pyplot as plt
# Создаем сетку точек для визуализации
xx, yy = np.meshgrid(np.arange(4, 8, 0.01), np.arange(1.5, 5, 0.01))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
# Визуализируем результаты
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, cmap=plt.cm.RdBu, alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.RdBu)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.title('Logistic Regression')
plt.show()
Здесь мы создаем сетку точек и используем метод predict() для предсказания класса каждой точки. Затем мы визуализируем результаты с помощью contourf() и scatter(), чтобы показать, как модель разделяет классы.

Вот примерно так можно использовать модель логистической регрессии.
Неплохое объяснение логистической регрессии от Loginom
Как выбрать строки из DataFrame на основе значений столбцов?
Другими словами, нам необходимо отфильтровать наш датафрейм и убрать некоторые строки.
Вначале создадим нужный датафрейм:
df = pd.DataFrame([[1, "A"], [2, "B"], [3, "C"]], columns = ["col1", "col2"])
print(df)
# col1 col2
# 0 1 A
# 1 2 B
# 2 3 C
Отфильтровать датафрейм мы можем так:
-
фильтрация по одному столбцу
print(df[df.col1>2]) # col1 col2 # 2 3 C -
фильтрация по нескольким столбцам
print(df[df.col1>1][df.col2 == "B"]) # col1 col2 # 1 2 B -
фильтрация из списка
print(df[df.col2.isin(["A", "B"])]) # col1 col2 # 0 1 A # 1 2 B -
использование
df.query()print(df.query('col1 > 2')) # col1 col2 # 2 3 C
Кстати, вот отличная шпаргалка с основами Pandas
И это — Моя шпаргалка по pandas
Как узнать тип данных элементов из массива NumPy?
Вообще, NumPy поддерживает такие типы данных:
i- целое числоS- строкаb- булево (логическое) значениеf- вещественное число (с плавающей точкой)u- целое число без знакакc- комплексное вещественное числоm- интервал времениM- дата/времяO- объектU- строка ЮникодаV- тип с фиксированным размером в памяти для штук типаvoid
Для того, чтобы посмотреть, какого же типа наши элементы в массиве, мы можем использовать dtype.
import numpy as np
arr1 = np.array([1, 2, 3, 4])
arr2 = np.array(['I', 'love', 'Interviewbit'])
arr3 = np.array([1, 2, 3, 4], dtype='S')
print(arr1.dtype) # int64
print(arr2.dtype) # <U12
print(arr3.dtype) # |S1
В чём отличие loc от iloc в Pandas?
loc и iloc - это атрибуты, в Pandas для доступа к данным в DataFrame или Series. В чём же они отличаются?
loc:
Используется для доступа по меткам (индексам) строк/столбцов.
Можно использовать метки строк и столбцов, а также срезы меток.
Включает последний элемент среза, если он существует.
Пример использования:
df.loc[row_label, column_label]илиdf.loc[row_label]для доступа к строке целиком.
iloc:
Используется для доступа к данным по целочисленным позициям строк и столбцов.
Можно использовать целочисленные позиции строк и столбцов, а также срезы позиций.
Исключает последний элемент среза, если он существует.
Пример использования:
df.iloc[row_position, column_position]илиdf.iloc[row_position]для доступа к строке целиком.
В общем, основное отличие между loc и iloc в том, что loc использует метки (индексы), а iloc использует целочисленные позиции для доступа к DataFrame/Series.
Скажем, пусть у нас такой DataFrame df:
Name Score
0 John 85
1 Anna 90
2 Peter 78
3 Linda 92
4 James 88
Сравните работу loc и iloc:
print(df.loc[1]) # Выводит строку с меткой (индексом) 1
# Output:
# Name Anna
# Score 90
# Name: 1, dtype: object
print(df.iloc[1]) # Выводит строку с позицией 1
# Output:
# Name Anna
# Score 90
# Name: 1, dtype: object
А вот так они работают со срезами:
print(df.loc[1:3]) # Выводит строки с метками (индексами) от 1 до 3 включительно
# Output:
# Name Score
# 1 Anna 90
# 2 Peter 78
# 3 Linda 92
print(df.iloc[1:3]) # Выводит строки с позициями от 1 до 3 (исключая 3)
# Output:
# Name Score
# 1 Anna 90
# 2 Peter 78
Напишите код, который строит все N-граммы на основе предложения
Вначале можно написать генератор биграмм — это сущий пустяк:
sentence = "Пример предложения для генерации N-грамм"
sentence = sentence.split()
bigrams = []
for n in range(len(sentence)-1):
bigrams.append((sentence[n], sentence[n+1]))
print(bigrams)
# [('Пример', 'предложения'), ('предложения', 'для'), ('для', 'генерации'), ('генерации', 'N-грамм')]
Ок, теперь обобщим это на случай N-грамм. Тоже не очень сложно
sentence = "Пример предложения для генерации N-грамм"
length = 3
sentence = sentence.split()
bigrams = []
for n in range(len(sentence)-(length-1)):
bigrams.append(sentence[n:n+length])
print(bigrams)
# [['Пример', 'предложения', 'для'], ['предложения', 'для', 'генерации'], ['для', 'генерации', 'N-грамм']]
При желании можно использовать всякие библиотечки, типо nltk:
from nltk import ngrams
def generate_ngrams(sentence, n):
words = sentence.split()
ngrams_list = list(ngrams(words, n))
return ngrams_list
sentence = "Пример предложения для генерации N-грамм"
n = 2
print(generate_ngrams(sentence, n))
# [('Пример', 'предложения'), ('предложения', 'для'), ('для', 'генерации'), ('генерации', 'N-грамм')]
Вот в принципе и всё с этим вопросом
Каковы возможные способы загрузки массива из текстового файла данных в Python?
В Python есть уйма способов загрузить текстовый массив, вот пара способов:
1 — numpy.loadtxt()
import numpy as np
data = np.loadtxt('filename.txt')
Эта функция загружает данные из текстового файла и создает массив data типа numpy.ndarray. По умолчанию она ожидает, что данные в файле будут разделены пробелами.
2 — numpy.genfromtxt()
import numpy as np
data = np.genfromtxt('filename.txt', delimiter=',')
Эта функция также загружает данные из текстового файла и создает массив data типа numpy.ndarray. Она позволяет указать разделитель данных, который может быть запятой, точкой с запятой или другим символом.
3 — pandas.read_csv()
import pandas as pd
data = pd.read_csv('filename.txt', delimiter=',')
Эта функция загружает данные из текстового файла и создает объект DataFrame типа pandas.DataFrame. Она также позволяет указать разделитель данных.
4 — csv.reader()
import csv
with open('filename.txt', 'r') as file:
reader = csv.reader(file)
data = [row for row in reader]
Эта функция загружает данные из текстового файла и создает список data, содержащий строки данных в виде списков. Она также позволяет указать разделитель данных.
5 — numpy.fromfile()
import numpy as np
data = np.fromfile('filename.txt', sep=' ')
Эта функция загружает данные из текстового файла и создает одномерный массив data типа numpy.ndarray. Она ожидает, что данные в файле будут разделены указанным символом.
Чем отличаются многопоточное и многопроцессорное приложение?
Многопоточное и многопроцессорное приложения отличаются друг от друга в том, как они используют ресурсы компьютера.
В многопроцессорных приложениях каждый процесс имеет свой собственный набор ресурсов, включая память, открытые файлы, сетевые соединения и другие системные ресурсы.
Многопроцессорность в Python может быть достигнута с помощью библиотек multiprocessing и concurrent.futures.
В многопоточных приложениях несколько потоков выполняются в рамках одного процесса, используя общие ресурсы. Это означает, что все потоки имеют доступ к общим данным.
Реализация многопоточности в Python выполняется за счет стандартной библиотеки threading.
При правильном использовании оба подхода могут ускорить выполнение программы и улучшить управляемость ею, однако многопоточное приложение может иметь проблемы с блокировками и условиями гонки при доступе к общим ресурсам. В многопроцессорных приложениях каждый процесс защищен от других процессов и обеспечивает более высокую степень изоляции.
Так выглядит многопоточность, потоки конкурируют за доступ к ресурсам, памяти и др. в рамках одного процесса
А так выглядит многопроцессорность

Отличное видео, объясняющее многопроцессорность
Как можно использовать groupby + transform?
Связка groupby и transform в Pandas позволяет выполнять групповые операции и применять функции к каждой группе данных. При этом сохраняется исходная структура DataFrame.
groupby группирует по 1 или нескольким столбцам. То есть мы можем сгруппировать данные по столбцу "категория" и получить отдельные группы данных для каждой категории.
transform применяет функцию к каждой группе данных и возвращает результат такого же размера и структуры, что и исходный DataFrame.
Пример: мы можем использовать команду transform для вычисления среднего значения каждой группы и добавления этого значения в новый столбец в исходном DataFrame.
import pandas as pd
data = {'Category': ['A', 'A', 'B', 'B', 'A', 'B'],
'Value': [1, 2, 3, 4, 5, 6]}
df = pd.DataFrame(data)
# Применяем группировку и трансформацию
df['Mean'] = df.groupby('Category')['Value'].transform('mean')
print(df)
# вывод
Category Value Mean
0 A 1 2.0
1 A 2 2.0
2 B 3 4.3
3 B 4 4.3
4 A 5 2.0
5 B 6 4.3
В данном примере мы сгруппировали данные по столбцу "Category" и применили функцию mean к столбцу "Value" в каждой группе. Результаты вычислений были добавлены в новый столбец "Mean" в исходном DataFrame.
Напишите финальные значения A0, ..., A7
Такое вот практическое задание, что ж, поехали.
A0 = dict(zip(('a','b','c','d','e'),(1,2,3,4,5)))
A1 = range(10)
A2 = sorted([i for i in A1 if i in A0])
A3 = sorted([A0[s] for s in A0])
A4 = [i for i in A1 if i in A3]
A5 = {i:i*i for i in A1}
A6 = [[i,i*i] for i in A1]
A7 = [i if i%2 else 0 for i in A1 if 2 < i < 8]
В целом, тут всё понятно, обычные list comprehensions, как по мне лучше начинать читать из с внутреннего for.
Можно разве что немного прокомментировать:
A0 —
zipпопарно читает кортежи и создаёт такие пары "ключ-значение":'a' : 1, 'b' : 2, ...A1 — просто диапазон от 0 до 9, но сейчас это именно что диапазон, а не список или что-то ещё
A2 — берём по элементу из A1, и если этот элемент есть в A0, то добавляем его в A2. Позже сортируем A2 по возрастанию
A3 — достаём значения словаря A0 по ключам из A0, сортируем
A4 — берём по элементу из A1, и если этот элемент есть в A3, добавляем в A4 этот элемент
А5 — создаём словарь со значениями, которые равны квадрату ключей. Ключи берём из A1
A6 — создаём списки в одном списке, каждый маленький список вида
[элемент, элемент**2]. Элементы берём из A1A7 — берём элементы из A1, если элемент из интервала (2, 8), то проверяем чётность элемента. Если элемент нечётный, то добавляем его в A7, иначе добавляем 0.
Чем отличаются mean() и average() в NumPy?
mean() и average() в NumPy - это две похожие функции, обе можно использовать для вычисления среднего арифметического. Но есть у них и отличия.
mean()
Функция mean() используется для вычисления среднего арифметического значения элементов массива. Она принимает один обязательный аргумент - массив, для которого нужно вычислить среднее значение. Функция возвращает среднее значение в виде скаляра. Используется mean() очевидным образом:
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
print(np.mean(arr)) # вывод: 3.0
average()
Функция average() предоставляет больше гибкости, так как позволяет указывать веса для каждого элемента массива. Функция принимает обязательный аргумент - массив, и необязательный аргумент weights, который указывает веса для каждого элемента массива. Если weights не указан, то все элементы массива считаются равновесными.
При использовании average() без указания весов мы будем просто получать среднее:
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
print(np.average(arr)) # вывод: 3.0
А вот при использовании average() с указанием весов вычисляется среднее взвешенное:
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
weights = np.array([0.1, 0.2, 0.3, 0.2, 0.2])
print(np.average(arr, weights=weights)) # вывод: 2.9
В общем, основное различие между mean() и average() в том, что mean() вычисляет среднее арифметическое значение элементов массива, в то время как average() позволяет указывать веса для каждого элемента массива (для вычисления среднее взвешенного).
Приведите пример использования filter и reduce над итерируемым объектом
Пример использования filter() и reduce() над итерируемым объектом в Python:
from functools import reduce
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# Пример использования filter() для отфильтровывания четных чисел
even_numbers = list(filter(lambda x: x % 2 == 0, numbers))
print(even_numbers) # выводит [2, 4, 6, 8, 10]
# Пример использования reduce() для нахождения суммы чисел от 1 до 10
sum_of_numbers = reduce(lambda x, y: x + y, numbers)
print(sum_of_numbers) # выводит 55
В этом примере мы использовали filter() для отбора только четных чисел в списке numbers, и reduce() для нахождения суммы всех чисел в списке от 1 до 10.
filter() принимает два аргумента - функцию-предикат и итерируемый объект. Он возвращает новый итератор, содержащий только те элементы итерируемого объекта,
которые удовлетворяют условиям, заданным функцией-предикатом.
reduce() также принимает два аргумента - функцию и итерируемый объект. Он выполняет функцию на каждой паре элементов из итерируемого объекта, образуя
редуцированное значение, которое в конечном итоге становится результатом функции.
В примере мы использовали reduce() для нахождения суммы всех чисел в
итерируемом объекте.
Как объединить два массива NumPy?
Не будем тянуть, можно начать сразу с полного списка всех фунций Numpy для объединения массивов.
-
np.concatenate: объединяет массивы вдоль указанной оси.
import numpy as np arr1 = np.array([1, 2, 3]) arr2 = np.array([4, 5, 6]) result = np.concatenate((arr1, arr2)) print(result) # Output: [1 2 3 4 5 6] -
np.vstack: объединяет массивы вертикально (по строкам).
import numpy as np arr1 = np.array([[1, 2, 3], [4, 5, 6]]) arr2 = np.array([[7, 8, 9], [10, 11, 12]]) result = np.vstack((arr1, arr2)) print(result) # Output: # [[ 1 2 3] # [ 4 5 6] # [ 7 8 9] # [10 11 12]] -
np.hstack: объединяет массивы горизонтально (по столбцам).
import numpy as np arr1 = np.array([[1, 2], [3, 4]]) arr2 = np.array([[5, 6], [7, 8]]) result = np.hstack((arr1, arr2)) print(result) # Output: # [[1 2 5 6] # [3 4 7 8]] -
np.dstack: объединяет массивы вдоль третьей оси (по глубине).
import numpy as np arr1 = np.array([1, 2, 3]) arr2 = np.array([4, 5, 6]) result = np.dstack((arr1, arr2)) print(result) # Output: # [[[1 4] # [2 5] # [3 6]]] -
np.column_stack: объединяет одномерные массивы вдоль второй оси (по столбцам). В общем, аналогичен
zip(), так же попарно объединяет массивы.import numpy as np arr1 = np.array([1, 2, 3]) arr2 = np.array([4, 5, 6]) result = np.column_stack((arr1, arr2)) print(result) # Output: # [[1 4] # [2 5] # [3 6]]print(list(zip([0, 1, 2, 3,], [4, 5, 6, 7]))) # => [(0, 4), (1, 5), (2, 6), (3, 7)] print(np.column_stack([arr1, arr2])) # => [[0 4] # [1 5] # [2 6] # [3 7]] -
np.row_stack: объединяет одномерные массивы вдоль первой оси (по строкам).
import numpy as np arr1 = np.array([1, 2, 3]) arr2 = np.array([4, 5, 6]) result = np.row_stack((arr1, arr2)) print(result) # Output: # [[1 2 3] # [4 5 6]] -
np.stack: объединяет массивы вдоль новой оси.
import numpy as np arr1 = np.array([1, 2, 3]) arr2 = np.array([4, 5, 6]) result = np.stack((arr1, arr2)) print(result) # Output: # [[1 2 3] # [4 5 6]] -
np.block: объединяет массивы произвольным образом.
import numpy as np arr1 = np.array([[1, 2], [3, 4]]) arr2 = np.array([[5, 6], [7, 8]]) result = np.block([[arr1], [arr2]]) print(result) # Output: # [[1 2] # [3 4] # [5 6] # [7 8]]
Что ж, на этом всё, это полный список функций в библиотеке Numpy для объединения массивов.
Напишите однострочник, который будет подсчитывать количество заглавных букв в файле
Для подсчета количества заглавных букв в файле можно использовать следующий однострочник:
num_uppercase = sum(1 for line in open('filename.txt') for character in line if character.isupper())
В этом однострочнике мы открываем файл 'filename.txt' и пробегаемся по всем его строкам и символам в каждой строке. Для каждого символа, который является заглавной буквой метод isupper() возвращает True, и мы добавляем 1 к счетчику с помощью функции sum(). В конце, num_uppercase будет содержать количество заглавных букв в файле.
Однострочники — это вообще очень приятная питонячая радость, есть даже целые книги (рекомендую, легко гуглится Кристиан Майер однострочники в Python filetype:pdf)
Как бы вы очистили датасет с помощью Pandas?

Для очистки возьмём реальный датасет, например цен на жилье в России с Kaggle (файл train.csv)
Перед очисткой можно взглянуть на датасет и поставить диагноз:
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.mlab as mlab
import matplotlib
plt.style.use('ggplot')
from matplotlib.pyplot import figure
matplotlib.rcParams['figure.figsize'] = (12,8)
pd.options.mode.chained_assignment = None
df = pd.read_csv('train.csv')
# shape and data types of the data
print(df.shape)
print(df.dtypes)
# отбор числовых колонок
df_numeric = df.select_dtypes(include=[np.number])
numeric_cols = df_numeric.columns.values
print(numeric_cols)
# отбор нечисловых колонок
df_non_numeric = df.select_dtypes(exclude=[np.number])
non_numeric_cols = df_non_numeric.columns.values
print(non_numeric_cols)
# (30471, 292)
# ...
Видим, что набор данных состоит из 30471 строки и 292 столбцов. Ну и ещё нам вывелась информация, , являются ли столбцы числовыми или категориальными признаками и всё такое.
1 проблемка реального датасета — отсутствующие даные
Обнаружить пропуски можно при помощи тепловой карты.
cols = df.columns[:30] # берём первые 30 колонок
# желтый - пропущенные данные, синий - не пропущенные
colours = ['#000099', '#ffff00']
sns.heatmap(df[cols].isnull(), cmap=sns.color_palette(colours))
plt.show()

Видите масштаб проблемы? Жёлтого довольно много, всё это — пропущенные значения.
Вместо тепловой карты можно составить список долей отсутствующих записей для каждого признака.
for col in df.columns:
pct_missing = np.mean(df[col].isnull())
print(f'{col} - {round(pct_missing*100)}')
# ...
# max_floor - 31
# material - 31
# build_year - 45
# ...
решение проблемы пропусков — отбрасываем пропущенные записи
Это решение подходит только в том случае, если недостающие данные не являются информативными. Мы можем создать новый набор данных df_less_missing_rows, в котором отбросим все строки, где больше 35 пропусков.
ind_missing = df[df['num_missing'] > 35].index
df_less_missing_rows = df.drop(ind_missing, axis=0)
решение проблемы пропусков — отбрасывание признаков (удаление столбцов)
Как и предыдущая техника, отбрасывание признаков может применяться только для неинформативных признаков. В процентном списке, построенном ранее, мы увидели, что признак hospital_beds_raion имеет высокий процент недостающих значений – 47%. Мы можем полностью отказаться от этого признака:
cols_to_drop = ['hospital_beds_raion']
df_less_hos_beds_raion = df.drop(cols_to_drop, axis=1)
решение проблемы пропусков — заполнение медианой
Для численных признаков можно воспользоваться методом принудительного заполнения пропусков. Например, на место пропуска можно записать среднее или медианное значение, полученное из остальных записей. Для категориальных признаков можно использовать в качестве заполнителя наиболее часто встречающееся значение. Возьмем для примера признак life_sq и заменим все недостающие значения медианой этого признака:
med = df['life_sq'].median()
print(med)
df['life_sq'] = df['life_sq'].fillna(med)
2 проблемка реального датасета — выбросы (нетипичные данные)
Для численных и категориальных признаков используются разные методы изучения распределения, позволяющие обнаружить выбросы. Если признак численный, можно построить гистограмму или коробчатую диаграмму (ящик с усами). Посмотрим на примере уже знакомого нам признака life_sq.
df['life_sq'].hist(bins=100)
Чтобы изучить особенность поближе, построим коробчатую диаграмму (boxplot).
df.boxplot(column=['life_sq'])
И сразу видим, что есть выброс со значением более 7000.
решение проблемы выбросов
Выбросы довольно просто обнаружить, но выбор способа их устранения слишком существенно зависит от специфики набора данных и целей проекта. Их обработка во многом похожа на обработку пропущенных данных, которую мы разбирали в предыдущем разделе. Можно удалить записи или признаки с выбросами, либо скорректировать их, либо оставить без изменений.
3 проблемка реального датасета — неинформативные признаки
Если признак имеет слишком много строк с одинаковыми значениями, он не несет полезной информации для проекта. Составим список признаков, у которых более 95% строк содержат одно и то же значение:
num_rows = len(df.index)
low_information_cols = []
for col in df.columns:
cnts = df[col].value_counts(dropna=False)
top_pct = (cnts/num_rows).iloc[0]
if top_pct > 0.95:
low_information_cols.append(col)
print('{0}: {1:.5f}%'.format(col, top_pct*100))
print(cnts)
print()
# oil_chemistry_raion: 99.02858%
# oil_chemistry_raion
# no 30175
# yes 296
# Name: count, dtype: int64
#
# railroad_terminal_raion: 96.27187%
# railroad_terminal_raion
# ...
решение проблемы неинформативных признаков — drop()
От неинформативных признаков лучше избавиться — выкидываем их из датасета при помощи drop().
Это не все проблемы, с реальными датасетами их больше. Например, это нерелевантные признаки, дубликаты строк, разные регистры символов, разные форматы данных (например дат), очепятки, адреса. Но методы анализа датасета выше могут пригодиться и в этих случаях.
Супер подробная статья об очистке и подготовке датасета
array и ndarray — в чём отличия?
В NumPy многомерные массивы можно создавать с помощью ndarray (N-мерный массив) и array. Есть некоторые отличия в их использовании, да и в целом, это разные средства NumPy.
ndarray (N-мерный массив):
ndarray(N-мерный массив) является основным объектом в NumPyэто многомерный массив элементов одного типа данных
ndarrayможет иметь любое количество измерений (осей) и форму (размеры по каждой оси)ndarrayможет содержать элементы различных типов данных, таких как целые числа, числа с плавающей запятой, комплексные числа и другиеndarrayобеспечивает эффективные операции над массивами, такие как математические операции, индексирование и срезы
Самые важные атрибуты объектов ndarray:
ndarray.ndim- число измерений (чаще их называют "оси") массива.ndarray.shape- размеры массива, его форма. Это кортеж натуральных чисел, показывающий длину массива по каждой оси. Для матрицы изnстрок иmстолбов,shapeбудет(n,m). Число элементов кортежаshapeравноndimndarray.size- количество элементов массива. Очевидно, равно произведению всех элементов атрибутаshapendarray.dtype- объект, описывающий тип элементов массива. Можно определить dtype, используя стандартные типы данных Python. NumPy здесь предоставляет целый букет возможностей, как встроенных, например:bool_,character,int8,int16,int32,int64,float8,float16,float32,float64,complex64,object_, так и возможность определить собственные типы данных, в том числе и составные.ndarray.itemsize- размер каждого элемента массива в байтах.ndarray.data- буфер, содержащий фактические элементы массива. Обычно не нужно использовать этот атрибут, так как обращаться к элементам массива проще всего с помощью индексов.
Очевидные примеры использования ndarray:
import numpy as np
a = np.array([1, 2, 3]) # одномерный массив
print(a)
# Вывод: array([1, 2, 3])
b = np.array([[1.5, 2, 3], [4, 5, 6]]) # двумерный массив
print(b)
# Вывод: array([[1.5, 2. , 3. ],
# [4. , 5. , 6. ]])
c = np.array([[1.5, 2, 3], [4, 5, 6]], dtype=np.complex) # массив с комплексными числами
print(c)
# Вывод: array([[1.5+0.j, 2.0+0.j, 3.0+0.j],
# [4.0+0.j, 5.0+0.j, 6.0+0.j]])
array:
arrayявляется альтернативным способом создания многомерных массивов в NumPyэто просто функция, которая принимает последовательность элементов и преобразует ее в многомерный массив
arrayможет принимать различные аргументы, такие как списки, кортежи или другие итерируемые объекты, и создавать соответствующий многомерный массивarrayможет принимать дополнительные аргументы, такие какdtype(тип данных элементов массива) иorder(порядок хранения элементов в памяти)
Пример использования array:
import numpy as np
data = [1, 2, 3, 4, 5]
arr = np.array(data) # создание массива из списка
print(arr)
# Вывод: array([1, 2, 3, 4, 5])
arr = np.array(data, dtype=np.float) # создание массива с указанием типа данных
print(arr)
# Вывод: array([1., 2., 3., 4., 5.])
Вот тут отличная теория по работе с массивами NumPy
Вычислите минимальный элемент в каждой строке 2D массива
Задание простое, его без проблем можно сделать, написав простой велосипед из цикла и чего-нибудь ещё. Но ведь у нас в NumPy есть функция apply_along_axis, с помощью неё можно делать что-то с каждой строкой/столбцом при помощи другой функции.
Итак, возьмём такой 2D массив a:
import numpy as np
np.random.seed(100)
a = np.random.randint(1, 10, [2, 3])
print(a)
# [[9 9 4]
# [8 8 1]]
Ну ок, а дальше мы просто применяем функцию apply_along_axis с 3 аргументами:
применяемая функция — конечно, будем тут использовать
lambdaнаш массив
что мы берём — столбцы или строки. Столбцы —
axis=0, строки —axis=1. Для многомерного массива выбор нужной оси осуществляется аналогично
mini = np.apply_along_axis(lambda x: np.min(x), arr=a, axis=1)
print(mini)
# [4 1]
Как проверить, является ли набор данных или временной ряд случайным?
Существует несколько статистических тестов, которые можно использовать для проверки случайности набора данных или временного ряда в Python. Рассмотрим некоторые из них:
Тест Колмогорова-Смирнова
from scipy.stats import kstest
import numpy as np
data = np.random.rand(100) # пример случайного набора данных
# потом можно затестить для data = range(100)
stat, p = kstest(data, 'uniform')
alpha = 0.05 # уровень значимости
if p > alpha:
print('Данные похожи на случайные')
else:
print('Данные не похожи на случайные')
Этот тест проверяет, соответствует ли распределение данных равномерному распределению на отрезке [0, 1]. Если p-value больше заданного уровня значимости, то данные можно считать случайными.
Тест Шапиро-Уилка
from scipy.stats import shapiro
import numpy as np
data = np.random.normal(0, 1, 100) # пример случайного набора данных
# потом можно затестить для data = range(100)
stat, p = shapiro(data)
alpha = 0.05 # уровень значимости
if p > alpha:
print('Данные похожи на случайные')
else:
print('Данные не похожи на случайные')
Этот тест проверяет, соответствует ли распределение данных нормальному распределению. Если p-value больше заданного уровня значимости, то данные можно считать случайными.
Тест Льюнга-Бокса
from statsmodels.stats.diagnostic import acorr_ljungbox
import numpy as np
data = np.random.normal(0, 1, 100) # пример случайного временного ряда
# потом можно затестить для data = range(100)
stat, p = acorr_ljungbox(data, lags=[10])
alpha = 0.05 # уровень значимости
if all(p > alpha):
print('Временной ряд похож на случайный')
else:
print('Временной ряд не похож на случайный')
Этот тест проверяет, является ли временной ряд случайным. Если все p-value для заданных лагов больше заданного уровня значимости, то временной ряд можно считать случайным.
Неплохая лекция об анализе временных рядов
В чём разница между pivot и pivot_table?
pivot и pivot_table - это методы из Pandas, которые используются для изменения формы данных в DataFrame.
pivot:
pivot переставляет значения столбцов в новые столбцы. Его параметры:
index: столбец/столбцы, которые будут использоваться в качестве индекса нового DataFrame.values: столбец, значения которого будут использоваться для заполнения новых столбцов.columns: столбец, значения которого будут использоваться в качестве названий новых столбцов.
import pandas as pd
data = {'municipality': ['A', 'A', 'B', 'B'],
'year': [2019, 2020, 2019, 2020],
'birth': [100, 200, 150, 250]}
df = pd.DataFrame(data)
print(df)
# municipality year birth
# 0 A 2019 100
# 1 A 2020 200
# 2 B 2019 150
# 3 B 2020 250
df_pivot = df.pivot(index='municipality', values='birth', columns='year')
print(df_pivot)
# year 2019 2020
# municipality
# A 100 200
# B 150 250
pivot_table:
pivot_table в отличие от pivot, позволяет агрегировать значения (при необходимости). Принимает параметры:
index: столбец/столбцы, которые будут использоваться в качестве индекса нового DataFrame.values: столбец, значения которого будут использоваться для заполнения новых столбцов.columns: столбец, значения которого будут использоваться в качестве названий новых столбцов.aggfunc: функция агрегации, которая будет применяться к значениям при необходимости.
import pandas as pd
import numpy as np
data = {'region': ['X', 'X', 'Y', 'Y'],
'municipality': ['A', 'A', 'B', 'B'],
'year': [2019, 2020, 2019, 2020],
'birth': [100, 200, 150, 250]}
df = pd.DataFrame(data)
print(df)
# region municipality year birth
# 0 X A 2019 100
# 1 X A 2020 200
# 2 Y B 2019 150
# 3 Y B 2020 250
df_pivot_table = df.pivot_table(index=['region', 'municipality'], values='birth', columns='year')
print(df_pivot_table)
# year 2019 2020
# region municipality
# X A 100.0 200.0
# Y B 150.0 250.0
В общем, основная разница между pivot и pivot_table в том, что pivot просто переставляет значения столбцов в новые столбцы, а pivot_table также позволяет агрегировать значения при необходимости
Реализуйте метод k-средних с помощью SciPy
Суть алгоритма k-средних в том, что он стремится минимизировать суммарное квадратичное отклонение точек кластеров от центров этих кластеров.
где — число кластеров,
— полученные кластеры,
, а
— центры масс всех векторов
из кластера
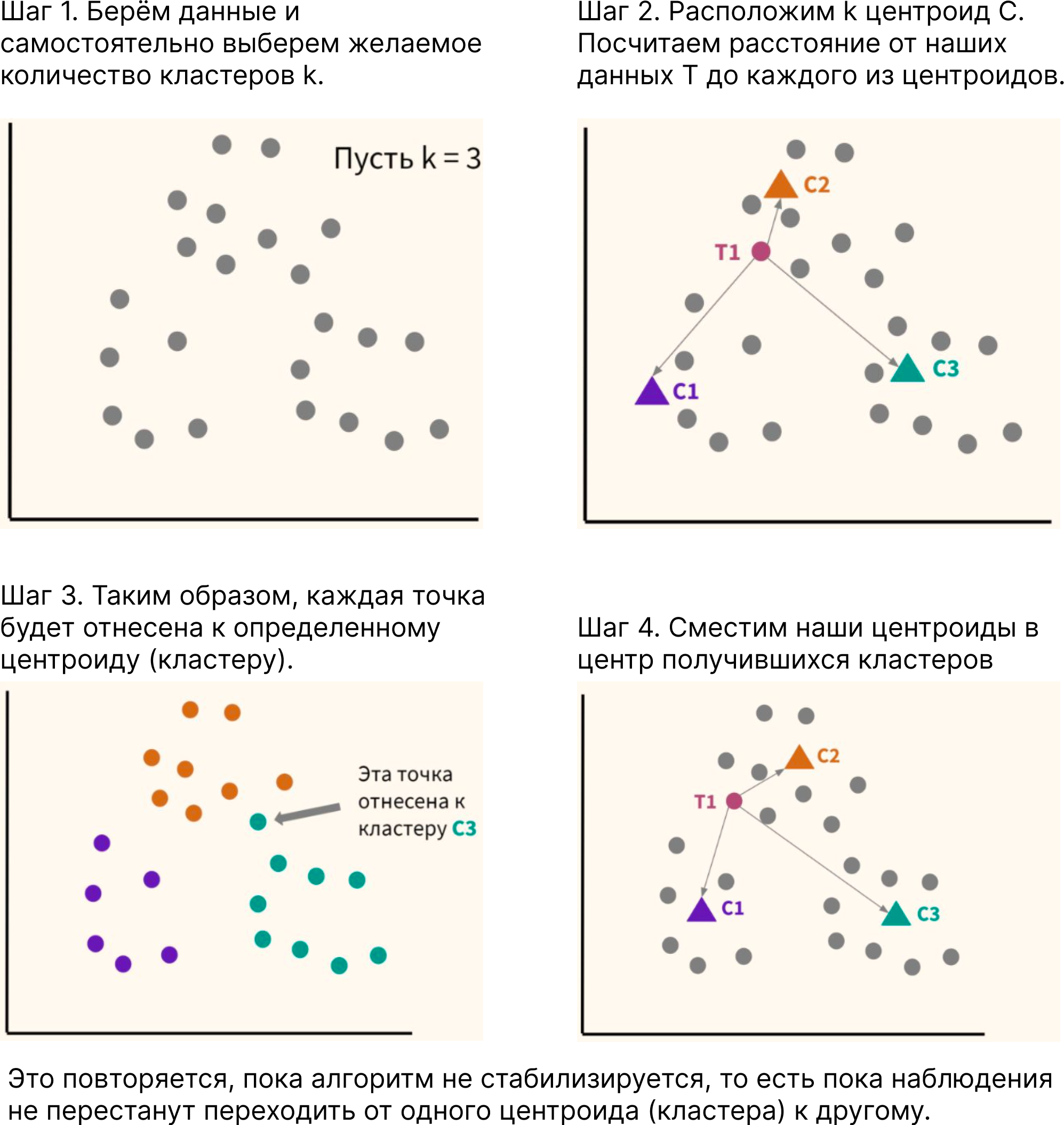
Проблемки k-means:
Не гарантируется достижение глобального минимума суммарного квадратичного отклонения V, а только одного из локальных минимумов.
Результат зависит от выбора исходных центров кластеров, их оптимальный выбор неизвестен.
Число кластеров надо знать заранее.
Ок, поехали писать код. Реализовать алгоритм k-means в SciPy можно с помощью модуля scipy.cluster и его функции kmeans. Вот подробное объяснение с примерами кода:
Необходимые импорты;
vstack— для объединения массивов,kmeans— для вычисления координат центроид и distortion,whiten— для нормализации данных на основе их статистических свойств
from numpy import vstack
from numpy.random import rand
import matplotlib.pyplot as plt
from scipy.cluster.vq import kmeans, whiten
Создаём массив и нормализуем данные при помощи
whiten(набор такой, чтобы получилось 3 кластера):
data = vstack(((rand(20,2) + 1),
(rand(20,2) + 3),
(rand(20,2) + 4.5)))
data = whiten(data)
Определяем количество кластеров (3), вычисляем координаты центроид и distortion
centroids, distortion = kmeans(data, 3)
Отображаем то, что хотим
print('centroids : ', centroids)
print('distortion :', distortion)
plt.plot(data[:,0], data[:,1], 'go', centroids[:,0], centroids[:,1], 'bs')
plt.show()
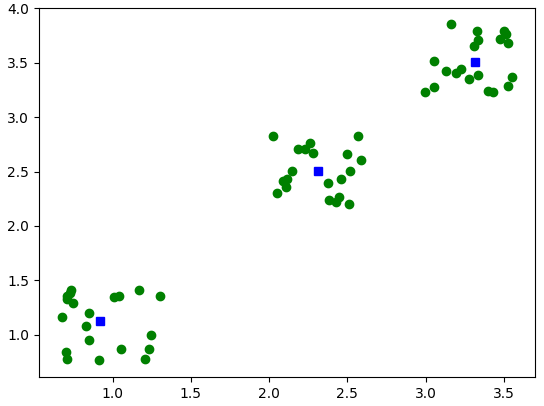
Обратите внимание:
В данном примере мы использовали двумерные данные, но алгоритм k-means также может быть применен к данным большей размерности.
Функция
kmeansвозвращает координаты центроидов, есть ещё функцияvq, она возвращает метки кластеров для каждой точки.
Отличная статья с массой примеров по кластерному анализу и k-means в частности
Какие есть варианты итерирования по строкам объекта DataFrame?
Мы можем итерироваться по строкам объекта DataFrame, то есть брать по очереди строки этого объекта в Pandas с помощью массы вариантов. К примеру, можно использовать range(len(df)), iterrows(), itertuples().
Итак, вначале создадим датафрейм df, подпишем колонки этого датафрейма как col1, col2:
df = pd.DataFrame([[1, "A"], [2, "B"], [3, "C"]], columns = ["col1", "col2"])
print(df)
# col1 col2
# 0 1 A
# 1 2 B
# 2 3 C
Применение всех 3 функций даст аналогичный результат:
for index in range(len(df)):
print(df["col1"][index], end=" ")
for index, row in df.iterrows():
print(row["col1"], end=" ")
for row in df.itertuples():
print(row.col1, end=" ")
# везде результат: 1 2 3
Что такое декоратор? Как написать собственный?
Декоратор в Python - это функция, которая принимает другую функцию в качестве аргумента и расширяет ее функциональность без изменения ее кода. Декораторы могут использоваться для добавления логирования, проверки аутентификации, тайминга выполнения и ещё кучи полезных штук.
Вот пример создания декоратора:
def my_decorator(func):
def wrapper():
print("Дополнительный код, который исполняется перед вызовом функции")
func()
print("Дополнительный код, который исполняется после вызова функции")
return wrapper
@my_decorator
def say_hello():
print("Привет!")
say_hello()
# Дополнительный код, который исполняется перед вызовом функции
# Привет!
# Дополнительный код, который исполняется после вызова функции
Этот код создает декоратор my_decorator, который добавляет дополнительный код до и после выполнения функции say_hello(). Декоратор применяется к say_hello() с помощью синтаксиса @my_decorator.
Таким образом, написав свой собственный декоратор, вы можете расширить функциональность функций, не изменяя их исходный код.
Вот, к примеру, декоратор, который позволяет измерять время выполнения функции:
from time import time
def executiontime(func):
def wrapper():
start = time()
func()
end = time()
print(f'Функция {func} выполнялась: {end - start} сек')
return wrapper
@executiontime
def create_tuple():
return tuple(range(10**7))
create_tuple()
Суть двумя словами: по сути декоратор принимает на вход другую функцию и позволяет её модифицировать снаружи, не меняя внутренней реализации самой функции. Кстати, один из полезнейших декораторов — @njit() из библиотеки numba, позволяет космически ускорить Python.
Ну и неплохая статья — 6 Python декораторов, которые значительно упростят ваш код
Секция "Data Science"
Кстати, так выглядит граф связи 45 тысяч хаброжителей, сам граф (gexf) лежит тут

Что такое сэмплирование? Сколько методов выборки вы знаете?
Сэмплирование (a.k.a data sampling) — метод корректировки обучающей выборки с целью балансировки распределения классов в исходном наборе данных.
Простая случайная выборка

Систематическая выборка (используется фиксированный интервал)

Кластеризованная выборка (данные разбиваются на кластеры, выбирается один из кластеров)
Выборка с взвешиванием (элементу присваивается вес, вероятность выбора элемента ~ его весу)

Стратифицированная выборка (данные делятся на однородные страты, затем из каждой страты берётся выборка)
Отличный wiki-конспект от ИТМО по теме
Также о методах сэмплирования рассказывается на Medium
Чем корреляция отличается от ковариации?
Корреляция и ковариация представляют собой меры связи между двумя случайными величинами.
Корреляция - это мера силы линейности двух переменных, а ковариация - мера силы корреляции.
Уже исходя из этого можно понять некоторые их отличия.
Отличие в принимаемых значениях. Значение корреляции имеет место между -1 и +1. Наоборот, значение ковариации лежит между -∞ и + ∞.
Инвариантность относительно масштабирования. На ковариацию влияет изменение масштаба, т.е. если все значение одной переменной умножается на постоянную, а все значение другой переменной умножается на аналогичную или другую постоянную, то ковариация изменяется. В отличие от этого, на корреляцию не влияет изменение масштаба.
Размерность. Корреляция безразмерна, т. е. это единичная мера взаимосвязи между переменными. В отличие от ковариации, где значение получается произведением единиц двух переменных.
Вот самые основные отличия между корреляцией и ковариацией.
Что такое кросс-валидация? Какие проблемы она призвана решить?
Кросс-валидация — это метод, предназначенный для оценки качества работы модели, широко применяемый в машинном обучении. Он помогает сравнить между собой различные модели и выбрать наилучшую для конкретной задачи.
В основе метода лежит разделение исходного множества данных на k примерно равных блоков, например k=5. Затем на k−1, т.е. на 4-х блоках, производится обучение модели, а 5-й блок используется для тестирования. Процедура повторяется k раз, при этом на каждом проходе для проверки выбирается новый блок, а обучение производится на оставшихся.

Перекрестная проверка имеет важное преимущества перед применением одного множества для обучения и одного для тестирования модели: если при каждом проходе оценить выходную ошибку модели и усреднить ее по всем проходам, то полученная ее оценка будет более достоверной.
На практике чаще всего выбирается k=10 (10-ти проходная перекрестная проверка), когда модель обучается на 9/10 данных и тестируется на 1/10. Исследования показали, что в этом случае получается наиболее достоверная оценка выходной ошибки модели.
Помимо получения более достоверной оценки, кросс-валидация помогает пытается решить такие проблемы:
1. Оценка производительности модели: кросс-валидация позволяет оценить, насколько хорошо модель обобщает данные и способна предсказывать новые наблюдения. Она помогает избежать проблемы переобучения или недообучения модели.
2. Выбор гиперпараметров: кросс-валидация может использоваться для выбора оптимальных значений гиперпараметров модели (гиперпараметры - это параметры модели, которые не могут быть обучены из данных, и их значения должны быть настроены вручную)
3. Обнаружение переобучения: кросс-валидация может помочь выявить переобучение модели, когда модель слишком хорошо подстраивается под обучающие данные и плохо обобщает новые данные. Путем оценки производительности модели на разных фолдах данных, кросс-валидация может помочь определить, насколько модель способна обобщать.
4. Устойчивость оценок: кросс-валидация позволяет получить более устойчивые оценки производительности модели путем усреднения результатов на разных разбиениях данных. Это особенно полезно, когда у вас есть ограниченное количество данных и вы хотите получить более надежные оценки.
5. Оценка важности признаков: кросс-валидация может использоваться для оценки важности признаков в модели. Путем анализа вклада каждого признака в процессе кросс-валидации, можно определить, какие признаки наиболее значимы для предсказания целевой переменной.
Подробная статья от Яндекса о кросс-валидации
Что такое матрица ошибок? Для чего она нужна?
Матрица ошибок (confusion matrix) - это таблица, которая используется в статистике и Data Science для оценки качества модели машинного обучения. Она позволяет оценить, насколько точно модель классифицирует объекты на разные классы.
Выглядит матрица ошибок так:
Предсказанный класс 0 |
Предсказанный класс 1 |
|
|---|---|---|
Фактический класс 0 |
True Negative (TN) |
False Positive (FP) |
Фактический класс 1 |
False Negative (FN) |
True Positive (TP) |
Тут у нас:
True Positive (TP) - количество объектов, которые были верно классифицированы как положительные;
False Positive (FP) - количество объектов, которые были неверно классифицированы как положительные;
True Negative (TN) - количество объектов, которые были верно классифицированы как отрицательные;
False Negative (FN) - количество объектов, которые были неверно классифицированы как отрицательные.
Матрица ошибок позволяет оценить следующие характеристики модели:
Accuracy (точность) - доля верно классифицированных объектов;
Precision (точность) - доля объектов, которые действительно принадлежат положительному классу среди всех объектов, которые модель отнесла к положительному классу;
Recall (полнота) - доля объектов положительного класса, которые модель верно классифицировала.
Как преобразование Бокса-Кокса улучшает качество модели?
Во-первых, преобразование Бокса-Кокса — это метод приблизить распределение к виду Гауссова нормального.
Основная идея этого метода состоит в том, чтобы найти такое значение λ, чтобы преобразованные данные были как можно ближе к нормальному распределению:
, если
, если
А теперь давайте пощупаем это преобразование. Вначале построим экспоненциальное распределение:
import numpy as np
import matplotlib.pyplot as plt
# для воспроизводимости закрепляем seed
np.random.seed(0)
# генерим 1000 значений с экспоненциальным распределением
values = np.random.exponential(scale=1, size=1000)
# строим гистограмму распределения
plt.hist(values, bins=30, density=True, alpha=0.7)
plt.xlabel('Значение')
plt.ylabel('Плотность')
plt.title('Экспоненциальное распределение')
plt.show()
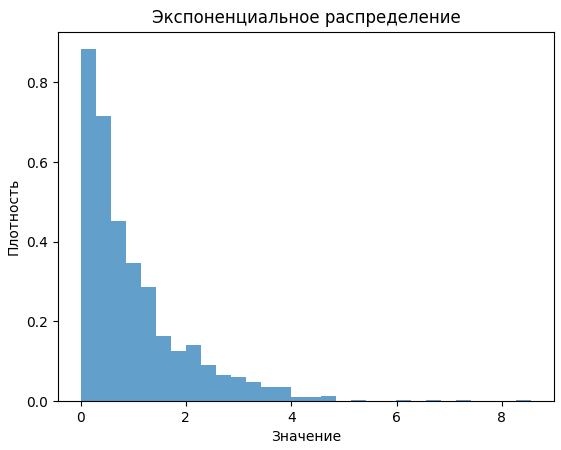
Невооружённым взглядом видно ненормальность распределения. Что ж, используем преобразование Бокса-Кокса как boxcox из scipy.stats. Выглядит это так:
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import boxcox
# для воспроизводимости закрепляем seed
np.random.seed(0)
# генерим 1000 значений с экспоненциальным распределением
values = np.random.exponential(scale=1, size=1000)
# преобразуем распределение с помощью Бокса-Кокса
transformed_values, lambda_ = boxcox(values)
# строим гистограмму распределения
plt.hist(transformed_values, bins=30, density=True, alpha=0.7)
plt.xlabel('Значение')
plt.ylabel('Плотность')
plt.title('Преобразованное с помощью Бокса-Кокса распределение')
plt.show()

Ну вот, теперь всё по красоте — распределение стало ближе к нормальному. Кстати, функция boxcox возвращает не только преобразованные данные, но и ту самую (
lambda_), которая позволяет сделать это преобразование.
Какие методы можно использовать для заполнения пропущенных данных, и каковы последствия невнимательного заполнения данных?
Данные из реального мира часто имеют пропуски. Есть множество методов для их заполнения. Полное «лечение» – это процесс удаления каждой строки, содержащей значение NA. Это допустимо, если значений NA не очень много, они задевают не очень много строк, и данных достаточно – в противном случае, мы можем потерять что-нибудь важное. В данных из реального мира удаление любых строк, содержащих NA, может привести к потере наблюдаемых паттернов в данных.
Если полное удаление пропусков невозможно, существует множество методов их заполнения – такие, как заполнение средним значением, медианой или модой. Какой из них лучше, зависит от контекста.
Другой метод – это использовать k ближайших соседей (KNN), чтобы определить ближайших соседей строки с пропущенными данными и использовать среднее значение, медиану или моду для этих соседей. Это обеспечивает большую настраиваемость и управляемость, чем можно добиться использованием статистических значений.
Если метод заполнения пропусков реализован неаккуратно, оно может привести к ошибке выборки – любая модель хороша настолько, насколько хороши ее исходные данные, и если данные отклоняются от реальности, то же самое будет с моделью.
Существует несколько способов обработки пропущенных данных:
удаление строк с пропущенными данными;
подстановка среднего значения, медианы или моды;
присваивание уникального значения;
предсказание пропущенных значений;
использование алгоритма, допускающего пропуски – например, случайный лес.
Тут ниже показано распределение значений непрерывной характеристики до заполнения пропусков средним значением и после него:
А вот так обстоят дела при заполнении пропусков в распределении дискретной характеристики модой:
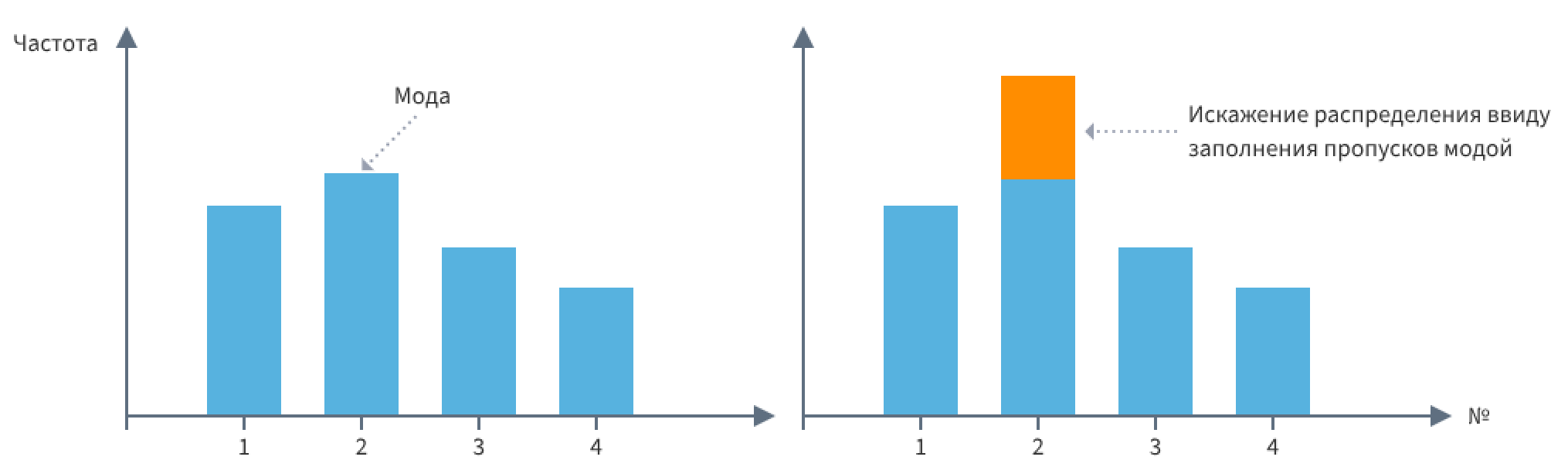
Как видно, после добавления среднего/моды распределение искажается.
Кстати, есть ещё варианты заполнения пропусков на основе регрессионных моделей.
Так выглядит заполнение на основе линейной регрессионной модели:
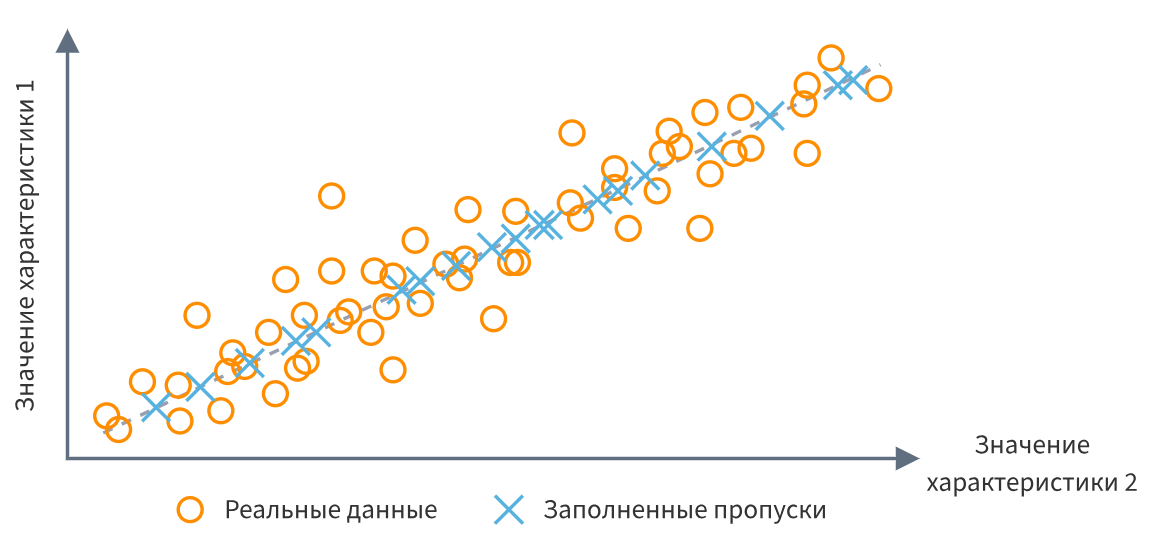
А это заполнение пропусков на основе стохастической линейной регрессии:

В общем, при наличии пропусков лучший метод – удалить строки с пропусками, поскольку это гарантирует, что мы не добавим никаких ошибок или сдвигов, и, в конечном счете, получим точную и надежную модель. Однако, этот метод можно использовать лишь в тех случаях, когда данных много, а процент пропусков невысок. То есть вариант полного удаления просто не всегда возможен.
Неплохая статья от Loginom по теме
Что такое ROC-кривая? Что такое AUC?
ROC-кривая — кривая рабочих характеристик (Receiver Operating Characteristics curve). Используется для анализа поведения классификаторов при различных пороговых значениях. Позволяет рассмотреть все пороговые значения для данного классификатора. Показывает долю ложно положительных примеров (англ. false positive rate, FPR) в сравнении с долей истинно положительных примеров (англ. true positive rate, TPR).
Или можно определить её так:
ROC-кривая — это кривая роста процента истинно позитивных результатов по мере роста процента ложных позитивных результатов. Полностью случайное предсказание будет изображаться прямой диагональной линией (черная штриховая линия на рисунке). Оптимальная модель будет как можно более близкой к оси y и к линии «y=1».

Одна из метрик того, насколько близка кривая ROC к этим линиям – AUC, или площадь под кривой (Area Under Curve). Чем выше AUC, тем лучше работает модель.
ROC-AUC показывает производительность решения задачи классификации при различных пороговых значениях. То есть, насколько точно модель различает разные классы. ROC — это вероятностная кривая, в то время как AUC — это площадь под этой вероятностной кривой.
ROC-AUC можно интерпретировать, как вероятность, что случайно выбранный объект будет проранжирован классификатором выше (будет иметь более высокую вероятность быть positive), чем случайно выбранный negative объект.
Оценка качества в задачах классификации и регрессии
Кстати, неплохое объяснение ROC-AUC есть у miracl6.
Что такое полнота (recall) и точность (precision)?
Точность можно описать как «процент реально истинных результатов среди тех, которые наша модель посчитала истинными». Или, что то же самое: точность равна доле истинноположительных классификаций к общему числу положительных классификаций. Данная величина часто упоминается как positive predictive value (PPV) или положительное прогностическое значение:
Это очень легко можно объяснить с помощью такой картиночки:
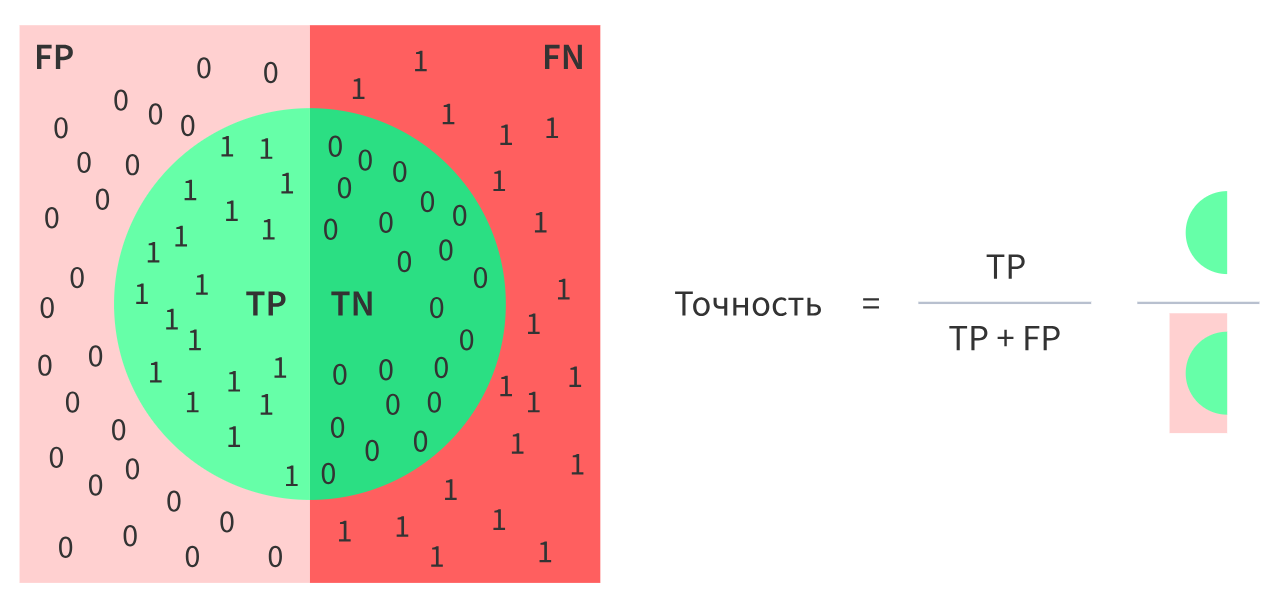
Несложно увидеть, что попытка отнести все объекты к одному классу неизбежно приведет к росту и уменьшению значения точности.
Полнота, известная еще как чувствительность или доля истинноположительных примеров (TPR — true positive rate), определяется как число истинноположительных классификаций относительно общего числа положительных наблюдений:
В общем, полноту можно рассматривать как способность классификатора обнаруживать определенный класс. Графически полноту можно визуализировать так:

Точность и полноту для каждого класса легко определять с помощью матрицы ошибок. Точность равна отношению соответствующего диагонального элемента матрицы и суммы элементов всей строки класса, а полнота — отношению диагонального элемента матрицы и суммы элементов всего столбца класса.
тут — класс,
— число элементов столбца (равно числу классов),
— номер элемента в столбце,
— элемент матрицы ошибок
Годная статья с Хабра — Метрики в задачах машинного обучения
Очень подробное объяснение на Loginom
Как бы вы справились с разными формами сезонности при моделировании временных рядов?
В реальных данных временных рядов (например, количества плюшевых мишек, закупаемых на фабрике игрушек) часто встречаются различные виды сезонности, которые могут пересекаться друг с другом. Годичная сезонность, вроде пика перед Рождеством и летнего спада, может сочетаться с месячной, недельной или даже дневной сезонностью. Это делает временной ряд нестационарным, поскольку среднее значение переменной различно для разных периодов времени.
При моделировании временных рядов с разными формами сезонности можно использовать различные подходы. Вот несколько методов, которые могут помочь:
1. Модель SARIMA (Seasonal AutoRegressive Integrated Moving Average): SARIMA - это расширение модели ARIMA (AutoRegressive Integrated Moving Average) для учета сезонности в данных. Она позволяет моделировать как обычную авторегрессионную и скользящую среднюю компоненты, так и сезонную компоненту.
2. Модель GARCH (Generalized AutoRegressive Conditional Heteroscedasticity): GARCH - это модель, которая учитывает гетероскедастичность (изменчивость дисперсии) в данных. Она может быть использована вместе с моделью ARMA (AutoRegressive Moving Average) для моделирования сезонности.
3. Декомпозиция временного ряда: Декомпозиция временного ряда позволяет разделить его на трендовую, сезонную и остаточную компоненты. Это может помочь в анализе и моделировании сезонности.
Существуют и другие методы типа моделирования с помощью нейронных сетей или использование специализированных алгоритмов машинного обучения. Разумеется, выбор метода зависит от конкретной задачи и доступных данных.
Кстати, для моделирования сезонности с использованием модели SARIMA можно использовать такой код на Python:
from statsmodels.tsa.arima.model import ARIMA
model = ARIMA(data, order=(p, d, q), seasonal_order=(P, D, Q, s))
model_fit = model.fit()
тут у нас data - это временной ряд, p, d, q - порядки для авторегрессионной, интегрированной и скользящей средней компонент соответственно, а P, D, Q, s - порядки для сезонной компоненты.
Какие ошибки вы можете внести, когда делаете выборку?
Ошибка выборки: неслучайный выбор включаемых в выборку объектов.
Ошибка недостаточности: для анализа берется слишком мало наблюдений.
Ошибка выжившего: игнорирование наблюдений, не прошедших через весь процесс получения данных.
Для уменьшения количества ошибок в выборке есть 2 основных метода – это рандомизация, при которой наблюдения выбираются случайным образом, и случайная выборка, при которой каждое наблюдение имеет равный шанс попасть в выборку.
Что такое RCA (root cause analysis)? Как отличить причину от корреляции?
Анализ причин (root cause analysis, RCA) – метод решения задач, используемый для выявления причин некоторого явления.
Корреляция измеряет уровень зависимости между двумя переменными, от -1 до 1. Причинно-следственная связь – это когда первое событие вызывает второе. Причинно-следственные связи учитывают только прямые зависимости, тогда как корреляция – и косвенные зависимости.
К примеру, повышение уровня преступности в Канаде совпадает с повышением продаж мороженого, то есть корреляция между ними положительна. Но это не значит, что одно является следствием другого. Просто и то, и другое происходит, когда становится теплее.
Провести анализ причинно-следственных связей можно с помощью проверки гипотез или A/B тестирования.
Что такое выброс и внутренняя ошибка? Объясните, как их обнаружить, и что бы вы делали, если нашли их в наборе данных?
Выброс (англ. outlier) – это значение в данных, существенно отличающееся от прочих наблюдений.
В зависимости от причины выбросов, они могут быть плохими с точки зрения машинного обучения, поскольку ухудшают точность модели. Если выброс вызван ошибкой измерения, важно удалить его из набора данных. Есть пара способов обнаружения выбросов.
1) Z-оценка/стандартные отклонения: если мы знаем, что 99.7% данных в наборе лежат в пределах тройного стандартного отклонения, мы можем найти элементы данных, выходящие за эти пределы. Точно так же, мы можем рассчитать z-оценку каждого элемента, и если она равна +/- 3, это выброс.

2) Межквартильное расстояние (Inter-Quartile Range, IQR) – концепция, положенная в основу ящиков с усами (box plots), которую также можно использовать для нахождения выбросов. МКР – это расстояние между 3-м и 1-м квартилями. После его расчета можно считать значение выбросом, если оно меньше Q1-1.5*IQR или больше Q3+1.5*IQR. Это составляет примерно 2.7 стандартных отклонений.
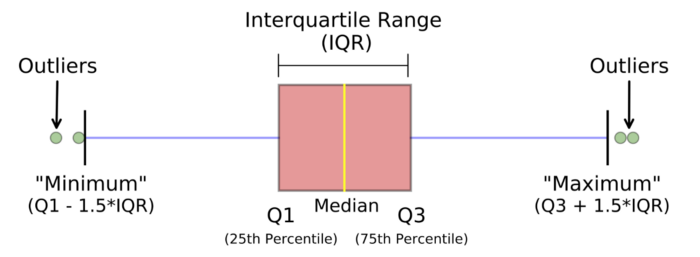
Другие методы включают кластеризацию DBScan, Лес Изоляции и устойчивый случайно-обрубленный лес.
Выбросы довольно просто обнаружить, но выбор способа их устранения слишком существенно зависит от специфики набора данных и целей проекта. Их обработка во многом похожа на обработку пропущенных данных — можно удалить записи или признаки с выбросами, либо скорректировать их, либо оставить без изменений.
Внутренняя ошибка (inlier) – это наблюдение, лежащее в пределах общего набора данных, но необычное либо ошибочное. Поскольку оно находится там же, где остальные данные, его труднее идентифицировать, чем выброс. Внутренние ошибки обычно можно просто удалить из набора данных.
Что такое A/B-тестирование?
Вот такой довольно широкий вопрос, что ж, давайте разбираться.
A/B-тестирование - это методика, используемая для сравнения двух или более вариантов одного и того же элемента или процесса с целью определить, какой из них дает лучший результат. Этот метод широко применяется в маркетинге, веб-разработке и других областях для принятия решений на основе данных.
Основные принципы A/B-тестирования:
Создание двух или более вариантов (A и B) для сравнения.
Разделение аудитории на группы, которые будут видеть разные варианты.
Сбор данных о поведении пользователей и результатов каждой группы.
Анализ данных и сравнение результатов для определения наилучшего варианта.
Процесс проведения A/B-тестирования включает следующие шаги:
Определение цели: определите, что вы хотите измерить или улучшить с помощью A/B-тестирования.
Выбор элемента для тестирования: выберите конкретный элемент или процесс, который вы хотите изменить или улучшить.
Создание вариантов: разработайте два или более варианта для сравнения.
Разделение аудитории: разделите аудиторию на группы, которые будут видеть разные варианты.
Запуск теста: запустите A/B-тестирование и начните сбор данных о поведении пользователей.
Анализ результатов: соберите и проанализируйте данные о поведении пользователей и результаты каждой группы.
Принятие решения: на основе анализа результатов выберите наилучший вариант и примените его.
Отслеживание и оптимизация: продолжайте отслеживать результаты и вносить улучшения на основе полученных данных.
A/B-тестирование может быть использовано для различных целей, таких как оптимизация веб-страниц, улучшение пользовательского опыта, повышение конверсии и многое другое. Этот метод позволяет принимать решения на основе фактических данных и улучшать эффективность различных аспектов бизнеса. Например, в маркетинге A/B-тестирование может быть использовано для сравнения различных версий рекламных объявлений или электронных писем, чтобы определить, какой вариант привлекает больше кликов или конверсий.
Допустим, у вас есть интернет-магазин и вы хотите узнать, какой дизайн кнопки "Купить" привлекает больше кликов. Вы можете провести A/B-тестирование следующим образом:
Шаг 1: Определение цели
Цель: Увеличить количество кликов на кнопку "Купить".
Шаг 2: Выбор элемента для тестирования
Дизайн кнопки "Купить".
Шаг 3: Создание вариантов
Красная кнопка с белым текстом.
Синяя кнопка с белым текстом.
Шаг 4: Разделение аудитории
Половина посетителей видит вариант A, а другая половина видит вариант B.
Шаг 5: Запуск теста
Внедрение вариантов A и B на сайт и начало сбора данных о кликах на кнопку "Купить".
Шаг 6: Анализ результатов
Сравнение количества кликов на кнопку "Купить" для вариантов A и B.
Шаг 7: Принятие решения
Если вариант B показывает значительно больше кликов, вы можете принять решение применить его на постоянной основе.
Шаг 8: Отслеживание и оптимизация
Продолжайте отслеживать количество кликов на кнопку "Купить" и проводить дополнительные тесты для оптимизации.
A/B-тестирование является мощным инструментом для принятия решений на основе данных и улучшения различных аспектов бизнеса. Однако, для достоверных результатов, необходимо учитывать статистическую значимость и размер выборки.
Подробный пошаговый план проведения A/B-тестирования
В каких ситуациях общая линейная модель неудачна?
Сперва об общих линейных моделях. Общие линейные модели относятся к обычным моделям линейной регрессии с непрерывной переменной отклика. Они включают в себя множество статистических моделей, таких как одиночная линейная регрессия, множественная линейная регрессия, Anova, Ancova, Manova, Mancova, t-тест и F-тест. Общие линейные модели предполагают, что остатки/ошибки имеют нормальное распределение.
Вот некоторые ситуации, где общая линейная модель может быть неудачной:
Нелинейные отношения: общая линейная модель предполагает линейные отношения между предикторами и зависимой переменной. Если существуют сложные, нелинейные отношения, то модель может быть неспособна адекватно описать данные (очевидно)
Несоблюдение предпосылок: общая линейная модель имеет определенные предпосылки, такие как нормальность остатков, гомоскедастичность и отсутствие мультиколлинеарности. Если эти предпосылки не выполняются, то результаты модели могут быть ненадежными.
Выбросы и влиятельные наблюдения: общая линейная модель чувствительна к выбросам и влиятельным наблюдениям, которые могут искажать оценки параметров и статистические выводы.
Мультимодальность: если данные имеют мультимодальное распределение, то общая линейная модель может не справиться с описанием таких данных.
Взаимодействия: общая линейная модель предполагает аддитивность эффектов предикторов. Если существуют взаимодействия между предикторами, то модель может не улавливать эти эффекты.
Недостаток гибкости: общая линейная модель имеет ограниченную гибкость в описании сложных данных. В некоторых случаях может потребоваться использование более сложных моделей, таких как нелинейные модели или модели машинного обучения.
Это были несколько ситуаций, где общая линейная модель будет не лучшим выбором.
Является ли подстановка средних значений вместо пропусков допустимым? Почему?
Подстановка средних значений – это метод замены пропусков в наборе данных средними значениями соответствующих признаков.
Как правило, подстановка средних значений – не лучший метод, поскольку он не принимает во внимание корреляцию между признаками. Например, у нас есть таблица с данными о возрасте и уровне физической формы, и для 80-летнего человека уровень физической формы пропущен. Если мы возьмем средний уровень физической формы для всех возрастов от 15 до 80 лет, очевидно, что наш 80-летний получит более высокий уровень, чем имеет на самом деле.
Кроме того, подстановка средних значений уменьшает дисперсию данных и повышает уровень ошибок. Это приводит к менее точной модели и более узким доверительным интервалам.
Есть данные о длительности звонков. Разработайте план анализа этих данных. Как может выглядеть распределение этих данных? Как бы вы могли проверить, подтверждаются ли ваши ожидания?
Чтобы очистить, исследовать и представить данные, я бы провел EDA – Exploratory Data Analysis (разведочный анализ данных). В процессе EDA я бы построил гистограмму длительности звонков, чтобы увидеть их распределение.
Можно предположить, что длительность звонков следует логнормальному распределению. Длительность звонка не может быть отрицательной, так что нижнее значение равно 0. На другом конце гистограммы будет небольшое количество очень длинных звонков.
Чтобы подтвердить, распределена длительность звонков логнормально или нет, мы могли бы использовать график КК (QQPlot).
Секция "Machine Learning"
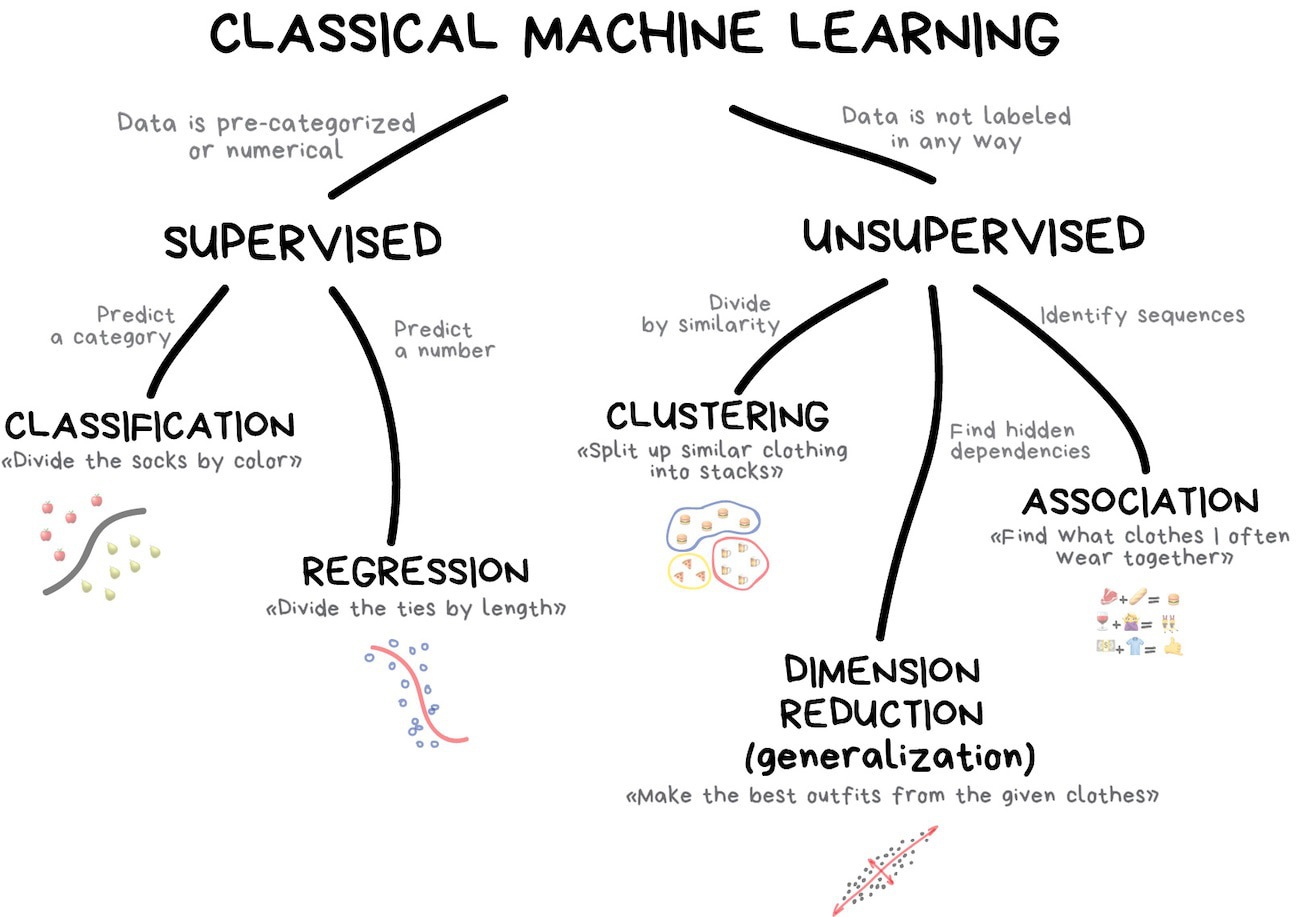
Что такое векторизация TF/IDF?
TF/IDF (Term Frequency/Inverse Document Frequency) - это метод векторизации текстовых данных, который используется для оценки важности слов в документе или коллекции документов. Он основывается на двух понятиях: частоте терма (TF) и обратной частоте документа (IDF).
Частота терма (TF) - это мера того, насколько часто определенное слово встречается в документе. Чем чаще слово встречается, тем больше его вес в документе.
Обратная частота документа (IDF) - это мера того, насколько уникально слово является в коллекции документов. Слова, которые встречаются редко в коллекции, имеют более высокий IDF и, следовательно, более высокую важность.
Векторизация TF/IDF преобразует текстовые документы в числовые векторы, где каждое слово представлено весом, основанным на его TF и IDF. Это позволяет использовать текстовые данные в алгоритмах машинного обучения, которые требуют числовых входных данных.
Вот так можно использовать векторизацию TF/IDF на языке Python с использованием scikit-learn:
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [
'Это первый документ.',
'Этот документ - второй документ.',
'А это третий.',
'Это первый документ?',
]
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(corpus)
print(vectorizer.get_feature_names()) # Выводит список всех слов в коллекции
print(X.shape) # Выводит размерность матрицы векторов TF/IDF
Ну и конечно же TF/IDF может быть использован в самых разных задачах обработки естественного языка, таких как классификация текстов, кластеризация и информационный поиск.
Что такое переобучение и как его можно избежать?
Переобучение на примере линейной регрессии
Переобучение на примере логистической регрессии
Переобучение (англ. overfitting) — негативное явление, возникающее, когда алгоритм обучения вырабатывает предсказания, которые слишком близко или точно соответствуют конкретному набору данных и поэтому не подходят для применения алгоритма к дополнительным данным или будущим наблюдениям.
При переобучении небольшая средняя ошибка на обучающей выборке не обеспечивает такую же малую ошибку на тестовой выборке. Вот так средняя ошибка для обучающей и тестовой выборок зависит от объёма датасета при переобучении:
С переобучением связаны такие понятия как bias и variance.
Bias — ошибка неверных предположений в алгоритме обучения. Высокий bias может привести к недообучению.
Variance — ошибка, вызванная большой чувствительностью к небольшим отклонениям в тренировочном наборе. Высокая дисперсия может привести к переобучению.
Возможные решения при переобучении
Увеличение количества данных в наборе;
Уменьшение количества параметров модели;
Добавление регуляризации/увеличение коэффициента регуляризации.
Вам дали набор данных твитов, задача – предсказать их тональность (положительная или отрицательная). Как бы вы проводили предобработку?
Поскольку твиты наполнены хэштегами, которые могут представлять важную информацию, и, возможно, создать набор признаков, закодированных унитарным кодом (one-hot encoding), в котором '1' будет означать наличие хэштега, а '0' – его отсутствие. То же самое можно сделать с символами '@' (может быть важно, какому аккаунту адресован твит). В твитах особенно часто встречаются сокращения (поскольку есть лимит количества символов), так что в текстах наверняка будет много намеренно неправильно записанных слов, которые придется восстанавливать. Возможно, само количество неправильно написанных слов также представляет полезную информацию: разозленные люди обычно пишут больше неправильных слов.
Удаление пунктуации, хоть оно и является стандартным для NLP, в данном случае можно пропустить, поскольку восклицательные знаки, вопросы, точки и пр. могут нести важную информацию, в сочетании с текстом, в котором они применяются. Можно создать три или большее количество столбцов, в которых будет указано количество восклицательных знаков, вопросительных знаков и точек. Однако перед передачей данных в модель пунктуацию следует убрать из текста.
Затем нужно провести лемматизацию и токенизацию текста. В модель следует передать не только чистый текст, но и информацию о хэштегах, '@', неправильно написанных словах и пунктуации. Все это, вероятно, повысит точность предсказаний.
Вот как-то так можно провести предобработку твитов.
Расскажите про SVM
SVM (Метод опорных векторов) – это целый набор алгоритмов, необходимых для решения задач на классификацию и регрессионный анализ.
Исходя из того что объект, находящийся в N-мерном пространстве, относится к одному из двух классов, метод опорных векторов строит гиперплоскость с мерностью (N – 1), чтобы все объекты оказались в одной из двух групп. На бумаге это можно изобразить так: есть точки двух разных видов, и их можно линейно разделить. Кроме сепарации точек, данный метод генерирует гиперплоскость таким образом, чтобы она была максимально удалена от самой близкой точки каждой группы.
SVM и его модификации помогают решать такие сложные задачи машинного обучения, как сплайсинг ДНК, определение пола человека по фотографии, вывод рекламных баннеров на сайты.
Также SVM имеет margin-based функцию потерь. Вы можете оптимизировать функцию потерь, используя методы оптимизации, например, L-BFGS или SGD.
Интересная вещь, которую могут выполнять SVM – это изучение классификаторов классов. SVM может использоваться для обучения классификаторов (даже регрессоров).
В каких случаях вы бы предпочли использовать SVM, а не Случайный лес (и наоборот)?
И SVM, и Случайный лес – мощные алгоритмы классификации. Если данные хорошо очищены и не содержат выбросов, SVM будет хорошим выбором. В противном случае, Случайный лес может суметь адаптироваться к этим данным. SVM (особенно с широким поиском параметров) потребляет намного больше вычислительной мощности, чем Случайные леса, так что при нехватке памяти Случайный лес будет предпочтительнее. Случайный лес также предпочтителен для задач мультиклассовой классификации, тогда как SVM предпочтителен для задач высокой размерности, таких, как классификация текста.
Каковы последствия установки неправильной скорости обучения?
Довольно общий вопрос, вообще проблем от неправильной скорости обучения может быть масса. Вот некоторые из них:
Сходимость: неправильная скорость обучения может привести к тому, что модель не будет сходиться к оптимальному решению. Если скорость обучения слишком высока, модель может "перепрыгнуть" оптимальное решение и не сойтись к нему. Если скорость обучения слишком низкая, модель может сходиться очень медленно или вообще не сходиться.
Переобучение: неправильная скорость обучения может привести к переобучению модели. Если скорость обучения слишком высока, модель может слишком быстро "запомнить" обучающие данные и не сможет обобщить свои знания на новые данные. Если скорость обучения слишком низкая, модель может недостаточно адаптироваться к обучающим данным и также не сможет хорошо обобщать.
Время обучения: неправильная скорость обучения может существенно повлиять на время, необходимое для обучения модели. Если скорость обучения слишком высока, модель может сходиться очень быстро, но может потребоваться больше времени для достижения оптимального решения. Если скорость обучения слишком низкая, модель может сходиться очень медленно, что также потребует больше времени для обучения.
Производительность модели: неправильная скорость обучения может сказаться на производительности модели. Если скорость обучения слишком высока, модель может иметь тенденцию к колебаниям и нестабильности во время обучения. Если скорость обучения слишком низкая, модель может иметь низкую точность и не сможет достичь высокой производительности.
Это мы разобрали некоторые проблемки, связанные со скоростью обучения. И конечно же, важно подобрать оптимальную скорость обучения для каждой конкретной задачи машинного обучения.
Объясните разницу между эпохой, пакетом (batch) и итерацией.
Это довольно просто:
Эпоха – один проход по всему набору данных, предназначенному для обучения (это и forward, и back propagation).
Пакет. Поскольку передача сразу всего набора данных в нейронную сеть требует слишком много вычислительной мощности, набор данных делится на пакеты.
Итерация – количество запусков пакетов в каждой эпохе. Если у нас 50.000 строк данных, а размер пакета составляет 1000 строк, в каждой эпохе будет запущено 50 итераций.
Вот собственно и всё.
Почему нелинейная функция Softmax часто бывает последней операцией в сложной нейронной сети?
Потому, что она принимает вектор действительных чисел и возвращает распределение вероятностей. Какой бы вектор x ни подали на ее вход (неважно, положительных или отрицательных), на выходе будет набор чисел, пригодный в качестве распределения вероятностей: каждый элемент выходного значения будет неотрицательным, и их сумма будет равна 1.
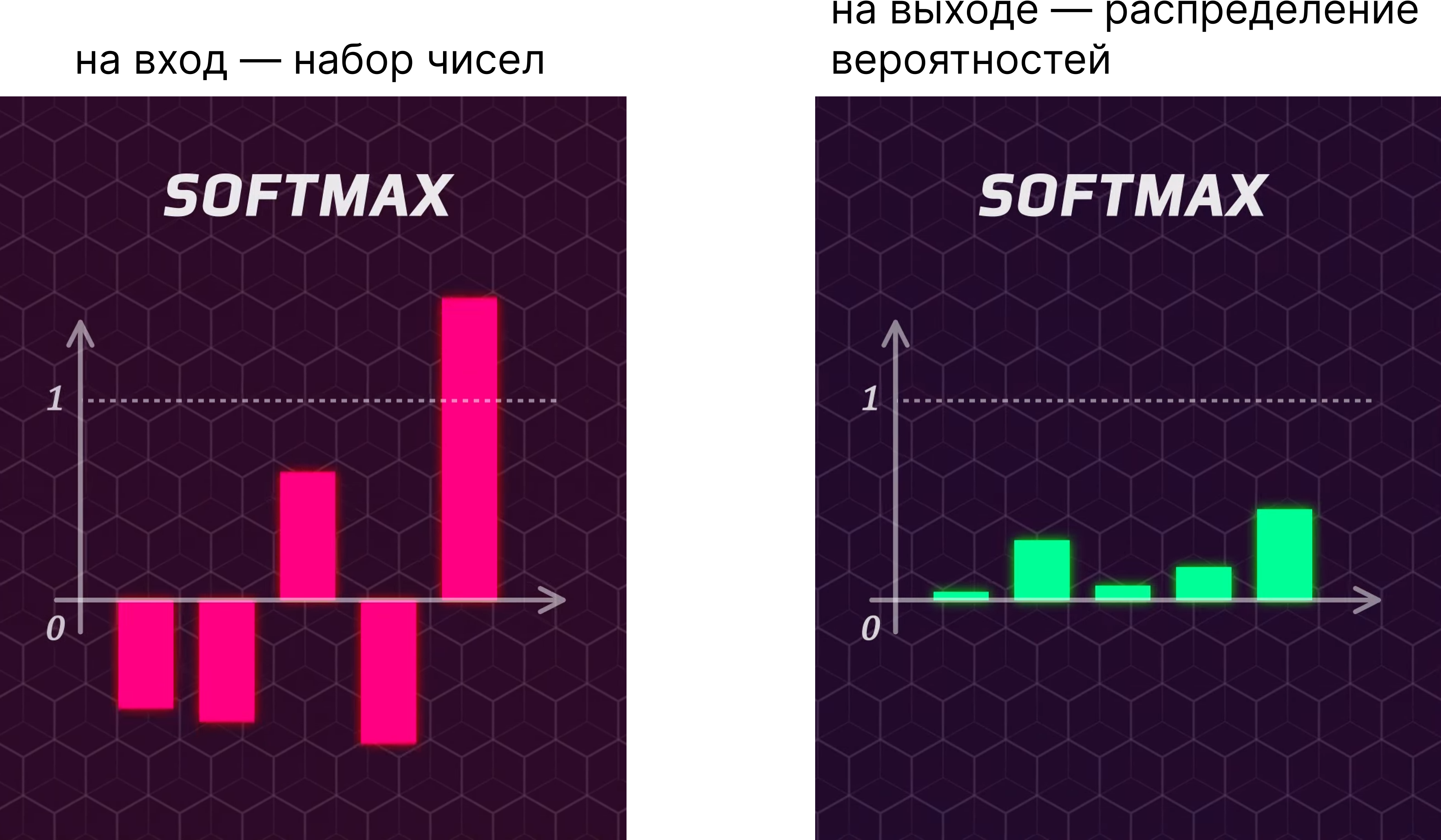
Вообще, для начинающих познавать нейронки я всегда рекомендую бесподобные ролики от Дмитрия Коробченко. В том числе он круто объясняет, что такое Softmax.
Объясните и дайте примеры коллаборативной фильтрации, фильтрации контента и гибридной фильтрации
Коллаборативная фильтрация - это метод рекомендации контента, основанный на собранных данных о предпочтениях пользователей. Он использует информацию о предыдущих действиях пользователей, таких как оценки, рейтинги или история просмотров, чтобы предложить им подходящий контент. Этот метод основывается на предположении, что пользователи с похожими предпочтениями будут заинтересованы в схожем контенте.
В качестве примера представим, что у нас есть онлайн-платформа для потокового видео, где пользователи могут оценивать фильмы. Коллаборативная фильтрация может использоваться для рекомендации фильмов пользователям на основе их предыдущих оценок и оценок других пользователей с похожими вкусами. Например, если пользователь А оценил фильм X высоко, а пользователь Б с похожими предпочтениями также оценил фильм X высоко, то система может рекомендовать фильм X пользователю Б.
Фильтрация контента - это метод, который используется для отбора и предоставления пользователю контента, соответствующего его интересам, предпочтениям или потребностям. Он основывается на анализе и классификации контента с использованием различных алгоритмов и правил.
Предположим, у нас есть новостной сайт, который предлагает пользователю новости на основе его интересов. Фильтрация контента может использоваться для анализа и классификации новостных статей на основе их содержания, тематики или ключевых слов. Например, если пользователь интересуется спортом, система может фильтровать новости и предлагать ему только те статьи, которые относятся к спорту.
Гибридная фильтрация - это комбинация различных методов фильтрации, таких как коллаборативная фильтрация и фильтрация контента, для предоставления более точных и персонализированных рекомендаций пользователю. Этот подход позволяет учесть как предпочтения пользователя, так и характеристики контента.
Пример. Скажем, что у нас есть интернет-магазин, который предлагает пользователю рекомендации товаров. Гибридная фильтрация может использоваться для анализа предыдущих покупок пользователя (коллаборативная фильтрация) и характеристик товаров (фильтрация контента). Например, система может рекомендовать пользователю товары, которые были приобретены другими пользователями с похожими предпочтениями и имеют характеристики, соответствующие интересам пользователя.
Вот как-то так работают все эти виды фильтрации.
В чем разница между bagging и boosting для ансамблей?
Вспомним, что ансамбль алгоритмов/методов — метод использования нескольких обучающих алгоритмов с целью получения лучшей эффективности прогнозирования, чем от каждого алгоритма по отдельности. Этакое комбо.
Работает ансамбль алгоритмов так:
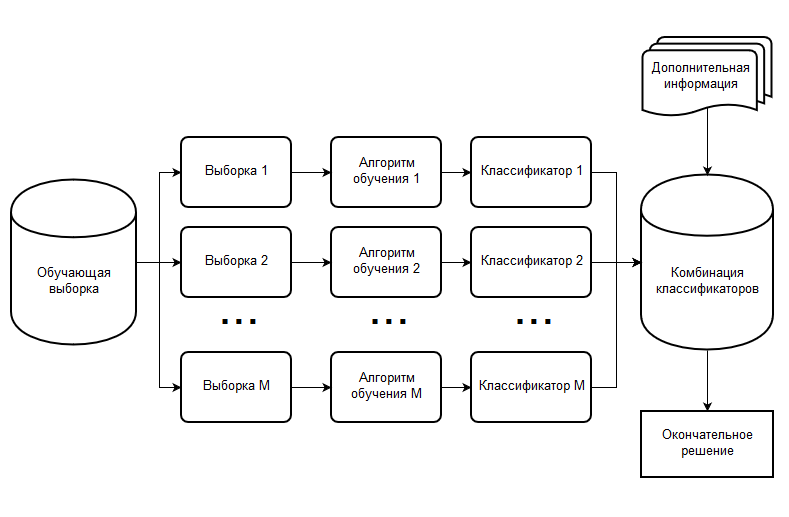
Bagging - это bootstrap aggregating. Вы из одной выборки делаете много подвыборок и потом на подвыборках обучаете, создавая устойчивые к выбросам регрессоры и классификаторы. Ключевой аспект, что обучение происходит параллельно.
Пусть наша целевая зависимость задаётся как
и к ней добавляется ещё нормальный шум
.
Такой семпл может выглядеть так:
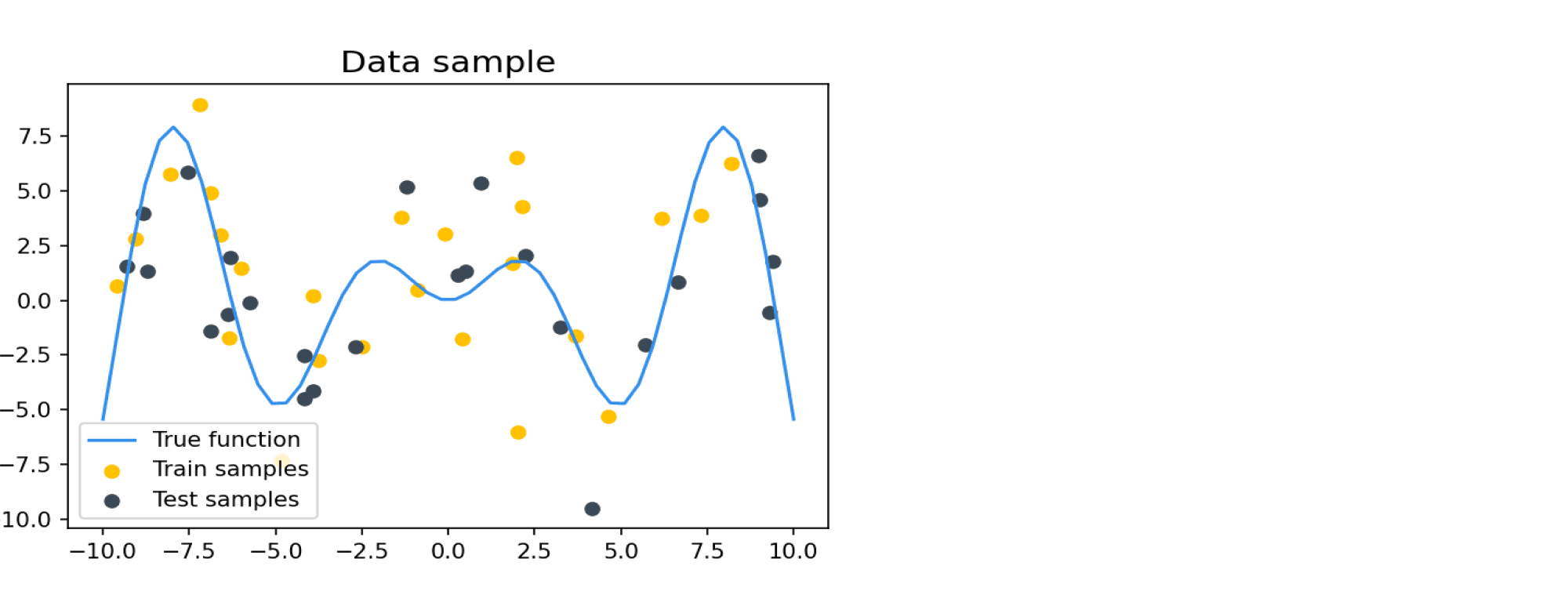
Попробуем посмотреть, как выглядят предсказания решающих деревьев глубины 7 и бэггинга над такими деревьями в зависимости от обучающей выборки. Обучим решающие деревья 100 раз на различных случайных семплах размера 20. Возьмём также бэггинг над 10 решающими деревьями глубины 7 в качестве базовых классификаторов и тоже 100 раз обучим его на случайных выборках размера 20. Если изобразить предсказания обученных моделей на каждой из 100 итераций, то можно увидеть примерно такую картину:

Видно, что общая дисперсия предсказаний в зависимости от обучающего множества у бэггинга значительно ниже, чем у отдельных деревьев, а в среднем предсказания деревьев и бэггинга не отличаются.
Чтобы подтвердить это наблюдение, мы можем изобразить смещение и разброс случайных деревьев и бэггинга в зависимости от максимальной глубины:
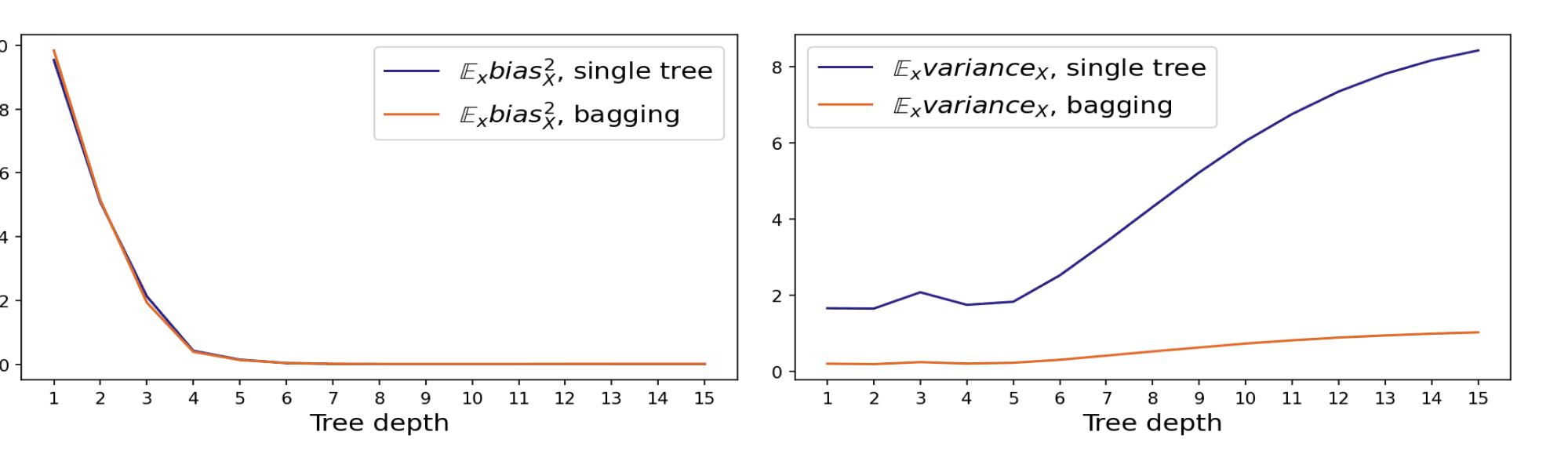
На графике видно, как значительно бэггинг сократил дисперсию. На самом деле, дисперсия уменьшилась практически в 10 раз, что равняется числу базовых алгоритмов , которые бэггинг использовал для предсказания:

Кстати, весь код, с помощью которого получены эти графики лежит тут на гите.
Boosting - это итеративные методы улучшения результатов ансамблей, на каждом следующем этапе обучения более важными для функции потерь оказываются плохо классифицированные на предыдущем этапе точки (или точки где предсказанное значение сильнее отличается от экспериментального).
Отличие от бэггинга в том, что в бэггинге базовые алгоритмы учатся независимо и параллельно, а в бустинге — последовательно.
Каждый следующий базовый алгоритм в бустинге обучается так, чтобы уменьшить общую ошибку всех своих предшественников. Как следствие, итоговая композиция будет иметь меньшее смещение, чем каждый отдельный базовый алгоритм (хотя уменьшение разброса также может происходить).
На текущий момент основным видом бустинга с точки зрения применения на практике является градиентный бустинг — о нём можно почитать тут, кстати. Градиентный бустинг сейчас — основное продакшн-решение, если работа происходит с табличными данными (в работе с однородными данными (картинками, текстами) доминируют нейросети).
Неплохая теория от ИТМО по этому поводу
Супер-подробное объяснение от Яндекса
Как выбрать число k для алгоритма кластеризации «метод k-средних» (k-Means Clustering), не смотря на кластеры?
Немного про сам метод k-средних
Это всеми любимый неконтролируемый алгоритм кластеризации. Учитывая набор данных в виде векторов, мы можем создавать кластеры точек на основе расстояний между ними. Это один из алгоритмов машинного обучения, который последовательно перемещает центры кластеров, а затем группирует точки с каждым центром кластера. Входные данные – количество кластеров, которые должны быть созданы, и количество итераций.
Есть два метода выбора значения k для метода k-средних.
Первый – это «метод локтя». Строится график зависимости функции потерь от количества кластеров k, и если представить, что график – это «рука», то лучшее значение количества кластеров будет там, где «локоть» этой «руки».

В данном случае очевидно, что «локоть» находится при k=3.
Однако, это не всегда так очевидно, поэтому в тех случаях, когда это не так, используется метод силуэта. Этот метод использует «рейтинг силуэта», находящийся в диапазоне от -1 до 1 для каждого количества кластеров. Количество кластеров с максимальным рейтингом обычно является оптимальным.
Как бы вы могли наиболее эффективно представить данные с пятью измерениями?
Что ж, для представления данных с пятью измерениями можно использовать различные методы визуализации, такие как:
Графики парных соотношений (Pair plots): это метод визуализации, который позволяет построить матрицу графиков, где каждый график показывает соотношение между двумя переменными. Это может быть полезно для анализа зависимостей между парами переменных.
Трехмерные графики (3D plots): это метод визуализации, который позволяет построить график, отображающий три переменные на трех измерениях. Это может быть полезно для анализа зависимостей между тремя переменными.
Тепловые карты (Heatmaps): это метод визуализации, который использует цветовую шкалу для отображения значений переменных на плоскости. Это может быть полезно для анализа зависимостей между несколькими переменными.
Многомерное шкалирование (Multidimensional scaling): это метод снижения размерности, который позволяет представить данные с пятью измерениями в двух или трех измерениях. Это может быть полезно для визуализации данных и выявления скрытых зависимостей между переменными.
Примеры алгоритмов, которые можно использовать для анализа данных с пятью измерениями, включают метод главных компонент (PCA), кластерный анализ, алгоритмы классификации и регрессии, а также нейронные сети. Эти алгоритмы могут помочь выявить зависимости между переменными и предсказать значения целевой переменной на основе имеющихся данных.
Говоря о понижении размерности — вот пример в тему: тут, в «Проанализировал комментарии нейросетью» Онигири при анализе комментов переходит от размерности 1536 к 2D и описывает некоторые практические инструменты типо t-SNE (стохастическое вложение соседей с t-распределением).
Кстати, насчёт понижения размерности: иногда лучше повысить размерность. Например, это бывает в задачах классификации, когда в более многомерном пространстве "сложный" случай решается 1 гиперплоскостью.
Что такое ансамбли, и чем они полезны?
Ансамбли – группы алгоритмов, которые «голосуют» для принятия финального решения. Ансамбли успешны, поскольку слабые стороны одной модели могут быть компенсированы сильными сторонами других моделей, это значит, что успешные модели должны быть диверсифицированы. Это также значит, что модели, входящие в ансамбль, должны иметь разные слабые стороны. Исследования показали, что правильно созданные ансамбли дают лучшие результаты, чем одиночные классификаторы (в принципе логично)
Держите примеры ансамблей различной структуры и содержания:
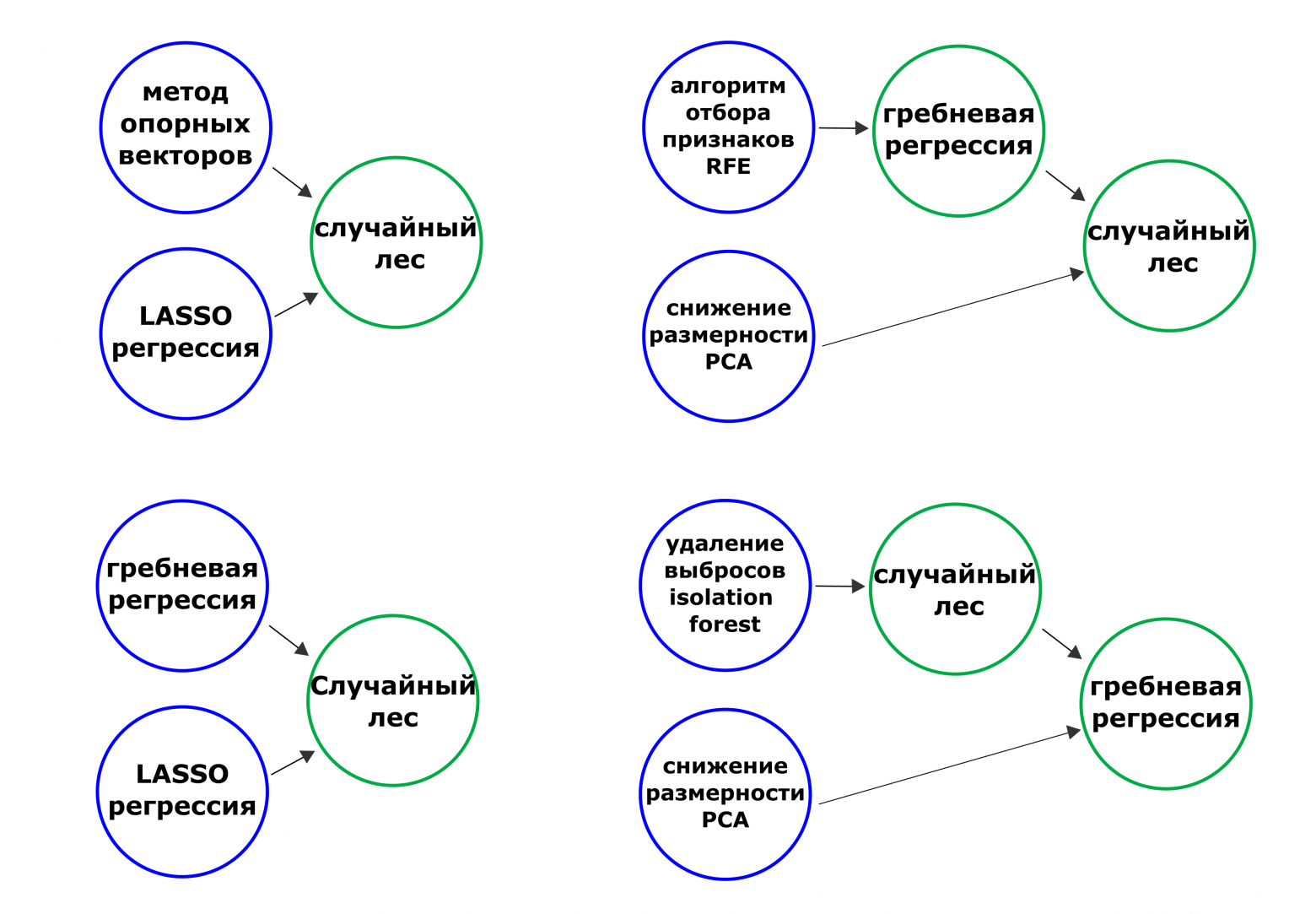
В вашем компьютере 5Гб ОЗУ, а вам нужно обучить модель на 10-гигабайтовом наборе данных. Как вы это сделаете?
Итак, есть несколько вариантов решения проблемы.
Использование генераторов/потоков данных: Можно загружать данные порциями и обучать модель поэтапно. Например, в библиотеке Python TensorFlow можно использовать tf.data.Dataset, чтобы эффективно работать с большими наборами данных, минуя необходимость загрузки всего набора данных в память.
import tensorflow as tf
# Создание генератора/потока данных
def data_generator():
# Загрузка и предобработка данных
yield processed_data_batch
dataset = tf.data.Dataset.from_generator(data_generator, output_types, output_shapes)
Использование распределенного обучения: Распределив обучение модели на несколько машин или GPU, можно уменьшить нагрузку на оперативную память каждого устройства.
Использование дискового пространства: Можно использовать технику под названием "out-of-core" обучение, когда части данных загружаются из дискового пространства для обучения модели.
Сокращение размера модели и данных: Можно использовать методы сжатия данных (например, методы сжатия изображений) и моделей (например, квантизация или обрезка весов).
Использование более эффективных алгоритмов и структур данных: Вместо использования стандартных моделей и алгоритмов, можно искать более эффективные варианты, специально созданные для работы с ограниченными ресурсами.
Использование облачных ресурсов: Если возможно, можно воспользоваться облачными вычислительными мощностями, чтобы увеличить объем доступной памяти.
Уменьшение размера обрабатываемых данных: Можно предварительно обработать данные для исключения ненужных характеристик или снижения их разрешения.
В дополнение упомяну, что для SVM может сработать частичное обучение. Набор данных можно разбить на несколько наборов меньшего размера. Поскольку SVM – это алгоритм с низкими вычислительными требованиями, в данном сценарии это может быть лучшим выбором.
Если данные не подходят для SVM, можно обучить нейронную сеть с достаточно малым размером пакета (batch size) на сжатом массиве NumPy. В NumPy есть несколько инструментов для сжатия больших наборов данных, которые интегрированы в широко распространенные пакеты нейронных сетей вроде Keras/Tensorflow и PyTorch.
Всегда ли методы градиентного спуска сходятся в одной и той же точке?
Нет, методы градиентного спуска не всегда сходятся в одной и той же точке. Поскольку пространство ошибок может иметь несколько локальных минимумов, различные методы градиентного спуска могут сходиться в разных точках, в зависимости от их характеристик: выбора начальной точки, формы функции, шага градиентного спуска и других.
Стоит однако упомянуть, что при определенном стечении обстоятельств методы градиентного спуска могут сходиться к одной и той же точке. Скажем, если функция выпуклая и гладкая, и шаг градиентного спуска выбран правильно, то методы градиентного спуска могут сойтись к глобальному минимуму функции.
Гляньте на работу разных оптимизаторов (методов градиентного спуска) — видно, что не все сходятся.
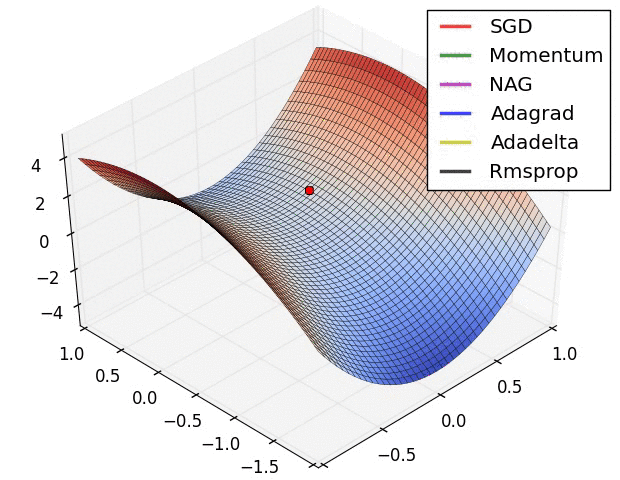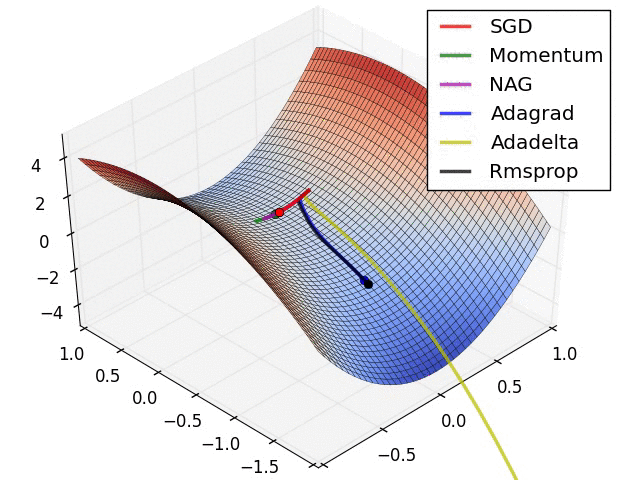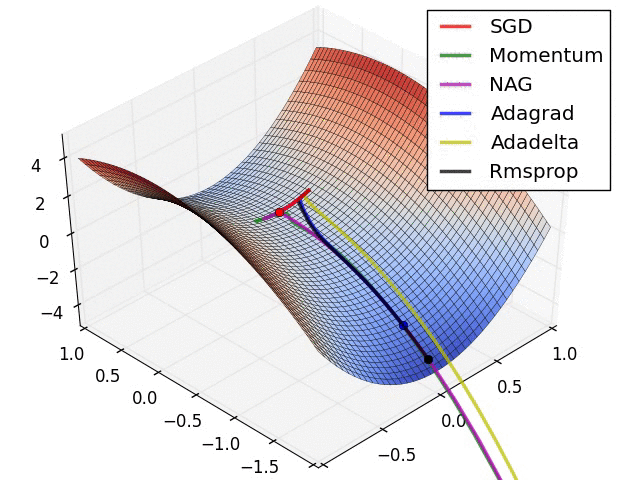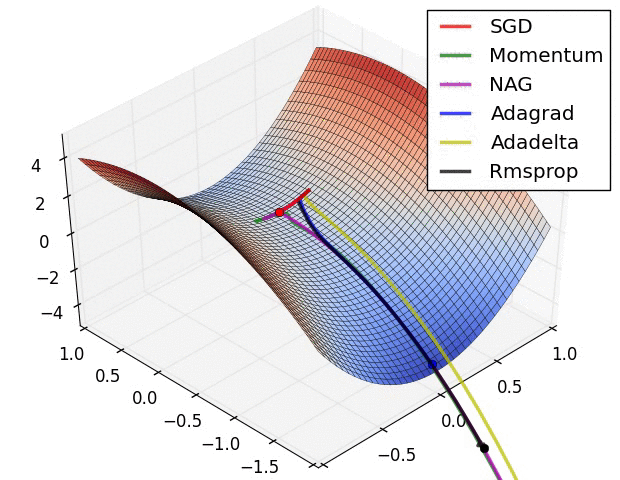
Вот и всё, какой вопрос — такой и ответ.
Кстати, неплохая статья на Хабре в тему — Градиентный спуск по косточкам
Что такое рекомендательные системы?
Очень широкий вопрос. Ну ок, можно начать с формального определения.
Рекомендательные системы – это разновидность систем фильтрации информации, которая должна предсказывать предпочтения пользователя. Либо же она предсказывает рейтинги, которые пользователь дал бы товарам. Рекомендательные системы широко используются для фильмов, новостей, научных статей, товаров, музыки и многого другого.
Основные подходы к построению рекомендательных систем:
Collaborative filtering (коллаборативная фильтрация) - метод, основанный на анализе поведения пользователей и их интересов. Алгоритмы коллаборативной фильтрации используют данные о ранее оцененных элементах пользователем и/или оценках других пользователей, чтобы предсказать оценку для нового элемента. Этот метод может быть основан как на покупках, так и на просмотрах или оценках пользователей.
Content-based filtering (фильтрация на основе контента) - метод, основанный на анализе характеристик элементов (например, жанр, автор, ключевые слова) и сравнении их с профилем пользователя. Этот метод может использоваться для рекомендации фильмов, книг, музыки и других типов контента.
Hybrid filtering (гибридная фильтрация) - метод, который комбинирует коллаборативную фильтрацию и фильтрацию на основе контента. Этот подход позволяет использовать преимущества обоих методов и улучшить качество рекомендаций.
Методы машинного обучения, используемые в рекомендательных системах:
Методы классификации - используются для определения класса элемента (например, жанра фильма) на основе его характеристик.
Методы кластеризации - используются для группировки элементов в кластеры на основе их характеристик и сходства.
Методы регрессии - используются для предсказания оценки пользователя для элемента на основе его характеристик и профиля пользователя.
Методы ассоциативного анализа - используются для поиска связей между элементами и их характеристиками.
Ну и конечно же нейронные сети - используются для построения более сложных моделей рекомендательных систем, которые могут учитывать более широкий набор данных.
Для оценки качества рекомендательных систем используются метрики, такие как точность, полнота, F1-мера и AUC-ROC. Кроме того, для улучшения качества рекомендаций могут использоваться методы активного обучения, которые позволяют системе запрашивать у пользователя дополнительную информацию о его предпочтениях.
Кстати, в апреле Андрей Карпати (тот самый из OpenAI) запилил свою рекомендательную систему и показал, что это не так уж сложно. Делается она так...
Объясните дилемму смещения-дисперсии (bias-variance tradeoff) и приведите примеры алгоритмов с высоким и низким смещением.
Смещение (bias) – это ошибка, внесенная в вашу модель из-за чрезмерного упрощения алгоритма машинного обучения, которое может привести к недообучению. В процессе обучения модели делаются упрощенные предположения, чтобы сделать целевую функцию более простой для понимания.
Алгоритмы машинного обучения с низким смещением включают деревья решений, KNN и SVM. А высоким смещением, в частности, отличаются линейная и логистическая регрессия.
Дисперсия (variance) – это ошибка, внесенная в вашу модель сложным алгоритмом машинного обучения, при котором модель усваивает также и шум из тренировочного набора данных, что приводит к плохой точности на тестовом наборе данных. Это может привести к высокой чувствительности и переобучению.
Обычно, по мере усложения модели вы увидите снижение ошибки вследствие уменьшения смещения модели. Однако, это происходит только до определенной точки – и если вы будете усложнять свою модель дальше, в конце концов вы ее переобучите.
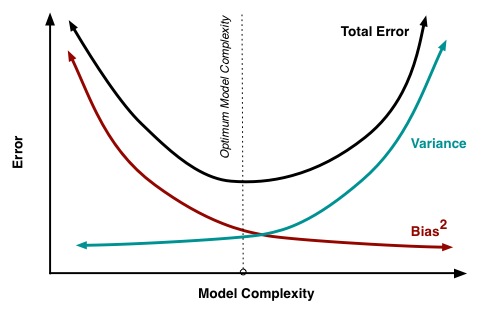
Дилемма bias–variance — конфликт в попытке одновременно минимизировать bias и variance, тогда как уменьшение одного из негативных эффектов, приводит к увеличению другого. Выглядит это как-то так — при небольшой сложности модели мы наблюдаем high bias. При усложнении модели bias уменьшается, но variance увеличится, что приводит к проблеме high variance.

Что такое PCA, и чем он может помочь?
Метод главных компонент (Principal Component Analysis, PCA) – метод сокращения размерности путем нахождения n ортогональных векторов, представляющих наибольшую вариантность из данных, где n – это размерность, до которой пользователь хочет сократить данные. Эти n векторов служат измерениями для новых данных.
PCA может помочь ускорить работу алгоритмов машинного обучения или визуализировать данные слишком большой размерности.
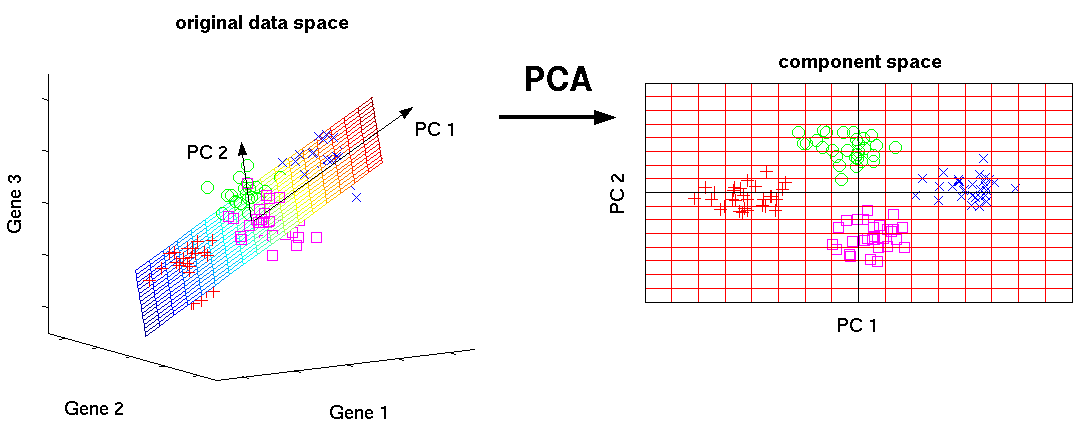
А вот последовательное уменьшение 3D — 2D — 1D:
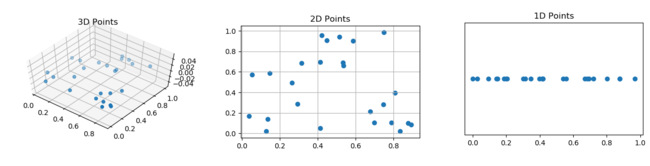
Метод главных компонент часто используется для представления многомерной выборки данных на двумерном графике. Для этого полагают и полученные пары значений
наносят как точки на график.
Проекция на главные компоненты является наименее искаженной из всех линейных проекций многомерной выборки на какую-либо пару осей. Как правило, в осях главных компонент удаётся увидеть наиболее существенные особенности исходных данных, даже несмотря на неизбежные искажения. Например, можно судить о наличии кластерных структур и выбросов.
Две оси и
отражают «две основные тенденции» в данных. Иногда их удаётся интерпретировать, если внимательно изучить, какие точки на графике являются «самыми левыми», «самыми правыми», «самыми верхними» и «самыми нижними». Этот вид анализа не позволяет делать точные количественные выводы и обычно используется с целью понимания данных.
Аналогичную роль играют многомерное шкалирование и карты Кохонена.
А вот так выглядит на практике уменьшение размерности с помощью PCA. Возьмём те самые ирисы:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import decomposition
from sklearn import datasets
# Загрузка данных
centers = [[1, 1], [-1, -1], [1, -1]]
iris = datasets.load_iris()
X = iris.data
y = iris.target
# Преобразование данных датасета Iris, уменьшающее размерность до 2
pca = decomposition.PCA(n_components=3)
pca.fit(X)
X = pca.transform(X)
y = np.choose(y, [1, 2, 0]).astype(float)
plt.clf()
plt.cla()
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.nipy_spectral, edgecolor='k')
plt.xlabel("PC1")
plt.ylabel("PC2")
plt.show()
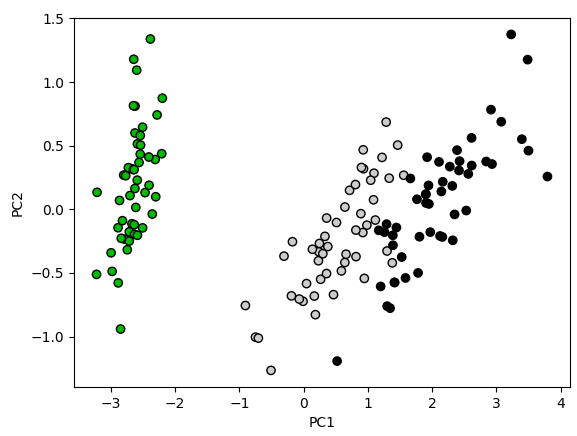
Супер-подробная лекция от ВШЭ по PCA с кодом
Объясните разницу между методами регуляризации L1 и L2.
Регуляризация – метод, который используется в машинном обучении для предотвращения переобучения путем добавления штрафного значения к функции потерь, которую модель пытается минимизировать.
Наиболее популярные — L1 и L2 регуляризация.
L1 чаще полезна в тех случаях, когда из большого количества признаков необходимо отсеять нерелевантные признаки, обнуляя их. И оставить только те признаки, которые имеют отношение к предсказанию.
L2 же используется, когда все признаки имеют отношение к прогнозированию целевого признака, но необходимо уменьшить влияние признаков, которые будут явно выделяться из всего набора признаков при обучении модели.
L1 (или регуляризация Лассо)
Добавляет штрафной коэффициент пропорциональный абсолютному значению весов модели. В общем, L1 устанавливает малые коэффициенты равными нулю, и добавляет штрафы для больших коэффициентов. В итоге у нас получается простая модель с меньшей вероятностью переобучения.
Формула L1 на примере целевой функции модели линейной регрессии:
— целевая функция
— количество выборок в датасете
— вектор целевых значений
— матрица признаков
— весовые коэффициенты
— штраф, который контролирует силу регуляризации
— норма L1 (Манхэттенское расстояние)
Сама норма L1 определяется как сумма абсолютных значений весов:
Так мы можем использовать L1-регуляризацию
import warnings
warnings.filterwarnings("ignore")
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import Lasso
from sklearn.metrics import mean_squared_error
# грузим данные
URL = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/housing.csv"
df = pd.read_csv(URL, header=None)
# используем срез из первых 100
X = df.iloc[:101, 5].values
y = df.iloc[:101, 13].values # target label
# чуть переформатируем данные
X_reshaped = X.reshape(-1, 1)
y_reshaped = y.reshape(-1, 1)
# создаём экземпляр лассо для регрессионной модели
lasso = Lasso(alpha=10)
# тренируем модель
lasso.fit(X_reshaped, y_reshaped)
# прогнозируем
y_pred = lasso.predict(X_reshaped)
# оцениваем модель
mse = mean_squared_error(y_reshaped, y_pred)
print(f"Среднеквадратичная ошибка: {mse}")
print(f"Коэффициент модели: {lasso.coef_}")
# строим линию наиболее лучшего соответствия
sns.scatterplot(x=X.ravel(), y=y.ravel())
plt.plot(X_reshaped.ravel(), y_pred.ravel(), color="red")
plt.title("Модель линейной регрессии с L1-регуляризацией")
plt.show()
# Среднеквадратичная ошибка: 34.709124595627884
# Коэффициент модели: [0.]

P.S. тут коэффициент прямой = 0 чисто в демонстративных целях.
Регуляризация L2 (a.k.a. регуляризация гребня)
Добавляет штрафной коэффициент к функции потерь пропорциональный квадрату весов. Таким образом уменьшает веса до нуля, в результате чего получается более плавная модель с меньшими, но ненулевыми весами для всех объектов. L2 полезна для уменьшения влияния на модель шума или выбросов в данных, а так же повышения стабильности модели.
Формула L2 на примере целевой функции модели линейной регрессии:
— целевая функция
— количество выборок в датасете
— вектор целевых значений
— матрица признаков
— весовые коэффициенты
— штраф, который контролирует силу регуляризации
— норма L2 или Эвклидово расстояние
Норма L2 — это обычное Эвклидово расстояние по "обобщённой теореме Пифагора":
Вот так можно использовать L2
import warnings
warnings.filterwarnings("ignore")
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression, Lasso, Ridge
from sklearn.metrics import mean_squared_error
# грузим данные
URL = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/housing.csv"
df = pd.read_csv(URL, header=None)
# используем срез из первых 100
X = df.iloc[:101, 5].values
y = df.iloc[:101, 13].values # target label
# чуть переформатируем данные
X_reshaped = X.reshape(-1, 1)
y_reshaped = y.reshape(-1, 1)
# создаём экземпляр Ridge, треним, прогнозируем
ridge = Ridge(alpha=100)
ridge.fit(X_reshaped, y_reshaped)
y_pred = ridge.predict(X_reshaped)
# оцениваем модель
mse = mean_squared_error(y_reshaped, y_pred)
print(f"Среднеквадратичная ошибка: {mse}")
print(f"Коэффициент модели: {ridge.coef_}")
# строим линию наиболее лучшего соответствия
sns.scatterplot(x=X.ravel(), y=y.ravel())
plt.plot(X_reshaped.ravel(), y_pred.ravel(), color="red")
plt.title("Модель линейной регрессии с L2-регуляризацией")
plt.show()
# Среднеквадратичная ошибка: 25.96309109305436
# Коэффициент модели: [[1.98542524]]
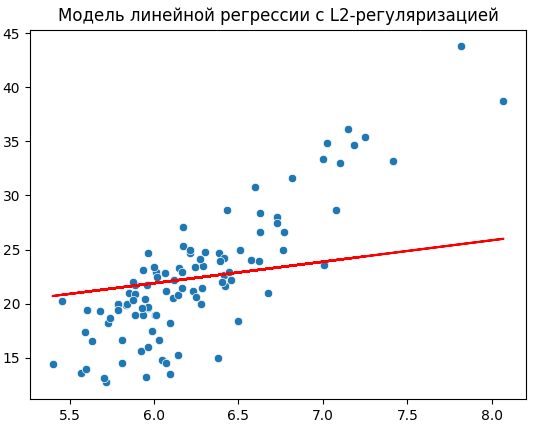
Отличное объяснение с примерами про L1 и L2 есть тут, посмотрите
А вот здесь супер-понятное объяснение L2 почти на пальцах
Ну и финальный вопросов для истинного дата-сайнтиста: "Сколько карандашей используется в Индии?" Пишите ответы и рассуждения в комменты)
Кстати, вот годнота для подготовки к собесу. С любовью отбирал каждый источник, каждый читал хотя бы по диагонали. Если впитать хоть часть этого, то можно в своём познании преисполниться:
Библиотеки Data Science, которые заслуживают вашего внимания
40 вопросов по статистике с собеседований на должность Data Scientist
109 популярных вопросов на собеседовании в сфере Data science
100 Data Science вопросов мидлу! Парень c Физтеха проходит собеседование
Обновляемая структурированная подборка бесплатных ресурсов по Data Science и Machine Learning
Типичные распределения вероятности: шпаргалка data scientist-а
Вкатываемся в Machine Learning с нуля за ноль рублей: что, где, в какой последовательности изучить
51 Python Interview вопрос/ответ на собеседовании для Data Scientist
Собеседование по Data Science: что могут спросить и где найти ответы на вопросы
Кстати, если вам реально хочется изучать Data Science, массу годного контента вы найдёте в моём тг канале — это разборы заданий с собесов и масса полезных инструментов. А вот телеграм канал для тех, кто хочет изучить машинное обучение — Нейронные сети, машинное обучение, python. Вот ещё папка с годными ресурсами по Python — поможет в подготовке к собесу.
Параллельно к этой статье я запилил ролик с разбором части этих вопросов, прошу — https://youtu.be/6Pk4OgdNxXQ

Комментарии (8)

CrazyElf
28.12.2023 12:29+1Отлично, что такой большой материал. Но сразу бросилось несколько вещей в глаза:
Зачем несколько однотипных вопросов на среднее и медиану (и моду), одного раза недостаточно?
"Многопроцессорность" - вы бы погуглили, что это такое на самом деле. Видимо, правильно тут будет "многопроцессность".
Вопросы насчёт
SVM- это вообще актуально? Кто-то применяет ещёSVMкроме как в учебных целях, чтобы просто выучить побольше разных видов моделей?Да и "случайный лес" уже тоже своё отжил, так что выбор между
SVMиRF- это выбор между двумя аутсайдерами.
А так то материал огонь, многое знаю, но где-то и плаваю до сих пор (особенно в тервере и прочей математике, Мехмат я окончил почти 30 лет назад и ничего оттуда не помню).

tim_leon
28.12.2023 12:29+1По 3 и 4 пункту - не так давно анализировал статьи по материаловедению, причем достаточно новые, зарубежные, и там применялись SVM и RF, SVM конечно в гораздо меньшей степени чем RF, применялись для классификации в большей степени фаз и т.д.
CrazyElf
28.12.2023 12:29Спасибо, интересно. Я в "живой среде" в основном в банках видел что применяется, ну и вообще что на слуху, у меня было стойкое ощущение, что кроме линейной/логистической регрессии и бустингов ничего практически не выжило больше.

Akina
28.12.2023 12:29+1Просмотрел только раздел по MySQL (в остальных - не такой уж и спец). Явная демонстрация практически полного непонимания того, о чём пишете. Плюс присутствует недостоверная и просто ошибочная информация - интересно, у кого это было списано? Хотя для DS, может, этого и достаточно...

deadmoroz14
28.12.2023 12:29+2Большое количество вопросов поставлено некорректно. Либо мало данных, либо поставлен слишком широко.
Например:Напишите функцию, которая определяет количество шагов для преобразования одного слова в другое
И в ответе сразу "наша функция должна принимать на вход 3 аргумента".
Откуда я об этом знать должен? Задание сформулировано так, что как будто даётся только слово "до" и слово "после" (и при этом ещё не сказано, что подразумевается под "преобразованием" )
Ну и зачем нужны такие вопросы в рамках подготовки?Вы баллотируетесь на пост, в выборке из 100 избирателей 60 будут голосовать за вас. Можете ли вы быть уверены в победе?
Нет (см. gerrymandering).
На вопрос ответил? Ответил. Но это совсем не то, что в предполагаемом правильном ответе.
Надо чётче формулировать .Ну и отдельно отмечу вопросы из серии
Как построить простую модель логистической регрессии на Python?
Где в коде ответа фигурирует
from sklearn.linear_model import LogisticRegressionБраво! Прямо-таки чистый Python!
Хотя чего это я, судя по корявой терминологии, это просто плохой перевод какой-то другой статьи:
метод максимизации подобия
правдоподобия
многопроцессорное приложение
многопроцессное
NumPy использует более оптимизированную память
Это как вообще?

annatok8794
28.12.2023 12:29Функция
LAGпозволяет запрашивать более одной строки в таблице, не вступая в таблицу к себе.При копировании перевода с Английского затесалась ошибочка
nikolay_karelin
Хорошая подборка.
К сожалению, часть изображений и фото не отображаются :(