Но вернёмся в Россию 2015 года. Ниже я покажу, как «из подручных средств» (x86 машин и любых «хранилок») сэкономить денег, повысить надёжность и решить ещё ряд типовых для сисадминов среднего и крупного бизнеса задач.
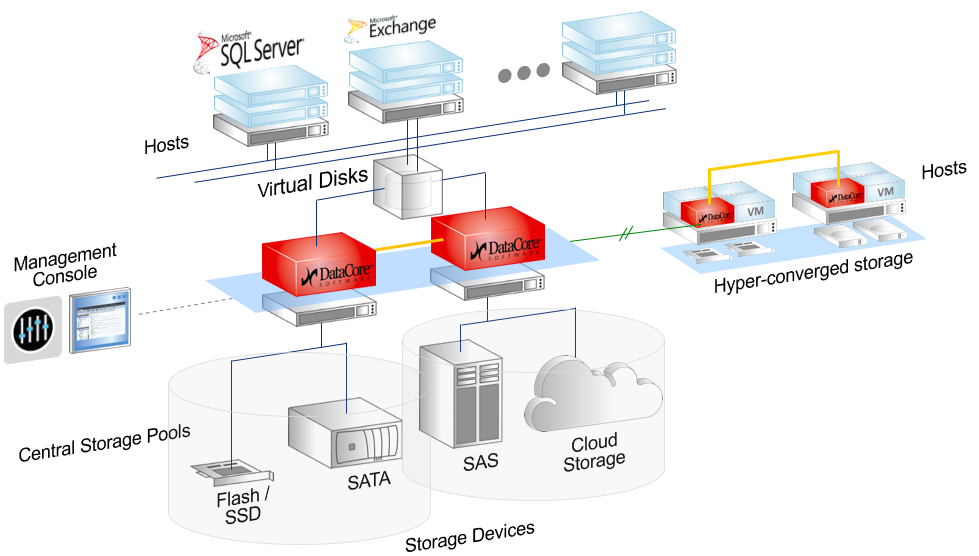
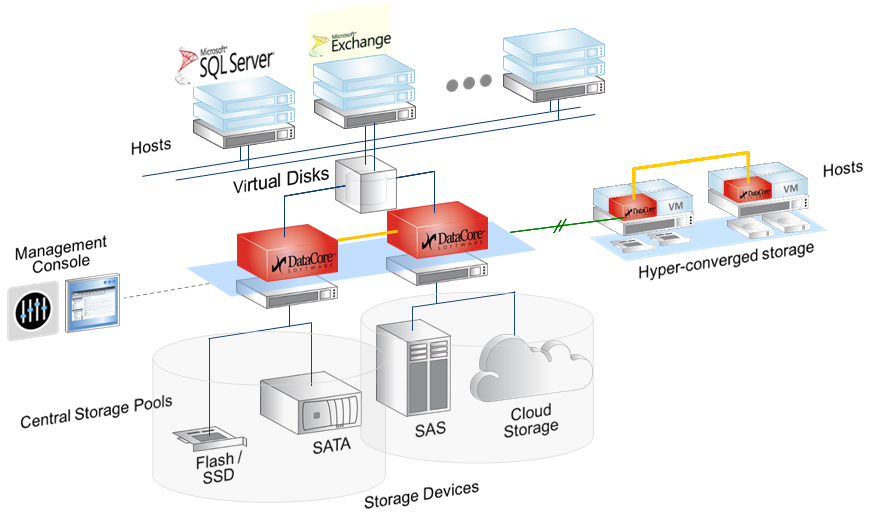
На этой схеме видны обе архитектуры, о которых пойдет речь. SDS — два красных контроллера в центре с любым бекэндом, от внутренних дисков до FC полок и облаков. И виртуальный SAN, на схеме Hyper-converged storage.
Самое главное:
- Вам плевать, что за железо стоит: диски, SSD, зоопарк производителей, старые и новые модели… — всё это отдаётся оркестирующему софту, и он приводит это к той виртуальной архитектуре, которая вам нужна в итоге. Грубо говоря, объединяет в один том или позволяет нарезать как вам удобно.
- Вам плевать, какие интерфейсы у этих систем. SDS построится сверху.
- Вам плевать, какие функции ваши хранилки могли, а какие не могли (опять же, теперь они могут то, что надо: решает софт сверху).
Заодно рассмотрим пару типовых задач с конкретным железом и ценами.
Кому это надо и зачем
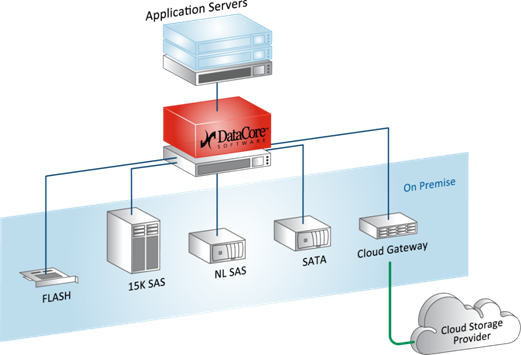
Фактически SDS-софт для хранения данных создаёт управляющий сервер (или кластер), в который подключаются разные типы хранилищ: дисковые полки, диски и оперативная память серверов (в качестве кэша), PCI-SSD, SSD-полки, а также отдельные «шкафы» систем хранения данных разного типа и моделей от разных вендоров и с разными дисками и протоколами подключения.

С этого момента всё это пространство становится общим. Но при этом ПО понимает, что «быстрые» данные надо хранить там-то, а медленные архивные — вообще воооон там. Вы же как сисадмин, грубо говоря, перестаёте думать категориями «RAID-группа на СХД», а начинаете мыслить такими понятиями, как «есть набор данных, надо разместить их в профиле БЫСТРЫЕ». Разумеется, согласившись с мастером или преднастроив, что этот профиль БЫСТРЫЕ находится на таких-то дисках таких-то СХД.
Это же ПО использует RAM серверов (контроллеров виртуальной СХД) в качестве кэша. То есть обычная x86 ОЗУ, до 1TB размером, чз кэш и читает и пишет, плюс есть плюшки типа превентивного чтения, группировки блоков, многопоточности и реально интересная Random Wrire Accelerator (но об этом ниже).
Самые частые применения такие:
- Когда пытливый ум и/или печальный опыт привели к пониманию, что без честной синхронной репликации между СХД не обойтись.
- Банальный дефицит производительности и бюджета одновременно.
- Накопилось много хранилищ. Большой парк, точнее, зоопарк: нет единого стандарта, меняется протокол, и вообще иногда появляется ощущение, что надо всё делать с нуля. Не надо, достаточно виртуализации. Тот же зоопарк, но на стороне хостов (куча разных ОС и два, а то и три разных гипервизора). И желание или чаще необходимость пользовать одновременно iSCSI и FC. Либо при использовании классической СХД — в этом случае также можно использовать множество ОС.
- Хочется использовать старое железо, чтобы не выбрасывать его. Как правило, даже сервера 8-летней давности вполне справляются с ролями нод — скорость оперативной памяти с тех пор поменялась несильно, а большего и не надо, узкое место обычно — сеть.
- У вас много случайной записи или нужно писать во много потоков сразу. Случайная запись превращается в последовательную, если использовать кэш и его фичи. Можно использовать даже старую, совсем старую систему хранения данных в качестве быстрой «файлопомойки» для офиса.
Что такое Software-defined Data Center и как SDS входят в философию SDDC
Разница между программно-определяемыми инфраструктурами и обычными «статическими» примерно такие же, какие случились между старыми добрыми электросхемами на лампах и «новыми» на транзисторах. То есть весьма и весьма существенная, но освоить это поначалу довольно сложно. Нужны новые подходы и новое понимание архитектуры.
Отмечу, что ничего прямо принципиально нового в самой концепции Software-defined нет, и базовые принципы применялись ещё лет 15 минимум назад. Просто называлось это иначе и встречалось далеко не везде.
В этом посте мы обсуждаем SDS (Software Defined Storage), речь только про СХД, дисковые массивы и другие устройства хранения, а также их интерфейсы.
Говорить я буду про технологии на базе софта DataCore. Это далеко не единственный вендор, но он покрывает практически все задачи виртуализации хранилищ данных полностью.
Вот несколько других вендоров, которые решают задачи хранения данных на программно-определяемых архитектурах:
• EMC с их ScaleIO позволяет объединять любое количество x86-серверов с дисковыми полками в единое быстрое хранилище. Вот теория, а вот практика отказоустойчивой системы для отечественных не самых надёжных серверов.
• Отечественная RAIDIX. Вот про них и их грибы.
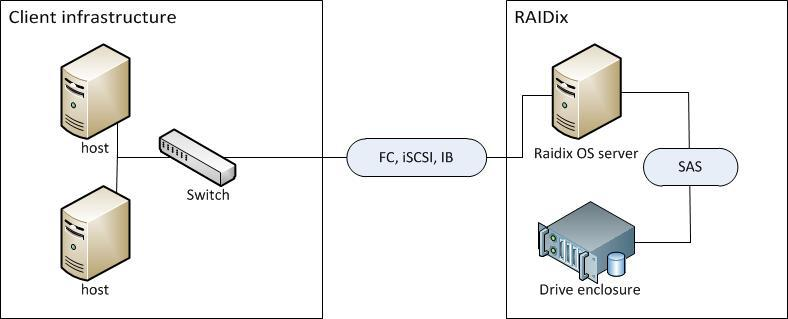
Их архитектура, заменяющая для ряда специфических задач типа видеомонтажа за 10–20 тысяч долларов СХД стоимостью в 80–100 тысяч
• У Riverbed есть крутое решение, с помощью которого мы соединяли все филиалы банка в московской СХД так, то они видели её в своей LAN-сети города и делали квазисинхронную репликацию через кэш.
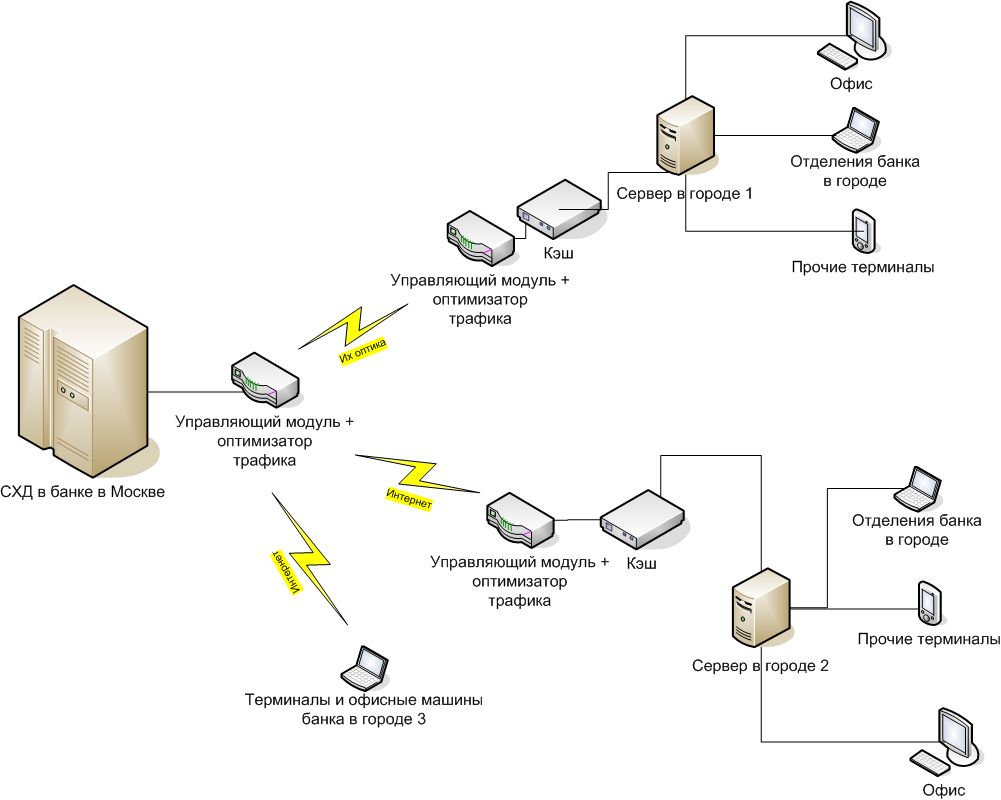
Сервера в городах 1 и 2 адресуются к СХД в Москве как к своим дискам «в корпусе» с LAN-скоростями. При необходимости можно работать напрямую (случай 3, аварийное восстановление офиса), но это уже означает обычные задержки сигнала от города до Москвы и обратно.
• Кроме того, подобные решения есть у Citrix и ряда других вендоров, но, как правило, они более заточены под собственные продукты компании.
• Nutanix решает задачи гиперхранилищ, но часто дороговат, поскольку они делают программно-аппаратный комплекс, и там софт отделяется от железа только на очень-очень больших объёмах.
• RED HAT предлагает продукты CEPH или Gluster, но эти вроде бы на первый взгляд красноглазые парни поддержали санкции.
У меня наибольший опыт именно с DataCore, поэтому прошу заранее простить (и дополнить), если я ненароком обойду чьи-то крутые функции.
Собственно, что надо знать про эту компанию: американцы (но не присоединились к санкциям, поскольку даже не размещались на бирже), на рынке 18 лет, всё это время пилят под руководством всё того же мужика, что и в самом начале, один-единственный продукт — софт для построения СХД — SANsymphony-V, которую я дальше буду называть для краткости SSV. Поскольку их главный — инженер, они угорали по технологиям, но вообще не думали о маркетинге. В результате их как таковых никто не знал до последнего года, а зарабатывали они тем, что встраивали свои технологии в чужие партнёрские решения не под своим брендом.
Про симфонию
SSV — это софтверное хранилище. Со стороны потребителя (хоста) SSV выглядит как обычное СХД, по факту — как диск, воткнутый прямо в сервер. В нашем случае на практике обычно это виртуальный многопортовый диск, две физические копии которого доступны через две разные ноды DataCore.
Отсюда следуют первая базовая функция SSV — синхронная репликация, и большая часть реально используемых LUN'ов DataCore — это отказоустойчивые диски.
Софт может быть размещён на любом x86 сервере (почти), в качестве ресурсов могут быть использованы почти любые блочные устройства: внешние СХД (FC, iSCSI), внутренние диски (включая PCI-SSD), DAS, JBOD, вплоть до подключённых облачных хранилищ. Почти — потому что есть требования к железу.
Виртуальные диски SSV может презентовать любому хосту (исключение ОС IBM i5).
Простое применение (виртуализатор / FC/iSCSI таргет):
И вот поинтереснее:
Сладкая функциональность
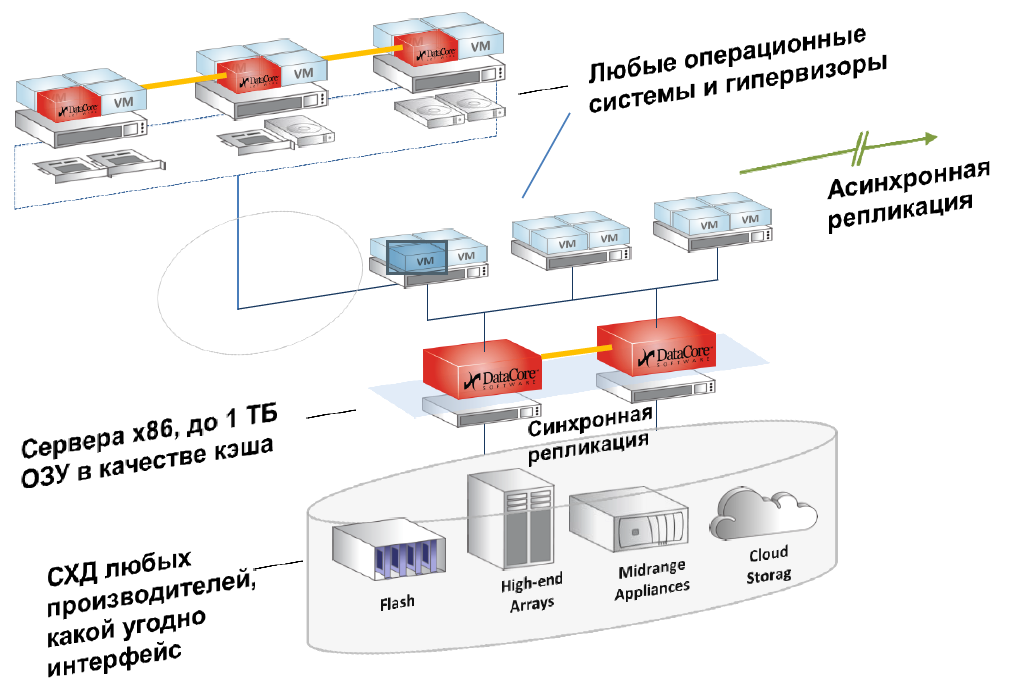
В SSV есть целый набор функций — кэширование, балансировка нагрузки, Auto-Tiering и Random Write Accelerator.
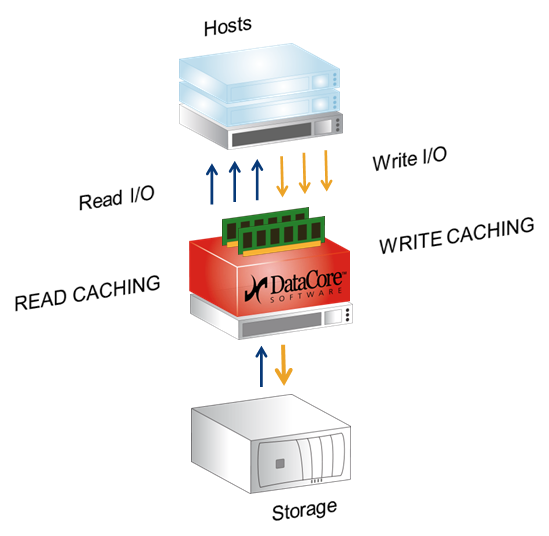
Начнём с кэширования. Кэш тут — это вся свободная оперативная память сервера, на котором установлен DC, работает и на запись и на чтение, максимальный объём 1Tb. Те же ScaleIO и RAIDIX не используют оперативку, зато нагружают диски «своих» серверов или контроллеров. Это обеспечивает более быстрый кэш.
В этой DC-архитектуре ставка сделана на скорость и надёжность. На мой взгляд, для практических задач среднего бизнеса сегодня получается самый быстрый и при этом вполне доступный кэш.
В этом же кэше на базе ОЗУ серверов работает функция оптимизация рандомной записи, например, под OLTP-нагрузку.
Принцип у оптимизатора очень простой: хост закидывает на виртуальный диск случайные блоки данных (например SQL), они попадают в кэш (ОЗУ), который технологически умеет писать рандомные блоки быстро за счёт упорядочивания этих блоков в последовательности. Когда набирается достаточный массив последовательных данных, они переносятся на дисковую подсистему.
Ещё примерно тут делается упреждающее чтение, группирование блоков, многопоточность, консолидация блоков, защита от boot/login — шторма, блендер-эффекта. Если управляющий софт понимает, что делает приложение хоста (например, читает VDI-образ по стандартной схеме), то чтение может производиться раньше, чем хост запросит данные, потому что то же самое он вычитывал последние несколько раз в такой же ситуации. Разумно положить это в кэш в момент, когда станет понятно, что именно он там делает.
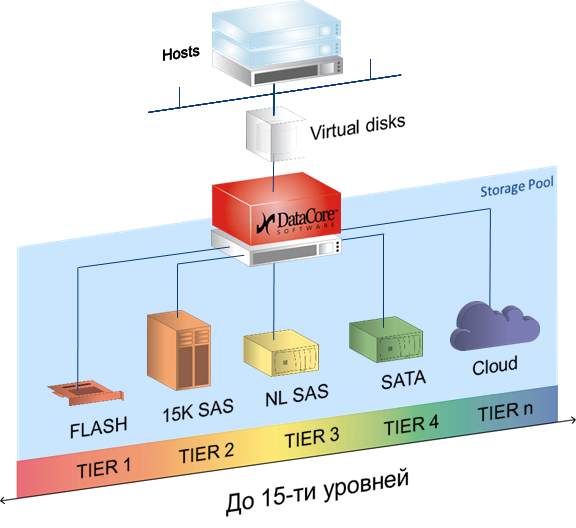
Auto-Tiering — это когда любой виртуальный диск базируется на пуле, в который могут быть включены самые разные носители — от PCI-SSD и FC СХД до медленных SATA и даже внешних облачных хранилищ. Каждому из носителей присваиваем уровень от 0 до 14, и софт автоматически перераспределяет блоки между носителями, в зависимости от частоты обращения к блоку. То есть архивные данные кладутся на SATA и прочие медленные носители, а горячие фрагменты БД, например, на SSD. Причём автоматически и оптимальным образом используются все доступные ресурсы, это не ручная обработка напильником.
Оценка статистики и последующее перемещение блоков происходит по умолчания раз в 30 секунд, но в случае если это не создаст задержки для текущих задач чтения и записи. Балансировка нагрузки присутствует в виде аналога RAID 0 — striping между физическими носителями в дисковом пуле, а также как возможность полноценно использовать обе ноды кластера (active-active) в качестве основной, что позволяет эффективнее нагрузить адаптеры и SAN-сеть.
С помощью SSV можно, например, организовать метрокластер между СХД, которые не поддерживают такую возможность или требуют дополнительного дорогостоящего оборудования для этого. И при этом не потерять (при наличии быстрого канала между узлами), а вырасти в производительности и функционале, плюс иметь запас по производительности.
Архитектура
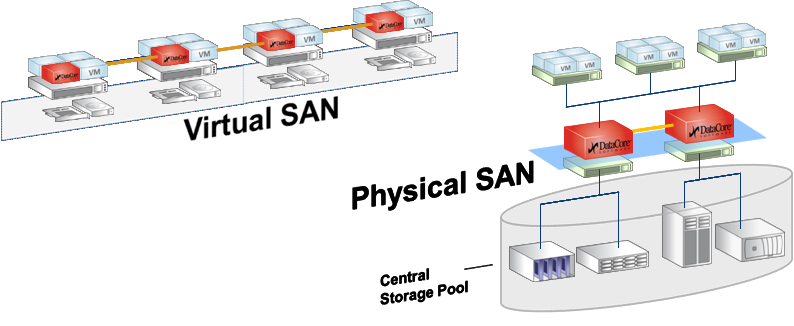
Архитектур у SSV всего две.
Первая — SDS, программно-определяемое хранилище. Классическая «тяжёлая» СХД представляет собой, к примеру, физическую стойку, где есть RISC-сервера и SSD-фабрика (либо HDD-массивы). Кроме, собственно, цены дисков, стоимость этой стойки во многом определяется разницей архитектур, очень важной для решений повышенной надёжности (например банков). Разница в цене между x86-й поделкой китайских тружеников и похожей по объёму СХД того же EMC, HP или другого вендора составляет от порядка до двух при аналогичном наборе дисков. Примерно половина этой разницы приходится на архитектуру.
Так вот, конечно же, можно объединить несколько x86-х серверов с дисковыми полками в одну быструю сеть и научить работать в качестве кластера. Для этого есть специальное ПО, например EMC Vipr. Или можно построить на базе одного x86-го сервера СХД, забив его дисками под завязку.
SDS — это фактически такой сервер. С тем лишь отличием, что в 99% случаев на практике это будут 2 ноды, а на бэкенде может быть всего что угодно.
Технически это два x86 сервера. На них стоит ОС Windows и DataCore SSV, между ними линки синхронизации (блок) и управления (IP). Эти сервера размещены между хостом (потребителем) и ресурсами хранения, например — кучей полок с дисками. Ограничение — должен быть блочный доступ и там и там.
Наиболее понятным описанием к архитектуре будет процедура записи блока. Виртуальный диcк презентован хосту как обычное блочное устройство. Приложение пишет на диск блок, блок попадает в ОЗУ первого узла (1), затем по каналу синхронизации записывается в ОЗУ второго узла (2), затем записано (3), записано (4).
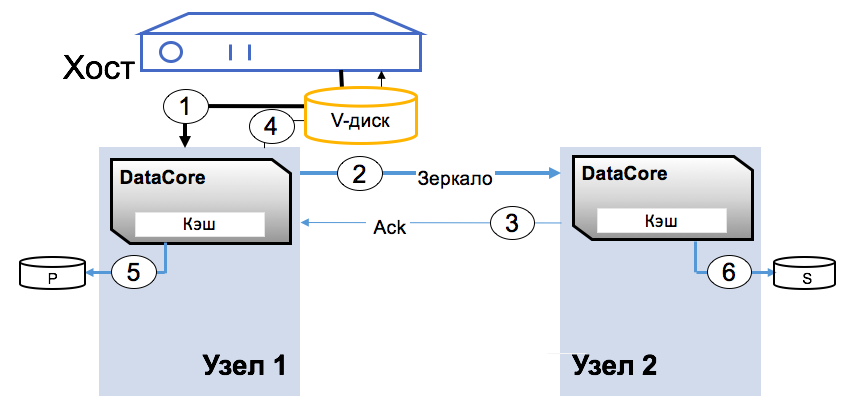
Как только блок появляется в двух копиях, приложение получает подтверждение записи. Конфигурация платформы DC и бэкенда зависит только от требований по нагрузке со стороны хостов. Как правильно производительность системы ограничена ресурсами адаптеров и SAN-сети.
Вторая — это Virtual SAN, то есть виртуальная СХД. DC SSV размещается в виртуальной машине с ОС Windows Server, в распоряжение DC отдаются ресурсы хранения, подключённые к этому хосту (гипервизору). Это могут быть как внутренние диски, так и внешние СХД, таких нод бывает от 2 до 64 штук в текущей версии. DC позволяет объединить ресурсы «под» всеми гипервизорами и динамически распределить этот объём.
Физических копий каждого блока также две, как в предыдущей архитектуре. На практике это чаще всего внутренние диски сервера. Практика — собрать отказоустойчивый мини-ЦОД без использования внешнего хранилища: это 2–5 нод, которые можно добавлять при необходимости новых вычислительных или ресурсов хранения. Это частный пример модной сейчас идеи гиперконвергентной среды, которая используется Google, Amazon и прочими.
Проще говоря, можно построить Enterprise-среду, а можно взять кучу не самой надёжной и не самой быстрой x86-техники, забить машины дисками и полететь захватывать мир по мелкому прайсу.
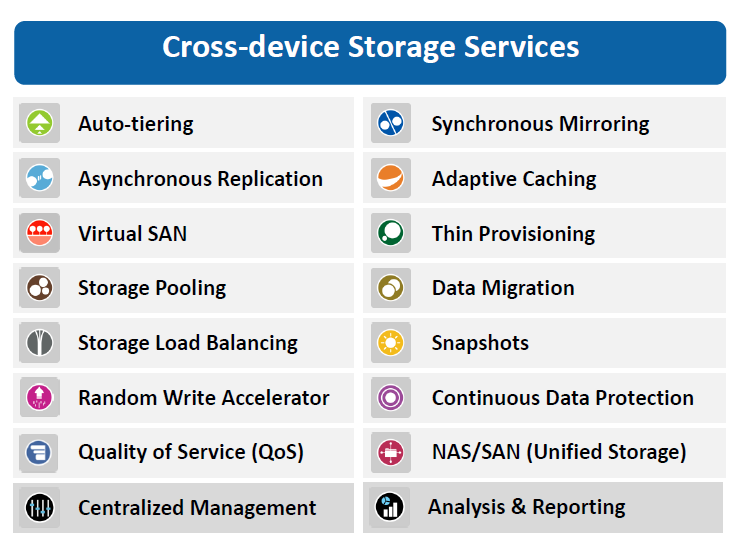
Вот что умеет получившаяся система:
Две практические задачи
Задача №1. Построение виртуального SAN. Есть три сервера виртуализации, размещенные в Центре обработки данных (2 сервера) и Резервном центре обработки данных (1 сервер).
Необходимо объединить в единый территориально распределённый кластер виртуализации VMware vSphere 5.5, обеспечиться реализацию функций отказоустойчивости и резервного копирования с помощью технологий:
• технология высокой доступности VMware High Availability;
• технология балансировки нагрузки VMware DRS;
• технология резервирования каналов данных;
• технология виртуальной сети хранения данных.
Обеспечить следующие режимы работы:
1) Штатный режим работы.
Штатный режим работы характеризуется функционированием всех ВМ в Подсистеме виртуализации ЦОД и РЦОД.
2) Аварийный режим работы.
Аварийный режим работы характеризуется следующим состоянием:
а) все виртуальные машины продолжают работать в ЦОД (РЦОД) в случаях:
— сетевой изоляции сервера виртуализации в пределах ЦОД (РЦОД);
— сбоя виртуальной сети хранения данных между ЦОД и РЦОД;
— сбоя локальной сети между ЦОД и РЦОД.
б) все виртуальные машины автоматически перезапускаются на других узлах кластера в ЦОД (РЦОД) в случаях:
— сбоя одного или двух серверов виртуализации;
— отказа площадки ЦОД (РЦОД) при катастрофе (сбой всех серверов виртуализации).
| Характеристики серверного оборудования |
|
| Сервер № 1 |
|
| Сервер |
HP DL380e Gen8 |
| 2 х процессора |
Intel Xeon Processor E5-2640 v2 |
| Объём оперативной памяти |
128 ГБ |
| 10 х НЖМД |
HP 300 ГБ 6G SAS 15K 2.5in SC ENT HDD |
| Сетевой интерфейс |
2* 10Gb, 4*1Gb |
| Сервер № 2 |
|
| Сервер |
HP DL380e Gen8 |
| 2 х процессора |
Intel Xeon Processor E5-2650 |
| Объём оперативной памяти |
120 ГБ |
| 8 х НЖМД |
HP 300 ГБ 6G SAS 15K 2.5in SC ENT HDD |
| Сетевой интерфейс |
2* 10Gb, 4*1Gb |
| Сервер № 3 |
|
| Сервер |
IBM x3690 X5 |
| 2 х процессора |
Intel Xeon Processor X7560 8C |
| Тип оперативной памяти |
IBM 8GB PC3-8500 CL7 ECC DDR3 1066 MHz LP RDIMM |
| Объём оперативной памяти |
264 |
| 16 х НЖМД |
IBM 146 ГБ 6G SAS 15K 2.5in SFF SLIM HDD |
| Сетевой интерфейс |
2* 10Gb, 2*1Gb |
Решение:
• Использовать имеющееся оборудование для создания подсистемы виртуализации.
• На базе того же оборудования и внутренних устройств хранения серверов создать виртуальную сеть хранения данных с функцией синхронной репликации томов с помощью программного обеспечения DataCore.
На каждом сервере виртуализации разворачивается виртуальный сервер — узел DataCore, к узлам DataCore дополнительно подключены виртуальные диски, созданные на локальных дисковых ресурсах серверов виртуализации. Данные диски объединяются в пулы дисковых ресурсов, на основе которых создаются зеркальные виртуальные диски. Диски зеркалируются между двумя узлами DataCore Virtual SAN — таким образом, на пуле дисковых ресурсов одного узла размещается «оригинал» диска, на втором — «зеркальная копия». Далее виртуальные диски презентуются серверам виртуализации (гипервизорам) либо виртуальным машинам напрямую.
Получается дёшево и сердито (коллеги подсказывают: конкурентное решение по цене) и без дополнительного железа. Кроме решения непосредственной задачи, сеть хранения данных получает массу полезного дополнительного функционала: повышение производительности, возможность интеграции с VMware, мгновенные снимки для всего объёма и так далее. При дальнейшем росте нужно только добавлять узлы виртуального кластера или апгредить имеющиеся.
Вот схема:

Задача №2. Унифицированная система хранения (NAS/SAN).
Все начиналось с Windows Failover cluster для файлового сервера. Заказчику необходимо было сделать файловую шару для хранения документов — с высокой доступностью и резервным копированием данных и с почти мгновенным их восстановлением. Было принято решение строить кластер.
Из имеющегося оборудования у заказчика было два сервера Supermicro (к одному из которых подключён SAS JBOD). Дискового объёма в двух серверах более чем достаточно (около 10 ТБ на каждый сервер), однако для организации кластера необходим shared storage. Также планировалось иметь резервную копию данных, т. к. одна СХД — это единая точка отказа, желательно с CDP с покрытием рабочей недели. Данные должны быть доступны постоянно, максимальное время простоя — 30 минут (и то могут полететь головы). Стандартное решение включало в себя покупку СХД, ещё одного сервера для бэкапов.
Решение:
• ПО DataCore установлено на каждый сервер.
В архитектуре DataCore, Windows Failover Cluster может быть развернут без использования общего хранилища SAN (используя внутренние диски серверов) или с использованием DAS, JBOD или внешних СХД с полной реализацией архитектуры — DataCore Unified Storage (SAN & NAS), в полной мере используя возможности Windows Server 2012 и NFS & SMB (CIFS) и предоставляя сервис SAN внешним хостам. Такая архитектура и была в итоге развёрнута, и не используемый под файловый сервер объём дисков не был презентован как SAN для ESXi хостов.
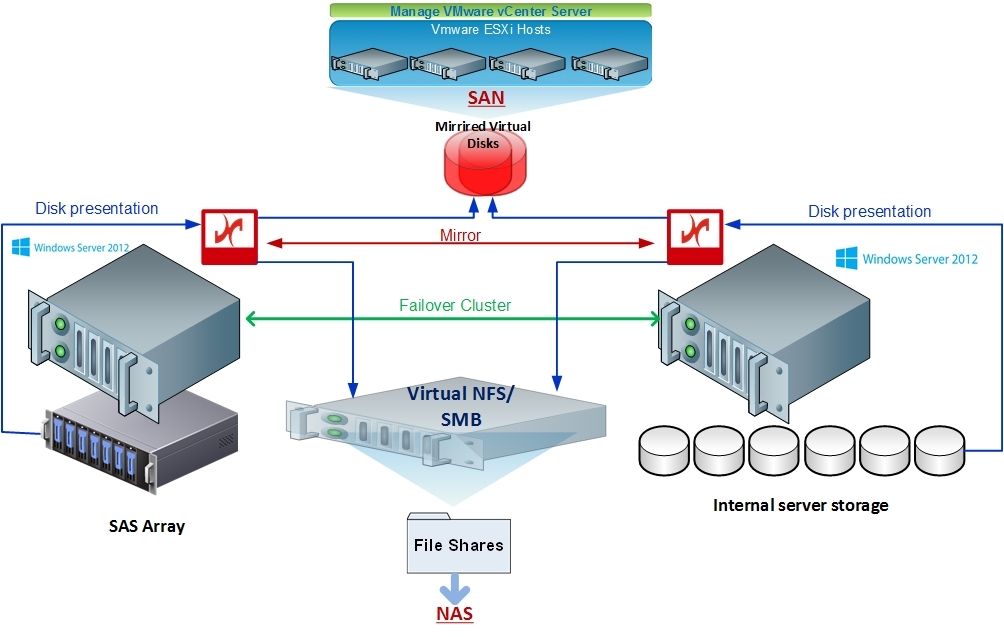
Получилось очень дёшево в сравнении с традиционными решениями, плюс:
- Отказоустойчивость ресурсов хранения (в том числе в контексте работы Windows Failover Cluster). В любой момент времени доступны две зеркальные копии данных.
- Благодаря функциям виртуализации уже самому Windows Cluster DataCore предоставляет зеркалируемый многопортовый виртуальный диск, т. е. проблема длительного chkdsk перестаёт существовать как таковая.
- Дальнейшее масштабирование системы (например, рост объёма данных требует подключения дополнительного дискового массива или наращивания объёма в самом сервере) представляет собой крайне простой процесс и без остановки работы сервиса.
- Выполнение каких-либо технологических работ по обслуживанию узлов кластера — без остановки сервиса файлового доступа.
- CDP у SANsymphony-V10 встроенная функция и ограничивается только свободным местом на дисках.
- Повышение производительности ресурсов хранения за счёт преимуществ DataCore, а именно — функции Adaptive Caching, когда в качестве кэша для подключённых систем хранения используется весь свободный объём ОЗУ серверов, причём кэш работает и на запись и на чтение, но это важнее для ESXi хостов, чем для файловых шар.
Главный принцип
Основной принцип виртуализации СХД — с одной стороны, скрыть от потребителя весь бекэнд, с другой стороны, предоставить любому бэкенду единый реально конкурентный функционал.
Важные практические замечания именно по Датакоре
- Во второй архитектуре DataCore делает почти то же самое, что, например, ScaleIO.
- Если у вас есть задача обеспечить хранение данных филиалов по России, но вы не хотите связывать их с текущей СХД и не хотите ставить новые СХД в филиалах, то есть простой как бревно метод. Берёте три сервера по 24 диска и получаете приемлемый объём и приемлемую производительность для работы большей части сервисов.
- Если надо упорядочить зоопарк — дешевле и проще вариант найти будет сложно. Сроки такие: последний пример — 8 дней на внедрение. Проектирование — ещё примерно неделя до этого. Оборудование использовали имеющееся, принципиально нового не закупали. Докупили только плашек оперативы в кэш. Лицензия Датакоры шла чуть больше недели, но мы закладываем две.
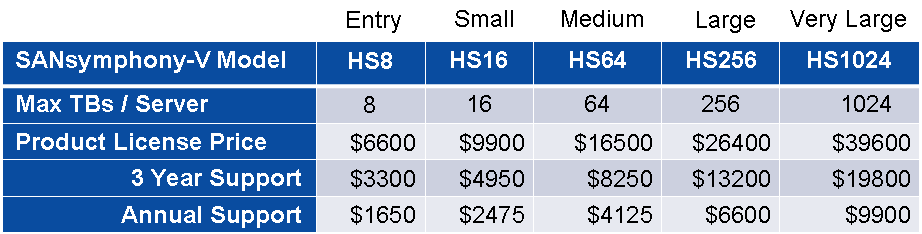
- Лицензируется DC по объёму — пачками по 8, 16 ТБ. Цены без скидок по street price такие (важно: прайс ниже — условный, на деле все довольно гибко, лицензирование осуществляется по хостам или ТБ и можно выбирать некоторые функции, поэтому по факту цены сильно отличаются, если нужно рассчитать для вашего кейса — пишите в личку):
- В одной из задач у нас была организация DMZ-сегмента крупной компании. Для экономии хранения и оптимизация доступа к локальному хранилищу поставили как раз DC. Общий SAN ядро с DMZ не делили, поэтому надо было бы либо покупать СХД и ещё одну железку типа файрволла с навесками для безопасного доступа внутрь, либо шевелить извилинами. Мы объединили 3 хоста виртуализации в единое пространство плюс оптимизировали доступ. Получилось дешёво и быстро.
- В ещё одной задаче у нас была оптимизация доступа под SQL. Там мы смогли использовать старые медленные хранилища. Запись благодаря кэшу DC пошла быстрее в десятки раз, чем напрямую.
- Есть полезный для некоторых ситуаций RAID Striping (можно строить программные RAID0 и RAID1, даже если подключённый DAS этого не умеет).
- Хорошие отчёты — визуальные и статистические инструменты предоставления данных о всевозможных параметрах производительности с указанием «узких» мест.
- QoS Control даёт возможность СУБД и критическим приложением работать быстрее, устанавливая ограничения на трафик ввода/вывода для менее важных нагрузок.
- Я вырубал узлы на тестах по питанию (в разумных пределах, сохраняя необходимое количество узлов для корректного восстановления), но не смог поймать коррапты. Synchronous Mirroring & Auto Failover — есть синхронная репликация и механизмы автоматического и настраиваемого восстановления после сбоев. Функция самолечения дисковых пулов такая: если физический диск в пуле выходит из строя или помечен для замены, DataCore автоматически восстанавливает пул на доступных ресурсах. Плюс журнал изменений на диске с возможностью восстановиться из любого состояния или из любого времени. Плановая замена дисков, естественно, делается без перерыва в работе. Как обычно, данные размазывают между другими инстансами, а потом при появлении первой возможности том «заползает» и на новый диск. Примерно по похожему принципу делается миграция между ЦОДами, только «замена дисков» носит массовый характер.
- Есть Virtual Disk Migration — простая и эффективная миграция данных с физических ресурсов в виртуальные и обратно. ПричЁм без остановки приложений.
Подводные камни
Естественно, не всё так радужно. Дешёвое негомогенное железо, не заточенное под критические данные, — это, конечно, будущее отказоустойчивых систем, но пока банки его попросту не берут в системы ядра. По понятным причинам.
Второй минус — нужна нехилая квалификация по проектированию сети, поскольку именно в неё упирается итоговая производительность системы. Все вендоры VirtualSAN создают кучу вопросов по проектированию сети, правильной полосе пропускания, постройке потоков. При этом все они говорят «думать не надо».
Так вот, думать надо, и это нетривиально, потому что надо очень хорошо представлять архитектуру, чтобы спроектировать всё как надо. Выстрелить себе в ногу — как нечего делать.
У Датакоры есть важная особенность: каждое решение проходит экспертизу лично у вендора. Вендор попросту не берёт на поддержку решение, пока не пройдет как проектное решение (сетевая часть), так и внедрение с последующей сдачей логов тестового запуска. Они их смотрят, говорят «о’кей» — и вот только тогда оно принимается на поддержку.
Они попутно на стадии проектирования помогают и страхуют от выстрелов в ногу. Причём, опять же, по моей практике именно советуют, а не говорят «так делать не надо».
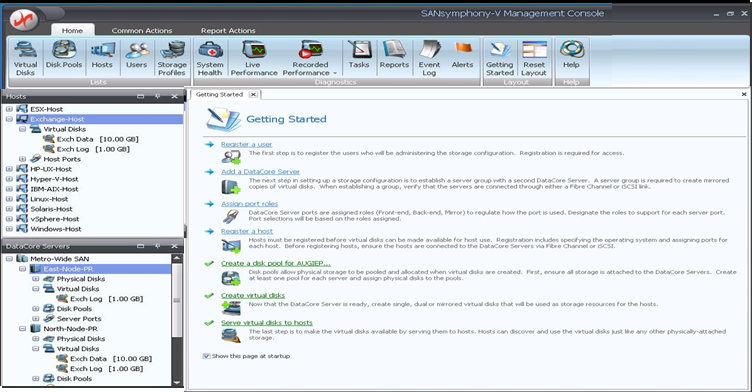
Мониторинг процесса:
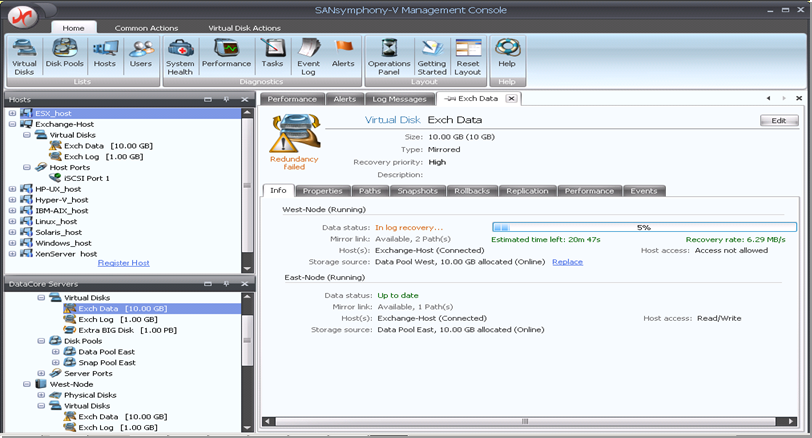
Тестирование резервной копии:
Экспорт для биллинга и журнала операций:
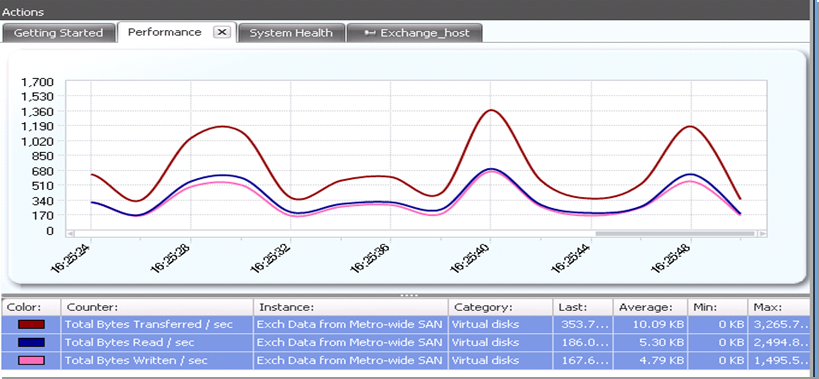
Статистика:
Итого
- Однозначный блочный доступ, без «прослоек» типа проприетарных файловых систем или файлов виртуальных машин.
- Файловый доступ, причём одновременно с блочным.
- Кросс-платформенная синхронная репликация — со свободой выбора аппаратных средств и протоколов подключения.
- Иерархическая структура хранения с автоматизированным перераспределением данных по уровням хранения. Необходимо также учитывать, что трёх классических уровней недостаточно. Необходимо пять, а лучше десять, чтобы добавить облачное хранилище.
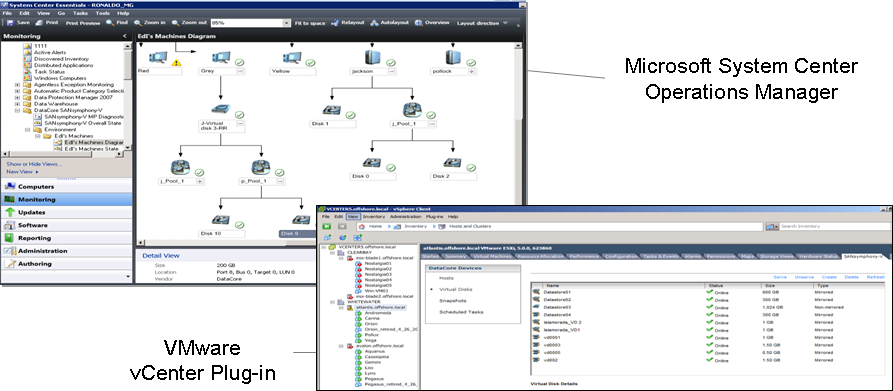
- Оптимизация использования ресурсов и управление ресурсами: thin provisioning. централизованное управление и широкий набор инструментов аналитики и отчётности. интеграция с системами управления инфраструктурой (MS SCOM, vCenter и т. д.).
- Многоуровневая защита данных: Snapshots, Continuous data protection. синхронная репликация и асинхронная репликация для построения катастрофоустойчивого решения.
- Инструменты повышения производительности (например, кэширование в RAM).
Кто использует много лет и зачем
SDS-подход — это фермы Amazon, дата-центры Google и Facebook, но это очень далёкие от бизнеса вещи. Более практические примеры такие:
- Администрация Болоньи (крупного города в Италии) содержит 50 офисов на 3500 машин и 4300 человек. Это музеи, библиотеки, обычные офисы управлений города, 200 школ и другие подобные здания. Очень хотели взять и сэкономить. Поставили SSV для 60 Oracle-инстансов, 10Тб почты, 200 виртуальных машин. Ничего не выкидывали: соединили в SSV хранилище IBM, NetApp, Nexsan и кучу своих флеш-дисков из серверов.
- Крупнейшие угледобытчики из Польши («Богданка») добыли не только 8,3 миллиона тонн угля, но и много геморроя со внедрением VMware и репликацией. Посмотрев на то, какой зоопарк получается по классическим схемам, плюнули, разобрались и поставили SSV.
- Imperial Tobacco из Польши с 1400 сотрудниками поймала обновление SAP и немного офигела, потому что пора было масштабироваться. Поставили под это дело на тормозящем уже железе SSV, соединили серверные в здании в один кластер (как я полагаю, купили ещё пару дешёвых серверов, оперативки и прочего для организации контроллеров) и снова стали жить как раньше. Плюс прикрылись от рисков.
- Шведский бумажный комбинат SCA просто хотел Hyper-V побыстрее. Поставили 2 ноды SANsymphony-V на IBM System x3500 с 10 TB (12 дисков по 900 Гб) на обычном 10 Гб/с Ethernet’е.
- Шведские владельцы онлайн-казино из NetEnt почувствовали себя почти банком по объёму операций и транзакциями. Но до банковских ценников им было далеко, поэтому решили делать репликацию дёшево и сердито. У них 14 SANsymphony-V нод на HP Proliant, 400 Тб под 1500 виртуальных машин.
- Колледж Kirkless из Великобритании немного балдел от того, что творили там набегающие 20 тысяч студентов в пиках. Прикинув, что эти же студенты будут творить через год-другой, а то и пять-шесть, решили не привязываться к железу и сразу закладываться на масштабируемую архитектуру. Заодно сильно уменьшили стоимость хранимого гигабайта.
Всё, вы дочитали до конца, выдыхайте. Я могу ещё часами рассказывать про особенности решения разных задач на таких архитектурах, но пост уже получился огромным. Поэтому давайте или перейдём к вопросам в комментариях, или же с удовольствием отвечу на ваши вопросы в почте albelyaev@croc.ru.
И да, вот здесь есть возможность всем подключиться к живой инсталляции и потрогать консоль своими руками.
Комментарии (15)

AlBelyaev
10.12.2015 13:38Для определения температуры данных используется функционал под названием data tiering. Вещь сейчас достаточно известная и распространенная. Tiering делается на блочном уровне. Блоки данных, к которым происходит наиболее частые обращения, размещаются на более быстрых носителях, а те блоки, к которым мало обращений, или их вовсе нет, размещаются на более медленных носителях. Плюс есть технологии, которые позволяют подгрузить сразу в кэш блоки, к которым еще не обращались, но вероятнее всего в скором времени обратятся.
Конкретно в Datacore Tiering работает на блочном уровне по очень простой схеме: SSV оценивает статистику обращения к конкретному блоку, сравнивает с историей, и если блок стал популярнее, то переносит его на быстрые носители. Если наоборот, то на медленные. Оценка и перенос происходит раз в секунду, 30 секунд или минуту. При этом перенос блоков является «неприоритетной» задачей, сначала приложение убедится что у него достаточно ресурсов для чтения и записи, и только потом осуществит перенос. При этом уровней аж 15 штук. Соответственно, и настройки могут быть очень гибкими.
AlanDenton
10.12.2015 13:57Спасибо за ответ.
Хорошо… Предположим ситуацию. База используется преимущественно на чтение и данные в нее заливаются раз в день.
В контексте SQL Server, когда нам нужно что-то прочитать из БД, то вначале происходят физические чтения с диска, после чего данные помещяются в память (Buffer Pool) и только потом возвращаются на клиент. При таком положении дел, файлы БД будут лежать на медленном носителе и при первой вычитке данных производительность будет не ахти. Если последнее критично, то все эти автоматические плюшки больше вреда принесут. Такие моменты как-то предусматриваются в data tiering о котором Вы упомянули?AlBelyaev
10.12.2015 16:55+1Да, базы и прочая OLTP-нагрузка переваривается хорошо. Тьиринг как раз помогает держать систему в нужном тонусе.
Если вы пишите, что производительность критична, то выставляем диску соответсвующий профиль и тьиринг будет держать данные на нужных носителях. Или если по каким-либо причинам вы не хотите привязывать диск к определенному профилю на помощь приходит механизм упреждающего чтения, который работает по следующей схеме:
— если чтение последовательное или укладывается в логику упреждающего чтения, тогда данные очень быстро читаются из кэша
— если чтение блоков носит абсолютно случайный характер, что наименее вероятно в сценарии работы с базами данных, тогда данные действительно будут читаться с того носителя на котором они размещены.
ToSHiC
11.12.2015 03:48На сколько большой кластер можно собрать? Скажем, если использовать как объектное хранилище (типа Amazon S3), то сколько машин/петабайт можно максимум запихать?
Можно ли растянуть кластер на несколько ДЦ для отказоустойчивости? На сколько хорошо переживает пропадание 1/4 или 1/3 узлов сразу?AlBelyaev
11.12.2015 17:35Формальное ограничение для коммерческих пользователей (т.е. не требует доп. манипуляций) это 64 хоста и 64PB, соответственно.
Между ДЦ растягивается, такой пример как раз описан в статье (Задача №1), реплицировать м/у площадками можно синхронно, можно асинхронно.
Падение четверти/трети или даже половины узлов никак не скажется на доступности сервиса, но если покрашились строго половинки от синхронных копий, например отрубилась связь с площадкой. Дело в том, что виртуальный диск, который презентует SSV живет строго в двух синхронных физических копиях. Если одну мы потеряли, то хост этого не замечает, если обе, то чуда не происходит и диск более недоступен.
То есть, если по феншую раскидать вирт. диски по хостам, то вероятность потерять сервис минимальна.

ximik13
11.12.2015 14:50Каким образом защищается кэш на запись от сбоев по электропитанию в серверной? Для примера можно взять конфигурацию из описанной вами задачи №1. Весь кластер находится в одной серверной и активно работает. В здании, где расположена серверная, аварийно отключается электропитание. Что будет с данными находящимися в кэше, но еще не записанными на диски? Есть механизмы, которые позволят не потерять их?
Уточнение по ScaleIO. Насколько помню документацию, ScaleIO так же использует ОЗУ серверов под кэширование операций ввода\вывода. Но кэшируются только операции чтения.
Спасибо за статью, читать было интересно :)!
gotch
11.12.2015 18:00Поддержу вопрос. Что это за такой RAM-кеш на запись? Как обеспечивается сохранность кеша?
Расскажу историю о самом примитивном случае. Был тестовый сервер с кешем контроллера на 128 mb и массивом RAID5 на 3 Tb. Бекапа кеша не было. Вроде бы казалось что такое 128Mb vs 3Tb. Как плотник супротив столяра. Контроллер вышел из строя. ВСЕ полезные данные на томе пришли в негодность. Все SQL БД и все включенные виртуальные машины оказались неисправимо повреждены. С тех пор RAM кешей без батареек мы как огня.AlBelyaev
12.12.2015 12:57К сожалению, даже самые невероятные аварии случаются и уносят миллионы. Примеров десятки реально, начиная от двух строек с забитыми сваями в европейском магистральном кольце с разрывом в 2 часа.
AlBelyaev
12.12.2015 12:49Спасибо за вопрос. Если виртуальный диск живет на двух нодах, запитанных от одного источника, то им точно нужен ИБП, без вариантов, в кэше никаких батареек нет, т.к. это самая обычная RAM x86. ИБП рекомендуется пользовать дружащий с виндой, чтобы датакор знал в каком он состоянии, т.е. на батарейке — выключаем кэш на запись, мало батарейки — нода просит соседку включить журнал рассинхронизации, а сама выключается.
В нашем случае (Задача 1) есть диски, как живущие в одном ЦОД, (условно vDisk1 на картинке) так и аля «метрокластре», т.е. одна копия в ЦОД, вторая в РЦОД (vDisk2 и vDisk3).
ScaleIO — так и есть, спасибо за уточнение.gotch
12.12.2015 14:27Спасибо за ответ. Отвлеченно скажу, что у нас славные стоечные ИБП APC не раз уносили стойку в сборе ) Переподключили по науке, от двух источников.

navion
14.12.2015 13:45Лицензируется DC по объёму — пачками по 8, 16 ТБ.
По объему на сервер или всего с любым количеством серверов? В первом случае это не конкурент СХД начального уровня при отсутствии второго сайта.
Кстати, какие там требования по latency и пропускной способности?AlBelyaev
16.12.2015 15:43+1По лицензированию, учитывается каждый узел, к нему объем, который нужно виртуализировать, плюс отдельно опции, например, FC и CDP входят не во все базовые лицензии. По небольшим одиноким СХД — тут не поспоришь, хорошее исключение — это высоконагруженные системы с раскладом: много иопсов — мало объема, тут обычный сервак в PCI-SSD картой и датакором прям поборются.
Что касается пропускной способности и задержки, то со стороны системы временных ограничений для синхронной репликации кэшей нет, реальные требования диктуются хостом, т.е. сколько приложение готово ждать ответа и именно эти требования должны быть основой для сайзинга, а именно — какие использовать тип протокола, тип HBA и максимально возможное расстояние между ЦОДами (например, оптоволокно дает 5 мкс задержки на 1 километр).
Сам Datacore — low latency app, т.е. значимых задержек не вносит. Лучшее что видел мой иометер это 0,14 милисекунд с синхронной репликацией.
gydex
15.12.2015 08:49Интересная статья. А есть ли пример развертывания системы именно для «зоопарка» техники?
AlBelyaev
16.12.2015 16:38Из красиво описанных есть пример конторы Continuum health partners, они как раз начинали с объединения несовметсимых стораджей, и плавно доросли до 2х петабайт.
Можно посмотреть или прочитать.
Но там про сам зоопарк разве что идея, деталей нет.
На практике же зоопарк в проектах виртуализации встречается регулярно. Из недавнего, казалось бы, простая задача, зеркалировать данные в формально «гомогенной» среде между трипаром и ивой, везде FC плюс имеются N штук MSA и пара P2000, нужно распределить коробки по 2-м площадкам и зеркалировать данные. Понятно, что SSV не единственное решение, но закрывает вопрос легко, добавляется пара не менее «гомогенных» серверов, на них Datacore и полетели, причем кэш и возможность подкинуть в сам сервер SSD или лучше PCI-SSD уравновешивают производительность площадок. Тут формально не зоопарк, а больше сложности внутри семейства, но подход абсолютно тот же.
AlanDenton
Спасибо за статью. Можно у Вас попросить рассказать как Вы определяете какие фрагменты БД горячие, а какие нет? Ну если tempdb все и так понятно… то как это Вы определяете для пользовательских БД.