Привет, Хабр!
Представляю 50+ вопросов для подготовки к собеседованию C#, грейд — джуниор/мидл.
Вопросы разные: есть сложные/простые, с детальным объяснением и с ответом в пару предложений.
Anyway, должно быть полезно, поскольку я выбрал самые частотные вопросы
Вообще по поводу собеседований на C#/.Net разработчика, на Хабре статей хватает, вот две, где освещаются вопросы с собесов: тут и здесь.
Но в этих статьях не хватает детального разбора вопросов, что я и решил исправить.
А кто хочет еще больше Для всех в моем канале о С# мы разбираем вопросы с реальных собеседований, публикуем гайды, полезные инструменты и многое другое, welcome! А здесь целая папка полезного для C# разработчиков.
Вообще, по моим и не только наблюдениям C# сейчас бурно развивается, в прошлом 2023 году TIOBE даже назвали C# языком года, что придаёт некоторую уверенность в завтрашнем дне для шарписта.
Так что пока кто-то всё ждёт конец света сингулярность (ну же, ещё чуть-чуть), другая часть несмотря ни на что готовится, проходит тернистый путь от тестового задания до оффера и вливается в C#-разработку, с чем я их искренее поздравляю.
В общем, уверен эта статья будет полезна для подготовки, не будем уже тянуть, поехали!

Оглавление
Расскажи про паттерн Singleton
Напиши программу для сложения всех чётных чисел в массиве
Что такое deadlock? Что делать со взаимоблокировками и как их избежать?
Напиши код, который считывает введённое расстояние в км и выводит ответ в метрах
Расскажи про асинхронность и где она применяется. Для чего нужны async, await?
await — во что эта конструкция разворачивается компилятором?
Потокобезопасен ли List? Вообще, расскажи про потокобезопасные коллекции
Отличие между операцией cast (приведения типов) и оператором as?
Алгоритмическая сложность для чтения и записи в Dictionary?
Расскажи о Dictionary и как он устроен?
Почему желательно получать хеши, равномерно распределённые по диапазону целых чисел?
В чем различие между "ref" и "out"?
В чем отличие необязательных параметров от именованных?
Отличия классов String и StringBuilder
Значимые и ссылочные типы — в чём отличия?
Как и для чего нужна конструкция using?
В чем отличие Finalize и Dispose?
В чем основные отличия класса от структуры в языке C#?
Как можно сравнить строки в C#?
Что такое управляемый код и CLR? Основные требования к управляемому коду.
Разница IEnumerable и IQueryable при работе с удаленной БД?
Расскажи про принцип инверсии зависимостей (Dependency Inversion)
Расскажи про свойства в C#?
Что такое assembly manifest (манифест сборки)?
Что такое GAC? Возможно ли поместить два файла с одинаковым именем в Global Assembly Cache?
Модификаторы доступа в C# — какие знаешь?
Расскажи про Boxing и Unboxing?
В чем суть полиморфизма?
Какие типы можно использовать в предложении foreach?
Чем отличается event от delegate?
Может ли класс реализовать два интерфейса, у которых объявлены одинаковые методы? Если да, то как?
В чём разница между System.Array.CopyTo() и System.Array.Clone()?
Что такое абстрактный класс? В каком случае вы обязаны объявить класс абстрактным?
Что общего между интерфейсами и абстрактными классами? В чём отличия? Когда что использовать?
В чем разница между абстрактными и виртуальными классами?
Что означает модификатор virtual?
В чем разница инкапсуляции и сокрытия?
Что такое частные и общие сборки?
Разница между LINQ lazy loading и eager loading
Можно ли запретить наследование от какого-то класса?
Можно запретить переопределение метода, но разрешить наследование класса?
Расскажи про Thread, Task
Что такое интеграционные тесты и unit-тесты?
Что такое MVVM?
Где использовать StringBuilder вместо String?
Какой уровень доступа имеют поля класса, если модификатор доступа не указан?
Как можно присвоить значения полям, которые помечены readonly?
Как блокируется одновременное выполнение одних участков кода несколькими потоками?
Какой интерфейс должен реализовать класс, чтобы к переменной данного типа был применим foreach?
Когда вызывается статический конструктор класса?
Чем отличаются константы и поля, доступные только для чтения?

✦ Расскажи про паттерн Singleton
Singleton (Одиночка, Синглтон) — порождающий паттерн, который гарантирует, что для определенного класса будет создан только один объект, а также предоставит к этому объекту точку доступа. Используется тогда, когда необходимо, чтобы для класса существовал только один экземпляр. Синглтоны бывают потокобезопасные и нет, с простой и отложенной инициализацией.
class Singleton
{
private static readonly Singleton _instance = new Singleton();
private Singleton() {}
static Singleton() {}
public static Singleton Instance { get { return _instance; } }
}
Существуют различные способы реализации Singleton в C#. Я приведу некоторые из них здесь в обратном порядке элегантности, начиная с наиболее часто встречающихся. Все эти реализации имеют четыре общие характеристики:
Единый конструктор, который является закрытым (модификатор
private) и без параметров. Это предотвратит создание других экземпляров (что было бы нарушением паттерна).Класс должен быть запечатанным (модификатор
sealed). Строго говоря это является необязательным условием, исходя из вышеизложенных концепций Singleton, но позволяет JIT-компилятору улучшить оптимизацию.Переменная, которая содержит ссылку на созданный экземпляр, должна быть статической.
Необходимо открытое (
public) статичное свойство, которое будет содержать ссылку на созданный экземпляр.
При реализации Singleton мы будем использовать общедоступное статическое свойство с названием Source, как средство доступа к экземпляру. Во всех случаях свойство может быть легко преобразовано в метод, не влияя на потокобезопасность или производительность.

1 версия - не потокобезопасная
// Пример реализации без использования потокобезопасности
public sealed class Singleton
{
private Singleton()
{
}
private static Singleton source = null;
public static Singleton Source
{
get
{
if (source == null)
source = new Singleton();
return source;
}
}
}
Вышеуказанная реализация не является потокобезопасной. Два разных потока могли бы пройти условие if (source == null), создав два экземпляра, что нарушает принцип Singleton. Обратите внимание, что на самом деле экземпляр, возможно, уже был создан до того, как условие будет пройдено, но модель памяти не гарантирует, что новое значение экземпляра будет видно другим потокам, если не будут приняты соответствующие блокировки.

2 версия - простая защита от потоков
public sealed class Singleton
{
private Singleton()
{
}
private static Singleton source = null;
private static readonly object threadlock = new object();
public static Singleton Source
{
get
{
lock (threadlock)
{
if (source == null)
source = new Singleton();
return source;
}
}
}
}
Эта реализация является потокобезопасной. Поток создает блокировку для общего объекта threadlock, а затем проверяет, был ли экземпляр создан до создания текущего экземпляра. Это устраняет проблему с защитой памяти (поскольку блокировка гарантирует, что все чтения экземпляра класса Singleton будут логически происходить после завершения блокировки, а разблокировка гарантирует, что все записи будут выполняться логически до освобождения блокировки) и гарантирует, что только один поток создаст экземпляр. К сожалению производительность данной версии страдает, поскольку блокировка возникает всякий раз, когда запрашивается экземпляр.
Обратите внимание, что вместо блокировки типа typeof(Singleton), как это делают в некоторых реализациях Singleton, я блокирую значение статической переменной, которая является закрытой (private) внутри класса. Блокировка объектов, к которым могут обращаться другие классы, ухудшает производительность и вносит риск взаимоблокировки. Я использую простой стиль - по возможности нужно блокировать объекты, специально созданные с целью блокировки. Обычно такие объекты должны быть использовать модификатор private.

3 версия - потокобезопасная без использования lock
public sealed class Singleton
{
// Явный статический конструктор сообщает компилятору C#
// не помечать тип как beforefieldinit
static Singleton() { }
private Singleton() { }
private static readonly Singleton source = new Singleton();
public static Singleton Source
{
get
{
return source;
}
}
}
Как вы можете заметить, это действительно очень простая реализация - но почему она является потокобезопасной и как в данном случае работает ленивая загрузка? Статические конструкторы в C# вызываются для выполнения только тогда, когда создается экземпляр класса или ссылается на статический член класса, и выполняются только один раз для AppDomain. Эта версия будет быстрее предыдущей, т.к. отсутствует дополнительная проверка на значение null. Однако в данной реализации есть несколько недочетов:
Загрузка является не такой ленивой, как в других реализациях. В частности, если у вас в классе
Singletonесть другие статические члены, кромеSource, для доступа к этим членам потребуется создание экземпляра. Это будет исправлено в следующей реализации.Возникнет проблема, если один статический конструктор вызовет другой, который, в свою очередь вызовет первый.

4 версия - полностью ленивая загрузка
public sealed class Singleton
{
private Singleton() { }
public static Singleton Source { get { return Nested.source; } }
private class Nested
{
static Nested()
{
}
internal static readonly Singleton source = new Singleton();
}
}
Здесь экземпляр инициируется первой ссылкой на статический член вложенного класса, который используется только в Source. Это означает, что эта реализация полностью поддерживает ленивое создание экземпляра, но при этом имеет все преимущества производительности предыдущих версий. Обратите внимание, что хотя вложенные классы имеют доступ к закрытым членам верхнего класса, обратное неверно, поэтому необходимо использовать модификатор internal. Это не вызывает никаких других проблем, поскольку сам вложенный класс является закрытым (private).

5 вариант - с использованием типа Lazy
Если вы используете версию .NET Framework 4 (или выше), вы можете использовать тип System.Lazy<T>, чтобы реализовать ленивую загрузку очень просто. Все, что вам нужно сделать, это передать делегат конструктору, который вызывает конструктор Singleton, которому передается лямбда-выражение:
public sealed class Singleton
{
private Singleton() { }
private static readonly Lazy<Singleton> lazy =
new Lazy<Singleton>(() => new Singleton());
public static Singleton Source { get { return lazy.Value; } }
}
Это довольная простая реализация, которая хорошо работает. Она также позволяет вам проверить, был ли экземпляр создан с использованием свойства IsValueCreated, если вам это нужно.

Кстати вот, годная статья в тему — «Паттерн Singleton в C#»

✦ Напиши программу для сложения всех чётных чисел в массиве
Вариантов много, вот 2 самых простых:
static long TotalAllEvenNumbers(int[] intArray) {
return intArray.Where(i => i % 2 == 0).Sum(i => (long)i);
}
или
static long TotalAllEvenNumbers(int[] intArray) {
return (from i in intArray where i % 2 == 0 select (long)i).Sum();
}
Также можно упомянуть, что реализация intArray.Where(i => i% 2 == 0).Sum() может быть легко написана в одну строку, но тогда высока вероятность переполнения.

✦ Что такое deadlock? Что делать со взаимоблокировками и как их избежать?
Deadlock — взаимная блокировка. Deadlock случается, когда каждый из двух потоков ожидает ресурс, удерживаемый другим потоком, поэтому ни один из них не может продолжить работу.
Существует много разных вариаций взаимоблокировки. Наиболее частой можно считать следующую:
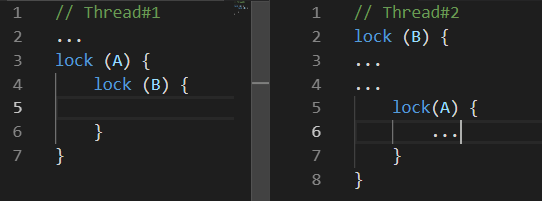
Пока Thread#1 что-то делал, Thread#2 заблокировал ресурс B, немного позднее Thread#1 заблокировал ресурс A и пытается заблокировать ресурс B.
К сожалению это никогда не произойдет, т.к. Thread#2 освободит ресурс B лишь после того как заблокирует ресурс А.

Взаимоблокировка представляет собой одну из самых сложных проблем многопоточности — особенно, когда имеется множество взаимосвязанных объектов. В сущности, сложная проблема заключается в том, что вы не уверены, какие блокировки получил вызывающий поток.
Как ни странно, проблема взаимоблокировки усугубляется (хорошими) шаблонами объектно-ориентированного проектирования, поскольку такие шаблоны создают цепочки вызовов, не определяемые вплоть до этапа выполнения.

Как избежать взаимоблокировки потоков? В целом это не так сложно, нужно просто проявлять осторожность при блокировании вызывающих методов в объектах, которые могут иметь ссылки на ваш объект. Кроме того, имеет смысл подумать, действительно ли нужна блокировка вызывающих методов в других классах. Выбирая средства синхронизации более высокого уровня, такие как продолжения/комбинаторы задач, параллелизм данных и неизменяемые типы, можно снизить потребность в блокировании.

✦ Напиши код, который считывает введённое расстояние в км и выводит ответ в метрах
Какой-то стыдно-простой вопрос, но пусть будет. Делается элементарно:
using System;
class abc
{
public static void Main()
{
int ndistance, nresult;
Console.WriteLine("Введи расстояние в км: ");
ndistance = Convert.ToInt32(Console.ReadLine());
nresult = ndistance * 1000;
Console.WriteLine("Расстояние в метрах: " + nresult);
Console.ReadLine();
}
}

✦ Расскажи про асинхронность и где она применяется. Для чего нужны async, await?
Асинхронность позволяет вынести отдельные задачи из основного потока в специальные асинхронные методы и при этом более экономно использовать потоки. Асинхронные методы выполняются в отдельных потоках. Однако при выполнении продолжительной операции поток асинхронного метода возвратится в пул потоков и будет использоваться для других задач. А когда продолжительная операция завершит свое выполнение, для асинхронного метода опять выделяется поток из пула потоков, и асинхронный метод продолжает свою работу.
Ключевыми для работы с асинхронными вызовами в C# являются два оператора: async и await, цель которых — упростить написание асинхронного кода.
Асинхронный метод обладает следующими признаками:
В заголовке метода используется модификатор
asyncМетод содержит одно или несколько выражений
await-
В качестве возвращаемого типа используется один из следующих:
void,Task,Task<T>,ValueTask<T>
Асинхронный метод, как и обычный, может использовать любое количество параметров или не использовать их вообще. Однако асинхронный метод не может определять параметры с модификаторами out, ref и in.
Также стоит отметить, что слово async, которое указывается в определении метода, не делает автоматически метод асинхронным. Оно лишь указывает, что данный метод может содержать одно или несколько выражений await.
Рассмотрим простейший пример определения и вызова асинхронного метода:
await PrintAsync(); // вызов асинхронного метода
Console.WriteLine("Некоторые действия в методе Main");
void Print()
{
Thread.Sleep(3000); // имитация продолжительной работы
Console.WriteLine("Hello METANIT.COM");
}
// определение асинхронного метода
async Task PrintAsync()
{
Console.WriteLine("Начало метода PrintAsync"); // выполняется синхронно
await Task.Run(() => Print()); // выполняется асинхронно
Console.WriteLine("Конец метода PrintAsync");
}
Здесь прежде всего определен обычный метод Print, который просто выводит некоторую строку на консоль. Для имитации долгой работы в нем используется задержка на 3 секунд с помощью метода Thread.Sleep(). То есть условно Print — это некоторый метод, который выполняет некоторую продолжительную операцию. В реальном приложении это могло бы быть обращение к базе данных или чтение-запись файлов, но для упрощения понимания он просто выводит строку на консоль.
Также здесь определен асинхронный метод PrintAsync(). Асинхронным он является потому, что имеет в определении перед возвращаемым типом модификатор async, его возвращаемым типом является Task, и в теле метода определено выражение await.
Стоит отметить, что явным образом метод PrintAsync не возвращает никакого объекта Task, однако поскольку в теле метода применяется выражение await, то в качестве возвращаемого типа можно использовать тип Task.
Оператор await предваряет выполнение задачи, которая будет выполняться асинхронно. В данном случае подобная операция представляет выполнение метода Print:
await Task.Run(()=>Print());
По негласным правилам в названии асинхронных методов принято использовать суффикс Async — PrintAsync(), хотя в принципе это необязательно делать.
И затем в программе (в данном случае в методе Main) вызывается этот асинхронный метод.
await PrintAsync(); // вызов асинхронного метода
А вот таким будет консольный вывод:
Начало метода PrintAsync
Hello METANIT.COM
Конец метода PrintAsync
Некоторые действия в методе Main

Асинхронный метод Main. Стоит учитывать, что оператор await можно применять только в методе, который имеет модификатор async. И если мы в методе Main используем оператор await, то метод Main тоже должен быть определен как асинхронный. То есть предыдущий пример фактически будет аналогичен следующему:
class Program
{
async static Task Main(string[] args)
{
await PrintAsync(); // вызов асинхронного метода
Console.WriteLine("Некоторые действия в методе Main");
void Print()
{
Thread.Sleep(3000); // имитация продолжительной работы
Console.WriteLine("Hello METANIT.COM");
}
// определение асинхронного метода
async Task PrintAsync()
{
Console.WriteLine("Начало метода PrintAsync"); // выполняется синхронно
await Task.Run(() => Print()); // выполняется асинхронно
Console.WriteLine("Конец метода PrintAsync");
}
}
}

Задержка асинхронной операции. В асинхронных методах для остановки метода на некоторое время можно применять метод Task.Delay(). В качестве параметра он принимает количество миллисекунд в виде значения int, либо объект TimeSpan, который задает время задержки:
await PrintAsync(); // вызов асинхронного метода
Console.WriteLine("Некоторые действия в методе Main");
// определение асинхронного метода
async Task PrintAsync()
{
await Task.Delay(3000); // имитация продолжительной работы
// или так
//await Task.Delay(TimeSpan.FromMilliseconds(3000));
Console.WriteLine("Hello METANIT.COM");
}
Причем метод Task.Delay сам по себе представляет асинхронную операцию, поэтому к нему применяется оператор await.

Преимущества асинхронности. Выше приведенные примеры являются упрощением, и вряд ли их можно считать показательным. Рассмотрим другой пример:
PrintName("Tom");
PrintName("Bob");
PrintName("Sam");
void PrintName(string name)
{
Thread.Sleep(3000); // имитация продолжительной работы
Console.WriteLine(name);
}
Данный код является синхронным и выполняет последовательно три вызова метода PrintName. Поскольку для имитации продолжительной работы в методе установлена задержка на три секунды, то общее выполнение программы займет не менее 9 секунд. Так как каждый последующий вызов PrintName будет ждать пока завершится предыдущий.
Изменим в программе синхронный метод PrintName на асинхронный:
await PrintNameAsync("Tom");
await PrintNameAsync("Bob");
await PrintNameAsync("Sam");
// определение асинхронного метода
async Task PrintNameAsync(string name)
{
await Task.Delay(3000); // имитация продолжительной работы
Console.WriteLine(name);
}
Вместо метода PrintName теперь вызывается три раза PrintNameAsync. Для имитации продолжительной работы в методе установлена задержка на 3 секунды с помощью вызова Task.Delay(3000). И поскольку при вызове каждого метода применяется оператор await, который останавливает выполнение до завершения асинхронного метода, то общее выполнение программы опять же займет не менее 9 секунд. Тем не менее теперь выполнение асинхронных операций не блокирует основной поток.
Теперь оптимизируем программу:
var tomTask = PrintNameAsync("Tom");
var bobTask = PrintNameAsync("Bob");
var samTask = PrintNameAsync("Sam");
await tomTask;
await bobTask;
await samTask;
// определение асинхронного метода
async Task PrintNameAsync(string name)
{
await Task.Delay(3000); // имитация продолжительной работы
Console.WriteLine(name);
}
В данном случае задачи фактически запускаются при определении. А оператор await применяется лишь тогда, когда нам нужно дождаться завершения асинхронных операций - то есть в конце программы. И в этом случае общее выполнение программы займет не менее 3 секунд, но гораздо меньше 9 секунд.

Определение асинхронного лямбда-выражения. Асинхронную операцию можно определить не только с помощью отдельного метода, но и с помощью лямбда-выражения:
// асинхронное лямбда-выражение
Func<string, Task> printer = async (message) =>
{
await Task.Delay(1000);
Console.WriteLine(message);
};
await printer("Hello World");
await printer("Hello METANIT.COM");

Сверхполезная статья — «Асинхронные методы, async и await»

✦ await — во что эта конструкция разворачивается компилятором?
Конструкция async/await разворачивается компилятором в конечный автомат. В конечном автомате переменные вашего метода становятся полями, чем достигается возможность запоминать состояние работы метода и продолжать его после ожидания завершения длительной операции.
async/await основан на TAP , поэтому новые потоки действительно могут и не создаваться, если в этом нет необходимости, и задача, поставленная в await может быть выполнена в текущем потоке. Это и не важно. Используя async/await вы добиваетесь не параллельного выполнения, а асинхронного. Конечный автомат умеет дождаться завершения длительных операций, выходящих за рамки вашего кода, таких как отправка запросов по сети, обращение к дисковой системе или СУБД. В этом и есть основное преимущество использования async/await.
Вот пример:
async Task<Model> GetModel(Func<Model, bool> condition)
{
var model = await dbContext.Models.FirstOrDefaultAsync(condition);// здесь текущий поток освобождается, и может выполнять другую работу. Работа метода возобновиться, после получения ответа от БД
return model;
}
Также следует отметить, что нужно быть внимательными и добиваться истинной асинхронности в коде. Истинный асинхронный код должен ставить в await только те методы, которые действительно освобождают поток и дожидаются выполнения операции, после чего реагируют на это. Часто такие методы основаны на EAP. Метод FirstOrDefaultAsync - это правильный метод. Если использовать не истинную асинхронность это не даст возможности освобождать потоки в await, чем не только убьет возможность масштабирования кода, но может и сделать его менее эффективным, чем без использования async/await, поскольку возможна ситуация переключения контекстов выполнения.
async Task<Model> GetModel(Func<Model, bool> condition)
{
var model = await Task.Run(dbContext.Models.FirstOrDefault(condition);)
return model;
}
Этот код выше будет работать, но асинхронности здесь не будет. Потоки освобождаться не будут. Наоборот, текущий поток должен дождаться выполнения Task, которая обращается к БД. В момент когда выполнение доходит до await выполнение прерывается и текущий поток освобождается. Но код внутри Task не является асинхронным, и он заморозит поток, пока не получит ответ от БД.
Как-то так

✦ Потокобезопасен ли List? Вообще, расскажи про потокобезопасные коллекции
Нет, List не потокобезопасен.
Самый простой способ сделать его таким — это блокировать доступ к базовым коллекциям (читать и писать) с помощью lock.

Ок, теперь неплохо было бы обсудить потокобезопасные коллекции.
Потокобезопасные коллекции. Пространство имён System.Collections.Concurrent (доки) содержит все стандартные потокобезопасные коллекции. Их поведение и методы отличаются от обычных аналогов, поэтому стоит изучить, как с ними правильно работать. Половина потокобезопасных коллекций строится на интерфейсе IProducerConsumerCollection<T>, он то и добавляет что-то общее между этими коллекциями. Остальные имеют более специфическое назначение.
Почитать про потокобезопасные коллекции можно здесь. Можно посмотреть даже видео.

ConcurrentList. Так же стоит отметить, что в .NET отсутствует коллекция ConcurrentList<T>, есть подробный ответ на этот вопрос.
Вот пример реализации самого простого потокобезопасного списка на базе ReaderWriterLockSlim, который я когда-то написал для другого ответа. Можно считать это болванкой для своего собственного решения.
public class ConcurrentList<T> : IEnumerable<T>, ICollection<T>
{
private readonly List<T> _list;
private readonly ReaderWriterLockSlim _lock;
public int Count
{
get
{
try
{
_lock.EnterReadLock();
return _list.Count;
}
finally
{
_lock.ExitReadLock();
}
}
}
public bool IsReadOnly => false;
public ConcurrentList() : this(null) { }
public ConcurrentList(IEnumerable<T> items)
{
_list = items is null ? new List<T>() : new List<T>(items);
_lock = new ReaderWriterLockSlim();
}
public void Add(T item)
{
try
{
_lock.EnterWriteLock();
_list.Add(item);
}
finally
{
_lock.ExitWriteLock();
}
}
public void Clear()
{
try
{
_lock.EnterWriteLock();
_list.Clear();
}
finally
{
_lock.ExitWriteLock();
}
}
public bool Contains(T item)
{
try
{
_lock.EnterReadLock();
return _list.Contains(item);
}
finally
{
_lock.ExitReadLock();
}
}
public void CopyTo(T[] array, int arrayIndex)
{
try
{
_lock.EnterReadLock();
_list.CopyTo(array, arrayIndex);
}
finally
{
_lock.ExitReadLock();
}
}
public bool Remove(T item)
{
try
{
_lock.EnterWriteLock();
return _list.Remove(item);
}
finally
{
_lock.ExitWriteLock();
}
}
private IEnumerable<T> Enumerate()
{
try
{
_lock.EnterReadLock();
foreach (T item in _list)
yield return item;
}
finally
{
_lock.ExitReadLock();
}
}
public IEnumerator<T> GetEnumerator()
=> Enumerate().GetEnumerator();
IEnumerator IEnumerable.GetEnumerator()
=> Enumerate().GetEnumerator();
}

Неизменяемые коллекции. Так же существуют неизменяемые коллекции System.Collections.Immutable. Они тоже являются потокобезопасными, так как данные в них нельзя изменить, а следовательно к ним можно получать безопасный доступ из нескольких потоков. Подробнее почитать можно здесь.

✦ Отличие между операцией cast (приведения типов) и оператором as?
Если в двух словах, то оператор as отличается от приведения типа cast только тем, что он никогда не сгенерирует исключение, даже когда присвоение типа невозможно. В ситуации, когда явное/неявное приведения типа выдаст ошибку CastEcxeption — оператор as просто присвоит переменной значение null.
Если после этого сравнить результат, полученный оператором, с null, или попытаться как-то работать с этой пустой ссылкой - получится, как и предполагается, NullReferenceException.

✦ Алгоритмическая сложность для чтения и записи в Dictionary?
Простейший вопрос, но мало ли.
Итак, чтение очень быстрое, потому что используются хэш-таблицы и сложность в этом случае стремится к O(1).
Запись проходит тоже очень быстро — O(1), в том случае если .Count() меньше емкости, если же больше, то скорость стремится к O(n).

✦ Расскажи о Dictionary и как он устроен?
Словарь (dictionary) — это обобщенная версия Hashtable, содержащая в себе объект структуры KeyValuePair<TKey, TValue>.
Главное свойство Dictionary — быстрый поиск с помощью ключей. Можно также добавлять и удалять элементы, наподобие того как это делается в List<T>, но без расходов производительности, связанных с необходимостью смещения последующих элементов в памяти.

Немного подробнее о работе Dictionary.
Инициализация. Инициализация происходит либо при создании (если передана начальный размер коллекции), либо при добавлении первого элемента, причем в качестве размера будет выбрано ближайшее простое число (3). При этом создаются 2 внутренние коллекции — int[] buckets и Entry[] entries. Первая будет содержать индексы элементов во второй коллекции, а она, в свою очередь, — сами элементы в таком виде:
private struct Entry
{
public int hashCode;
public int next;
public TKey key;
public TValue value;
}

Добавление элементов. При добавлении элемента вычисляется хэшкод его ключа и затем — индекс корзины в которую он будет добавлен по модулю от величины коллекции:
int bucketNum = (hashcode & 0x7fffffff) % capacity;
Выглядеть это будет примерно так:
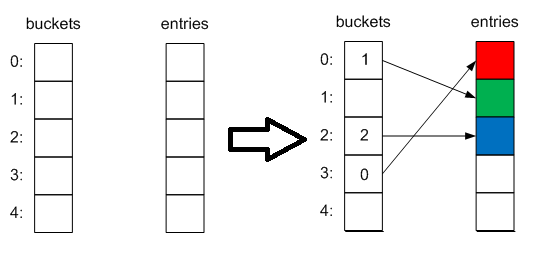
Затем проверяется нет ли уже такого ключа в коллекции, если есть — то операция Add выбросит исключение, а присваивание по индексу просто заменит элемент на новый. Если достигнут максимальный размер словаря, то происходит расширение (выбирается новый размер ближайшим простым числом). Сложность операции соответственно — O(n).
Если происходит коллизия (то есть в корзине индексов bucketNum уже есть элемент), то новый элемент добавляется в коллекцию, его индекс сохраняется в корзине, а индекс старого элемента — в его поле next.

Таким образом получаем однонаправленный связный список. Данный механизм разрешения коллизий называется chaining.
Если при добавлении элемента число коллизий велико (больше 100 в текущей версии), то при расширении коллекции происходит операция перехэширования, перед выполнением которой случайным образом выбирается новый генератор хэш-кодов. Сложность добавления O(1) или O(n) в случае коллизии.

Удаление элементов. При удалении элементов мы затираем его содержимое значениями по умолчанию, меняем указатели next других элементов при необходимости и сохраняем индекс этого элемента во внутреннее поле freeList, а старое значение — в поле next. Таким образом, при добавлении нового элемента мы можем повторно использовать такие свободные ячейки:
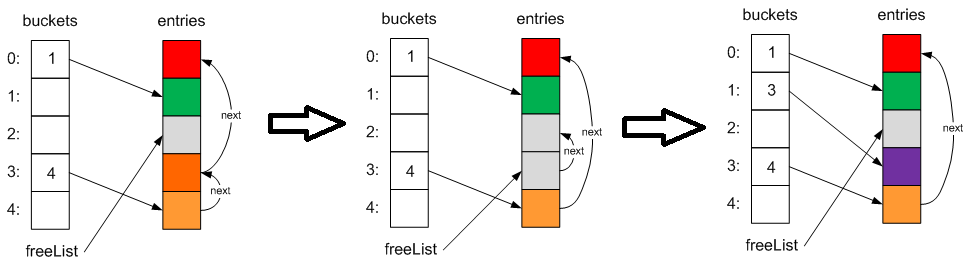
Сложность снова O(1) или O(n) в случае коллизии.

Годная статья — «Под капотом у Dictionary и ConcurrentDictionary»

✦ Почему желательно получать хеши, равномерно распределённые по диапазону целых чисел?
Ну, в целом всё очевидно.
Если два ключа возвращают хеш-значения, дающие один и тот же индекс, класс словаря вынужден искать ближайшее доступное свободное место для сохранения второго элемента, к тому же ему придется выполнять некоторый поиск, чтобы впоследствии извлечь требуемое значение.
Понятно, что это наносит ущерб производительности, и если множество ключей дают одни и те же индексы, куда их следует поместить, вероятность конфликтов значительно возрастает. И вместо идеальной сложности чтения-записи O(1) мы получаем чуть ли не O(n).

✦ В чем различие между "ref" и "out"?
Если в двух словах, то параметр с ключевым слово out может быть не инициализирован, а параметр с ключевым словом ref обязательно должен быть инициализирован до вызова метода, который использует эти параметры.
Давайте на примере разберем, что это значит. Создадим метод, который будет принимать числовой параметр. В данном методе этот параметр будем увеличивать и выводить значение. В методе Main() создадим параметр с этим же именем и будем также выводить его значение:
static void Main(string[] args)
{
int param = 10;
testMethod(param); //Выйдет значение = 11
Console.WriteLine("Значение переменной param в методе Main = {0}", param); //Выйдет значение = 10
Console.ReadLine();
}
static void testMethod(int param)
{
param++;
Console.WriteLine("Значение переменной param в методе testMethod = {0}", param);
}
Во втором случае вышло 10, потому что int — это ValueType (это когда параметр передаётся по значению), это значит, что при выполнении команды testMethod(param) метод testMethod() будет работать с копией переменной param (в данный момент происходит копирование переменной в стеке), что никак не повлияет на переменную param, которая была объявлена в методе Main().
Модифицируем наш код, добавив оператор ref перед переменной в методе testMethod(). Обратите внимание, что при вызове данного метода нужно также ставить оператор ref:
static void Main(string[] args)
{
int param = 10;
testMethod(ref param); //Выйдет значение = 11
Console.WriteLine("Значение переменной param в методе Main = {0}", param); //Выйдет значение = 11
Console.ReadLine();
}
static void testMethod(ref int param)
{
param++;
Console.WriteLine("Значение переменной param в методе testMethod = {0}", param);
}
Теперь программа в обоих случаях выводит 11. Тут дело в том, что мы в стек (это область памяти в пространстве адресов) загоняем ссылку на область памяти, где находится переменная param, и в методе testMethod() мы уже работаем не с копией, а с тем же самым параметром param, что и в методе Main(). Те изменения, которые мы провели с переменной param в методе testMethod() будут видны и снаружи (за областью видимости метода).
Внесем изменения в наш код. Просто объявим переменную param, но не будем её инициализировать, т.е. вместо строки int param = 10; запишем int param;. Компилятор старается контролировать использование неинициализированных переменных вы даст ошибку в этом случае. Мы пытаемся переменную, которая не содержит никаких значений, передать в метод и там с ней выполнять определенные действия, но так делать нельзя. А что делать если инициализация переменной выполняется как раз в этом методе?
В этом случае как раз и используют out:
static void Main(string[] args)
{
int param;
testMethod(out param); //Выйдет значение = 11
Console.WriteLine("Значение переменной param в методе Main = {0}", param); //Выйдет значение = 11
Console.ReadLine();
}
static void testMethod(out int param)
{
param = 10;
param++;
Console.WriteLine("Значение переменной param в методе testMethod = {0}", param);
}
Теперь в методе testMethod() обязательно нужно проинициализировать переменную param.

Норм статья в тему — «ref и out в C#»

✦ В чем отличие необязательных параметров от именованных?
Необязательные параметры позволяют опускать аргументы функции, в то время как именованные параметры разрешают передавать аргументы по названию параметра.
public void optionalParamFunc(int p1, int p2 = 2, int p3 = 3);
optionalParamFunc(1, p3:10); //это эквивалентно optionalParamFunc(1,2,10);

Пример использования необязательных аргументов показан ниже:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace ConsoleApplication1
{
class Program
{
// Аргументы b и с указывать при вызове необязательно
static int mySum(int a, int b = 5, int c = 10)
{
return a + b + c;
}
static void Main()
{
int sum1 = mySum(3);
int sum2 = mySum(3,12);
Console.WriteLine("Sum1 = "+sum1);
Console.WriteLine("Sum2 = "+sum2);
Console.ReadLine();
}
}
}
// Sum1 = 18
// Sum2 = 25

Пример использования именованных аргументов:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace ConsoleApplication1
{
class Program
{
static int mySum(int a, int b = 5, int c = 10)
{
return a + b + c;
}
static void Main()
{
// Использование именованных аргументов
// при вызове метода
int sum1 = mySum(a: 3, b: 10);
Console.WriteLine("Sum1 = " + sum1); // 3 + 10 + 10 (c)
Console.ReadLine();
}
}
}
// Sum1 = 23

✦ Отличия классов String и StringBuilder
Объект класса String представляет собой неизменяемую строку. Когда выполняется какой-нибудь метод класса String, система создает новый объект в памяти с выделением ему достаточного места.
Объект класса StringBuilder представляет собой динамическую строку. При создании строки StringBuilder выделяет памяти больше, чем необходимо этой строке, а при добавлении к ней каких-либо элементов строка не пересоздается заново. В том случае если выделенной памяти не будет хватать для добавления новых элементов, то емкость объекта будет увеличена.

✦ Значимые и ссылочные типы — в чём отличия?
Значимые типы (value type) хранятся в стеке. Стек - это структура данных, которая растет снизу вверх: каждый новый элемент помещаются поверх предыдущего. Время жизни переменных таких типов ограничено их контекстом. Физически стек — это некоторая область памяти в адресном пространстве.

А ссылочные типы (reference type) хранятся в куче (изображение ниже), это другая область памяти, которую можно представить как неупорядоченный набор различных объектов. Когда создаётся объект ссылочного типа в стеке помещается ссылка на адрес в куче. Когда этот объект перестает использоваться, то ссылка уничтожается. После этого в дело вступает автоматический сборщик мусора: он видит, что на объект в куче нету больше ссылок, и удаляет этот объект и очищает память.


✦ Как и для чего нужна конструкция using?
Ключевое слово using упрощает работу с объектами которые реализуют интерфейс IDisposable.
Интерфейс IDisposable содержит один метод Dispose(), который используется для освобождения ресурсов, которые захватил объект. При использовании using не обязательно явно вызывать Dispose() для объекта.
Пример использования using:
Test();
void Test()
{
using (Person tom = new Person("Tom"))
{
// переменная tom доступна только в блоке using
// некоторые действия с объектом Person
Console.WriteLine($"Name: {tom.Name}");
}
Console.WriteLine("Конец метода Test");
}
public class Person : IDisposable
{
public string Name { get;}
public Person(string name) => Name = name;
public void Dispose() => Console.WriteLine($"{Name} has been disposed");
}
// Name: Tom
// Tom has been disposed
// Конец метода Test

Отличная статья в тему — «Конструкция using»

✦ В чем отличие Finalize и Dispose?
Метод Finalize уже определен в базовом для всех типов классе Object, однако данный метод нельзя так просто переопределить. И фактическая его реализация происходит через создание деструктора. Вызывается сборщиком мусора, а точный момент вызова не определен.
Метод Dispose нужен для ручного освобождения ресурсов, через его явный вызов или с помощью using.

Рекомендуется реализовывать интерфейс IDisposable, вместо того, что б создавать пользовательские финализаторы. То есть, если нужно освободить ресурсы памяти в определённом месте — вызовите метод Dispose в указанном месте и таким образом дадите компилятору знать, что в данном месте нужно освободить неуправляемые ресурсы памяти.
Что бы не реализовывать интерфейс явно, можно просто использовать конструкцию using (по закрытию блока using автоматически вызовется метод Dispose).

Хардкорное объяснение на листочке — https://www.youtube.com/watch?v=ZSVXmb_K4F0

✦ В чем основные отличия класса от структуры в языке C#?
Структуры синтаксически очень похожи на классы, но существует принципиальное отличие, которое заключается в том, что класс – является ссылочным типом (reference type), а структуры – значимым типом (value type). Следовательно, классы всегда создаются в “куче” (heap), а структуры создаются в стеке (stack).
И вот ещё отличия класса от структуры:
Все структурные типы неявно наследуются от
System.ValueType, они не бывают абстрактными и всегда неявно запечатаныПри присваивании переменных структурного типа, создается копия данных
Объявления полей структуры не могут иметь инициализаторов
Различная интерпретация
thisдля структуры и классаСтруктура не может содержать конструктор без параметров
Структура не может содержать деструктор
Для ссылочных типов значение по умолчанию –
nullПри конвертировании между ссылочным и размерным типами происходит упаковка и распаковка.

✦ Как можно сравнить строки в C#?
Блок кода лучше тысячи слов, думаю из этого всё понятно:
string s1 = "123";
string s2 = s1.Substring(0, 2) + "3";
//по значению, все варианты сработают
if (s1 == s2) { }
if (s1.CompareTo(s2) == 0) { }
if (s1.Equals(s2)) { }
if (string.Equals(s1, s2)) { }
//по ссылке, не сработают, так сравнивать не надо
if ((object)s1 == (object)s2) { }
if (object.ReferenceEquals(s1, s2)) { }

Хабростатья в тему — «Сравнение строк в C# (по умолчанию)»

✦ Что такое управляемый код и CLR? Основные требования к управляемому коду.
Управляемый код — код программы, исполняемый под управлением CLR.
CLR (общеязыковая исполняющая среда) — исполняющая среда для байт-кода CIL (MSIL), в которой компилируются программы, написанные на .NET-совместимых языках программирования (C#, Managed C++, Visual Basic .NET, F# и прочие). CLR является одним из основных компонентов пакета Microsoft .NET Framework.
CLR поддерживает 3 сценария взаимодействия:
Управляемый код может вызывать неуправляемые функции из DLL
Управляемый код может использовать готовы компоненты COM
Неуправляемый код может использовать управляемый тип

Требование к коду — написанный управляемый код должен быть полностью совместим с CTS (Common Type System), который поддерживают все .Net-совместимые языки.
Вот пожалуй самое основное по этому вопросу.

Интересная хабростатья в тему — «.NET Managed + C unmanaged: какова цена?»

✦ Разница IEnumerable и IQueryable при работе с удаленной БД?
IEnumerable. Объект IEnumerable представляет набор данных в памяти и может перемещаться по этим данным только вперед.
IQueryable. Он располагается в пространстве имен System.Linq. Объект предоставляет удаленный доступ к базе данных и позволяет перемещаться по данным как в прямом порядке от начала до конца, так и в обратном порядке. В процессе же выполнения запроса, происходит оптимизация запроса.
IEnumerable<Phone> phoneIEnum = db.Phones;
var phones1 = phoneIEnum.Where(p => p.Id > id).ToList(); //SELECT * FROM PHONES, фильтрация на стороне клиента
IQueryable<Phone> phoneIQuer = db.Phones;
int id = 3;
var phones2 = phoneIQuer.Where(p => p.Id > id).ToList(); //SELECT * FROM PHONES WHERE ID > 3

Разница между IQueryable и IEnumerable. Основное отличие между этими интерфейсами в том, что IEnumerable работает со всем массивом данных, а IQueryable с отфильтрованным. IEnumerable получает все данные на стороне сервера и загружает их в память а затем позволяет сделать фильтрацию по данным из памяти. Когда делается запрос к базе данных, IQueryable выполняет запрос на серверной стороне и в запросе применяет фильтрацию.
Вот отличные картинки для сравнения этих 2х методов обращения к базе


Когда что использовать?
IEnumerable
IEnumerableможет двигаться только вперед по коллекции, он не может идти назадХорошо подходит для работы с данными в памяти (списки, массивы)
Подходит для LINQ to Object и LINQ to XML
Поддерживает отложенное выполнение (Lazy Evaluation)
Не поддерживает произвольные запросы
Не поддерживает ленивую загрузку (lazy loading)
Методы расширения, работающие с
IEnumerableпринимают функциональные объекты
Пример кода:
MyDataContext dc = new MyDataContext ();
IEnumerable<Employee> list = dc.Employees.Where(p => p.Name.StartsWith("S"));
list = list.Take<Employee>(10);
Сгенерированный SQL
SELECT [t0].[EmpID], [t0].[EmpName], [t0].[Salary] FROM [Employee] AS [t0]
WHERE [t0].[EmpName] LIKE @p0

IQueryable
IQueryableможет двигаться только вперед по коллекции, он не может идти назадIQueryableлучше работает с запросами к базе данных (вне памяти)Подходит для LINQ to SQL
Поддерживает отложенное выполнение (Lazy Evaluation)
Поддерживает произвольные запросы (используя
CreateQueryи методExecute)Поддерживает ленивую загрузку (lazy loading)
Методы расширения, работающие с
IQueryableпринимают объекты выражения
Пример кода:
MyDataContext dc = new MyDataContext ();
IQueryable<Employee> list = dc.Employees.Where(p => p.Name.StartsWith("S"));
list = list.Take<Employee>(10);
Сгенерированный SQL
SELECT TOP 10 [t0].[EmpID], [t0].[EmpName], [t0].[Salary] FROM [Employee] AS [t0]
WHERE [t0].[EmpName] LIKE @p0

Годная статья по теме — «Сравнение коллекций в .NET»

✦ Расскажи про принцип инверсии зависимостей (Dependency Inversion)
Принцип инверсии зависимостей (Dependency Inversion) служит для создания слабосвязанных сущностей, которые легко тестировать, модифицировать и обновлять. Этот принцип можно сформулировать так: модули верхнего уровня не должны зависеть от модулей нижнего уровня. И те и другие должны зависеть от абстракций.
Короче, абстракции не должны зависеть от деталей. Детали должны зависеть от абстракций.
Чтобы понять принцип, поглядим на код:
class Book
{
public string Text { get; set; }
public ConsolePrinter Printer { get; set; }
public void Print()
{
Printer.Print(Text);
}
}
class ConsolePrinter
{
public void Print(string text)
{
Console.WriteLine(text);
}
}
Класс Book, представляющий книгу, использует для печати класс ConsolePrinter. При подобном определении класс Book зависит от класса ConsolePrinter. Более того мы жестко определили, что печать книгу можно только на консоли с помощью класса ConsolePrinter. Другие же варианты, например, вывод на принтер, вывод в файл или с использованием каких-то элементов графического интерфейса - все это в данном случае исключено. Абстракция печати книги не отделена от деталей класса ConsolePrinter. Все это является нарушением принципа инверсии зависимостей.
Теперь попробуем привести наши классы в соответствие с принципом инверсии зависимостей, отделив абстракции от низкоуровневой реализации:
interface IPrinter
{
void Print(string text);
}
class Book
{
public string Text { get; set; }
public IPrinter Printer { get; set; }
public Book(IPrinter printer)
{
this.Printer = printer;
}
public void Print()
{
Printer.Print(Text);
}
}
class ConsolePrinter : IPrinter
{
public void Print(string text)
{
Console.WriteLine("Печать на консоли");
}
}
class HtmlPrinter : IPrinter
{
public void Print(string text)
{
Console.WriteLine("Печать в html");
}
}
Теперь абстракция печати книги отделена от конкретных реализаций. В итоге и класс Book, и класс ConsolePrinter зависят от абстракции IPrinter. Кроме того, теперь мы также можем создать дополнительные низкоуровневые реализации абстракции IPrinter и динамически применять их в программе:
Book book = new Book(new ConsolePrinter());
book.Print();
book.Printer = new HtmlPrinter();
book.Print();

Вот, пожалуй, самая суть Dependency Inversion.

✦ Расскажи про свойства в C#?
В C# существуют специальные методы доступа — свойства. Они обеспечивают простой доступ к полям класса для получения или установки их значения.
Стандартное описание свойства имеет следующий синтаксис:
[модификаторы] тип_свойства название_свойства
{
get { действия, выполняемые при получении значения свойства }
set { действия, выполняемые при установке значения свойства }
}
Вначале определения свойства могут идти различные модификаторы, в частности, модификаторы доступа. Затем указывается тип свойства, после которого идет название свойства. Полное определение свойства содержит два блока: get и set.
В блоке get выполняются действия по получению значения свойства. В этом блоке с помощью оператора return возвращаем некоторое значение.
В блоке set устанавливается значение свойства. В этом блоке с помощью параметра value мы можем получить значение, которое передано свойству.
Блоки get и set еще называются акссесорами или методами доступа (к значению свойства), а также геттером и сеттером.

Давайте поглядим пример:
Person person = new Person();
// Устанавливаем свойство - срабатывает блок Set
// значение "Tom" и есть передаваемое в свойство value
person.Name = "Tom";
// Получаем значение свойства и присваиваем его переменной - срабатывает блок Get
string personName = person.Name;
Console.WriteLine(personName); // Tom
class Person
{
private string name = "Undefined";
public string Name
{
get
{
return name; // возвращаем значение свойства
}
set
{
name = value; // устанавливаем новое значение свойства
}
}
}
Здесь в классе Person определено приватное поле name, которая хранит имя пользователя, и есть общедоступное свойство Name. Хотя они имеют практически одинаковое название за исключением регистра, но это не более чем стиль, названия у них могут быть произвольные и не обязательно должны совпадать.

Годная статья по теме — «Свойства в C#»

✦ Что такое assembly manifest (манифест сборки)?
Манифест — ключевой компонент сборки, который содержит метаданные. Если у сборки отсутствует манифест, то заключенный в ней код MSIL выполняться не будет.
Манифест может храниться в PE-файле (EXE или DLL) с кодом MSIL или же в отдельном PE-файле, содержащем только данные манифеста.
Манифест сборки содержит следующую информацию (первые чертыре составляют удостоверение сборки):
Имя сборки
Номер версии: основной и дополнительный номера. Используется для управления версиями
Язык и региональные параметры: информация о языке и региональных параметрах, которые поддерживает сборка
Информация о строгом имени: открытый ключ издателя
Список всех файлов сборки: хэш и имя каждого из входящих в сборку файлов
Список ссылок на другие сборки, которые использует текущая сборка
Список ссылок на типы, используемые сборкой

Полезная статья — «Сборки .NET»

✦ Что такое GAC? Возможно ли поместить два файла с одинаковым именем в Global Assembly Cache?
GAC (Global Assembly Cache) — глобальный кэш сборок, место где хранятся разделяемые сборки.
В GAC нельзя помещать полностью одинаковые сборки (сборки с полностью совпадающим сложным именем).
Сложное имя сборки состоит из нескольких частей:
Имя сборки без расширения
Номер версии. Благодаря разграничению по версии можно хранить разные версии одной и ой же сборки
Открытый ключ
Необязательное значение для культуры (при локализации сборки)
Цифровая подпись, которая создается с помощью хэш-значения содержимого сборки и значения секретного ключа. Секретный ключ представляет собой файл с расширением *.snk. Если совпадают у двух сборок только имена сборки, а все остальное отличается, то их можно помещать в GAC вместе.

✦ Модификаторы доступа в C# — какие знаешь?
Ну, тут всё просто, в C# имеются такие модификаторы доступа:
public: публичный, общедоступный класс или член класса. Такой член класса доступен из любого места в коде, а также из других программ и сборок.private: закрытый класс или член класса. Представляет полную противоположность модификаторуpublic. Такой закрытый класс или член класса доступен только из кода в том же классе или контексте.protected: такой член класса доступен из любого места в текущем классе или в производных классах. При этом производные классы могут располагаться в других сборках.internal: класс и члены класса с подобным модификатором доступны из любого места кода в той же сборке, однако он недоступен для других программ и сборок (как в случае с модификаторомpublic).protected internal: совмещает функционал двух модификаторов. Классы и члены класса с таким модификатором доступны из текущей сборки и из производных классов.private protected: такой член класса доступен из любого места в текущем классе или в производных классах, которые определены в той же сборке.

✦ Расскажи про Boxing и Unboxing?
Упаковка (boxing) и распаковка (unboxing) — операции преобразования значимых типов данных в ссылочные и обратно. Эти операции могут негативно сказываться на производительности из-за дополнительных вычислений: выделения памяти под новый объект и копирования данных.

Упаковка (boxing). Упаковка происходит при преобразовании значимого типа в тип System.Object, System.Enum, System.ValueType или интерфейса. Эта операция может быть выполнена явно и неявно:
int a = 10;
object b = a; // Неявная упаковка
object c = (object)a; // Явная упаковка
Неявная упаковка происходит, когда переменная значимого типа используется в контексте, где ожидается ссылочный тип. Примеры таких операций:
вызов метода с параметрами ссылочного типа и аргументами значимого;
вызов методов базового ссылочного типа у экземпляров значимых типов;
объявление переменной ссылочного типа с инициализацией экземпляром значимого.
Несколько примеров рассмотрены подробнее ниже.
Пример 1
struct Point : IComparable<Point>
{
....
public int CompareTo(Point point) { .... }
}
static void
ProcessComparableItems<T>(IComparable<T> lhs,
IComparable<T> rhs)
{ .... }
static int Calculate(....)
{
var firstPoint = new Point(....);
var secondPoint = new Point(....);
ProcessComparableItems(firstPoint, secondPoint);
....
}
Метод ProcessComparableItems работает с двумя параметрами типа IComparable<T>. В то же время структура Point реализует этот интерфейс. Несмотря на это, при вызове метода ProcessComparableItems с аргументами типа Point каждый из них будет упакован:
// ProcessComparableItems(firstPoint, secondPoint);
IL_0039: ldloc.0
IL_003a: box BoxingTest.Program/Point // <=
IL_003f: ldloc.1
IL_0040: box BoxingTest.Program/Point // <=
IL_0045: call void
BoxingTest.Program::ProcessComparableItems
<valuetype BoxingTest.Program/Point>(....)
....
Пример 2
var dateTime = new DateTime(....);
Type typeInfo = dateTime.GetType();
dateTime — переменная значимого типа (DateType). У dateTime вызывается метод GetType, определённый в типе System.Object. Чтобы выполнить такой вызов, объект dateTime придётся упаковать:
// Type typeInfo = dateTime.GetType();
IL_0014: ldloc.0
IL_0015: box [System.Runtime]System.DateTime // <=
IL_001a: call instance class
[System.Runtime]System.Type
[System.Runtime]System.Object::GetType()
....

Распаковка (unboxing). Распаковкой называют преобразование упакованного значения обратно в значимый тип. Операция распаковки имеет свои особенности:
распаковка обязана осуществляться в точно такой же тип данных, который был упакован. В случае несоответствия возникнет исключение
InvalidCastException;при попытке распаковать нулевую ссылку возникнет исключение
NullReferenceException.
Пример
double a = 1;
object b = a;
int c = (int)b;
Из-за несоответствия типов при попытке распаковки переменной возникнет исключение InvalidCastException. Исправленный вариант:
int c = (int)(double)b;

Годная статья в тему — «Упаковка и распаковка в C#»

✦ В чем суть полиморфизма?
Слово полиморфизм дословно — наличие многих форм. В парадигме ООП полиморфизм часто выражается как «один интерфейс, несколько функций».
Полиморфизм может быть статическим или динамическим. В статическом полиморфизме ответ на функцию определяется во время компиляции. В динамическом полиморфизме он решается во время выполнения.

Статический полиморфизм. Механизм связывания функции с объектом во время компиляции называется ранним связыванием. Он также называется статической привязкой. C# предоставляет два метода для реализации статического полиморфизма. Они -
Перегрузка функций
Перегрузка оператора
Мы обсудим перегрузку оператора чуть ниже.
Перегрузка функции. Вы можете иметь несколько определений для одного и того же имени функции в той же области. Определение функции должно отличаться друг от друга по типам и / или количеству аргументов в списке аргументов. Вы не можете перегружать объявления функций, которые отличаются только возвращаемым типом.
В следующем примере показано использование функции print() для печати различных типов данных:
using System;
namespace PolymorphismApplication {
class Printdata {
void print(int i) {
Console.WriteLine("Printing int: {0}", i );
}
void print(double f) {
Console.WriteLine("Printing float: {0}" , f);
}
void print(string s) {
Console.WriteLine("Printing string: {0}", s);
}
static void Main(string[] args) {
Printdata p = new Printdata();
// Call print to print integer
p.print(5);
// Call print to print float
p.print(500.263);
// Call print to print string
p.print("Hello C++");
Console.ReadKey();
}
}
}
Когда приведенный выше код компилируется и выполняется, он производит следующий результат:
Printing int: 5
Printing float: 500.263
Printing string: Hello C++

Динамический полиморфизм. C# позволяет создавать абстрактные классы, которые используются для обеспечения частичной реализации класса интерфейса. Реализация завершается, когда производный класс наследуется от него. Абстрактные классы содержат абстрактные методы, которые реализуются производным классом. Производные классы имеют более специализированную функциональность.
Вот правила об абстрактных классах:
Вы не можете создать экземпляр абстрактного класса
Вы не можете объявить абстрактный метод вне абстрактного класса
Когда класс объявляется запечатанным , его нельзя унаследовать, абстрактные классы не могут быть объявлены герметичными.
Пример абстрактного класса:
using System;
namespace PolymorphismApplication {
abstract class Shape {
public abstract int area();
}
class Rectangle: Shape {
private int length;
private int width;
public Rectangle( int a = 0, int b = 0) {
length = a;
width = b;
}
public override int area () {
Console.WriteLine("Rectangle class area :");
return (width * length);
}
}
class RectangleTester {
static void Main(string[] args) {
Rectangle r = new Rectangle(10, 7);
double a = r.area();
Console.WriteLine("Area: {0}",a);
Console.ReadKey();
}
}
}
Когда приведенный выше код компилируется и выполняется, он производит следующий результат:
Rectangle class area :
Area: 70
Когда у вас есть функция, определенная в классе, который вы хотите реализовать в унаследованном классе, вы используете виртуальные функции. Виртуальные функции могут быть реализованы по-разному в разных унаследованных классах, и вызов этих функций будет решаться во время выполнения. Динамический полиморфизм реализуется абстрактными классами и виртуальными функциями.
Вот, поглядим на примере:
using System;
namespace PolymorphismApplication {
class Shape {
protected int width, height;
public Shape( int a = 0, int b = 0) {
width = a;
height = b;
}
public virtual int area() {
Console.WriteLine("Parent class area :");
return 0;
}
}
class Rectangle: Shape {
public Rectangle( int a = 0, int b = 0): base(a, b) {
}
public override int area () {
Console.WriteLine("Rectangle class area :");
return (width * height);
}
}
class Triangle: Shape {
public Triangle(int a = 0, int b = 0): base(a, b) {
}
public override int area() {
Console.WriteLine("Triangle class area :");
return (width * height / 2);
}
}
class Caller {
public void CallArea(Shape sh) {
int a;
a = sh.area();
Console.WriteLine("Area: {0}", a);
}
}
class Tester {
static void Main(string[] args) {
Caller c = new Caller();
Rectangle r = new Rectangle(10, 7);
Triangle t = new Triangle(10, 5);
c.CallArea(r);
c.CallArea(t);
Console.ReadKey();
}
}
}
Когда приведенный выше код компилируется и выполняется, он производит следующий результат:
Rectangle class area:
Area: 70
Triangle class area:
Area: 25

Вот пожалуй самое основное по полиморфизму.

Полезная хабростатья — «Ad-hoc-полиморфизм и паттерн type class в C#»
И вот ещё годная статья с примерами

✦ Какие типы можно использовать в предложении foreach?
Сразу к сути — можно использовать типы, которые реализуют интерфейс IEnumerable или IEnumerable<T>. Либо же любые типы, которые удовлетворяют следующим условиям:
Включают открытый метод
GetEnumeratorбез параметров с классом, структурой или тип интерфейсом в качестве возвращаемого значения;Тип возвращаемого значения метода
GetEnumeratorдолжен содержать открытое свойствоCurrentи открытый методMoveNextбез параметров с типом возвращаемого значенияBoolean.

✦ Чем отличается event от delegate?
Отличаются так же, как отличаются свойства от полей.
Главное отличие в том, что event может быть только членом класса и может быть запущен только в классе, в котором объявлен. Помимо этого, при наличии event компилятор создает не только соответствующее приватное поле-делегат, но еще и два открытых метода для подписки и ее отмены на события.
Из меньших отличий стоит вспомнить о том, что событие, в отличие от делегата, может быть членом интерфейса. Это потому, что делегаты всегда являются полями, тогда как интерфейсы содержать поля не могут. Кроме того, событие, в отличие от делегата, не может быть локальной переменной в методе.

Хабростатья в тему — «Коварный вопрос по Event/Delegate»

✦ Может ли класс реализовать два интерфейса, у которых объявлены одинаковые методы? Если да, то как?
Если коротко, может. Общие методы при этом надо реализовывать один раз неявно или два раза явно (с указанием имени интерфейса). При явной реализации метод нельзя будет вызывать без приведения экземпляра класса к интерфейсу (если только не будет третьей реализации метода в классе).
Если два метода интерфейса выполняют разные действия, то неявная реализация интерфейсов может быть некорректной.
Если класс реализует 2 интерфейса, содержащих член с одинаковой сигнатурой, при реализации такого члена в классе оба интерфейса будут использовать этот член в качестве собственной реализации.

✦ В чём разница между System.Array.CopyTo() и System.Array.Clone()?
Метод System.Array.CopyTo() копирует не только сами элемента класса Array, но и всякие объекты, которые связаны ссылками с этими элементами Array. Это называется "глубоким копированием".
Метод System.Array.Clone() осуществляет так называемое "поверхностное копирование". При поверхностном копировании метод копирует только элементы объекта класса Array, и методу не важно, являются ли эти элементы value или reference типами. Копирование объектов которые связаны какими-то ссылками не происходит, а сами ссылки копируются так же, как и в оригинальном Array.
Ещё пару отличий между методами:
System.Array.CopyTo()требует наличия выходного массива, тогда какSystem.Array.Clone()создает новый массив.System.Array.CopyTo()позволяет указывать индекс элемента, начиная с которого производить копирование.

✦ Что такое абстрактный класс? В каком случае вы обязаны объявить класс абстрактным?
Сразу перейдём к сути.
Абстрактный класс — это класс, имеющий неполную реализацию, которую реализует его неабстрактный наследник. К примеру, интерфейс — это абстрактный класс, у которого ни один метод не реализован, все они публичные и нет переменных класса.
Нельзя создать экземпляр абстрактного класса.
Абстрактные классы нужны для того, чтобы выделять общий функционал от нескольких классов в обособленный класс. От этого отдельного класса потом можно унаследовать либо просто сигнатуру функционала, либо вместе с реализацией.
Класс обязательно нужно объявлять как абстрактный, когда он содержит абстрактные члены.

✦ Что общего между интерфейсами и абстрактными классами? В чём отличия? Когда что использовать?
Один из принципов проектирования гласит, что при создании системы классов надо программировать на уровне интерфейсов, а не их конкретных реализаций. Под интерфейсами в данном случае понимаются не только типы C#, определенные с помощью ключевого слова interface, а определение функционала без его конкретной реализации. То есть под данное определение попадают как собственно интерфейсы, так и абстрактные классы, которые могут иметь абстрактные методы без конкретной реализации.
В этом плане у абстрактных классов и интерфейсов много общего. Нередко при проектировании программ в паттернах мы можем заменять абстрактные классы на интерфейсы и наоборот. Однако все же они имеют некоторые отличия.
Когда следует использовать абстрактные классы:
Если надо определить общий функционал для родственных объектов
Если мы проектируем довольно большую функциональную единицу, которая содержит много базового функционала
-
Если нужно, чтобы все производные классы на всех уровнях наследования имели некоторую общую реализацию. При использовании абстрактных классов, если мы захотим изменить базовый функционал во всех наследниках, то достаточно поменять его в абстрактном базовом классе.
Если же нам вдруг надо будет поменять название или параметры метода интерфейса, то придется вносить изменения и также во всех классы, которые данный интерфейс реализуют.
Когда следует использовать интерфейсы:
Если нам надо определить функционал для группы разрозненных объектов, которые могут быть никак не связаны между собой.
Если мы проектируем небольшой функциональный тип
Ключевыми здесь являются первые пункты, которые можно свести к следующему принципу: если классы относятся к единой системе классификации, то выбирается абстрактный класс. Иначе выбирается интерфейс. Посмотрим на примере.
Допустим, у нас есть система транспортных средств: легковой автомобиль, автобус, трамвай, поезд и т.д. Поскольку данные объекты являются родственными, мы можем выделить у них общие признаки, то в данном случае можно использовать абстрактные классы:
public abstract class Vehicle
{
public abstract void Move();
}
public class Car : Vehicle
{
public override void Move()
{
Console.WriteLine("Машина едет");
}
}
public class Bus : Vehicle
{
public override void Move()
{
Console.WriteLine("Автобус едет");
}
}
public class Tram : Vehicle
{
public override void Move()
{
Console.WriteLine("Трамвай едет");
}
}
Абстрактный класс Vehicle определяет абстрактный метод перемещения Move(), а классы-наследники его реализуют.
Но, предположим, что наша система транспорта не ограничивается вышеперечисленными транспортными средствами. Например, мы можем добавить самолеты, лодки. Возможно, также мы добавим лошадь — животное, которое может также выполнять роль транспортного средства. Также можно добавить дирижабль. Вобщем получается довольно широкий круг объектов, которые связаны только тем, что являются транспортным средством и должны реализовать некоторый метод Move(), выполняющий перемещение.
Так как объекты мало связаны между собой, то для определения общего для всех них функционала лучше определить интерфейс. Тем более некоторые из этих объектов могут существовать в рамках параллельных систем классификаций. Например, лошадь может быть классом в структуре системы классов животного мира.
Возможная реализация интерфейса могла бы выглядеть следующим образом:
public interface IMovable
{
void Move();
}
public abstract class Vehicle : IMovable
{
public abstract void Move();
}
public class Car : Vehicle
{
public override void Move() => Console.WriteLine("Машина едет");
}
public class Bus : Vehicle
{
public override void Move() => Console.WriteLine("Автобус едет");
}
public class Hourse : IMovable
{
public void Move() => Console.WriteLine("Лошадь скачет");
}
public class Aircraft : IMovable
{
public void Move() => Console.WriteLine("Самолет летит");
}
Теперь метод Move() определяется в интерфейсе IMovable, а конкретные классы его реализуют.
Говоря об использовании абстрактных классов и интерфейсов можно привести еще такую аналогию, как состояние и действие. Как правило, абстрактные классы фокусируются на общем состоянии классов-наследников. В то время как интерфейсы строятся вокруг какого-либо общего действия.
Например, солнце, костер, батарея отопления и электрический нагреватель выполняют функцию нагревания или излучения тепла. По большому счету выделение тепла - это единственный общий между ними признак. Можно ли для них создать общий абстрактный класс? Можно, но это не будет оптимальным решением, тем более у нас могут быть какие-то родственные сущности, которые мы, возможно, тоже захотим использовать. Поэтому для каждой вышеперечисленной сущности мы можем определить свою систему классификации. Например, в одной системе классов, которые наследуются от общего астрактного класса, были бы звезды, в том числе и солнце, планеты, астероиды и так далее — то есть все те объекты, которые могут иметь какое-то общее с солнцем состояние. В рамках другой системы классов мы могли бы определить электрические приборы, в том числе электронагреатель. И так, для каждой разноплановой сущности можно было бы составить свою систему классов, исходяющую от определенного абстрактного класса. А для общего действия определить интерфейс, например, IHeatable, в котором бы был метод Heat, и этот интерфейс реализовать во всех необходимых классах.
Таким образом, если разноплановые классы обладают каким-то общим действием, то это действие лучше выносить в интерфейс. А для одноплановых классов, которые имеют общее состояние, лучше определять абстрактный класс.

✦ В чем разница между абстрактными и виртуальными классами?
Абстрактные классы — это те, которые помечены ключевым словом abstract. В абстрактном классе содержатся абстрактные члены (методы, свойства, индексаторы, события); они не имеют внутренней реализации и выступают в роли интерфейса. Они так же должны быть помечены ключевым словом abstract. При наследовании от абстрактного класса, класс-наследник получает все свойства своего класса родителя, а если в родительском классе есть еще и абстрактные члены, то в классе наследнике обязательно их нужно переопределять.
Виртуальный класс — это просто класс, в котором есть виртуальные члены (методы, свойства...). Виртуальные члены помечаются модификатором virtual и имеют внутреннюю реализацию, которая может быть переопределена в классе-наследнике.

✦ Что означает модификатор virtual?
Модификатор virtual служит для того, чтобы помечать виртуальные методы или свойства в классе родителя.
Виртуальные методы (свойства) — это такие, которые мы хотим переопределить в классах наследниках. А чтобы переопределить метод в классе-наследнике, этот метод определяется с модификатором override. Переопределенный метод в классе-наследнике должен иметь тот же набор параметров, что и виртуальный метод в базовом классе.
Переопределять можно и невиртуальные методы, но тогда выбор метода (родителя или наследника) будет осуществляться статически во время компиляции на основании типа переменной, а не типа объекта, хранящейся в ней.

А вот так может выглядеть использование virtual:
// Пример базового класса с виртуальным методом
public class Animal
{
// Виртуальный метод, который может быть переопределен в производных классах
public virtual void MakeSound()
{
Console.WriteLine("Animal makes a sound");
}
}
// Пример производного класса, переопределяющего виртуальный метод
public class Dog : Animal
{
// Переопределение виртуального метода
public override void MakeSound()
{
Console.WriteLine("Dog barks");
}
}

✦ В чем разница инкапсуляции и сокрытия?
Инкапсуляция — одна из парадигм ООП. Она представляет собой способность языка "изолировать" определённые участки кода, исключая возможность нарушения целостности. Основной единицей инкапсуляции в C# является класс. Инкапсуляция позволяет качественно структурировать код и помогает обезопасить его от многих возможных проблем и вопросов, касательно защиты данных и информации.
Сокрытие же скрывает детали о процессе (в то время как инкапсуляция обеспечивает своего рода целостность). Для определения прав доступа к данным в классе и к классу непосредственно используются модификаторы доступа. Получается, что использование этих модификаторов и есть то самое сокрытие. Термин "сокрытие" лучше употреблять в контексте методов. Сокрытие метода представляет собой реализация тела метода в дочернем классе, сигнатура которого соответствует сигнатуре метода в родительском классе. Для сокрытия применяется ключевое слово new.
Вот так может выглядеть сокрытие:
class Animal
{
public void Say()
{
Console.WriteLine("*Some sounds*");
}
}
class Cat:Animal
{
public new void Say() // сокрытие
{
Console.WriteLine("Miew!");
}
}

Интересная статья — «Инкапсуляция – это сокрытие или нет?»

✦ Что такое частные и общие сборки?
Частные сборки:
Видны только самому приложению
Нет необходимости заботиться об уникальном имени во всем глобальном пространстве имен
Не нужно делать записей в реестре при развертывании приложения
Сборки просто копируются в директорию приложения или в подчинённую директорию
Общая среда выполнения (CLR) при запуске приложения прочитает его манифест и определит какие сборки необходимы. Затем будет произведен поиск нужной сборки по директории приложения (процесс зондирования)
Общие сборки:
Общие сборки могут быть использованы сразу несколькими приложениями
Сборка должна иметь строгое имя (strong name)
Сборка должна быть помещена в общедоступное место – Global Assembly Cache (GAC, глобальный кэш сборок)

✦ Разница между LINQ lazy loading и eager loading
Если сразу к сути, то в случае lazy loading, зависимые таблицы (дочерние объекты) не загружаются автоматически с родительскими, а загрузятся в тот момент, когда они понадобятся. В LINQ по умолчанию используется lazy loading.
В случае eager loading, зависимые объекты загружаются автоматически с родительской таблицей. Для того, чтобы использовать eager loading нужно применить метод Include().

Теперь можно чуть подробнее
Отложенная загрузка (lazy loading) заключается в том, что Entity Framework автоматически загружает данные, при этом не загружая связанные данные. Когда потребуются связанные данные Entity Framework создаст еще один запрос к базе данных. Например, загрузить первого заказчика из гипотетической таблицы Customers и сохранить его в переменной customer. Затем вам может понадобиться узнать, какие заказы связаны с этим покупателем. Допустим, в классе модели Customer у нас определено навигационное свойство Orders. Если вы обратитесь к этому свойству (customer.Orders), то Entity Framework отправит запрос в базу данных на извлечение всех связанных с этим покупателем заказов.
Entity Framework применяет отложенную загрузку, используя динамические прокси-объекты. Вот как это работает. Когда Entity Framework возвращает результаты запроса, он создает экземпляры ваших классов и заполняет их данными, которые были возвращены из базы данных. Entity Framework имеет возможность динамически создавать новый тип во время выполнения, производный от вашего класса модели POCO. Этот новый класс выступает в качестве прокси-объекта для вашего класса POCO и называется динамическим прокси-объектом. Он будет переопределять навигационные свойства вашего класса POCO и включать в себя некоторую дополнительную логику для извлечения данных из базы данных, когда вызывается навигационное свойство. Т.к. динамический прокси-класс является производным от вашего класса POCO, ваше приложение работает непосредственно с классом POCO и не должно знать, что за кулисами создается динамический прокси-объект во время выполнения.
DbContext имеет настройку конфигурации для отложенной загрузки с помощью свойства DbContext.Configuration.LazyLoadingEnabled. Этот параметр включен по умолчанию, поэтому если вы не изменяли значение по умолчанию для него, динамический прокси-объект будет выполнять отложенную загрузку.
Для того, чтобы использовать динамические прокси-объекты, и, следовательно, отложенную загрузку, есть пара условий, которым должен соответствовать ваш класс модели. Если эти условия не выполняются, Entity Framework, не будет создавать динамические прокси-объекты для класса и будет просто возвращать экземпляры вашего класса POCO, которые не могут выполнять отложенную загрузку, а следовательно, взаимодействовать с базой данных:
Ваш класс модели должен иметь модификатор доступа
publicи не должен запрещать наследование (ключевое словоsealed).Навигационные свойства, которые должны обеспечивать отложенную загрузку, должны быть виртуальными (модификатор
virtual).
Прежде чем изменять класс модели, давайте посмотрим на поведение приложения без отложенной загрузки. Добавим новый метод LazyLoading() в наш класс программы, который имеет следующий код:
public static void LazyLoading()
{
SampleContext context = new SampleContext();
// Загрузить одного покупателя
Customer customer = context.Customers
.Where(c => c.CustomerId == 2)
.FirstOrDefault();
// Попытаться загрузить связанные с ним заказы
if (customer != null && customer.Orders != null)
foreach (Order order in customer.Orders)
Console.WriteLine(order.ProductName);
}
Если мы теперь вызовем этот метод в главном методе Main(), то никакие связанные данные не будут загружаться. В этом примере не происходит отложенная загрузка, т.к. наш класс модели Customer не подходит под второе условие – навигационное свойство Customer.Orders не является виртуальным. Давайте изменим это:
public class Customer
{
// ...
// Ссылка на заказы
public virtual List<Order> Orders { get; set; }
}
Теперь, при запуске приложения Entity Framework создаст динамически прокси-объект для класса Customer и извлечет данные заказов из базы при их запросе. На рисунке ниже наглядно показано какие данные загружает Entity Framework в этом примере:

Отложенная загрузка является очень простой в использовании, потому что используется автоматически. При этом, она является довольно опасной в плане производительности! Что если мы захотим извлечь сначала всех пользователей используя не отложенный запрос, а затем захотим извлечь все заказы, связанные с этими пользователями:
public static void LazyLoading()
{
SampleContext context = new SampleContext();
context.Database.Log = (s => System.Diagnostics.Debug.WriteLine(s));
// Загрузить всех покупателей
List<Customer> customers = context.Customers
.ToList(); // +1 запрос к базе
// ... какой-то код работы с данными покупателей
// Загрузить все их заказы
List<Order> orders = customers.SelectMany(c => c.Orders)
.ToList(); // +3 запроса к базе данных
}
В этом примере создается три запроса, при попытке извлечь все заказы, связанные с заказчиками в коллекции customers. Мы даже включили средство протоколирования в этом запросе, чтобы вы убедились сами. Количество запросов SELECT при извлечении данных из таблицы Orders зависит от количества покупателей в коллекции customers – Entity Framework будет отправлять один запрос на выборку заказов для каждого покупателя. Очевидно, что такой подход является катастрофическим в плане производительности, если в коллекции будет храниться большое число покупателей.

Прямая загрузка данных (eager loading) позволяет указать в запросе какие связанные данные нужно загрузить при выполнении запроса. Благодаря этому, когда в коде вы будете ссылаться на связанную таблицу через навигационное свойство, SQL-запрос не будет направляться в базу данных, т.к. связанные данные уже будут загружены при первом запросе. В Entity Framework для этих целей используется метод Include(), которому передается делегат, в котором можно указать навигационное свойство, по которому данные должны загружаться при первом запросе. Этот метод является расширяющим для IQueryable. В примере ниже мы добавили метод EagerLoading(), в котором исправили предыдущий пример, используя прямую загрузку:
public static void EagerLoading()
{
SampleContext context = new SampleContext();
context.Database.Log = (s => System.Diagnostics.Debug.WriteLine(s));
// Загрузить всех покупателей и связанные с ними заказы
List<Customer> customers = context.Customers
.Include(c => c.Orders)
.ToList(); // +1 запрос к базе
// ... какой-то код работы с данными покупателей
// Получить все их заказы
List<Order> orders = customers.SelectMany(c => c.Orders)
// Запрос к базе данных не выполняется,
// т.к. данные уже были извлечены
// ранее с помощью прямой загрузки
.ToList();
}
В этом примере базе данных будет отправляться всего один запрос при инициализации коллекции customers.
Метод Include() можно использовать для загрузки нескольких связанных таблиц. Этот метод возвращает тип IQueryable<TEntity>, где TEntity это базовый тип, на коллекции которого он был вызван, поэтому можно использовать цепочку вызовов Include. Давайте изменим модель, добавив два новых сущностных класса:
public class Customer
{
// ...
public Profile Profile { get; set; }
}
public class Order
{
// ...
public List<OrderLines> Lines { get; set; }
}
public class Profile
{
[Key]
[ForeignKey("CustomerOf")]
public int CustomerId { get; set; }
public DateTime RegistrationDate { get; set; }
public DateTime LastLoginDate { get; set; }
public Customer CustomerOf { get; set; }
}
public class OrderLines
{
public int OrderLinesId { get; set; }
public string Address { get; set; }
}
Класс Profile связан с классом Customer связью один-к-одному, а класс OrderLine связан с классом Order связью один-ко-многим. Обратите внимание, что мы не использовали виртуальные навигационные свойства, т.к. при прямой загрузке делать это необязательно. Для загрузки связанных данных из таблицы Profiles нужно будет использовать отдельный вызов метода Include(), а для загрузки связанных данных из OrderLines нужно указать метод Select() со ссылкой на этот класс, при вызове метод Include() для Orders (т.к. OrderLines напрямую не связан с Customer):
context.Customers
.Include(c => c.Profile)
.Include(c => c.Orders.Select(o => o.Lines))
.ToList();
В этом примере будут загружены все связанные данные для всех пользователей. Стоит напомнить, когда мы изменяем модель и используем подход Code-First базу данных нужно будет воссоздать с использованием инициализатора модели или удалив ее вручную.
Т.к. метод Include() возвращает тип IQueryable<TEntity>, мы можем использовать цепочку вызовов методов LINQ как обычно. Например, следующий запрос извлекает все связанные данные для покупателя с идентификатором равным 2:
Customer customer = context.Customers
.Include(c => c.Profile)
.Include(c => c.Orders.Select(o => o.Lines))
.Where(c => c.CustomerId == 2)
.FirstOrDefault();
if (customer.Orders != null)
foreach (Order order in customer.Orders)
Console.WriteLine(order.ProductName);
Стоит заметить, что при таком подходе к созданию запроса, обязательно возникнет проблема с производительностью приложения.
Ранее мы рассмотрели, как можно ограничить выбор столбцов в запросе. Естественно такой вопрос обязательно возникнет при выборке связанных данных, т.к. зачастую большинство данных из связанных таблиц не требуется. Для такой сложной загрузки можно не использовать методы Include(), а явно указать загрузку нужных связанных данных через вложенные анонимные объекты в запросе Select(). Допустим, нам нужно выбрать имена и фамилии всех покупателей, названия товаров, которые они заказали, а также их количество. Это можно сделать с помощью следующего запроса:
public static void EagerLoading()
{
SampleContext context = new SampleContext();
List<Customer> customers = context.Customers
.Select(c => new
{
fname = c.FirstName,
lname = c.LastName,
orders = c.Orders.Select(o => new // вложенный анонимный объект
{
pname = o.ProductName,
quantity = o.Quantity
})
})
.AsEnumerable()
.Select(an => new Customer
{
// Инициализируем экземпляр Customer из анонимного объекта
FirstName = an.fname,
LastName = an.lname,
Orders = an.orders.Select(o => new Order
{
ProductName = o.pname,
Quantity = o.quantity
}).ToList()
})
.ToList();
// Отобразить извлеченные данные
foreach (Customer customer in customers)
{
Console.WriteLine("\nЗаказы покупателя {0} {1}: \n",
customer.FirstName, customer.LastName);
foreach (Order order in customer.Orders)
Console.WriteLine("\t\t{0} - {1} шт.",
order.ProductName, order.Quantity);
}
}
Несмотря на свою сложность, этот запрос намного производительнее, нежели если бы мы извлекали все данные из таблиц Customers и Orders. На рисунке ниже наглядно показано, какие данные извлекаются из этих таблиц с помощью этого запроса:


Полезная статья — «Lazy loading»
И вот ещё — «Загрузка связанных данных»

✦ Можно ли запретить наследование от какого-то класса?
Да, можно. Для того, чтобы запретить наследоваться от класса необходимо объявить его с модификатором sealed.
Например, если мы не хотим чтобы от класса SomeClass можно было наследоваться, то объявляем его так:
sealed class SomeClass
{
// Объявление класса
}

В качестве альтернативы, можно запретить и создание экземпляров этого класса с помощью ключевого слова static (под капотом, будет использована пара модификаторов: abstract sealed).
static class Helper
{
// допустимы лишь статические методы
}

✦ Можно запретить переопределение метода, но разрешить наследование класса?
Ответ в одно предложение.
Да, можно; для этого нужно определить родительский класс с модификатором public, а метод в нем пометить как sealed.

✦ Расскажи про Thread, Task
Класс Thread создает и контролирует поток. На входе указывается метод, который будет выполняться в потоке.
Класс Task позволяет запускать отдельную продолжительную задачу. Она запускается асинхронно в одном из потоков из пула потоков, но ее можно запускать и синхронно.
var t = new Thread(() => Thread.Sleep(1000));
t.IsBackground = false; //основной поток, система сама ожидает его завершение
t.Start();
Task.Run(() => Task.Delay(1000)).Wait(); //с использованием TPL

Отличия Thread и Task.
Это совсем разные вещи. Thread представляет собой физический, системный поток выполнения (за исключением SQL Server под .NET 2.0, да). А Task — это штука, которая по сути перепрыгивает из потока в поток, а зачастую и вовсе не находится ни в каком потоке. В результате у вас может быть всего 10 активных потоков, но тысячи Task'ов.
Например, если вы делаете await на операцию чтения из сети, то он время ожидания прихода ответа от сервера ваша асинхронная функция вовсе не занимает никакого потока, а существует в спящем виде как обыкновенный объект где-то в памяти. Когда ответ реально приходит, функция находит какой-то поток (при обычных условиях это главный поток, но может быть и какой-то посторонний, если вы попросите), и продолжает выполнение на нём дальше.

Пара полезных статей:

✦ Что такое интеграционные тесты и unit-тесты?
Модульное тестирование (unit-тесты): проверка отдельного модуля (класса, библиотеки) приложения независимо от другого модуля. Позволяет провести регресионное тестирование (при внесении изменений в модуль, убедиться, что он по прежнему работает).
Интеграционное тестирование: программные модули объединяются и тестируются в группе. Эти тесты проверяют правильность взаимодействия нескольких подсистем (например, двух классов). Проводится после модульного тестирования.
Тут ещё можно упомянуть следующий этап — системное тестирование: проверяется все приложение в целом по принципу черного ящика.

Статья в тему — «Тестирование веб-приложений»

✦ Что такое MVVM?
Шаблон MVVM (Model—View—ViewModel) позволяет отделить логику приложения от визуальной части, используется в WPF. Этот паттерн задает общую архитектуру приложения. Основные компоненты:
Модель (Model) описывает используемые в приложении данные. Модели могут содержать логику, непосредственно связанную этими данными, например, логику валидации свойств модели.
Представление (View) — определяет визуальный интерфейс (кнопки, текстовые поля и прочие визуальные элементы), через который пользователь взаимодействует с приложением.
Модель представления (ViewModel) — связывает модель и представление через механизм привязки данных. Если в модели изменяются значения свойств, автоматически идет изменение отображаемых данных в представлении, хотя напрямую модель и представление не связаны. ViewModel также содержит логику по получению данных из модели, которые потом передаются в представление. И также VewModel определяет логику по обновлению данных в модели.

Годная статья в тему — «Паттерн MVVM»

✦ Где использовать StringBuilder вместо String?
Если ответить коротко, то StringBuilder даёт преимущество только при множестве операций на изменение строки. Например при наращивании строки в цикле. Во всех остальных случаях StringBuilder медленнее и требует больше памяти. Кроме того, он не является потокобезопасным, в отличии от String.

✦ Какой уровень доступа имеют поля класса, если модификатор доступа не указан?
Если не указывать модификатор доступа для поля класса, то по умолчанию они объявляются с модификатором private.
Для всех модификаторов доступа действует правило: если не указан модификатор, то устанавливается максимально строгий, при котором код будет компилироваться.

✦ Как можно присвоить значения полям, которые помечены readonly?
Если сразу к сути, то можно присвоить значение полю readonly только в следующих контекстах:
Когда переменная инициализируется в объявлении, например:
public readonly int y = 5;В конструкторе экземпляра класса, содержащего объявление поля экземпляра.
В статическом конструкторе класса, содержащего объявление статического поля.
Как-то так, с этим вопросом всё, пожалуй.

✦ Как блокируется одновременное выполнение одних участков кода несколькими потоками?
Для осуществления блокировки одновременного выполнения определенных участков кода несколькими потоками используется ключевое слово lock.
lock определяет блок, внутри которого весь код становится недоступным для других потоков до завершения работы текущего потока.

Поглядим на примере.
int x = 0;
// запускаем пять потоков
for (int i = 1; i < 6; i++)
{
Thread myThread = new(Print);
myThread.Name = $"Поток {i}"; // устанавливаем имя для каждого потока
myThread.Start();
}
void Print()
{
x = 1;
for (int i = 1; i < 4; i++)
{
Console.WriteLine($"{Thread.CurrentThread.Name}: {x}");
x++;
Thread.Sleep(100);
}
}
Здесь у нас запускаются 5 потоков, которые вызывают метод Print и которые работают с общей переменной x. И мы предполагаем, что метод выведет все значения x от 1 до 3. И так для каждого потока. Однако в реальности в процессе работы будет происходить переключение между потоками, и значение переменной x становится непредсказуемым. Например, вывод может быть таким:
Поток 5: 1
Поток 2: 1
Поток 1: 6
Поток 3: 7
Поток 4: 9
Поток 1: 11
Поток 4: 11
Поток 2: 11
Поток 3: 14
Поток 1: 16
Поток 3: 16
Поток 5: 18
Поток 5: 21
Поток 2: 21
Поток 4: 21
Решение проблемы в том, чтобы синхронизировать потоки и ограничить доступ к разделяемым ресурсам на время их использования каким-нибудь потоком. Для этого используется ключевое слово lock. Оператор lock определяет блок кода, внутри которого весь код блокируется и становится недоступным для других потоков до завершения работы текущего потока. Остальный потоки помещаются в очередь ожидания и ждут, пока текущий поток не освободит данный блок кода. В итоге с помощью lock мы можем переделать предыдущий пример следующим образом:
int x = 0;
object locker = new(); // объект-заглушка
// запускаем пять потоков
for (int i = 1; i < 6; i++)
{
Thread myThread = new(Print);
myThread.Name = $"Поток {i}";
myThread.Start();
}
void Print()
{
lock (locker)
{
x = 1;
for (int i = 1; i < 4; i++)
{
Console.WriteLine($"{Thread.CurrentThread.Name}: {x}");
x++;
Thread.Sleep(100);
}
}
}
Для блокировки с помощью lock используется объект-заглушка, в данном случае это переменная locker. Обычно это переменная типа object. И когда выполнение доходит до оператора lock, объект locker блокируется, и на время его блокировки монопольный доступ к блоку кода имеет только один поток. После окончания работы блока кода, объект locker освобождается и становится доступным для других потоков.
В этом случае консольный вывод будет более упорядоченным:
Поток 1: 1
Поток 1: 2
Поток 1: 3
Поток 5: 1
Поток 5: 2
Поток 5: 3
Поток 3: 1
Поток 3: 2
Поток 3: 3
Поток 2: 1
Поток 2: 2
Поток 2: 3
Поток 4: 1
Поток 4: 2
Поток 4: 3

Годная хабростатья в тему — «Многопоточность на низком уровне»

✦ Какой интерфейс должен реализовать класс, чтобы к переменной данного типа был применим foreach?
Простой вопрос, перейдём сразу к сути.
Оператор foreach может применяться для переменных, которые реализуют интерфейс IEnumerable или IEnumerable<T>, либо к экземпляру любого типа, удовлетворяющим условиям:
должен включать открытый метод
GetEnumeratorбез параметров с классом, структурой или типом интерфейса в качестве возвращаемого значения;тип возвращаемого значения метода
GetEnumeratorдолжен содержать открытое свойствоCurrentи открытый методMoveNextбез параметров с типом возвращаемого значенияBoolean.

✦ Когда вызывается статический конструктор класса?
Статический конструктор вызывается автоматически для инициализации класса перед созданием первого экземпляра типа или при первом обращении к каким-либо статическим членам.
Статический конструктор выполняется раньше, чем конструктор экземпляра.
Вообще, неплохо бы вспомнить основные свойства статических конструкторов:
Статический конструктор не принимает модификаторы доступа и не имеет параметров.
Класс или структура могут иметь только один статический конструктор.
Статические конструкторы не могут быть унаследованы или перегружены.
Статический конструктор нельзя вызывать напрямую. Он предназначен только для вызова из общеязыковой среды выполнения (CLR). Он запускается автоматически.
Пользователь не управляет временем, в течение которого статический конструктор выполняется в программе.
Если вы не предоставили статический конструктор для инициализации статических полей, все статические поля инициализируются значениями по умолчанию, которые указаны в разделе Значения по умолчанию типов C#.
Если статический конструктор создает исключение, среда выполнения не вызывает его во второй раз, и тогда тип остается неинициализированным на все время существования домена приложения. Чаще всего исключение TypeInitializationException вызывается, когда статический конструктор не может создать экземпляр типа или в статическом конструкторе создается необработанное исключение. Для устранения неполадок со статическими конструкторами, которые не определены явным образом в исходном коде, может потребоваться проверка кода на промежуточном языке (IL).
Наличие статического конструктора не позволяет добавлять атрибут типа BeforeFieldInit. Это ограничивает возможности оптимизации во время выполнения.
Поле, объявленное как
static readonly, может быть присвоено только при его объявлении или в статическом конструкторе. Если явный статический конструктор не требуется, инициализируйте статические поля в объявлении, а не через статический конструктор, чтобы оптимизировать среду выполнения.Среда выполнения вызывает статический конструктор не более одного раза для каждого домена приложения. Этот вызов выполняется в заблокированном регионе на основе определенного типа класса. В тексте статического конструктора не нужны дополнительные механизмы блокировки. Чтобы избежать риска взаимоблокировки, не блокируйте текущий поток в статических конструкторах и инициализаторах. Например, не следует ожидать выполнения задач, потоков, обработчиков ожидания или событий, а также создавать блокировки или выполнять блокирующие параллельные операции, как, например, параллельные циклы,
Parallel.Invokeи запросы Parallel LINQ.

✦ Чем отличаются константы и поля, доступные только для чтения?
Итак, сразу перейдём к отличиям.
Константы должны быть определены во время компиляции, а поля для чтения могут быть определены во время выполнения программы.
Соответственно значение константы можно установить только при ее определении. Поле для чтения можно инициализировать либо при его определении, либо в конструкторе класса.
Константы не могут использовать модификатор static, так как уже неявно являются статическими. Поля для чтения могут быть как статическими, так и не статическими.

Годная статья по теме — «Константы, поля и структуры для чтения»

The end
Вот мы и прошлись по одним из самых частотных вопросов на позицию младшего C#-разраба.
Уверен, было полезно. Успехов с собесами и всех благ)
Вообще, было бы интересно услышать от тех, кто давно в отрасли о перспективах и тенденциях, что вы думаете ждёт C# в ближайшие 5 лет?
Пишите)
Комментарии (17)

Fitbie
19.03.2024 13:21+3Асинхронные методы выполняются в отдельных потоках
Не буду говорить за все остальное, но async/await блок провальный. Буквально с первой же фразы - асинхронность, это чуть ли не противоположность многопоточности, кроме пары исключений.
Пока я писал ответ на этот пост, решил сделать свой с ссылками на материалы для изучения.
И я даже знаю корень проблемы - Metanit. Сайт прекрасный, Евгений молодец, но без связки с MSDN это тикающая бомба. И в теме асинхронности она взорвалась, отсюда и вышеприведенная цитата, и Thread.Sleep() в примерах кода. Без негатива, но лучше незнание, чем лжеучение.
rukhi7
19.03.2024 13:21но async/await блок провальный
но очень интересный, очень хорошо оформлено-изложено, я теперь хорошо понимаю что мне хотели внушить в коментариях к моей недавней статье
и с этим можно работать и разобрать каждое противоречие в изложенном материале по полочкам. Я скопировал себе для работы.
Fitbie
19.03.2024 13:21+1Окинув взглядом этот пост еще раз я понял - бездушная копипаста. Это даже не GPT, сурс.
rukhi7
19.03.2024 13:21но мне под моей статьей писали явно не копипастом, писали с эмоциями, но по смыслу писали примерно то же самое.
Теперь ссылку посмотрел, действительно копи-паст, классно :) !
Fitbie
19.03.2024 13:21+1Я читал вашу статью и понял что вы хотели донести, но как лично я вижу это:
Есть Клири (надеюсь правильная транслитерация) и есть, допустим, Metanit. Первый говорит что асинхронность не создает потоки вообще никогда (хотя на самом деле, если прокликать его сайт, то можно наткнуться и на await Task.Run() в частных случаях), а второй говорит полностью обратное.
И тут есть момент: лучше человеку вбить в голову что асинхронность != потоки, чем вбить обратное. Объясню на примере: я сам учебный план строил по Metanit, просто я разбавлял его поверхностность конкретикой с msdn и пр., и я помню, что асинхронность у него идет сразу после TPL. Таким образом, учитывая, что его статьи написаны для начинающих, и написаны слишком уж коротко, получается такой вопрос: а зачем оно надо, когда задачу можно решать синхронно-мультипоточно. Если же человеку сказать обратное, то у него как минимум возникнет вопрос "а как тогда это работает", и дальше он уже сам нагуглит и про контексты и про configureAwait и про UI/ASP потоки.
Конечно, лучше всего написать простыню текста, объясняющего все азы async/await, но это работа для Майкрософт (хотя, надо признать, их async/await написан вполне человеческим языком, да и половина статей там за авторством Клири).rukhi7
19.03.2024 13:21+1Первый говорит что асинхронность не создает потоки вообще никогда ..., а второй говорит полностью обратное.
просто вот с этого надо начинать:
определения синхронного и асинхронного методов, которое дал Стивен Тоуб (например):
this method is “synchronous” because a caller will not be able to do anything else until this whole operation completes and control is returned back to the caller
this method is “asynchronous” because control is expected to be returned back to its caller very quickly and possibly before the work associated with the whole operation has completed
здесь действительно про потоки ничего нет, казалось бы.
Я напишу наверно в ближайшем будущем.

SideshowBob
19.03.2024 13:21Прям представил как вы разворачиваете перспективного кандидата с собеса, видно же, что некоторое понимание вопроса есть, и есть о чем задать уточняющие вопросы на собесе, и выяснить, он хреново пишет статьи или код... так сразу непонятно )

Kahelman
19.03.2024 13:21+1К вопросу с синглетоном: вообще-то его предложили для С++, поскольку там не определён порядок инициализации статических переменных. В C# достаточно создать статический экземпляр класса, и со всем остальным котом можно не заморачиваться.
Kahelman
19.03.2024 13:21+2Абстрактные классы нужны для того, чтобы выделять общий функционал от нескольких классов в обособленный класс. От этого отдельного класса потом можно унаследовать либо просто сигнатуру функционала, либо вместе с реализацией.
Класс обязательно нужно объявлять как абстрактный, когда он содержит абстрактные члены.
Порадовало. Особенно последнее предложение. Масло-маслинное.
Класс абстрактный потому что он содержит абстрактные методы. А не наоборот.
Правильный вопрос: зачем вам абстрактные классы если есть интерфейсы. Ну или в чем отличие интерйфецсов от абс тактных классов.

MonkAlex
19.03.2024 13:21Не уверен, что правильно понял.
Можно сделать абстрактный класс без абстрактных методов и свойств.
Такой класс нельзя будет создавать (через new по крайней мере), что потребует явно объявить наследник для использования.
А вот если в обычный класс воткнуть абстрактный метод - да, класс придётся тоже объявить абстрактным.
Так что вроде в целом текст логически верный.


PashaPash
19.03.2024 13:21+2Значимые типы (value type) хранятся в стеке
ага, конечно...
class SomeClass { int someField; // <--- int значимый? someField хранится в стеке? }и да, "локальные переменные value type хранятся в стеке" - тоже неправильный ответ (контрпример - замыкание).
---
неуправляемые ресурсы памяти
вместо того, что б создавать пользовательские финализаторы
не "памяти", и не "вместо". и собеседующий будет рад услышать про Safe handles.
atd
Какой-то список кринжа, боянов, ещё и с неправильными ответами...
Vitimbo
Что стоит знать об уровне блога
Такие статьи не должны писать копирайтеры. Нужно хоть какое-то представление о теме разговора иметь, а не просто надергать вопросы их десятков таких же топов, гуляющих по интернету уже который год.
FanatPHP
Если бы копирайтер. Судя по другим подборкам, это пишет тупо ИИ. Причем на любую тему - хочешь тебе Go, хочешь - Питон, хочешь - SQL, хочешь - вот Шарпы. Причем пишет с нескольких аккаунтов.
По факту это рак, который добивает и так уже почти бессмысленный Хабр. Но всем, как обычно, пох.
FanatPHP
Но у него в канале достаточно подписчиков, чтобы апать статью, так что она все равно будет в плюсах
radtie
Тихо, тихо, щас ChatGPT проиндексирует статью, и у нас будущем все еще будет работа.