Если вкратце, то проект из себя представляет несколько БД и приложений, расположенных на разных серверах. «Задача» в данном проекте – это хранимая процедура или .Net приложение. Соответственно «задача» должна быть выполнена на определённой БД и на определенном сервере.

Все данные, которые относятся к очереди, хранятся на выделенном сервере. На серверах, где необходимо выполнять задачи, хранятся только метаданные, т.е. процедуры, функции и служебные данные, которые относятся к этому серверу. Соответственно, данные, относящиеся к задачам, мы получаем запросами с использованием LinkedServer.
Все данные, которые относятся к очереди, хранятся на выделенном сервере. На серверах, где необходимо выполнять задачи, хранятся только метаданные, т.е. процедуры, функции и служебные данные, которые относятся к этому серверу. Соответственно, данные, относящиеся к задачам, мы получаем запросами с использованием LinkedServer.
Почему так?
- Удобство. Мы можем в любой момент указать, что теперь на сервере Б хранятся данные.
- Так было реализовано до нас.
Ниже приведены два наиболее популярных классических способа обработки очереди:
- Отправлять уведомление обработчику задач о наличии задачи.
- Производить опрос очереди на наличие задач.
Изначально в проекте был реализовал второй вариант. Чтобы минимизировать время ожидания обработки задач, наше приложение опрашивает очередь каждый 100-500ms.
Cобственно, в этом ничего страшного и нет, кроме одного – при такой реализации таблица лишний раз блокируется. Наперед скажу, в запросе используется блокировка строк с возможностью только чтения незаблокированных строк:
READPAST, ROWLOCK, UPDLOCK
Итак, вернемся к проблеме. При анализе я обратил внимание на значение счетчика — batch requests/sec в Active Monitor. Данное значение при малом количестве (около 50) задач в очереди, зашкаливало за 1000, а также нагрузка на CPU резко возрастала.
Первая мысль: нужно переходить к реализации первого варианта (отправка уведомления обработчику задач). Данный метод был реализован с использованием службы Service Broker и SignalR:
- Service Broker использовали для отправки уведомления о появлении задачи;
- SignalR использовали для отправки уведомления обработчикам задач.
Почему SignalR?
Данный инструмент уже используется в проекте, а сроки были сжаты, поэтому я не стал внедрять что-то аналогичное, например, NServiceBus.
Моему удивлению не было предела, когда данное решение не помогло. Да, был получен прирост в производительности, но это не решило проблему окончательно. Для отладки был написан стресс-тест, когда в очередь добавляется более 500 задач.
Создание такого стресс-теста позволило найти «корень зла».
Анализ списка активных запросов и отчетов производительности, во время большой нагрузки показа наличие «очень интересных запросов», которые состояли из одной команды:
fetch api_cursor0000000000000003
Дальнейший анализ показал, что это запросы с LinkedServer. Сразу возник вопрос: ”Неужели запрос такого типа select * from RemoteServer.RemoteDatabase.dbo.RemoteTable where FieldId = Value порождает запрос (fetch api_cursor0000000000000003) на RemoteServer?” Оказывается, да, и даже тогда, когда LinkedServer — это MS SQL.
Для более наглядного примера созданим таблицу «Test» (код создания таблицы доступен в приложении к статье) на сервере “А”, а на сервере “B” выполним запрос:
select * from dev2.test_db.dbo.test
где dev2 — это наш сервер “А”.
При первом выполнении такого запроса у нас будет подобный лог в профайлере на сервере А:
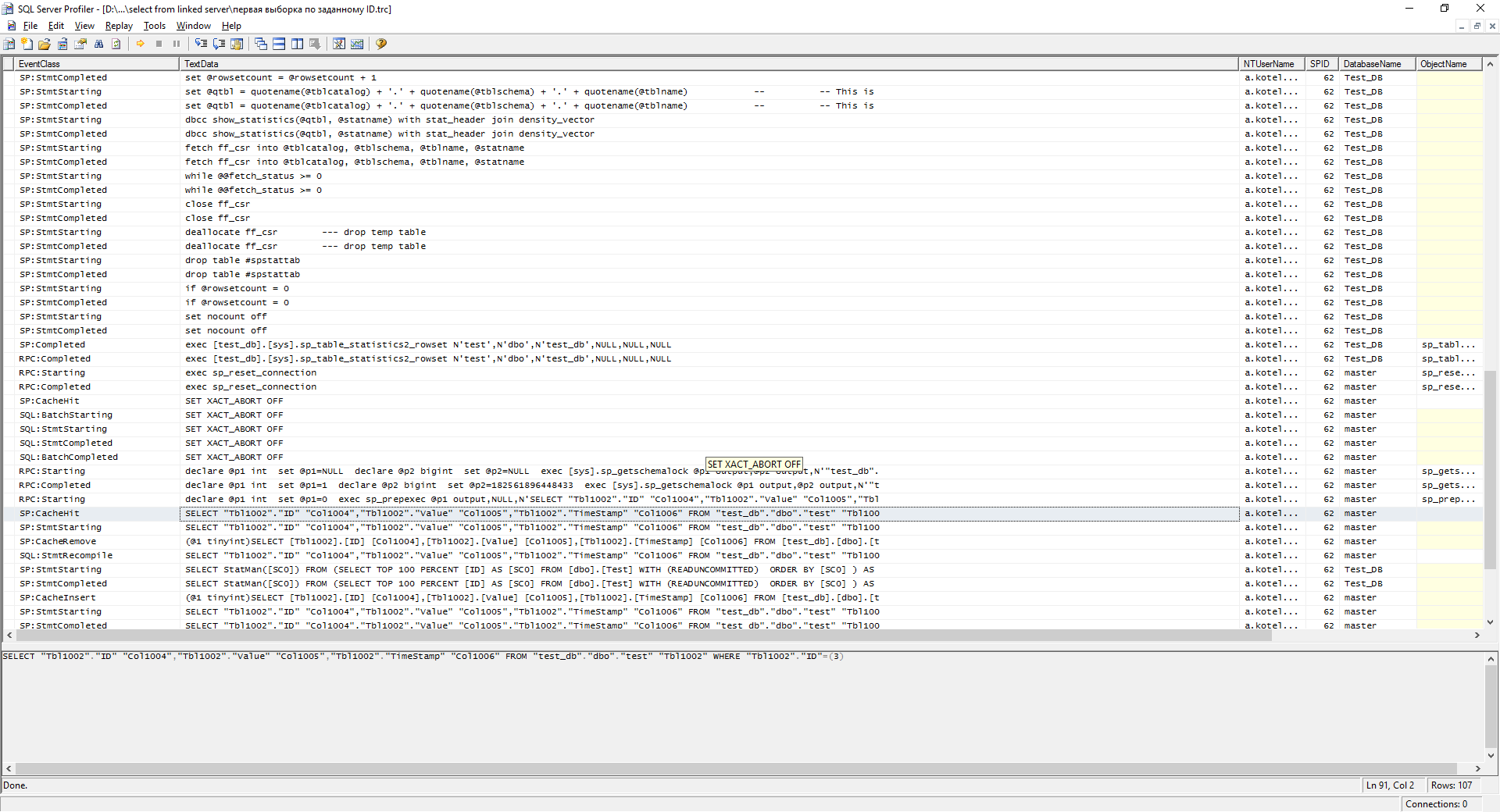
А теперь выполним запросы уже по ID:
select * from dev2.test_db.dbo.test where ID = 3

Как видно на скриншоте, план запроса был добавлен в кэш. Если выполнить этот запрос второй раз, то уже немного лучше.
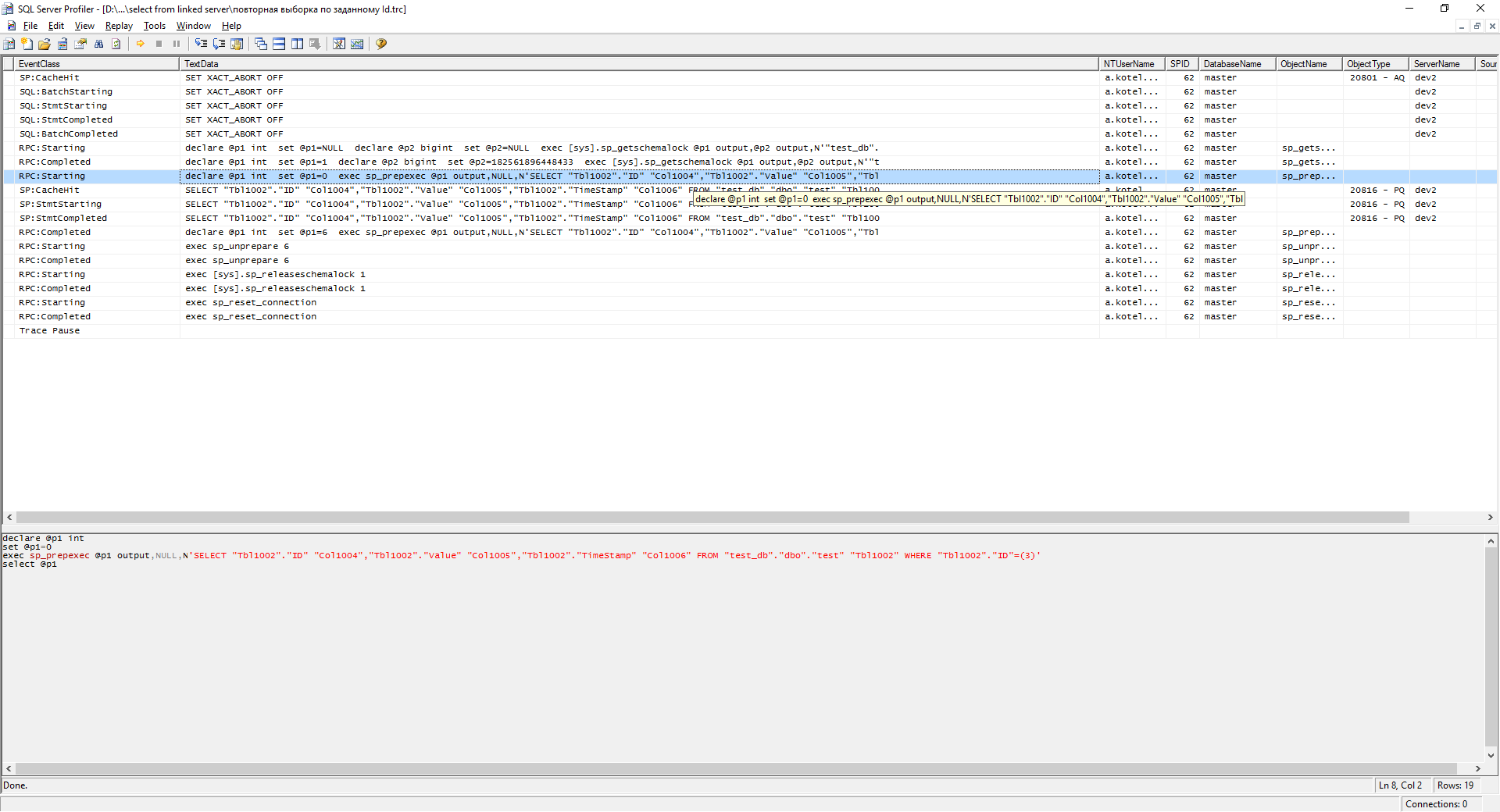
Как мы видим, данные уже берутся из кэша.
При изменении условий мы получим аналогичную выборку — первая выборка по заданному Id. Но суть в том, что при больших количествах разных запросов кэша не хватает. И sql начинает городить кучу запросов к таблице, что приводит к «тормозам». Вы спросите: «А как же индексы?» Индексы есть, но запросы даже с условием по Primary Key (PK) порождали данную проблему.
А что Google говорит по этому поводу? А много чего, только толку нет:
- Что запросы должны выполняться от пользователя, который относится к одной из следующих ролей: sysadmin, db_owner, db_ddladmin, чтобы можно было использовать статистику;
- Неверно настроен LinkedServer.
Более толковые ответы были найдены только в 3-х статьях:
- Exposing API Server Cursors
- Top 3 Performance Killers For Linked Server Queries
- Технологии Push и Pull при работе с linked servers в Microsoft SQL Server
Насколько я разобрался, нельзя настроить LinkedServer так, чтобы всегда использовалась Pull технология для получения данных с LinkedServer. Все зависит от того, где вы обрабатываете запрос.
Время поджимало, и единственное решение, которые нас могло спасти, это переписать часть запросов на dynamic sql. Т.е. выполнять запросы на сервере, на котором хранятся данные.
Работать с данным на LinkedServer можно несколькими способами:
- В запросе непосредственно указать источник данных – удаленный сервер. Данная реализация имеет несколько недостатков:
- низкая производительность;
- возращает большой объем данных.
select * from RemoteServer.RemoteDatabase.dbo.RemoteTable where Id = @Id
- Использовать OPENQUERY. Не подходит по ряду причин:
- невозможно указать имя удаленного сервера в качестве параметра;
- передать параметры в запрос;
- также существуют проблемы, которые были описаны в статье Dynamic T-SQL и как он может быть полезен
select * from OPENQUERY(RemoteServer, 'select * from RemoteDatabase.dbo.RemoteTable').
По ссылкам доступны примеры логов для следующих запросов. Данные запросы выполнятся на сервере “B”, а логи с сервера “A”:
select * from OPENQUERY(dev2, 'select * from test_db.dbo.test') where id = 26
select * from OPENQUERY(dev2, 'select * from test_db.dbo.test where ID = 26')
- Выполнить запрос на удаленном сервере. Аналогично OPENQUERY:
- нельзя указать имя сервера в качестве параметра, так как имя задается на этапе компиляции процедуры;
- также существуют проблемы, которые были описаны в статье Dynamic T-SQL и как он может быть полезен
exec ('select * from RemoteDatabase.dbo.RemoteTable') at RemoteServer
По ссылкам доступны примеры логов для следующих запросов:
exec ('select * from test_db.dbo.test') at dev2
exec ('select * from test_db.dbo.test where Id = 30') at dev2
- exec at server/На стороне клиента с заданным Id.trc
- exec at server/На стороне сервера с заданым Id.trc
- Еще возможно выполнить запрос на удаленном сервере, выполнив процедуру sp_executesql.
DECLARE @C_SP_CMD nvarchar(50) = QUOTENAME(@RemoteServer) + N'.'+@RemoteDatabase +N'.sys.sp_executesql' DECLARE @C_SQL_CMD nvarchar(4000) = 'select * from dbo.RemoteTable' EXEC @C_SP_CMD @C_SQL_CMD
По ссылкам доступны примеры логов выполнения запросов с использованием sp_executesql:
- sp_executesql/Полная выборка на клиенте.trc
- sp_executesql/Полная выбрка на стороне сервера.trc
- sp_executesql/Выборка по Id на клиенте.trc
- sp_executesql/Выборка по Id на сервере.trc
Четвертый способ и был использовал для решения задачи.
Ниже приведены несколько графиков входящего и исходящего трафика на сервере, где расположена основная база очереди до и после использования sp_executesql. При этом размер БД 200-300Мб.


Исходящие пики – это копирование backup на NFS.
Напрашивается вывод: изначально драйвер от MS для работы с «MS sql linked server» не может сам выполнять запросы на сервере источнике данных. Следовательно, коллеги, давайте стараться выполнять их на источнике данных, для решения хотя бы части вопросов с производительностью.
Файлы к статье.
Комментарии (11)

alexhott
09.06.2016 16:13+1Вы не дошли до самого эффективного метода
openqwery засунуть в sp_executesql
Тогда можно передать параметры и работать с таблицами содержащими xml поля
akotelevets
09.06.2016 16:14+1Я считаю что OPENQUERY, нужно использовать при работе с другими СУБД.
я описывал способ решения проблему с которой я столкнулся.
npocmu
09.06.2016 21:46Я я всегда считал что 4D адресация для линкед-серверов, это всего лишь возможности драйвера, а не СУБД. В частности она у меня работает с линкед-сервером DB2 (правда с драйвером OLE/DB от Микрософт). К сожалению, разработчики драйверов для СУБД не заморачиваются поддержкой этой фичи, и тогда, да — остается только OPENQUERY
Vlacodlak
10.06.2016 13:27+1в общем, использовать указание сервера и динамического запроса в openquery можно, но с одной небольшой уловкой:
1. Выполняете select * from operowset('SQLNCLI', 'Server=Self_servername\instancename;UID=username;PWD=password;', @dsql), где @dsql — динамический запрос с openquery (одно но — должно возвращать выборку, и если идет изменение данных, то надо настраивать MSDTC)
2. использовать @dsql совместно с sp_executesql, но если необходимо вернуть данные и сними еще что-то сделать (select и проч), то придется заворачивать ответ (таблицу) в строку и потом ее возвращать. Для определенных select (когда колонки известны) — конструируем определенный xml ответ (select id as "@id", data as "@data" from openquery(...) for xml path('element'), root('Result')), либо если не известная сигнатура ответа то генерация в авто режиме (select * from openquery(...) for xml auto). После получения строки из sp_executesql ее можно развернуть обратно в табличку.Vlacodlak
10.06.2016 13:46+2Так же отмечу, что встречались случаи, когда необходимо было хранить информацию о настройках подключаемых БД в таблицах. Клиент мог завести кучу подключений к разным БД в систему, тогда openrquery не подходит (слишком много link server появляется). Из ситуации как раз и спасал динамический @dsql = select * openrowset(provider, строка с подключением, скрипт), который в дальнейшем выполнялся через sp_executesql + xml обертка.
alexhott
14.06.2016 09:48+1Вроде как openquery напрямую поддерживает insert и update
UPDATE OPENQUERY (OracleSvr, 'SELECT name FROM joe.titles WHERE id = 101')
SET name = 'ADifferentName';
INSERT OPENQUERY (OracleSvr, 'SELECT name FROM joe.titles')
VALUES ('NewTitle');
DELETE OPENQUERY (OracleSvr, 'SELECT name FROM joe.titles WHERE name = ''NewTitle''');
akotelevets
14.06.2016 09:58+1Да, так и есть. Но:
- Параметры — задаются на этапе компиляции запроса;
- Имя сервера указываться на этапе компиляции запроса.
Все это можно обойти используя бубен и это оправдано, когда у вас LinkedServer не MsSql Server.
AlanDenton
Спасибо за статью. Когда читал чуть слезу не пустил, потому что сражался примерно с такими же проблемами :)
Вариант с sys.sp_executesql действительно очень хороший. НО! Он не всегда будет работать. Если в настройках линкед-сервера отключен RPC, то запрос будет падать по ошибке:
В большинстве случаев, это можно игнорировать, но в моем случае мы разрабатывали плагин для SSMS, который должен был подсказывать объекты линкед-сервера и работать при этом на любой конфигурации. Настройки менять не разрешалось. В результате множества тестов вот такой вариант оставили:
akotelevets
AGhost
SELECT name
FROM [linked_server].[AdventureWorks2012].sys.databases
— так это же самый первый, обычно используемый вариант, при котором у автора и были проблемы… или не так?
akotelevets
Структура запроса таже.