- Первое место: 3000 USD.
- Второе место: 2000 USD.
- Третье место: 1000 USD.
- Возможно, мы решим отметить чьи-то чрезвычайно оригинальные решения двумя специальными призами в 400 USD.
- Если Вы отправите кому-то ссылку на этот конкурс, поставив наш адрес в CC, и этот человек займёт призовое место, Вы получите половину суммы приза (разумеется, не в ущерб награде победителя). За одного победителя такую награду может получить только один человек — тот, кто отправил ссылку первым.
Мы ищем талантливых программистов, поэтому авторы интересных решений будут приглашены на собеседования.

Правила
На этот раз мы решили попробовать что-то новенькое: для разнообразия, этот конкурс — не на производительность кода.
Условия конкурса на английском языке размещены на GitHub. Ниже — перевод на русский язык.
- Отправляйте решения с помощью этой формы. По электронной почте решения не принимаются.
- Решения принимаются до 27 мая 2016, 23:59:59 UTC.
- Предварительные результаты будут опубликованы 3 июня 2016, а окончательное объявление победителей — 10 июня 2016.
- Можно отправлять решения многократно, но от каждого участника будет рассмотрено только самое последнее решение, отправленное до окончания срока приёма работ.
- Для тестирования мы будем использовать Node.js v6.0.0 (текущая версия на момент публикации). Можно использовать любые возможности языка, поддерживаемые интерпретатором в стандартной конфигурации.
- Весь код решения должен находиться в единственном файла на JS.
- Решение должно быть на JS. Если Вы предпочитаете CoffeeScript или подобные языки, необходимо оттранслировать решение в JS перед отправкой.
- Нельзя загружать никаких модулей, даже тех, что входят в стандартный комплект Node.js.
- Ваш JS-файл должен быть не больше 64 КиБ.
- Вы можете предоставить один дополнительный файл данных для своей программы (см. ниже). Если Вы предоставляете такой файл, то он делит квоту в 64 КиБ с JS-файлом.
- Если Ваш JS-файл или дополнительный файл данных — продукт генерации, минификации и/или компиляции с других языков вроде CoffeeScript, пожалуйста, приложите архив с исходниками, а также, желательно, описанием подхода. Содержимое этого архива будет опубликовано, но мы не будем его тестировать.
- Нам нужно знать Ваше полное имя, но если Вы хотите, мы опубликуем вместо него псевдоним. Мы сохраним Ваш адрес электронной почты в тайне.
- Запрещается публикация участниками своих решений до окончания конкурса. Нарушители будут дисквалифицированы.
- Задавайте вопросы по условию задачи в комментариях к этой публикации или по электронной почте.
Постановка задачи
Вам нужно написать программу, которая отличает слова английского языка от последовательностей символов, не являющихся словами. В этой задаче мы считаем словами английского языка те и только те строки, которые встречаются в списке words.txt, прилагаемом к условию. Членство в списке регистронезависимое. Казалось бы, это просто — нужно только проверить, встречается ли строка в словаре — если бы не ограничение на размер решения в 64 КиБ.
Едва ли возможно написать программу, которая укладывалась бы в ограничение и всегда давала бы верные ответы. Но 100% правильных ответов и не требуется. Мы измерим, как часто Ваша программа будет отвечать правильно, и победит программа, дающая наибольший процент правильных ответов.
API
Ваш JS-файл должен быть модулем для Node.js, экспортирующим две функции:
init(data)
Необязательно. Если функция экспортирована, она будет вызвана один раз для инициализации модуля. В качестве аргумента
data будет передано содержимое дополнительного файла данных (в виде Buffer), если Вы его предоставили, или undefined в противном случае.test(word)
Эта функция должна возвращать
true, если она классифицирует word как слово английского языка, и false в противном случае. Эту функцию можно вызывать многократно для различных слов.Вместе с программой Вы можете предоставить дополнительный файл данных. Если Вы это сделаете, то тестовая система прочитает этот файл в
Buffer и передаст Вашей функции init. Файл данных делит квоту в 64 КиБ с JS-файлом, то есть ограничение применяется к сумме размеров этих двух файлов. Вы также можете указать, что Ваш файл данных сжат с помощью gzip. Если Вы отметите соответствующую опцию в форме отправки решения, то содержимое файла данных будет обработано функцией zlib.gunzipSync перед тем, как попасть в функцию init. Этот вариант удобен тем, что Вам не нужно ни внедрять в код на JS двоичные данные, ни писать самостоятельно стандартный алгоритм распаковки. При этом, конечно, ограничение по размеру касается сжатых данных; после распаковки их размер вполне может превысить 64 КиБ.Тестирование
Мы будем тестировать Вашу программу на большом количестве слов. Некоторые из них будут реальными словами из предоставленного словаря, а некоторые — генерированными не-словами с различной степенью сходства с настоящими словами, от шума вроде dknwertwi до почти-слов вроде sonicative. Мы будем использовать в тестах только ASCII-строки, содержащие латинские буквы нижнего регистра, а также символ
' (апостроф).В отличие от предыдущих соревнований, Вы можете заранее увидеть наши тесты по адресу hola.org/challenges/word_classifier/testcase. При каждой загрузке Вы получите редирект на адрес, содержащий случайное число. Это число — начальное значение для детерминистического генератора псевдослучайных чисел. С каждым конкретным начальным значением Вы всегда получите один и тот же набор тестов, а, варьируя начальное значение, можете получить множество разных тестов. Генератор возвращает JSON-объект, ключами которого являются 100 различных слов, а значениями —
true или false в зависимости от того, встречается ли слово в словаре (хотя последнее Вы легко можете проверить самостоятельно). С помощью генератора тестов Вы можете сами измерить процент правильных ответов, которые даёт Ваша программа, или сравнить разные версии решения между собой. Мы оставляем за собой право ограничивать частоту запросов к генератору тестов.Наша тестовая система загрузит Ваш модуль один раз. Затем, если модуль экспортирует функцию
init, тестовая система её вызовет. Если Вы предоставили дополнительный файл данных, он будет загружен в Buffer, распакован при необходимости, и передан функции init в качестве аргумента data. После этого тестовая система вызовет функцию test много раз для разных слов и подсчитает число правильных ответов. Значения, которые возвращает функция, будут приведены к булевым.Мы будем генерировать тесты тем же генератором, который описан выше. Мы сгенерируем некоторое количество блоков по 100 слов. Решения всех участников получат одни и те же наборы тестов. Мы возьмём столько блоков по 100 слов, сколько потребуется для того, чтобы с уверенностью различить между результатами тройки призёров. В случае практически неразличимых результатов мы оставляем за собой право разделять призы между несколькими участниками. Вместе с результатами конкурса мы опубликуем начальные значения псевдослучайного генератора, которые мы использовали для тестирования, и исходный код генератора тестов.
Отправка решения
Для отправки решений пользуйтесь формой. Мы не принимаем решения по электронной почте.
Мы ожидаем, что многие решения будут содержать генерированный, минифицированый, сжатый код или данные, и поэтому просим отправить нам также и исходники решения. Если код или данные — результат генерации, приложите, пожалуйста, генератор. Если код минифицирован или сжат, включите оригинал, а также программу для сжатия, если это не публичный модуль. Если код скомпилирован из другого языка вроде CoffeeScript, включите оригинал на этом языке. Мы также просим Вас по возможности включить файл README с кратким описанием Вашего подхода к решению (на английском языке). Не включайте, пожалуйста, словарь из условия задачи — он у нас уже есть. Всё это упакуйте, пожалуйста, в tar.gz или zip, и отправьте нам вместе с решением. Размер этого архива не учитывается при проверке ограничения на размер решения в 64 КиБ. Мы опубликуем содержимое Вашего архива, но не будем его тестировать. Оно также поможет нам определить, кого наградить специальными призами за оригинальность.
Если у Вас не получается отправить решение, напишите, пожалуйста, комментарий или письмо.
Желаем удачи всем участникам!
Комментарии (312)
VovanZ
27.04.2016 18:53+4Вы статью читали?
> Казалось бы, это просто — нужно только проверить, встречается ли строка в словаре — если бы не ограничение на размер решения в 64 КиБ.
Файл размером 6+ МБ. С собой тащить все данные не получится.
> Нельзя загружать никаких модулей, даже тех, что входят в стандартный комплект Node.js.
Загрузить их откуда-то тоже не получится (ну а как это сделать без модуля http?), да и это явно противоречит духу правил.
romy4
27.04.2016 19:00-9написано, что модули нельзя загружать, но не написано, что нельзя загружать словарь по урлу, если я правильно понял.

feldgendler
27.04.2016 19:03+1А как Вы загрузите словарь по урлу?
romy4
27.04.2016 19:03-6Всё очень зависит от накладываемых ограничений и ОС.
feldgendler
27.04.2016 19:05+1Покажите пример хотя бы для какой-нибудь одной ОС.
romy4
27.04.2016 19:11-7Не хочу, чтобы это наталкивало на какие-то мысли :)
feldgendler
27.04.2016 19:19+6Мы всё равно дисквалифицируем всех, кто придумает, как обмануть тестовую систему.

Jamdaze
27.04.2016 22:06+1А может лучше за это премию дать?
feldgendler
27.04.2016 22:07+7Одно другому не мешает. Мы вполне можем дать премию за оригинальный подход, и при этом дисквалифицировать из основного зачёта.
VovanZ
28.04.2016 00:19+1Как ни странно, соглашусь. Вроде как, это очевидно по «духу» правил, но явно не упомянуто.
feldgendler, я думаю, стоит в явном виде написать, что нельзя работать с сетью и файловой системой (если вы почитаете правила ACM и подобных соревнований — там это явно написано).
dottedmag
28.04.2016 00:59В ICPC нет запрета на использование стандартных библиотек.
VovanZ
28.04.2016 01:22Да, но тут вопрос в том, что считать стандартной библиотекой js.
Можно ли считать модули, входящие в поставку node стандартной библиотекой JS (не node)? В браузере то их нет :)
Так что вопрос неочевидный…feldgendler
28.04.2016 03:13+3«Нельзя загружать никаких модулей, даже тех, что входят в стандартный комплект Node.js».
romy4
27.04.2016 19:02И ещё хотел спросить, на какой ОС (семействе ОС) будет тестирование?
feldgendler
27.04.2016 19:04Ubuntu. Но в отличие от предыдущего конкурса, здесь это не имеет значения, так как нас не интересует оптимизация по производительности. Не могу придумать, как операционная система могла бы повлиять на подход к решению этой задачи.
romy4
27.04.2016 19:09-3Раз нельзя загружать стандартные модули, то значит можно пользоваться тем, что уже загружено в глобальном пространстве. Из этого можно что-то состряпать.
feldgendler
27.04.2016 19:18+2Желаю удачи. Как сказал выше dottedmag, успешное решение такого типа тянет на специальный приз. Имейте в виду, что обходной способ загрузить какой-либо модуль без использования require запрещён так же, как и require.
Задача, тем не менее, не об этом.

dom1n1k
27.04.2016 19:15Ну как отфильтровать действительно случайные последовательности — более-менее понятно.
А вот как бороться с «почти словами» с 1-2 опечатками — пока даже идей никаких нет.feldgendler
27.04.2016 19:21+1Сходство слов с английскими варьируется по плавной шкале. Ваше решение может успешно отсеивать совершенный шум, менее успешно слова с невысокой степенью подобия, совсем плохо — слова с высокой степенью подобия. Чем точнее распознаватель, тем больше шансов на победу.

expolit
27.04.2016 19:41+31. Я правильно понимаю, что задача сводится к написанию алгоритма который сможет ответить есть ли данная последовательность символов в предоставленном словаре, без учета регистра, пробелов или спец символов, т.е. только [a-zA-Z\-]?
2. Я правильно понимаю, Что даже если слово правильное и английское, но его нету в словаре который предоставили — оно считать, что слово не английское?dottedmag
27.04.2016 19:57Да и да.
Вtestбудут подаваться только слова вида[a-zA-Z'-]+, не нужно отфильтровывать пробелы и спецсимволы.expolit
27.04.2016 20:08+1Спасибо вам за: https://simple.wikipedia.org/wiki/Llanfairpwllgwyngyllgogerychwyrndrobwllllantysiliogogogoch
3. Т.е. я правильно понимаю то что регистр слов не важен?
4. Там есть все буквы английского словаря как слова с одной буквой. Это тоже считаем что это слово? Например «Z»?

OLS
27.04.2016 22:09Зачем подавать в тестах слова с дефисом, если в словаре нет ни одного слова с дефисом?

vitvad
27.04.2016 19:58+14… дающая наибольший процент правильных ответов.
а вдруг повезетfunction main(){ return Math.random() > 0.5 } module.exports = { init: function(data){ // м-м-м бинарничек console.log('бдыщь') }, test: main }
не, ну а че б и нет? :)dottedmag
27.04.2016 20:13+250% — это baseline, да.
vitvad
27.04.2016 21:03почти
Math.randomvar n = 1000000; new Array(n).join('1').split('').reduce(function(memo){ memo += new Array(100).join('1').split('').map(function(){ return Math.random() > 0.5;}).filter(function(item){ return item;}).length / 100; return memo; }, 0) / n; // 0.4949049399999358
NeXTs_od
27.04.2016 21:18+1потому что
map calls a provided callback function once for each element in an array, in order, and constructs a new array from the results. callback is invoked only for indexes of the array which have assigned values; it is not invoked for indexes which have been deleted or which have never been assigned values.
© mdcvitvad
27.04.2016 21:20да спасибо уже нашел
callbackfn should be a function that accepts three arguments. map calls callbackfn once for each element in the array, in ascending order, and constructs a new Array from the results. callbackfn is called only for elements of the array which actually exist; it is not called for missing elements of the array.
http://www.ecma-international.org/ecma-262/6.0/index.html#sec-array.prototype.map
Mr_Destiny
28.04.2016 13:13Простите за оффтоп,
Боюсь на сто тестов статистики не хватит чтобы набить 50%.
Тем более что мы имеем две вероятности — того тест в словаре, и того что рандом выдаст >0.5. Поправьте если ошибаюсь, но тогда baseline 25% при условии случайного выбора «слово» — «не слово» для теста.feldgendler
28.04.2016 13:14Программа, всегда возвращающая
false, наберёт 50%. Чтобы сделать хуже, чем 50%, нужно специально постараться.Mr_Destiny
28.04.2016 13:32Да, Вы совершенно правы.
Впрочем, человек в начале треда постарался и сделал 25% с рандомом :)
Интересно, сколько будет подано решений с return false — return true?
vintage
28.04.2016 13:37+150% он сделал. Не усложняйте рассуждения сверх меры :-)
Mr_Destiny
28.04.2016 13:49А, я забыл добавить совпадения типа «нет в словаре» — «нет в словре». Тогда получаем 50%
Надо придумать простое решение которое будет давать меньше 50% и получить приз за spectacular failure.
degorov
28.04.2016 13:53Взять нормальное решение и добавить инверсию… Хотя это уже не очень простое получается.
Mr_Destiny
28.04.2016 13:55+2Да, именно что «не очень простое».
Хотя, если получится простое ошибочное, можно к нему добавить инверсию иии… PROFIT!
dkukushkin
27.04.2016 20:13+2Данная задача чисто алгоритмическая — без привязки к конкретному языку реализации алгоритма. Т.е. уровень знания языка она не отражает. Причем для JS — эта задача нетипичная, язык заточен под другие вещи.
Имх., для поиска специалистов именно на JS — не совсем удачная постановка.dottedmag
27.04.2016 20:16+8Эта задача – для поиска программистов, а не «специалистов на JS».
dkukushkin
28.04.2016 00:04-2Тогда зачем привязали к конкретному языку? Если иметь алгоритм — то его можно легко воплотить на любом языке, даже если ты с этим языком ранее не работал. Это касается именно этой задачи.
На практике для большинства проектов нужны кодеры. И нечего стесняться. Кодер — этот тот человек, который сможет качественно написать код по имеющемуся алгоритму. На самом деле кодерство — не такая уж простая задача, как некоторые думают.feldgendler
28.04.2016 00:18+6К конкретному языку привязали затем, чтобы тестировать всё одной тестовой системой с одним API.
expolit
27.04.2016 20:17+1Есть ли какие то ограничения по памяти? по времени исполнения?
Т.е. если я напишу магический алгоритм, который генерирует этот словарь в переменную, но в итоге он скушает 1GB и займет 100 секунд. Это будет противоречить правилам?dottedmag
27.04.2016 20:22+5Гигабайт и 100 секунд – не противоречит. 10 гигабайт и 1000 секунд – тоже не противоречит. Терабайт и неделя – отказать.

thewizardplusplus
27.04.2016 21:14Вроде бы в правилах данные ограничения не указаны. Стоило бы указать, чисто для проформы. Чтобы как в прошлый раз никто не придрался к вам с претензиями, что его решение несправедливо дисквалифицированно.
Ведь можно, например, найти весь словарь в числе пи, в программе указать лишь смещение, затем в
init()рассчитать пи с нужной тончностью и получить 100% надёжность теста. А потом возмущаться, что вы недождались завершения работыinit()и отдали приз другому.
Imp5
27.04.2016 21:19+9Смещение займёт больше, чем словарь.
Arhont375
28.04.2016 11:30Можно рассчитать смещение смещения и так до тех пор, пока не уложится в ограничения
feldgendler
28.04.2016 11:30+1Смещение смещения займёт больше, чем смещение, и так далее.

napa3um
28.04.2016 11:53+1К тому же велика вероятность, что при переборе смещений наступит тепловая смерть вселенной.
OLS
27.04.2016 21:48+3Как участник предыдущего конкурса, большинство из нововведений решительно одобряю. Появился и определенный детерминизм и возможность предварительно тестировать решение. Единственное, мне кажется, что размер блока в 100 слов несколько маловат — в ходе разработки похоже придется запрашивать десятки блоков для реальной оценки незначительных улучшений в коде.
feldgendler
27.04.2016 22:10Запросите себе один раз достаточно много блоков и используйте их для тестирования всех своих вариантов.

Zavtramen
27.04.2016 21:56+1Что есть 64 КиБ? Первый раз вижу такую аббревиатуру. Вики подсказывает, что это кибибайты и на деле это означает 64000 байт, мне кажется проще именно так и указать в задаче.
napa3um
27.04.2016 22:07+6Кило — множитель 1000, киби — множитель 1024.
Zavtramen
27.04.2016 22:11Ох, совсем старый стал, даже в википедию не могу посмотреть нормально )
Тем более стоило просто указать просто кол-во байт.

SkyHunter
28.04.2016 15:56Однако, здравствуйте. Всю жизнь «килобайт» означал 1024 байта. А кто полагал иначе — считался ламером.
napa3um
28.04.2016 15:59+3Приставки были введены Международной электротехнической комиссией (МЭК) в марте 1999 года. После 1999 года ламеры и эксперты по приставкам поменялись местами.
https://ru.wikipedia.org/wiki/Двоичные_приставки
https://habrahabr.ru/post/193256/
feldgendler
27.04.2016 22:11+11 кибибайт = 1024 байта. Дурацкое сокращение КиБ использовано только по той причине, что отличие от десятичного килобайта здесь важно.
Zavtramen
27.04.2016 22:18+3Мне кажется лучше указать конкретное число, в данном случае 65536 байт. Оно вполне узнаваемо программистами.
OLS
27.04.2016 22:08А членство точно регистронезависимое? Непонятно, зачем тогда словарь подается на вход в регистрах…
Spiritschaser
27.04.2016 22:12-1> Едва ли возможно написать программу, которая укладывалась бы в ограничение и всегда давала бы верные ответы.
Ну на JavaScript да.feldgendler
27.04.2016 22:12+4Скорее всего, ни на чём нельзя.
Zavtramen
27.04.2016 22:19Не соглашусь, если будет язык программирования в котором ваш словарь будет уже встроен по дефолту, то на нем ваша задача будет решаться парою строк )
Spiritschaser
27.04.2016 23:35-1Для этих целей был придуман Perl. Не факт, что получится, но код будет существенно компактнее.

pro_co_ru
29.04.2016 11:11+2Факт, что не получится.
Исходный файл со словами занимает 6906809 Байт, а требуется ужать всё вместе с кодом до 65535, т.е. чуть более чем в 100 раз.
Что-то мне не верится что из менее чем 1% знаний о исходном наборе данных можно восстановить гарантированно все 100%, какой бы при этом язык не был использован.Spiritschaser
29.04.2016 11:16-6Задача конкурса — выработать алгоритм классификации выборки приложенного словаря с последующим отнесением слов к словарю или не-словарю. Ещё раз повторю, что для таких вещей статистические либы на C и перл подходят больше.
Не, если упиться смузи, можно мокап на JS сразу лепить, потом отладить.
zhaparoff
27.04.2016 22:12+4Допускается ли использование каких-либо open-source библиотек при условии что их код будет включен в файл решения и общий размер будет удовлетворять ограничению в 64КиБ?
pallada92
27.04.2016 22:12+2На данный момент ни в словаре, ни в тестах, символ "-" не встречается. Может так случится, что данные потом поменяются?
feldgendler
27.04.2016 22:14Спасибо, Вы нашли ошибку в условии задачи! Убрал упоминание символа
-.OLS
27.04.2016 23:03+1Правильно ли я понимаю, что файл words.txt зафиксирован и изменяться от текущего состояния на этапе проверки решений не будет?
Temtaime
27.04.2016 22:16+1Можно ли отправить несколько решений?
feldgendler
27.04.2016 22:17Учитывается только последнее решение, отправленное каждым участником. Если у Вас есть несколько вариантов, Вы сами можете протестировать их с помощью генератора тестов и определить, какой лучше.
Temtaime
27.04.2016 22:37А что насчёт символа "-"? Я не нашёл его в words.txt — можно ли все слова с ним считать неправильными?
UPD — надо обновлять страницу :(feldgendler
27.04.2016 23:09Это была ошибка в условии. Убрали из условия упоминание этого символа, в тестах его не будет.
abyss101
27.04.2016 22:17Решения типа прошерстить все доступные ресурсы (файловая систем, интернет, итд) на предмет слов/текстов в принципе могут быть приняты? Или это гарантированная дисквалификация?
feldgendler
27.04.2016 22:18Эти решения невозможны, так как для доступа к интернету и файловой системе нужно загружать модули.
vird
27.04.2016 23:30+1отличает слова английского языка
tsktsk
stddmp
bkbndr
Очень замечательные слова.
weltschmerzes
Очень английскоеvird
27.04.2016 23:35+1Еще перлы
llanfairpwllgwyngyllgogerychwyrndrobwllllantysiliogogogoch
llanfairpwllgwyngyll
feldgendler
28.04.2016 00:59+1Да, в этом словаре много дикостей, в том числе аббревиатуры. Тем не менее, по определению в этой задаче английское слово — это слово из этого списка.
valanchik
29.04.2016 14:06Тогда тот кто первый обучит нейронную сеть на этом словаре и умудрится поместить результат её обучения в 64Кб(gzip) — тот и молодца!
vintage
27.04.2016 23:49+1Как генерируются тестовые примеры? Поровну и тех и тех? Для каждого пункта с равной вероятностью выбирается взять слово из словаря или сгенерировать рандом? Или как ещё?
feldgendler
28.04.2016 00:16Слов и не-слов примерно поровну, но среди не-слов бывают разные. Есть целый диапазон похожести на английские.

datacompboy
28.04.2016 00:39А словарь в 64k не упаковывается, случаем?
feldgendler
28.04.2016 00:50+4Я не думаю, что это возможно, но если окажется возможно, то тот, кому это удастся, достоин награды.

4orever
28.04.2016 05:34Ну мне удалось его в 100КиБ впихнуть. Еще есть, куда оптимизировать, но не уверен, что до 64 ужать получится :)
К тому же это после gzip, а его реализация тоже потребует памяти.
vk2
28.04.2016 09:04+3«Вы также можете указать, что Ваш файл данных сжат с помощью gzip. Если Вы отметите соответствующую опцию в форме отправки решения, то содержимое файла данных будет обработано функцией zlib.gunzipSync перед тем, как попасть в функцию init. Этот вариант удобен тем, что Вам не нужно ни внедрять в код на JS двоичные данные, ни писать самостоятельно стандартный алгоритм распаковки. При этом, конечно, ограничение по размеру касается сжатых данных; после распаковки их размер вполне может превысить 64 КиБ»
sslobodyanyuk
28.04.2016 15:00> … дающая наибольший процент правильных ответов
ну, в таком случае, можно упаковать часть словаря :)OLS
28.04.2016 20:48И это было бы замечательно (и более того — в реальном мире даже сработает !), если бы генерация тестовых выборок у организаторов конкурса использовала частотный словарь, т.е. генерировала реальные слова пропорционально их появлению в реальном мире. А при равномерном использовании шанс получить на входе теста «Hello» и «Actinomycetaceae» равен, что делает Вашу идею не очень перспективной.

wizzard0
02.05.2016 15:59100 это сурово. а сколько процентов success rate выходит, если выкинуть часть словаря?
Spiceman
05.05.2016 13:15+1Ну мне удалось его в 100КиБ впихнуть.
Как? У меня 820КиБ, хоть ты тресни.
Хотя, есть идея как сжать сильнее, но время распаковки O(n!) и будет длиться до конца жизни вселенной.
haldagan
05.05.2016 15:45+1Судя по всему товарищ просто ошибся — либо у него выходит 1МБ с копейками (ошибся на порядок), либо он имеет в виду размер фильтра блума (это для ~50% false-positive), либо он упаковывал с потерями. А так — да, с gzip'ом 100% утрамбовываются примерно в 820-860 КиБ.
Тут ниже есть комментарий о возможности упаковки «где-то в 300 Кб-1 Мб смотря как упаковывать.» — но я постеснялся спрашивать, как была получена первая цифра.haldagan
05.05.2016 16:27Зря я, наверное, так категорично усомнился в способностях незнакомого человека. Посему заранее прошу прощения и вопрошаю 4orever: А действительно ли Вы упаковали словарь в 100 КиБ без потерь И требует ли алгоритм распаковки существенного количество байт на реализацию? Если требуется более одного-двух кибибайт в обфусцированном виде, то, думаю, стоит включить эту цифру в общий размер словаря.
4orever
06.05.2016 01:00Как написал чуть ниже — ошибся конечно. Я экспериментировал с префиксным деревом (тогда я еще не знал о том, как оно называется) + свой наскоро состряпанный формат сохранения в текст, а дальше gzip. Современные архиваторы достаточно умны, чтобы абстрагировавшись от содержимого выдать наилучший результат. Попробовал кое-что нагородить дополнительно, но особой экономии это не дало.
Spiceman
05.05.2016 18:20+2А так — да, с gzip'ом 100% утрамбовываются примерно в 820-860 КиБ.
Какая-то фантастика. Почитаешь комментарии и думаешь, что я тут вообще делаю. Мне чтоб в 820 упаковать пришлось еще некоторую предобработку словаря сделать. И то сжимал winrar-ом. gzip-ом только 920 получается. Как вы это делаете? И что я тут делаю?haldagan
05.05.2016 19:35-1>пришлось еще некоторую предобработку словаря сделать
Разумеется я указал размер после «предобработки» и gzip'a, а не просто ужатого gzip'ом словаря. Имелось в виду, что словарь и после обработки содержит 100% информации о словах (т.е. не укорочен/не испорчен блумом/машинным обучением / etc).

quverty
06.05.2016 18:26WinRAR-ом? У меня после предобработки и gz тоже что-то похожее получилось по размеру, но я ещё и 7z попробовал — получилась типа 730 КиБ. Правда непонятно как это может помочь.
4orever
06.05.2016 00:54Да-да, расслабьтесь :) Как написали выше — ошибся, нечего по ночам такими вещами заниматься :)
100Кб было частичное префиксное дерево.
P.S. ДУмал, что удалил тот коммент.
datacompboy
28.04.2016 22:27$ ./test.coffee
97193/97193 (100.00%)
fn = 0
fp = 0
вот только нет, не упаковывается.dottedmag
01.05.2016 00:32А какого размера-то
test.coffee?vird
01.05.2016 03:07См. выше по комментариям.
https://gist.github.com/vird/453a86cf16903c017b060cdd457baf86
Это просто верификатор. 100% выходит где-то в 300 Кб-1 Мб смотря как упаковывать.
datacompboy
01.05.2016 12:28vird правильно говорит. мне пока удалось в чуть-чуть меньше метра утрамбовать, есть еще возможности ужаться раза в два, но не больше.
в 64к не влезает даже арифметическим кодированием.
Turbo
28.04.2016 02:03+1А вы имеете отношение к организаторам конкурса? У меня предложение. В файле words.txt чуть больше 660К слов. А вы можете сгенерировать файлик схожего размера «words_fail.txt» с неправильными словами? Что бы не насиловать онлайн генератор зазря. )
feldgendler
28.04.2016 03:15+3Я и есть ответственный за проведение конкурса.
Насилуйте генератор на здоровье.Turbo
28.04.2016 10:44А зачем? То есть какой в этом смысл? Сейчас придется писать доп. код, который будет получать слова, потом выкидывать оттуда правильные, а ещё судя по тексту и забанить за нагрузку могут…
degorov
28.04.2016 10:51+1Я 100К слов выкачал в 1 поток минут за 15 и всё. Я не думаю, что мои действия хоть сколько-нибудь нагрузили сервер :)
feldgendler
28.04.2016 11:08За нагрузку не забаним. Просто можем иногда отвечать «Rate limit exceeded» вместо результата, тогда надо чуть подождать и повторить запрос.
maxceem
28.04.2016 04:20Мне тоже было бы интересно получить такой файлик.
feldgendler
28.04.2016 11:11Уважаемые участники, мы предоставили Вам достаточно информации. Чтобы получить её в других форматах, которые вам удобнее, — преобразуйте, пожалуйста, сами.
vird
28.04.2016 15:16+1Используйте на здоровье
for (i = _i = 0; _i < 1000; i = _i += 1) { console.log("https://hola.org/challenges/word_classifier/testcase/" + i); }
node script.js > list
mkdir solution_list
cd solution_list
wget -i ../list
Склеивание результатов, думаю, понятно как реализовать.

Don_Eric
28.04.2016 09:20+3задача кажется чисто математической. Просто подобрать параметры к bloom filter
Imp5
28.04.2016 11:04Ну вот, оказалось, что я только что изобрёл bloom filter.
vintage
28.04.2016 11:18+2
SabMakc
03.05.2016 17:18Всем хороша статья. Ей бы еще реализацию корректную…
Возможно, отрицательные результаты хеш-функции — не очень большая проблема.
То, что JS прекрасно работает с отрицательными индексами — тоже не проблема (как известно, JS и правду умножит и ложь поделит).
А вот то, что в результате фильтр Блума использует в два раза больший объем памяти — уже проблема…
P.S. эх, а только 85% правильных ответов достиг…vintage
03.05.2016 17:50+1В 2 раза больший по сравнению с чем?
На какой выборке? У меня всего 78 на миллионе. С починенным блюмом и парой эвристик.
SabMakc
03.05.2016 18:32Реализация из статьи использует удвоенный объем памяти относительно того, что было задано при инициализации. С этой реализацией у меня 85% было на миллионе тестовых слов. И да, есть дополнительная обработка слов.
vintage
03.05.2016 18:41+1Речь об отрицательных хеш-суммах? Ну так они и сохранение в файл не переживают :-) Так что по любому надо заменять на сложение по модулю.
Чувствую вся разница реализаций будет именно в предобработке слов :-)
SabMakc
03.05.2016 19:02Вот я и предупреждаю о некорректной реализации ;) Может кому времени и/или нервов сэкономлю…
В принципе, исправляется достаточно легко — берем по модулю или меняем 0xFFFFFFFF на 0x7FFFFFFF (меньше кода).
И да, разница в основном будет в доп. обработке слов и в эвристиках.
Ну и в подходах к решению — те же нейронные сети не думаю, что стоит сбрасывать со счетов.
Don_Eric
03.05.2016 18:03можно использовать маленькие блюмы только для префиксов например. занимает мало, а шума отсеивает много
yarulan
28.04.2016 11:31Не влезает (если я правильно посчитал). При вероятности ложноположительного срабытывани в 1% размер фильтра составляет (-(661000 * ln(0.01)) / (ln(2) ** 2)) / 8 / 1024 == 773КиБ, 10% — 387КиБ, 50% — 116КиБ.
Turbo
28.04.2016 11:58Из Вики и статьи:
https://en.wikipedia.org/wiki/Bloom_filter
https://habrahabr.ru/post/112069/
Вероятность ложного срабатывания:

Оптимальное значение k:
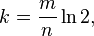
Что для этой задачи равно:
k = 65536/660000*ln(2) = 0,09929697*0,69314718 = 0,068827414. То есть оптимум 1.
p = 1 — e^(-n/m) = 1 — e^10,07080078125 = 1 — 4,2296729941409029988465653752585e-5 = 0,9999577
То есть вероятность ложного срабатывания 0,9999577. Что в общем очень-очень плохо.
Поправьте меня если я где-то ошибся в расчетах.Turbo
28.04.2016 12:05Забыл перевести байты в биты.
p = 1 — e^(-660000/524288) = 1 — e^(-1,25885009765625) = 1 — 0,28398039 = 0,7160196
Результат лучше, но все равно не очень хороший.Don_Eric
28.04.2016 12:13да, получается что общий результат будет 50% + 0.28*50% = 64%
можно его увеличить если добавить юристику — заранее отсеивать шум по грамматическим правилам (типа 5 согласных подряд)Turbo
28.04.2016 12:17Каждое правило уменьшает длину фильтра.
Но вообще там в правилах написано что текстовый файл с дополнительными данными можно архивировать. Дальше все зависит от того насколько хорошо сожмется файлик с фильтром. )
vitalybogryashov
28.04.2016 10:56+1Откуда будут браться неправильные слова? специально искривляться или генерироваться или из другого справочника, например другого языка? Больше вопрос такого плана — не будут ли специально подбираться максимально похожие слова для снижения эффективности скрипта?
feldgendler
28.04.2016 10:58Алгоритм генерации не-слов мы раскроем только при подведении итогов конкурса. Как нетрудно видеть сейчас из генерируемых тестов, не-слова генерируются с различной степенью сходства с настоящими, от шума до слов, которые выглядят настолько «родными», что даже понятны носителю языка.

ainoneko
28.04.2016 13:10Некоторые даже настолько понятны, что уже используются (как упоминаемое в условии «sonicative»). ^_^

vistoyn
28.04.2016 10:58Я правильно понял?
вес файла архива с помощью gzip + js файла должен быть не больше 64 КиБ.
а файл в распакованном виде может быть больше чем 64 КиБ.
slnpacifist
28.04.2016 10:59+1feldgendler, Добавьте, пожалуйста, форму для проверки решения, чтобы можно было убедиться, что решение точно удовлетворяет требованияем. Например, чтобы проверятор запускал решение на 1 блоке и рапортовал ошибки, возникшие при этом (слишком большой размер файлов, не удалось разжать приложенный файл и т.п.)
feldgendler
28.04.2016 11:00Размер файла проверяется формой отправки. В остальном — напишите проверялку сами и выложите здесь, другие спасибо скажут.
slnpacifist
29.04.2016 15:10К сожалению, меня не так поняли.
Я прошу не интерфейс для тестирования, а доступ к тестирующему серверу. Например, в спортивном программировании перед соревнованием проводится пробный тур. На нем участники проверяют, что тестирующая среда ведет себя так, как они предполагают. А в соревнованиях topcoder есть возможность проверить свое решение на тестах из условия задачи.
Возможность проверить свое решение в реальной тестирующей среде, пусть и с дикими ограничениями, помогла бы избежать самой главной ошибки прошлого hola challenge.feldgendler
29.04.2016 15:31+1Что такое «доступ к тестирующему серверу»? Вы шелл туда хотите, что ли?
Imp5
29.04.2016 15:44Думаю, достаточно простого запуска выполнения на двух тестовых словах, одно есть в списке, второго нет (хотя бы «a» и «zzzz»).
Для того, чтобы убедиться, что файл нормально распаковался и модуль загрузился без ошибок.feldgendler
29.04.2016 15:49+2var mod = require('your-program.js'); var data = fs.readFileSync('your-data.gz'); // optional data = zlib.gunzipSync(data); // optional if (mod.init) mod.init(data); console.log('a:', mod.test('a')); console.log('zzz:', mod.test('zzzz'));
Antelle
29.04.2016 22:31+4Скорее всего, говорят о возможности попробовать запустить в окружении. Например new Int32Array(buffer) будет вести себя по-разному в зависимости от endianness операционки. Или кодировка регекспов. В принципе это надо знать и так и при написании модуля учитывать, но тем не менее такие ошибки весьма досадные, поэтому идея загрузить, автоматически попробовать и добавить в табличку результатов — идея здравая, так часто делают.
vird
28.04.2016 15:23+7https://gist.github.com/vird/453a86cf16903c017b060cdd457baf86
Пользуйтесь.
Решение должно лежать в solution.js
Проверочные данные в validation.json
Сжатый словарь в serialize.gz
ivan19631224
28.04.2016 11:00> Мы ожидаем, что многие решения будут содержать генерированный, минифицированый, сжатый код или данные, и поэтому просим отправить нам также и исходники решения
Вопрос: это пожелание или требование? Иными словами, будут ли рассматриваться решения, которые минифицированы/обфусцированы (или, например, скомпилированны из другого языка в javascript) без предоставления исходников? Если это требование, то, я считаю, это следует прописать в правилах более чётко.
Если это требование, то вот ещё более тонкий момент: если я, например, сделал и обучил нейронную сеть, которая решает задачу, обязан ли я описывать топологию сети, а так же предоставлять алгоритм обучения и наборы данных, которые я использовал?feldgendler
28.04.2016 11:05+3По поводу нейронной сети: именно этого мы и ожидаем, да. Это самое интересное. Словами описывать не обязательно, но надо приложить обучающую программу и данные.
Мы не можем машинно проконтролировать соблюдение этого условия, поэтому я вынужден сказать, что решения, не содержащие всех исходников, будут протестированы автоматом. Такой вариант нежелателен, так как мы не сможем оценить красоту решения.

Lonsdaleite
28.04.2016 11:54+1Я считаю, что мой английский не очень плох (фильмы-книги понимаю в основном). Но вот дайте мне сотню рандомных слов из этого words.txt, и я этот тест завалю, потому что мой словарный запас ограничен. А тут надо программу научить…
Вопрос: вдвоем можно участвовать? Приз потом пополам поделить.feldgendler
28.04.2016 11:55+2Я Вас уверяю, носители английского языка сказали бы то же самое.
Можно.
haldagan
28.04.2016 12:01+1>Если Вы отправите кому-то ссылку на этот конкурс, поставив наш адрес в CC, и этот человек займёт призовое место, Вы получите половину суммы приза (разумеется, не в ущерб награде победителя)
Уж простите за вопрос, но правильно ли я понимаю, что существует возможность «перекрестного» приглашения? Обычно в таких случаях «приглашающего» заставляют сначала зарегистрироваться самому, а уж потом приглашать друзей с реферальным кодом.feldgendler
28.04.2016 12:04Мы хотели сделать так, чтобы приглашать могли люди, не собирающиеся участвовать сами. Злоупотребления отфильтруем вручную.
haldagan
28.04.2016 12:16+1Не сочтите за занудство, но подобное обычно в правилах прописывается изначально, именно для того, чтобы действия наподобие
> Злоупотребления отфильтруем вручную.
Не вызывали негатива и вопросов в духе «а как вы фильтровали?», «а я все по правилам делал, за что?» и т.д.feldgendler
28.04.2016 12:19+1Заранее всё предусматривать — это надо тогда юриста нанимать писать условия конкурса, и результат будет выглядеть как лицензионное соглашение и требовать для прочтения и трактовки другого юриста.

FlashManiac
28.04.2016 12:30Всем добрый день!
Как я понимаю метод init(data) запускается один раз и дальше запускается только test(word) много много раз? Или же на каждую сотню-блок — все по новой? Сколько будет минимально блоков?dottedmag
28.04.2016 12:33+1initзапускается один раз,testзапускается много раз.
Зачем вам знать, сколько будет блоков? Производительность в этой задаче неважна.
Don_Eric
28.04.2016 12:31интересная задача, я был не прав по поводу чисто математического решения через блюм фильтр
а если построить структуру типа trie tree, где каждый узел это буквы алфавита и бит, если это слово в словаре. Вероятность принадлежности слова определять как глубину в этом деревеdottedmag
28.04.2016 12:34А сколько места займёт сериализованное
trie?Don_Eric
05.05.2016 19:46+1Trie дерево, которое вместит в себя 75% слов, содержит 1 миллион дуг. В 64Кб вряд ли влезет :/
4orever
06.05.2016 01:24Остается заставить программу по тестовой выборке подобрать оптимальное дерево на 64К, которое даст наибольший процент :)
4orever
06.05.2016 01:27+1Только сдается мне, что мы решим не практическую задачу «отсекать несловарные слова», а просто подберем алгоритм, который лучше обманет другой алгоритм, генерирующий псевдослучайные слова.
Don_Eric
28.04.2016 13:09из-за того, что есть очень много повторений в суффиксах и префиксах, то можно создать 2 дерева, одно проверяет слово сначала, другое с конца
napa3um
28.04.2016 13:53Избыточность суффиксов и префиксов эффективно нивелируется gzip-ом (он словарный) без дополнительных телодвижений.
vird
28.04.2016 16:35Как ни странно, подход не работает. Второе префиксное дерево очень плохо режет. Т.е. почти нет улучшений точности по сравнению с отдельно взятым первым деревом.

Shedar
28.04.2016 13:07+11. Есть ли ограничения по географии участников?
2. С учетом того, что проверки после сабмита нет, будет ли дана возможность исправиться, если засабмиченная версия не запустилась или сразу на выход?feldgendler
28.04.2016 13:15Ограничений нет.
Мы описали API настолько подробно, что считаем, что каждый, кто умеет читать условие задачи, вполне может его выполнить.
molnij
28.04.2016 13:11Зависит ли от чего-то вес ошибки в итоговой оценке? Ошибочно распознанное как английское и ошибочно распознанное как не-английское будут равноценны? Влияет ли длина слова на это?
feldgendler
28.04.2016 13:12Никаких весов. Ложноположительные и ложноотрицательные результаты имеют одинаковый вес, не зависящий от длины слова.

Rogaven
28.04.2016 13:14Не нашёл информации в условиях конкурса – под какими лицензиями выкладываются присланные работы на ваш гитxаб в конце (например здесь https://github.com/hola/challenge_linked_list/tree/master/submissions). А так же как будут рассматриваться работы, если в них лицензия указана явно?
feldgendler
28.04.2016 13:17Вы можете указывать лицензию сами (включите её в архив исходников), но она не должна препятствовать публикации Вашей работы по окончанию конкурса.

Temirkhan
28.04.2016 13:59-3Каждый раз смотрю на конкурсы на python/js и не понимаю(очевидно, виной мой ограниченный кругозор и(ли) непонимание задачи), в чем их сложность? Ради интереса набросал небольшой массив «основополагающих» частей для англоязычных слов и прошелся им в цикле с использованием регулярных выражений. Если это не совсем уж странные слова(например xbybonyjkettjtjzbuqreff), то, вроде, отрабатывает довольно сносно.
dottedmag
28.04.2016 14:03+1Насколько сносно, если не секрет?
Temirkhan
28.04.2016 15:07-1Скормил проверке весь словарь и обнаружил, что сносно — понятие очень относительное)
Array
(
[0] => 320969 //false
[1] => 340717 //true
)
И все же, для интереса открыл список неопределившихся слов. Он буквально напичкан абракадаброй(xbybonyjkettjtjzbuqreff) именами(Abdullah), латинскими словами и аббревиатурами. Если с латынью и именами можно поступить так же, как с остальным алфавитом, то с аббревиатурами все очень плохо — я понятия не имею, как их систематизировать(разве только регулярку задать с чередующимися согласными)dottedmag
28.04.2016 15:22+5Это только половина задачи. Вторая половина — отсеивать неслова.
На словаре ваше решение даёт 51.5% правильных ответов, что на 1.5% лучше, чемfunction(word){ return Math.random()>0.5; }Temirkhan
28.04.2016 16:13-1Не понял… Если из словаря я определил «слова», а остальная часть в подавляющем большинстве является кракозябрами, именами, аббревиатурами, то что остается? «Вычислить погрешность»...?
На словаре ваше решение даёт 51.5% правильных ответов, что на 1.5% лучше, чем function(word){ return Math.random()>0.5; }
Некорректно проводить такое сравнение. Хотя бы потому что оставшиеся 48.5% — это не не определившиеся слова, а «не слова» в своем большинстве.
napa3um
28.04.2016 14:19+1В результате вычисления полного списка регулярных выражений, проверяющих на соответствие словарю, как раз и получится возможное представление префиксного дерева этого словаря, которое уже упомянули выше. Причём, не самое оптимальное представление из возможных.

apro
28.04.2016 14:59а может и третью функцию добавите, типа `right_answer(word, answer)`
будет вызываться после test(word) и давать обратную связь алгоритму, чтобы он доплнительно обучался во время теста?
ComradeAndrew
28.04.2016 15:04Обучите сами. У вас есть все слова которые считаются правильными. И генератор неправильных.

vermilion1
28.04.2016 16:23Мы будем использовать в тестах только ASCII-строки, содержащие латинские буквы нижнего регистра, а также символ ' (апостроф).
Значит ли это, что из словаря будут исключены аббревиатуры? Аббревиатура в нижнем регистре это уже слово (валидное или нет).napa3um
28.04.2016 16:53+3Это значит, что весь словарь можно привести к нижнему регистру перед обучением своей модели.

n0isy
28.04.2016 17:35Более того, передаётся на проверку слово в нижнем регистре, а не как изначально. Из-за этого трётся доп. информация — является ли это слово «аббревиатурой», либо именем собственным, либо просто «словом».
sarytchev
28.04.2016 18:44-2Что взять за основу для генерации слов?
feldgendler
28.04.2016 18:45+1Не понимаю вопрос.
sarytchev
28.04.2016 18:47-2на чем логику построить?
приставка +корень+суф.+окончание или просто наиболее встречаемые в словаре слова(корни) из них генерить.
Или все это рандомом
Или как?feldgendler
28.04.2016 18:53+2Вы спрашиваете меня, как решать задачу?
sarytchev
28.04.2016 18:56-4подсказку ищу
vird
28.04.2016 21:39+4Всё-таки очень нужно чтобы можно было проверить рабочий ли submission на конечной машине. Я уже 2 решения отослал с переоптимизацией от closure compiler. Только сейчас заметил когда ужимал мини-решение.
BTW. Тем временем 60,11% в 683 байта и 82.82% в 62464 байт.
Теоретически существует решение в как минимум 90%. Возможно, даже есть 95%.vird
28.04.2016 23:30Присоединяюсь к писавшим выше про список ложных срабатываний. Т.е. должен быть выделен training set и verification set. Это стандарт для задач машинного обучения. Пока я не вижу, чтобы эти выборки были зафиксированы.
У меня получилось решение, которое на диапазоне сидов 0-1000 работало хорошо, расширил диапазон, упало ниже 65%. Тестовый dataset странный предмет, вроде он есть, но на самом деле он бесконечный.
Решение откатил. Качаю dataset по-больше.
mwizard
29.04.2016 00:06+3А что мешает вам самостоятельно разделить данные на обучающую и тестовую выборки? На сидах 0-1000 учите, на 1000-1500 проверяете.
vird
29.04.2016 02:14Получается немного нечестная ситуация. Я имею одну выборку, а другие участники — другую выборку. И тут смотря как кому повезло. А если есть одна выборка на всех, то тут ни у кого нет особых преимуществ.
feldgendler
29.04.2016 05:03+3Все решения мы будем тестировать на одном и том же наборе тестов. Номера блоков мы пока не скажем, кончено.
oleg_chornyi
29.04.2016 05:01+5Никто ж не говорит, что это строго задача машинного обучения. Это один из возможных подходов к ее решению.
Joshua
29.04.2016 11:27+1Генератор иногда отдает настолько похожие слова что у меня вопрос: вы потом проверяете, что генератор сгенерировал ТОЧНО слово ВНЕ словаря?
pro_co_ru
29.04.2016 11:31+1Странно, что про генетическое программирование народ молчит.
А ведь в самом топе будет жесточайшая битва, где победит тот кто лучше сбалансирует все свои словари, фичи и прочие признаки, и ужмёт их в 64 КиБ, вместе с исходником.waterlaz
29.04.2016 20:47+6Вангую, что в первой тройке не будет ни генетического программирования, ни нейронных сетей с, прости Господи, deep learning.

Zifix
29.04.2016 20:55Мне казалось, что генетическое программирование это обходной путь для полного перебора, вы уверены что этот подход вообще принципиально применим к задаче?
pro_co_ru
30.04.2016 09:05+2Думаю, что его можно применить для анализа исходного файла с разных сторон, а не в самом решении.
Да даже те же регулярки, если их будет столько много что они не будут умещаться в 64к, то можно будет подобрать такую комбинацию регулярок, которая будет покрывать больше всего правильных слов и давать меньшее кол-во ошибок на не словах.pro_co_ru
30.04.2016 09:32+1Да и сами регулярки тоже можно мутировать, скрещивать, чтобы получилась популяция регулярок, которая не была бы избыточной.

arusakov
30.04.2016 11:38+1Попробуйте написать пару unit тестов :)
pro_co_ru
01.05.2016 16:17+4Да уж, с первой попытки дало 57% на 10000 слов из тесткейсов. Что-то даже страшно стало представить себе, чем там занимаются те, у кого уже за 80% перевалило :)
pro_co_ru
04.05.2016 08:58+1Уже 73.6%, после того как проанализировал те слова в которых ошибаюсь, отсеял наиболее часто встречающиеся паттерны.

inker
29.04.2016 22:06+4А как можно верифицировать отправляемые файлы? Код написан и отправлен, однако боюсь, что ввиду своей рассеяности где-то сглупил (например, опечатался в названиях методов или перепутал файлы при отправке), из-за чего всё труды пойдут насмарку.

caveeagle
30.04.2016 11:23+2Если кому-то нужен файл false-set, размером примерно с true-set, можете брать: false-words
vintage
30.04.2016 12:05Он каким образом получен-то?
caveeagle
30.04.2016 12:27Самым тривиальным — через ихний генератор testcase. Это для тех, кому лениво самому парсить json, и ждать пару часов, пока наберётся достаточная выборка.
vintage
30.04.2016 12:53Заодно таких ленивых можно слить, выдав им неправильные данные ;-)
mwizard
30.04.2016 13:13+1Я вообще не понимаю мотивации доброхотов, которые подсказывают решения — «а давайте нейронными сетями, а давайте генетическим алгоритмом, а давайте префиксным деревом». Этим людям не нужны 1000-3000$? Зачем вы помогаете прямым конкурентам? -_-

webmasterx
30.04.2016 13:22+1затем, что для программиста деньги — вторичное
mwizard
30.04.2016 13:24+1Лихо вы за всех расписались, я аж программировать разучился от такого заявления.
caveeagle
30.04.2016 13:31+5Может, потому что мировой опыт (и теория игр) подсказывает — кооперация эффективнее соперничества =) Кому-то подскажу я, а кто-то подскажет мне — получаются более эффективные решения.
И да, не всё меряется деньгами и первыми местами в конкурсах.Demanoidos
30.04.2016 16:11+1Поддержу. Я вот про фильтр блума из этой ветки узнал, но до сих пор никак не допру, как он работает :)
haldagan
02.05.2016 17:00+5Попытаюсь «на пальцах» объяснить. Не бейте ногами — аналогия заведомо некорректная, но может помочь понять принцип работы.
В природе существует туча разных молекул.
Перед нами стоит задача перебирать пролетающие мимо молекулы и отбирать только молекулы кислорода (O2) и воды (H2O).
Для этого мы будем использовать фильтр блума:
За первую хэш-функцию возьмем процедуру «получить названия атомов», которая возвращает список атомов, из которых состоит молекула.
Применим эту хэш-функцию к необходимым нам молекулам, и получим результат в виде «О» для первой молекулы и «Н, О» — для второй.
Минимальный фильтр блума с максимальным количеством false-positive в нашем случае будет выглядеть так:
H О
1 1
То есть ловя каждую молекулу и применяя к ней хэш-функцию «получить названия атомов», а затем сверяясь с нашим фильтром, мы ни за что не пропустим ни кислород, ни воду, однако мы «нахватаем» false-positive на таких молекулах как H2SO4, С2H5OH, HCl и т.д. Т.к. в этих молекулах тоже содержится H и/или O.
Для уменьшения количества false-positive, мы увеличим размер фильтра. Для максимального уменьшения false-positive на нашей хэш-функции, расширим фильтр до полной таблицы Менделеева.
В итоге мы получим подобный фильтр для наших O2 и H2O:
H He Li Be… O F Ne… Nb Mo…
1_0__0_0_..._1 0 0__… 0__0…
Теперь наш фильтр не пропустит молекулы С2H5OH и HCl, поскольку при применении к этим молекулам хэш-функции «получить названия атомов» мы получим результаты «C,H,O» и «H,Cl».
Пытаясь сверить «C,H,O» с нашим фильтром мы увидим, что, в нем хоть и установлены биты на местах H и O, но также не установлен бит на месте «С», Что говорит нам о том, что в списке того, что нам нужно, этой молекулы точно нет.
Однако у текущего нашего фильтра все еще будут случаться false-positive на таких молекулах как O3 и H.
Для решения этой проблемы мы введем вторую хэш-функцию вида «получить количество атомов в молекуле», которая будет возвращать количество указанных атомов в тестируемой молекуле.
Она будет применятся после сразу основной на каждом атоме из списка, возвращенного первой хэш-функцией. Наш фильтр тоже увеличится и будет теперь выглядеть примерно так:
H1 H2 H3 H4 H5… He1 He2 He3… O1 O2 O3 O4 O5…
0__1__0__0__0_..._0___0___0__..._1__1__0__0__0…
Этот фильтр уже не пропустит H, потому что после применения обеих наших хэш-функций к этой молекуле мы получим позицию «H1», для которой в нашем фильтре бит не установлен.
Стало хоть сколько-то понятней?
П.С.: Шрифт не моноширинный, парсер жрет пробелы, простите за извращения с "_"Demanoidos
03.05.2016 18:58Благодарю, аналогия прекрасная, моноширинный шрифт не проблема :)
Стало быть, фильтр Блума в чистом виде совершенно неприменим к решению данной задачи с приемлемой точностью, потому что для построения ряда битов надо слишком большое число. Накладных расходов больше, чем профит.
Исходный словарь рядом ухищрений получить ужать до 900 с копейками килобайт, дальше пока неясно, куда двигаться.vintage
03.05.2016 19:37+1900 килобайт — это более 7 мегабит, что даёт крайне высокую точность в фильтре блюма для 600 килослов.
Don_Eric
03.05.2016 20:50смотря что называть «приемлимой точностью»
300Кб для блюма дает точность больше 90%
60Kb — около 70%
chersanya
30.04.2016 15:04+2Скорее всего далеко не все, кто пишет, участвуют — так что просто высказывают свои мысли по этому поводу.
Don_Eric
30.04.2016 18:08+2я не собираюсь участвовать в конкурсе, потому что я не верю что выиграю и жалко на это тратить время, но пообсуждать в решении задачи очень интересно.
vird
30.04.2016 22:09+1Проверил. В списке нету слов из words.txt.
Совпадения с моим списком 55012
Различия 614277 (т.е. в 11 раз больше)
Список претендует на то, что он был получен честным способом.
Я уже организаторам говорил «а давайте всё-таки один общий false dataset». Ну вот. Теперь есть как минимум 2 dataset'а, которые отличаются друг от друга.vird
30.04.2016 22:17Только одно замечание. Наличие дубликатов.
626919 — без дубликатов
669289 — с дубликатами
Некоторые по несколько раз, например, overwort
Kookle
30.04.2016 16:12У меня вопрос к организаторам: сколько всего «не-слов» у вас сгенерено?
Хочу скачать их все, но надо же знать когда остановиться.feldgendler
30.04.2016 16:12Они реально генерируются в момент запроса. У нас не хранится какого-то запаса не-слов.
Kookle
30.04.2016 16:20Выходит что на «не словах» тренировать программу бесмысленно?
feldgendler
30.04.2016 16:25+1Я этого не говорил.
Kookle
30.04.2016 16:31-4Я знаю что не говорили. Спрошу немного по другому — ваш алгоритм генерации не-слов может генерить бесконечное количество не-слов, или есть какой-то предел?
feldgendler
30.04.2016 16:42Понятно, что есть только конечное число слов любой ограниченной длины. Практически достижимых ограничений нет.
mwizard
01.05.2016 10:57+6Немного забавной, хоть и бесполезной статистики.
Сумарно с сида 1 по 254200 всего встречается 10'041'446 уникальных не-слов, и 630'403 словарных слов. В словаре всего 630'404 слова, и единственное, которое до сих пор не встретилось — «constructor». С момента обнаружения последнего уникального слова в сиде 175475 прошло уже 78725 сидов. Для сравнения, чтобы найти предпоследнее слово, потребовалось всего 4475 сидов, в 17.6 раз меньше.
Так что есть хорошая вероятность, что слово «constructor» не встретится в выдаче вообще никогда.
KlonKaktusa
01.05.2016 23:35It probably has something to do with a «constructor» property of javasctipt objects. Looks like a bug.
mwizard
01.05.2016 23:38Я выполняю парсинг Python-овским
json.loads(), а ему глубоко пофиг на специальные свойства JavaScript-а. Так что если баг и есть, то не на моей стороне.
Проверил на node.js для очистки совести:
> s = JSON.stringify({constructor: "foobar"}) '{"constructor":"foobar"}' > JSON.parse(s) { constructor: 'foobar' }

kroshanin
02.05.2016 15:38-3В исходном файле words.txt есть слова, которые отличаются лишь регистром (например, ABEL, Accra).
Их не так уж и мало — приблизительно 31 000, привожу скрипт (mysql) для их выборки:
SELECT word, COUNT(*) AS quality FROM words_good GROUP BY LOWER(word) HAVING quality > 1
Думаю, их стоит исключить из списка, поскольку по условиям задачи все слова будут в нижнем регистре.mwizard
02.05.2016 15:49Об этом уже писали. Словарь дается «как есть», проверяться все слова будут в lowercase безотносительно того, в каком регистре они были в словаре.

zBit
02.05.2016 15:50+2Самому сделать не судьба?
Вы предлагаете организатору конкурса сделать работу за конкурсантов?
degorov
02.05.2016 15:55+2cat words.txt | tr A-Z a-z | sort | uniq > words_dedup.txt
mwizard
02.05.2016 16:24-2Теперь это codegolf-тред.
cat words.txt | sort -fu | tr A-Z a-z > words_dedup.txt
У меня на два непробельных символа короче :)dottedmag
02.05.2016 16:55-3Useless use of cat
sort -fu words.txt | tr A-Z a-z > words_dedup.txtvintage
02.05.2016 17:30-2cat words.txt | sort -unique > words_dedup.txtdottedmag
02.05.2016 23:58-3Тогда уж
sort -unique < words.txt > words_dedup.txt, но мойsortне знает-q.vintage
03.05.2016 01:19-2А мой шелл не знает
<:-)
строка:1 знак:14 + sort -unique < words.txt > words_dedup.txt + ~ Оператор "<" зарезервирован для использования в будущем. + CategoryInfo : ParserError: (:) [], ParentContainsErrorRecordException + FullyQualifiedErrorId : RedirectionNotSupported
vird
02.05.2016 18:10+1(оффтоп) Иногда использование cat оправдано.
https://habrahabr.ru/post/267697/#comment_8591149
4orever
06.05.2016 01:20+2Я немного подостыл к задаче и особо нет времени дальше биться за проценты. Поэтому выкладываю свои дилетантские, далекие от всяких Блюмов и нейросетей, размышления. Может кого-то натолкнут на свежие мысли.
1. Собираем статистику по длине слов на выборке в 1 млн. и выясняем, что простейшее if(strlen > 20 (или около того)) return false; else return true; дает что-то порядка 60% (точную цифру не сохранил).
2. Если тупо проанализировать словарь на отсутствующие 3-х буквенные комбинации с привязкой к длине слова и позиции относительно начала слова, то без всякого ИИ можно получить порядка 72%. С помощью перфиксного дерева можно много комбинаций запихнуть в 50+К, на код останется порядка 14К, вполне достаточно.
3. Любопытно, хотя и ожидаемо — анализ из п.2, но по контрольным суммам дает 50% :) Алгоритм расчета контрольных сумм дает равномерность распределения.
Не имел опыта работы с нейросетями, но общий смысл представляю так: Есть некий набор входных параметров, влияющих на выходные. При этом у каждого входного параметра есть некий весовой коэффициент, от которого зависит, насколько он влияет на результат. Весовые коэффициенты подбираются эмпирически в процессе обучения. Многослойность и т.п. — это уже детали, можно разобраться при желании. Но встает вопрос. Выходной параметр в текущей задаче это есть/нет в словаре. А что можно взять за входные параметры? Длину слова? Префиксы/постфиксы? Ну т.е. буквально на пальцах какие такие признаки будет искать этот пресловутый ИИ в мешанине слов и недослов?napa3um
06.05.2016 01:32+1Вопрос про «буквально на пальцах» (о том, как моделировать задачу и как представлять фичи) как раз и является основной сложностью применения машинного обучения (в любой задаче). Ответ на него будет достоин написания отдельной статьи (после конкурса).
Don_Eric
06.05.2016 08:33я начал с самого простого — задал каждую букву как параметр. Получилось 67%
Интересно попробовать adversarial networks

Gromo
06.05.2016 21:52+5Добавлю немного своих размышлений и результатов исследований:
1. Используя префиксное дерево, дающего 100% результат удалось добиться размера 845Кб
2. То же префиксное дерево, но с результатом 98% весит уже 784Кб
3. 89% — 474Кб
4. 85% — 356Кб
и т.д…
Данная статистика наглядно показывает зависимость размера от результата.
Использование фильтрации по неиспользуемым сочетаниям букв даёт нулевой результат — 3-х буквенные неиспользуемые сочетания занимают 12Кб места, а толку от них 0, т.к. в выборке сгенерированных «неправильных» слов размером в 500тыс слов (ссылка в комментах выше) ни одно из этих сочетаний не используется.
Попытки найти какой-либо шаблон в словах, который бы использовался в словаре, но не использовался бы в сгенерированных словах, не удались. Сгенерированные слова слишком похожи на слова из словаря, а слова из словаря слишком разные. Например, слова с 5 согласными буквами подряд встречаются в словаре 1053 раза, а слова с одной и той же буквой 3 раза подряд встречаются 109 раз. При этом данная статистика бесполезна.
Следующим шагом была попытка использования масок для слов, например, 010101100 — где 0 — гласные, 1 — согласные, либо маски, сгруппированные по буквам, например, проверка одного и того же слова сразу по нескольким маскам, использующим различные группировки букв. Толку от подобного подхода слишком мало — опять же из-за сильной схожести сгенерированных слов со словами из словаря.
Наибольший результат достигается использованием фильтрации по первым буквам слов — для 3 букв при размере 17.5Кб результат — 57%, для 4 букв — 89Кб и 64%, для 5 букв — 73% (размер не смотрел). Использование префиксного дерева позволяет уменьшить размер — 3.5Кб для 3 букв, 24Кб — для 4 букв, 89Кб — для 5. Отсекая малоиспользуемые префиксы для 5 букв можно добиться результата в 71% при размере 60Кб (мой лучший результат). Попытка дополнительно учитывать длину слова и/или конечные буквы значительно увеличивает размер, при этом мало влияя на результат. Например, попытка использовать 2 префиксных дерева по 4 буквы для отсечения слов и с начала и с конца, даёт 66% при размере 58Кб, 5 с начала и 3 с конца — 71% при размере 67Кб. Выводы можете сделать сами.
Думаю, что нейронные сети могут найти более хороший подход к решению данной задачи, однако каким образом можно будет запихнуть результат обучения подобной сети в 64 Кб — не имею ни малейшего представления.
P.S. когда я увидел возможность упаковки 6.3Мб словаря в 100Кб, я был очень удивлён, но у меня появился стимул. Очень жаль, что это оказалось усечённое префиксное дерево :(.
Suntechnic
06.05.2016 23:51Прошел через все описанное, более-менее. Кроме фильтрации по первым трем (4-5) буквам (делал прямо сейчас) — спасибо за стат по этому подходу. Теперь не стану.
Осталось добавить что попытка использовать описанные алгоритмы совместно, не дает хороших результатов, так как множества слов по которым алгоритмы отрабатывают имеют мощные пересечения и если каждый алгоритм дает скажем 57% то совместное применение разве что 58%.
Что до упаковки… как только мы пытаемся применить какую-то допобработку к словарю, степень сжатия результата сильно уменьшается. Мне например удалось ужать словарь что-то до 4,8Мб без потерь, но в итоге упаковался он в те же условные 100Кб.
Что в общем логично, так как любая уменьшающая словарь допобработка уменьшает его избыточность, а меньше избыточность == меншь степень сжатия.
: (
ArtemS
07.05.2016 10:50Например, слова с 5 согласными буквами подряд встречаются в словаре 1053 раза, а слова с одной и той же буквой 3 раза подряд встречаются 109 раз. При этом данная статистика бесполезна.
Не скажите. А сколько раз слова с 5 согласными встречаются среди «не слов»? Если их в разы больше, это вполне можно использовать.Gromo
07.05.2016 14:43Добавление подобной проверки не дало ощутимой разницы при тестировании на 12К случайных слов, но ради интереса я проверил в словаре «неверных» слов и результаты интересны:
Total words: 598216
Words with 5 consonants: 68502 or 11.45%
Words with 3 same letters: 2835 or 0.47%
Против статистики «верных» слов:
Total words: 630404
Words with 5 consonants: 1053 or 0.17%
Words with 3 same letters: 109 or 0.02%
Так что я ошибался — проверка на 5 согласных подряд должна добавить несколько процентов.
Добавлю сюда результат проверки для 4 гласных подряд:
Correct words with 4 vowels: 2447 or 0.39%
Incorrect words with 4 vowels: 6467 or 1.08%napa3um
07.05.2016 14:51Всего лишь нужно эти правила научиться подбирать автоматизировано, и ваша программа превратится в machine learning.


romy4
В чём сложность конкурса скачать файл и найти в нём слово?
feldgendler
Ваша программа не может ничего скачать, поскольку правилами запрещена загрузка любых модулей, с помощью которых это можно было бы сделать.
dottedmag
Если программа без
requireсможет скачать файл, то автор будет вполне достоин спецприза :)Demogor
Для программы — фигня вопрос(решение по конкурсу не проходит, т.к. нельзя вмешиваться в тестовую систему). Для модуля — пока не придумал.
node index.js <words.txt для локального файла
что-нибудь в духе
lynx -dump https://github.com/hola/challenge_word_classifier/raw/master/words.txt>words.txt
node index.js <words.txt
для удаленного файла.
Считывание:
var stdin = process.openStdin();
var result=[];
var t="";
var word=«aaa»;
stdin.addListener(«data», function(d) {
t+=d.toString();
});
stdin.addListener(«end», function(d) {
result=t.split('\n');
var a=result.findIndex((x)=>x.toLowerCase()===word)===-1;
console.log('Result: ', a);
});
romy4
Ок, а где брать словарь? Реализовывать http (ну хоть сокеты доступны)?
dottedmag
Нет, сокеты недоступны.
feldgendler
Сокеты без
requireтоже недоступны. Надо угадывать, похоже слово на английское или нет.romy4
написано, что модули нельзя загружать, но не написано, что нельзя загружать словарь по урлу, если я правильно понял. — верно?
BuriK666
чтоб загрузить словарь нужен модуль http ну или tcp.