 Зато какая сортировка!
Зато какая сортировка!(А. С. Пушкин)
Если бы это была запись для твиттера, то она была бы следующей: «Программисты на Cache ObjectScript! Используйте Cyrillic4 вместо Cyrillic3!». Но тут Хабр, поэтому придётся развернуть мысль – добро пожаловать под кат.
Всё в Cache хранится в глобалах. Данные, метаданные, классы, программы. Узлы глобала сортируются по значениям индексов (subscript) и сохраняются на диске не в том порядке, в котором их вставили, а в отсортированном — для быстрого поиска:
USER>set ^a(10)=""
USER>set ^a("фф")=""
USER>set ^a("бб")=""
USER>set ^a(2)=""
USER>zwrite ^a
^a(2)=""
^a(10)=""
^a("бб")=""
^a("фф")=""При сортировке Cache различает числа и строки — 2 рассматривается как число и сортируется перед 10. Команда zwrite и функции $Order и $Query выводят индексы глобала в том порядке, в котором они хранятся на диске: сначала пустая строка, затем отрицательные числа, ноль, положительные числа, затем строки в порядке, определяемом таблицей сортировки (collation).
В простейшем случае таблица сортировки сопоставляет каждому символу некоторый порядковый номер. Далее таблицу сортировки я буду называть сортировкой.
Стандартная сортировка в Cache так и называется — Cache standard. Она сопоставляет каждому символу его код в Unicode.
Сортировка, с которой создаются локальные массивы в текущем процессе, определяется локалью (Портал Управления > Администрирование Системы > Конфигурация > Настройка поддержки национальных языков). Для rusw — русской локали юникодных инсталляций Cache — таблица сортировки по умолчанию — Cyrillic3. Другие возможные сортировки в rusw — Cache standard, Cyrillic1, Cyrillic3, Cyrillic4, Ukrainian1.
Метод ##class(%Collate).SetLocalName() меняет сортировку для локальных массивов текущего процесса:
USER>write ##class(%Collate).GetLocalName()
Cyrillic3
USER>write ##class(%Collate).SetLocalName("Cache standard")
1
USER>write ##class(%Collate).GetLocalName()
Cache standard
USER>write ##class(%Collate).SetLocalName("Cyrillic3")
1
USER>write ##class(%Collate).GetLocalName()
Cyrillic3У каждой сортировки есть парная, в которой числа сортируются как строки. Имя такой парной сортировки получается добавлением " string" к имени оригинальной сортировки:
USER>write ##class(%Collate).SetLocalName("Cache standard string")
1
USER>kill test
USER>set test(10) = "", test(2) = "", test("фф") = "", test("бб") = ""
USER>zwrite test
test(10)=""
test(2)=""
test("бб")=""
test("фф")=""
USER>write ##class(%Collate).SetLocalName("Cache standard")
1
USER>kill test
USER>set test(10) = "", test(2) = "", test("фф") = "", test("бб") = ""
USER>zwrite test
test(2)=""
test(10)=""
test("бб")=""
test("фф")=""Cache standard и Cyrillic3
В Cache standard символы сортируются в порядке их кодов Unicode:
write ##class(%Library.Collate).SetLocalName("Cache standard"),!
write ##class(%Library.Collate).GetLocalName(),!
set letters = "абвгдеёжзийклмнопрстуфхцчщщьыъэюя"
set letters = letters _ $zconvert(letters,"U")
kill test
//заполняем test данными
for i=1:1:$Length(letters) {
set test($Extract(letters,i)) = ""
}
//выводим индексы массива test в отсортированном порядке
set l = "", cnt = 0
for {
set l = $Order(test(l))
quit:l=""
write l, " ", $Ascii(l),","
set cnt = cnt + 1
write:cnt#8=0 !
}USER>do ^testcol
1
Cache standard
Ё 1025,А 1040,Б 1041,В 1042,Г 1043,Д 1044,Е 1045,Ж 1046,
З 1047,И 1048,Й 1049,К 1050,Л 1051,М 1052,Н 1053,О 1054,
П 1055,Р 1056,С 1057,Т 1058,У 1059,Ф 1060,Х 1061,Ц 1062,
Ч 1063,Щ 1065,Ъ 1066,Ы 1067,Ь 1068,Э 1069,Ю 1070,Я 1071,
а 1072,б 1073,в 1074,г 1075,д 1076,е 1077,ж 1078,з 1079,
и 1080,й 1081,к 1082,л 1083,м 1084,н 1085,о 1086,п 1087,
р 1088,с 1089,т 1090,у 1091,ф 1092,х 1093,ц 1094,ч 1095,
щ 1097,ъ 1098,ы 1099,ь 1100,э 1101,ю 1102,я 1103,ё 1105,Все буквы на своём месте, кроме букв «ё» и «Ё». Их коды в Unicode выбиваются из общего порядка. Поэтому для русской локали понадобилась своя таблица сортировки — Cyrillic3, в которой буквы идут в том же порядке, как и в русском алфавите:
USER>do ^testcol
1
Cyrillic3
А 1040,Б 1041,В 1042,Г 1043,Д 1044,Е 1045,Ё 1025,Ж 1046,
З 1047,И 1048,Й 1049,К 1050,Л 1051,М 1052,Н 1053,О 1054,
П 1055,Р 1056,С 1057,Т 1058,У 1059,Ф 1060,Х 1061,Ц 1062,
Ч 1063,Щ 1065,Ъ 1066,Ы 1067,Ь 1068,Э 1069,Ю 1070,Я 1071,
а 1072,б 1073,в 1074,г 1075,д 1076,е 1077,ё 1105,ж 1078,
з 1079,и 1080,й 1081,к 1082,л 1083,м 1084,н 1085,о 1086,
п 1087,р 1088,с 1089,т 1090,у 1091,ф 1092,х 1093,ц 1094,
ч 1095,щ 1097,ъ 1098,ы 1099,ь 1100,э 1101,ю 1102,я 1103,В Cache ObjectScript есть специальный бинарный оператор ]] — «сортируется после». Он возвращает 1, если в индексе массива левый аргумент будет размещен после правого аргумента, иначе 0:
USER>write ##class(%Library.Collate).SetLocalName("Cache standard"),!
1
USER>write "А" ]] "Ё"
1
USER>write ##class(%Library.Collate).SetLocalName("Cyrillic3"),!
1
USER>write "А" ]] "Ё"
0Глобалы и таблицы сортировки
Разные глобалы в одной и той же базе данных могут иметь разную сортировку. У каждой базы данных есть настройка — сортировка для новых глобалов. Сразу после инсталляции у всех баз кроме USER сортировка по умолчанию для новых глобалов — Cache standard. Для USER — в зависимости от локали инсталляции. Для rusw — Cyrillic3.
Создание глобала с сортировкой отличной от сортировки по умолчанию для данной базы:
USER>kill ^a
USER>write ##class(%GlobalEdit).Create(,"a",##class(%Collate).DisplayToLogical("Cache standard"))В списке глобалов в Портале управления (Обозреватель Системы > Глобалы) для каждого глобала показывается его сортировка (четвёртый столбец).
Нельзя поменять сортировку существующего глобала. Нужно создать глобал с новой сортировкой и скопировать данные из старого глобала командой merge. Массовую конвертацию глобалов из одной сортировки в другую можно сделать методом ##class(SYS.Database).Copy()
Cyrillic4, Cyrillic3 и умляуты
В процессе эксплуатации Cyrillic3 выяснилось, что преобразование текстового индекса во внутренний формат происходит дольше, чем в сортировке Cache standard, поэтому вставка и навигация по глобалу (или локальному массиву) с сортировкой Cyrillic3 выполняется медленней. Была создана новая сортировка Cyrillic4, доступная с версии 2014.1. Порядок букв кириллицы в ней такой же, как и в Cyrillic3, но Cyrillic4 заметно быстрее.
for collation="Cyrillic3","Cyrillic4","Cache standard","Cyrillic1" {
write ##class(%Library.Collate).SetLocalName(collation),!
write ##class(%Library.Collate).GetLocalName(),!
do test(100000)
}
quit
test(C)
set letters = "абвгдеёжзийклмнопрстуфхцчщщьыъэюя"
set letters = letters _ $zconvert(letters,"U")
kill test
write "test insert: "
// заполняем test данными
set z1=$zh
for c=1:1:C {
for i=1:1:$Length(letters) {
set test($Extract(letters,i)_"плюс длинное русское слово" _ $Extract(letters,i)) = ""
}
}
write $zh-z1,!
//перебираем индексы массива test
write "test $Order: "
set z1=$zh
for c=1:1:C {
set l = ""
for {
set l = $Order(test(l))
quit:l=""
}
}
write $zh-z1,!USER>do ^testcol
1
Cache standard
test insert: 1.520673
test $Order: 2.062228
1
Cyrillic3
test insert: 3.541697
test $Order: 5.938042
1
Cyrillic4
test insert: 1.925205
test $Order: 2.834399Cyrillic4 пока не является сортировкой по умолчанию в локали rusw, но, создав свою локаль на базе rusw, можно указать Cyrillic4 сортировкой по умолчанию для локальных массивов. Или указать Cyrillic4 сортировкой по умолчанию для новых глобалов в настройках базы данных.
Cyrillic3 медленнее Cache standard и Cyrillic4, потому что в её основе лежит алгоритм более общий, чем сортировка двух строк в зависимости от кодов соответствующих символов этих строк.
В немецком языке при сортировке буква ? должна восприниматься как ss. В Cache так и работает:
USER>write ##class(%Collate).GetLocalName()
German3
USER>set test("Stra?er")=1
USER>set test("Strasser")=1
USER>set test("Straster")=1
USER>zwrite test
test("Strasser")=1
test("Stra?er")=1
test("Straster")=1Обратите внимание на порядок строк. А именно, что первые четыре буквы первой строки — «Stras», затем «Stra?», затем опять «Stras». Такого порядка нельзя достичь, если каждой букве сопоставлять некоторый код.
Нам с вами повезло с русским языком — в нём нет умляутов или букв, которые могут сортироваться одинаково, как, например, v и w в финском языке. В русском языке достаточно дать каждой букве номер, и сравнивать строки по номерам букв на соответствующих позициях. За счёт этого и получилось выиграть в скорости в Cyrillic4.
Таблицы сортировки и SQL
Не путайте таблицу сортировки в глобалах и сортировку (тоже collation) для столбца в SQL. Вторая сортировка — преобразование, применяемое к значению, перед тем как положить его в индексный глобал или сравнить с другим значением. В Cache SQL сортировка по умолчанию для строк — SQLUPPER. Это преобразование переводит все буквы в верхний регистр, удаляет пробельные символы в конце и добавляет один пробел в начало строки. Три другие SQL сортировки (EXACT, SQLSTRING, TRUNCATE) описаны в документации.
При некотором умении не сложно создать путаницу, когда разные глобалы в базе данных имеют разную сортировку, а локальные массивы — третью. SQL для внутренних нужд использует базу CACHETEMP, сортировка глобалов которой тоже может отличаться от сортировки по умолчанию текущей локали.
Основное правило одно — чтобы ORDER BY в запросах SQL возвращал строки в ожидаемом порядке, сортировка глобалов, в которых хранятся данные и индексы таблиц, участвующих в запросе должна быть такой же как сортировка по умолчанию для базы CACHETEMP и сортировка локальных массивов. Подробнее — смотрите абзац в документации «SQL and NLS Collations».
Создадим тестовый класс:
Class Habr.test Extends %Persistent
{
Property Name As %String;
Property Surname As %String;
Index SurInd On Surname;
ClassMethod populate()
{
do ..%KillExtent()
set t = ..%New()
set t.Name = "Павел", t.Surname = "Ёлкин"
write t.%Save()
set t = ..%New()
set t.Name = "Пётр", t.Surname = "Иванов"
write t.%Save()
set t = ..%New()
set t.Name = "Прохор", t.Surname = "Александров"
write t.%Save()
}
}Внесём данные (можете потом поменять имена на строки из немецкого примера):
USER>do ##class(Habr.test).populate()Выполним запрос:

Результат неожиданный. Главный вопрос — почему не алфавитный порядок имён (Павел, Пётр, Прохор)? Смотрим план запроса:

Ключевые слова в этом плане — «populates temp-file». Для выполнения запроса оптимизатор SQL решил использовать временную структуру — temp-file — глобал (в некоторых случаях локальный массив), видный только текущему процессу (process-private global). В индексы этого глобала помещаются значения и потом выводятся в отсортированном порядке. Временные глобалы хранятся в базе CACHETEMP, сортировка дла новых глобалов в которой — Cache standard. Но почему «ё» в начале, а не в конце? В индексы временного глобала кладётся значение поля name приведённое к верхнему регистру (SQLUPPER — преобразование по умолчанию для строк), соответственно буква Ё будет идти в самом начале.
Отменив автоматические преобразование (функция %Exact), получим всё ещё неправильный, но хотя бы ожидаемый порядок — «ё» сортируется после всех букв

Не будем пока исправлять таблицу сортировки в CACHETEMP — проверим запросы с surname. Ведь на этот столбец есть индекс в глобале ^Habr.TestI. Сортировка этого глобала — Cyrillic3, значит и порядок строк должен быть алфавитный:

Опять не то. Смотрим план:

Чтобы вывести фамилии в исходном виде (до преобразования SQLUPPER, которое по умолчанию применяется к элементам индекса SurInd) данных только индекса мало и нужно обращаться к таблице, поэтому оптимизатор SQL решил брать данные сразу из таблицы и сортировать их во временной переменной — так же как и в случае с name.
Если указать в запросе, что верхний регистр нас устраивает, то порядок будет верный — ведь данные будут браться напрямую из индексного глобала ^Habr.testI:

План запроса ожидаемый:

Теперь давайте сделаем, что давно нужно было сделать — изменим сортировку по умолчанию для новых глобалов в базе CACHETEMP на Cyrillic3 (или на Cyrillic4).
Запросы, использовавшие временные структуры, теперь выводят строки в правильном порядке:
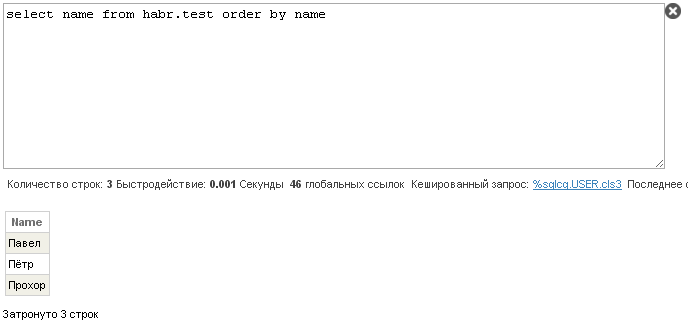

Выводы
- Если вас не волнует, в каком порядке отображаются данные с буквой Ё, — используйте таблицу сортировки Cache standard.
- Если вы используете Cyrillic3, протестируйте своё приложение с таблицей сортировки Cyrillic4. Приложение станет быстрее.
- Проверьте, что в базе данных CACHETEMP, рабочей базе данных и в настройках локали стоит одна и та же таблица сортировки.
morisson
Вот простой вопрос есть: установил заново Cache, буду работать с русским (Ё нужна), надо ли что-то сразу переключать в сортировках? И если да — в скольки местах и на что?
DAiMor
все зависит от региональных настроек операционной системы, по ним установщик определяет какую локаль активировать.
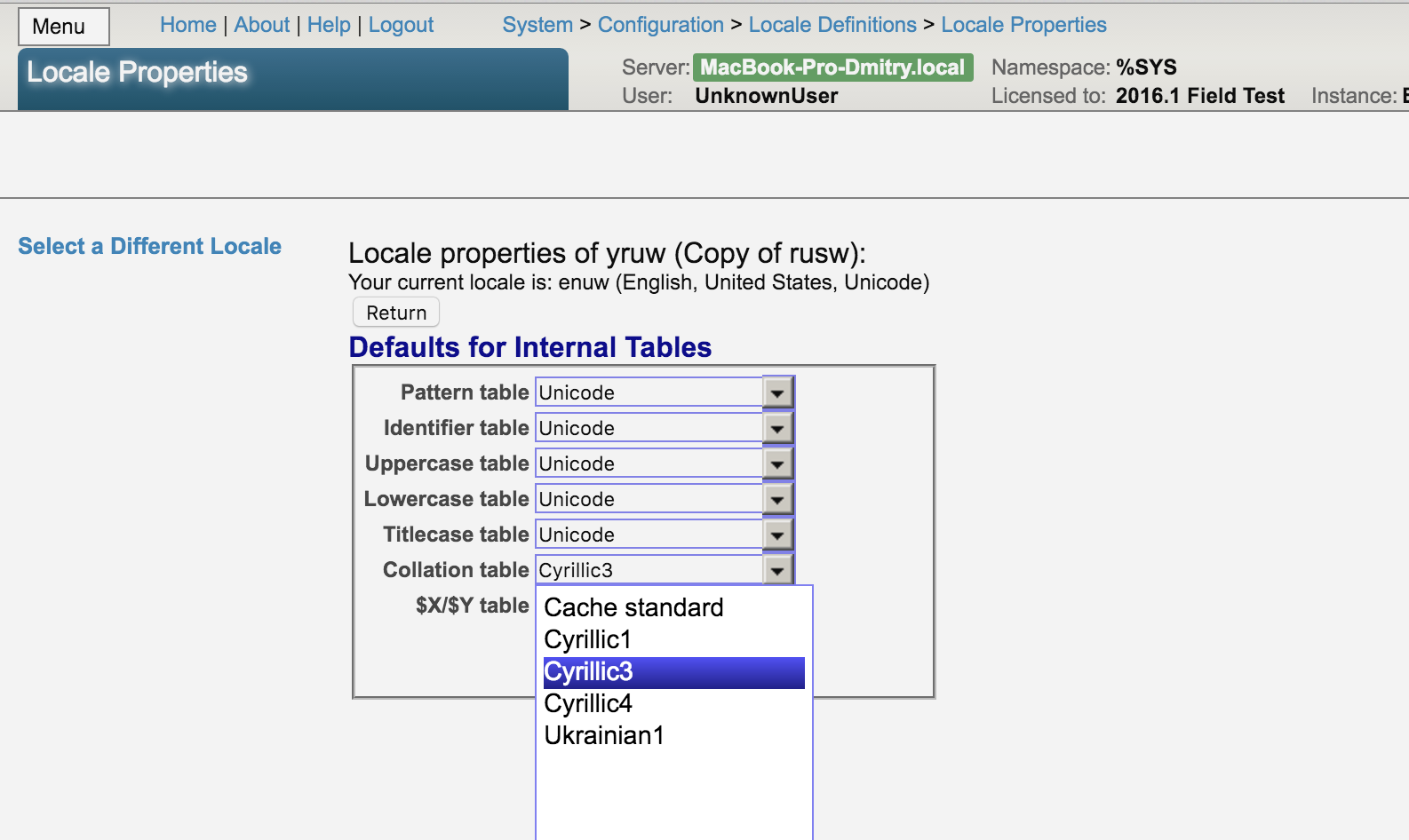
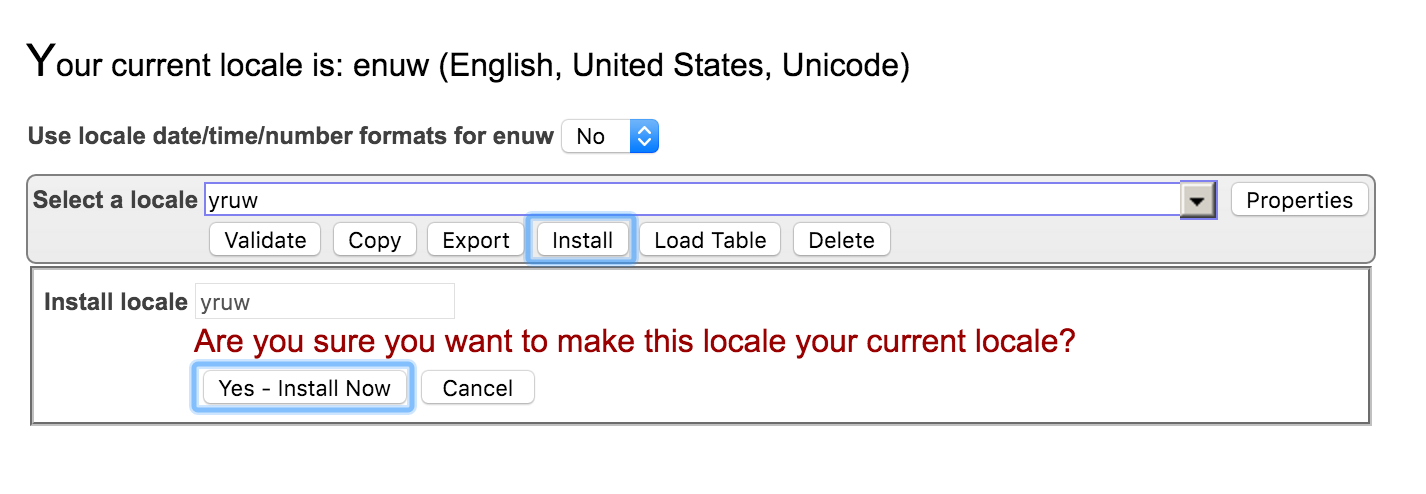
поправить нужно настройках локализации. Нужно скопировать локаль rusw в yruw или rus8 в yru8 для 8-битных систем. И в скопированной локали уже можно делать изменения.
сохранить. и установить новую локаль
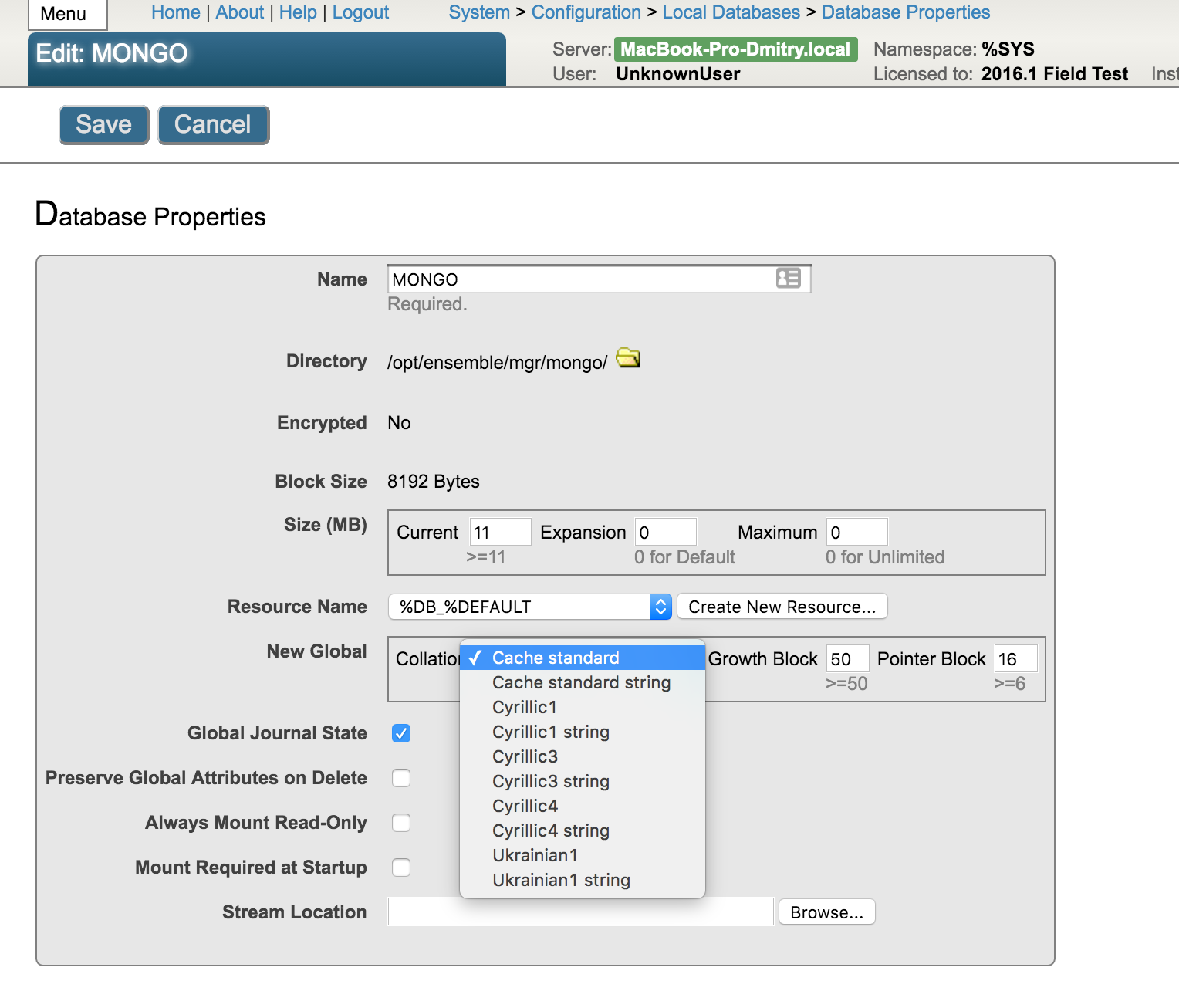
После этого можно изменить сортировку по умолчанию для базы данных
adaptun
интересное имя у базы данных на скриншоте :-)
morisson
Тоже заметил — особенно хорошо в сочетании с подписью в поле ввода )
morisson
Спасибо!
Еще парочка вопросов:
Cyrillic 4 брать или Cyrillic 4 string брать для глобалов?
Что такое Cyrillic 1?
Украинцам надо менять все сразу на Ukranian 1 или можно пользоваться Cache Standard?
DAiMor
сортировку брать со string или нет зависит от требований, как указано в статье, отличие только в сортировки чисел.
Cyrillic 1 — думаю эта сортировка уже порядком устарела
Для украины Cache standard так же сортиовать будет не верно. Так что лучше выбрать Ukranian 1
morisson
Да, правда, невнимательно читал.
Интересно, зачем такое может быть нужно?
Успокаивает, что если "что-то пошло не так", можно всегда попробовать другую сортировку. (да, при этом потребуется скопировать глобал целиком, а, возможно, и два раза скопировать, если нужно изменить сортировку в существующем глобале).