Однако, как только у нас появляется отдельная система для хранения очереди сообщений (мы используем RabbitMQ), сразу возникают проблемы с транзакционностью. Например, если мы хотим сохранить в БД отметку о том, что мы отправили сообщение в Rabbit, не так уж и просто гарантировать, чтобы отметка была сохранена только в случае успешной отправки сообщения. О том, как мы справлялись с этой проблемой читайте под катом.
В некоторых сценариях можно просто отправлять сообщения в RabbitMQ после завершения SQL транзакции. Например, если нам надо при регистрации отправить email с паролем и на странице, которая отображается после регистрации, есть кнопка “переотправить письмо”, то мы вполне можем позволить себе обойтись без какой-либо транзакционности и в случае ошибки отправки сообщения, просто выводить уведомление пользователю.
Можно отправлять сообщение прямо перед коммитом SQL-транзакции. В этом случае мы можем откатить SQL-транзакцию, если упадет отправка сообщения, но есть вероятность того, что после успешной отправки сообщения упадет коммит SQL транзакции. Но если для вас приемлема ситуация, когда редкие сообщения будут доставлены системе-получателю, но система-отправитель об этом забудет, я бы рекомендовал использовать этот способ, так как он очень прост в реализации.
В сценариях, когда упавшая транзакция будет обязательно повторена, можно не бояться того, что в системе отправителе не останется записи об отправке (и более того, отправку сообщения можно выполнять в любой момент транзакции, а не только перед коммитом). Однако, при этом необходимо операцию обработки сообщения сделать идемпотентной, чтобы одно и то же с точки зрения системы-отправителя сообщение не было обработано два раза в системе-получателе.
Например, нам надо отправить потребителю email и проставить отметку об этом в БД. Данные потребителя хранятся в CRM системе. CRM система общается с email-шлюзом через очередь в RabbitMQ. Отправка сообщения выполняется задачей, у которой есть уникальный идентификатор и список потребителей, которым нужно отправить сообщение. Если обработка отправки письма потребителю падает (например по SQL таймауту), то через некоторое время задача снова попытается отправить сообщение. При таком сценарии мы можем отправлять сообщение в RabbitMQ до завершения транзакции, но при обработке сообщения в email-шлюзе мы должны сохранять уникальный идентификатор задачи и номер потребителя в списке. Если в БД email-шлюза уже есть сообщение с таким идентификатором задачи и номером потребителя, то повторно мы его не отправляем.
Для того чтобы email-шлюз абстрагировался от того, как именно CRM отправляет сообщения, CRM должен передавать не идентификатора задачи и номера потребителя в списке, а ключ идемпотентности — уникальное значение, сформированную на основании этих данных. При других способах отправки email ключ идемпотентности будет формироваться по другому. При таком подходе email-шлюз не должен ничего знать о том, как ему могут отправляться сообщения — главное, чтобы отправитель передавал ключ, уникально определяющий сообщение.
Далеко не во всех случаях можно гарантировать, что в случае падения SQL транзакции, она будет повторена через некоторое время. Также не всегда есть данные, на основании которых можно сформировать уникальный ключ идемпотентности. А операцию обработки сообщения из очереди желательно всегда делать идемпотентной, так как даже при отсутствии дублирующихся сообщений одно сообщение может быть обработано несколько раз, если упадет вызов метода Ack RabbitMQ. Для решения проблемы в общем случае, нам нужно что-то вроде распределенной транзакции между RabbitMQ и MS SQL и автоматически формируемый ключ идемпотентности. Обе эти задачи можно решить следующим образом:
- В рамках SQL транзакции в специальную таблицу в БД сохраняется уникальный идентификатор сообщения.
- После выполнения INSERT запроса, но до завершения SQL транзакции, сообщение сохраняется в промежуточную очередь. В этом сообщении кроме прочего передается уникальный идентификатор, который был сохранен в БД.
- Отдельная задача обрабатывает промежуточную очередь и проверяет, что уникальный идентификатор сообщения есть в БД.
- Если есть, сообщение перекладывается в очередь, которую обрабатывает уже система-получатель. Для того, чтобы не хранить во вспомогательной таблице старые идентификаторы, после того как сообщение перемещено его идентификатор удаляется из БД (даже если удаление идентификатора упадет, это не повлияет на работоспособность системы — просто останется лишняя запись в БД).
- Если в момент запроса записи в БД по уникальному идентификатору транзакция еще не была завершена, то запрос будет ждать завершения этой транзакции, и только после этого вернет запись. То есть никакой дополнительной логики для ожидания завершения транзакции писать не надо.
- Если уникальный идентификатор отсутствует в БД, это точно значит, что транзакция была откачена и сообщение выбрасывается.
- Уникальный идентификатор сообщения используется в системе-получателе в качестве ключа идемпотентности.
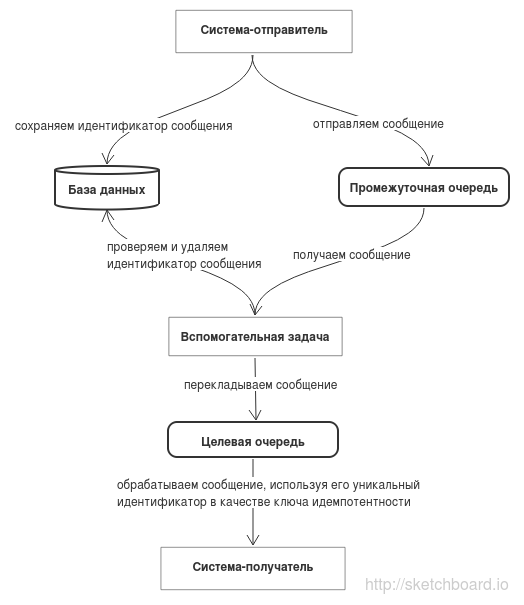
При таком подходе гарантируется, что в системе-отправителе сохранится информация об отправленном сообщении. Если в транзакции отправки сообщения и так создается запись с уникальным идентификатором, то можно использовать его и обойтись без вспомогательной таблицы.
Здесь может возникнуть вопрос: «А чем это лучше использования таблички в БД в качестве очереди? Все равно ведь приходится вспомогательные запросы к БД делать.» Дело в том, что если использовать таблицу в БД в качестве очереди, то для получения последнего необработанного сообщения будут выполнятся запросы вроде «SELECT TOP 1 * FROM Messages WHERE Status = 'New'». Если мы хотим обрабатывать сообщения в несколько потоков, то для того, чтобы гарантировать, что одно сообщение не будет обработано двумя разными потоками, придется использовать Serializable транзакцию для получения последнего сообщения и изменения его статуса. При использовании Serializable транзакции запрос на получение последнего необработанного сообщения будет блокировать все записи со статусом 'New' и никто не сможет добавлять новые сообщения, пока не закончится транзакция получения сообщения.
Но в такой транзакции постоянно будет возникать deadlock, так как два потока смогут одновременно прочитать последнее необработанное сообщение, наложив при этом shared блокировку, а потом при попытке обновлении статуса сообщения не смогут повысить уровень этой блокировки до эксклюзивного, и одна из транзакций будет откачена. Поэтому уже при чтении сообщения надо накладывать update блокировку. В итоге очередь станет узким местом, так как доступ к ней (и на запись, и на чтение) в один момент сможет получить только один поток.
Если же использовать описанный выше подход, то все запросы к вспомогательной таблице (вставка, поиск и удаление) выполняются по известному уникальному ключу и блокируют только одну запись в БД. Поэтому при многопоточной обработке сообщений не возникает узкого места, в котором несколько потоков будут ждать, когда освободится блокировка, чтобы добавить или получить сообщение.
Комментарии (33)

leo_habr
14.05.2015 17:49Какой стек у вас используется?
Для .NET гляньте NServiceBus и те патерны которые они предлагают для distributed applications.
Youkai Автор
14.05.2015 19:42NServiceBus работает как надстройка над MSMQ, который умеет интегрироваться с MS DTC.
MSMQ нас не устраивает, а для RabbitMQ NServiceBus не может сделать распределенную транзакцию.

romario13
15.05.2015 08:30Наверное я что-то упустил. Перечитал еще раз и не помогло. Помогите разобраться пожалуйста.
Имеем — система получатель, которая использует идентификатор сообщения как идемпотентный ключ.
Имеем — система отправитель, которая генерит этот идентификатор сообщения.
Вопрос такой — почему система отправитель не отсылает сообщение сразу в целивую очередь?
Это для того чтобы все работало в ситуации недоступности MQ, где БД является более надежной? При этом мы помещаем идентификатор сообщения в БД и переотправляем сообщение в MQ по таймауту?Youkai Автор
15.05.2015 13:39Так как мы отсылаем сообщение в очередь до коммита, мы не можем гарантировать, что транзакция была завершена (коммит транзакции может упасть, хоть это и маловероятно). Поэтому нам нужна промежуточная очередь, при обработке сообщения из которой мы проверяем, что запись с идемпотентным ключом есть в БД (а значит транзакция была успешно закоммичена).
Если отправлять сообщение после коммита SQL транзакции, то может возникнуть ситуация, когда запись в БД об отправке есть, а сама отправка упала.romario13
15.05.2015 14:17Если мой тезис не верный и вы не пытаетесь обезопасить себя от неработающего MQ, то пусть генерит ваша система отправитель сообщение с уникальным идентификатором и отправляет сразу в MQ.
Первый воркер запишет его в БД, а второй удалит после отправки. Это ваша схема но с упращенной системой-отправителем. Этот подход может снизить вероятность повторной отправки но не предотвратит ее как и ваш описанный в статье.romario13
15.05.2015 15:22Первый воркер запишет его в БД, а второй удалит после отправки.
Ерунду я написал какую-то. Ничего это не снизит.
Итого: если уверенность достаточна в MQ — отправляйте сразу воркеру, отправляющему письма.
Если нет — то нужно более надежное место, куда можно сохранить задачу. И в случае отсутствия MQ переотправить ее позже. Или пассивный механизм — когда кто-то по шедулеру забирает задачи на выполнение с помощью MQ.
Далее отмечать выполнение (или удаление записи) в журнале по факту выполнения задачи.
Можно еще переотправлять в MQ если достигнут таймаут ожидания завершения задачи. В самом MQ задача на отправку сообщения может иметь TTL чтобы снизить количество дублей при длительном простое MQ.
Youkai Автор
15.05.2015 16:28100% уверенности, что отправление сообщения в MQ не упадет, у нас нет.
Если сохранять задачу на отправку, например, в SQL, а потом переотправлять, то список этих задач в итоге превратится в очередь. Проблемы с использованием SQL в качестве очереди я описал в конце статьи.
Подход с промежуточной очередью для отправки работает быстрее и при его использовании чаще всего можно обойтись без дополнительных таблиц, так что он даже проще, чем вариант со списком задач в БД.romario13
16.05.2015 00:36то список этих задач в итоге превратится в очередь. Проблемы с использованием SQL в качестве очереди я описал в конце статьи.
Конечно это так. Есть минусы. Вопрос только в контексте задачи. Если мы помещая эту задачу в SQL DB будем еще и вызывать MQ для старта процесса, а после отправки удалять, то в этой БД может быть не так много задач в итоге, требующих переотправки.
Второй хинт — это при переотправки одним потоком вытаскивать Только идентификаторы задач и по ним стартовать процесс в mq где уже пойдет распараллеливание с вытаскиванием аргументов задачи и т.д.
При таком подходе кролик осилит на обычном сервере более 1000 стартов процессов в секунду (помещений сообщений в очередь). Для задач где почтовое уведомление актуально хотя бы час (не сообщение с подтверждением регистрации), мы можем себе позволить переотправить минимум 3,6 миллиона сообщений в час.Youkai Автор
16.05.2015 15:39Да это вроде рабочий вариант. Хочу только уточнить пару нюансов:
- Воркер, переотправляющий сообщения, должен вытаскивать только старые сообщения (например, отправленные более минуты назад), причем скорее всего придется использовать уровень изоляции ReadUncomitted. Иначе SELECT всех сообщений будет блокировать обработку текущих.
- Этот подход, как и наш, может добавлять дубли сообщений в очередь.
На мой взгляд вариант с промежуточной очередью все-таки проще, а также обладает следующими преимуществами:
- Можно обойтись без дополнительной таблицы, если в SQL транзакции и так создается сущность с уникальным ключом.
- Его можно использовать и для отправки писем о регистрации.
romario13
16.05.2015 16:02Контекст этой ветки обсуждения о том, что MQ может быть не достаточно надежным и соответственно вариант с промежуточной очередью не рассматривается. Надо городить журнал (очередь) на стороне системы.
Youkai Автор
17.05.2015 15:43Ну SQL мы тоже не считаем 100% надежным. Мы не стремимся обработать запрос пользователя в 100% случаев. Но если одна из операций упала (SQL транзакция или отправка в очередь), то другую операцию мы должны откатить.
romario13
17.05.2015 22:09Понятно что вы рассматриваете только попытку отправки сообщения в mq и транзакцию БД, а о гарантированном выполнении вы не заботитесь.
Мысль же была о том, что если операция важная (это не ваш случай), то на mq систему полагаться не стоит до определенной степени (даже если она приняла ваше сообщение). И тогда имеет смысл регистрация процессов на стороне системы отправителе для последующей переотправки.
youlose
«Однако, как только у нас появляется отдельная система для хранения очереди сообщений (мы используем RabbitMQ), сразу возникают проблемы с транзакционностью. Например, если мы хотим сохранить в БД отметку о том, что мы отправили сообщение в Rabbit, не так уж и просто гарантировать, чтобы отметка была сохранена только в случае успешной отправки сообщения»
Включаете подтверждение исполнения задач (ack) у консумера. И в конце обработки задания перед ack публикуете данные о том что задача выполнилась в очередь с результатами. Всё и ваш велосипед не нужен =).
Youkai Автор
Ack при обработке мы используем, конечно же, но проблема с транзакционностью, которую я описал, относится к транзакции отправки сообщения.
Но и при обработке сообщения одного только Ack'а не достаточно. Если после публикации данных в очередь с результатами упадет Ack, то это сообщение будет обработано два раза. Поэтому обработку сообщения всегда лучше делать идемпотентной.
youlose
«Если после публикации данных в очередь с результатами упадет Ack»?
куда упадёт?
если сообщение не удалось отправить что с ним должно произойти, надо пробовать отправить его ещё раз?
Youkai Автор
Ack актуален только при обработке сообщения, при отправке Ack вызвать нельзя. Если сохранять информацию об успешной обработке сообщения где-либо (в другой очереди или в SQL базе), нет гарантии, что после этого отработает Ack (хотя бы из-за недоступности сети, но в реальных условиях между завершением транзакции и Ack может выполнятся еще код, который также может упасть). В этом случае сообщение через некоторое время обработается еще раз, чего мы не хотим.
Что делать, если падает именно отправка сообщения, я подробно написал в статье.
youlose
Ack актуален если задачу надо 100% выполнить, это элемент надёжности, раз вы не хотите гарантированной доставки сообщений, значит это не нужно.
«при отправке Ack вызвать нельзя»
на самом деле у раббита есть и подтверждение публикации сообщений — www.rabbitmq.com/confirms.html (ни разу им не пользовался, у нас нет с этим проблем)
Короче ещё раз перечитал, судя по всему вам вообще асинхронная отправка писем не нужна, раз вы пытаетесь это сделать в течение SQL транзакции, отправляйте синхронно и будет вам счастье.
Youkai Автор
Мы хотим гарантированной доставки сообщений, поэтому используем Ack. Но Ack не гарантирует, что сообщение не будет обработано несколько раз, поэтому обработку сообщений нужно делать идемпотентной.
При отправке нам необходимо гарантировать, что сообщение будет добавлено в очередь только в случае успешного завершения SQL-транзакции. В зависимости от того в какой момент отправляется сообщение могут быть две разные проблемы:
Как вы предлагаете использовать confrim для того, чтобы избежать обеих проблем?
Синхронная отправка email нас не устраивает (хотя бы потому, что при этом в случае downtime email-шлюза, не работают все системы, которым нужно отправлять email).
В течение SQL транзакции мы только добавляем сообщение в промежуточную очередь. Практически сразу после завершения транзакции, мы перекладываем это сообщение в очередь, которую обрабатывает система-получатель. Обработка сообщения (отправка email, если система-получатель — это email-шлюз) полностью асинхронна и система-отправитель не ждет, когда она будет завершена.
youlose
Хорошо, вот такой вариант:
2 очереди с ручным подтверждением задач + durable(чтобы пережить рестарт сервера):
1й воркер(для бизнес логики до отправки):
0. проверяем guid(см п. 2) не выполнялась ли бизнес логика для этой задачи, если выполнялась ack'каем задачу
1. запускаем SQL транзакцию
2. тут пишем в базу какой-то guid чтобы потом эту транзакцию не делать ещё раз, если ackнуть не удасться
3. делаем бизнес логику
4. отправляем сообщение в очередь отправки
5. комиттим транзакцию
6. ack'аем задание
2й воркер(отправка почты):
1. отправляем
2. ack'аем задание
И третьей очереди не надо + промежуточных обращений к БД, с БД работает только первый воркер. Как такую схему сможете поломать?
romario13
Если 1ый воркер сломается на 6ой задаче нужна же еще логика восстановления?
romario13
И если на шаге 1 упал, тоже беда?
youlose
Если сломался на 1 шаге, то значение о выполненной бизнес логике не запишется, задача не будет отмечена выполненной и будет передана другому воркеру или повторно обработана этим же.
Если сломается на 6 шаге, то это задание будет передано другому воркеру (или этому же). Он на 0 шаге увидит что бизнес логика выполнялась и тупо ack'нет это задание.
romario13
Все понял, спасибо. Перепутал что где ask'ается :)
В вашем примере не будет обеспечиваться однократная отправка почтового сообщения. Второй воркер может не смочь подтвердить отправку на шаге 2 и обработает это задание позже еще раз. Как это реализуется в исходной статье я тоже пока не понимаю.
Мне кажется системе-отправителю имеет смысл писать в свою БД идентификаторы сообщений перед отправкой в MQ только с одной целью — быть более устойчивой если MQ не работает или не отправит сообщение за разумное время. В этом случае переотправлять сообщения в MQ.
youlose
Ну отправка почты вообще ненадёжная штука, то есть даже отдав сообщение почтовому серверу вы не можете быть уверены на 100% что письмо дойдёт (поправьте меня если я не прав). И риск того что между отправкой и ack что-то произойдёт минимален, да и человек не особо напряжётся что ему придёт 2 одинаковых письма.
В крайнем случае можно работу как с первым воркером организовать, но в тех задачах с которыми я работаю единичные письма можно терять.
P.S. В общем я считаю что защита обсчёта бизнес логики важна, а отправки почты нет.
Youkai Автор
Немного устал повторять, но статья про другое)
Проблему с тем, что отправка email на почтовый сервер — не идемпотентная операция, мы решили немного усложнив логику работы второго воркера. Полностью она выглядит так:
При таком подходе мы не гарантируем, что email будет отправлен в 100% случаев, но гарантируем, что один email не будет отправлен два раза. Если упадет отправка email, то запись об email останется в невалидном статусе «Отправляется» (хотя если запись в этом статусе — есть вероятность, что email все таки отправился и упало изменение статуса). У нас настроен мониторинг, который проверяет количество таких записей и шлет алерт если их много. Сейчас сообщения в таком статусе остаются крайне редко — только если возникают проблемы на уровни сети.
romario13
Вы сами пришли к противоречию. Два тезиса:
1) но гарантируем, что один email не будет отправлен два раза.
2) то запись об email останется в невалидном статусе «Отправляется» (хотя если запись в этом статусе — есть вероятность, что email все таки отправился
Ваш подход не решает задачу первого требования. Отсюда вопрос — будет ли более простой подход менее надежным — сразу отправлять в целевую очередь. При этом меняется только описание первого вашего пункта на такое:
Получаем запись об email из БД (если ее там нет, значит транзакция [системы — отправителя] не была закомичена, и сообщение можно выбросить).
Youkai Автор
1 и 2 не противоречит друг другу.
Если email остался в статусе «Отправляется», это может означать два варианта:
Т.е. если сообщение повисло в этом статусе мы не знаем наверняка было оно отправлено или нет. Эти сообщения мы автоматически не отправляем, поэтому гарантируется, что один email не будет отправлен два раза.
В вашем упрощенном подходе email-шлюз должен иметь доступ к БД системы-отправителя. Если вам не нужно выделять email-шлюз в отдельную систему, и вы считаете его частью CRM системы (и у них одна общая БД на двоих), то это вполне валидный подход.
Youkai Автор
Еще раз поясню, вопрос (да и вся статья) был про транзакцию отправки сообщения в очередь. Вы же описываете транзакцию обработки сообщения из очереди.
Обработка сообщения у нас устроена примерно так как вы описали, но вы упустили два нюанса:
Youkai Автор
Хотя второй воркер нам нужен не для поддержания надежности, а из-за других нюансов (не буду в это углубляться).
В большинстве случаев можно использовать более простые алгоритмы.
Если мы хотим гарантировать, что email не будет отправлен два раза (и при этом не сможем гарантировать, что он будет отправлен):
Если мы хотим гарантировать, что email будет отправлен хотя бы один раз (и при этом не сможем гарантировать, что email не будет отправлен два раза):
Если использовать последний алгоритм, при падении коммита будут ситуации, когда письмо уже было отправлено, а записи в базе о нем еще нет (но позже она появится). Если мы отслеживаем открытие письма и изменяем при этом статус записи об email в БД, то лучше будет все-таки разделить отправку и выполнение SQL-транзакции по разным воркерам (это гарантирует нам, что email будет отправлен только после поялвения записи в БД).
romario13
Дружище! Так это самое главное — что вы жертвуете гарантированной отправкой уведомлений! Этого в явном виде нет в статье. Я это понял из комментариев и то не с первого раза.
Поясню контекст.
Обычно в рамках mq систем и взаимодействия с ними необходимо добиться гарантированного выполнения задачи. Отправка сообщения поэтому понимается как задача, которую нужно обязательно выполнить.
Заголовок статьи о транзакциях между mq и sql — что тоже подразумевает неизбежность выполнения или откат запланированных действий.
Применение термина идемпотентность в контексте отправки почты означает, что многократное повторение действия отправки эквивалентно однократному. Т.е. если отправляем почту данным получателям — то не важно сколько вызвался воркер, но все равно отправляем в итоге один раз. А у нас — или отправится или нет. И мы не знаем при повторах что делать а просто игнорируем дублирующиеся сообщения.
Все это привело в меня в непонимание.
Но Если мы жертвуем гарантированной отправкой сообщения — ситуация конечно меняется. Тогда вопрос стоит в выработки решения, где эти жертвы минимальны и от этого надо отталкиваться и это должно быть предметом анализа как мне кажется.
Youkai Автор
Жертвуем гарантированностью мы на этапе обработки сообщения (отправки email). И это частный случай. При отправке платежей, например, мы можем гарантировать 100% отправку, так как сервисы ОСМП идемпотенты.
Как уже писали, выше идемпотентность отправки email мы гарантировать не можем, но мы можем хотя бы гарантировать идемпотентность нашей бизнес логики, сохраняющей информацию об отправке в БД email-шлюза.
То, что мы сейчас обсуждаем выходит за рамки статьи, и в ней про это я и не собирался писать. Статья описывает как сделать распределенную транзакцию, отправляющую сообщение в очередь и сохраняющую информацию об этом в системе-отправителе. Обработка сообщения не является частью этой транзакции.
romario13
Поняно. У нас проблема в общей терминологии. Это не транзакция в каноническом смысле.
Если речь шла о том как продолжить процесс в MQ только после успешной транзакции в системе-отправителе, убрав таким образом возможные дубли процессов — то ваш метод решает задачу.
HDDimon
deleted