
Все видели просмотрщик html-файлов в TotalCommander. Загорелся идеей написать простой и очень маленький текстовый браузер для своей операционки. Поначалу, смотрел в сторону asm-xml — отличный парсер, однако ну очень уж большой (мой предел — 64 килобайта, не технический, просто принцип такой). Ниже описан очень простой способ получения текста из html.
Сразу оговорюсь, что код мне нужен именно независимый, (для своей ОС), поэтому все готовые библиотеки отпадают сразу. Почему assembler? — только потому что всё в моей ОС пишется на нем. Но метод можно передвинуть на любой язык…
Итак, поскольку важен маленький размер кода — от классического парсера с построением дерева, парсингом иерархической структуры решил отказаться. Пошел «в лоб».
Собственно, процесс состоит из нескольких этапов.
Вначале нужно избавиться от содержимого тегов script — только тех, где код написан напрямую, а не там, где подключаются внешние скрипты. Почему? Просто дошел опытным путем, когда выявил, что некоторые, весьма большие, скрипты ломают логику моего парсера)
Далее идет основной цикл. Мы шаг за шагом (точнее байт за байтом) проходим все теги (ищем открытие и закрытие тега). Т.е. у нас в итоге получается не дерево тегов, а список, состоящий из строк преполненных dword заголовками.
Если текст не подпадает под тег — то и записываем его просто как текст.
Структура временная выглядит так (касным выделены заголовки — обозначение тегов):
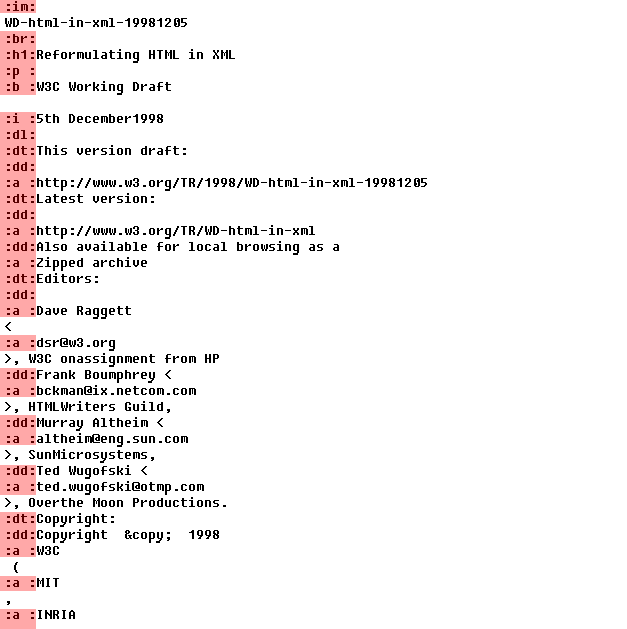
Поясню момент. Казалось бы, логичнее каждому тегу выдать соответствующий хеш или идентификатор. Но, для этого нужно парсить все виды тегов, например: <p и <p style=… — нужно отдельно проверять. А у нас же — просто проход до файлу со сравнением через каждый байт четырех байт:
inc esi
cmp byte[esi + 0], '<'
Если это открывающий тег, то <p class… превращаем в :p:
Это, конечно же, лентяйство, говнокод и т.п., но это быстро, коротко и эффективно!
Ну а дальше собственно берем получившийся список и строка за строкой, в зависимости от типа тега, отдаем на обработку соответствующей процедуре обработки, которая пишет уже в выходной буфер. (Есть еще мелочи эстетические — убираем повторение пробелов, переносов и т.п.)
Ожидаю комментариев вида: «говнокод», «учи матчасть» и т.п. Поэтому скажу сразу: код (в конце статьи ссылка) — это просто прототип, написанный «на коленке», а насчет «алгоритма» — согласен, это трудно назвать алгоритмом, но он работает! Всего 4Кб программа!
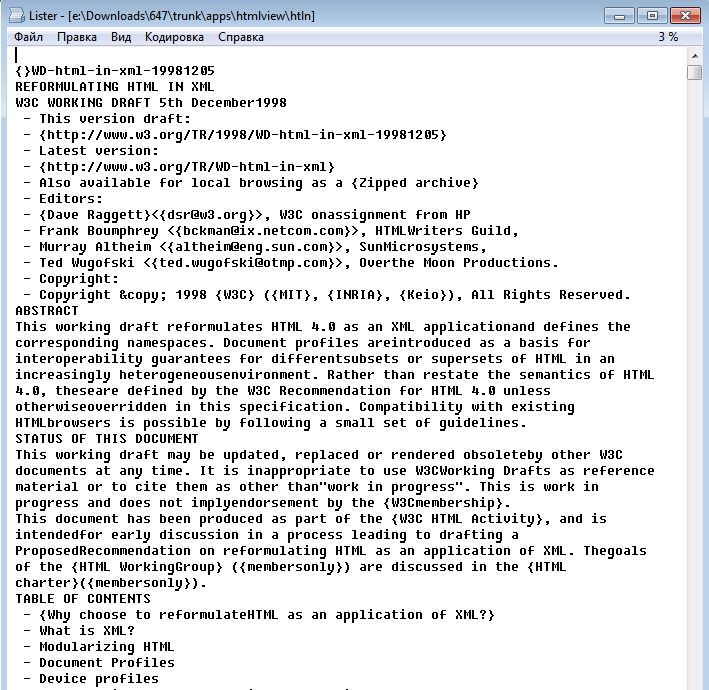
По ссылке рабочий пример (проверял также на исходнике html главной страницы хабра — скрин внизу) — всё работает. Единственно — ограничение размера файла (просто пока не добавил выделение памяти, использую 3 по 64 Кб неинициализированных буфера). После работы программа выдаст два файла — в одном список временный, во втором — готовый текст. Учтите, что в тексте переносы — это 0x0A, поэтому смотрим TotalCommander'ом в режиме текста.
Тест на документе «W3C Reformulating HTML in XML»:
Тест на главной страницу Хабрахабра:

Исходник + win32binary
А теперь вопрос: у кого получится меньше, чем 4Кб?
Комментарии (10)

Lure_of_Chaos
30.06.2016 02:45Первое, что приходит на ум для реализации идеи — читать посимвольно, обращая внимание на «уголки» тегов, складывая их в «стек» для соблюдения вложенности, и оставлять текст, опционально обрабатывая некоторые теги, такие, как «невидимые» теги, переводы строки, абзацы и т.д. Даже не знаю, что может быть быстрее и экономнее по расходу памяти, чем такой подход.
И, по мне, было бы лучше обрабатывать так, чтобы на выходе получился текст-разметка типа markdown или похожее — тогда, можно будет восстановить почти полноценную разметку с сохранением читабельности.

lizarge
30.06.2016 11:26> Итак, поскольку важен маленький размер кода — от классического парсера с построением дерева, парсингом иерархической структуры решил отказаться. Пошел «в лоб».
Ну тут связи особо нет, правда как я понял в вашей ОС ограничение не только в размере самого кода, но и оперативной памяти, тогда логично.
shevmax
01.07.2016 07:14Объедините секции PE файла и получите еще больше экономии.
shevmax
01.07.2016 07:27P.S. В общем благодаря простым манипуляциям с секциями — ровно 3 кб файл вышел.
Еще убрал лишний ExitProcess и кое как адаптировал расположение переменных. Итог: 2560 байт.
omegicus
01.07.2016 10:13ну я не имел ввиду прямо уж такие размеры маленькие) ну это да, 2кб это круто.
кстати, смотрел как-то файлы, люди делали, миниатюрные, кажись 97 байт у кого-то самый маленький файл PE получался. Единственно, точно не помню, но кажись на Win7x64 он отказался стартовать. Правда там были манипуляции с заголовком PE…shevmax
01.07.2016 10:19Ага, знаю про такое. Но там уже хитрости с накладыванием одних заголовков на другие. А тут полностью стандартный рабочий файл выходит.

hodzanassredin
01.07.2016 11:36Парсить html неблагодарное дело, так как часто битые есть. Ради интереса сравню по скорости с тем, что мы сейчас используем на большом массиве html. Мы преобразуем корпус в текст и гоняем всякий ml для реалтайм классификации. И сейчас парсинг хтмл узкое место. Посмотрим как изменится отношение скорости к качеству. Перепробовали кучу реализаций. Надо как раз что то очень примитивно быстрое и достаточно хорошее. Но придется еще доработать для выбора невидимых инлайн стилей и т.п.
omegicus
01.07.2016 12:29вот-вот, доработайте) у меня времени нету пока, я тоже займусь позже.
Ну а этот метод — ему пофиг, битая структура html или нет...)
gearbox
Я смотрю, Вы уже листер с гуями на асме запилили! Зачотно, чо! )
А если по чесноку — вывод в файл в длину засчитывается? Обработка параметров со строки? Можно ли не читать с файла а читать только с stdin? А к кодировкам как мы относимся?(можно было бы впрячься, я в свое время баловался подобными ужиманиями)
omegicus
да всё можно, я просто пример самой идеи сделал быстро, если подумать хорошо — можно намного умнее сделать всё)