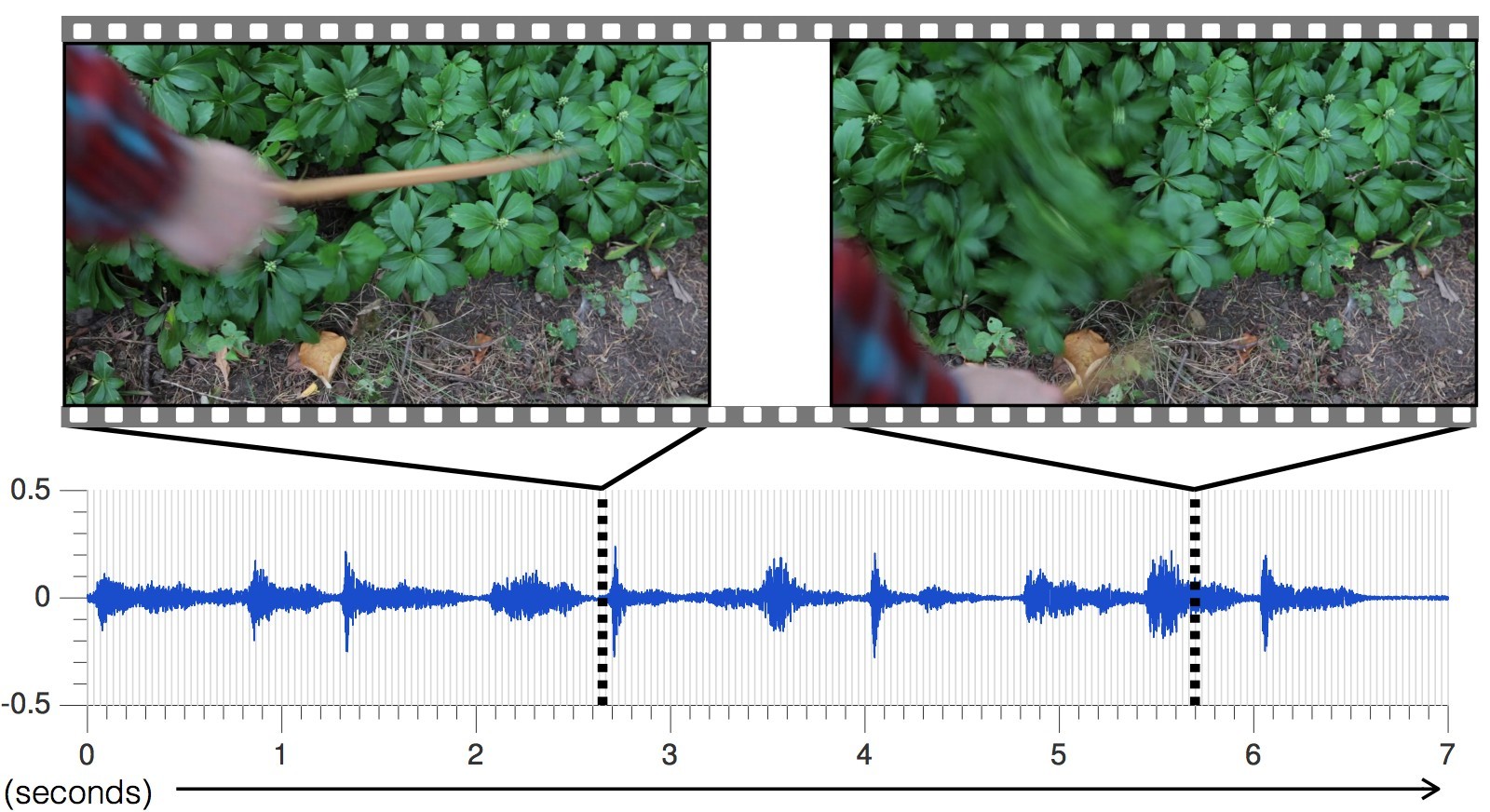
Сотрудники лаборатории информатики и искусственного интеллекта (CSAIL) Массачусетского технологического института и подразделения Google Research спроектировали нейросеть, которая обучилась озвучивать произвольный видеоряд, генерируя реалистичные звуки и предсказывая свойства объектов. Программа анализирует видео, распознаёт объекты, их движение и тип соприкосновения — удар, скольжение, трение и так далее. На основании этой информации она генерирует звук, который человек в 40% случаев считает более реалистичным, чем настоящий.
Учёные предполагают, что эта разработка найдёт широкое применение в кинематографе и на телевидении для генерации звуковых эффектов по видеоряду без звука. Кроме того, она может быть полезна для обучения роботов лучше понимать свойства окружающего мира.
Окружающие звуки многое говорят о свойствах окружающих объектов, поэтому в процессе самообучения будущие роботы могут действовать как дети — трогать предметы, пробовать их на ощупь, тыкать в них палкой, пробовать сдвинуть, поднять. При этом робот получает обратную связь, узнавая свойства объекта — его вес, упругость и так далее.
Издаваемый предметом звук при соприкосновении тоже несёт важную информацию о свойствах предмета. «Когда вы проводите пальцем по стакану с вином, издаваемый звук соответствует количеству жидкости, налитой в стакан», — объясняет аспирант Эндрю Оуэнс (Andrew Owens), ведущий автор опубликованной научной работы, которая пока не готова для научного журнала, а только опубликована в открытом доступе на сайте arXiv.org. Презентация научной работы состоится на ежегодной конференции по машинному зрению и распознаванию образов (CVPR) в Лас-Вегасе в этом месяце.
Учёные подобрали 977 видеороликов, в которых люди совершают действия с окружающими объектами, состоящими из различных материалов: царапают, бьют их палкой и т.д. В общей сложности видеоролики содержали 46 577 действий. Студенты CSAIL вручную разметили все действия, указав тип материала, место соприкосновения, тип действия (удар/царапание/другое) и тип реакции материала или объекта (деформация, статичная форма, жёсткое движение и др.). Видеоролики со звуком использовались для обучения нейросети, а расставленные вручную метки — только для анализа результата обучения нейросети, но не для обучения её.

Нейросеть анализировала характеристики звука, который соответствует каждому типу взаимодействия с объектами — громкость, высота и другие характеристики. При обучении система покадрово изучала видеоролик, анализировала звук в этом кадре и находила соответствие с наиболее похожим звуком в уже накопленной базе данных. Самое главное было научить нейросеть растягивать звук на кадры.
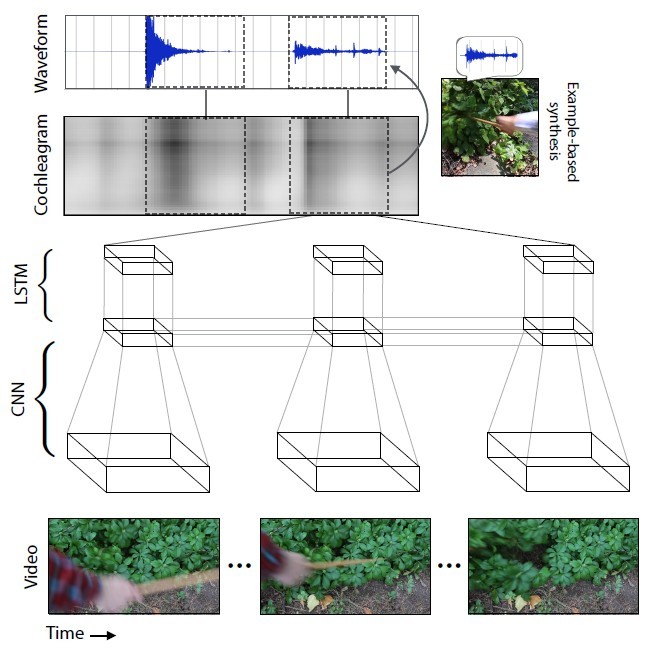
С каждым новым видеороликом точность предсказания звуков увеличивалась.
Сгенерированный нейросетью звук для разных сцен, по сравнению с настоящим

В результате нейросеть научилась точнейшим образом предсказывать самые разнообразные звуки со всеми нюансами: от стучания камней до шуршания плюща.
«Нынешние подходы исследователей в области искусственного интеллекта фокусируются только на одном из пяти органов чувств: специалисты по машинному зрению изучают визуальные изображения, специалисты по распознаванию речи изучают звук и так далее, — говорит Абхинав Гупта (Abhinav Gupta), доцент кафедры робототехники университета Карнеги–Меллон. — Нынешнее исследование — это шаг в правильном направлении, который имитирует процесс обучения таким же способом, каким это делают люди, то есть интегрируя звук и зрение».
Чтобы проверить эффективность ИИ, учёные провели онлайновое исследование на Amazon Mechanical Turk, участникам которого предлагалось сравнить два варианта звукового сопровождения конкретного видеоролика и определить, какой звук настоящий, а какой — нет.
В результате эксперимента ИИ удалось обмануть людей в 40% случаев. Впрочем, по мнению некоторых комментаторов на форумах, обмануть человека не так уж сложно, потому что значительную часть знаний о звуковой картине мира современный человек получает из художественных фильмов и компьютерных игр. Звуковой ряд для фильмов и игр составляют специалисты, используя коллекции стандартных образцов. То есть мы постоянно слышим примерно одно и то же.
В онлайновом эксперименте в двух случаях из пяти люди считали, что сгенерированный программой звук более реалистичный, чем настоящий звук с видеоролика. Это более высокий результат, чем у других методов синтезирования реалистичных звуков.

Наиболее часто ИИ вводил в заблуждение участников эксперимента звуками таких материалов, как листья и грязь, потому что эти звуки более сложные и не такие «чистые», какие издаёт, например, дерево или металл.
Возвращаясь к обучению нейросети, как побочный результат исследования обнаружилось, что алгоритм может различать мягкие и твёрдые материалы с точностью 67%, просто предсказывая их звук. Другими словами, робот может посмотреть на асфальтовую дорожку и траву перед собой — и сделать вывод, что асфальт твёрдый, а трава мягкая. Робот будет знать это по предсказанному звуку, даже не ступая на асфальт и траву. Затем он может ступить куда хочет — и проверить свои ощущения, сверив с базой данных и в случае необходимости произведя коррекцию в библиотеке звуковых образцов. Таким способом в будущем роботы будут изучать и осваивать окружающий мир.
Впрочем, исследователям предстоит ещё большая работа по совершенствованию технологий. Нейросеть сейчас часто ошибается при быстром движении объектов, не попадая в точный момент контакта. Кроме того, ИИ способен генерировать только звук на основании прямого контакта, который записан на видео, а ведь вокруг нас так много звуков, которые не основаны на визуальном контакте: шум деревьев, гул вентилятора в компьютере. «Что было бы по-настоящему здорово, это как-то симулировать звук, который не настолько точно связан с видеорядом», — говорит Эндрю Оуэнс.
Комментарии (31)

sens_boston
14.06.2016 01:05-4>>Учёные предполагают, что эта разработка найдёт широкое применение в кинематографе и на телевидении…
Поправлю данную фразу более приближенно к реальности: «ученые предполагают, что эта разработка даст очередной жирный грант, позволящий им и далее заниматься всяческой интересной фигней, а, при удачном стечении обстоятельств, позволит основать новый стартап, развести лохов на финансирование и обогатить отцов-основателей»
P.S. У кого там из фантастов MIT-шный AI «навернул» (тут должно быть другое слово) Землю через 400 милилсекунд после обретения самосознания? C этими MIT-шными учеными нужно бы построже :D
P.P.S. Тэг в P.S. был опущен ;)
tmteam
14.06.2016 13:35Если их технология доходит до коробочного решения, то это много дешевле чем восстанавливать звук в студии — почему бы и нет?
sens_boston
14.06.2016 17:06Где вы прочитали про «коробочное решение»-то? Лично я обратил внимание на фразу: «В результате эксперимента ИИ удалось обмануть людей в 40% случаев», что, на мой взгляд, говорит лишь о том, что три из пяти человек заметили явную «лажу» (абсолютно неудовлетворительный результат для кинематографа. Опять-таки непонятно, как «обманулись» эти 40 процентов.
tmteam
14.06.2016 17:0940 процентов — это маркетология, не для специалистов. Не обращайте просто внимание на это.
А вот про уровень «коробочности» решения — я нигде ничего не видел, потому и написал «Если их технология доходит… то:»sens_boston
14.06.2016 17:30Какая «маркетология»-то? (судя по тому, как мой пост заминусовали, окружающие все-таки придерживаются мнения, что это «чистая наука», они же пока не продают ничего. Да и процент для «маркетологии» уж больно низок ;) Из текста опять-таки ясно, что ни о каком «коробочном решении» речь не идет — весьма ранние эксперименты с непонятным результатом (кстати, то, что они тестировали через «Amazon Mechanical Turk», тоже весьма показательно — рекомендую взглянуть на тамошнюю оплату; как ожидать реальных результатов от таких тестеров, просто непонятно. Для справки замечу, что всевозможные компании и исследовательские лаборатории в США регулярно набирают добровольцев для тестов, только оплата там обычно не центы, а сотни долларов.
tmteam
14.06.2016 17:52Вас заминусовали за обратное. Показана интересная идея, с некоторой реализацией. Сообщество же намекает: «Ваши предположения о мотивации учёных оставьте при себе»
sens_boston
15.06.2016 01:32А с моей точки зрения, описана довольно странная идея, с абсолютно непонятным будущим (глубоко сомневаюсь, что эта идея найдет хоть какое-то практическое применение), зато обильно уснащенная модными баззвордами: ИИ, роботы и т.п.
А эксперимент с копеечными тестерами (вопрос еще раз — почему? Если это серьезная разработка, что им мешало нанять людей локально, и провести реальный серьезный эксперимент?) и 40% результатом — это вообще курам на смех.
Сейчас, похоже, просто тренд такой — нацепить на любую разработку яркий лейбл «AI» и продать подороже…

NikitosZs
14.06.2016 02:01Прогнать бы видео игры на гитаре или хотя бы на барабанной установке.
>>На основании этой информации она генерирует звук, который человек в 40% случаев считает более реалистичным, чем настоящий звук.
Обожаю то, как люди умеют оперировать процентами.
mbait
14.06.2016 05:42-2Видеоролики со звуком использовались для обучения нейросети, а расставленные вручную метки — только для анализа результата обучения нейросети, но не для обучения её.
Правда??? Вот это прорыв… Хотя, постойте: зачем в цепочке «видео -> изображение -> звук» текстовые метки? Да, как-то неудобное получилось… Но ведь всё равно круто — по видео восстановить звук? Что говоришь, мальчик? Это только классификатор, который не может выйти за пределы множества известных классов, то есть всё ещё не умеет делать обобщения? Сейчас вот прям совсем неловко вышло.
Если серьёзно, то статья — отличный показатель того, чем сейчас занимаются 95% исследовательских институтов. Алгоритм примерно такой:
1. Так заходим в интернет, смотрим… что там у гуглов? — Ага, RNN, LSTM, TensorFlow, свёрточные сети.
2. Вообщем так, народ, сейчас в моде нейронные сети. Будем из бросать, пилить, ломать, лизать, засовывать куда-нибудь, пока не получим материал, который можно оформить в виде статьи.
3. Пишем статью, где экстраполируем наш результат и рассказываем, как сильный ИИ перенесёт столицу в Нью-Васюки.
4. ???
5. PROFIT!
6. 10 GOTO 1.tmteam
14.06.2016 13:33Насколько я понял — исходные звуки не использовались как семплы, а использовались как исходный материал для обучения. В итоге мы должны получить не классификатор а генератор. При этом использовалась ограниченная выборка для барабанной палочки и элементов природы, для простоты.
mbait
14.06.2016 18:39Классификатор является частью генератора. Классифицируются не куски аудио целиком, а какие-то их короткие фрагменты, переведённых их временной в частотную область. Поищите «classify» по тексту статьи.
Генерация происходит или простой подстановкой аудио-сэмпла или обратным переходом их частотной области во временную:
To synthesize sound from these videos, we present an algorithm that uses a recurrent neural network to map videos to audio features. It then converts these audio features to a wave-form, either by matching them to exemplars in a database and transferring their corresponding sounds, or by parametrically inverting the features.

zorg-kirill
14.06.2016 10:16А смогут ли они оживить звук в немом кино? (работы Чарли Чаплина например)

MonsterGod
14.06.2016 12:10А зачем? Там вся прелесть именно в том, что оно немое. Но теоретически, наверное смогут.

perfect_genius
14.06.2016 10:58Пусть тогда визуализируют потоки воздуха, например от вентилятора, какими-нибудь частицами или дымом.


gleb_kudr
14.06.2016 12:49Например, этим можно еще сильнее улучшить распознавание речи — подцепляем модуль считывания по губам и вуаля.



Ravebinovich
16.06.2016 20:01Эта технология была бы полезна в видеоиграх и, особенно, в набирающей популярность VR. Например, когда герой шляется по лесу, переходит ручей и падает в яму, то всё звуковое сопровождение будет генерироваться на ходу и каждый раз звучать уникально. Атмосферность будет на выстоте.
Akronix
Теперь в экранках будет всегда чистый звук;)
strlock
Когда нибудь и «экранок» не будет, а только Full-HD восстановленные нейросетью по записям из ручки-камеры.)
hdfan2
И даже ручки не надо. Пришёл из кино и рассказываешь нейросети: «Ну там, короче, всё так зашибись, и махача, короче, такая, ну просто отвал башки, и космические корабли такие, в натуре, а этот м#дак в чёрном, прикинь, говорит: «Люк, я тебя, типа, породил, а теперь, короче, опаньки», а потом, херакс, и наши, типа, победили». Пара минут — и фильм готов.
invekc
Слишком много энтропии. Но вот создание таких фильмов как «Варкрафт» могло бы обойтись без участия человека.
seminole
Свинку Пэпу можно генерировать прямо в ящике.
Sketch_Turner
Недавно смотрел экранку Civil War. Снятая в 4К со штатива и уменьшенная до 1080 она ничем не отличалась от рипа. Порой даже как-то… лучше выглядела))))