О хранении данных в Parquet-файлах не так много информации на Хабре, поэтому надеемся, рассказ об опыте Wrike по его внедрению в связке со Spark вам пригодится.
В частности, в этой статье вы узнаете:
— зачем нужен “паркет”;
— как он устроен;
— когда стоит его использовать;
— в каких случаях он не очень удобен.
Наверное, стоит начать с вопроса, зачем мы вообще начали искать новый способ хранения данных вместо предварительной агрегации и сохранения результата в БД и какими критериями руководствовались при принятии решения?
В отделе аналитики Wrike мы используем Apache Spark, масштабируемый и набирающий популярность инструмент для работы с большими данным (у нас это разнообразные логи и иные потоки входящих данных и событий). Подробнее о том, как у нас работает Spark, мы рассказывали ранее.
Изначально нам хотелось развернуть систему быстро и без особых инфраструктурных изощрений, поэтому мы решили ограничиться Standalone кластер-менеджером Спарка и текстовыми файлами, в которые записывали Json. На тот момент у нас не было большого входного потока данных, так что развёртывать hadoop и т.п. не было смысла.
О том, какая картина у нас была на начальном этапе:
- Мы стремились обойтись минимальным стеком технологий и сделать систему максимально простой, поэтому сразу отбросили Spark поверх hadoop, Cassandra, MongoDB, и другие, требующие особого менеджмента, способы хранения. Наши диски вполне шустрые и отлично справлялись с потоком данных, кроме того машины в кластере расположены близко друг к другу и связаны мощным сетевым интерфейсом.
- Входные данные у нас были плохо структурированы, поэтому выделить универсальную схему было сложно.
- Схема быстро эволюционировала из-за того, что мы постоянно добавляли новые события и улучшали трэкинг активности пользователей, поэтому выбрали json как формат данных и складывали их в обычные текстовые файлы.
- Мы стремились приблизиться к event-based аналитике. А в этом случае каждое событие должно быть максимально обогащено информацией, чтобы свести количество join операций к минимуму. На практике обогащение данных порождало всё больше колонок в схеме (это важный момент, мы к нему ещё вернёмся). Кроме того, из за большого количества событий совершенно разного рода, но связанных между собой и характеризуемых различными параметрами, схема также обзаводилась большим количество колонок и информация была достаточно разряженной.
- Мы работали с неизменяемыми данными: записали, а дальше только читаем.
После нескольких недель работы мы поняли, что с json данными работать неудобно и трудоемко: медленное чтение, к тому же при многочисленных тестовых запросов каждый раз Spark вынужден сначала прочесть файл, определить схему и только потом подобраться непосредственно к выполнению самого запроса. Конечно, путь Спарку можно сократить, заранее указав схему, но каждый раз проделывать эту дополнительную работу нам не хотелось.
Покопавшись в Спарке, мы обнаружили, что сам он активно использует у себя внутри parquet-формат.
Что такое Parquet
Parquet — это бинарный, колоночно-ориентированный формат хранения данных, изначально созданный для экосистемы hadoop. Разработчики уверяют, что данный формат хранения идеален для big data (неизменяемых).
Первое впечатление — ура, со Spark наконец-то стало удобно работать, он просто ожил, но, как ни странно, подкинул нам несколько неожиданных проблем. Дело в том, что parquet ведёт себя как неизменяемая таблица или БД. Значит для колонок определён тип, и если вдруг у вас комбинируется сложный тип данных (скажем, вложенный json) с простым (обычное строковое значение), то вся система разрушится. Например, возьмём два события и напишем их в формате Json:
{
“event_name”: “event 1”,
“value”: “this is first value”,
}
{
“event_name”: “event 2”,
“value”: {“reason”: “Ok”}
}
В parquet-файл записать их не получится, так как в первом случае у вас строка, а во втором сложный тип. Хуже, если система записывает входной поток данных в файл, скажем, каждый час. В первый час могут прийти события со строковыми value, а во второй — в виде сложного типа. В итоге, конечно, получится записать parquet файлы, но при операции merge schema вы наткнётесь на ошибку несовместимости типов.
Чтобы решить эту проблему, нам пришлось пойти на небольшой компромисс. Мы определили точно известную и гарантируемую поставщиком данных схему для части информации, а в остальном брали только верхнеуровневые ключи. При этом сами данные записывали как текст (зачастую это был json), который мы хранили в ячейке (в дальнейшем с помощью простых map-reduce операций это превращалось в удобный DataFrame) в случае примера выше ‘ “value”: {“reason”: “Ok”} ‘ превращается в ‘ “value”: “{\”reason\”: \”Ok\”}” ‘. Также мы столкнулись с некоторыми особенностями разбиения данных на части Спарком.
Как выглядит структура Parquet файлов
Parquet является довольно сложным форматом по сравнению с тем же текстовым файлом с json внутри.
Примечательно, что свои корни этот формат пустил даже в разработки Google, а именно в их проект под названием Dremel — об этом уже упоминалось на Хабре, но мы не будем углубляться в дебри Dremel, желающие могут прочитать об этом тут: research.google.com/pubs/pub36632.html.
Если коротко, Parquet использует архитектуру, основанную на “уровнях определения” (definition levels) и “уровнях повторения” (repetition levels), что позволяет довольно эффективно кодировать данные, а информация о схеме выносится в отдельные метаданные.
При этом оптимально хранятся и пустые значения.
Структура Parquet-файла хорошо проиллюстрирована в документации:
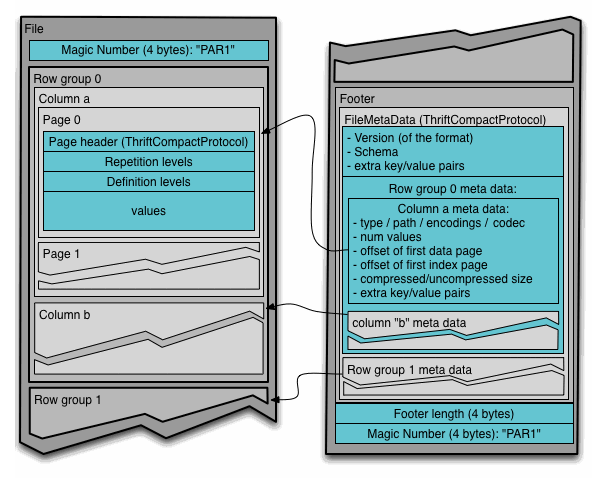
Файлы имеют несколько уровней разбиения на части, благодаря чему возможно довольно эффективное параллельное исполнение операций поверх них:
Row-group — это разбиение, позволяющее параллельно работать с данными на уровне Map-Reduce
Column chunk — разбиение на уровне колонок, позволяющее распределять IO операции
Page — Разбиение колонок на страницы, позволяющее распределять работу по кодированию и сжатию
Если сохранить данные в parquet файл на диск, используя самою привычную нам файловую систему, вы обнаружите, что вместо файла создаётся директория, в которой содержится целая коллекция файлов. Часть из них — это метаинформация, в ней — схема, а также различная служебная информация, включая частичный индекс, позволяющий считывать только необходимые блоки данных при запросе. Остальные части, или партиции, это и есть наши Row group.
Для интуитивного понимания будем считать Row groups набором файлов, объединённых общей информацией. Кстати, это разбиение используется HDFS для реализации data locality, когда каждая нода в кластере может считывать те данные, которые непосредственно расположены у неё на диске. Более того, row group выступает единицей Map Reduce, и каждая map-reduce задача в Spark работает со своей row-group. Поэтому worker обязан поместить группу строк в память, и при настройке размера группы надо учитывать минимальный объём памяти, выделяемый на задачу на самой слабой ноде, иначе можно наткнуться на OOM.
В нашем случае мы столкнулись с тем, что в определённых условиях Spark, считывая текстовый файл, формировал только одну партицию, и из-за этого преобразование данных выполнялось только на одном ядре, хотя ресурсов было доступно гораздо больше. С помощью операции repartition в rdd мы разбили входные данные, в итоге получилось несколько row groups, и проблема ушла.
Column chunk (разбиение на уровне колонок) — оптимизирует работу с диском (дисками). Если представить данные как таблицу, то они записываются не построчно, а по колонкам.
Представим таблицу:
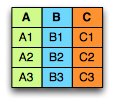
Тогда в текстовом файле, скажем, csv мы бы хранили данные на диске примерно так:

В случае с Parquet:

Благодаря этому мы можем считывать только необходимые нам колонки.
Из всего многообразия колонок на деле аналитику в конкретный момент нужны лишь несколько, к тому же большинство колонок остается пустыми. Parquet в разы ускоряет процесс работы с данными, более того — подобное структурирование информации упрощает сжатие и кодирование данных за счёт их однородности и похожести.
Каждая колонка делится на страницы (Pages), которые, в свою очередь, содержат метаинформацию и данные, закодированные по принципу архитектуры из проекта Dremel. За счёт этого достигается довольно эффективное и быстрое кодирование. Кроме того, на данном уровне производится сжатие (если оно настроено). На данный момент доступны кодеки snappy, gzip, lzo.
Есть ли подводные камни?
За счёт “паркетной” организации данных сложно настроить их стриминг — если передавать данные, то полностью всё группу. Также, если вы утеряли метаинформацию или изменили контрольную сумму для Страницы данных, то вся страница будет потеряна (если для Column chank — то chank потерян, аналогично для row group). На каждом из уровней разбиения строятся контрольные суммы, так что можно отключить их вычисления на уровне файловой системы для улучшения производительности.
Выводы:
Достоинства хранения данных в Parquet:
- Несмотря на то, что они и созданы для hdfs, данные могут храниться и в других файловых системах, таких как GlusterFs или поверх NFS
- По сути это просто файлы, а значит с ними легко работать, перемещать, бэкапить и реплицировать.
- Колончатый вид позволяет значительно ускорить работу аналитика, если ему не нужны все колонки сразу.
- Нативная поддержка в Spark из коробки обеспечивает возможность просто взять и сохранить файл в любимое хранилище.
- Эффективное хранение с точки зрения занимаемого места.
- Как показывает практика, именно этот способ обеспечивает самую быструю работу на чтение по сравнению с использованием других файловых форматов.
Недостатки:
- Колончатый вид заставляет задумываться о схеме и типах данных.
- Кроме как в Spark, Parquet не всегда обладает нативной поддержкой в других продуктах.
- Не поддерживает изменение данных и эволюцию схемы. Конечно, Spark умеет мерджить схему, если у вас она меняется со временем (для этого надо указать специальную опцию при чтении), но, чтобы что-то изменить в уже существующим файле, нельзя обойтись без перезаписи, разве что можно добавить новую колонку.
- Не поддерживаются транзакции, так как это обычные файлы а не БД.
В Wrike мы уже достаточно давно используем parquet-файлы в качестве хранения обогащённых событийных данных, наши аналитики гоняют довольно много запросов к ним каждый день, у нас выработалась особая методика работы с данной технологией, так что с удовольствием поделимся опытом с теми, кто хочет попробовать parquet в деле, и ответим на все вопросы в комментариях.
P.S. Конечно, в последствии мы не раз пересматривали свои взгляды по поводу формы хранения данных, например, нам советовали более популярный Avro формат, но пока острой необходимости что-то менять у нас нет.
Для тех, кто до сих пор не понял разницу между строково-ориентированными данными и колончато-ориентированными, есть прекрасное видео от Cloudera,
а также довольно занимательная презентация о форматах хранения данных для аналитики.
Комментарии (14)

facha
22.03.2016 10:23Расскажите, какое вы используете хранилище (насколько я понял, это не HDFS) в кластере.

Wriketeam
22.03.2016 11:50+2На данный момент мы используем терабайтные SSD, примонтированные по NFS. Есть несколько нюансов: довольно неудобная масштабируемость и проблемы с маппингом данных за всю историю (приходится указывать разные пути). Пока мы не хотим использовать HFS, так как придется обязательно тащить hadoop и YARN. В данном случае для нас важно обеспечить максимально эффективное многократное чтение данных за большой период истории, поэтому сейчас мы рассматриваем GlusterFS в режиме Distributed. Striped режим мы считаем излишним, так как "паркет" уже разбит на куски, соответствующие MR порции — группы строк, как описывается в статье. Более того, наличие POSIX интерфейса довольно удобно для интеграции. В любом случае пока мы остановились только на parquet-файлах, их можно перенести в любое хранилище в дальнейшем, так что это дает нам возможность для экспериментов. Остальная часть инфраструктуры постоянно меняется, мы экспериментируем и постараемся рассказывать о результатах.

xhumanoid
22.03.2016 15:08+2Кроме как в Spark, Parquet не всегда обладает нативной поддержкой в других продуктах.
можно подробней о каких продуктах идет речь? так как у нас математики без проблем читают паркет в питоновские датафреймы, impala & hive так вообще нативно подхватывают. Читать файлы из java тоже не составляет никакого труда.
Не поддерживаются транзакции, так как это обычные файлы а не БД.
он и не должен, это формат хранения ;) к тому же immutable
На данный момент мы используем терабайтные SSD, примонтированные по NFS
Пока мы не хотим использовать HFS, так как придется обязательно тащить hadoop и YARN
подозреваю хотели написать HDFS, но не суть
почему установка HDFS сразу же подразумевает установку YARN и остальных вещей? (у самого крутиться HDFS + HBase без какого-либо YARN). HDFS — распределенное хранилище, YARN — вычислительная платформа, они достаточно неплохо разделены. Поэтому от standalone spark кластера вас никто не заставляет отказываться, можете поднять hdfs + spark standalone, проблем никаких нету (подымал такую конфигурацию, от spark yarn отличий в разворачивании на клоудере вообще нету)
к тому же перейдя от NFS на HDFS вы получаете профит в виде локальности данных, ваши spark задачи будут отправляться на ноды на которых эти данные и лежат, а это сразу решает несколько проблем:
1) затыки на дисковом IO, ради чего вы и покупали ссд (все уйдет на локальные диски, которые в сумме выдадут за те же деньги в разы большую производительность)
2) затыки на сетевом интерфейсе (прокачать каких-то 1ТБ даже с 10Гбитной сеткой занимает существенное время, тут же будет независимое чтение с разных дисков и минимум нагрузка на сеть, если все-таки промахнемся с задачей)
HDFS ведь и придумывалось не только для распределенности, но и ради локальности данных (кстати это причина почему хадуп на SAN/NAS у меня вызывает улыбку) и GlusterFS в этом плане вам ничем не поможет, так как спарк не сможет получить распределение блоков.
Колончатый вид заставляет задумываться о схеме и типах данных.
в вашем примере я не понял как парсить и обрабатывать данный json с разной структурой? каждый раз проверяем наличие нужных полей и вложен или нет?
Эффективное хранение с точки зрения занимаемого места.
тут согласен, особенно если сверху еще какой dictionary encoding для строк пройдется, то зачастую вообще копейки на выходе
В общем spark на NFS имеет смысл там же где и GPU вычисления: входных-выходных данных мало, а вычислительной математики много
grossws
Насколько parquet применим при отсутствии hadoop-common в classpath? У меня сложилось первое впечатление, что он довольно сильно завязан на куски хадупа.
Wriketeam
К сожалению, точного ответа на этот вопрос у нас нет, так как непосредственно из java мы с parquet не работали, работаем только из Спарка. При этом parquet — это лишь формат, значит теоритически с ним можно работать и без единого пересечения с hadoop. Более того, существует реализация на c++ parquet-cpp для чтения файлов, что говорит о том, что hadoop не обязателен. Сама по себе конструкция этого формата хоть и разрабатывалась специально для hadoop но не предполагает его наличие, также надо понимать, что вся прелесть этого формата в том, что с ним легко работать через MapReduce и необходимо что-то похожее на hadoop, поэтому во многих библиотеках и примерах всегда присутствует импорт hadoop-библиотек.