Допустим, вам нужно быстро распарсить 8-битные целые числа (0, 1, 2, …, 254, 255) из строки ASCII/UTF-8. Задача взята из проекта simdzone под руководством Йероена Коеккоека (NLnet Labs). Дана строка и её длина: например, ’22’ и длина 2. Наивное решение на C может выглядеть так:
int parse_uint8_naive(const char *str, size_t len, uint8_t *num) {
uint32_t n = 0;
for (size_t i = 0, r = len & 0x3; i < r; i++) {
uint8_t d = (uint8_t)(str[i] - '0');
if (d > 9)
return 0;
n = n * 10 + d;
}
*num = (uint8_t)n;
return n < 256 && len && len < 4;
}Этот код — функция C, получающая в качестве входных аргументов строку символов, её длину и указатель на 8-битный беззнаковый integer. Функция возвращает значение Boolean, определяющее, можно ли спарсить входную строку в 8-битный беззнаковый integer, или нет. Она ограничивает ввод максимум тремя символами, но позволяет использовать нули в начале (например, 002 — это 2).
Сначала функция инициализирует 32-битный беззнаковый integer n, присваивая ему значение 0, в нём мы будем хранить ответ. Затем функция итеративно обходит входную строку, извлекая из строки каждый цифровой символ и преобразуя его в беззнаковый 8-битный integer. Извлечённая цифра затем умножается на 10 и прибавляется к n. Этот процесс продолжается до конца строки или пока функция не обработает 4 байта строки. Наконец, функция присваивает значение n беззнаковому 8-битному integer, на который указывает num. Затем она возвращает булево значение, обозначающее, меньше ли распарсенный integer, чем 256, и длину входной строки (от 1 до 3 символов). Если входная строка содержит любые нецифровые символы или если длина строки больше 3 байтов, то функция возвращает false.
Если длина входных данных предсказуема, то эта наивная функция должна работать быстро. Однако если длина варьируется (от 1 до 3), то процессор будет склонен к неверному прогнозированию ветвления и к дорогостоящим затратам вычислительных ресурсов.
В C++ можно вызвать from_chars:
int parse_uint8_fromchars(const char *str, size_t len, uint8_t *num) {
auto [p, ec] = std::from_chars(str, str + len, *num);
return (ec == std::errc());
}Функция std::from_chars получает три аргумента: указатель на начало входной последовательности символов, указатель на её конец и ссылку на выходную переменную, в которой будет храниться распарсенное целочисленное значение. Функция возвращает объект std::from_chars_result, содержащий два члена: указатель на первый нераспарсенный символ и код ошибки, указывающий, был ли парсинг успешным.
В этой функции вызывается std::from_chars со входной строкой и длиной в качестве аргументов, а также с указателем на 8-битный беззнаковый integer, в котором будет храниться распарсенное значение. Затем функция проверяет равенство возвращённого std::from_chars кода ошибки std::errc(), что указывает на успешность парсинга. Если парсинг был успешным, функция вернёт true. В противном случае она вернёт false.
Можно ли справиться лучше, чем эти функции? Это не так уж очевидно. Обычно мы не стремимся оптимизировать функции, считывающие от 1 до 3 байтов. Но тем не менее: возможно ли это? Можем ли мы ускорить работу?
Допустим, мы всегда можем считывать 4 байта, даже если строка короче (то есть существует буфер). Часто это вполне безопасное допущение. Если числа находятся внутри более длинной строки, то мы часто можем эффективно проверить, находимся ли мы в четырёх байтах конца строки. Даже если это не так, считывание четырёх байтов всегда безопасно, если мы не пересекаем границу страницы, а это проверить очень легко.
То есть можно записать входные данные в 32-битное слово и обработать все байты за раз в одном регистре. Это часто называют SWAR: в computer science SWAR означает «SIMD в пределах регистра»; это методика выполнения параллельных операций над данными, содержащимися в регистре процессора.
Йероен Коеккоек сначала придумал вполне рабочую методику со SWAR, но она была лишь примерно на 40% быстрее наивного решения в случае непредсказуемых входных данных, и потенциально медленнее наивного решения в случае предсказуемых входных данных. Давайте изучим решение, которое может быть конкурентоспособным в любом случае:
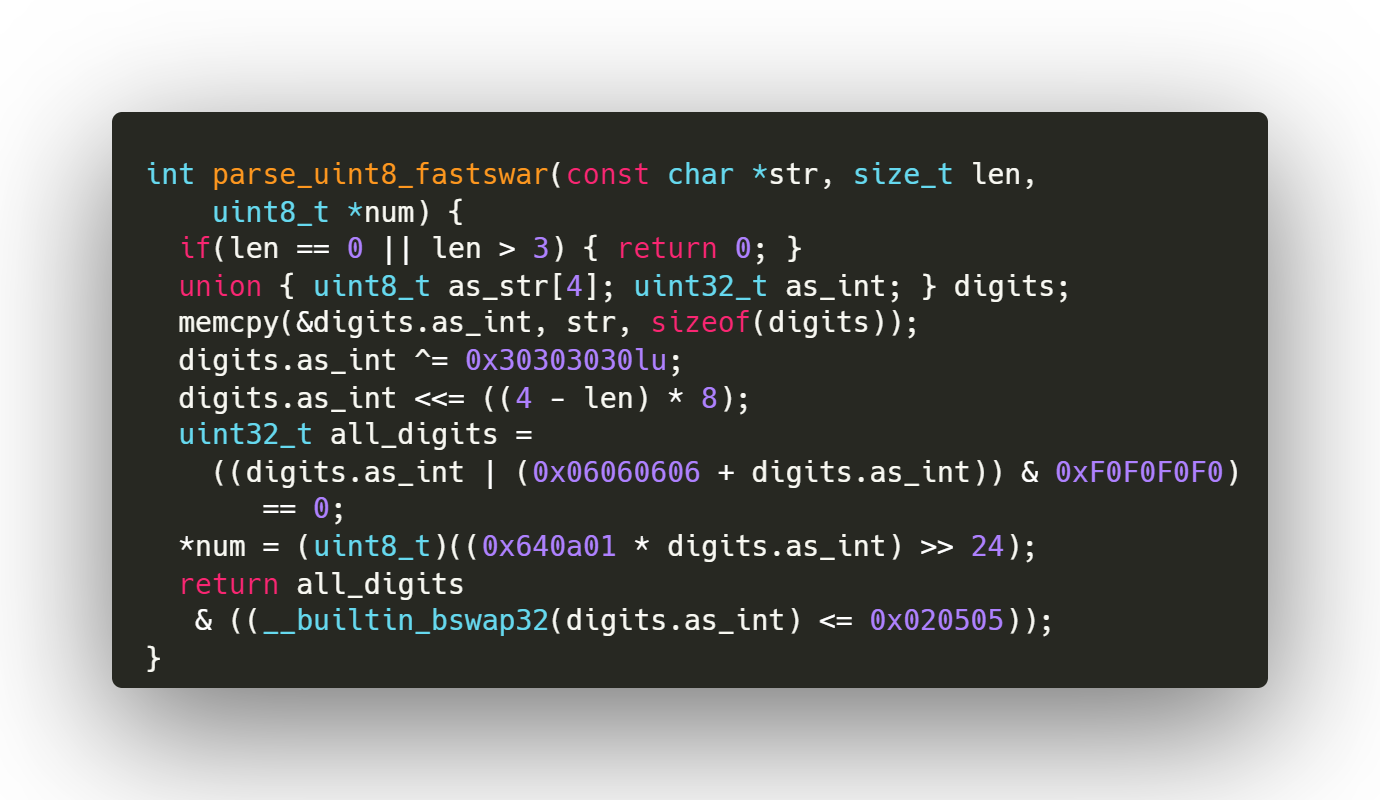
int parse_uint8_fastswar(const char *str, size_t len,
uint8_t *num) {
if(len == 0 || len > 3) { return 0; }
union { uint8_t as_str[4]; uint32_t as_int; } digits;
memcpy(&digits.as_int, str, sizeof(digits));
digits.as_int ^= 0x30303030lu;
digits.as_int <<= ((4 - len) * 8);
uint32_t all_digits =
((digits.as_int | (0x06060606 + digits.as_int)) & 0xF0F0F0F0)
== 0;
*num = (uint8_t)((0x640a01 * digits.as_int) >> 24);
return all_digits
& ((__builtin_bswap32(digits.as_int) <= 0x020505));
}Этот код — тоже функция на C, получающая в качестве входных аргументов строку символов, её длину и указатель на 8-битный беззнаковый integer. Функция возвращает булево значение, определяющее, можно ли распарсить входную строку в 8-битный беззнаковый integer. Мы проверяем, находится ли длина в интервале ([1,3]), и если нет, то возвращаем false, прекращая исполнение функции. После этой первоначальной проверки функция сначала инициализирует объединение digits , содержащее массив из четырёх беззнаковых 8-битных integer и одного 32-битного беззнакового integer. Затем функция копирует входную строку в 32-битный беззнаковый integer при помощи функции memcpy. Функцияmemcpy копирует входную строку в 32-битный беззнаковый integer. В коде продакшена, когда вы не знаете целевую платформу, может понадобиться отобразить порядок байтов, если целевая платформа имеет формат big endian. Системы big endian чрезвычайно редки: в основном это мейнфреймы. Современные системы компилируют инверсию порядка байтов в единичные быстрые команды. В коде своего поста я предполагаю, что вам не встретится система big endian, что справедливо в 99,99% случаев.
Затем функция обращает биты 32-битного беззнакового integer при помощи оператора XOR и константы 0x30303030lu. Эта операция преобразует каждый цифровой символ входной строки в соответствующее десятеричное значение. И в самом деле: символы ASCII от 0 до 9 имеют в ASCII значения точек кода от 0x30 до 0x39. Затем функция сдвигает 32-битный беззнаковый integer влево на определённое количество битов, зависящее от длины входной строки. Эта операция удаляет все замыкающие байты, не относящиеся ко входной строке. Строго говоря, когда длина не находится в пределах допустимого интервала ([1,3]), сдвиг может быть неопределённым поведением, но мы ещё до этого возвращаем значение false, указывая, что результат вычислений недопустим.
Следующая часть — это то место, где вклад в процедуру сделал я. Сначала мы проверяем при помощи краткого выражения, все ли символы — это цифры. Затем функция умножает 32-битный беззнаковый integer на константу 0x640a01, использующую 32-битный беззнаковый integer. Это краткий способ выполнить два умножения (на 100 и на 10) и два сложения за раз. Обратим внимание, что 0x64 — это 100, а 0x0a — это 10. Затем результат этого умножения сдвигается вправо на 24 бита. Эта операция извлекает самый старший байт 32-битного беззнакового integer, обозначающий распарсенный 8-битный беззнаковый integer. В конце функция присваивает значение распарсенного 8-битного беззнакового integer 8-битному беззнаковому integer, на который указывает num. Затем она возвращает булево значение, показывающее, меньше ли распарсенный integer, чем 256, и состоит ли он полностью из цифр.
На процессорах x64 функция может скомпилироваться в примерно в двадцать ассемблерных команд:
lea rcx, [rsi - 4]
xor eax, eax
cmp rcx, -3
jb .END
mov eax, 808464432
xor eax, dword ptr [rdi]
shl esi, 3
neg sil
mov ecx, esi
shl eax, cl
lea ecx, [rax + 101058054]
or ecx, eax
test ecx, -252645136
sete cl
imul esi, eax, 6556161
shr esi, 24
mov byte ptr [rdx], sil
bswap eax
cmp eax, 132358
setb al
and al, cl
movzx eax, al
.END: # %return
retДля тестирования этих функций я написал бенчмарк. В бенчмарке используются случайные входные значения или последовательный ввод (0,1,…), и он оказался очень релевантным. я воспользовался GCC 12 и Linux-сервером на Ice Lake (Intel) с частотой 3,2 ГГц. В таблице указано количество миллионов распарсенных чисел за секунду.
случайные числа |
последовательные числа |
|
std::from_chars |
145 миллионов/с |
255 миллионов/с |
naive |
210 миллионов/с |
365 миллионов/с |
SWAR |
425 миллионов/с |
425 миллионов/с |
То есть при непредсказуемых входных значениях решение со SWAR в два раза быстрее, чем наивное решение. В случае предсказуемых входных данных мы обгоняем наивное решение примерно на 15%. Будет ли это полезно в вашем конкретном случае, зависит от ваших данных, так что стоит провести собственные бенчмарки.
Важно, что методика со SWAR полностью эквивалентна наивному решению, за исключением того, что она всегда считывает 4 байта, вне зависимости от длины.
Результаты from_chars совершенно разочаровывают. Я теряюсь в догадках, почему наивное решение настолько быстрее, чем стандартная библиотека. Она решает немного иную задачу, но разница всё равно достаточно велика. Возможно, стандартной библиотеке (GCC 12) ещё есть, куда совершенствоваться.
Сможете ли вы справиться лучше? Бенчмарк выложен на github. В рамках бенчмарка мы также тщательно проверяем корректность валидации.
Благодарности: я признателен Йероену Коеккоеку из NLnet Labs за то, что он предложил мне эту задачу. Описанное решение усовершенствовано на основании предложения Жан-Марка Бурге.
Дополнение: пользователь Perforated Bob предложил версию, которая будет быстрее в некоторых компиляторах:
int parse_uint8_fastswar_bob(const char *str, size_t len, uint8_t *num) {
union { uint8_t as_str[4]; uint32_t as_int; } digits;
memcpy(&digits.as_int, str, sizeof(digits));
digits.as_int ^= 0x303030lu;
digits.as_int <<= (len ^ 3) * 8;
*num = (uint8_t)((0x640a01 * digits.as_int) >> 16);
return ((((digits.as_int + 0x767676) | digits.as_int) & 0x808080) == 0)
&& ((len ^ 3) < 3)
&& __builtin_bswap32(digits.as_int) <= 0x020505ff;
}
Комментарии (21)

TheCalligrapher
30.12.2023 08:22+1Использованный в коде
unionсодержит полеas_str. Однако нигде в коде это поле не используется, что говорит о том, что ни это поле никому тут нинафиг не нужно, ни весьunionникому тут нинафиг не нужен. Зачем код замусорен всем этим? В чем глубинный смысл?
bolk
30.12.2023 08:22В комментариях к оригиналу есть версия:
Neat! I have noticed a small mistake:
memcpy(&digits.as_int, str, sizeof(digits));should be
memcpy(&digits.as_str, str, sizeof(digits));TheCalligrapher
30.12.2023 08:22+5Это не ошибка, это бессмыслица. Если уж автор воспользовался memcpy, то union ему действительно не нужен. Собственно, потому он и не заметил этой "ошибки", что код прекрасно работает и так. Union с фиктивными полями иногда приходится использовать для, целей выравнивания, но здесь совсем не тот случай. Автор наворотил ненужной фигни с union поверх вполне работоспособной техники и, похоже, до сих пор не понял, что это лишь ненужная фигня.
bolk
30.12.2023 08:22+1Понятно, что оно там не нужно, но как-то же автор планировал использовать этот код. Может вот так.


Apoheliy
30.12.2023 08:22+1memcpy(&digits.as_int, str, sizeof(digits));
По-моему, копировать из строки больше байт, чем там есть - это UB, крэш, эксплойт на слив данных из соседней памяти ... и вообще нехорошо.
Согласно https://en.cppreference.com/w/cpp/types/integer типа uint32_t может не быть: provided if and only if the implementation directly supports the type
Возможно, стоит рассмотреть табличный метод: массив 256 байт на первый символ, далее на второй и третий. В телефонии это считается одним из самых быстрых способов делать фиксированные вычисления.

Zara6502
30.12.2023 08:22Я теряюсь в догадках, почему наивное решение настолько быстрее, чем стандартная библиотека
Ну я с таким на C# сталкиваюсь постоянно, недавно статью вот даже написал. И это удручает, так как стандартными методами пользуются весьма охотно.


sergio_nsk
30.12.2023 08:22Результаты from_chars совершенно разочаровывают. Я теряюсь в догадках, почему наивное решение настолько быстрее, чем стандартная библиотека.
Потому что голландец, видимо, середнячок, судя по другим комментариям о ненужном
unionи незнании о том, чтоstd::from_chars()немного универсальней с четвёртым параметромint base = 10, и там без произведения сbaseне обойтись. Ну и всякие ошибкиerrc::invalid_argument,errc::result_out_of_range.
feelamee
30.12.2023 08:22Насчёт base - если они не догадались оптимизировать самый частый контекст использования...
sergio_nsk
30.12.2023 08:22-1А кто подсчитывал, что основание 10 для байта самое частое, а не 16? И
from_charsне ограничена только диапазоном 0-255, теперь им для каждого целочисленного знакового и беззнакового типа писать оптимизации?
Mingun
30.12.2023 08:22-1Разумеется, а зачем еще нужна стандартная библиотека? Чтобы самому все писать что ли?
feelamee
30.12.2023 08:22я бы мог поспорить, но не вижу смысла, потому что у функции автора и std::from_chars разные требования, хоть с помощью них и можно решить одну задачу.
Помню пост, где wc на haskell был быстрее gnu имплементации на Си. Ох и споров там было.
Просто это нечестный, в какой-то степени, бенчмарк.

feelamee
30.12.2023 08:22интересно, будет ли какой-то эффект, если убрать проверки на длину и all_digits
Какой смысл от них? Мне кажется это тоже самое, что добавлять проверку в strlen.

roqin
30.12.2023 08:22+4Задача взята из проекта simdzone под руководством Йероена Коеккоека (NLnet Labs).
Я тут слегка посмотрел и выяснил:
Что упоминающийся Йероен Коеккоек - это Jeroen Koekkoek (https://imap.nlnetlabs.nl/people/, https://github.com/k0ekk0ek), т.е. явно голландец;
И следовательно тут надо применять правила нидерландско-русской транскрипции;
И он получается скорее Йерун Куккук, там oe передаёт у.
P.S. Прошу меня извинить, просто странный набора знаков в глаза бросился ????



ReadOnlySadUser
30.12.2023 08:22Не понятно, почему эта статья в хабах С и С++.
считывание четырёх байтов всегда безопасно, если мы не пересекаем границу страницы, а это проверить очень легко.
С этого места человек перестаёт писать код на Си/С++. Потому как стандарты Си и С++ ничего не знают ни про границы страниц, ни про что-то еще. Выход за границу массива определяется как UB.
Де факто, человек с этого момента начинает писать на ассемблере, под конкретную аппаратную архитектуру, конкретный аллокатор в конкретной ОС. Это допустимо, если он пишет код под одну конкретную железку, но в остальных случаях - такому коду не место в продакшене.
ReadOnlySadUser
30.12.2023 08:22+1Я тут ради прикола написал самую дубовую реализацию этой функции через switch-case, вообще не думая.
static int parse_uint8_switch_case(const char *str, size_t len, uint8_t *num) { uint8_t hi, mid, lo; #define as_u8(x) ((uint8_t)((x) - '0')) switch(len) { case 1: *num = as_u8(str[0]); return *num < 10; case 2: hi = as_u8(str[0]); lo = as_u8(str[1]); *num = (uint8_t)(hi * 10 + lo); return (hi < 10) && (lo < 10); case 3: hi = as_u8(str[0]); mid = as_u8(str[1]); lo = as_u8(str[2]); *num = (uint8_t)(hi * 100 + mid * 10 + lo); return ((hi == 2) && (mid < 6) && (lo < 6)) || ((hi < 2) && (mid < 10) && (lo < 10)); default: return 0; } #undef as_u8 }А потом запустил бенчмарки. Результат довольно-таки занимательный:

Как всегда, кто-то решил что он умнее разработчиков компилятора, и умнее разработчиков предсказателя переходов)
P.S.
Что делает код Боба и почему он такой быстрый - я понятия не имею :) Есть подозрение, что выстрелил UB и код делает ровным счётом нихрена, я не вникал.


Fasterpast
30.12.2023 08:22Да уж, помню как когда я начал изучать микроконтроллеры и С, меня впечатлило преобразование char в int простым вычитанием '0' )
iig
Хм.