Автор статьи — Михаил Комаров, MVP — Cloud and Datacenter Management
В данной статье будут рассмотрены:
- механизм работы со счетчиками производительности;
- настройка сборщиков данных как с помощью графического интерфейса, так и с помощью командной строки;
- создание черного ящика для записи данных.
Также рассмотрим и обсудим работу с утилитой PAL и ее применение для сбора и анализа данных, включая типовые проблемы локализованных систем.
В общем виде задачу о производительности можно представить в виде трех частей: сбор данных, анализ полученных данных и создание черного ящика для упреждающего мониторинга проблемной системы.
Сбор данных
Начнем со всем давно известного Performance Monitor. Это стандартная утилита, которая входит во все современные редакции Windows. Вызывается либо из меню, либо из командной строки или строки поиска в Windows 8/10 вводом команды perfmon. После запуска утилиты мы видим стандартную панель, в которой можем добавить и удалить счетчики, изменить представление и масштабировать графики с данными.
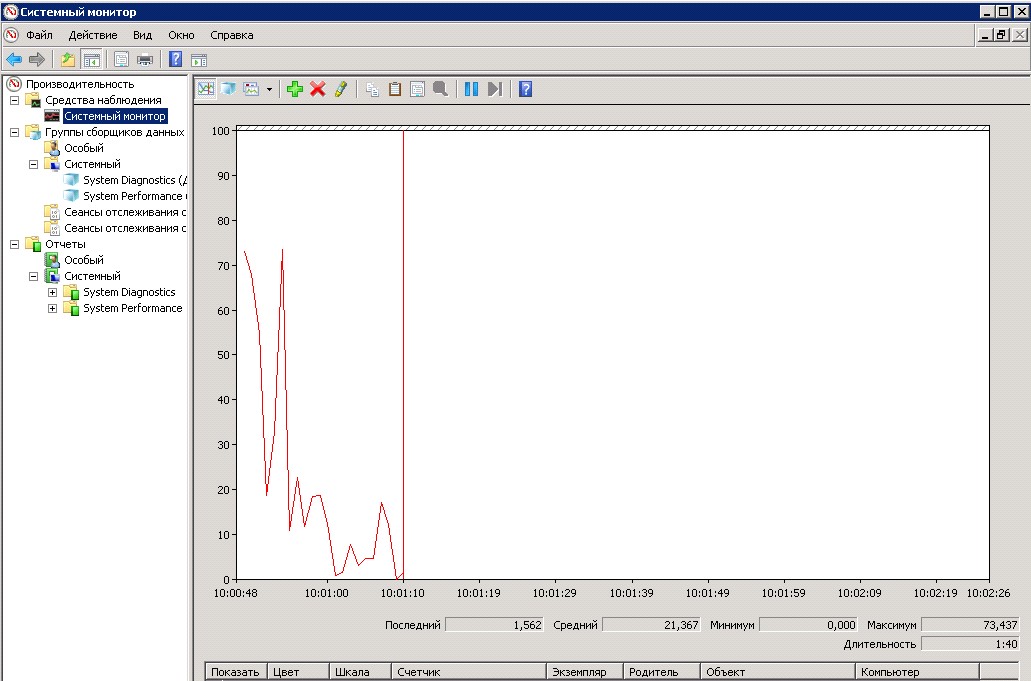
Также есть сборщики данных, с помощью которых производится сбор данных о производительности системы. При определённых навыках и сноровке операции по добавлению счетчиков и настройке параметров сбора данных можно производить из графического интерфейса. Но когда возникает задача настройки сбора данных с нескольких серверов, разумнее использовать утилиты командой строки. Вот этими утилитами мы и займемся.
Первая утилита — это Typeperf, которая может выводить данные со счетчиков производительности на экран или в файл, а также позволяет получить список счетчиков, установленных в системе. Примеры использования.
Выводит на экран загрузку процессора с интервалом 1 сек.:
typeperf "\Processor(_Total)\% Processor Time"
Выводит в файл названия счётчиков производительности, связанные с объектом PhysicalDisk:
typeperf -qx PhysicalDisk -o counters.txtВ нашем случае мы можем использовать утилиту Typeperf, чтобы создать файл с нужными нам счетчиками, который в дальнейшем будем использовать как шаблон для импорта счетчиков в сборщик данных.
Следующая утилита – Logman. Данная утилита позволяет создавать, изменять и управлять различными сборщиками данных. Мы будем создавать сборщик данных для счетчиков производительности. Вот, например, краткая справка по команде Logman, которая относится к счетчикам производительности и управлению сборщиком данных.
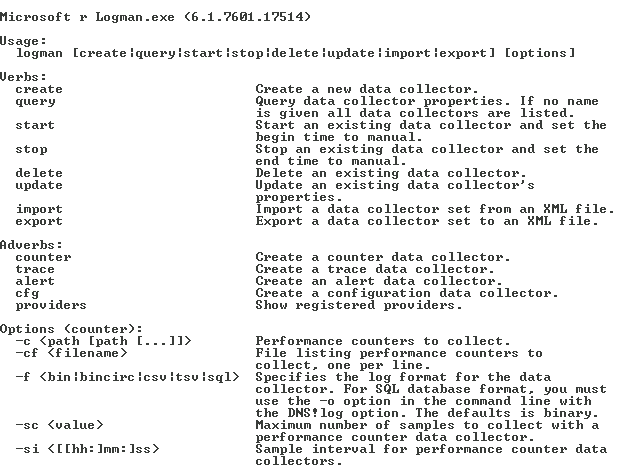

Разберем несколько примеров, которые нам понадобятся в дальнейшем.
Создадим сборщик данных с именем DataCollector_test, импортировав счетчики производительности из файла test.xml:
logman import DataCollector_test -xml C:\PerfTest\test.xmlСоздание файла для сбора данных производительности с включённым циркулярным режимом и заданным размером:
logman update DataCollector_test -f bincirc -max 600Изменение пути файла с данными производительности по умолчанию:
logman update DataCollector_test -o C:\PerfTest\Test_log.blgЗапуск коллектора данных DataCollector_test:
logman start DataCollector_testОстановка коллектора данных DataCollector_test:
logman stop DataCollector_testОтметим, что все эти действия можно производить с удаленным компьютером.
Рассмотрим еще одну утилиту — Relog, которая позволяет производить манипуляции с файлом данных после работы сборщика данных. Вот ее описание:

Ниже несколько сценариев применения этой утилиты.
Извлечение данных счетчиков производительности из файла logfile.blg с применением фильтра со списком счетчиков counters.txt и записью результата в бинарный формат:
relog logfile.blg -cf counters.txt -f binИзвлечение списка счетчиков производительности из logfile.blg в текстовый файл counters.txt:
relog logfile.blg -q -o counters.txtНапрямую работать с этой утилитой мы не будем, но информация о ней в дальнейшем поможет в случае возникновения проблем в файле PowerShell, который генерирует утилита PAL.
Отметим еще один момент, некоторые системы анализа требуют данные с наименованиями счетчиков производительности на английском языке. Если интерфейс нашей системы на русском языке, то нам необходимо проделать следующие манипуляции: завести локального пользователя, дать ему права на сбор данных (обычно дают права локального администратора), войти в систему под ним и в свойствах системы изменить язык интерфейса.

Обязательно выйти из системы и зайти во второй раз под этим пользователем для инициализации английского интерфейса и выйти из системы. Далее указать в сборщике данных, что сбор данных будет производиться от имени этого пользователя.

После этого имена счетчиков и файлов будут на английском языке.
Также отметим возможность сбора данных для SQL Server с помощью утилиты из состава продукта. Это SQLDIAG, которая обрабатывает журналы производительности Windows, журналы событий Windows, трассировки SQL Server Profiler, сведения о блокировках SQL Server и сведения о конфигурации SQL Server. Указать, какие типы сведений нужно собирать с помощью программы SQLdiag, можно в файле конфигурации SQLDiag.xml.

Для конфигурирования файла SQLDiag.xml можно использовать инструмент PSSDIAG с codeplex.com.

Вот так выглядит окно этого инструмента.

В итоге, процесс сбора данных для SQL может выглядеть так. С помощью PSSDIAG мы формируем xml-файл. Далее посылаем этот файл клиенту, который запускает SQLDIAG c нашим xml-файлом на удаленном сервере и присылает нам для анализа результат работы в виде blg-файла, который мы будем анализировать в следующей части.
Анализ данных с помощью утилиты PAL
Данная утилита написана Clint Huffman, который является PFE-инженером Microsoft и занимается анализом производительности систем. Также он является одним из авторов авторизованного курса Vital Sign, который читается в Microsoft и доступен для корпоративных заказчиков, в том числе в России на русском языке. Утилита распространяется свободно, ссылку на нее я приведу ниже.
Вот так выглядит стартовое окно утилиты.

На вкладке Counter Log задаётся путь к файлу данных со счетчиками производительности, собранными ранее. Также мы можем задать интервал, за который будет производиться анализ.

На вкладке Threshold File находится список шаблонов, которые можно экспортировать в формат xml и использовать как список счетчиков для сборщика данных. Обратите внимание на большой выбор шаблонов для анализа производительности для различных систем. Пример загрузки из командной строки был показан выше. Самое ценное, что в этих заранее подготовленных шаблонах установлены граничные значения для этих параметров, которые будут использованы в дальнейшем для анализа собранных данных!!!
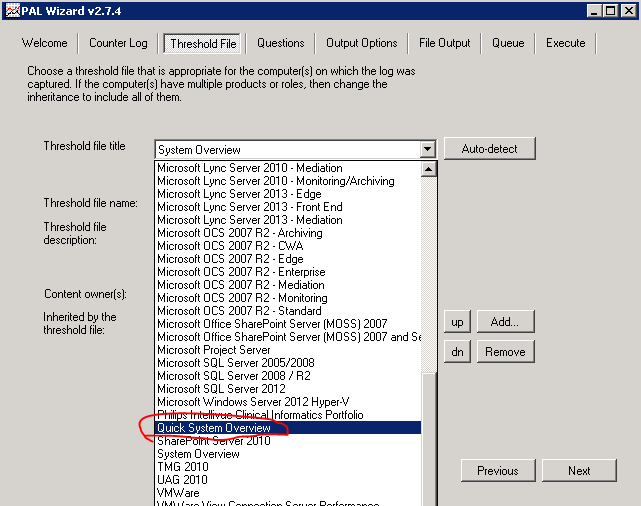

Вот так, например, выглядят граничные значения для счётчиков дисковой производительности:

Мы можем создавать свои шаблоны с использованием нужных счетчиков, которые будут подстроены под нужды нашей организации.
Действуем по следующему алгоритму: на рабочей станции запускаем утилиту PAL, переходим на вкладку Threshold File и экспортируем шаблон в виде xml-файла. На основании этого файла на сервере создаем сборщик данных и запускаем сборку информации.
После сбора данных копируем полученный файл на рабочую станцию, чтобы анализом не нагружать сервер, возвращаемся на вкладку Counter Log, указываем путь к файлу. Снова переходим на Threshold File и выбираем тот самый шаблон, который экспортировали для сборщика данных.
Переключаемся на вкладку Question и указываем объем оперативной памяти на сервере, на котором был осуществлён сбор данных. В случае 32-битной системы заполним UserVa.

Переходим к вкладке Output Options, на которой задаем интервал разбиения для анализа. Значение по умолчанию AUTO делит интервал на 30 равных частей.

Вкладка File Output выглядит довольно обычно, указываем на ней путь к файлам итоговых отчетов в формате HTML или XML.

Вкладка Queue показывает итоговый скрипт на PowerShell. В общем можно сказать, что утилита собирает параметры, которые она подставляет в скрипт PAL.PS1.

Итоговая вкладка задает параметры исполнения. Можно одновременно запустить несколько скриптов и указать число потоков на процессоре. Хотелось бы акцентировать внимание, что обработку blg делает не утилита, а скрипт PowerShell, и это открывает возможности для полной автоматизации анализа логов. Например, каждые сутки перезапускается сборщик данных, в результате освобождается текущий blg-файл и создаётся новый. Старый файл копируется на специальный сервер, где будет запускаться скрипт, обрабатывающий данный файл. После этого готовый HTML- или XML-файл с результатами перемещается в определённую директорию или высылается на почтовый ящик.

Обратите внимание, что утилита должна работать только в английской локализации. Иначе получим сообщение об ошибке.

Также файл с данными должен быть с названиями счетчиков на английском. Выше я указывал, как это сделать. После нажатия Finish запустится скрипт PowerShell, время работы которого зависит от объёма данных и быстродействия рабочей станции.
Итогом работы утилиты будет отчет в выбранном формате, в котором есть графики и числовые данные, позволяющие понять, что происходило в системе за заданный период с учетом граничных значений алертов в шаблоне на вкладке Threshold File. В общем, анализ HTML-файла позволит на начальном этапе определить проблемные места в системе и понять, куда двигаться дальше, как в плане более тонкого мониторинга, так и в плане модернизации или переконфигурирования системы. В блоге Clint Huffman есть скрипт, которым можно конвертировать файл шаблона с граничными условиями в более понятный формат.


Черный ящик
Иногда возникает необходимость в превентивном мониторинге проблемной системы. Для этого мы создадим «черный ящик», в который будем записывать данные производительности. Вернемся к скриптам, описанным ранее.
Создадим сборщик данных c именем BlackBox, импортировав счетчики производительности из файла SystemOverview.xml, который выгрузили из утилиты PAL или создали самостоятельно:
logman import BlackBox -xml C:\ BlackBox\SystemOverview.xmlСоздание файла для сбора данных производительности с включённым циркулярным режимом и заданным размером 600 МБ (около 2 суток при стандартном наборе счетчиков):
logman update BlackBox -f bincirc -max 600Изменение пути файла с данными производительности по умолчанию:
logman update BlackBox -o C:\ BlackBox \ BlackBox _log.blgЗапуск коллектора данных BlackBox:
logman start BlackBoxДанный скрипт создает задачу перезапуска сборщика данных в случае перезапуска системы:
schtasks /create /tn pal /sc onstart /tr "logman start BlackBox " /ru systemНа всякий случай поправим свойства диспетчера данных, чтобы не заполнить место на диске, так как после перезапуска сборщика данных создается новый файл с лимитом 600 МБ.

Отметим, что скопировать файл с данными можно только при остановленном сборщике данных. Остановить же последний можно скриптом или с помощью графического интерфейса.
Остановка коллектора данных BlackBox:
logman stop BlackBoxНа этом закончим часть, посвященную сбору и первичному анализу производительности.
Ресурсы
Performance Monitor
https://technet.microsoft.com/en-us/library/cc749154.aspx
Утилита PAL
https://pal.codeplex.com/
Блог Clint Huffman
http://blogs.technet.com/b/clinth/
Книга Clint Huffman
Windows Performance Analysis Field Guide
http://www.amazon.com/dp/0124167012/ref=wl...=I2TOVTYHI6HDHC
Комментарии (2)

Ghool
01.05.2016 10:31Спасибо за подробный разбор.
Два дополнения:
1) blg-файлы можно копировать и во время сбора данных. Что забавно: объём файла, куда идёт запись может быть нулевым, но файл-копия будет верного объёма :))
2) утилита relog позволяет склеивать не более 19 или 20 blg-файлов за раз
ostapbender
Что-то очень сложно.
Как, например, следующий способ. Взять Statsify (порт Graphite под Windows), установить на требуемые сервера Statsify Agent, в statsify-agent.config перечислить, какие счётчики собирать, потом установить Grafana и наблюдать красивые графики. Плюс автоматом получаем историю, агрегирование данных и т.д.