Мы лишь немного вдумчивей прочитаем то, что написано на рекламном сайте этой фирмы. Берем первую самую главную настройку.
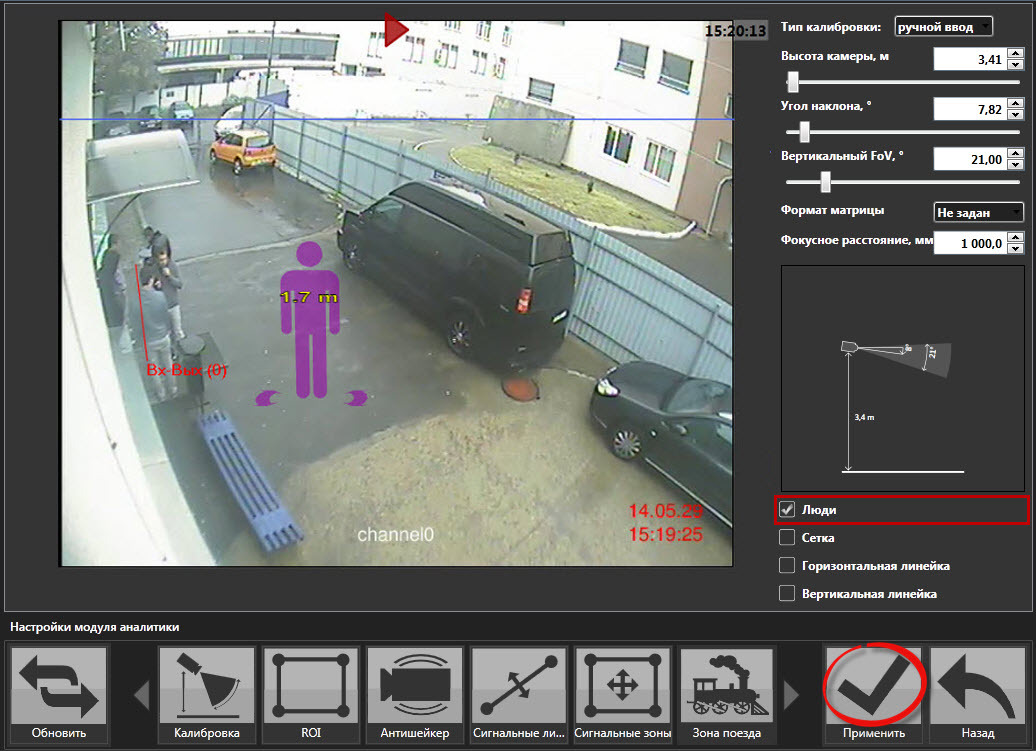
Предлагается выставить размеры человека, чтобы отличать его рамку детекции от других объектов и исходя из этого классифицировать объекты. Но мы в прошлой статье уже говорили:
1. Двухмерная камера теоретически не может определять размеры объектов, т.к. у нее нет перспективы. Но тут предлагается псевдо перспектива, основанная на разнице и заведомо известном положении высот. Предполагается, что всё движение идет лишь по земле, и теоретически можно построить для «землян» такую логику. Если бы не птицы, которые летают, а также насекомые, которые ползают по камере. И их размеры не откалибруешь.

2. Контрастный детектор видит только то, что отличается от фона. Если обратить внимание на человека слева (на котором красная линия), то легко заметить, что его туловище полностью (для камеры — полностью) сливается с фоном. Т.е. компьютер будет видеть только белые брюки и отдельно ходящую черную голову.
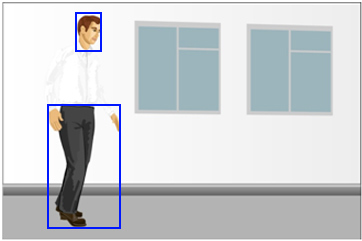
Хотя, если выставить чувствительность на полную, то можно и попробовать находить хоть какие-то отличия, но тогда помехи забьют весь архив. Даже артефакты оцифровки будут давать сработки.
3. Размеры детекции даже на самой контрастной цели определяются совокупностью замкнутой области движения, т.е. несколько пересекающихся человек будут образовывать более крупные фигуры, нежели один человек.

4. При движении любого объекта зоной детекции является не только то место, где он находится в данный момент, но и совокупно такая же зона, где он находился один кадр назад. Процесс детектирования – это сравнение кадров: последующих с предыдущими. Соответственно, в последующем будет изменено то место, куда человек передвинулся, и то место, которое он освободил. Длина этой зоны будет зависеть от скорости движения: чем дальше объект передвинулся за время двух кадров, тем больше зона. Для автомобиля это может быть вся область кадра.

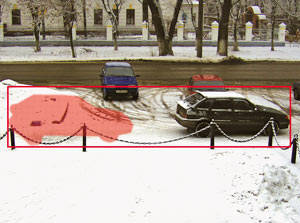
5. Как дополнение нужно сказать и про откровенный ляп рекламного хайтека, эта картинка из настроек того же Синезиса:

Как видно, зона детекции и по вертикали, и, как ни странно, по горизонтали сильно отличается от фигуры человека. Видимо, сами разработчики не сильно верят в то, что пишут.
А вот здесь, когда нужно отличить человека от машины, писатели рекламы Синезиса показывают явно вытянутые фигуры по вертикали:
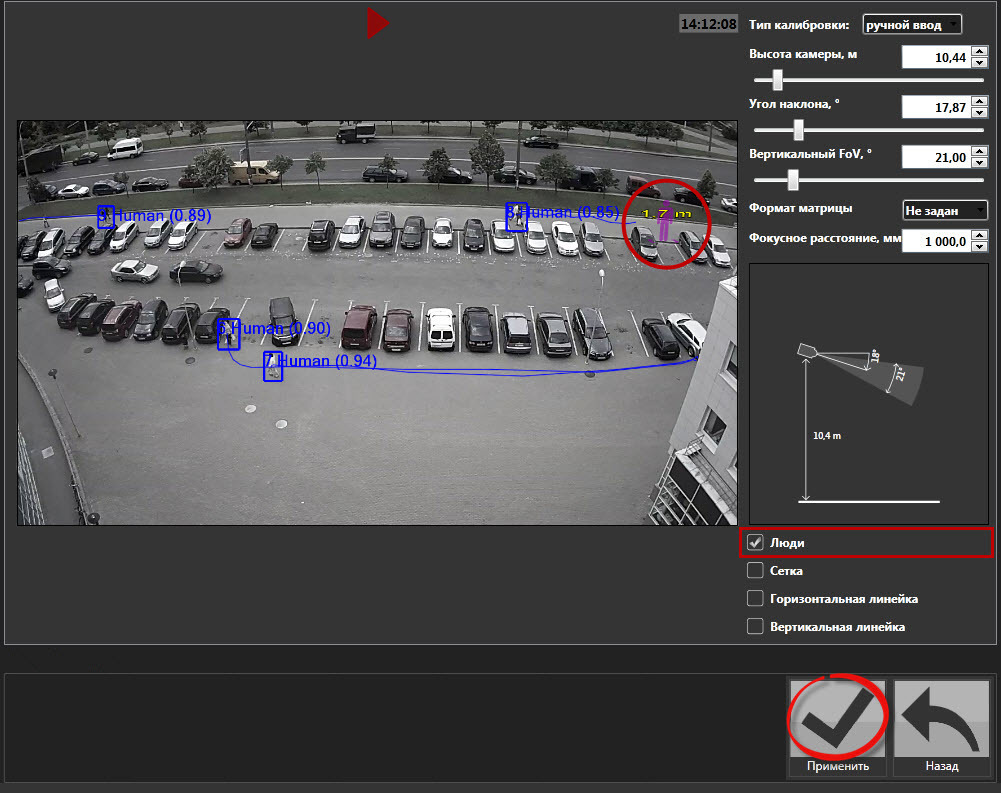
По логике — да, тачки будут вытянуты по горизонтали, если конечно передвигаться они будит тоже только по горизонтали. Но вот в правом верхнем углу мы опять замечаем ляп. Там рамкой обведена фигура из двух человек. Соответственно, если пойдет вместе 3-4 человека, то это уже будет распознаваться как машина. Ну, что сделаешь, детектор объектов не обманешь!
По сути все дальнейшие настройки модулей видеоаналитики Kipod основаны на попытку вычислять размеры объектов wiki.allprojects.info/pages/viewpage.action?pageId=31785131
Т.е. почти вся технология видеоналитики строится на заведомо не рабочем в реальных условиях принципе.
От массы других компаний, связавших свой бизнес с видеоаналитикой, Синезис отличает антипрактичность. Чувствуется, кто придумывал свои хитрые алгоритмы, никогда серьезно их не испытывал. Берем очередную настройку:
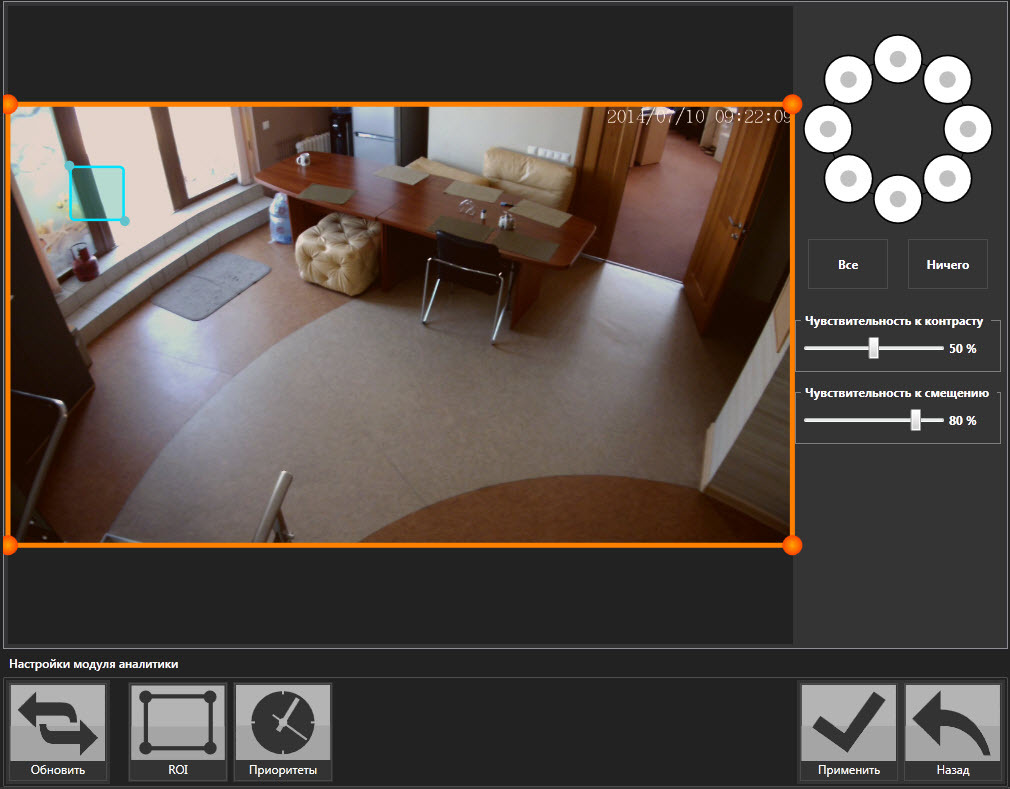
Так называемым зонам интереса можно задать уровень контрастности для сработки – чувствительность. Отличная вещь – работает на все 100, если не менять освещение. Но в данном случае нам показана комната, где вечером надо выставить чувствительность побольше, а утром – поменьше. Во 2-ой (голубой) зоне вообще нужны противоположные значения: при дневном свете окно яркое, при искусственном – темное. Вот и надумаешься!
Очевидно, что во время демонстрации освещение резко не изменится, а значит, у продавца есть длительный шанс, чтобы убедить покупателя в интеллектуальных способностях.
Еще немного о 2-ой (голубой) зоне. Надо быть очень далеким от практики, чтобы выставить место детекции на окне. Солнце – объект не предсказуемый, его настроение меняется постоянно, поэтому в солнечные дни демонстрацию лучше не проводить, 2-ая зона будет реагировать постоянно.
Но у Синезиса есть возможность тестирования, грех не попробовать. Вот что насрабатывало за сутки.
При этом вырезаны множественные повторы, пауки и жуки колбасили постоянно, поэтому в ролике только пример.
Продолжение следует…
Комментарии (37)

datacompboy
15.05.2015 15:20Ну что уж вы так!" Один раз даже и правда люди в кадре были!

Videoanalitic Автор
15.05.2015 16:39Причем здесь понятие «видеоаналитика»? Людей в кадре засечет любой видеодетектор.
Кстати, я не сказал, сколько людей не было зафиксировано — ровно половина. Детектор объектов пытается искать рамку человека, о такая не всегда появляется на человеке, хотя бы из-за теней.

BearMef
15.05.2015 16:41+1В сочетании со звуком это просто фильм ужасов какой-то…
P.S.… для тех, кто с системами наблюдения до сих пор не сталкивался ;)

BelBES
15.05.2015 17:36+1интеловскую библиотеку Open CV
Как-то даже стало за державу обидно :) OpenCV уже давно не только «интеловская». Вот копипаста из файла LICENSE:
Copyright © 2000-2015, Intel Corporation, all rights reserved.
Copyright © 2009-2011, Willow Garage Inc., all rights reserved.
Copyright © 2009-2015, NVIDIA Corporation, all rights reserved.
Copyright © 2010-2013, Advanced Micro Devices, Inc., all rights reserved.
Copyright © 2015, OpenCV Foundation, all rights reserved.
Copyright © 2015, Itseez Inc., all rights reserved.
краткая история проекта OpenCVVideoanalitic Автор
15.05.2015 18:06-7Рад приветствовать коллегу! Кто бы сомневался, что встречу здесь всех, о ком пишу!
Естественно, я говорил об Интеле как о классике, именно он начинал: Copyright © 2000-2015, Intel Corporation, all rights reserved.
Другие подтянулись спустя несколько лет после закрытия Интелом направления. В системах видеонаблюдения используются тоже, в основном, старые интеловские алгоритмы, а не те направления, что появилось после.
Да Вы всё лучше меня знаете, просто решили зайти на огонек?
Спасибо! Очень рад!BelBES
15.05.2015 20:01+1От того, еще интелового, OpenCV оставался разве что малоюзабельный ANSI C интерфейс библиотеки, который в версии 3.0 окончательно выкинули.
Сейчас разумеется интел также активно принимает участие в развитии библиотеки, но большая часть работы делается именно в Itseez. Большинство людей из топа контрибьютеров OpenCV являются сотрудниками этой компании.
Что такое «старые интеловские алгоритмы» не совсем понятно :) В библиотеке много чего появилось за последующие годы.
Вообще из публично доступных детекторов, ближе всего к state of the art библиотека Doppia от уже упомянутого мной Родриго Бененсона, а не OpenCV…Videoanalitic Автор
18.05.2015 09:13Много слышал, но было бы интересно узнать из первых рук. Если можно, расскажите внутренности новшеств?

ErmIg
15.05.2015 19:05+3Здравствуйте. Хотелось бы сделать пару замечаний по поводу вашего анализа видеоаналитики от компании Синезис.
Да, многие алгоритмы видеоаналитики компании Синезис используют принцип выделение подвижных объектов на неподвижном фоне. Однако, думать, что алгоритмы только на этом и оканчиваются — это очень упрощенное представление. Так, мы используем адаптирующуюся модель фона, которая достаточно быстро подстраивается под изменения освещенности и прочие изменения на сцене. Хотя наши алгоритмы и не осуществляют распознавания всех объектов на сцене, однако мы применяем различные методики по минимизации ложных срабатываний от различных помех, характерных для уличного видеонаблюдения: насекомые, птицы, изменения освещенности, атмосферные осадки и прочее. Без этого наши алгоритмы были бы практически не применимы. И автор бы сам заметил бы это, если бы лучше проанализировал наши продукты.
К стати, синий квадратик на экране, который вы привели — это не еще одна зона, и минимальный размер объекта для детекции. И естественно, что уровни чувствительности не надо подбирать отдельно для ночи и дня — алгоритм сам прекрасно адаптируется.
По поводу OpenCV — это безусловно очень полезная библиотека компьютерного зрения и мы отдельные ее элементы иногда используем в своих проектах, однако в большинстве случаев без существенной доработки ее нельзя использовать в коммерческих решениях по соображениям точности и производительности.
С глубочайшим уважением, начальник отдела машинного зрения компании Синезис, Игорь Ермолаев.BelBES
15.05.2015 20:04Так, мы используем адаптирующуюся модель фона, которая достаточно быстро подстраивается под изменения освещенности и прочие изменения на сцене.
А если не секрет, на каких работах вы основывались? Когда я игрался с задачей вычитания фона, лучших результатов мне удалось добиться используя алгоритм VIBE, но вроде как у него с патентами какие-то заморочки есть.ErmIg
18.05.2015 08:17+1У нас собственные наработки — анализируется поведение фона на достаточно большом отрезке времени для каждого признака (серое изображение, градиент и т.д.), затем мы строим нижнюю и верхнюю границу таким образом, чтобы большинство значений лежало внутри этого интервала. Сигналом считается все то, что лежит за верхними и нижними границами. Использование в качестве признаков градиентов с усилением позволяет нам детектировать малоконтрастные объекты (поэтому как правило у нас нет проблем с со светлыми объектами на светлом фоне и темными на темном, исключая конечно ситуацию, когда и живой оператор начинает сомневаться). Использование многомасштабных признаков позволяет нам быть эффективнее связывать части слабоконтрастных объектов между собой, а также делает алгоритмы сегментации более эффективными в плане вычислений. Ну и мы активно используем SIMD инструкции процессоров для оптимизации вычислений — в среднем получается в 9 раз быстрее, чем без них.
P.S. Если интересно, то могу написать отдельную статью про это.Videoanalitic Автор
18.05.2015 10:59позволяет нам детектировать малоконтрастные объекты (поэтому как правило у нас нет проблем с со светлыми объектами на светлом фоне и темными на темном, исключая конечно ситуацию, когда и живой оператор начинает сомневаться)
Здесь есть маханькое НО. Чем сильнее пытаешься найти слабоконтрастное изменение, тем больше уровень помех. Учитывая стандартный алгоритм, все это опять подпадает под тему статьи — показать можно, а в жизни работать не будет.
На реальных объектах всё делается с точность наоборот — чувствительность загрубляют как могут, чтобы избавиться хоть от какой-то части помех.
Использование многомасштабных признаков позволяет нам быть эффективнее связывать части слабоконтрастных объектов между собой
Да нет там никаких особых признаков. Это же ВИДЕОНАБЛЮДЕНИЕ. Там есть только один признак — градации оттенков, и ВСЁ! Или у вас ренгеновские аппараты стоят?ErmIg
18.05.2015 11:15Если вы внимательно посмотрите на картинку настройки видеоаналитики, которую вы привели у себя в статье, то увидите, что там не одна чувствительность, а две (к контрасту и к смещению). Так вот 99 % всех помех возникают и исчезают на одном и том же месте. А нас интересуют движущиеся объекты — это позволяет все эти помехи отсечь, хотя мы их естественно регистрируем на нижнем уровне наших алгоритмов.
Videoanalitic Автор
18.05.2015 11:23Вообще, мысль здравая, но не в данном контексте. Если мы говорим про слабоконтрастность, то мы должны понимать, что где-то объект будет чуть контрастнее — где-то менее, ведь фон везде разный. В разных местах движущаяся цель будет проявляться по-разному. Поэтому конкретно в данном случае такая настройка лишь ухудшает чувствительность к движению слабоконтрастной цели.
Хотя для других форм помех такая настройка могла бы быть полезна, но тоже — лишь для детектора движения. Где же все-таки ваша видеоаналитика?
Videoanalitic Автор
18.05.2015 09:21По-моему такими фразами Вы зарывате себя еще глубже. Что такое «достаточно быстро подстраивается под изменения освещенности и прочие изменения на сцене»? Через сколько минут после изменения освещенности вы подстроитесь?
Какие «прочие изменения на сцене» вы игнорируете?
Надеюсь, это общая рекламная фраза: «мы применяем различные методики по минимизации ложных срабатываний от различных помех, характерных для уличного видеонаблюдения: насекомые, птицы, изменения освещенности, атмосферные осадки и прочее». Потому что все описанное ПРИ ВАШЕЙ МЕТОДИКЕ (ЖЕСТКАЯ ВИДЕОАНАЛИТИКА) в полной мере невозможно в принципе. Хотя да, какой-то процент и можно отсеять.
«что уровни чувствительности не надо подбирать отдельно для ночи и дня — алгоритм сам прекрасно адаптируется» — тогда непонятна задача этой настройки?ErmIg
18.05.2015 10:28Компания Синезис делает не одну универсальную видеоаналитику для работы во всех возможных условиях, а несколько различных модулей для конкретных специфических условиях. То, что вы привели в обзоре — это ДЕТЕКТОР ДВИЖЕНИЯ — простейший алгоритм, который в большинстве случаев не требует настройки. Он специально создавался из более продвинутого уличного детектора путем упрощения и отбрасывания всего сложного, что требует настройки.
Типичное время адаптации алгоритма в ситуации (в темной комнате включили свет) — до 10 секунд. Для более плавного изменения освещенности (солнце зашло за облачко) — алгоритмы адаптируются на ходу без потери трекинга объектов.
По поводу фильтрации ложных объектов — мы не утверждаем, что фильтруем 100 процентов ложных срабатываний, однако фильтрация 90-95% ложных срабатываний уже делает наши алгоритмы практически применимыми. Все равно срабатывания детектора на конечном этапе как правило проверяются живым оператором.
Конечно можно основывать работу алгоритмов на детектировании на видео конкретных объектов путем работы различных детекторов, однако такой подход тоже имеет недостатки — низкая производительность, чувствительность только к узкому классу объектов (а реальность очень разнообразна). Так что для каждого задачи нужен свой подход. Пока не льзя сказать, что один подход однозначно лучше другого.
Videoanalitic Автор
18.05.2015 10:45Компания Синезис делает не одну универсальную видеоаналитику для работы во всех возможных условиях, а несколько различных модулей для конкретных специфических условиях.
Там приведена универсальная ВАША настройка, которая используется во всех модулях ВАШЕЙ видеоаналитики. Т.е. всё, на чем базируется ВСЯ ВАША видеоаналитика.
То, что вы привели в обзоре — это ДЕТЕКТОР ДВИЖЕНИЯ — простейший алгоритм, который в большинстве случаев не требует настройки
Мною взято только описание вашей видеоаналитики. Без него тогда ничего в вашей видеоаналитике не остается. Может быть, вам все главы с заголовками «видеоаналитика» переименовать в «детектор движения»?
Для более плавного изменения освещенности (солнце зашло за облачко)
Вы реально считаете, что это плавное изменение освещенности? Тогда выйдите на улицу и проверьте! Вы не успеете моргнуть, как солнце резко выйдет или зайдет.
Типичное время адаптации алгоритма в ситуации (в темной комнате включили свет) — до 10 секунд.
10 секунд — без анализа?!
однако фильтрация 90-95% ложных срабатываний уже делает наши алгоритмы практически применимыми
Ваша детекция построена ВСЕГО ЛИШЬ на размерах и форме рамок движения. При таком подходе можно еще как-то фильтровать общие по всему кадру и равномерно распределенные помехи типа однородного дождя и снега. И то, если они не бликуют, особенно ночью на фонарях освещения.
Все равно срабатывания детектора на конечном этапе как правило проверяются живым оператором.
Так и обычное видеонаблюдение — тоже проверяются живым оператором. В каком месте у вас интеллект и видеоаналитика?ErmIg
18.05.2015 10:59Так и обычное видеонаблюдение — тоже проверяются живым оператором. В каком месте у вас интеллект и видеоаналитика?
— Без аналитики один оператор может следить за 10 камерами, с видеоаналитикой за 100 камерами. Выгода очевидна.Videoanalitic Автор
18.05.2015 11:00В общем — очевидна. С вашей системой — нет.
Разница в подходе отсутствует. Технология ни чем не отличается.
ErmIg
18.05.2015 11:08Ваша детекция построена ВСЕГО ЛИШЬ на размерах и форме рамок движения.
— Это вы сами придумали?Videoanalitic Автор
18.05.2015 11:24Я не мог написать инструкцию к вашей системе, которая хранится на вашем сайте.
BelBES
15.05.2015 20:20+2А вообще какая-то странная статья. Как известно, задача детектирования объектов на данный момент не решена, существуют лишь алгоритмы, которые могут находить приближенное решение с некоторой точностью. Поэтому у любого алгоритма можно найти правильные 10 кадров, на которых он будет выдавать полный мусор, вместо адекватных результатов. Другой момент, что о точности алгоритма имеет смысл говорить в контексте тестовой выборки схожей с боевыми условиями эксплуатации. А вопрос о жучках/паучках — это вообще не к алгоритмам претензия, а к тем, кто плохо установил камеру.
Videoanalitic Автор
18.05.2015 09:26В этом и проблема. Именно это и является темой статьи.
Детектирования объектов — еще как возможно, если создать идеальные лабораторные условия. Если под конкретный объект, под конкретное освещение, под… выставить соотв. настройки. Вы увидите идеальную работу, уверяю Вас. Но для реальной жизни — Вы правы — это пока невозможно в теории.
Тема статьи как раз про это.
Жучки — паучки тоже не зависят от того, кто ставил камеру. Они лишь реальность, при которой необходимо обеспечить работу видеоаналитики. Это обязательное условие. Так же как и дождь, снег, крупные блики, тени…ErmIg
18.05.2015 10:36+1При разработке и тестировании алгоритмов видеоаналитики мы используем большие наборы видео, которые воспроизводят все возможные ситуации с помехами — мухи, птички, облачка, дождик, сильный ветер, день ночь и т.д. (сутки видео с сотнями, а иногда и тысячами различных ситуаций). И естественно в алгоритмах мы не можем затачиваться под конкретное видео, так как это приведет к тому, что на других видео качество резко упадет. Мы еще 5 лет назад успешно прошли тесты ILIDS (у нас есть соответствующий сертификат от министерства внутренних дел Великобритании), которые воспроизводят эти все эти ситуации.
Прежде чем писать обличительные статьи, рекомендую сначала ознакомиться с предметной областью.Videoanalitic Автор
18.05.2015 10:50Так Вы бы и показали реальные тесты.
И Вы, я так понял, не поняли самой статьи. Она не утверждает, что ваша система ничего не может. В ней конкретные ляпы вашего хелпа. При таком описании и таких картинках можно судить, что данный самолет летать не может.
Здесь обсуждение не того, что вы можете или не можете, а конкретных противоречий вашей инструкции. Если Вы пишете, что самолет без мотора и крыльев летает как ласточка, то это явный ляп, что я и подметил.
Ну, а сертификатов сейчас — каких только нет! Хотите от Буша дам сертификат?ErmIg
18.05.2015 11:05Здесь обсуждение не того, что вы можете или не можете, а конкретных противоречий вашей инструкции.
Ну так обратились бы к нам, мы бы инструкцию подправили бы и еще вам спасибо сказали бы. Это небольшая техническая ошибка, а не повод писать статьи про то, что у нас ничего не работает.Videoanalitic Автор
18.05.2015 11:26Ну так обратились бы к нам, мы бы инструкцию подправили бы и еще вам спасибо сказали бы. Это небольшая техническая ошибка, а не повод писать статьи про то, что у нас ничего не работает.
В том то и дело, что это не техническая ошибка.
Если вы подправите инструкцию, в ней ничего не останется про видеоаналитику.
tangro
Для борьбы со срабатыванием на жуков, пауков и капли дождя можно ставить рядом две камеры и засчитывать «срабатывание» только при одновременном (примерно) сигнале с обеих. А собак и людей вроде бы нормально детектирует.
Videoanalitic Автор
А Вы не пробовали три камеры ставить? Какая вероятность, что на них всех за ночь не поселяться пауки?
Люди и собаки, а также тени и птицы действительно хорошо детектируются, только причем здесь видеоаналитика? Это обычный контрастный видеодетектор, существующий в любом Дивиарике.
olegchir
Ну если уже есть две камеры на одну картинку, то это перспектива, а значит качество анализа можно значительно улучшить, не?
Videoanalitic Автор
Нет, конечно! По Вашей логике получается: если камер 3, то это уже четвертое измерение. А, если 4, то…
Кроме камер, нужна еще логика обработки этих камер в одной связке, а где Вы такую встречали?
BelBES
Вы отрицаете тот факт, что при использовании 2-х камер можно получить depth для кадра?
Ну вот, например, статья товарища Бененсона о применении стереокамер для повышения качества в задаче детектирования пешеходов…
Videoanalitic Автор
Я не отрицаю технический прогресс, я говорю строго про Синезис. Там вы где-то видели рекомендацию — поставить две камеры?
olegchir
Берешь C++ и пишешь эту логику.
Videoanalitic Автор
Хорошая идея. Статья как-раз про то, чего не хватает разработчикам видеонаблюдения: хороших программистов и C++
datacompboy
вот кстати, пауков за год на подъезде было всего два.
а вот мотыльков… как только лампа сбоку перегорает — так в объектив ломятся как на обед
tangro
Может и поселятся, но произойдёт это не одновременно. И в итоге появление паука в одной камере не вызовет тревоги, а появление человека (одновременно на двух камерах) — вызовет. Да, логику надо будет на чём-то написать, но это по крайней мере выглядит возможным.