Этот материал будет полезен для COO, бизнес-аналитиков и топ-менеджеров компаний. Хотя в тексте присутствуют некоторые технические детали, они не будут слишком обременительными. Цель материала: показать общую логику, которую мы использовали для извлечения и анализа данных.
Контекст
Компания Фикус, один из лидеров Российского рынка по озеленению корпоративных и общественных пространств. Уже год мы с ними внедряем ИИ-решения по всему контуру бизнеса: от саппорт-службы для потенциальных заказчиков до разработки персональных ассистентов сотрудникам.
Осенью 2023 года в компании произошли значимые организационные изменения в одном из ключевых подразделений. Руководитель отдела ушел, и команда воспользовалась этим моментом для устранения проблемных мест в рабочих процессах. До этого момента в функционировании отдела наблюдалась определенная неясность и несогласованность, которые требовали исправления. Генеральный директор предложил извлечь и проанализировать данные из корпоративных информационных систем, чтобы выявить реальную схему управления и взаимодействия внутри команды, которая отличалась от официально утвержденных бизнес-процессов.
Решение
Компания активно использует систему управления Kaiten, где за несколько лет накопилось большое количество информации, включая дискуссии, комментарии и обсуждение проектов. Эти данные легли в основу нашей работы.
Извлечение и связывание данных
Честно говоря, мы оказались в выгодном положении по нескольким причинам:
а) Компания последовательно применяет сквозные методологии управления проектами и канбан. Сквозное управление вовлекает участников практически всех отделов на разных этапах и позволяет системно накапливать информацию. До 2022 года "Фикус" работал в Trello, а затем перешел на Kaiten.
б) Кайтен предоставляет API и легко выдергивать информацию любую хранимую информацию. Если система управления выстроена хорошо (а в компании она выстроена хорошо) , у нас может быть много полезных данных в одном месте, что существенно ускоряет процесс майнинга.
Первым шагом мы извлекли два JSON-файла:
- JSON со всей информацией по проектам за 2023 год;
- JSON со всеми комментариями за тот же период.
def get_kaiten_cards(token, **params):
url = 'URL'
headers = {
'Accept': 'application/json',
'Content-Type': 'application/json',
'Authorization': f'Bearer {token}'
}
response = requests.get(url, headers=headers, params=params)
if response.status_code == 200:
return response.json()
else:
response.raise_for_status()
def get_all_kaiten_cards_for_period(token, start_date, end_date):
offset = 0
limit = 100
all_cards = []
while True:
response_cards = get_kaiten_cards(token, limit=limit, offset=offset, created_after=start_date,
created_before=end_date)
if not response_cards:
break
all_cards.extend(response_cards)
if len(response_cards) < limit:
break
offset += limit
return all_cards
def save_to_json(data, filename):
with open(filename, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=4)
def load_from_json(filename):
with open(filename, 'r', encoding='utf-8') as f:
return json.load(f)
def get_card_comments(token, card_id):
url = f'.../api/latest/cards/{card_id}/comments'
headers = {
'Accept': 'application/json',
'Content-Type': 'application/json',
'Authorization': f'Bearer {token}'
}
response = requests.get(url, headers=headers)
try:
response.raise_for_status()
return response.json()
except requests.exceptions.HTTPError as e:
print(f"Ошибка при получении комментариев для карточки {card_id}: {e}")
return []
if __name__ == "__main__":
token = 'TOKEN'
start_date = "2023-01-01T00:00:00Z"
end_date = datetime.now().isoformat() + "Z"
cards_filename = "kaiten_cards.json"
comments_filename = "kaiten_comments.json"
all_comments = []
if os.path.exists(cards_filename):
cards = load_from_json(cards_filename)
for card in cards:
card_id = card.get("id")
if card_id:
comments = get_card_comments(token, card_id)
all_comments.extend(comments)
save_to_json(all_comments, comments_filename)
else:
print(f"Файл {cards_filename} не найден.")Далее мы связали все комментарии, которые были оставлены в ИС, с проектами и сотрудниками, которые их оставляли.

Визуализация данных
Уже на этом этапе, когда мы еще не приступили к анализу сообщений, стало любопытно визуализировать связанные данные с помощью Neo4J. Получился такой граф:

Использование настольной базы данных Neo4j ограничивало нас в возможностях визуализации: не удается изменить размер вершин в графах в зависимости от количества отправленных комментариев, что могло бы наглядно показать коммуникационную нагрузку участников. В качестве альтернативы так же использовали Bloom – онлайн инструмент от Neo4j для визуализации данных, однако и он не предоставил достаточной наглядности в представлении данных, хотя по размерам кластеров здесь мы уже могли увидеть кто из сотрудников оставил больше всего комментариев.
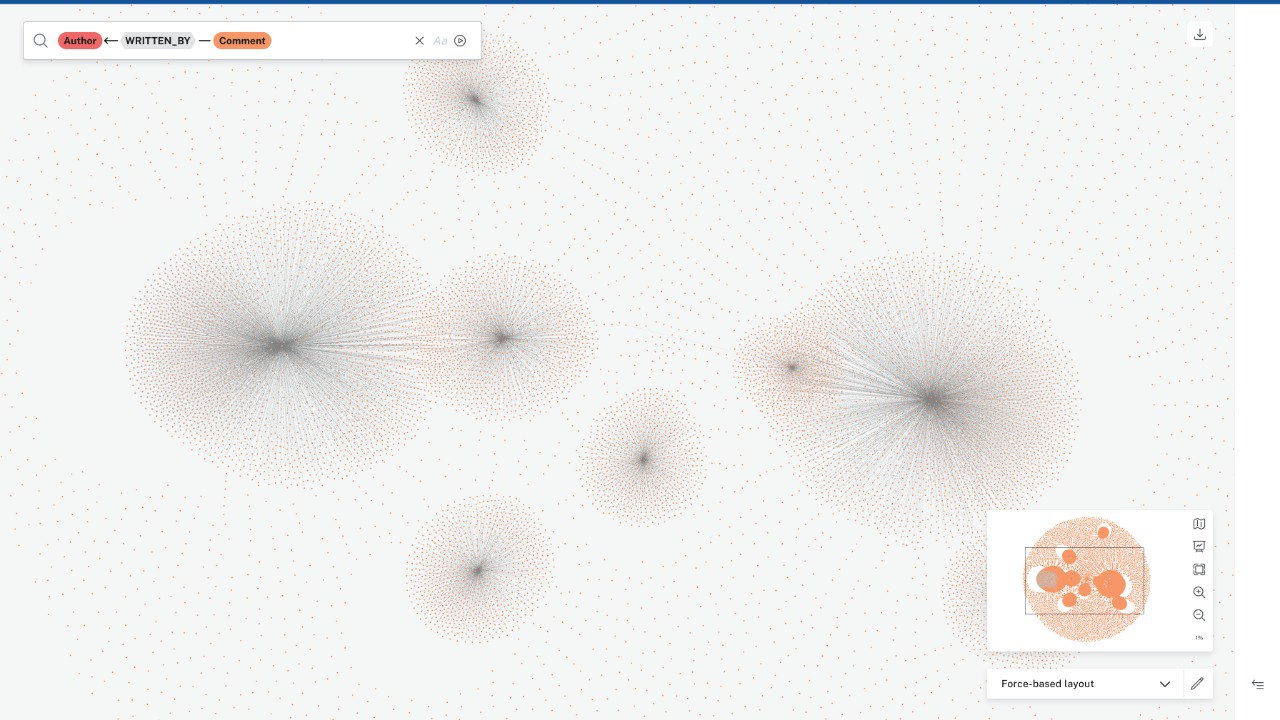
Тем не менее, нас такой формат визуализации не устроил, поэтому я выбрал Plotly – гибкую библиотеку Python, которая отлично подходит для решения моих задач.
В этом случае мы использовали данные об авторах сообщений и упоминаниях сотрудников в комментариях, чтобы создать новый граф. Чем больше упоминаний, тем больше размер вершины в графе. Для балансировки графа мы использовали формулу центральности по степени. Параметр «центральность» помогает оценить важность каждой вершины графа (сотрудника), основываясь на ее позиции в структуре. В результате мы получили следующую визуализацию:

Это уже можно использовать для анализа и позволяет нам определить ключевых участников бизнес-процессов. Интенсивность коммуникаций с некоторыми сотрудниками (определяется диаметром и положением вершин графа) указывает на то, что без их участия задачи не могут быть продвинуты вперед или, наоборот, двигаются только благодаря их участию. Необходимо тщательно проанализировать сообщения и на их основе сформулировать дальнейшие задачи, что и будет сделано в следующем этапе.
Кроме того, существует понятие «информационной нагрузки». Если ключевые сотрудники (с точки зрения замыкания на себя основных бизнес-процессов) перегружены сообщениями, у них остается меньше времени на выполнение основной работы. Наша задача – минимизировать эту нагрузку. Как – предмет внутренних обсуждений, в этой статье касаться этого не будем.
Майнинг бизнес-процессов с помощью LLM
Теперь давайте перейдем к следующему этапу. Нам необходимо определить, какие бизнес-процессы действительно функционируют в компании. Важно также узнать, какие ожидания у коллег при взаимодействии, какие проблемы решаются в процессе, и какие компоненты включает каждый процесс. Для этого мы использовали модель генеративного ИИ из семейства GPT (gpt-3.5-turbo), которая проанализировала сообщения в информационной системе. Получилась такая таблица:
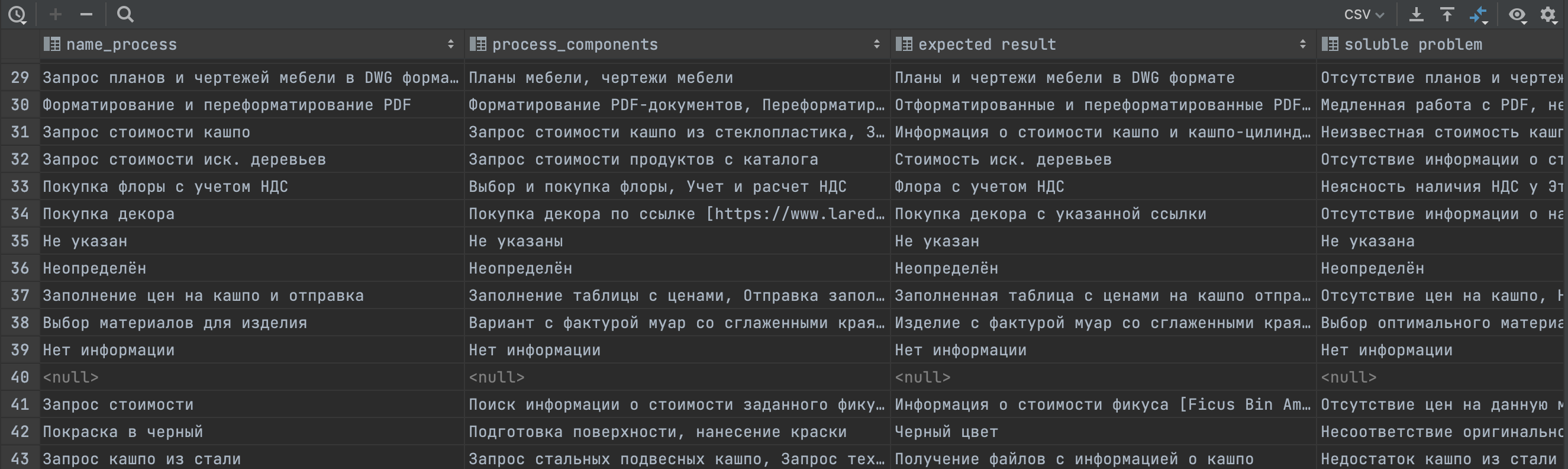
После обработки всех сообщений с помощью LLM, мы провели очистку данных, удалив пустые строки и дублирующиеся значения. Затем мы выделили авторов сообщений и всех, кто был упомянут в сообщениях и снова создали граф, в котором к вершинам (сотрудникам) были привязаны упоминаемые в сообщениях процессы.
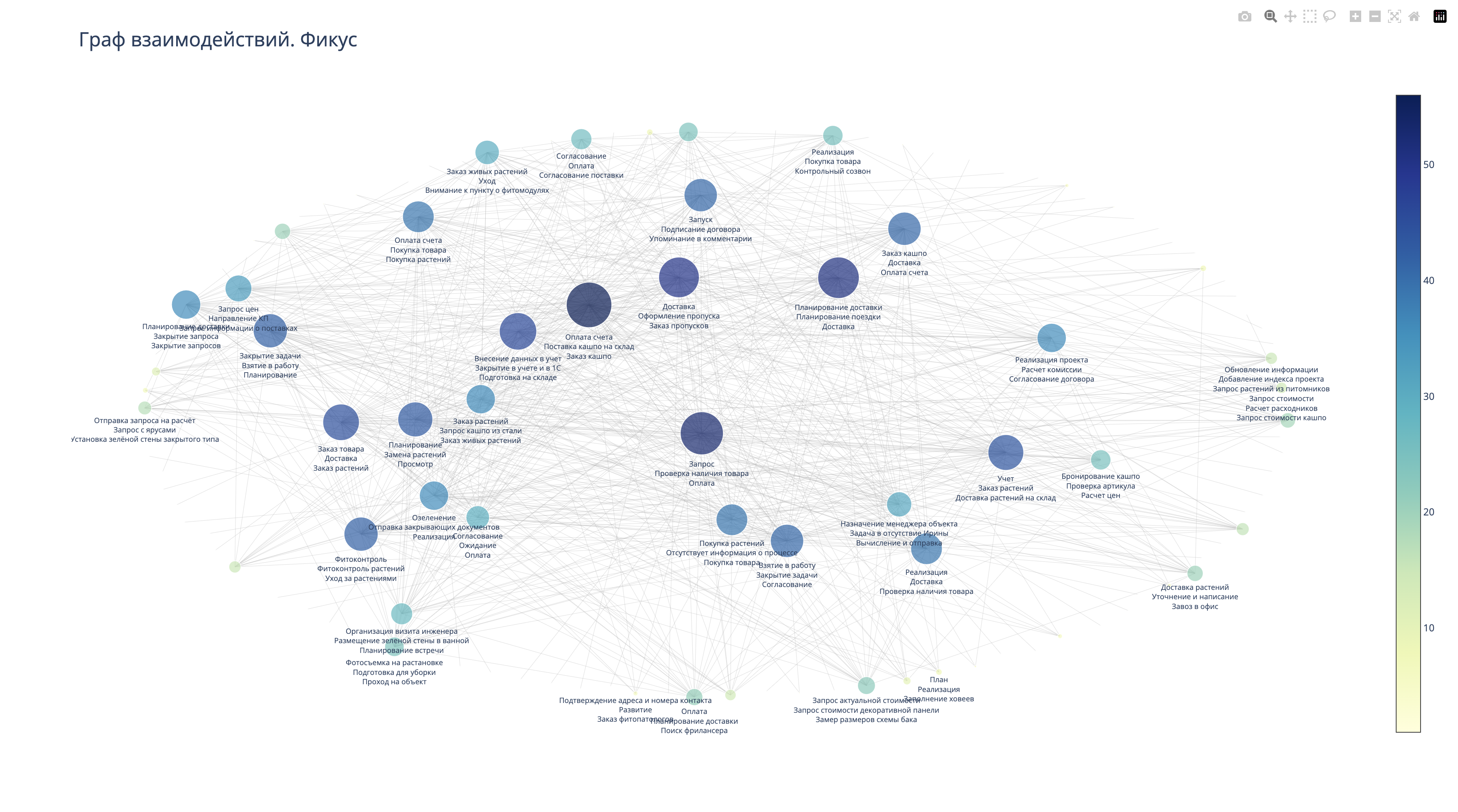
В результате, как и требовалось, мы получили социальный граф бизнес-процессов "Как есть". Далее вместо упоминания процессов, мы можем ожидания от выполненной работы, решаемые проблемы, компоненты процесса и другие намайненные с помощью LLM данные. Например так:

Таким образом, на основе собранной нами информации и визуализации, мы можем принимать те или иные управленческие решения, которые будут опираться на реальное положение дел в компании.
Заключение
Это не предел использования данных. Мы могли бы так же проследить появление бизнес-процессов в течение времени, посмотреть задержки (сколько занимает по времени тот или иной процесс на основе разницы между полученным комментарием и откликом) и много чего еще. Но это предмет для другой статьи.
Спасибо, что дочитали до конца.
Комментарии (13)

s_w_n
21.04.2024 06:45Если в качестве массива данных копроративную электронную почту загрузить?

Kirill_Kazakov Автор
21.04.2024 06:45Да. Но нужно вычленить получателей / отправителей, чтобы связать данные.

tempart
21.04.2024 06:45Пытаюсь понять практическое применение.
Можете привести любой реальный или потенциально исполняемый кейс улучшения бизнес-процессов на основании результатов этой работы?Kirill_Kazakov Автор
21.04.2024 06:45Я постараюсь ответить на ваш вопрос, но не уверен, что это именно то, что вы ожидаете. И заранее прошу прощения, если выйдет занудно. Компания, о которой в материале идет речь, занимается проектным бизнесом. Основной процесс один – реализация проекта. Он начинается со входящего запроса, завершается закрытием проекта в системе учета. Проект может быть реализован очень быстро, а может быть очень сложным и комплексным – тогда его движение может занимать несколько лет. На каждом этапе у нас есть набор поддерживающих бизнес-процессов. Но компания не использует BPMN, а сторонник гибких методологий, например адаптивного кейс-менеджмента, где каждый проект – это кейс, этапы – постоянные константы процесса, а конкретные задачи на этапах – переменные. То есть, в компании поддерживающие процессы называют просто "задачами".
На разных этапах подключаются разные "круги" (опять же, нестандартная история, в компании нет отделов). Итого, по мере движения проекта от первого до последнего этапа, сотрудники ведут коммуникации по проекту в Кайтен. Например, на 1 этапе мы больше обсуждаем презентацию проекта, а в середине обсуждаем сроки поставок. Если взять все коммуникации по всем сотрудникам, соединить получателей и отправителей – получится карта процесса ведения проектов As is. Понимаю, что это не линкуется с BPMN или другими методологиями, но в нестандартной системе нестандартные подходы :))
После того как мы визуализировали данные с помощью Plotly, у нас появились данные об информационной нагрузке на каждого сотрудника (определяется диаметром вершины графа), а с помощью формулы центральности по степени мы уточнили веса сотрудников в системе.
В нашем случае это дало наглядное понимание кто из сотрудников является "узким местом" c точки зрения информационной нагрузки. Но информационная нагрузка = нагрузка на процесс. Представьте, что у нас есть поток, который прерывается, пока мы не решим определенную задачу. Чтобы её решить, отправляется запрос к сотруднику, который должен её выполнить. После выполнения поток продолжает движение. По диаметру вершины графа и по положению в системе графа можно определить, на кого оказывается наибольшее информационное давление и именно эти же люди выполняют ключевые задачи в общем потоке. Далее мы можем сделать практические выводы: 1. Снизить нагрузку на сотрудника, путем: а) автоматизировать определенные задачи; б)перераспределить обязанности.
Еще одно конкретное практическое применение: в статье я писал про руководителя, который ушел из компании (он руководил кругом обеспечения и закупок). Из сообщений, которые мы спарсили, мы определили какие задачи он замыкал. Чтобы работа не "встала", часть задач по такой же логике, как я описал выше, была автоматизирована, часть мы перераспределили по сотрудникам.
tempart
21.04.2024 06:45Кирилл, прошу меня простить, но то, что я прочитал и понял - это кошмар и ужас. Ваша компания по своему принципу работы напоминает секту. Переназвать устоявшиеся термины, смешать в кучу и назвать это "гибкими методологиями" - вот что получилось.
Бизнес не просто так пытается выстраивать бизнес-процессы. У вас же всё подменено даже не ролями, а конкретными личностями. Представляю, какие в этой каше дикие перегрузки испытывают сотрудники.Нет желания дальше раскрывать сказанное - это очень долго. Для начала: BPMN - это не методология, это нотация. Если в вашей компании не понимают разницы, то дальше просто нет смысла в диалоге
Если что, есть методологии поиска узких мест. Но ими можно пользоваться, если есть понимание бизнес-процессов. И там анализируются разные составляющие бизнес-процессов. Количество коммуникаций между людьми - лишь один из них
Kirill_Kazakov Автор
21.04.2024 06:45Не сочтите за спор. Но у меня есть представление о том, что такое бизнес-процессы, 4 года преподавал в ВШЭ по этой теме. И да, я ошибся, назвав BPMN методологией, а не нотацией, что вышло случайно. Пардон. Если я правильно понимаю, вы занимаетесь проектированием и анализом бизнес-процессов именно с помощью неё. У меня был опыт и проектирования и анализа, например, с помощью Comundа. Но, опять же, я не являюсь сторонником отдельных методов, нотаций или чего либо еще. Есть задача, есть способы их решения. Здесь был предложен один из. Кстати, может быть не вам, но другим читателям будет интересно изучить труды Anna Grandori https://openlibrary.org/authors/OL1071918A/Anna_Grandori – здесь очень полезно про структуру организаций и бизнес-процессы именно с точки зрения сетей взаимодействия.
Kirill_Kazakov Автор
21.04.2024 06:45И, кстати, насчет секты – я бы не был столько категоричным. Например, мы можем взять банк "Точка" или "ВкусВилл" – у них похожий подход.

DShorokhov
21.04.2024 06:45Добрый день!
Кирилл, спасибо за интересный кейс майнинга. Подскажите, сколько времени ушло на такой анализ? И сколько бы он мог занять, если бы вы уже знали подходящий вариант визаулизации?
К дискуссии о практическом применении, я бы использовал это как доказательную базу для приоритезации направлений дальнейшего анализа. Также будет полезно сравнить информацию от сотрудников с тем, что показывает граф коммуникаций. Было бы интересно узнать, что было дальше именно в вашем кейсе.
Kirill_Kazakov Автор
21.04.2024 06:45Около 2 недель. 1 неделя у нас ушла на то, чтобы подобраться к данным, найти подходящий способ визуализации. 2 дня ушло на майнинг комментариев с помощью LLM, создание таблиц и остальное время – это визуализация + интерпретация. Я не аналитик, поэтому могу быть не точным в терминологии. По времени, если бы заранее знали подходящий вариант визуализации...тут несколько переменных: количество данных, которые нужно спарсить, структура данных + прогонка через LLM. На 18 000 сообщений, я выше упомянул, ушло +- 2 дня.
в нашем кейсе после проведения анализа мы: 1. Презентовали структуру процессов сотрудникам; 2. Указали кто является узким местом, предложили часть задач автоматизировать, что и было сделано.
На самом деле те данные, которые были получены, использовались процентов на 30. Потому что у нас есть данные по времени движения проектов по этапам, время упоминания сотрудников, время отклика и много чего еще. Можно построить динамическую карту по каждому проекту, чтобы увидеть временные задержки, связать из с процессами, а далее предложить способы оптимизации. Но это лишь пример.
p.s. Есть некоторые данные, которые в кейсе не были опубликованы. Например, последняя иллюстрация показывает "ожидания" к сотрудникам. Но мы так же разобрали проблемы, которые решаются в процессе коммуникаций и компоненты процессов.

Natella-Fruitella
21.04.2024 06:45Кирилл, спасибо за то, что делитесь наработками, публикуя статью.
Мне очень интересно и полезно было почитать про такой способ анализа процессов. Это расширяет кругозор простых бизнес-аналитиков, не знакомых пока с методами выгрузки и анализа инфы из таск-трекеров.
Спасибо огромное за информацию!
Продолжайте ваши изыскания и эксперименты, жду новых статей, подписалась на вас.
Lelant0s
Ощущение, что делалось ради красивой картинки для презентации руководству. Всё то же самое сделал бы аналитик по бизнес-процессам, только в конце еще бы обосновал где и почему "тонко" и главное - что делать. И заняло бы это от силы пару недель, если он один.
Kirill_Kazakov Автор
Спасибо за ваше мнение. Цель материала была не обосновать читателям где тонко, а показать подход к майнингу процессов и их визуализации через социальный граф. Декомпозировать отдельный процесс и разобрать где тонко и что делать – другая задача.