Вступление
Привет, Хабр! С вами Владимир Исабеков, руководитель группы статического тестирования безопасности приложений в Swordfish Security. В прошлых статьях, посвященных фаззингу REST API, мы рассказывали о методе Stateful REST API Fuzzing и настройках инструмента RESTler. Сегодня мы поговорим о режимах тестирования, аннотациях, проблемах при подготовке и проведении фаззинга API и способах их решения. Статья написана в соавторстве с инженером по безопасности Артемом Мурадяном @TOKYOBOY0701.

Режимы фаззинга
Прежде всего необходимо понять, как RESTler формирует цепочки запросов. Для создания последовательностей фаззер может использовать различные стратегии. Давайте рассмотрим подробно каждую из них.
BFS
Первая стратегия – BFS (обход в ширину). Основной алгоритм, который используется в этом режиме, выглядит так:

Последовательность запросов увеличивается на каждой итерации, когда в конец цепочки добавляются реквесты с удовлетворенными зависимостями. Иногда соблюдены не все параметры для отправки запроса, в этом случае нужно сначала создать методом POST какой-нибудь объект, а уже потом его запрашивать.
Для каждого добавленного реквеста происходит конкретизация параметра, если его тип в грамматике указан как restler_fuzzable. Комбинации таких критериев формируются согласно указанным значениям в словаре для фаззинга. Далее выполняется цепочка запросов и проверяется ответ сервера: если он имеет действительный код состояния, то новая последовательность сохраняется. В противном случае она отбраковывается, а полученный код ошибки регистрируется для анализа и отладки.
Создаваемые динамические объекты в ходе выполнения цепочек запросов сохраняются и при необходимости используются в последующих реквестах. По умолчанию для каждого запроса с несколькими restler_fuzzable типами генерируются все возможные комбинации значений, поэтому в больших словарях может быть астрономическое количество сочетаний.
Еще раз посмотрим на картинку выше: в функции EXTEND для реквестов с удовлетворенными потребностями формируются все допустимые комбинации цепочек запросов длины n+1. Так как эта функция вызывается при каждой итерации основного цикла (8 строка), то алгоритм комбинирует все последовательности запросов – это и есть обход в ширину.
BFS-Fast
При использовании BFS-Fast в функции EXTEND каждый запрос добавляется к не более чем одной последовательности. В результате мы получаем меньший набор newSeqSet, который охватывает (т. е. включает хотя бы один раз) каждый реквест, но не генерирует все допустимые последовательности запросов.
Вернемся к алгоритму на картинке и увидим, что BFS-Fast, как и BFS, проверяет каждый restler_fuzzable тип исполняемого запроса на всех итерациях основного цикла в строке 8. Этот режим по-прежнему обеспечивает полный охват грамматики, но с меньшим количеством последовательностей запросов, что позволяет ему быстрее увеличивать длину цепочек, чем при обходе в ширину (BFS).
RandomWalk
В стратегии RandomWalk в EXTEND два цикла строк 16 и 17 исключаются. Вместо этого функция возвращает новую последовательность, которая состоит из запросов с нужными параметрами и генерируется путем случайного выбора одной цепочки реквестов seq в seqSet и запроса в reqSet. Функция случайным образом выбирает такую пару до тех пор, пока не будут удовлетворены все ее зависимости. Таким образом эта стратегия будет исследовать пространство поиска возможных последовательностей запросов глубже и быстрее, чем BFS или BFS-Fast.
Когда RandomWalk не может расширить цепочку запросов дальше, он начинает с пустой последовательности. Отметим, что RandomWalk не сохраняет в памяти прошлые цепочки между перезапусками и в будущем может генерировать их повторно.
Однозначного ответа на вопрос, какой же из 3 режимов выбрать, нет. Различные стратегии поиска вполне могут дополнять друг друга. При запуске фаззера по умолчанию используется режим BFS. Но можно указать стратегию в консоли с помощью параметра
--search_strategy [bfs-fast(default), bfs,bfs-cheap,random-walk]
или в конфигурационном файле Engine_settings (при последующем запуске фаззера путь к файлу указывается в параметре --settings):
“fuzzing_mode”: “bfs”;
Аннотации
На рынке есть много инструментов, которые могут получать на вход спецификацию и отправлять запросы. У вас мог возникнуть вопрос: чем же RESTler лучше других фаззеров?
Ответ простой: RESTler позволяет нам предоставлять аннотации с информацией о зависимостях между запросами производитель-потребитель. Это полезно, когда фаззер не может автоматически вывести зависимости из-за отсутствия "линковки". Для того чтобы добавить такую связь, нужно на этапе компиляция RESTler внести аннотацию следующим способом:

В формате json указываем:
producer_endpoint: «путь» функции, которая «производит» значение для потребляющей функции;
producer_method: HTTP метод производящей функции;
producer_resource_name: имя созданного значения. Может быть в теле ответа, заголовке ответа или пути запроса;
consumer_param: имя параметра в запросе потребителя;
consumer_endpoint: путь функции пользователя;
consumer_method: HTTP метод функции потребителя;
except: список функций, которые не являются потребителями;
description: описание.
После компиляции спецификации получаем следующую грамматику:

Как мы видим, RESTler сохраняет ID созданных проектов для последующих запросов.
На рисунке ниже можем наблюдать, что в нужное поле записывается сохраненный до этого ID команды:

Эта возможность выделяет RESTler среди конкурентов, поскольку позволяет:
повысить покрытие исходного кода;
избежать большого количества отклоненных запросов;
построить более эффективные последовательности реквестов;
упростить фаззеру построение цепочек запросов;
решить проблему пустого приложения.
Проблемы при подготовке к фаззингу и способы их решения
Создание или перенастройка спецификации с использованием парсеров может привести к массе ошибок, так как работают они достаточно посредственно. Рассмотрим несколько проблем, которые могут возникнуть при подготовке к фаззинг-тестированию, и расскажем, как их можно решить.
Подготовка cхемы
В примере ниже можно увидеть, что изначально в адресе присутствует заданное имя пользователя. Компилируя такой пример, RESTler будет отправлять все запросы именно на адрес /rest/user/username , так как в параметрах функции нет описания, что это inpath параметр и его можно менять.

Результат после исправления вручную:

После этих операций мы можем проверить полученную грамматику и убедиться, что теперь имя пользователя будет фаззиться корректно:
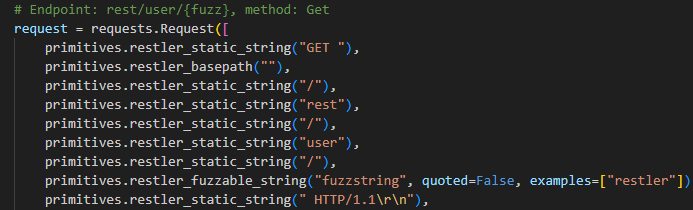
Отсутствие типизации
Часто в спецификации не указывается тип данных, которые можно передавать в конкретном параметре. Конечно, RESTler будет пытаться сам изменять этот критерий для тестирования валидаторов. Однако во время длительного тестирования мы будем отправлять большое количество ложных запросов, что плохо влияет на эффективность тестирования.
Заранее подготовленное веб-приложение
Нам необходимо иметь ненулевое приложение. Данная проблема усложняет этап тестирования, когда мы хотим определить, какие ручки вообще могут работать с RESTler. Например, есть интерфейс, который возвращает информацию о пользователе, а самого юзера нет. В этом случае мы будем получать ошибку 4хх на каждый запрос и не сможем понять, можно ли тестировать вообще эту функцию. Даже если мы создадим пользователя вручную, при повторном запуске RESTlertest мы получим ответ (с помощью другого интерфейса), что «такой пользователь уже существует».
Для решения этой проблемы необходимо создать спецификацию с такими интерфейсами отдельно и перед этим запускать RESTlertest, который будет выполнять своего рода модульные тесты, тем самым создавая нужные данные в БД. Также нужно добавить интерфейсы удаления этих данных, чтобы вернуть приложение в исходное состояние. С этой задачей частично справляются аннотации.
Парсинг спецификации
В большинстве случаев при отправке каких либо данных мы используем формат JSON, что несет некоторые трудности при проведении фаззинга. Допустим, у нас есть интерфейс создания пользователя /user/create/. Так выглядит json, который мы отправляем:
{
"login":"admin",
"password":"admin",
"info":{"age":"99","city":"Moscow","sex":"male"}
}
Теперь посмотрим на него в спецификации:
/v2/user/create:
post:
tags:
- General
summary: api/v2/users/
requestBody:
content:
application/json:
schema:
type: object
parameters:
- in: body
name: login
example: 'admin'
name: password
example: 'admin'
name : info
age: 99
city: 'Moscow'
sex: male
При компиляции спецификации RESTler не поймет, что он получил на вход структуру. Из-за этого мы получим следующую грамматику:

То есть, при каждой мутации будет изменяться сам JSON, а не его переменные. Это значит, что все запросы будут отвергнуты на этапе проверки валидности тела самого JSON и покрытие в таком случае будет минимальным.
А вот как должна выглядеть правильная спецификация:
/v2/user/create:
post:
tags:
- General
summary: "Create a new user"
requestBody:
required: true
content:
application/json:
schema:
type: object
properties:
login:
type: string
example: "admin"
password:
type: string
example: "admin"
info:
type: object
properties:
age:
type: integer
example: 99
city:
type: string
example: "Moscow"
sex:
type: string
example: "male"
Здесь при компиляции мы получаем разобранный JSON, в котором будет мутировать только значение параметров, а сама структура сохранит целостность:

Как видно, тело отправляемых данных делится на restler_static и restler_fuzzable. По названию можно догадаться, в чем отличие между этими типами. Таким образом мы можем создавать очень сложные структуры и корректно их мутировать. Данный подход поможет RESTler определить параметры и в процессе фаззинга автоматически удалять некоторые из них или добавлять свои.
В примере на картинке выше мы будем проводить грамматический фаззинг на уровне самого JSON. Это позволит отбросить большое количество неверных запросов и увеличить покрытие. Кроме валидаторов формата будут задействованы функции-обработчики, что будет положительно влиять на качество тестирования.
Конверторы
Проблема конверторов состоит в том, что их подавляющее большинство просто не работает. И перед их использованием приходится маскировать информацию в спецификации.
Проблемы при проведении фаззинга и способы их решения
Рассмотренные выше проблемы в большей части относились к подготовительному этапу, то есть затрагивали саму спецификацию, а не процесс фаззинга.
Во всех приложениях по-разному реализованы статусы ответов. К примеру, 200 может содержать LogTrace в ответе. Иногда мы получаем токен авторизации, но при этом статус 4**. В таких случаях стоит изначально проанализировать само приложение, учитывая особенности на всех этапах тестирования. RESTler позволяет вручную указать, какие ответы могут потенциально содержать ошибки, а также дает возможность с ними поработать. Сделать это можно с помощью параметра custom_bug_codes:
{
"custom_bug_codes":["201","203"]
}
Разбиение спецификации
Для оптимизации работы рестлера рекомендуется разбивать API схему на подмножества, учитывая функционал самих интерфейсов. На примере user-rest:
GET:/user/login – получение информации о пользователе с использованием логина;
PUT:/user/login – изменение информации о пользователе;
GET:/user – получение списка всех юзеров с учетом фильтров;
POST:/user – создание пользователя;
POST:/user/status – изменение статуса;
POST:/user/password - изменение пароля.
Такая разбивка позволит решить следующие проблемы:
большое количество ложных запросов в запуске;
создание некачественных цепочек запросов (объединение в цепочки абсолютно разных по функционалу запросов);
низкая производительность.
Файлы в ответе
Довольно часто можно встретить проблемы в файлах, которые нам отправляет сервер. Например, когда мы тестируем интерфейс создания отчета по фильтрам, в ответ он может отправить PDF-файл неправильного размера, с некорректным содержимым или временем подачи.
Еще одной проблемой может стать кодировка данных. К примеру, RESTler будет завершаться с ошибкой при попытке декодирования каких-либо данных, полученных от сервера:

RESTler решает данную проблему путем пропуска ошибок декодирования. Сделать это можно с помощью параметра "ignore_decoding_failures": True. Для запросов такого рода также рекомендуется увеличить время ответа.
Заключение
Итак, мы описали этапы и нюансы тестирования, рассмотрели, какие уязвимости помогает обнаружить RESTler, какие проблемы возникают при подготовке и проведении фаззинга и как их можно решить.
В результате нашего исследования по API fuzzing мы смело можем сделать вывод, что RESTler – это первый автоматический инструмент для анализа состояния облачных сервисов через их REST API, позволяющий максимально точно настраивать процесс тестирования. Благодаря этому фаззер можно использовать для многих целей:
Фаззинг на основе грамматики. Позволяет построить структуру запроса с добавлением динамических и статических частей, а также динамически генерируемых значений, например токенов;
Генерация тестов на основе обратной связи. Дает возможность сохранять информацию об объекте, который был создан/изменен/удален/перенесен для использования в последующих запросах;
Фаззинг белого ящика. С помощью анализа исходного текста программы помогает более точно настроить грамматику, генератор входных значений и словарь;
Тестирование на проникновение. Фаззер находит уязвимости API, анализируя найденные ошибки, а также дает возможность использовать собственные словари, где могут находиться заранее подготовленные нагрузки для проведения автоматического пентеста;
Модульные тесты. RESTler позволяет начать фаззинг в режиме TEST, по сути, запуская своего рода модульный тест с применением только спецификации;
Нагрузочное тестирование. Учитывая то, что фаззинг подразумевает огромное количество запросов, инструмент можно использовать для генерации высокого трафика со случайными значениями и наблюдать за тестируемым приложениям с точки зрения производительности, заранее настроив время генерации запросов, число параллельных реквестов и время ожидания.
Всё перечисленное выделяет RESTler на фоне конкурентов. Инструмент открывает широкий спектр возможностей для повышения безопасности API приложений.