
В работе сетевого устройства можно выделить две абстракции – управляющий уровень (control plane) и передающий уровень (data plane). Сontrol plane отвечает за логику работы сетевого устройства для обеспечения в дальнейшем возможности передачи пакетов (заполнение различных таблиц, например, маршрутизации, отработку различных служебных протоколов ARP/STP/и пр.). Data plane в свою очередь отвечает непосредственно за передачу полезного трафика через наше сетевое устройство. Т.е. сontrol plane нам предоставляет информацию куда и как слать сетевой трафик, а data plane уже выполняет поставленные перед ним задачи. Данные абстракции могут быть выделены как на логическом, так и на физическом уровне. Но всегда ли на сетевом оборудовании присутствует такое разделение и где именно выполняются функции каждой из абстракций? Давайте попробуем в этом разобраться.
Данное разделение появилось достаточно давно с целью повышения производительности сетевых устройств. Стало ясно, что использование одной абстракции для управления и передачи сетевого трафика неэффективно. Управляющий уровень имеет достаточно сложную логику работы и не выполняет огромное количество операций в секунду. Передающий уровень, наоборот, выполняет относительно однообразные операции, но при этом их очень много. Таким образом, для управляющего уровня требуется интеллектуальное железо, а для передающего – высокопроизводительное. Так как достичь обоих параметров в одной микросхеме сложно и зачастую дорого, логику работы сетевых устройств решили разделить. Это позволило бы реализовывать сложную логику, например, на базе процессоров общего назначения, а высокую производительность получить на специализированных микросхемах. Перед производителями сетевого оборудования на одной чаше весов находится функциональность и производительность, а на второй – стоимость решения. Предлагаю рассмотреть рабочие места управляющего и передающего уровней на примере различных типов сетевых устройств: коммутаторов и маршрутизаторов. Работая сетевым инженером, не всегда глубоко вникаешь в аппаратную часть устройства. Но понимание общих принципов архитектуры необходимо для правильного выбора устройств, дизайна сети, а также подхода к решению сетевых проблем.
Если мы обратим свой взор на программно-определяемые сети (Software-defined Network – SDN), мы обнаружим, что управляющий уровень полностью или частично переносится вообще на выделенное устройство. Однако рассмотрение таких решений оставим за рамками данной статьи.
Коммутаторы
Начнём с коммутаторов, так как тут мы получим наиболее наглядное разделение наших абстракций. Главное для коммутатора– скорость передачи данных. Вся обработка пакетов должна реализоваться на скорости порта (wire-speed), иначе коммутатор будет тормозящим элементом в нашей сети. В связи с этим, именно в коммутаторах мы можем обнаружить реализацию передающего уровня на отдельных микросхемах – ASIC’ах (ASIC — интегральная схема специального назначения). Фактически на коммутаторе управляющий уровень выполняется на базе процессора общего назначения, а передающий уровень, как мы уже отметили, на базе ASIC.
Процессоры, которые устанавливаются в сетевое оборудование, зачастую имеют отличия от тех, которые стоят в наших ПК и серверах. Это чаще всего специализированные процессоры, которые рассчитаны на использование внутри различных устройств (сетевых, систем хранения данных и пр.) и относятся к классу встраиваемых процессоров (embedded processors). Обычно они имеют небольшой размер, потребляют немного энергии и являются частью однокристальной системы (System on a chip – SoC). SoC – практически полноценный компьютер, выполненный на базе одной микросхемы (с (микро)процессором, оперативной памятью, контроллером ввода/вывода, интерфейсами и пр.). Некоторые из таких процессоров заточены на выполнение операций в сетевых устройствах, другие имеют более широкий спектр применения. При этом чаще всего на них можно запустить, например, какие-то решения на базе Unix/Linux, так как они всё же остаются в первую очередь процессорами общего назначения.
Классический ASIC имеет предопределённый набор функций, которые выполняются аппаратно. Фактически общая логика обработки пакетов закладывается в ASIC на этапе производства микросхемы, изменить которую достаточно сложно. В ASIC’е мы получаем приемлемый уровень логики и при этом высокую скорость обработки пакетов. Таким образом, высокая производительность в коммутаторе достигается за счёт выполнения функций передающего уровня на ASIC’ах. И именно ASIC’и являются причиной относительно ограниченной логики работы коммутатора, которую сложно дальнейшем изменить. Можно было бы вместо ASIC использовать микросхемы FPGA (Field-Programmable Gate Array), которые можно перепрограммировать. Но они дороги и энергоёмки. Поэтому производители сетевого оборудования, чтобы не увеличивать стоимость своих устройств, с одной стороны, часть обработки пакетов пытаются перенести на процессор общего назначения (т.е. туда где работает управляющий уровень), что не всегда хорошо сказывается на производительности устройства. С другой стороны, стараются модернизировать ASIC, сделав их более функциональными и даже программируемыми (например, ASIC UADP компании Cisco).
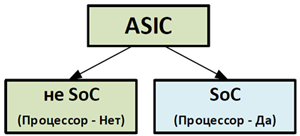
Это чуточку упрощённая формулировка, но для общего понимания, думаю, достаточная. Таким образом, классический ASIC выполнять более специфичные операции, а SoC более общие, так как там есть процессор.
Обычно в коммутаторе стоит один или несколько ASIC’ов. Например, на каждые 12/24 порта ставится свой ASIC. Программирование логики работы ASIC’а выполняет управляющий уровень. Именно он заполняет все таблицы внутри ASIC’а (маршруты, списки доступа и пр.). ASIC может иметь достаточный интеллект, чтобы коммутировать пакеты внутри себя, или же осуществлять коммутацию пакетов через внешнюю шину/коммутационную фабрику. Такая архитектура используется в первую очередь в коммутаторах фиксированной конфигурации (не модульных). Примерами таких коммутаторов могут быть Cisco Catalyst 2960/3650/3850.
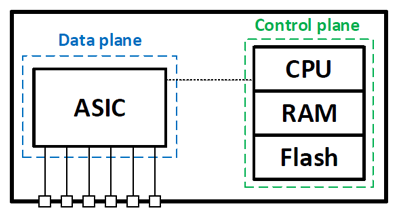
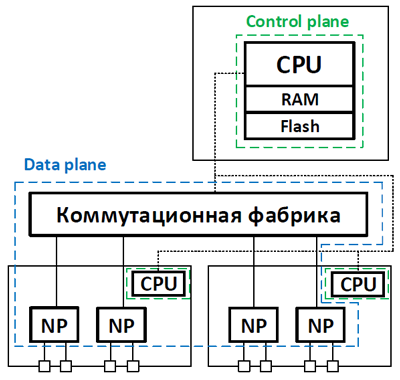
Приведённые в статье структурные схемы коммутаторов и маршрутизаторов являются упрощёнными для акцентирования внимания в первую очередь на расположении управляющего и передающего уровней. Они не включают все структурные элементы устройств.
Если мы имеем дело с модульным коммутатором (коммутатор, в который можно устанавливать платы с различными типами портов), архитектура может быть более сложной. Больше портов, значит, требуется больше производительность и больше ASIC’ов. Существует как минимум два подхода в реализации архитектуры таких коммутаторов.
В первом случае, передающий уровень выполняется централизованно на выделенных ASIC’ах, которые располагаются на отдельной плате. В этом случае ASIC’и на линейных картах являются менее интеллектуальными и выполняют крайне ограниченный набор функций. Программированием логики продолжает заниматься управляющий уровень, которой в свою очередь запускается на своих аппаратных мощностях (используется опять же процессор общего назначения (причём их может быть несколько), расположенный на отдельном модуле — супервизоре). Примером таких коммутаторов могут быть Cisco Catalyst 4500 и Cisco Catalyst 6500/6800 (централизованная коммутация).

* микросхемы Port ASIC, установленные на линейных картах, не обладают большой интеллектуальностью и выполняют крайне ограниченный набор функций
Возможен вариант, где на каждом модуле с линейными портами, стоит своя специализированная плата передачи. В этом случае каждый модуль имеет свой передающий уровень, что позволяет повысить производительность всей «коробки». Можно сказать, что это промежуточный вариант между первым и вторым подходами реализации архитектуры модульных коммутаторов. Примером таких коммутаторов могут быть Cisco Catalyst 6500/6800 (распределённая коммутация).

* микросхемы Port ASIC, установленные на линейных картах, не обладают большой интеллектуальностью и выполняют крайне ограниченный набор функций
Второй подход – использовать достаточно интеллектуальные ASIC’и на линейных картах. В этом случае каждый ASIC может самостоятельно обработать сетевой трафик, выполняя основной набор функций. Т.е. мы сразу имеем распределённый передающий уровень. Это может оказаться более дорогим решением, но при этом зачастую более производительным. Также мы минимизируем при такой архитектуре задержки при передаче пакетов. Примером подобного коммутатора может быть Cisco Nexus 9500.

Архитектура модульных коммутаторов бывает достаточно сложной. В частности, для реализации передающего уровня могут использоваться несколько различных ASIC’ов в рамках одной линейной карты. Каждый из них выполняет свой спектр задач или же объединяет нижестоящие ASIC’и. Коммутационная фабрика также может быть построена на базе ASIC’ов, выполняющих как функции связи между линейными картами, так и определённые виды обработки.
Отметим, что в коммутаторах мы можем иметь распределение уровня управления. Например, в коммутаторе Cisco Nexus 9500 управляющий уровень внутри одного устройства разнесён: часть функций выполняются на супервизоре, а часть на плате линейных портов (на каждой плате стоит свой процессор общего назначения).
До этого момента всё рассмотрение шло в рамках одного устройства. Но многие коммутаторы умеют объединяться в одно логическое устройство по средствам стекирования. В случае если у нас собран стек из коммутаторов, обычно управляющий уровень запускается на основном коммутаторе (его ещё называют активным/мастером). А передающий уровень будет запущен отдельно на каждом коммутаторе в стеке. Т.е. через стековый канал связи управляющий уровень, расположенный на основном коммутаторе, раздаёт управляющую информацию на все коммутаторы в стеке для работы передающего уровня локально. Примером такой модели работы может быть стек Cisco StackWise или HPE IRF.
Маршрутизаторы
Давайте теперь посмотрим, как обстоят дела с нашими абстракциями в маршрутизаторах. Если мы будем рассматривать относительно бюджетные маршрутизаторы, управляющий и передающий уровни будут выполняться на одном и том же железе — процессоре общего назначения (чаще всего в формате SoC). Процессорное время будет распределяться в этом случае между обеими абстракциями. Никаких специализированных микросхем для передающего уровня, как это было в коммутаторах, мы там не найдём. В связи с этим мы получим очень гибкую логику работы устройства, но не самые выдающиеся значения по производительности (десятки и сотни мегабитов в секунду). Причём разные вендорные ухищрения (например, Cisco Express Forwarding) являются лишь оптимизацией обработки пакетов на программном уровне на базе стандартной аппаратной базы. Примерами таких устройств являются, Cisco 800, 1900, 2900 и пр. Ситуация меняется, если наш процессор общего назначения становится многоядерным (например, в Cisco ISR 4300), да ещё таких процессоров может быть несколько (например, в Cisco ISR 4400). В этом случае управляющий и передающий уровни могут выполняться на разных ядрах и процессорах. Причём передающему уровню выделяется сразу несколько ядер, чтобы получить параллельную обработку пакетов, а значит, повысить производительность нашего устройства. Стоит заметить, что некоторые ядра могут быть отданы вообще под сторонние сервисы (конечно, если процессор это позволяет сделать).

Современные SoC имеют многоядерные процессоры. 48 ядрами уже никого не удивишь. А вкупе с интегрированными в SoC акселираторами пакетной обработки, на базе одного SoC можно получить очень хорошую производительность: на рынке есть решения SoC, позволяющие обрабатывать сетевой трафик на скоростях до 40 Гбит/с.
Отдельный разговор – это высокопроизводительные маршрутизаторы. В этом случае обычных процессорных мощностей общего назначения может не хватать. Производители сетевого оборудования переносят передающий уровень на отдельное железо, более адаптированное для обработки большого потока трафика. Фактически мы идём к архитектуре коммутаторов. Но так как маршрутизатор более функционален, обычных ASIC’ов не достаточно. В связи с этим каждый производитель предлагает свои решения.
Один из вариантов – использование специализированных сетевых процессоров (Network Processor — NP или Network Processing Unit — NPU). Сетевые процессоры существенно функциональнее, чем ASIC’и, но при этом более производительные, чем процессоры общего назначения.
- программируемые – есть возможность запускать на них различные сервисы (МСЭ, IPSec, NAT и пр.), не ограничиваясь стандартными сетевыми функциями L2/L3. Также программируемость позволяет без замены железа добавлять новый функционал;
- многопоточные – количество потоков измеряется сотнями (так как процессоры являются многоядерными), что позволяет получить большую производительность;
- энергоэффективность – если сравнивать с обычными процессорами, сетевые процессоры предоставляют лучшее соотношение пропускная способность/Вт. Данный параметр в первую очередь влияет на плотность портов на линейных картах устройств.
В качестве примера рассмотрим маршрутизаторы Cisco ASR 1000, где основные функции передающего уровня выполняется на отдельной плате. На такой плате размещается один или два специализированных сетевых процессоров Cisco QuantumFlow Processor (QFP), которые занимаются непосредственно обработкой трафика. Данный процессор имеет архитектуру RISC и заточен именно под передачу трафика. QFP второго поколения включает до 128 процессорных ядер, на каждом из которых может быть запущено четыре отдельных процесса. Т.е. мы имеем до 256 ядер на одной плате (в случае двух процессоров). Сравнив с архитектурой более простых маршрутизаторов, где всё выполняется на нескольких ядрах, можно сразу сделать вывод, что такие маршрутизаторы являются более производительными.
Сетевые процессоры выпускаются различными компаниями (Cisco, EZChip, Broadcom и пр.) и используются для выполнения функций передающего уровня многими производителями сетевого оборудования. Например, сетевые процессоры используются в оборудовании компаний Huawei (как в маршрутизаторах, например, в NetEngine40E, так и в коммутаторах S12700).
Кроме сетевых процессоров, на рынке представлены специализированные чипсеты, например, Juniper Trio chipset. Они позиционируются между сетевыми процессорами и ASIC’ами. По большому счёту, общий смысл сохраняется – передающий уровень выполняется на специализированном железе, в данном случае чипсете Trio Chipset. Отметим, что до вывода на рынок Trio chipset, компания Juniper активно использовала в своих маршрутизаторах программируемые ASIC’и собственной разработки (Internet Processor ASIC и I-Chip).
Стоит отметить, что в топовых решения, мы будем иметь не только разнесение уровней управления и передачи между разным железом, но и распределение внутри каждого уровня. Например, в маршрутизаторе Cisco ASR 9000 управляющий уровень внутри одного устройства разнесён: часть функций выполняются на процессорной плате, а часть на плате линейных портов. То же самое касается и передающего уровня: сетевых процессоров много и они расположены непосредственно на линейных картах.
В заключение
Так как реализаций архитектур даже у одного вендора достаточно много, рассмотреть их все крайне сложно. Однако, если нам требуется большая производительность, чаще всего передающий уровень будет выполняться на специализированном железе: будь то сетевой процессор, специализированный чипсет, обычный или программируемый ASIC, или что-то ещё. В некоторых устройствах мы встретим даже комбинацию этих микросхем. Нередко производители сетевого оборудования в своём оборудовании используют микросхемы сторонних компаний (например, ASIC’и или сетевые процессоры).
Комментарии (16)

00x2142
18.05.2016 18:32Хорошая статья, с удовольствием почитал.
А как происходит взаимодействие control и data plane? ASR 1000 может быстро гнать трафик, но в режиме NAT, QOS, PBR, ACL etc. его производительность падает. Насколько я понимаю функции ACL можно зашить в ASIC (и кто то так и делает). Что насчет других функций? Трафик тогда отправляется на обычный процессор и там обрабатывается?
ksg222
18.05.2016 23:15+1На ASR 1000 функции control plane выполняются на плате Route Processor (RP), а функции data plane на Embedded Services Processor (ESP). На RP у нас находится процессор общего назначения, а на ESP находится сетевой процессор QFP.
Связь между RP и ESP осуществляется через внутренние каналы связи, в частности через Ethernet out-of-band Control (EOBC). После того как RP просчитал всю необходимую информацию для обеспечения передачи трафика, эти данные через канал EOBC попадают на ESP, программируя его работу. Далее функции обработки и передачи пакета (NAT, QoS, routing, ACL и пр.) выполняются уже непосредственно на сетевом процессоре (для каждого пакета выделяется одно из его ядер). Т.е. практически все функции data plane реализуются на сетевом процессоре (кроме шифрования). А так как там очень много ядер, мы получаем параллельную обработку большого количества пакетов. Грубо говоря, имеем обычный маршрутизатор, только с очень большим количеством ядер.
Производительность действительно зависит от набора включённых сервисов.
Более детально с архитектурой ASR 1000 Вы можете ознакомиться, например, здесь.00x2142
19.05.2016 15:55Ну то есть, как уже и было сказано, архитектура ASR похожа на свич. ИМХО чем выше рангом железка тем меньше разницы между свичом и роутером. Яркий пример — 6500/7600 серия.
Но мне все равно не до конца ясно почему происходит такое падение производительности, если все функции в итоге обрабатываются аппаратно специализованной платой.ksg222
19.05.2016 16:08Падение производительности, видимо, связано с тем, что используется всё-таки сетевой процессор, а не ASIC с жёсткой логикой. Т.е. имеем по большому счёту программную обработку. А значит, чем больше операций нужно произвести над одним пакетом, тем меньше общая производительность. А вот на сколько меньше, уже зависит от качества кода ОС.
kvant21
20.05.2016 02:02+1Ну у свитчевых ASICов тоже есть пределы производительности, вообще говоря. Просто в большинстве случаев их подбирают так, чтобы они могли работать на полной скорости. А так как функциональности у них минимум, то и подобрать сравнительно легко.
А вот при малейшем усложнении задачи начинаются вопросы — сравните QoS на ASR1K и на 6500, и ужаснитесь :)
И вообще, большие модульные свитчи типа 6500/6800 частенько могут оказываться oversubscribed в зависимости от конфигурации, вполне может быть и 2:1, и 4:1, и никто не удивляется )
На ASR же на самом деле всё не так плохо, стандартные NAT, PBR и QoS практически не влияют на производительность, особенно если IMIXом мерять, а не 64byte. И ISR 4K тоже это касается. По сравнению c ISR G2, умирающими чуть более чем полностью от какого-нибудь NAT NVI — прогресс налицо, и прогресс в нужную сторону.
DonAlPAtino
19.05.2016 10:01На ASA'х тоже же все на центральном процессоре крутиться? Или для встроенного коммутатора там ASIC есть?
ksg222
19.05.2016 10:27Да, всё верно. Data-plane (кроме шифрования) выполняется на том же процессоре общего назначения, где и control plane. Архитектура работы сходна с обычным маршрутизатором. В зависимости от модели мы имеем разное количество ядер. Что касается встроенного коммутатора (речь, видимо, про 5505), думаю там стоит самый простой ASIC, который никакой существенной логики не выполняет. Но это моё предположение, так как документа по архитектуре 5505 я не нашёл. Возможно, меня кто-то поправит.
kvant21
19.05.2016 10:38+1Спасибо, хорошая статья. Интересно, куда всё это придет с учетом развития Интеловских x86. Свежее поколение, ЕМНИП, уже 22-ядерное, и это со взрослыми частотами. Догонють ведь рано или поздно все эти модные QFP! Хотя, скорее всего, high-end уровня ASR9K/старших MX в любом случае останется за специальными чипами, там тоже технологии не стоят на месте.
Кстати, не было ли у кого-нибудь опыта с CSR1000V/XRv9K/vRouter? Сколько Mpps ожидать можно? Обещают красиво, например Brocade заявляли line-rate 10G на одно x86 ядро. Звучит как-то слишком хорошо чтобы быть правдой :)ksg222
19.05.2016 10:59Согласен, современные процессоры (не только Intel) предоставляют очень серьёзные мощности. И для обычных устройств их достаточно. Более того прослеживается тенденция виртуализации всего и вся даже в рамках традиционных железок. Привязка к специализированному железу, видимо, останется только в high-end решениях и около них.
Есть опыт работы с CRS1000V и ASAv. Но по максимумам производительности дельного сказать ничего не смогу, так как нагрузка на них небольшая, а какое-то нагрузочное тестирование не проводили. Только цифры, которые предоставляет вендор.kvant21
20.05.2016 02:13Спасибо. Надеюсь, доберусь потестить производительность в обозримом будущем. Интересно, насколько будет влиять включение всяких манипуляций с траффиком. В производительность голой маршрутизации я вполне готов поверить, всё же Intel не зря наверное свой DPDK пилят который год уже. А вот что будет, если навесить хотя бы QoS с шейпером — вопрос, мне кажется, определяющий место этих решений среди железных собратьев )
Хотя, под облачные платформы без большой нагрузки в любом случае интересные штуки.
htol
20.05.2016 12:22Ни куда не приведет. Текущих 2-4-х ядерный процессоров уже выше головы для контрол плейна. А от дата плейна любой проц довольно быстро умрет от прерываний даже с учетом пулинга. Без особых сервисов тестил csr1000v. Максимум что удалось выжать в качестве простой молотилки пакетов — 80 гигабит. Дальше все уперлось в процессор, а было всего-то 60 ядер… Но это мало кому нужно и будет дешевле купить железное решение в виде маршрутизатора для таких масштабов.
kvant21
20.05.2016 23:22Спасибо за цифры, интересно. Но ведь не хай-эндом единым — 80G на краю энтерпрайзной сетки мало кому нужны, например. 10G и то далеко не всегда. И если искомые несколько Mpps укладываются в средней паршивости сервер, то почему бы и нет. А те, кому и этого не нужно, могли бы даже консолидировать с помощью виртуализации что-нибудь еще на то же железо.
Другое дело, что свитч не догнать в любом случае, а маршрутизатор хорош навороченным control-plane и сервисами. И если первое — скорее сильная сторона виртуализированных x86 решений, то второе может стать камнем преткновения. Так-то стареющий 3945Е на Xeone образца 2008 года тоже несколько Mpps может, только вот первый же ACL всё меняет радикально. А новые ISR4K даже придавили шейпером, чтобы этот эффект не был так заметен.ksg222
22.05.2016 23:53Действительно, влияние сервисов на производительность может быть неким «камнем предкновения» для CPU общего назначения.
Если я не ошибаюсь, в маршрутизаторах ISR G2 3900 для обработки трафика в работе используется только одно ядро. Хотя сам процессор является многоядерным. Обусловлено это тем, что обычный IOS может работать только в рамках одного потока. Видимо, из-за этого включение сервисов достаточно ощутимо влияет на производительность. Это справедливо для всей линейки ISR G2. Не уверен, что первый же ACL сильно сказывается на производительности (никогда не проверял), но то, что на неё хорошо влияет включение инспектирования трафика в рамках МСЭ или относительно хитрый QoS, это точно.
В ISR 4000 используется IOS XE, который позволяет обрабатывать трафик в много-поточном режиме. Плюс более современные процессоры. Плюс шейпер, который не даёт маршрутизатору захлёбываться по CPU. В итоге получается коробка с относительно прогнозируемой мощностью. Как мне кажется, достаточно правильный подход, чтобы нивелировать проблему с сервисами. Когда меняешь ISR G2 даже на стоимостный эквивалент ISR 4000, приятно удивляешься разнице в производительности.
Что касается «свитч не догнать в любом случае», тут вопрос спорный, так как производительность некоторых маршрутизаторов (можно посмотреть, например, на решение Cisco CRS) близка или даже превосходит производительность high-end коммутаторов. Правда, как было уже отмечено, грань между маршрутизатором и коммутатором в этих решениях стирается. Да и вообще, есть ли смысл сравнивать их производительности.
А для энтерпрайса, верно отмечено, далеко не всегда нужны какие-то огромные мощности. Да и консолидацию Cisco уже предлагает.
paralon
Сергей, добрый день.
Я правильно из всего этого понял, что по факту роутинг во всех Cisco роутерах до ISR 4300 (то есть вся линейка ISR G2) осуществлялся «софтварно»?
ksg222
Да, всё верно. Он и на ISR 4000 выполняется, можно сказать, программно. Просто там появляются дополнительные выделенные ядра под эту задачу (передачу и обработку пакетов). Вообще с появлением многоядерных процессоров, как мне кажется, «софтварная» обработка может давать очень приличную производительность. Главное чтобы ОС была правильно написана, позволяя эффективно обрабатывать пакеты и делая это в много поточном режиме.
kvant21
Забавный факт: 3925E/3945E построены на натуральном Intel Xeon :)