Под напором появления новых асинхронных неблокирующихся фреймворков может показаться, что блокирующиеся вызовы — это пережиток прошлого, и все новые сервисы нужно писать на полностью асинхронной архитектуре. В этом посте я расскажу, как мы решили отказаться от неблокирующих асинхронных вызовов бэкендов в пользу обычных блокирующих.
В архитектуре HeadHunter есть сервис, который собирает данные с других сервисов. Например, чтобы показать вакансии по поисковому запросу, нужно:
- сходить в бэкенд поиска за “айдишками” вакансий;
- сходить в бэкенд вакансий за их описанием.
Это простейший пример. Часто в этом сервисе много всякой логики. Мы его даже назвали “logic”.
Изначально он был написан на python. За несколько лет существования logic в нем накопилось всякого тех. долга. Да и разработчики были не в восторге от необходимости копаться как в python, так и в java, на которой у нас написано большинство бэкендов. И мы подумали, почему бы не переписать logic на java.
Причем python logic у нас прогрессивный, построен на асинхронном неблокирующемся фреймворке tornado. Вопроса “блокироваться или не блокироваться при походе на бэкенды” даже не стояло: из-за GIL в python нет настоящего параллельного исполнения потоков, поэтому хочешь — не хочешь, а запросы надо обрабатывать в одном потоке и не блокироваться при походах в другие сервисы.
А вот при переходе на java мы решили еще раз оценить, хотим ли продолжать писать вывернутый коллбэчный код.
def search_vacancies(query):
def on_vacancies_ids_received(vacancies_ids):
get_vacancies(vacancies_ids, callback=reply_to_client)
search_vacancies_ids(query, callback=on_vacancies_ids_received)
Конечно callback hell можно сгладить. В java 8, например, появилась CompletableFuture. Еще можно посмотреть в сторону Akka, Vert.x, Quasar и т. д. Но, может быть, нам не нужны новые уровни абстракции, и мы можем вернуться к обычным синхронным блокирующимся вызовам?
def search_vacancies(query):
vacancies_ids = search_vacancies_ids(query)
return get_vacancies(vacancies_ids)
В этом случае мы будем выделять под обработку каждого запроса поток, который при походе на бэкенд будет блокироваться до тех пор, пока не получит результат, а затем продолжит исполнение. Обратите внимание, что я говорю про блокировку потока в момент вызова удаленного сервиса. Вычитывание запроса и запись результата в сокет будет по-прежнему осуществляться без блокировки. То есть, поток будет выделяться под готовый запрос, а не под соединение. Чем потенциально плоха блокировка потока?
- Потребуется много памяти, так как каждому потоку нужна память под стек.
- Все будет тормозить, так как переключение между контекстами потоков — не бесплатная операция.
- Если бэкенды затупят, то свободных потоков в пуле не останется.
Мы решили прикинуть, сколько нам понадобится потоков, а потом оценить, заметим ли мы эти проблемы.
Сколько нужно потоков?
Нижнюю границу оценить несложно.
Предположим, сейчас у python logic такие логи:
15:04:00 400 ms GET /vacancies
15:04:00 600 ms GET /resumes
15:04:01 500 ms GET /vacancies
15:04:01 600 ms GET /resumes
Вторая колонка — это время от поступления запроса до отдачи ответа. То есть logic обработал:
15:04:00 суммарная длительность запросов - 1000 ms
15:04:01 суммарная длительность запросов - 1100 ms
Если мы будем выделять под обработку каждого запроса поток, то:
- в 15:04:00 мы теоретически можем обойтись одним потоком, который вначале обработает запрос GET /vacancies, а потом обработает запрос GET /resumes;
- а вот в 15:04:01 уже придется выделять минимум 2 потока, так как один поток за одну секунду никак не сможет обработать больше секунды запросов.
На самом деле, в самое нагруженное время на python logic такая суммарная длительность запросов:
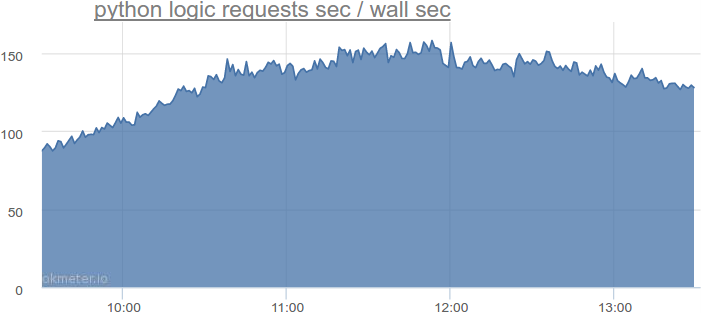
Больше 150 секунд запросов за секунду. То есть нам потребуется больше 150 потоков. Запомним это число. Но надо еще как-то учесть, что запросы приходят неравномерно, поток может быть возвращен в пул не сразу после обработки запроса, а чуть позже, и т. д.
Давайте возьмем другой сервис, который блокируется при походах в базу данных, посмотрим, сколько ему требуется потоков, и экстраполируем числа. Вот, например, сервис приглашений и откликов:
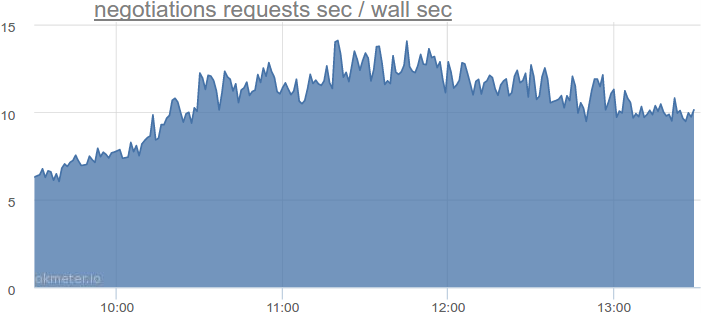
До 14 секунд запросов за секунду. А что с фактическим использованием потоков?
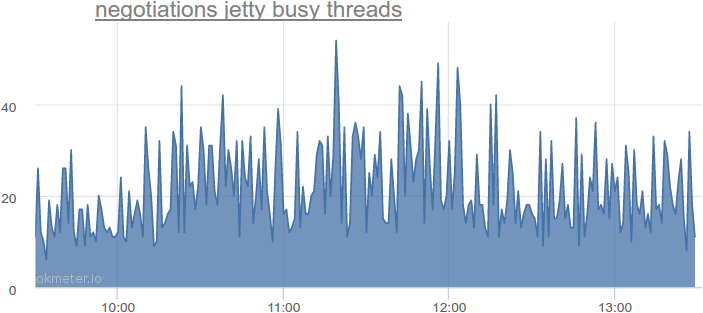
До 54-х одновременно используемых потоков, что в 2-4 раза больше по сравнению с теоретически минимальным количеством. Мы смотрели на другие сервисы — там похожая картина.
Тут уместно сделать небольшое отступление. В HeadHunter в качестве http сервера используется jetty, но в других http серверах похожая архитектура:
- каждый запрос — это задача;
- эта задача поступает в очередь перед пулом потоков;
- если в пуле есть свободный поток — он берет задачу из очереди и выполняет ее;
- если свободного потока нет — задача лежит в очереди, пока свободный поток не появится.
Если нам не страшно, что запрос будет некоторое время лежать в очереди — можно выделить потоков немногим больше, чем рассчитанный минимум. Но если мы хотим максимально сократить задержки, то потоков нужно выделить больше.
Давайте выделим в 4 раза больше потоков.
То есть, если мы сейчас переведем весь python logic на java logic с блокирующейся архитектурой, то нам потребуется 150 * 4 = 600 потоков.
Давайте представим, что нагрузка вырастет в 2 раза. Тогда, если мы не упремся в CPU, нам потребуется 1200 потоков.
Еще представим, что наши бэкенды тупят, и на обслуживание запросов уходит в 2 раза больше времени, но об этом позже, пока пусть будет 2400 потоков.
Сейчас python logic крутится на четырех серверах, то есть на каждом будет 2400 / 4 = 600 потоков.
600 потоков — это много или мало?
Несколько сотен тредов — это много или мало?
По-умолчанию, на 64-х битных машинах java выделяет под стек потока 1 МБ памяти.
То есть для 600 потоков потребуется 600 МБ памяти. Не катастрофа. К тому же это — 600 МБ виртуального адресного пространства. Физическая оперативная память будет задействована только тогда, когда эта память действительно потребуется. Нам почти никогда не требуется 1 МБ стека, мы часто зажимаем его до 512 КБ. В этом смысле ни 600, ни даже 1000 потоков для нас не проблема.
Что с затратами на переключение контекста между потоками?
Вот простенький тест на java:
- создаем пул потоков размером 1, 2, 4, 8… 4096;
- закидываем в него 16 384 задачи;
- каждая задача — это 600 000 итераций складывания случайных чисел;
- ждем выполнения всех задач;
- запускаем тест 2 раза для прогрева;
- запускаем тест еще 5 раз и берем среднее время.
static final int numOfWarmUps = 2;
static final int numOfTests = 5;
static final int numOfTasks = 16_384;
static final int numOfIterationsPerTask = 600_000;
public static void main(String[] args) throws Exception {
for (int numOfThreads : new int[] {1, 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024, 2048, 4096}) {
System.out.println(numOfThreads + " threads.");
ExecutorService executorService = Executors.newFixedThreadPool(numOfThreads);
System.out.println("Warming up...");
for (int i=0; i < numOfWarmUps; i++) {
test(executorService);
}
System.out.println("Testing...");
for (int i = 0; i < numOfTests; i++) {
long start = currentTimeMillis();
test(executorService);
System.out.println(currentTimeMillis() - start);
}
executorService.shutdown();
executorService.awaitTermination(1, TimeUnit.SECONDS);
System.out.println();
}
}
static void test(ExecutorService executorService) throws Exception {
List<Future<Integer>> resultsFutures = new ArrayList<>(numOfTasks);
for (int i = 0; i < numOfTasks; i++) {
resultsFutures.add(executorService.submit(new Task()));
}
for (Future<Integer> resultFuture : resultsFutures) {
resultFuture.get();
}
}
static class Task implements Callable<Integer> {
private final Random random = new Random();
@Override
public Integer call() throws InterruptedException {
int sum = 0;
for (int i = 0; i < numOfIterationsPerTask; i++) {
sum += random.nextInt();
}
return sum;
}
}
Вот результаты на 4-х ядерном i7-3820, HyperThreading отключен, Ubuntu Linux 64-bit. Ожидаем, что лучший результат покажет пул с четырьмя потоками (по количеству ядер), так что сравниваем остальные результаты с ним:
| Количество потоков | Среднее время, мс | Стандартное отклонение | Разница, % |
|---|---|---|---|
| 1 | 109152 | 9,6 | 287,70% |
| 2 | 55072 | 35,6 | 95,61% |
| 4 | 28153 | 3,8 | 0,00% |
| 8 | 28142 | 2,8 | -0,04% |
| 16 | 28141 | 3,6 | -0,04% |
| 32 | 28152 | 3,7 | 0,00% |
| 64 | 28149 | 6,6 | -0,01% |
| 128 | 28146 | 2,3 | -0,02% |
| 256 | 28146 | 4,1 | -0,03% |
| 512 | 28148 | 2,7 | -0,02% |
| 1024 | 28146 | 2,8 | -0,03% |
| 2048 | 28157 | 5,0 | 0,01% |
| 4096 | 28160 | 3,0 | 0,02% |
Разница между 4 и 4096 потоками сравнима с погрешностью. Так что и в смысле накладных расходов от переключения контекстов 600 потоков для нас не является проблемой.
А если бэкенды затупят?
Представим, что у нас затупил один из бэкендов, и теперь запросы к нему занимают в 2, 4, 10 раз больше времени. Это может привести к тому, что все потоки будут висеть заблокированными, и мы не сможем обрабатывать другие запросы, которым этот бэкенд не нужен. В этом случае мы можем сделать несколько вещей.
Во-первых, оставить про запас еще больше потоков.
Во-вторых, выставить жесткие таймауты. За таймаутами надо следить, это может быть проблемой. Стоит ли она того, чтобы писать асинхронный код? Вопрос открытый.
В-третьих, никто не заставляет нас писать все в синхронном стиле. Например, какие-то контроллеры мы вполне можем написать в асинхронном стиле, если ожидаем проблем с бэкендами.
Таким образом, для сервиса походов по бэкендам при наших нагрузках мы сделали выбор в пользу преимущественно блокирующейся архитектуры. Да, нам нужно следить за таймаутами, и мы не можем быстро отмасштабироваться в 100 раз. Но, с другой стороны, мы можем писать простой и понятный код, быстрее выпускать бизнес-фичи и тратить меньше времени на поддержку, что, на мой взгляд, тоже очень круто.
Полезные ссылки
Комментарии (34)

mwizard
05.04.2016 11:43+1"Как мы деградировали и вернулись к потокопроблемам."

YourLastDoctor
05.04.2016 13:28Интересно другое — как в Tornado можно «умудриться» устроить callback hell?
mwizard
05.04.2016 13:30+11Люди не знают или не хотят знать про Futures, Deferred и т.д., а еще игнорируют наличие async/await и asyncio. О причинах в статье ни слова, кроме "мы решили, что так будет проще" — и вместе с простотой получили обратно весь ворох проблем, для ухода от которых асинхронное программирование и было придумано.
Чем им блокирующий код слаще и приятнее, чем псевдоблокирующий код с await-ами (или yield-ами) — не знаю.
keyplayer
05.04.2016 13:42+3Уход от асинхронного кода не был основной мотивацией. Когда мы выбирали, как писать logic на java, мы рассматривали как асинхронные, так и синхронные варианты. Нам понравился синхронный варинат, потому это просто, понятно и не создает существенных проблем при нашем профиле нагрузки. О каком ворохе проблем мы забыли?

FeNUMe
05.04.2016 11:52+1У вас же вроде раньше Frontik/Tortik бегали по бекэндам, в статье про их замену или дополнительный слой-сборщик?
keyplayer
05.04.2016 12:05От Tortik мы оказались в пользу Frontik.
Frontikи у нас выступают в качестве фронтовых серверов, которые занимаются шаблонизацией.
Им разрешено ходить по бэкендам, но только параллельно.
Как только при походах на бэкенды появляется последовательная логика, например "после похода на бэкенд 1 проверь ответ и реши, стоит ли ходить на бэкенд 2", тогда эта логика выносится в отдельный слой, который мы называем logic.
Мы выделили этот слой, чтобы переиспользовать логику для основной версии сайта, мобильной версии сайта и api.
Изначально python logic был написан на Frontik. Теперь мы переписываем его на java.

AndreySu
05.04.2016 11:55Расскажите поподробней хотя бы про часть этой новой архитектуры, потому что синтетические тесты с кучей потоков выполняющих складывание рандомных чисел ничего не показывает в реальном приложении.

ragus
05.04.2016 13:25+1мы решили еще раз оценить, хотим ли продолжать писать вывернутый коллбэчный код
могли взять gevent/eventlet и не писать коллбэчный код.keyplayer
05.04.2016 13:26Основная мотивация — переписать на java, так как основная часть бэкендов у нас на java.

IvanPanfilov
05.04.2016 15:00-7Надо было брать kotlin с ним все еще намного проще и скоро будет асинхронность
bromzh
05.04.2016 13:55+4А зачем вы писали колбечную лапшу в питоне?
@coroutineв торнадо работает и во второй ветке. А в третьей есть asyncio.
Ок, надо переписать всё на java. Но там тоже можно не писать лапшу. А единственный аргумент в пользу такого решения звучит как-то так: мы хотим писать в синхронном стиле.
В итоге: у вас таймауты, куча памяти расходуется на треды в которых в основном I/O, вы плохо масштабируетесь, но зато нет callback hell, который вы же сами и устроили.

afiskon
05.04.2016 13:57Спасибо за интересную статью.
Сам в последнее время часто думаю о дизайне вроде того что вы описали. Поправьте меня, если я неправ, но верно ли я понимаю, что описанный подход не сработает, если
а) вы хотите слать пользователю пуши, скажем по вебсокету или если у вас кастомный tcp протокол? В этом случае "по треду на запрос" превращается в "по треду на коннект". Или есть идеи как это обойти?
б) если в бэкенде вы ходите в другие бэкенды или СУБД которые выполняют долгие (скажем, больше 1 сек) операции. Опять же, ваши трэды будут висеть по много секунд в ожидании ответа и быстро кончатся.
Все верно? Если да, не боитесь в будущем столкнуться с этими проблемами при вашем текущем дизайне?lega
05.04.2016 14:20Я не автор но отвечу,
а) автор написал «никто не заставляет нас писать все в синхронном стиле. Например, какие-то контроллеры мы вполне можем написать в асинхронном стиле», веб-сокеты как раз про это.
б) если какой-то сервис тормозит и не укладывается в рамки то нужно его фиксить, если это нормальное поведение, тогда можно переложить на асинхронный вариант.afiskon
05.04.2016 15:31Это понятно. На самом деле я всего лишь спрашиваю, не известно ли автору каких-то способов решения этих проблем, о которых я мог не подумать, без перекладывания на асинхронный вариант. Вот чуть ниже он пишет что возможно в случае а) такой способ есть, я правда пока не понял, в чем именно он заключается.
keyplayer
05.04.2016 14:57Если взять такой цикл запроса: вычитывание запроса из сокета -> походы по бэкендам для формирования результата -> записть результата в сокет, то только этап походов по бэкендам у нас блокирующийся. Вычитываение запроса и запись результата в сокет по-прежнему происходят без блокировки с помощью селекторов. В селекторе можно зарегистрировать тысячи сокетов, а выделять тред только тогда, когда в сокете появятся данные. Поэтому с пушами необязательно выделять тред под коннект.
По поводу проблем нехватки тредов в будущем.
При расчетах я заложил увеличение нагрузки в 2 раза и все равно получил, что 600 тредов на сервер нам вполне хватит.
Не хватит — сделаем 1000, 2000, 4000 тредов.
Но, на самом деле, мы раньше упремся в CPU из-за десериализации ответов от бэкендов, чем в нехватку тредов.afiskon
05.04.2016 15:30Мм… не могли бы вы пояснить переход к «необязательно выделять тред под коннект». Вот у меня крутится какой-то background процесс который в какой-то момент, не суть важно какой, приходит к пониманию, что пользователю с коннектом 12345 нужно послать в вебсокет очередной кусок данных. Что происходит дальше?
keyplayer
05.04.2016 16:05+1Например, этот background процесс может записать данные в промежуточный буфер, найти socket, в который нужно записать эти данные, и создать задание по асинхронной записи данных из промежуточного буфера в этот socket. Heinz Kabutz неплохо рассказывает как это происходит в java на низком уровне. Но обычно на таком низком уровне никто не работает, а используют более высокоуровневые библиотеки, например Netty. Это как раз асинхронный неблокирующий ввод-вывод, и в этой задаче он оправдан.
lega
05.04.2016 14:14Вот ещё 5 копеек за "блокирующий" подход:
Так что и в смысле накладных расходов от переключения контекстов 600 потоков для нас не является проблемой.
А в асинхронном коде на переключение контекстов, конкретно в питоне, на это будет тратится много* (гораздо больше) CPU, в итоге асинхронный код все больше проигрывает чем быстрее асинхронные вызовы.
За таймаутами надо следить, это может быть проблемой. Стоит ли она того, чтобы писать асинхронный код? Вопрос открытый.
В асинхронном коде тоже за этим нужно следить, т.к. проблемные конекты тоже потребляют ресурсы.
и мы не можем быстро отмасштабироваться в 100 раз
Это не зависит от подхода, асинхронный или блокирующий.
Я считаю что, должны быть «жесткие» таймауты (но правильно выставленные), если какой-то сервис не укладывается в таймаут, то нужно его фиксить, а не подгонять весь окружающий мир (если речь о подконтрольных сервисах)
Вообщем асинхронный код нужно применять по месту, а не везде подряд.
Так же ещё существуют горутины/корутины/файберы/микро-треды и т.д. которые берут плюсы от обоих подходов.


Vanger13
05.04.2016 15:20+1Мы тут в своей песочнице тоже пришли примерно к такому же выводу. Асинхронищина навязывается Scala Play + Slick фреймворками, однако писать\читать такой код достаточно сложно (по началу, потом наичнаешь привыкать и учишься его «выпрямлять», но это все равно требует доп. усилий), плюс к этому, «оказывается», что не все библиотеки имеют async API — приходится все равно городить thread pool'ы и тюнить их. А вот бонусов от этой асинхронщины нам было вообще никакой — нагрузки у нас нет, проблем запустить рядом еще один инстанс сервиса тоже нет, если появляются проблемы то упираемся в базу, а не в сервис.

ImLiar
05.04.2016 17:30+1До тех пор, пока вы 2+2 складываете, бойлерплейт с Future действительно кажется лишним. А если я хочу N параллельных запросов в базу отослать? Это мне N потоков руками запускать и их контролировать, синхронизировать результат выполнения и вот это всё. Хоп, и уже всё не так радужно с блокирующим подходом.
keyplayer
05.04.2016 17:45У нас бывают случаи, когда нужно сделать несколько параллельных запросов к разным бэкендам. В этом случае мы отправляем запросы асинхронно, получаем CompletableFuture, комбинируем их в одну, блочимся, а дальше опять работаем в синхронном стиле.
Но мы стараемся не отправлять N параллельных запросов, то есть стараемся не делать запросов в цикле, иначе можно одним запросом положить несолько бэкендов :-)
amaksr
05.04.2016 18:07+2Асинхронный подход хорош для ограниченного круга задач, типа на один запрос пользователя сгенерировать множество запросов в другие системы. Для реализации бизнес логики чуть сложнее бложика сложность разработки возрастает непропорционально, не смотря на все Futures, Deferred, Promises и т.д. Да что там бизнес-логика — задача по чтению файла строка за строкой с последующим выводом счетчика строк, из задачи для школьников превращается в задачу, не каждому девелоперу по плечу, если решать ее через асинхронный подход. Как потом искать девелоперов, которые смогут поддерживать такой код, и сколько это будет стоить?
Поэтому со статьей согласен полностью.YourLastDoctor
05.04.2016 18:23+4Вот странно: ну пусть в торнадо с python2 сопрограммы на генераторах требовали некоторого бойлерплейта, в 3м питоне появился async/await, под JVM есть Scala, где Future комбинируются так же, как Option, и любые другие местные монадические типы; во всех перечисленных случаях вложенность кода с вовлечением большего числа отложенных эффектов не возрастает. О каких проблемах идет речь?
keyplayer
06.04.2016 11:14Да, по моему опыту, монадические типы действительно упрощают асинхронный код. Но ведь без них еще проще.

gandjustas
06.04.2016 01:45Проблема только в том, как выглядит асинхронный код?
В c# это вовсе не проблема.
YourChief
06.04.2016 01:47+1Вопроса “блокироваться или не блокироваться при походе на бэкенды” даже не стояло: из-за GIL в python нет настоящего параллельного исполнения потоков, поэтому хочешь — не хочешь, а запросы надо обрабатывать в одном потоке и не блокироваться при походах в другие сервисы.
В питоне потоки непригодны для параллельных вычислений, а вот для параллельного ввода-вывода они вполне пригодны — GIL-то в сисколлах не участвует.keyplayer
06.04.2016 11:21Да, я неточно написал. У нас на самом деле смешанная нагрузка: есть как ввод-вывод при походах на бэкенды, так и вычислительная нагрузка при сериализации, десериализации и бизнес-логике.
axden
12.04.2016 14:55+2Интересно, что Google применил аналогичный подход thread-per-request при разработке Google Percolator, системы инкрементного обновления индекса (вместо Map-Reduce-based).
Описано здесь. В качестве плюсов они приводят:
— код проще
— хорошая утилизация CPU на многоядерных машинах
— легче читать stack trace'ы
— гонок в коде оказалось «меньше, чем опасались»
Самое интересное, что для решения проблем с масштабируемостью и большим числом потоков, они специально пропатчили Linux ядра на своих серверах. И видимо удалось как-то сгладить проблемы. Жаль подробности не приводятся.
Такое получилось вынесение сложности из Application кода в kernel.
Полная цитата из документа:
Early in the implementation of Percolator, we decided to make all API calls blocking and rely on running thousands of threads per machine to provide enough parallelism to maintain good CPU utilization. We chose this thread-per-request model mainly to make application code easier to write, compared to the event-driven model. Forcing users to bundle up their state each of the (many) times they fetched a data item from the table would have made application development much more difficult. Our experience with thread-per-request was, on the whole, positive: application code is simple, we achieve good utilization on many-core machines, and crash debugging is simplified by meaningful and complete stack traces. We encountered fewer race conditions in application code than we feared. The biggest drawbacks of the approach were scalability issues in the Linux kernel and Google infrastructure related to high thread counts.
Our in-house kernel development team was able to deploy fixes to address the kernel issues.
AndreySu
А как же накладные расходы на доступ из кучи потоков к общим ресурсам?
keyplayer
Хорошее замечание.
В тесте я хотел показать, что накладные расходы на переключение между контектами потоков — не проблема при нашем профиле нагрузки.
Проблема синхронизации на общих ресурсах — отдельная проблема.
Но у нас запросы достаточно независимы. Они делят не так много общих ресурсов. Клиент для похода по бэкендам, например. Однако большую часть времени потоки проводят в блокировке ожидания ответа от бэкенда, так что рассчитываем, что проблему синхронизации на общих ресурсах мы не заметим.