
ИИ Google AlphaGo одержал победу и в пятой, заключительной партии в го, одолев одного из лучших игроков среди людей — Ли Седоля. На этот раз чемпион играл черными камнями, а программа — белыми. Корейский игрок в го старался постоянно атаковать противника, как и в четвертой, победной для себя партии. Тогда Седоль старался не давать инициативу своему виртуальному сопернику.
Как и в прошлый раз, время у игрока-человека закончилось быстрее, чем у машины, поэтому Седоль стал использовать дополнительное время, бёёми. Ему все же удалось несколько потревожить систему защиты AlphaGo, но ИИ решил эту проблему и вернул отвоеванные территории. Практически до самого конца игроки шли на равных, но Седолю все же пришлось признать поражение. Случилось это после пяти часов напряженной игры.
По словам представителей Google, организовавших эту игру, если бы Седоль выиграл у компьютера в большинстве партий, то он бы получил $1000000. Но поскольку победа осталась за AlphaGo, то миллион ушел на благотворительность.
#AlphaGo wins game 5 taking the historic match 4-1. Congrats DM team and Lee Sedol. Awesome displays of human ingenuity all round!
— Mustafa Suleyman (@mustafasuleymn) 15 марта 2016 г.
Сама программа для игры в Го была создана компанией DeepMind, купленной Google некоторое время назад. По мнению создателей программы, только за время обучения она обработала около 30 млн различных комбинаций, постепенно обучаясь различным методам и схемам игры. Используется и вычисление оптимальных комбинаций, но не для всей игры в целом, а только для решения часто возникающих локальных моментов.
Если вы вдруг пропустили трансляцию, вот видео с разбором «полетов»:
Ну и ссылочка на файл с ходами, если хотите разобраться детально.
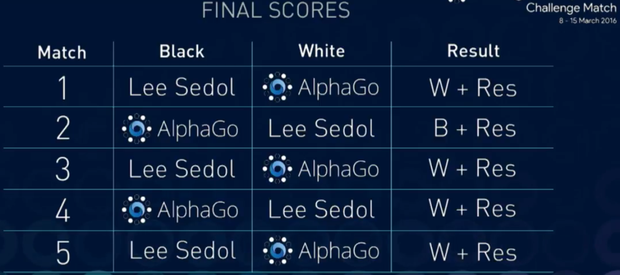
Напомню, что Ли Седоль проиграл первую, вторую, третью и пятую партии машине. Четвертую партию он выиграл, о чем уже упоминалось выше.
Комментарии (128)

AngusMetall
15.03.2016 16:21+1Кто-нибудь из разбирающихся прокомментируйте ходы Седоля. Было ли в них что то необычное, намекающее на правдивость того, что он якобы нашёл слабое место у AlphaGo?

el777
15.03.2016 16:34+2Думаю, если бы нашел, то выиграл бы и 5-ю игру. Либо машина быстро это обнаружила и перестроила игру. Но это еще круче.

Avitale
15.03.2016 16:57+2Возможно, повлияло то, что в этот раз машина играла белыми. Все-таки от того, кто ходит первым, может зависеть и дальнейшая стратегия.

dimykus
15.03.2016 17:18+7Но первыми ходят черные.
Avitale
15.03.2016 17:46+1Верно, перепутала с шахматами. Но стратегия все равно зависит от того, каким по очереди ты ходишь :)
Frosterman
16.03.2016 14:45Го сильно отличается от шахмат…
Avitale
16.03.2016 14:50Спасибо, я в курсе чем го отличается от шахмат. Перепутать, какой именно цвет ходит первым, не так уж и сложно. Давайте вы не будете приосаниваться на фоне такой глупой ошибки?
Frosterman
16.03.2016 18:44Но стратегия все равно зависит от того, каким по очереди ты ходишь
мой комментарий относится вот этому тексту. В отличии от шахмат, в Го первый ход в партии очень слабо влияет на итоги всей партии.Xaliuss
16.03.2016 20:17Вроде заметно влияет у лучших игроков. Не зря есть коми в 7,5 очков бонуса белым, как компенсация за очередь хода, и как минимум в первой и пятой париях матча белые выиграли только за счёт этого бонуса. В результате чёрные при прочих равных должны играть агрессивнее.
Многие комментаторы говорили, что игра за белых у Альфаго немного получше.Frosterman
17.03.2016 01:24На высоких уровнях игры возможно и влияет, но для этого надо много условий и самое главное из них — равный уровень игроков. По сути первый ход в партии даёт преимущество только в одном локальном участке, т.е. начинающий потенциально имеет на один участок доминирования больше. Ну и не стоить забывать что как только в локальной стычке определяется победитель и он ставит решающий камень, после которого становится очевидным его преимущество, проигравшая сторона автоматом делает первый ход в любой другой перспективной для него части поля. Т.е. право первого ход а в той локальной зоне уже за ним.
Многие комментаторы говорили, что игра за белых у Альфаго немного получше.
любопытное заявление. Я, к сожалению, уже давно не играю в Го и не в состоянии полноценно оценить игру таких профи.Даже жаль что так вышло — возможно стоило бы превратить это увлечение в постоянное хобби.Xaliuss
17.03.2016 10:03По сути первый ход в партии даёт преимущество только в одном локальном участке, т.е. начинающий потенциально имеет на один участок доминирования больше. Ну и не стоить забывать что как только в локальной стычке определяется победитель и он ставит решающий камень, после которого становится очевидным его преимущество, проигравшая сторона автоматом делает первый ход в любой другой перспективной для него части поля. Т.е. право первого ход а в той локальной зоне уже за ним.
Ну так в результате, в таком упрощении при нечётном количестве игровых зон чёрные возьмут на одну больше, а при чётном у них будет право первого выбора наиболее выгодной (с наибольшим числом очков) зоны. Всё конечно намного сложнее, но этот перевес примерно в коми и оценивается.
Соответственно при игре белыми, когда зоны ещё не размечены Альфаго, программа может уже считать, что у неё некоторое преимущество и наоборот. Это влияет на тактику.

Heath
15.03.2016 16:37+1АльфаГо локально доигрывает некоторые ветки, которые человек доигрывать не стал бы. То есть пока что явно «видит» не так, как видят обученные люди. Плюс профессионалы круто натаскиваются на решения задач (в том числе на жизнь и смерть групп), чему АльфаГо не обучали. Она не тренировалась на типовые тэсудзи. Судя по всему, вопрос решаемый.
Vlad_Hm
15.03.2016 16:40+1Вопрос, имхо, всего лишь в модификации модели оценок. Решить можно. Важнее, что для АльфаГо, которая создана не исключительно для побед в го (в отличии от множества других программ ранее) — это вопрос частный и непринципиальный.
Heath
15.03.2016 16:42+1Не понял вот это «АльфаГо, которая создана не исключительно для побед в го». Конкретно АльфаГошная нейросеть натренирована только на это. Используемые подходы используются не только в АльфаГо, это так.
Vlad_Hm
15.03.2016 17:03+1Я был неточен. Я имел ввиду именно модель, систему. АльфаГо — конкретная реализация, частность.
GreenGoblin
15.03.2016 16:55+3По крайней мере одно слабое место вскрылось точно — неадекватное поведение в проигрышных ситуациях, что было очень хорошо видно в конце четвертой игры. И даже несколько в этой — в начале игры Седоль вел после удачного розыгрыша в нижнем правом углу, хоть потом бот и отыгрался. Правда загнать бота такого уровня в проигрышную ситуацию можно, похоже, только по чистой случайности…
Не уверен, что достаточно понимаю в го, чтобы комментировать игру такого уровня, но мне показалось, что играл Седоль в своей обычной манере.
Sadler
15.03.2016 18:19+1Судя по репликам авторов, сеть училась на обширной базе прошлых игр людей в интернете. Являются ли победители в интернете непогрешимыми? Очевидно, нет. Какие-то их ошибки сложная нейросеть обязательно будет перенимать. И, что ещё хуже, будет даже ожидать от соперника этих ошибок, что непростительно в текущей ситуации. Так что это может быть не случайность, просто у сети было недостаточно достойных противников.
zuborg
15.03.2016 18:32+2База игр использовалась для бутстрапа системы — для построения сети оценки вероятности выигрыша. Дальше эта сеть обучалась и тюнилась на игре сама с собой — так что замеченные ошибки были исправлены и не оказывают своего негативного влияния.
Sadler
15.03.2016 18:52Дальше эта сеть обучалась и тюнилась на игре сама с собой — так что замеченные ошибки были исправлены и не оказывают своего негативного влияния.
Так не бывает: если вероятность выбора конкретного хода в течение «бутстрапа» упала в ноль, как в том-самом-случае, сетка может хоть вечность играть сама с собой, но так и не узнать, что есть шанс сыграть лучше. Либо нужно вводить какой-то элемент случайности, что сильно замедлит обучение, т.к. будут выбираться сильно неоптимальные ходы, и мы вряд ли можем себе такое позволить слишком часто (но это хорошая тренировка поведения в случае ошибок), либо нужно, опять же, периодически заливать в неё новые игры с живыми людьми, которые имеют свойство ошибаться. Вариантом выхода из такой ситуации является игра с несколькими конкурирующими нейросетями, которые быстро и жёстко укажут первой на её ошибки. Но это потребует кратно увеличить используемые для обучения ресурсы.daiver19
15.03.2016 19:49+3Разве суть обучения на своих играх не использование случайных/суб-оптимальных ходов? Иначе пользы никакой от него не будет.
Sadler
15.03.2016 19:59+2Если такая игра будет слишком случайной, полученная сеть политик окажется бесполезной при игре с живыми людьми (обучение будет проходить слишком медленно, я пробовал). Разработчики не зря говорят, что система без привлечения внешних данных от игроков-людей — это следующая сложная задача для системы.
zuborg
15.03.2016 19:58+2А вот тут на помощь приходит МонтеКарло )
Низкоприоритетные ходы тоже рассматриваются, пусть и не так детально (ведь нет смысла глубоко рассматривать очевидно проигрышные ходы).
Элемент случайности присутствует как при анализе позиции, так и про обучении (ознакомьтесь с обзором архитектуры AlphaGo)
Если расчетная вероятность выигрыша в рассматриваемой позиции близка к нулю, то скорее всего так и есть — результат матча свидетельствует сам за себя.Sadler
15.03.2016 20:11+3Ага, низкоприоритетные ходы тоже рассматриваются, пока вычисление не обрубается по таймеру, самый лучших ход оказывается недосчитан, и Седоль выигрывает игру. Из обзора как раз вижу, что используют модель с конкуренцией, но не отдельных сетей, а нескольких версий одной, что, имхо, менее эффективно, но и менее затратно в плане расчётов.
В том случае к нулю была близка не вероятность выигрыша (value network), а шанс выбора человеком этого хода (policy network). Просто игроки в интернете, пусть даже у них высокий рейтинг, практически не знали о тактике, которую применил Седоль, и в процессе самообучения AlphaGo не "изобрела" этот ход.zuborg
15.03.2016 20:21+2С одной стороны да, возможно есть какой-то хитрый аспект, который в обучающей базе игр не проявлялся, соотв policy network не будет рассматривать такие ходы как вероятные, и они не будут рассматриваться при анализе позиции — это дает шанс обыграть AlphaGo (если найти такой аспект, конечно).
Но как всегда, есть но ). Во первых, вероятность рассмотрения таких ходов ненулевая, особенно если учесть что настройка AlphaGo поощраяет исследование нерассмотренных позиций.
Второй момент — как только пойдут партии с такими ходами — сеть их начинает анализировать и использовать при моделировании развития позиции, соответственно у программы есть возможность найти противодействие — она тоже будет развиваться.Sadler
15.03.2016 21:15+3Да, она будет развиваться, поэтому для неё очень позитивен факт поражения в четвёртой игре. Поэтому же ждём следующих матчей с не менее серьёзными противниками.

sim31r
16.03.2016 01:13+2Человек тоже так делает, сначала «видит» низкоприоритетных ходы, а потом «эврика!» и увидел сильный ход, чем больше времени, тем сильнее игра.
Если размышления человека прервать по таймеру, раньше положенного времени, точно так же сделает слабый ход.
Platon_msk
15.03.2016 18:52+2Неадекватное поведение в проигрышных ситуациях мне очень напоминает то, что происходило с системой дифуров, описывающих двигатель и движитель в одном из наших проектов.
При выходе за граничные значения скоростей/ускорений система «разваливалась» и начинала выдавать весьма «весёлые» данные. При отсутствии искусственных ограничений на диапазоны система начинала высчитывать совершенно космические высоты и скорости.
Здесь видимо то же самое — система с положительной обратной связью получила на входе колебание, которое не смогла отсечь. Как следствие — пошла вразнос.
vsb
16.03.2016 00:46+3Я так думаю, что это человеку оно кажется неадекватным. А компьютер просто оценивал матожидание победы для каждого хода. Те ходы, что вам кажутся неадекватными, давали вероятность победы, если бы противник ответил неправильно. Те ходы, что вам кажутся адекватными, просто привели бы к проигрышу с большей вероятностью. Вот и всё.
Т.е. по факту компьютеру надо было просто сдаваться, т.к. очевидно, что противник не дал бы ему вылезти из проигрышной ситуации. Видимо граница для признания поражения была выбрана с большим запасом.
flashtech
15.03.2016 22:17+1По оценке про-комментатора, в начале игры AlphaGo допустила серьезную ошибку в развитии. По его словам, в том конкретном (и достаточно часто встречающемся) паттерне у края доски достаточно сложно просчитать все варианты, но любой профессиональный игрок его бы опознал, понял, что там нет шансов, смирился с локальной потерей и продолжил в другом месте. AI вместо этого еще довольно долго пыталось там бороться и усугубляло свое положение, теряя все больше. Может подобных паттернов было мало в обучающей выборке.
Но несмотря на это, в середине партии AlphaGo смог выравнять ситуацию и далее особо серьезных ошибок уже не допускал. Было несколько довольно странных ko threat ходов, но возможно к этому моменту бот считал что он ведет и просто упрощал ситуацию на доске.

Heath
15.03.2016 16:35+6При поражении Ли Седоля в третьей партии (и, соответственно, в матче) я написал статью «Го-сингулярность» с соображениями о том, почему это исторический матч и в чём разница с поражением человека в шахматы.
veam
15.03.2016 16:45+4Если AlphaGo запустить на игровой Го-сервер KGS, никто не сможет определить, что играет не с человеком.
А ту же рыбку в шахматах легко отличить от человека?

Singerofthefall
15.03.2016 17:27+1Да, AlphaGo понимает игру Го лучше человека.
Мне не очень нравится слово «понимает» в этом контексте. Оно как бы подразумевает, что AlphaGo обладает какими-то сакральными знаниями о игре, которых у нас нет, однако это не так. ИИ по сути делает то же, что и игрок-человек — на основании собственного опыта и просчета на N ходов вперед пытается найти наиболее перспективный ход — но, в силу нашей ограниченности, делает это гораздо быстрее и глубже.
Обратите внимание, например, на ходы 58 и 84 в последней игре. Эти ходы бессмысленны, и, как справедливо заметил Майкл Рэдмонд, вполне возможно, что AlphaGo делал их потому, что в тех играх, на которых его обучали, игроки, делавшие подобные ходы в йосе, побеждали чаще чем проигрывали. Но AlphaGo не знает, что человек скорее всего сделает подобный ход только для того, чтобы получить один лишний период бёёми.zuborg
15.03.2016 17:38+2Слово "понимает" напротив, вполне усместно и корректно. Пониманием обладает не тот, кто знает (помнит из прошлого опыта) некоторые частности, а тот, кто имеет адекватную модель объекта понимания (чем более адекватная модель — тем глубже понимание). Наличие адекватной модели позволяет делать предсказания (т.е. моделировать, прошу прощения за тавтологию) — как раз это отличает понимающего субъекта от непонимающего.

ArisChik
15.03.2016 18:34По моему личному мнению, «понимает» это тот, кто можеть дать мотивацию поступку. При чем, желательно чуть более глубокую чем, «в 63,2876% игроки с таким ходом побеждали». Потому что это лишь статистическое наблюдение, а не объяснение почему именно в 63,2876% игроки с таким ходом побеждают.
И в этом все еще принципиальная разница между ботом и человеком: машина не может декодировать свои ходы, не может вывести их мотивацию из числовых признаков своей сети, не может вести онлайн, как комментатор-человек и объяснять почему игроки за столом принимают те или иные решение.
Это сугубо вычислительная машина, которая намного лучше просчитывает дерево игры, позциии, стратегии и вероятности исхода, но не понимает их.zuborg
15.03.2016 18:55+2Я понимаю что Вы хотите сказать своим коментарием )
Тем не менее, когда Вам кажется, что Вы в состоянии объяснить мотивацию хода словами, типа "ход сюда оказывает поддержку этой группе камней и защищает от соединения вот этих вражеских групп" — это иллюзия. Мозг игрока учитывает множество факторов из имеющегося опыта, и не все из них в состоянии быть адекватно вокализированы подобным образом. Анализ хода происходит на более глубоком и тонком уровне, где слова не играют никакой роли.
Расширю свою мысль из предыдущего коментария — обладание пониманием игры Го означает не возможность подбирать слова для объяснения хода. Понимание игры означает возможность адекватно (в идеале — абсолютно точно) оценить позицию, оценить перспективы одного хода относительно другого. В некотором роде понимание AlphaGo есть не широкое (программа не может оценить, приведет данный ход к соединению указанных групп или нет), но более глубокое в частном узком вопросе — какой ход более выгодный для победы. Конкретно текущую реализацию натаскивали на этот частный вопрос, но в целом это можно сделать и для других вопросов, без изменения архитектуры.Heath
15.03.2016 19:11Спасибо, вы как раз излагаете мою позицию. Я уверен, что «объяснения» следуют за выбором хода. Известно, что человек рационализирует своё решение через некоторое время после принятия решения. И АльфаГо именно что «понимает» Го. Она не может его объяснить — для этого отсутствует встроенная грамматика. Но идеи внутри неё есть.
zuborg
15.03.2016 19:41+1Ваша позиция мне близка и понятна )
В даном случае идет вопрос согласования интерпретаций такого понятия, как "понимание" — разные люди просто вкладывают в это понятие разный смысл, отсюда в большинстве случаев и возникают споры вокруг "понимания". Я придерживаюсь мнения, что "понимание" имеет отношение к воссозданию работающей в должной мере некоторой мысленной модели (не аналитической) объекта понимания — тогда понимающий субъект в состоянии мысленно воспроизвести интересующие его аспекты объекта понимания.
Но идея насчет идей внутри программы немного спорная. Само понятие "идея" соотносится с аналитическим мышлением, тогда как архитектура AlphaGo лишена этого аспекта. Максимум, что мы можем увидеть по логам — это результат оценки хода.
Даже если внутри сети и есть группа нейронов, отвечающих за качество формы, или распознавание вилки, или ко-угрозы (последний случай наверняка нет), не думаю, что будет правильным утверждать, что AlphaGo обладает соответствующей идеей (хотя и будет ею (а точнее — соответствующей группой нейронов) пользоваться при принятии решения).
ArisChik
15.03.2016 19:52+1Я понимаю Вас, интересная мысль. Просто мы говорим о разных «пониманиях». В том смысле, в котором вы пишите, это, пожалуй, таки понимание игры, как объективный расчет лучшего хода на более глубоком уровне, из-за более технических особенностей. AlphaGo способен расчитать дальше и глубже и более адекватно оценить позциии, выбрав лучший вариант из дерева решений, что можно трактовать, как понимание.
Но, все-таки, в широком смысле вряд ли машины способны «понимать» в схожем к нам ключе. Особенно это заметно, если расширить варианты ответов из «бинарных» на поле вещественных. То есть, довольно просто оценивать машину пока мы играем в абстрактную игру всего с 2-мя исходами: победа или проигрыш. А если добавить «социальный» элемент?mihaild
15.03.2016 20:09+1AlphaGo как раз и играет на вещественных числах (она каждым ходом максимизирует вещественное число — вероятность выигрыша).
Любой "социальный" элемент должен сводиться к вещественным числам (см. VNM utility theorem).
zuborg
15.03.2016 20:13+1Да, понятие "понимание" имеет не только объективный (понимания процесса или объекта), но и социальный аспект — понимание собеседника (противника, партнера..). Интерпретация понимания как моделирования работает и в этом случае:
Когда два субъекта общаются друг с другом посредством речи — они тоже воссоздают у себя в мозгу ментальную модель собеседника (узкую, разумеется, только относительно обсуждаемого вопроса). Если достигнуто взаимопонимание — модели согласованы с действительностью и дают хороший предсказательный результат — субъект А может смоделировать, как будет воспринята его речь субъектом Б и подобрать соответствующие слова, чтобы достичь нужного результата.
Разумеется, ни одна программа на текущий момент не может и близко подойти к такому уровню понимания людей — слишком глубокий разрыв в данных. У программ просто нет соответствующих знаний об окружающей среде, включая психилогию людей, тогда как каждый человек получает их во время своего взросления и воспитания.
Каким бы глубоким не было понимание игры Го сетью AlphaGo — это ещё катастрофически далеко до более обширного понимания вселенной, чтобы называться действительно сильным ИИ.
impetus
15.03.2016 20:42+1Разумеется, ни одна программа на текущий момент не может и близко подойти к такому уровню понимания людей
В пусть и несколько специфической «беседе» вида «партия игры в Го» — программа продемонстрировала просто идеальное понимание партнёра-человека.
Platon_msk
15.03.2016 18:58+1Вы противоречите сами себе. Мотивация «в 63,2876% игроки с таким ходом побеждали» достаточно обоснованна и не строится на «интуиции». Человек зачастую поступает именно так. И да, машина может обосновать каждый свой ход. В логах у неё наверняка содержится полная цепочка, приведшая к выполнению хода. Человек же, особенно в условиях цейтнота, зачастую делает «интуитивные» ходы.
ArisChik
15.03.2016 19:28+1-->> Человек зачастую поступает так
Да, но это не означает, что он понимает, что он делает. И это как раз и есть «интуция» — принятие решений без объяснимых на то оснований.
-->> В логах у неё наверняка содержится полная цепочка, приведшая к выполнению хода
Не в случаи с машинным обучением. Оно построено на признаках, которые описываются числовым путем и не допускают качественного выражения. Например, как простейшая нейронная сеть обучается распознавать рукописные числа? (Handwritten digits)
Оцифрованные записи с числами приводятся к единому формату (например, ЧБ 256x256), потом декодируются в матрицу 256x256, где 1 отмечается наличие ручки в этом пикселе, 0 — отсутствие. Например, так:
1 1 1 1
0 0 1 0
0 1 0 0
1 0 0 0
И каждая такая матрица в тренировочной выборке имеет правильный ответ (в моем случаи, это 7). А дальше задача нейронной сети — подобрать такую конфигурацию «фич» (features) для каждого из своих скрытых слоев, что бы при применении этого набора features вероятность правильного ответа на выходе нейронной сети была максимальной. Есть разные алгоритмы для этого (например, back-propagation neural networks), но features — просто матрица некоторых вещественных чисел, не более того.
Далее вы можете этой нейронной сети «скармливать» уже «реальные» данные, а она будет отвечать, что за число написано, НО, это не означает, что нейронная сеть ПОНИМАЕТ, что за число написано. Оно вам не скажет «вы дали мне число 0, потому что на рисунке изображен замкнутый овал, наклоненный вправо от центральной оси». Просто у нее внутри существуют матрицы чисел, полученые путем обучения на множестве тренировочных данных, применение которых говорит, что это, скорей всего, число 0.
Именно по этому машинное обучение все еще во многом исскуство, не только наука: найти и подобрать признаки, которые можно использовать для обучения, привести их к единому формату (выразить категориальные и качественные в количественном виде), скомбинировать и дать объяснение результату — это все еще задача человека.mihaild
15.03.2016 19:43+3Вопрос, может ли машина мыслить, не интереснее вопроса, может ли подлодка плавать.
Человек тоже построен на признаках, которые описываются числовым путем. Просто наше мышление заточено под компактное описание таких признаков — нам интуитивно кажется, что утверждение "камень падает" "проще" уравнений механики (например).ArisChik
15.03.2016 20:59+1Подлодка не может сама решить «как ей плавать» и от умения плавать, например, вперёд-назад она не научится сама плавать боком. А вот человек сам способен обучаться — достаточно его научить не тонуть.
mihaild
15.03.2016 21:16+1А человек не может сам решить, проваливаться ли ему сквозь пол.
Вообще, "обучение" — это просто удобная модель. Никаких специальных законов физики для "обучения" новым процессам нет. Монетка, положенная на стол, "учится" лежать на нем той стороной, которой положили.

grozaman
15.03.2016 18:35+2Автор статьи как раз говорит:
> Мы старательно пытаемся доказать себе, что как вид являемся венцом эволюции
И поэтому воспринимаем в штыки, когда какой-то там AlphaGo «понимает» игру лучше чем мы.
Люди недооценивают возможности нейронных сетей и не видят, что эти нейронные сети есть узкие реализации возможностей человека.bobermai
15.03.2016 18:37+2Эм… Серьезно? Подъемный кран с легкостью поднимет груз куда больший, чем любой штангист, уже можно начинать комплексовать по этому поводу?
grozaman
15.03.2016 18:40Нет. Я немного абстрагировался и сказал в целом. Люди недооценивают возможности ИИ и в конечном итоге человечеству это может влететь в копеечку, когда весьма внезапно будет реализован первый сильный ИИ.
Heath
15.03.2016 19:15Дело в том, что АльфаГо не ИИ. Это выносная копилка для опыта и идей про Го, как Википедия — копилка для знаний, оформленных в тексте по определённым правилам. До ИИ ещё пахать и пахать.
grozaman
15.03.2016 19:22+3AlphaGo отлично подходит под определение слабого ИИ. Инструмент для игры в Го.
Вашим определениям также не противоречит. До сильного ИИ бесспорно ещё пахать и пахать. А слабый ИИ сейчас сплошь и рядом.
impetus
15.03.2016 20:20+5Уже ПОЗДНО комплексовать по этому поводу — но таки да, когда появились первые подъёмные краны — это было крутейшим читерством.
Социумы. так и не принявшие новой реальности — тупо вымерли.
Задолго до того таким читерсвом была, например, лошадь.… колесо, парус, лук, разделение труда, письменность, огнестрел, танковые клинья… Вот до нейросетей дожили — круто!sim31r
16.03.2016 01:28Сильная нейросеть принципиально отличается от вами перечисленного. Что рабочий, что машина управляются своим, человеческим разумом, разница только в количестве подведенной энергии.
Здесь же, идет речь о зачатках (пока что) чужеродного разума, масштабируемого, не ограниченного ни чем. Я думаю так же, как и Стивен Хокинг, если что, он предупреждал.
ArtificialLife
15.03.2016 21:00Нет же, штангисты будут в ужасе когда антропоморфные роботы будут толкать штанги весом больше, чем у них.
sim31r
16.03.2016 01:21+1Человек скорее всего тоже «понимает» на таком же уровне. Вряд ли человек мастер, сможет обосновать ход, который ему подсказала интуиция. На вопрос почему? Не будет внятного ответа. Так как сильный ход генерирует нейронная сеть, что у человека, что у компьютера, у НС нет логичного обоснования в традиционном понимании.
Более того, некоторые навыки, даже мастера не могут передать ученикам, обучение учеников отдельный навык. Со стороны выглядит так что человек делает что-то, и делает хорошо, а объяснить ни как не может. Хоть взять пример с катанием на велосипеде, нейронная сеть просчитывает дифферинциальные уравнения в реальном времени, но прячет процесс в глубине своей структуры, куда нет осознанного доступа.
Надо сказать спасибо разработчикам AlphaGo уже за то, какую они дали пищу для размышления об основах разума.
GreenGoblin
15.03.2016 17:34+4Почитал, интересно. Однако, думаю, вы все-таки несколько переоцениваете важность события. В сущности, инженеры гугла всего лишь сумели прикрутить к монтекарловскому брутфорсу хорошие эвристики на основе сверточных нейросетей. Кто интересовался этими вещами, тот знает, что в алгоритмах машинного обучения нет никакой магии. Нейросеть, обученная на человеческих играх, выходит за человеческие рамки только благодаря нечеловечески быстрому перебору вариантов. Игры с собой — это просто удачный способ генерации данных для обучения, вроде как алгоритмы распознавания символов тренируют на искаженных/зашумленных картинках. Ничего принципиально нового, того, чего не было бы в изначальном датасете, нейросеть оттуда не извлечет. У неё даже с извлечением простейших абстракций большие проблемы. Именно поэтому успех применения машинного обучения зависит в первую очередь от подготовки входных данных. Например, среди фич альфагошной нейросети есть число степеней свободы группы и наличие ханэ для каждого хода…
В общем, гугл молодец, за го обидно, но в деле создания сильного ИИ этот успех мало чего изменил.zuborg
15.03.2016 17:41+2То, что довольно банальная концепция внутреннего устройства AlphaGo показала себя настолько сильно — это просто поразительно.
Мы ещё не знаем, что в итоге понадобится для создания сильного ИИ, вполне может быть, что его создание произойдет так же заурядно — кто-то просто соединит нужные ингредиенты в нужной последовательности.bobermai
15.03.2016 17:51+2вы уверены, что сильно повела себя именно концепция, а не тупое превосходство в вычислительной мощности? На мой взгляд тот факт, что человеку постоянно не хватало времени, свидетельствует скорее о втором.
zuborg
15.03.2016 18:12+1Прошу прощения, но по вычислительной мощности Вы не сможете тягаться со своим собственным телефоном — но это не делает телефон чем-то исключительным. А тупо вычислять варианты в Го никак не могут привести к победе программы над человеком, это стало понятным ещё давно.
Устройство AlphaGo относительно несложное, что-то подобное может реализовать сейчас любой специалист по нейронным сетям (уверен, что счет таких попыток уже идет на сотни или даже тысячи). Конечно, не факт, что это не тупиковая ветвь на пути к сильному ИИ, но кто знает, кто знает..bobermai
15.03.2016 18:22+1Ну да, варианты вычисляются не тупо, а умно.
Что тоже не делает это чем-то исключительным :)Heath
15.03.2016 19:16+1Варианты не вычисляются. Нейросеть — это не алгоритм. Там внутри неё копится неотделимая от нейросети магия. :)
bobermai
15.03.2016 19:18+2Так и до поняшек недалеко :)
grozaman
15.03.2016 19:32+1То что люди называют «интуицией», «дежавю» и т.д., есть побочный эффект работы нашей нейронной сети. Вы правда думаете, что ваш мозг «просчитывает» и «вычисляет» нужные варианты, чтобы случайно увидеть дежавю?
Nadoedalo
15.03.2016 20:20+1Эм, дак вроде «дежавю» объясняется тем что одно из полушарий сработало медленнее другого, а потом фантазия и подстройка других воспоминаний. Вообщем-то стойкое ощущение дежавю — следствие офигенного сжатия с потерями и медленной скорости распространения сигнала.
grozaman
15.03.2016 20:37+2Точного объяснения вроде пока никто не нашел. Всё лишь догадки.
Далее не претендую на научность, так что имхо:
Лично для себя объясняю это тем, что когда мозг всё это складирует в долговременную память, то увидев какой-то особый паттерн в реальности, мозг как бы смотрит на всю эту огромную кучу сохраненных ранее визуальных образов и пытается вычленить похожие образы, используя только что увиденный паттерн. Это на мой взгляд создает ощущение пронизанности сквозь всё прожитое прошлое.Nadoedalo
15.03.2016 21:03+1Эм. Попробую ещё раз объяснить.
У нас «два ядра»-полушария, они оба и по-разному обрабатывают информацию. Иногда информация одним ядром уже обработана, а другим ещё нет. Когда второе ядро обработает эту информацию — нам покажется что где-то мы это уже видели, потому что похожий образ лежит в кратковременной памяти. Вот только шерстит мозг при попытках вспомнить — долговременную и сравнивает с образом в кратковременной. Находит похожий паттерн и наполняет его чертами из кратковременного(либо не наполняет если не нашлось, тогда просто чувство дежавю мол где-то видел а где — хз).
Т.е сравнение с долговременной памятью постоянно не происходит т.к на это нужно много усилий(прошерстить сколько там, петабайт сжатых данных?). А вот на устранение коллизии потратится приходится. Потому и дежавю. Пока тупишь «где-то-я-это-уже-видел» мозг устраняет ошибку =)grozaman
15.03.2016 21:41+1Так понятней, понял Вас.
В любом случае это плод сложной работы не имеющей отношения к вычислениям или перебору.
sim31r
16.03.2016 01:56+1Это одно из возможных объяснений. Но оно не идеально. Вот, например, я вспоминаю IP адрес сервера и его расположение. Вообще помню ничего сначала. Оба полушария думают, но ответа нет. Через минуту вспоминаю где сервер в все его параметры. Но нет и намека на дежавю, сначала просто тупо не помнишь, потом вспоминаешь во всех деталях.
Если следовать вашему объяснению, то любое воспоминание приведет к дежавю, одно полушарие вспомнило, другое нет, и начались мозговые глюки. По факту же происходит реже (раз в год?), у некоторых вообще нет такого, скорее всего объяснение сложнее.
Упрощенно объяснить можно и термоядерный синтез, создали плазму погорячее и черпаем энергию. Но это же не имеет отношения к реальности, просто одно из правдоподобных, псевдонаучных объяснений.
Я тоже могу предложить псевдонаучное объяснение. Дежавю воспопинание из бэкапа, не «настоящее». Если в мозге возник микроинсульт, или по другой причине повредился мельчайший блок памяти, мозг перекинул данные из умирающих клеток в свободные, но с потерей части данных (индексная таблица какая-то). Вроде данные есть, лежат на всякий случай (вдруг пригодятся для выживания), но с рядом проблем для восприятия. Вот когда мозг натыкается на эти данные, возникают обильные глюки — дежавю, сознание глючит, хоть и мозг маскирует процесс как может, а в это время восстанавливается информация по возможности (начиная с того, вообще она была ли?).
Мое обоснование, дежавю похоже на то что описывают наркоманы, мозговой трип (ух как заглючило). Но трипы возникают при отклонении работы мозга от нормы, разрушительном отклонении, когда сбиваются процессы и часто необратимо (например: я понял что я гриб и эта мысль всегда со мной). Мозг, к сожалению не AlphaGo, постоянно в режиме контролируемого разрушения после 12 лет примерно, нейроны и связи между ними теряются день за днем по разным причинам.Nadoedalo
16.03.2016 02:19+1Почему же любое? Процесс мышления сейчас описывают как волну по всем нейронам/связям и откликаются по сути все связи. Но если подряд получить 2 «равноправных» отклика — получаем ошибку. Где-то даже статья была на хабре по поводу того «как мы думаем».
А само обоснование кажись у научпока было, хотя и это всего-лишь гипотеза
PS трипы не делают ничего такого чего нельзя было бы сделать и без вещества, разве-что стимулируют на активность — хоть в виде «глюков», хоть в виде размышлений о чём угодно. Общие примеры — медитация, НЛП. Частный — создание тульпы. Да и вообщем-то каждый раз когда фантазируешь или «входишь в поток» — ты отправляешься в трип
PSS большинство психоактивных веществ вообщем-то не токсичны и дозы самого вещества крайне малы что бы иметь возможность разрушить сколь-либо значимое количество клетокsim31r
16.03.2016 02:47+1По аналогии с ПК. Главная ценность у большинства пользователей, не железо, а данные. Для мозга это еще более актуально, микродозы может и не повредят мозг физически, но могут вызвать изменение сознания, изменение мотивации (овощезация), навязчивые идеи.
Даже шизофрения может развиваться как заражение от общения с шизофреником, есть статистика. Сбойная логика одного человека, неосознанно копируется другим при общении. Общение с человеком с высоким IQ повышает IQ (немного, но статистически заметно), общение с дураком атрофирует мозг.
А тут речь о химических веществах действующих напрямую на мозг. Очень опасные эксперименты.Nadoedalo
16.03.2016 03:04+1Да что угодно вызывает изменение сознания. Еда и питьё вызывает. Дыхание и его отсутствие вызывает. Любые конкретные и абстрактные вещи вызывают изменение сознания. Сам факт того что Вы читаете это сообщение — изменяет Ваше сознание.
Эффекта трипа можно достичь даже с помощью медитации.
PS т.е если я считаю что я умнейший человек на планете — мне не стоит общаться с другими людьми потому что отупею? А откуда я знаю что Вы не шизофреник и не заражаете меня сейчас?
PSS вещества, действительно, могут обернуться проблемами с психикой, в том числе психическими заболеваниями. Но только в том случае если есть к этому предрасположенность/находится в латентном состоянии
PSSS Вы мечтаете? Значит Вы шизофреник. Где-то была такая статейка =)sim31r
16.03.2016 03:52+1Что угодно вызывает изменение сознание, но обычно в небольших пределах.
Медитация бывает разная. При помощи НЛП тоже вводят в транс, а потом зомбируют и превращают в боевиков ИГИЛ, даже успешных людей (например актер Дорофеев что снялся в главной роли «Дочь якудзе»), уже пропал в Сирии, бросив жену с новорожденным ребенком.
Если вы умнейший человек, тогда вам интересно будет общаться с умнейшими людьми. Действительно не стоит общаться с даунами, не интересно как минимум, о чем говорить то?
О том что была предрасположенность, обычно узнают уже после, когда поздно. Надо ли проверять, есть ли предрасположенность к психическим заболеваниям, проверяя организм на прочность? После тяжелых наркотиков понятно, выживут только самые сильные, и что? Получается это форма разрушения мозга, предрасположенные страдают сильнее, остальные почти не заметно (особенно для себя, со стороны может быть заметно).
По поводу мечты я поискал материал, действительно, есть связь мечты и шизофрении, всего должно быть в меру (мечта мечте рознь), пример клинического случая (можете поискать подобное):
А за долго до моего первого попадания в психушку я любил и люблю мечтать. Я мечтал целыми днями, причём не просто мечтал а метал с воображением. И молился я мечтательно. Напр во время молитвы воображал произвольно Бога, Святых и тд. У меня начался бред на религиозной почве. Я начал слышать голоса и думал что это говорит Бог.
Но как же я заблуждался. Потом у меня началась жуткая депрессия с отчаянием. Я ничего не мог с собой поделать и мне хотелось покончить с собой. У меня помимо слуховых галлюцинаций были ещё и зрительные. Это был ад какой то.Nadoedalo
16.03.2016 04:10+1Достаточно умный человек найдёт о чём пообщаться с другим человеком любого уровня интеллекта если он достаточно замотивирован(имеет интерес). Можно даже с резиновой уткой пообщаться(Rubber duck debugging)
Предрасположенность проверяется очень просто — если были психические отклонения в семье(кажись до дедушек-бабушек) то предрасположенность есть. Иначе — на свой страх и риск, потому что скрытые проблемы с психикой выявить достаточно сложно, если не невозможно.
Я абсолютно не мотивирую применять любые вещества, но и не имею ничего против рекреационного их применения.
А что на счёт «начал мечтать и съехал с ума» — тут проблема в «железе» а не в «софте». В теории можно и без «железа» сделать так что бы мозг мог «глючить»(опять таки — НЛП, медитации, создание тульп — вот это всё), да он вообщем-то и так глючит постоянно в профилактических целях(пример — фантомные вибрации телефона). Просто мы считаем незначительные глюки — нормой и чаще всего просто не замечаем их.
PS ту же шизофрению успешно лечили с помощью психоактивных веществ
Zhrun
16.03.2016 11:08А нельзя ли натравить AlphaGo на поиск этих самых ингредиентов необходимых для создания сильного ИИ ?
bobermai
16.03.2016 12:07+1Эм… Сдается мне, что тут все та же проблема — " AlphaGo обыграл человека в интеллектуальную игру, значит, он может думать, давайте дадим ему другую задачу на "думать"". Нет. Он не может думать. Он — специализированный механизм, спроектированный и настроенный для игры в го. Даже играть в шашки он сам по себе не может.
GreenGoblin
15.03.2016 18:25+2В комментарии нелепая ошибка, не знаю, как это получилось, но необходимо исправить. Не ханэ, а ситё.

liddom
15.03.2016 18:59+1в алгоритмах машинного обучения нет никакой магии.
Я полагаю, и в алгоритмах работы человеческого мозга тоже нет никакой магии. Просто большое количество нейронов, определенная степень связности. Конечно, сама архитектура сети тоже важна, но там, мне кажется, тоже никакой магии не спрятать.sim31r
16.03.2016 02:03+1Эволюцию ИИ можно связать с эволюцией разума на планете у животных. Уровень бактерий, насекомых пройден. В целом ИИ сравним с разумом птиц, например. У них крошечный мозг, специализированный на обработке изображений разум. До человека ИИ не дотягивает, так как у людей есть универсальное абстрактное мышление, вероятно надстройка над нейронной сетью, причем очень разная у всех людей.
impetus
15.03.2016 20:29+2инженеры гугла всего лишь сумели прикрутить к монтекарловскому брутфорсу хорошие эвристики на основе сверточных нейросетей.
(пожимая плечами) типичный «маленьгий шаг одного человека»… Глядя на посудины «эпохи великих географических открытий» — вот так оно часто и бывает — на обычных в общем-то для современника инструментах (кораблях и экипажах) человечество и вплывает в новую реальность. Это только для ракет и атомных бомб потребовались весьма неординарные сверхусилия, чаще прогресс эволюции идёт более мелкими шажками
Vadim-Zero
15.03.2016 22:16-2Сильный ИИ не более чем филосовская спекуляция…
GreenGoblin
15.03.2016 22:29+2Потому что мы созданы по образу и подобию Божию, а бездушная железяка в принципе не может думать? =)
Vadim-Zero
16.03.2016 16:53Под думанием можно понимать любую внутреннюю комуникацию в ПО. А филосовский пафос возводит думанье в ранг чего то очень важного. Тоесть в думаньи нет не чего сильного, скорей мышление не более чем артефакт второй сигнальной. Дико медленный способ внутреней комуникации.
u010602
15.03.2016 19:03+1А я не согласен с этим:
Причина, по которой AlphaGo не претендует на разрушение человеческой культуры Го, проста: новые смыслы, которые уже созданы (sic!) внутри нейросети, никак не передать напрямую обратно в людей.
Передать вполне возможно, примерно как играя с немым или иностранцем, язык которого вы не знаете. Пытаясь понять как он играет, вы получите себе, его идеи, пускай и с погрешностью. Знание субъектом человеческого языка не всегда идет на пользу идеям. Например иногда программный код понятнее комментариев к нему написанных. И иногда понять что хотел сделать человек проще по его коду, чем по его не принужденным рассказам.
Кроме того Википедия сама себя не развивает, не структурирует, не наполняет, это делают люди. А АльфаГо будет эволюционировать идеи и без человеческого вмешательства.Heath
15.03.2016 19:20+1Нет, чисто от игры вы не получите идеи. Вы получите только опыт, который (возможно) вы сможете рационализировать, преломляя его в призме своего предыдущего опыта. Идеи человека тотально опосредованы его физиологией, окружающей реальностью и накопленной культурой. АльфаГо — это «чистое Го», её «идеи» не имеют вообще никаких семантических аналогий с человеком, они просто там эволюционируют с каждой итерацией игры против немного меняющейся копии.
u010602
15.03.2016 20:10Не больше чем в мозгу инвалида-маугли. Т.е. у АльфаГо тоже есть свой контекст. Ведь он обучался на человеческих партиях, т.е. он изучал и наши культуры через Го. Возможно там внутри он определяет, что игрок азиат, просто не знает кто такие азиаты. Ну и когда я играю в шахматы у меня например нет ни каких аналогий с реальным миром, и названия фигур только сбивают с толку, и я не могу объяснить как я играю. Чем это отличается от АльфаГо?
Kornet
15.03.2016 20:53Статья хорошая. Только непонятно, почему, что вы, что marks пишете название игры го с большой буквы? Из уважения к древности? Тогда и Шахматы надо писать с большой буквы.
В английском название пишется с большой буквы для различения с глаголом "go". В русском для этого нет причин. Как и "шашки" или "нарды", "го" пишется с маленькой буквы.

Alexey2005
15.03.2016 17:34+1А ведь мозг человека тоже представляет собой нейросеть, причём нейронов там больше, а связи между ними гибче. Возможно, изменением методики тренировок удастся натренировать и человека так же играть?
Например, скормить живому мозгу все 130 тыс. партий, разбив на фрагменты, как разбивали для AlphaGo. И чтобы человек не пытался строить планы, что-то там организовывать, а играл просто на нейросети, на одних набитых рефлексах, даже не понимая смысла игры.
zuborg
15.03.2016 17:45+1Мозг человека затачивался эволюцей под другие задачи, тренировки тут влияют, но не принципиально.
Может быть когда-нибудь генная инженерия достигнет уровня, когда можно будет создать ДНК организма, заточенного под игру Го, а пока приходится решать эту задачу в кремнии, а не органикой.impetus
15.03.2016 20:49+1мозг человека наблюдаемо избыточен практически для любых задач — успешность человека в живой природе сравнима с несравнимо более примитивным волком например. Или крысами. Подо что и как затачивался мозг человека — вопрос на сейчас скорее открытый — есть например гипотезы что это типа павлиньего хвоста — чисто украшательство полового отбора, а все успехи цивилизации — мелкие побочные бонусы использования уже и так имеющегося инструмента.
Nadoedalo
15.03.2016 21:15+2Что-то я не вижу прямой связи между интеллектом и количеством девах/детей. Скорее даже наоборот.
mihaild
15.03.2016 21:19+1В современном обществе уже нет, но любой современный человек гораздо умнее любого первобытного. А способность, например, убедить конкурента что ему надо идти вон в ту пещеру (где сидит медведь) — сильно помогает.
sim31r
16.03.2016 02:26+1Вообще-то племя с таким отношением к ближним мгновенно исчезало. Внутри племени, как-раз типично отношение «сам погибай, а товарища (детей) выручай». Чужаков с вредными советами просто прогоняли не вступая в диалог. По мере глобализации, традиционная мораль стала архаизмом, а навыки обмана основой благополучия.
Современный человек умнее. IQ растет на 10 единиц за 100 лет, хотя бы за счет питания, обилия информации и образования, реализуется весь генетический потенциал, который ранее был забит голодом, холодом и дефицитом информации.Nadoedalo
16.03.2016 03:21+1Вообще-то эксперименты показывают что в ЛЮБОЙ группе животных(на крысах тестировали + статистика по людям) разделение происходит на «социальных», «асоциальных» и «психопатов» в соотношении 75/20/5. Тестировалось просто — давали 2 педальки — одна кормит другую крысу, другая бьёт током. Крысы существа социальные и когда видят что делают другой крысе больно — перестают это делать.
Разделение это происходит в любой группе, это модель поведения социальных групп а не генетическая предрасположенность.
Объясняется это тем что так выгоднее всего для выживания группы — у социальных крыс вместе шансов выжить обычно больше. Но и «сливаются» всей группой, так что 25% это «бэкап» — шансов на выживание у асоциальных крыс выше, а у психопатов он ещё выше.
В человеческом обществе психопатами по воле или неволе становятся лидеры групп т.к только их модель поведения выгодна всей группе.
Так что люди убивавшие других людей ради выгод/забавы были всегда. Просто обычно их очень мало, и не думаю что высокоразвитый интеллект это их наследие.
PS интеллект — средство выживания а не размножения. «Эволюции» в целом выгодно когда есть чего пожрать и больше напрягаться не надо, но и останавливать мутации никто не собирается. Повышенный/пониженный интеллект — всего-лишь мутация
PSS IQ не может расти, 100 баллов это «средний человек»mihaild
16.03.2016 03:32+1Можно ссылку на то, откуда взято такое объяснение?
Я всегда думал, что отбор не может делать "бекапы". И закрепляет он только то, что помогает размножению (например, ген делающий своего носителя бесплодным, но увеличивающий срок жизни в 10 раз, закреплен не будет). А если бы был ген, "останавливающий" мутации — он бы распространился по всей популяции (т.к. мутации в среднем вредны), после чего популяция благополучно исчезла при изменении условий.
Пример: пусть время от времени возникают события, которые требуют чтобы одна особь пожертовала собой для спасения вида. Пусть в популяции откуда-то есть ген, обладатели которого жертвуют собой в такой ситуации. Со временем распространенность этого гена будет падать — пока не достигнет нуля, после чего вид вымрет.Nadoedalo
16.03.2016 03:42+1Дать ссылку на моего дядьку? :D Я конечно спрошу, но вряд-ли он разрешит =)
А вообще должно легко гуглится.
PS распределение социальное а не генетическое. Один и тот же человек в разных ситуациях может взять другую роль себе, например — стать психопатом. Классический случай — убийство члена группы ради блага всей группы(вынужденный каннибализм например) — до этого все были «социальными», но кто-то ведь должен это сделать?
PS те же механизмы у альфа-бета-омега «психики»
liddom
16.03.2016 07:35+1Пример: пусть время от времени возникают события, которые требуют чтобы одна особь пожертовала собой для спасения вида. Пусть в популяции откуда-то есть ген, обладатели которого жертвуют собой в такой ситуации. Со временем распространенность этого гена будет падать — пока не достигнет нуля, после чего вид вымрет.
Если это приводит к выживанию родственных особей в которых вероятность наличия этого же гена больше единицы, то ген будет распространяться в популяции. К примеру, выгодно пожертвовать собой для спасения трех своих детей: 0.5 — вероятность наличия гена в каждом из детей. Также выгодно для спасения 5 двоюродных братьев(вероятность наличия гена в каждом — 0.25). При социальных группах, связанных сильным родством, это вполне себе хорошая стратегия выживания.mihaild
16.03.2016 13:23Если носитель гена больше полезен родственникам, чем случайным представителям вида — то да, будет распространяться. В моем (точнее, Юдковского) примере важно, что дискриминации нет — помощь одинакова для всего вида.
mihaild
16.03.2016 03:27+1Это было утрирование. Но конкуренция в любом случае есть — и более высокий интеллект помогал оставить больше потомства.
Nadoedalo
16.03.2016 03:36+1Только потому что позволял добывать больше еды в изменяющихся условиях — соотвественно мог прокормить больше потомства.
Это я к тому что интеллект не внутривидовое преимущество а межвидовое. Сейчас выживать не надо — в итоге «высокий» интеллект не культивируется.mihaild
16.03.2016 13:27"Преимущество" — это уже более высокий уровень абстракции. Чтобы ген распространился, нужно, чтобы у его носителей было больше потомства, чем в среднем по популяции. Т.е. нужно быть не только умнее тигра — нужно быть умнее соплеменника.
sim31r
16.03.2016 02:17Вообще-то мозг человека недостаточен(!) для любых задач. Примеров тысячи, начиная с врачебных ошибок, немного выше бы сильнее интеллект врача, и спас бы жизнь. На этом ресурсе, мне кажется, всем очевидно, что каждый хочет понимать больше, но часто натыкается на предел возможностей мозга (это очевидно, если глянуть на формулы квантовой механики, интересные, но малопонятные).
Мозг человека просто не мог быть еще совершеннее, и то что есть, потребляет 10% энергии организма, при массе в 1%. Больше просто некуда, при дефиците ресурсов в процессе эволюции, колоссальная нагрузка на организм.
Успешность человека даже в живой природе, на порядок выше волка. Приоритет настолько высок, что человек даже потерял клыки и когти, толстый череп и кожу, шерсть, не нужны они, есть более сильное оружие.
bobermai
15.03.2016 17:48+1Если вы возьмете человека, с рождения ничего кроме доски не видящего, и будете его тренировать, с поощрениями и наказаниями, а заодно обрежете ему биохимию так, чтобы гормоны не влияли — наверное, получится. Только зачем?
sim31r
16.03.2016 02:31+1Не получится, есть предел для развития. Почитайте биографии шахматистов, некоторые стали фанатами шахмат с 5 лет, сами, такой у них личный выбор и они не жалеют. Но победить компьютер они не смогут. Просто из-за генетических ограничений мозга, количества нейронов, связей и быстродействия.
bobermai
16.03.2016 10:48увлеченный чем-то человек не равен человеку, которого внешними средствами ограничили рамками одной задачи.

sumanai
15.03.2016 18:00+1Большую часть нейронов мозга не получится задействовать в высшей нервной деятельности, так как в ней участвует только кора мозга.
Heath
15.03.2016 19:20+1Собственно, именно так с 5 лет тренируют профессиональных игроков в Корее. Ну, почти. :)


Old_Chroft
15.03.2016 17:56+1Случилось это после пяти часов напряженной игры.
Мне кажется тут имели место уже не только интеллектуальные способности.
Swillwo
15.03.2016 18:56+1Вот интересно, насколько долго "переключить" AlphaGo в режим, например, шахмат? Какой бы она показала результат в игре с DeepBlue?
GreenGoblin
15.03.2016 19:31+2DeepBlue сто лет в обед, если уж сравнивать, то с современными программами.
В общем-то, основная фишка альфаго — применение сверточных нейросетей — очень хорошо подходит именно для го. Точно так же хорошо для этого подходит наша зрительная кора, с которой в свое время сверточные сети и были срисованы.
Шахматы — немножко другое, оценка позиции сильнее зависит от взаимного расположения фигур, больше динамики, всяких неожиданностей… Но можно и на шахматы натаскать нейросеть, вопрос в эффективности по сравнению с альтернативами.mihaild
15.03.2016 19:46+2Видел как раз обратное утверждение — что в го более важна глобальная позиция, чем в шахматах (в шахматах даже перебор на несколько ходов перед с оценкой "каждая фигура стоит такое-то количество очков, суммируем всё" уже дает относительно неплохой результат).
Но в любом случае интересный вопрос, подходят ли нейросети для шахмат. (я не специалист по нейросетям, но до сих пор не "понимаю", как они могут работать и для го)

valemak
15.03.2016 19:39Сейчас уже в смартфонах более сильные шахматные программы, чем суперкомпьютер DeepBlue 20-летней давности.

KvanTTT
16.03.2016 01:07+1Я вот подумал, что мощный гошный движок, конечно, в будущем можно будет запустить хотя бы на обычном компе. Но действительно ли можно будет засунуть всю мощь AlphaGo в смартфон с учетом того, что частота процессора давно особо не растет, да и ядра до бесконечности наращивать не получится.
sim31r
16.03.2016 02:39+1Непонятно только, зачем в смартфон устанавливать альфаго, при дефиците в нем энергии (1 ход потребует 1 заряд аккумулятора?) и проблемой с охлаждением, если смартфон подразумевает собой онлайн режим и легкий доступ к изначальной альфаго, которая подскажет сильный ход за несколько секунд.
KvanTTT
16.03.2016 12:54Ну не всегда же смартфон подразумевает онлайн режим. Тем более интересна теоретическая возможность запуска мощного ИИ на таком устройстве, поскольку для этого потребуются качественные улучшения алгоритмов, а не количественные, что очень важно. А теперь представьте, что сможет делать суперкомпьютер при таких улучшениях алгоритмов.

RolexStrider
17.03.2016 00:03-1Итак, одна из сложнейших игр с полной, или как тут уточнили, совершенной информацией — не то чтобы пройденный этап… Но черт побери, знаковый. Тут в комментах проскакивало, что по всей вероятности, будучи вдохновленными успехом AlphaGo и простотой "кубиков" из которых она построена, куча народа уже пытается воспроизвести ее. Даже на ГитХабе видел уже минимум два проекта, и это три дня назад. А сегодня — их наверное стало за сотню.
Я это к чему. Starcraft — достаточно интересная ПРОМЕЖУТОЧНАЯ цель. А вот что будет интересно — безлимитный холдем на полном столе. И ни в коем случае не надо про Polaris и Cepheus — они в лимитный хедз-ап.
Bytamine
Вызов лучшему игроку уже отправлен?
i1yas
Хассабис вроде как дал устное согласие на матч с Ke Jie. Он номер один в Китае, и вообще негласно может считаться лучшим игроком в мире (у Ли Седоля он последний матч выиграл 8:2 ).
Vlad_Hm
Если АльфаГо за время подготовки к новому матчу сделает такой же скачок в качестве игры, как между игрой против Фань Хуэя и Ли Седолем, то у Ke Jie нет шансов.
Хорошая интрига, демонстрирующая темпы и пределы развития АльфаГо.