
Зачастую в процессе разработки собственных устройств или моддинга уже существующих, встаёт задача выполнения стороннего кода: будь то ваши собственные программы с SD-флэшек, или программы, написанные другими пользователями с помощью SDK для вашего устройства. Тема компиляторов и кодогенерации достаточно сложная: чтобы просто загрузить ELF или EXE (PE) программу, вам нужно досконально разбираться в особенностях вашей архитектуры: что такое ABI, релокации, GOT, отличие -fPIE от -fPIC, как писать скрипты для ld и т. п. Недавно я копал SDK для первых версий Symbian и основываясь на решениях из этой ОС понял, каким образом можно сделать крайне «дешевую» загрузку любого нативного кода практически на любом микроконтроллере, совершенно не вникая в особенности кодогенерации под неё! Сегодня мы с вами: узнаем, что происходит в процессе загрузки программы ядром Linux, рассмотрим концепцию, предложенную Symbian Foundation и реализуем её на практике для относительно малоизвестной архитектуры — XTensa (хотя она используется в ESP32, детали её реализации «под капотом» для многих остаются загадкой). Интересно? Тогда добро пожаловать под кат!
❯ Как это работает?
Думаю, для многих моих читателей реализация процесса загрузки exe-программ и dll-библиотек в память процесса оставалась эдаким чёрным ящиком, в детали реализации которого вдаваться не нужно. Отчасти это так и есть: современные ОС разруливают процесс загрузки бинарников в память сами, не требуя от программиста вообще ничего, даже понимания того, куда будет загружена его библиотека или программа.

Давайте для общего понимания вкратце разберемся, как происходит загрузка программ в Windows/Linux:
1. Система создаёт процесс и загружает в память программы секции из ELF/PE. Обычные программы для своей работы используют 3 секции: .text (код), .data (не-инициализированный сегмент памяти для глобальных переменных), .bss (сегмент памяти для инициализированных переменных). Каждому процессу выделяется собственное адресное пространство, называемое виртуальной памятью, которое не позволяет программе испортить память ядра, а также позволяет не зависеть от разметки физической памяти на выполняющей машине. Концепцию виртуальной памяти реализует специальной модуль в процессоре, называемый MMU.
2. Если бы наши программы не использовали никаких зависимостей в виде динамических библиотек, то на этом процесс загрузки можно было бы закончить: каждая программа имеет свой адрес загрузки, относительно которого линкер строит связи между обращениями к коду/данным программы. Фактически, для самых простых программ линкеру остаётся лишь прибавить адрес загрузки программы (например, 0x100) к каждому абсолютному обращению к памяти.
Однако современные программы используют десятки библиотек и для всех предусмотреть собственный адрес загрузки не получится: кто-то где-то всё равно будет пересекаться и вероятно, портить память. Кроме того, современные стандарты безопасности в Linux рекомендуют использовать позиционно-независимый код, дабы использовать преимущества ASLR (Address Space Layout Randomization, или простыми словами возможность загрузить программу в случайное место в памяти, дабы некоторые уязвимости, завязанные на фиксированном адресе загрузки программы перестали работать).
3. Поэтому для решения этой проблемы придуман т. н. динамический линкер, который уже на этапе загрузки программы или библиотеки патчит программу так, чтобы её можно было загрузить в любой участок памяти. Для этого используются данные, полученные от обычного линкера а этапе компиляции программы: помимо .text, .data и .bss, линкер создаёт секции .rel и .rel-plt, которые называются релокациями. Если объяснять совсем условно, то релокации — это просто запись вида «какой абсолютный адрес в коде программы нужно пропатчить» -> «на какое смещение его пропатчить». Самая простая релокация выглядит вот так:
struct Relocation
{
int textOffset;
int valueToPatch;
};
...
*((int*)&code[rel.textOffset])) = rel.valueToPatch + loadAddress;
Где по итогу:
org 100h
; Было
mov bx, 15
; Стало
mov bx, 271
.rel-plt же служит для резолвинга вызовов к dll/so: изначально программа ссылается на заранее определенные в процессе компиляции символы, которые уже в процессе загрузки патчатся на физические адреса функций из загруженной библиотеки.
И казалось бы — всё очень просто, пока в дело не вступают GOT (Global Offset Table — глобальная таблица смещений) и особенности реализации конкретного ABI. И ладно бы x86 или ARM, там всё разжевано и понятно, однако на других архитектурах начинаются проблемы и не всегда очевидно что и где за что отвечает.
А ведь чаще всего нужно просто загрузить небольшую программу, которой не нужны комплексные загрузчики: немного кода, немного данных и всё. И тут у нас есть три выхода:
- Писать полноценный загрузчик ELF-бинарников. ELF может оказаться громоздким для некоторых окружений и его реализация может оказаться тривиальной не для всех.
- Зарезервировать определенный сегмент в памяти (пусть с 0xFFF по 0xFFFF) и скомпилировать нашу программу с адресом загрузки 0xFFF с параметром -fno-pic. В таком случае, линкер сгенерирует обращения к памяти по абсолютным адресам — если переменная лежит по адресу 0xFFF, то программа будет обращаться сразу к этому адресу памяти, без необходимости что либо динамически линковать. Именно такой подход использовался во времена ZX Spectrum, Commodore 64 и MS-DOS (однако там роль «виртуальной памяти» выполняла такая особенность 8086, как сегменты). У такого подхода есть и минусы: относительная невозможность загрузки сразу нескольких программ одновременно, зарезервированное пространство линейно отъест небольшой кусок памяти у основной прошивки, нет возможности динамической аллокации секций. Зато такой код теоретически будет работать быстрее, чем PIC.
Проблемы реализации такого способа: иногда нужно лезть в систему сборки основной прошивки и патчить скрипт линкера так, чтобы он не трогал определенный регион памяти. В случае esp32, например, это требует патча в сам SDK и возможного «откола» от мейнлайн дистрибутива. - Использовать программу с относительной адресацией, однако без сегментов .bss и .data. Самый простой в реализации способ, который к тому же очень экономичен к памяти, позволяет загружать программу в любое место и пользоваться всеми фишками динамического аллокатора и не требует вмешательств в основную прошивку, кроме примитивного загрузчика программ. Именно его я и предлагаю рассмотреть подробнее.
Недавно мы сидели в чате ELF-сцены (разработка нативных программ под телефоны Siemens, Sony Ericsson, Motorola и LG с помощью хаков) и думали, как же можно реализовать загрузчик сторонних программ на практически неизвестных платформах. Кто-то предлагал взять ELF под основу — однако с его реализацией под некоторые платформы есть трудности, а кто-то предлагал писать «бинлоадер» — самопальный формат бинарников, который получается из, например, тех же эльфов.

В это же время я копал SDK для Symbian и хорошо помнил, что в прикладных приложениях для этой ОС нет поддержки глобальных переменных вообще. Да, сегмент .data и .bss полностью отсутствует — переменные предлагается хранить в структурах. Почему так сделано? Всё дело в том, что каждая программа в Symbian — это dll-библиотека, которую загружает EKA и создаёт экземпляр CApaApplication. И дабы была возможность загрузить dll один раз для всех программ (что справедливо для системных библиотек), ребята полностью выкинули возможность использования любых глобальных переменных. А ведь идея интересная!
Однако в таком подходе есть несколько серьезных ограничений:
- Отсутствие глобальных переменных может стать проблемой при портированиии уже существующего софта, хотя вашим программам ничего не мешает передавать в каждую функцию структуру с глобальным стейтом, который можно при необходимости изменять. Кроме того, нет ограничений на использование C++ (за исключением необходимости ручной реализации new/delete и отсутствием исключений).
- Отсутствие преинициализированных данных. Вот это уже может стать относительно серьёзной проблемой, у которой, тем не менее, есть свои обходные решения. Например если вы храните команды для инициализации дисплея в таблице, или какие-либо калибровочные данные — вы не сможете их объявить, просто используя инициализаторы в C. Тоже самое касается и строковых литерал. Тут есть два варианта: часть таблиц можно вынести на стек (если эти самые таблицы достаточно маленькие), либо подгружать необходимые данные из бинарника с помощью основной прошивки (например, LoadString и т. п.).
Давайте же на практике посмотрим, имеет ли право на жизнь такой подход!
❯ Практическая реализация
Формат нашего бинарника будет до безобразия прост: небольшой заголовок в начале файла и просто сырой дамп сегмента .text, который можно экспортировать из полученного elf даже без необходимости писать скрипт для линкера. При этом нужно учесть, что ESP32 — это микроконтроллер частично Гарвардской архитектуры, т. е. шина данных и кода у него расположены отдельно. Однако у чипа есть полноценный MMU, который позволяет маппить регионы физической памяти в виртуальную память, чем мы и воспользуемся в итоге!
Заголовок нашего бинарника будет выглядеть вот так:
unsigned short GetGlobalStateSize();
void Start(SysCall sysCall, GlobalState* state);
typedef struct
{
int Header;
unsigned short(*GetGlobalStateSize)();
void(*Start)(SysCall sysCall, GlobalState* ptr);
} ExecutableStruct;
ExecutableStruct header __attribute__ ((section (".text"))) = {
0x1337,
&GetGlobalStateSize,
&Start
};
Программа общается с основной прошивкой посредством псевдо-syscall'ов: функции, которая в качестве первого аргумента ожидает номер нужной службы и один 32х-битный указатель для описания структуры с параметрами. Реализация syscall'ов — одна из самых простых и неприхотливых с точки зрения обратной совместимости с будущими прошивками.
void SysCall(unsigned short callNum, void* data)
{
printf("SysCall %d\n", callNum);
}
Концептуально всё очень просто: GetGlobalStateSize сообщает нашему загрузчику размер структуры для хранения глобального стейта, в то время как Start уже фактически заменяет main() в нашей программе. Необходимости в crt0 нет, поскольку весь необходимый инит выполняет бутлоадер ESP32. Впрочем, при желании вы можете выделить отдельный стек для вашей программы — это повысит надежность, если выполняемая программа удумает испортить стек.
unsigned short GetGlobalStateSize()
{
return sizeof(GlobalState);
}
void Test2(SysCall sysCall)
{
sysCall(25, 0);
}
void Test3(SysCall sysCall)
{
sysCall(35, 0);
}
void Start(SysCall sysCall, GlobalState* state)
{
Test2(sysCall);
Test3(sysCall);
sysCall(15, 0);
}Собираем нашу программу:
xtensa-esp32-elf-cc.exe test.c -fno-pic -nostdlib -nostartfiles -Wl,--section-start=.text=0x0
xtensa-esp32-elf-objcopy.exe --only-section=.text --output-target binary a.out run.bin
-fno-pic отключает генерацию кода, зависимого от GOT, -nostdlib и -nostartfiles убирает из билда crt0 и stdlib, благодаря чему мы получаем только необходимый код. --section-start задает смещение для загрузки секции .text на 0x0 (в идеале это делать необходимо из скрипта для ld).
objcopy скопирует из полученного ELF только необходимую нам секцию .text.
Как же это работает на практике? Давайте дизассемблируем выходной бинарник и посмотрим, что у нас дает на выхлопе cc:
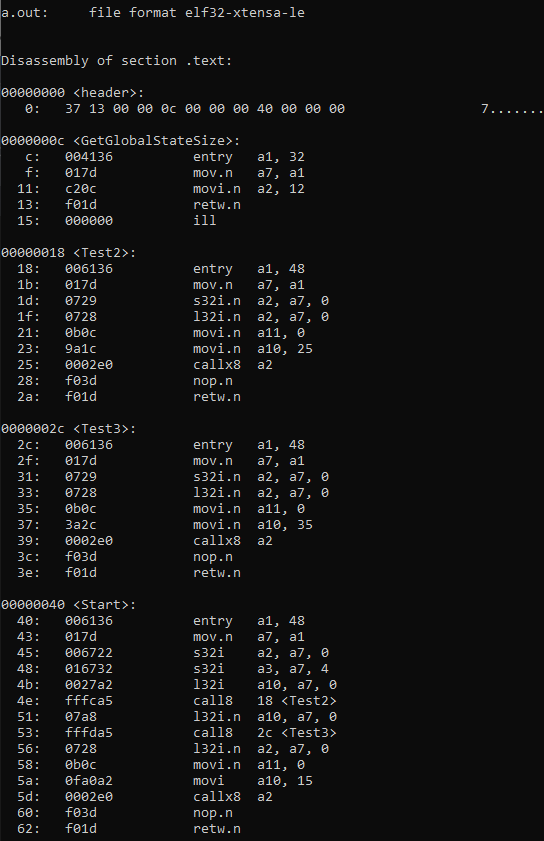
Обратите внимание, что Start вызывает подфункции с помощью инструкции CALLX8, которая в отличии от обычного Immediate-версии CALL8, выполняет переход относительно текущего адреса в PC, благодаря чему переход полностью независим от адреса загрузки программы в памяти. А благодаря тому, что все данные, в том числе и указатель на глобальный стейт передаются через стек, нет необходимости релокейтить сегменты данных.
По итогу всё, что нужно от загрузчика бинарников — это загрузить программу в память для инструкций, выделить память для структуры с стейтом программы и передать управление Start. Всё!
Конкретно в случае ESP32, у нас есть два возможных решения задачи загрузки программы в память:
- Загрузить программу в IRAM. Такая возможность теоретически есть, однако на практике загрузчик ESP32 устанавливает права только на чтение и выполнение на данный регион памяти. Попытка что-то скопировать туда закончится исключением SIGSEGV. Кроме того, сегмент IRAM относительно небольшой — всего около 200Кб.
- Самопрограммирование. Для этого, в esp32 есть два механизма — Partition API и SPI Flash API. Я выбрал Partition API для простоты реализации.
Для нашей прошивки необходимо будет переразметить флэш-память. Для этого запускаем idf.py menuconfig, идём в Partition Table -> Custom partition table CSV. Создаём в папке проекта partitions.csv, куда пишем:
# ESP-IDF Partition Table
# Name, Type, SubType, Offset, Size, Flags
nvs, data, nvs, 0x9000, 0x6000,
phy_init, data, phy, 0xf000, 0x1000,
factory, app, factory, 0x10000, 1M,
executable, data, undefined, 0x110000, 0x10000Для заливки программы можно использовать соответствующее Partition API, либо parttool.py:
parttool.py --port "COM41" write_partition --partition-name=executable --input "run.bin"Переходим к загрузчику программы:
bool ExecuteBinary(int length)
{
const esp_partition_t* partition = esp_partition_find_first(ESP_PARTITION_TYPE_DATA, ESP_PARTITION_SUBTYPE_ANY, "executable");
if(partition <= 0)
{
printf("Failed to get executable partition\n");
return 0;
}
void* mmappedPtr = 0;
esp_partition_mmap_handle_t handle;
esp_err_t err = esp_partition_mmap(partition, 0, length, ESP_PARTITION_MMAP_INST, &mmappedPtr, &handle);
printf("Mapped program to instruction address space: %d\n", (int)mmappedPtr, (int)err);
// Fix pointers
ExecutableStruct e = *((ExecutableStruct*)mmappedPtr);
e.GetGlobalStateSize += (unsigned int)mmappedPtr;
e.Start += (unsigned int)mmappedPtr;
if(e.Header != 0x1337)
{
printf("Header mismatch (got %d)\n", e.Header);
return 0;
}
unsigned short stateSize = e.GetGlobalStateSize();
if(stateSize < 1)
{
printf("GetGlobalStateSize returned 0. Is it desired behaviour?\n");
}
void* data = malloc(stateSize);
printf("Allocated program state of %d bytes\n", stateSize);
if(!data)
{
printf("Failed to allocate program state of size %d\n", stateSize);
return 0;
}
e.Start(&SysCall, data);
free(data);
return 1;
}
Прошиваем ESP32:
idf.py build
idf.py flash
idf.py monitor
И смотрим результат:
SysCall 25
SysCall 35
SysCall 15
Всё работает!
❯ Заключение
Как видите, ничего сложного в выполнении сторонних программ при условии соблюдении некоторых ограничений нет. Да, в таком подходе есть как серьезные плюсы, так и минусы, однако он делает своё дело и позволяет реализовать запуск игр на кастомных игровых консолях, или сторонних программ на самодельных компьютерах. Ну и конечно же не стоит забывать про плагины! Авось в вашем решении нужна возможность расширения функционала устройства, однако предоставлять исходный код или даже объектные файлы нет возможности — тогда вам может пригодится и такая методика.
Пожалуй, стоит упомянуть ещё один… очень своеобразный метод, который я иногда встречаю при реализации самодельных компьютеров. Люди пишут… эмуляторы 6502/Z80 :)
И если такой подход ещё +- применим к ESP32, то в AVR просадки производительности будут слишком серьезными. Так зачем, если можно использовать все возможности ядра на максимум?
Возможно, захочется почитать и это:
- ➤ Эльфы и пингвины: что такое ELF и как он работает в Linux?
- ➤ KC868-A2: ESP32 + LAN8720A + GSM 2G/4G (на квадрате 9x9 см)
- ➤ Электроника для самых маленьких: или еще один UV излучатель для активации фотополимера
- ➤ Реверс-инжиниринг и ремонт платы зарядного устройства
- ➤ Полная история игровой вселенной «Гарри Поттера» — «Золотое поколение»

Комментарии (36)

ultrinfaern
05.01.2024 08:10Чесно говоря не понял, в чпм проблема загрузить .bss и .data если с .text проблем нет.
После вашей загрузки вы спрашиваете размер памяти выделяете и отдаете программе. Но это тоже самое что загрузить остальные сегменты и дать программе адреса где они есть. Может вместо GetGlobalStateSize лучше было GetDataAddress, GetBssAddress или что-то подобное.

bodyawm Автор
05.01.2024 08:10+2.bss и .data если с .text проблем нет.
В том, что для отказа от релокаций, я эксплуатирую такую особенность кодогенератора, как генерация относительных переходов, вместо абсолютных. Однако любые обращения к глобальным переменным всё равно окажутся по абсолютным адресам (либо через GOT), что потребует реализацию релокаций. Например:
int a; int main() { a = 5; }Пусть a лежит по адресу 0x0 относительно .text, а программа загружается по адресу 0x100. Получается что после линковки, программа обратится именно к смещению 0x100, хотя программа может быть загружена куда угодно - например в 0x200. По итогу логика программы ломается.

Kelbon
05.01.2024 08:10e.GetGlobalStateSize += (unsigned int)mmappedPtr; e.Start += (unsigned int)mmappedPtr;А это точно сделает то что нужно (это указатели на функции, прибавит к ним не количество байт, а в sizeof(void(*)()) больше)
И ещё наверное опечатка, проверка поинтера на отрицательность
const esp_partition_t* partition = ...; if(partition <= 0)bodyawm Автор
05.01.2024 08:10А это точно сделает то что нужно (это указатели на функции, прибавит к ним не количество байт, а в sizeof(void(*)()) больше)
Там всё нормально. Почему это он должен прибавить sizeof(void(*)())?
С проверкой очепятка, да, спасибо Там проверка на ESP_ERR должна быть.Kelbon
05.01.2024 08:10Там всё нормально. Почему это он должен прибавить sizeof(void(*)())?
Потому что указатель на функцию и казалось бы должно прибавляться sizeof(X), но да, кажется оно работает именно прибавляя байты (что конечно далеко не каждый сишник знает)
p.s. это кажется расширение гцц
bodyawm Автор
05.01.2024 08:10In GNU C, addition and subtraction operations are supported on pointers to
voidand on pointers to functions. This is done by treating the size of avoidor of a function as 1.A consequence of this is that
sizeofis also allowed onvoidand on function types, and returns 1.The option -Wpointer-arith requests a warning if these extensions are used.
В любом случае спасибо за наводку. Всегда считал такое поведение соответствующим стандарту ;)

VelocidadAbsurda
05.01.2024 08:10+1А Thread-Local Storage заабьюзить не пробовали? Если в данном GCC всё реализовано как надо, то всё должно свестись к добавлению к статическим/глобальным переменным атрибута __thread, и те начнут адресоваться относительно регистра THREADPTR (который при старте выставить на выделенную область). Для TLS и секция инициализации предусмотрена, которую по идее можно средствами ld поместить в кодовый сегмент и при старте скопировать в выделенную область (по аналогии с инициализацией .data в RAM из flash на микроконтроллерах).
Вдогонку: ещё один класс проблем, решаемых relocations, но не решаемых PC-relative адресацией: всякие константные таблицы указателей вроде { CmdText, CmdHandler }[], которые ld положит в .text как есть и никто их не пересчитает при загрузке.
bodyawm Автор
05.01.2024 08:10Глянул сейчас реализацию TLS, там большая зависимость от динамического линкера :(
VelocidadAbsurda
05.01.2024 08:10+2Да, но по идее он должен делать довольно простые вещи - копировать данные инициализации в динамически выделенную память и записывать в THREADPTR её адрес. Секцию с данными инициализации в скрипте линкера помещаете в «основной» сегмент (где код), ее начало/длину там же вытаскиваете в виде двух uint32 в заголовок, а при загрузке делаете memcpy оттуда в выделенную вами область, выставляете THREADPTR на неё же, прыгаете на точку входа, всё, вы - динамический линкер. Основная «магия» всех этих действий будет в другом - GCC сгенериурет код, где все обращения к static/global будут относительно THREADPTR, который под вашим контролем.

NutsUnderline
05.01.2024 08:10эм... ка кто тут все очень свалено в кучу, особенно в начальной части, изложенное надо прямо таки осиливать.
для начала про старое. сегментная, или скорее страничная архитектура позволяет иметь памяти несколько программ одновременно, несмотря на то что они имеют готовый бинарник рассчитанный на определенный адрес. Просто они находятся в разных страницах, которые отображаются на один и тот же адрес. Они при этом как бы не могут исполнятся одновременно но реально одновременно на таких архитектурах мало что работает - либо один код, либо другой, а поверх этого - тот или иной контроль по времени.
При этом высшим пилотажем было создание т.н. релоцируемого кода который использовал только относительные переходы и мог быть просто размещен по любому адресу без особой релокации
динамическая же загрузка кода на не очень навороченных контроллерах уровня stm32 и esp32 это как бы и круто, но это усложнение эффективность которого надо просчитать. например для flipper zero так сделали, как бы есть подгружаемые приложения которые используют графический интерфейс в общем стандарте., но все равно люди делают альтернативные прошивки потому что чего то не хватает.
ну и с точки зрения безопасности это лишняя брешь. обязательно кому нить покажется интересным подгрузить свой код в, скажем, какой нить выключатель на esp32, потом это будет совсем "само" и т.д.
bodyawm Автор
05.01.2024 08:10+2Я не стал во всех подробностях расписывать процесс загрузки бинарников. Там как раз недавно статья про ELF вышла в блоге Таймвеба, в ней особенности формата расписаны подробнее. Я же хотел НА ПРАКТИКЕ и без воды показать proof of concept.
Идём к сегментной памяти. Сегментная и страничная память - это разные вещи, страница памяти - это единица для MMU, в то время как сегмент - особенность 8086 для адресации большего объёма памяти, чем позволяет шина. Вообще, насколько мне известно, сегментация - это особенность исключительно 8086 (могу ошибаться), иных процессоров с таким способом организации памяти я не видел.
одновременно
Это почему? Сначала разберемся, что значит "одновременно" выполнять код? Если речь о вызове кода из, например, библиотеки в другом сегменте, то для этого существуют far-вызовы. Если речь о вытесняющей многозадачности, то щедуллеры сохраняют полностью весь стейт задачи в стек - в том числе и указатели на сегменты, поэтому нет никакой проблемы выполнять хоть десять потоков в разных сегментах "одновременно".
При этом высшим пилотажем было создание т.н. релоцируемого кода который использовал только относительные переходы и мог быть просто размещен по любому адресу без особой релокации
Так это ведь задача компилятора была :)
динамическая же загрузка кода на не очень навороченных контроллерах уровня stm32 и esp32 это как бы и круто, но это усложнение эффективность которого надо просчитать. например для flipper zero так сделали, как бы есть подгружаемые приложения которые используют графический интерфейс в общем стандарте., но все равно люди делают альтернативные прошивки потому что чего то не хватает.
Это нужно для достаточно узкого круга задач. Никто не говорит, что нужно писать плагины для умных выключателей. Это нужно для самодельных игровых консолей, компьютеров и других девайсов, где может пригодится выполнение пользовательского кода.
NutsUnderline
05.01.2024 08:10+2Скорее вопрос устоявшейся терминологии. Стариковским голосом: сходите к спектрумистам, они четко скажут что у них испокон времен были страницы (page) памяти, а никак не сегменты. Именно для "для адресации большего объёма памяти, чем позволяет шина". Помниться вроде и в случае 8051 там были даже не страницы а банки, для того же ограничения. Я не вижу большой проблемы называть это и сегментом памяти, но термин сегмент дейcтвительно фигурирует в случае 8086, может где то еще. Точно так же можно MMU называть например "регистр страниц", особенно когда он никакой виртуализации адресов не осущетвляет.
Про одновременность тоже все относительно. Реальная одновременность - на нескольких ядрах, и то они делят между собой общие шины, скажем к памяти. иначе идет тот или иной скачек по задачам, с разделением по времени. тот же шедулер, причем на неспешных процах даже сохранять все-все на стек - заметный оверхет, достаточно прерываний с сохранением только нужных регистров.
И заметте, никаких вумных компиляторов. Все на голом асме, а то и в машинном коде, и с точностью до такта процессора.

CrashLogger
05.01.2024 08:10+1На Спектруме действительно страницы, потому что они физически переключаются в адресном пространстве при записи в соответствующий регистр. И пока подключена одна страница, остальные недоступны. А в 8086 вся память доступна постоянно. Сегменты - это способ обратиться к любому адресу в пределах мегабайта, имея только 16-битные регистры.

Ivanii
05.01.2024 08:10+3По моему в голосовалке не хватает "Использовал сторонний интерпретатор(PDP-11, 68000, Z80, ARM, STM32, AVR и т.д.)"
bodyawm Автор
05.01.2024 08:10+2Ну это самое странное как по мне решение. Бесспорно интересное, но я бы предпочел собрать на базе МК обвязку для реального Z80
NutsUnderline
05.01.2024 08:10ну это как то слишком обще. про такое я бы тоже хотел подробнее почитать для какой примерно задачи, на каком хосте и что эмулировалось.
я например, мечтал сделать какой-нить байткод на том же avr для целей security но реальной задачи так и не вышло.

Alyoshka1976
05.01.2024 08:10+2Это весьма популярная тема у любителей ретроархитектур. Из личного опыта ATmega328+STM8+FRAM оказываются самодостаточным i8080 компьютером с клавиатурой и выводом на телевизор, работающим под управлением CP/M (неспешно, конечно, но консоль вполне отзывчива).

iShrimp
05.01.2024 08:10+3Интересная идея! Использование относительной адресации позволяет удобно запускать код, созданный на самом устройстве. Это не только про микрокомпьютеры (игрушки для гиков), но также и про контроллеры умного дома, различные умные датчики, реле, сигнализации и т.д. Пока что самая популярная из подобных платформ - MicroPython - использует виртуальную машину.
Выше уже упомянули Флиппер - мультитул для хакеров, но можно развить идею и сделать мультитул для электронщиков, физиков, математиков и т.д. в форм-факторе инженерного программируемого калькулятора. Типа OpenRPNCalc, или NumWorks, или Электроника МК-161, но с GPIO, анализатором/генератором сигналов, осциллографом, встроенными и пользовательскими математическими функциями.
Интересно, какие сейчас доступны МК c double-precision FPU и хорошей документацией, взамен STM32F7/H7.



Hamletghost
05.01.2024 08:10+1Обратите внимание, что Start вызывает подфункции с помощью инструкции CALLX8, которая в отличии от обычного Immediate-версии CALL8
Строго наоборот: call8 это Immediate pc relative call
Callx8 - indirect call по адресу в регистре
И в вашем листинге это так и есть: start вызывает функции используя call8 относительно счетчика инструкций, а вот «сисколы» везде вызываются через callx8, его адрес вы везде продергиваете через стек (а изначально его передает в start загрузчик и это абсолютный адрес)

aamonster
05.01.2024 08:10+1Всё ждал, где же в статье будет про специфику загрузки на гарвардской архитектуре, думал, может, какой-то хитрый хак. И тут раз – и лёгким движением рук (MMU) гарвардская архитектура превращается в фон неймановскую (точнее, реальная архитектура вообще не важна [код не видит, какие шины есть], а с софтовой точки зрения – никаких отличий от фон неймановской).
bodyawm Автор
05.01.2024 08:10Это я на ESP32 эксплуатировал наличие MMU. А на AVR я бы просто использовал команду SPM - я ведь не просто так написал, что такой способ подходит только для самопрограммируемых МК.
aamonster
05.01.2024 08:10+3Логично. Но я, собственно, к тому, что упоминание гарвардской архитектуры в заголовке не имеет отношения к тому, что описано в статье. С тем же успехом вы могли написать "на микроконтроллерах, которые я купил в таком-то магазине" – вроде и правда, но отношения к делу не имеет.
NutsUnderline
05.01.2024 08:10+1в соседней теме разговор перешел на близкую тему: патчинг бинарного кода обычной флешки (контроллер 8051 совместимый) с целю интеграции в нее своего выполняемого кода
Catmengi
05.01.2024 08:10Я конечно не претендую на правильность своего мнения, так как для этого подхода и компилятор бы пришлось бы изменить. Но можно было использовать программную сегментацию, просто храня в каком-то регистре адрес сегментов а уже там где нибудь в заголовке храня адреса под сегментов, как по мне можно было бы использовать код который не будет зависеть от GOT но и сегменты выпиливать не пришлось бы, пришлось бы сильно патчить компилятор

jcmvbkbc
05.01.2024 08:10+1Давайте для общего понимания вкратце разберемся, как происходит загрузка программ в Windows/Linux:
Система создаёт процесс и загружает в память программы секции из ELF/PE. Обычные программы для своей работы используют 3 секции: .text (код), .data (не-инициализированный сегмент памяти для глобальных переменных), .bss (сегмент памяти для инициализированных переменных).
На картинке перед этим абзацем видны program header и сегменты и section header и секции. Program header -- это то, как выглядит ELF-файл с точки зрения загрузчика. Section header -- это то, как выглядит ELF-файл с точки зрения линковщика. Загрузчик оперирует сегментами -- непрерывными областями памяти с одинаковым доступом к ним. Сегмент может содержать одну или больше секций, но загрузчику до этого нет дела.
т. н. динамический линкер, который уже на этапе загрузки программы или библиотеки патчит программу так, чтобы её можно было загрузить в любой участок памяти.
Некоторые программы не рассчитаны на загрузку в произвольный участок памяти, потому что это position-dependent executable. (Т.е. они могут при этом работать, и это, кстати, ваш случай, но только лишь в силу удачного стечения обстоятельств). Некоторые программы содержат код релокации в себе и не зависят от динамического линковщика, например static position-independent executable. (Я об этом писал подробнее здесь, в разделе "форматы исполняемых файлов").
bodyawm Автор
05.01.2024 08:10Ну камон, это же просто иллюстрация из вики :)
А почему uclinux не глянули? У него футпринт ниже + формат бинарников как раз заточен под загрузку в системы без MMU (у ESP32 есть MMU, но мы с вами знаем какой :)).
jcmvbkbc
05.01.2024 08:10Ну камон, это же просто иллюстрация из вики :)
Так я говорю не об иллюстрации, она как раз ок. Я говорю, что текст под ней -- не очень соответствует действительности.
А почему uclinux не глянули? У него футпринт ниже + формат бинарников как раз заточен под загрузку в системы без MMU
nommu ядро я как раз использовал, потому что других вариантов просто нет. А почему bFLT мне не подошёл в той же статье написано (TL;DR: формат неудобный, с сильными встроенными ограничениями, выгоды от его использования нет). Вместо этого я добавил в тулчейн поддержку FDPIC и получил выполнение кода откуда угодно (в т.ч. из флэша прямо из образа файловой системы) и работающую динамическую линковку.
bodyawm Автор
Вот такой вот достаточно узконаправленный материал сегодня получился. Не претендую, что материал станет достаточно успешным, но полагаю кому-то всё же будет интересно. С другой стороны, меня просто удивляют некоторые проекты компьютеров из МК: люди реально пишут эмуляторы иных архитектур, вместо того чтобы использовать возможности целевого МК на максимум!
Собственно, почему бы и не поделится своим видением!?
bodyawm Автор
В следующей статье вас ждёт легенда своих лет: Nokia N-Gage QD, с ремонтом и рассказом о типовых болячках смартфонов Nokia тех лет, ковырянии в Symbian SDK и попытках написать игру под эту платформу. Мы рассмотрим некоторые особенности Symbian и попробуем разобраться, почему эта система проиграла войну с Android и iOS!
И хардварно оживил, и софтварно обогатил :)