Реконструкция фильмов при помощи искусственных нейросетей
Предлагаю вашему вниманию перевод авторского описания работы алгоритма автокодировщика, использовавшегося для создания реконструкции фильма “Бегущий по лезвию”, о котором я уже делал статью.В ней была описана общая история создания фильма и то, как Warner подала, а затем отозвала иск о нарушении копирайта. Здесь же вы найдёте более подробное техническое описание алгоритма и даже его код.
В этом блоге я опишу работу, которой я занимался весь прошлый год – реконструкция фильмов при помощи искусственных нейросетей. Сначала тренируется их способность реконструировать отдельные кадры из фильмов, а затем проводится реконструкция каждого кадра в фильме и создание последовательности кадров заново.
Используемый тип нейросетей называется автокодировщиком. Автокодировщик – тип нейросети с очень малым размером скрытого слоя. Он кодирует порцию данных в гораздо более короткое представление (в данном случае – в набор из 200 чисел), а затем реконструирует данные наилучшим возможным образом. Реконструкция не идеальна, но проект был по большей части творческим исследованием возможностей и ограничений данного подхода.
Работа была проделана в рамках диссертации на факультете творческих вычислений в институте Голдсмита.
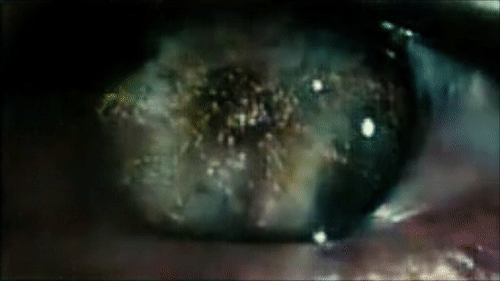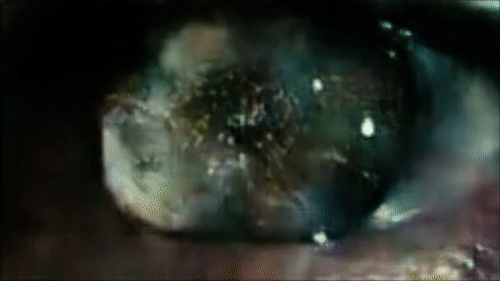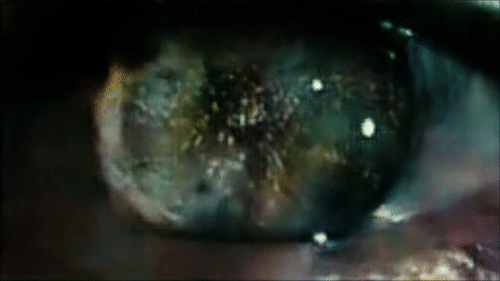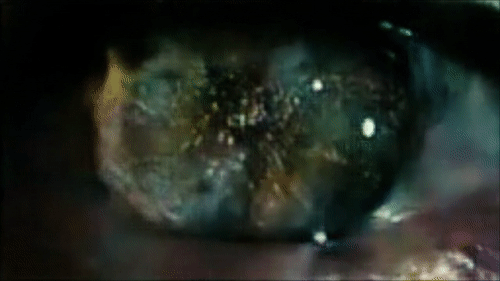
Реконструкция глаза Роя Батти, смотрящего на Лос-Анджелес в первой сцене
Сравнение оригинального трейлера «Бегущего по лезвию» с реконструкцией
Первые 10 минут реконструкции фильма
Техническое описание
В последние 12 месяцев резко пошли вверх интерес и усилия разработчиков в использовании нейросетей для генерации текста, картинок и звуков. В частности, за последние месяцы серьёзно продвинулись методы генерации картинок.

Изображения спальных комнат, созданные DCGAN
В ноябре 2015 Рэдфорд с соавторами чрезвычайно удивили сообщество интересующихся данной темой, использовав нейросети для создания реалистичных изображений спальных комнат и лиц, используя состязательный метод обучения нейросетей. Сеть создаёт случайные примеры, а сравнивающая сеть (дискриминатор) пытается отличить сгенерированные картинки от настоящих изображений. Со временем генератор начинает производить всё более реалистичные изображения, которые дискриминатор уже не в состоянии отличить. Состязательный метод впервые был предложен Гудфелло с соавторами в 2013 году, но до работы Рэдфорда не представлялось возможным создавать реалистичные изображения при помощи нейросетей. Важным прорывом, сделавшим это возможным, стало использование «свёрточного автокодировщика» [convolutional autoencoder] для создания изображений. До этого предполагалось, что такие нейросети не могут эффективно создавать картинки, поскольку использование накапливающихся слоёв приводит к потере информации между слоями. Рэдфорд отмёл использование накапливающихся слоёв и просто использовал пошаговое обратное свёрточное кодирование [strided backwards convolutions]. (Для незнакомых с понятием «свёрточного автокодировщика» я подготовил визуализацию).

Я изучал создающие модели и до работы Рэдфорда, но после её опубликования стало очевидно, что это правильный подход. Однако создающие состязательные сети не умеют реконструировать картинки, а лишь создают примеры из случайного шума. Поэтому я начал изучать возможности тренировки вариационного автокодировщика – который умеет восстанавливать изображения – с дискриминирующей сетью, использующейся для состязательного подхода, или даже с сетью, оценивающей схожесть реконструированной картинки и реального примера. Но я даже не успел этим заняться, а Ларсен с соавторами уже опубликовали в 2015 году работу, комбинирующую оба этих подхода весьма элегантным способом – сравнивая разницу в реакциях на реальные и реконструированные изображения в верхних слоях дискриминирующей сети. Они смогли выдать выученную метрику схожести [learned similarity metric], кардинально первосходящую попиксельное сравнение ошибок восстановления (иначе процедура ведёт к размытой реконструкции – см. картинку выше).
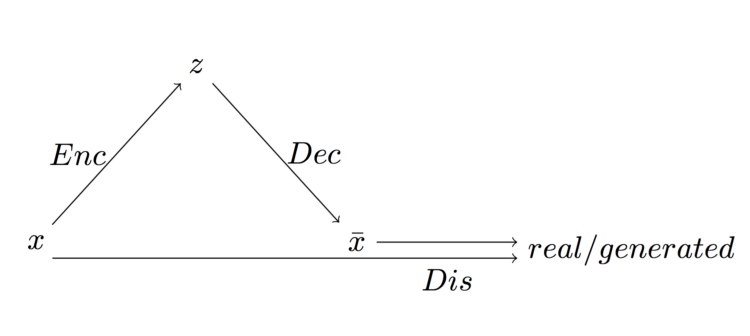
Общая схема вариационного автокодировщика, скомбинированного с дискриминирующей сетью
Модель Ларсена состоит из трёх отдельных сетей – кодировщика, декодировщика и дискриминатора. Кодировщик кодирует набор данных x в скрытое представление z. Раскодировщик пытается воссоздать набор данных из скрытого представления. Дискриминатор обладает как оригинальным, так и реконструированным наборами, и определяет, являются ли они настоящими или поддельными. Реакция на них в верхних слоях сети сравнивается, чтобы определить, как близко реконструкция подошла к оригиналу.
Я сделал эту модель на базе библиотеки TensorFlow, намереваясь расширить её с помощью LSTM для создания видеопредсказаний. Из-за временных ограничений мне этого сделать не удалось. Но это привело меня к созданию модели для генерации больших не-квадратных изображений. Предыдущие модели описывали изображения разрешения 64х64, с 64 картинками для пакетной обработки. Я расширил сеть до картинок с разрешением 256х144 с пакетами по 12 картинок (с большим количеством мой GPU NVIDIA GTX 960 просто не справился). У скрытого представления было 200 переменных, а значит, модель кодировала картинку 256х144 с тремя цветовыми каналами (110 592 переменных) в представление из 200 чисел перед реконструкцией изображения. Сеть тренировалась на наборе данных из всех кадров «Бегущего по лезвию», обрезанных и масштабированных до 256х144. Сеть тренировалась в 6 эпох, что заняло у меня 2 недели.
Художественная мотивация
Реконструкция второго теста Войта-Кампфа
Фильм Ридли Скотта «Бегущий по лезвию» 1982 года – это адаптация классического научно-фантастического произведения «Мечтают ли андроиды об электроовцах?» Филиппа Дика (1968). В фильме Рик Декард (Харрисон Форд) – охотник за головами, зарабатывающий охотой и убийствами репликантов – андроидов, которые так хорошо сделаны, что их невозможно отличить от людей. Декарду необходимо проводить тесты Войта-Кампфа, чтобы различить андроидов и людей, задавая всё более сложные вопросы из области морали и изучая зрачки подопытных, с намерением вызвать эмпатическую реакцию в людях, но не в андроидах.
Один из главных вопросов истории – задача определения того, что является человеком, а что – нет, становится всё более сложной по мере увеличения сложности технологических разработок. Новые андроиды «Нексус-6», созданные корпорацией Tyrell, со временем вырабатывают эмоциональные реакции, а новый прототип Рейчел содержит имплантаты памяти, из-за которых она считает себя человеком. Метод отделения людей от не-людей, несомненно, позаимствован у методологического скептицизма великого французского философа Рене Декарта. Даже имя Декард очень похоже на Декарта. Декард на протяжении фильма пытается определить, кто человек, а кто – нет, при этом не высказанным остаётся предположение, что Декард и сам сомневается в том, является ли он человеком.
Не стану углубляться в философские проблемы, рассмотренные в фильме (по этому поводу есть две неплохие статьи), скажу лишь следующее. Успехи систем глубокого обучения проявляются в том, что системы становятся всё более вовлечёнными в окружающую их среду. При этом, виртуальная система, распознающая изображения, но не вовлечённая в окружение, представляемое этими изображениями – это модель, характеристики которой похожи на картезианский дуализм, в котором тело и дух разделены.
Нейросеть – сравнительно простая математическая модель (если сравнивать её с мозгом), и излишняя антропоморфизация этих систем может привести к проблемам. Несмотря на это, продвижения в деле глубокого обучения значат, что предмет включения моделей в среду их окружения и их соотношения с теориями о природе разума следует рассматривать в контексте технических, философских и художественных последствий.



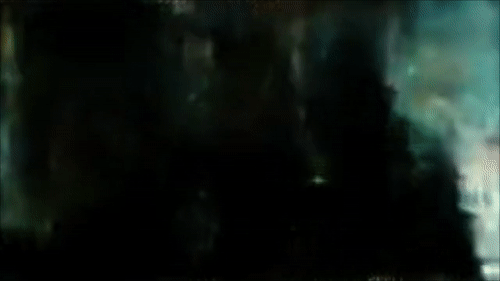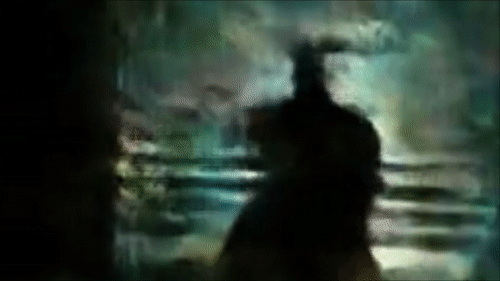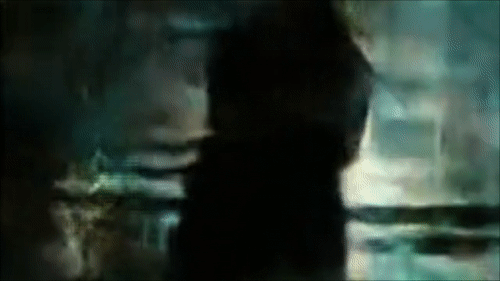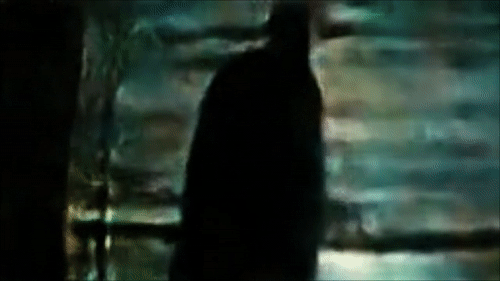
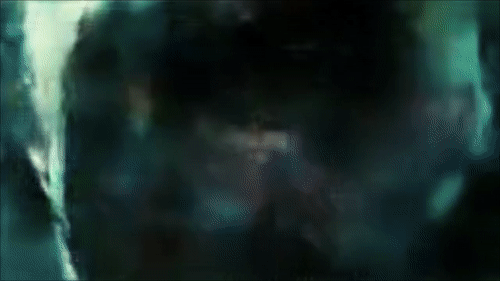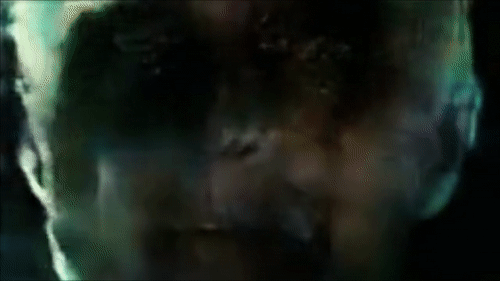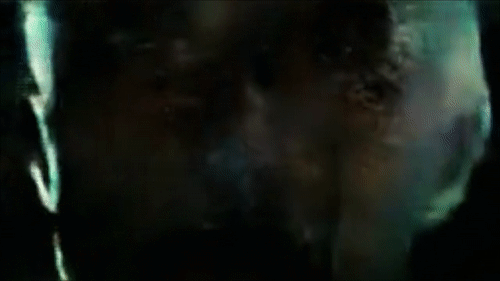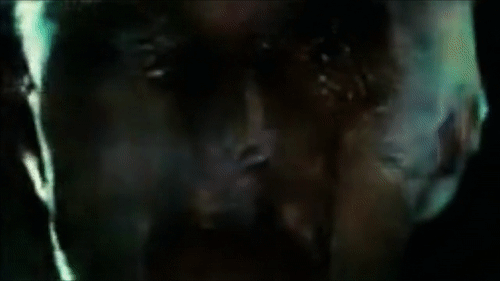
Реконструкция «Бегущего по лезвию»
Реконструированный фильм получился неожиданно связным. Это не идеальная реконструкция, но учитывая, что модель была разработана для эмуляции набора изображений одной сущности, в одном и том же ракурсе, она неплохо справляется с работой, учитывая, как сильно разнятся отдельные кадры.
Статичные и высококонтрастные сцены, мало меняющиеся со временем, реконструированы очень хорошо. Это оттого, что, по сути, модель «видела» один и тот же кадр гораздо чаще, чем просто 6 тренировочных эпох. Это можно рассматривать как избыток данных, но поскольку набор тренировочных данных намеренно искажён, об этом не стоит волноваться.
У модели есть предрасположенность сжимать множество сходных кадров с минимальными отличиями в один (когда, например, актёр говорит в статичной сцене). Поскольку модель представляет отдельные изображения, её невдомёк, что существуют небольшие отклонения от кадра к кадру, и что они достаточно важны.
Также модели с трудом удаётся сделать различимую реконструкцию сцен с малым контрастом, особенно с присутствием лиц. Также она с трудом реконструирует лица, когда изменений очень много – при движении или вращении головы. Это не удивительно, учитывая ограничения модели и чувствительность людей в распознавании лиц. Недавно появились успехи в разработке при помощи объединения создающих моделей и сетей с изменением пространственных моделей [spatial transformer networks], которые могут помочь с этими вопросами, но их описание выходит за рамки этой статьи.
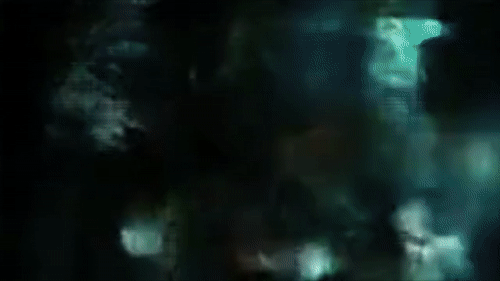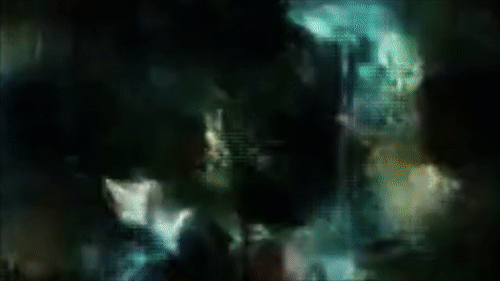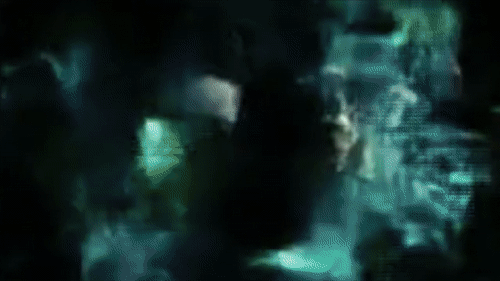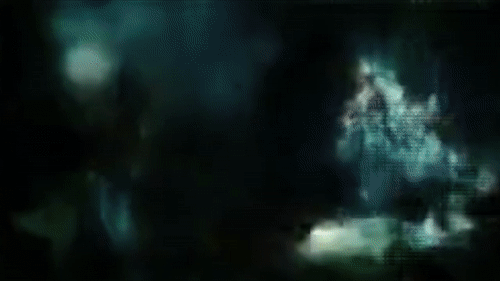

Реконструкция сцен фильма «Койяанискаци» с использованием сети, натренированной на «Бегущий по лезвию»
Реконструкция других фильмов
Пример реконструкции фильма «Койяанискаци» с использованием сети, натренированной на «Бегущий по лезвию»
Кроме реконструкции фильма, на котором сеть тренировалось, можно заставить её реконструировать любое видео. Я поэкспериментировал с разными фильмами, но лучше всего получилось с одним из моих любимых — «Койяанискаци» (1982). Он состоит в основном из сцен с замедлением и ускорением времени, причём сцены очень разнятся, что делает его идеальным кандидатом для проверки работы модели «Бегущего по лезвию».
Ничего удивительного в том, что модель гораздо лучше воссоздаёт фильм, на котором она тренировалась, по сравнению с видео, которых она ни разу не «видела». Улучшить результаты можно, тренируя сеть на большом количестве разнородного видеоматериала, например на сотнях часов случайных видео. Но модель потеряет в эстетическом качестве, которое проистекает из единственного законченного фильма. И хотя чаще всего отдельные кадры сами по себе сложно разобрать, в движении изображения становятся более связными и при этом достаточно непредсказуемыми.
Реконструкция рекламы Apple 1984 года с использованием сети, натренированной на «Бегущий по лезвию»
Реконструкция Matrix III Джона Уитни с использованием сети, натренированной на «Бегущий по лезвию»
Кроме «Койяанискаци» я проверил сеть на реконструкции ещё двух фильмов. Это известная реклама 1984 года Apple Macintosh, снятая тем же Ридли Скоттом. Стив Джобс нанял его, когда посмотрел «Бегущий по лезвию» в кино. У рекламы много общего с «Бегущим по лезвию» в визуальном смысле, поэтому выбор этого видео был оправдан.
Другой фильм – анимация Джона Уитни " Matrix III". Он был пионером компьютерной анимации и первым штатным художником IBM с 1966 по 1969 года. Matrix III (1972) был одним из серии фильмов, демонстрировавших принципы гармонической прогрессии. Он был выбран для проверки того, как модель справится с реконструкцией абстрактных неестественных изображений.



Автокодирование «Помутнения»
После «Бегущего по лезвию» я хотел посмотреть, как модель поведёт себя, если её потренировать на другом фильме. Я выбрал фильм 2006 года «Помутнение» [A Scanner Darkly]. Это ещё одна экранизация романа Филиппа Дика, и стилистически она весьма отличается от «Бегущего по лезвию». «Помутнение» был снят методом ротоскопирования – он был снят на камеру, а затем каждый кадр был прорисован художником.
Модель достаточно хорошо уловила стиль фильма (хотя и не так хорошо, как в работе по переносу художественного стиля), но ей было ещё труднее реконструировать лица. Видимо, это из-за того, что в фильме есть контрастные контуры и есть сложности с распознаванием черт лица, а также присутствуют неестественные и усиленные изменения светотени от кадра к кадру.
Трейлер «Бегущего по лезвию», реконструированный с использованием сети, тренированной на «Помутнении»
Фрагмент «Койяанискаци», реконструированный с использованием сети, тренированной на «Помутнении»
Опять-таки, реконструкция одних фильмов моделями, тренированными на других, практически мало распознаваема. Результаты не такие связные, как с моделью «Бегущего по лезвию», возможно из-за наличия гораздо большего количества цветов в «Помутнении», и в том, что моделирование естественных изображений, для этой модели является более сложным. С другой стороны, изображения необычные и сложные, что приводит к появлению малопредсказуемого видеоряда.
Заключение
Честно говоря, я был сильно удивлён тем, как модель повела себя, когда я начал тренировать её на «Бегущем по лезвию». Реконструкция фильма вышла лучше, чем я мог представить, и я удивляюсь тому, что получилось при реконструкции других фильмов. Обязательно буду делать больше экспериментов с тренировками на большем количестве фильмов, чтобы поглядеть на результат. Я хотел бы адаптировать процедуру тренировки, чтобы она принимала во внимание последовательность кадров, чтобы сеть лучше различала длинные последовательности схожих кадров.
Код проекта доступен на GitHub. Подробности есть также на моём сайте.
Комментарии (14)
Vjatcheslav3345
09.06.2016 08:43«Статичные и высококонтрастные сцены, мало меняющиеся со временем, реконструированы очень хорошо. Это оттого, что, по сути, модель «видела» один и тот же кадр гораздо чаще, чем просто 6 тренировочных эпох. Это можно рассматривать как избыток данных, но поскольку набор тренировочных данных намеренно искажён, об этом не стоит волноваться.»
Можно регулировать обучение анализируя степень изменения в кадрах и организуя обратную связь для показа кадров сети — статичные кадры сеть будет видеть реже а нестатичные — чаще.

kraidiky
10.06.2016 00:04Тоже пару лет назад, когда только начал изучать нейронные сети поставил сетку из 240 нейронов изучать фотку моей девушки. Уходили на работу и поставил её на 8 часов учиться. Возвращаемся, а на неё с экрана смотрит она только примерно такая как на тех картинках из статьи. В общем она на меня посмотрела немного очумевши и попросила больше так не делать. :)
BelBES
Что-то так и не понял, что идет на вход сети и что получается на выходе :(
Intercross
Сначала сеть учат, то есть прогоняют через неё кадр, смотрят, что получается на выходе, а другая система оценивает, хорошо или плохо и насколько, в зависимости от этого изменяется сама сеть, цены шага к отдельным нодам сети, что-то вроде того. Потом кадры прогоняют уже через обученную сеть, выход которой не оценивается, а записывается. Как-то так.
DistortNeo
Если почитать работу, то на входе серия из 12 цветных кадров 256х114 (~1М значений), на выходе — представление в виде массива 200х12, по 200 значений на кадр, из которого обратно реконструируются кадры.
Используются свёртки 5x5 в количестве 80, 160, 320 и 640 штук соответственно на каждый слой, т.е. общее количество вещественных коэффициентов натренированной сети составляет около 30к.
Почему 256х114: а больше в память GPU не влазило и считалось долго.
Главный вопрос: зачем? Для компрессии, например, алгоритм не подходит. 256х114х3 — это 85кб на кадр, 200 значений — это либо 800 байт, либо 1600 байт (float/double), которые, по идее, нельзя больше сжать. Современные кодеки жмут сильно лучше.
HappyLynx
> Современные кодеки жмут сильно лучше.
Тут нужно сделать оговорку, что «сильно лучше» если мы говорим о среднестатистических видеоданных, когда дельта между кадрами невелика. Если же мы возьмем любой фильм, разобьем на отдельные кадры, перемешаем их и сошьем обратно в случайном порядке, то современные кодеки на таких данных покажут результат не лучше, а, возможно, и хуже, чем подобная нейронная сеть.
Саму сеть нужно улучшать, подавая на вход не отдельные кадры, а последовательность, тогда её можно обучить «понимать» дельты кадров. И вот тогда она станет куда более похожей на «современные кодеки».
А в том виде, как эта сеть реализована здесь, при её сравнении с современными кодеками получается сравнение пальца с дудкой.
DistortNeo
Так на вход нейросети как раз и подаются последовательности кадров (12 кадров), а не отдельные кадры.
HappyLynx
Из статьи не совсем ясно, что подразумевается под «пакетом» из 12 кадров, и как они подаются на сенсорный слой. Нужно лезть в код.
DistortNeo
Было бы логично, если бы подавались последовательные кадры. Какой смысл подавать 12 разных кадров?
А код вызывает очень много вопросов. Например, вот кусок кода обучения:
Фактически, есть набор PNG-файлов, которые обрабатываются блоками, длина которых определена в конфиге. Проблема в том, что порядок выдачи файлов функцией glob не определён.
А код функции run ещё более странный:
Отсортировали по порядку (почему не сделали этого при обучении?), затем зачем-то перемешали.
supersonic_snail
Пакет — batch из mini-batch gradient descent. Перемешивается это все потому, что обучается на отдельных кадрах. Никакого взаимодействия между кадрами там нет. Поэтому собирать один batch из соседних кадров будет скорее вредно, чем полезно.
DistortNeo
Понятно. Тупо обрабатывается набор несвязанных изображений, а не видеопоток. В таком случае, ценность проведённого исследования близка к нулю.
Обработка и анализ межкадровой разницы — это же самое главное в обработке видео.
supersonic_snail
На входе картинка, на выходе картинка, но в процессе обработки она сжимается до очень небольшого количества чисел, в этом случае 200. Задача сети состоит в том, чтобы сначала закодировать картинку в небольшой массив, а потом раскодировать эту же картинку из набора чисел. Весь фильм он обработал покадрово такой сетью, потом склеил назад в видео.
BelBES
Да, уже понял… тогда не понятно этого восторга… ни на чем кроме Бегущего по лезвию оно нормально не отработало....
supersonic_snail
Именно. Он просто взял готовую реализацию готового алгоритма и обучил его на фильме, все. Причем, если я все верно понял, весь Бегущий — это training set. При таком обучении естественно оно будет на нем нормально работать.