
В эти выходные ЦЕРН порадовал физиков со всего мира, опубликовав в открытом доступе 300 терабайт данных с коллайдера. Студенты и школьники могут скачать эти данные и использовать для курсовых и лабораторных работ. Возможно, какой-нибудь любитель даже обнаружит скрытые корреляции, которые ускользнули от внимания специалистов ЦЕРН.
Причины такого решения объяснила Кати Лассила-Перини, работающая на детекторе компактный мюонный соленоид: «После того, как мы исчерпали наши возможности по анализу данных, мы не видим причин, почему не сделать их доступными для всех, — сказала она. — Здесь многочисленные выгоды: начиная с того, что они подогреют интерес старшеклассников к науке, и заканчивая подготовкой специалистов по физике элементарных частиц завтрашнего дня. И лично для меня, как координатора проекта хранения данных компактного мюонного соленоида, это важная часть обеспечения доступности наших исследовательских данных».
Сами данные получены во время экспериментов 2011 года, в основном, от столкновения протонов с энергией 7 тераэлектронвольт. При таких столкновениях порождается множество редких элементарных частиц, которые разлетаются в разные стороны и регистрируются детекторами.
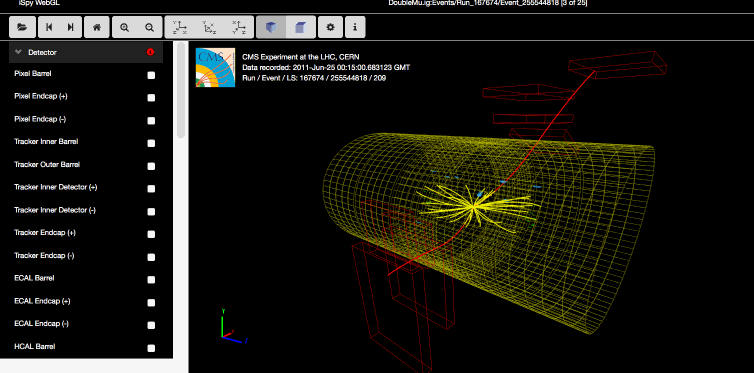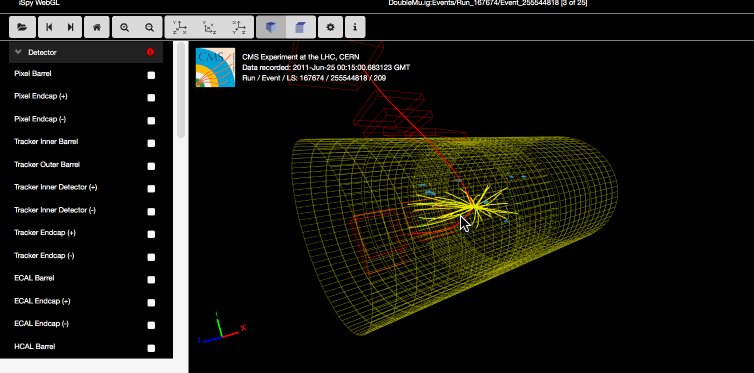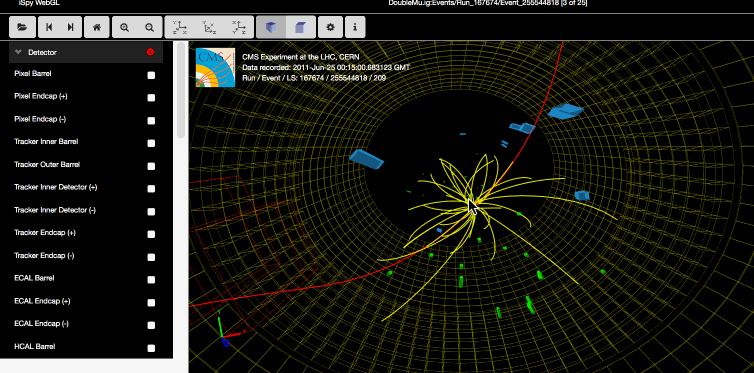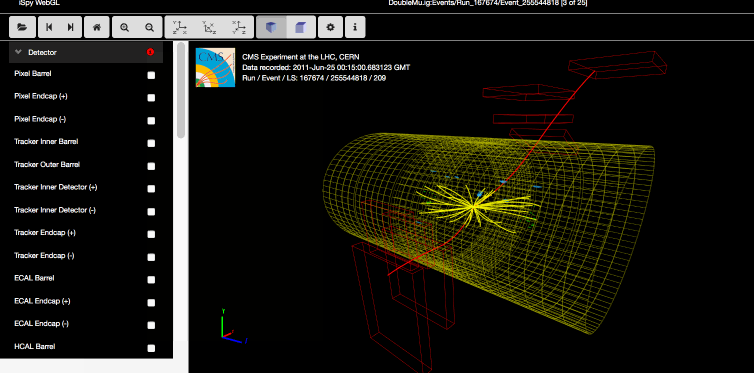
Для обработки и анализа данных ЦЕРН предоставляет инструментарий. Там есть уже готовая виртуальная машина CernVM с операционной системой Linux CERN 6 и всеми установленными программами. Виртуальная машина открывается в VirtualBox или другом менеджере под Linux или Windows. Отдельные инструменты ЦЕРН с открытым исходным кодом опубликованы в репозитории на Github.
Ссылки на все наборы данных и программы собраны на странице CMS Open Data. Там есть «сырые» данные без обработки в формате AOD (Analysis Object Data), данные моделирования для экспериментов 2011 года в формате AODSIM и примеры упрощённых наборов данных для использования в различных приложениях и для анализа.
В прошлый раз ЦЕРН публиковал данные с экспериментов в открытом доступе в ноябре 2014 года: тогда выложили 27 терабайт, собранные в 2010 году.
Комментарии (34)

artsnz
24.04.2016 23:33+1А почему такие старые данные? Почему не опубликовать свежие данные? с 2015 года например?
rPman
24.04.2016 23:42+4Вот аналогия, вы собрались с друзьями, создали компанию и собираете уникальные данные о сокровищах, зарытых пиратами… вы вложили в это дело огромные деньги (покупки артефактов, доступ и анализ библиотечных данных) и еще больше своего времени и сил… через некоторе время, не найдя в части этих данных ничего интересного, вы (не важно почему) подарить часть данных музею/библиотеке...
И тут из толпы выкрики — а почему так мало, — а почему такие старые данные!
artsnz
25.04.2016 00:35+1Насколько мне известно Церн — это не частная контора, а межгосударственный проект, который финансируется из бюджета тех самых государств — это раз, два оно работает на благо науки и человечества, а не ради коммерческих целей, и есть ли в церне коммерческая составляющая? Так почему не открывать данные в онлайне? Речь исключительно про колайдер, а не сторонние проекты церна типа интернетов и пр…
rPman
25.04.2016 01:39+2Пожалуйста, не принимайте мой комментарий как мое личное несогласие с халявой, естественно это не так — все (каждый в отдельности) мы любим халяву, пока недостаточно богаты/могущественны, чтобы обеспечить всем себя самостоятельно (процент таких людей очень и очень мал). Да, само собой все научные достижения должны быть общедоступны, ресурсы должны принадлежать народу, всем по потребностям и т.п… но я не обо этом хотел говорить
Межгосударственные отношения нужно рассматривать с позиции аналогии отношения обычных частных лиц в условиях абсолютной анархии без контроля сверху. И все не равны! Дал где то слабину и сосед откусит от тебя очередной кусок, или еще хуже, вас уже едят, но со скоростью, с которой вы готовы смириться… а если ошибешься, тебя начнут кушать с еще большей скоростью.
Пока ваши действия имеют отношение только к тому что происходит внутри вас, это одно дело, можете играть в коммунизм, показушную демократию или тоталитарный ад оруэла, но как только вы выходите на международную сцену, работают другие правила.
В проекте ЦЕРН участвуют далеко не все страны, и раздавать знания, способных изменить распределение сил, попросту опасно… это как вводить в шахматную партию джокера. И речь тут я думаю даже не в деньгах а в возможностях, которые могут появиться у ранее слабых не-участниках.
К сожалению эта система стремится к стабилизации, и ни о каком развитии говорить не получается.

CYBOPOB
24.04.2016 23:52+6Подозреваю что более новые данные еще находятся в обработке. Не отдавать же возможное открытие кому нибудь другому :-)

Orcus13
25.04.2016 01:25Чтоб не украли научное открытие, видимо они над ними еще работают.
В астрономии фотографии выкладываются в общий доступ также с приличной задержкой.

mrxak
26.04.2016 21:59А пока идет Run 2 «свежих» данных и не будет. Они мало того, что сырые, так ещё и не структурированные. Скорее это защита от «псевдооткрытий». А структурировать их будут уже после. Если не в курсе, при работе коллайдера, пока задние детекторы ещё отрабатывают сигнал от столкновений, в переднем уже сталкиваются следующие частицы. Поэтому при работе это всё сваливается в этакую кучу, потом уже связывается по времени и превращается в те самые «сырые» данные. Где знают, что примерно хотят найти, обрабатывают быстрее, остальное остаётся на потом.
Скрытый текст
Специально взял из share, значит они и так уже где-то доступны. Это, скорее всего, дискретизированный уровень сигнала в каналах одного из детекторов.
pwrlnd
24.04.2016 23:34Представляю себе школьника, у которого под столом стоит пачка винтов на 300+ТБ и нехилый такой компьютер, который всё это сможет прожевать…
TimsTims, никто не заставляет выкачивать все данные. Также особых вычислительных мощностей не требуется, так как это не симуляция, а уже готовые данные.Vjatcheslav3345
25.04.2016 23:21Вот и те кто думал что 300 кб хватит всем 1 тб и ноут представить себе не могли, как мы сейчас — суперкомп размером с пылинку.
LeoPlus
25.04.2016 00:21+1Нука дайте-ка, щас я бозонов накопаю!

Old_Chroft
25.04.2016 02:38Жизнь такова, что в этой области науки еще и LeoPlus-ов накопать можно :-)
Существует масса проектов, (астрономы, генетики, физики) где наши глаза и знания во-первых, а во-вторых любознательность и вычислительные мощности позволя(ю)т найти много всего интересного.
Vjatcheslav3345
25.04.2016 09:15А нельзя ли заливать их в проекты распределённых вычислений и хранить понемногу, дублированно на множестве компьютеров и обрабатывать как самостоятельно — по своим идеям, так и понемногу вычислять что то на общее благо.

Kyoki
25.04.2016 10:01Очень хорошо… Но лучше бы они прикрутили какой-нибудь апи к этим данным, пусть даже платный. Все-таки не у каждого университета есть возможность хранить по 300 Тб.
yea
25.04.2016 11:50А и не нужно хранить всё. Данные носят сессионный характер, можно обрабатывать их частями.
Vjatcheslav3345
25.04.2016 23:16Можно даже свежий трафик обрабатывать с помощью апи и в распределёнке — только договориться с пользователями в соглашении, что новый трафик какое то небольшое время из за научных приоритетов будет обрабатываться шифрованным, а потом автоматом расшифровывается.

TimsTims
> Студенты и школьники могут скачать эти данные
Представляю себе школьника, у которого под столом стоит пачка винтов на 300+ТБ и нехилый такой компьютер, который всё это сможет прожевать…
> для меня, как координатора проекта хранения данных
Похоже, она решила таким образом сделать «бэкап», что если вдруг у неё что-то потеряется, можно попросить копию «у того школьника»
А если серьезно, то это большой шаг по открытию данных науки для каждого. Действительно из миллиардов людей — наверняка есть один тот-самый эйнштейн, который заметит нужную деталь и сделает открытия в науке
rPman
Если бы только винты, так как вычислительные мощности для анализа могут понадобиться гораздо мощнее.
Школьники? может тут ошибка перевода и речь идет о high school т.е. университеты?
TimsTims
Зато какая веская причина выпросить у родителей новый комп с 300тб на борту!)
Grox
Можно делать инкрементальную обработку. И часть данных кэшировать у себя.
TimsTims
Да, помимо знаний — Как всё это обработать и сохранить, надо еще оставить места в голове по теории физики, чтобы хотя бы знать что искать. А мне кажется, что гений физики — он так себе программист…
Grox
Так вы думаете в ЦЕРН все физики-программисты? Объеденяться нужно.
TimsTims
Я не про ЦЕРН, а про школьников, у которых нет 300тб и им надо научиться кэшировать результаты и освоить сложные программы по bigdata перед тем, Как начать изучение данных, используя науку
Grox
А я для примера. Школьник-программер + школьник-физик, вот уже и команда. Винтами по несколько ТБ школьников не удивишь. Кэшировать это совсем не сложно. Сложные программы освоить? Вы больше пугаете. Изучать данные можно и без науки. Это само по себе интересно.
mityada
В исходной статье (http://cms.web.cern.ch/news/cms-releases-new-batch-research-data-lhc) есть фраза
«The “derived datasets” on the other hand require a lot less computing power and can be readily analysed by university or high-school students, and CMS has provided a limited number of datasets in this format.»
То есть часть данных уже обработана и суперкомпьютер под столом иметь не обязательно.
High school это старшие классы средней школы, а не университет.
vkn
High school это как раз средняя школа.
SvyatoslavMC
В России средняя 5-9 класс, у нас аналог High school как раз 10-11 класс.
yea
«Средняя школа» в России — это общее название всего цикла обучения с первого по одиннадцатый класс. После девятого класса дают аттестат об основном образовании, а после одиннадцатого — о полном среднем.
Xaliuss
С 5 по 11 все таки, 1-4 начальное образование, по 9 класс частичное среднее.