Один из наиболее частых вопросов, с которыми сталкиваются специалисты по обработке и анализу данных — «Какой язык программирования лучше всего использовать для решения задач, связанных с машинным обучением?» Ответ на этот вопрос всегда приводит к сложному выбору между R, Python и MATLAB. Вообще говоря, никто не может дать объективный ответ, какой же язык программирования лучше. Конечно, язык, который вы выбираете для машинного обучения, зависит от ограничений конкретной задачи и данных, предпочтений самого специалиста и тех методов машинного обучения, которые нужно будет применить. Согласно опросу о любимом инструменте пользователей Kaggle для решения задач анализа данных R предпочитают 543 из 1714.
Сейчас в CRAN доступен 8341 пакет. Кроме CRAN, есть и другие репозитории с большим количеством пакетов. Синтаксис для установки любого из них прост:
Вот несколько пакетов, без которых вы вряд ли обойдетесь, как специалист по анализу данных:
Если необходимо решить, что делать с пропущенными значениями, MICE — именно то, что вам нужно. Когда возникает проблема пропущенных значений, наиболее частый способ ее решения — простые замены: нулями, средним, модой, т.д. Однако, ни один из этих методов не гибок и может привести к несоответствиям в данных.
Пакет MICE поможет заменить пропущенные значения, используя разнообразные техники, в зависимости от данных, с которыми вы работаете.
Давайте рассмотрим пример использования MICE.

Итак, мы создали случайный блок данных, намеренно внеся в него несколько пропущенных значений. Теперь можно посмотреть на работу MICE и перестать беспокоиться на их счет.

В примере по MICE мы использовали значения по умолчанию, но вы можете почитать о каждом из параметров и изменить их в соответствии с вашими требованиями.
2. Пакет
Пакет
Функция
rpart — аббревиатура, которая расшифровывается, как Recursive Partitioning and Regression Trees (рекурсивное разбиение и регрессионные деревья). С помощью rpart можно применять как регрессию, так и классификацию. Если говорить о синтаксисе, то он довольно простой:
Давайте рассмотрим массив данных

Допустим, наша цель — прогнозировать Species по дереву решений; это можно реализовать одной строчкой кода:
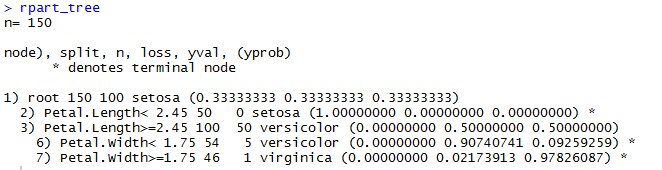
Здесь можно увидеть разделение разных вершин и прогнозируемый класс.
Чтобы прогнозировать на основании нового массива данных, можно воспользоваться простой функцией
3.
Пакет
Давайте построим дерево, воспользовавшись тем же примером, что и выше.
Вот как будет выглядеть построенное дерево:

В этом пакете также есть функция прогнозирования, ее хорошо использовать для прогнозирования классов по новым входным данным.
4.
Пакет
Можно облегчить построение моделей прогнозирования благодаря специальным встроенным функциям для разбиения данных, выбора важных признаков, предварительной обработки данных, оценки важности переменных, настройки модели через повторную выборку и визуализацию.
Пакет
После установки пакета
Чтобы строить модели прогнозирования,
Пакет
Короче говоря, это обязательный к использованию пакет R, который удовлетворит все ваши требования к построению моделей прогнозирования.
Сейчас в CRAN доступен 8341 пакет. Кроме CRAN, есть и другие репозитории с большим количеством пакетов. Синтаксис для установки любого из них прост:
install.packages(“Name_Of_R_Package”).Вот несколько пакетов, без которых вы вряд ли обойдетесь, как специалист по анализу данных:
dplyr, ggplot2, reshape2. Безусловно, это не полный список. В этой статье мы подробнее остановимся на пакетах, применяемых в машинном обучении.1. Пакет MICE — позаботиться о пропущенных значениях
Если необходимо решить, что делать с пропущенными значениями, MICE — именно то, что вам нужно. Когда возникает проблема пропущенных значений, наиболее частый способ ее решения — простые замены: нулями, средним, модой, т.д. Однако, ни один из этих методов не гибок и может привести к несоответствиям в данных.
Пакет MICE поможет заменить пропущенные значения, используя разнообразные техники, в зависимости от данных, с которыми вы работаете.
Давайте рассмотрим пример использования MICE.
dataset <- data.frame(var1=rnorm(20,0,1), var2=rnorm(20,5,1))
dataset[c(2,5,7,10),1] <- NA
dataset[c(4,8,19),2] <- NA
summary(dataset)
Итак, мы создали случайный блок данных, намеренно внеся в него несколько пропущенных значений. Теперь можно посмотреть на работу MICE и перестать беспокоиться на их счет.
install.pckages(“mice”)
require(mice)
dataset2 <- mice(dataset)
dataset2<-complete(dataset2)
summary(dataset2)
В примере по MICE мы использовали значения по умолчанию, но вы можете почитать о каждом из параметров и изменить их в соответствии с вашими требованиями.
2. Пакет rpart: давайте разделим данные
Пакет
rpart в языке R используется для построения классификационных и регрессионных моделей с применением двухшаговой процедуры, а результат представляется в виде бинарных деревьев. Самый простой способ построить регрессионное или классификационное дерево с применением rpart — вызвать функцию plot(). Сама по себе функция plot() может не дать достаточно красивый результат, поэтому есть альтернатива — prp() — мощная и гибкая функция. prp() в пакете rpart.plot часто называют настоящим швейцарским ножом для построения регрессионных деревьев.Функция
rpart() позволяет установить отношение между зависимой и независимыми переменными, чтобы показать дисперсию зависимой переменной на основании независимых. Например, если компания, предоставляющая онлайн-обучение, хочет узнать, как на их продажи (зависимая переменная) влияет продвижение в соц.сетях, газетах, реферальных ссылках, по сарафанному радио, т.д., в rpart есть несколько функций, которые могут помочь с анализом этого явления.rpart — аббревиатура, которая расшифровывается, как Recursive Partitioning and Regression Trees (рекурсивное разбиение и регрессионные деревья). С помощью rpart можно применять как регрессию, так и классификацию. Если говорить о синтаксисе, то он довольно простой:
rpart(formula, data=, method=,control=)
Давайте рассмотрим массив данных
iris, который выглядит так:Допустим, наша цель — прогнозировать Species по дереву решений; это можно реализовать одной строчкой кода:
rpart_tree <- rpart(formula = Species~., data=iris, method = ‘class’)
summary(rpart_tree)
plot(rpart_tree)
Здесь можно увидеть разделение разных вершин и прогнозируемый класс.
Чтобы прогнозировать на основании нового массива данных, можно воспользоваться простой функцией
predict(tree_name,new_data), которая выдаст прогнозируемые классы в качестве результата.3. PARTY: давайте снова разделим данные
Пакет
PARTY в R используется для рекурсивного разделения и отображает непрерывное улучшение ансамблевых методов. PARTY — еще один пакет для построения деревьев решений на основании алгоритма условного умозаключения. ctree() — главная функция пакета PARTY, она имеет широкое применение и сокращает время на обучение и возможные отклонения.PARTY имеет синтаксис, схожий с другими функциями прогнозной аналитики в R, т.е.ctree(formula,data)
Давайте построим дерево, воспользовавшись тем же примером, что и выше.
party_tree <- ctree(formula=Species~. , data = iris)
plot(party_tree)
Вот как будет выглядеть построенное дерево:
В этом пакете также есть функция прогнозирования, ее хорошо использовать для прогнозирования классов по новым входным данным.
4. CARET: Classification And REgression Training (классификация и регрессионное обучение)
Пакет
CARET — Classification And REgression Training (классификация и регрессионное обучение) — разработан для комбинирования моделей обучения и прогнозирования. В пакете есть несколько алгоритмов, подходящих для разных задач. Специалист по анализу данных не всегда может точно сказать, какой алгоритм лучше для решения той или иной задачи. Пакет CARET позволяет подобрать оптимальные параметры для алгоритма с помощью контролируемых экспериментов. Метод перекрестного поиска, реализованный в этом пакете, ищет параметры, комбинируя различные методы оценки производительности модели. После перебора всех возможных комбинаций метод перекрестного поиска находит комбинацию, которая дает наилучшие результаты.Можно облегчить построение моделей прогнозирования благодаря специальным встроенным функциям для разбиения данных, выбора важных признаков, предварительной обработки данных, оценки важности переменных, настройки модели через повторную выборку и визуализацию.
Пакет
CARET — один из лучших в R. Разработчики этого пакета понимали, как трудно выбрать наиболее подходящий алгоритм для каждой задачи. Бывают случаи, когда используется конкретная модель, и есть сомнения в качестве данных, но все же чаще всего проблема оказывается в выбранном алгоритме.После установки пакета
CARET можно выполнить names(getModelInfo()) и увидеть список из 217 доступных методов.Чтобы строить модели прогнозирования,
CARET использует функцию train(). Ее синтаксис выглядит так:train(formula, data, method)
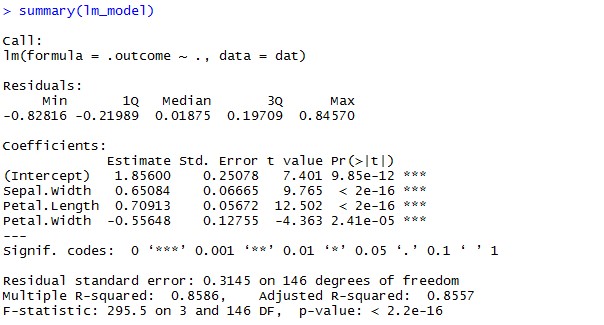
Lm_model <- train(Sepal.Length~Sepal.Width + Petal.Length + Petal.Width, data=iris, method = “lm”)
summary(lm_model)
Пакет
CARET не только строит модели, но и разбивает данные на тестовые и обучающие, производит необходимые преобразования и т.д.Короче говоря, это обязательный к использованию пакет R, который удовлетворит все ваши требования к построению моделей прогнозирования.
Поделиться с друзьями
Комментарии (7)

ternaus
16.07.2016 05:35А как у R с нейронными сетями? Я знаю про пакет H2O
Там есть что-нибудь уровня keras?
P.S. На тему MATLAB: Если во время интервью, выясняется, что компания использует MATLAB для Data Science — идти туда не надо.
Ananiev_Genrih
19.07.2016 09:48про keras не в курсе но пакеты по работе с сетями присутствуют:
kohonen: Supervised and Unsupervised Self-Organising Maps
nnet: Feed-Forward Neural Networks and Multinomial Log-Linear Models
RSNNS: Neural Networks in R using the Stuttgart Neural Network Simulator (SNNS)
neuralnet: Training of neural networks
FCNN4R: Fast Compressed Neural Networks for R
dimm_ddr
Есть ли в R что-либо достаточно мощное для обработки изображений? Насущная задача: нужно разбить большое изображение на много мелких перекрывающихся, после чего по определенному алгоритму их все пометить. При этом желательно чтобы мелкие изображения были не отдельным массивом данных, а чем-то вроде ссылок на основной — иначе требуемая память увеличивается в несколько сотен раз. В питоне это можно сделать с помощью openCV + numpy.
Я ни в коем случае не пытаюсь сказать что питон лучше, мне действительно хотелось бы узнать какими пакетами такую задачу можно решить в R.
tzlom
По хорошему — надо танцевать от того, что именно за алгоритм обработки, есть допустим raster, он умеет большие картинки и
Если жадная обработка в память не лезет то может быть можно последовательно отрезать-обработать-сохранить, заодно можно легко распараллелить этот процесс.
Касательно не дублируя память — не знаю, в детали не влезал, на сколько я знаю OpenCV всегда делает копию. Кстати есть пакет videoplayR который по сути частичный биндинг OpenCV.
dimm_ddr
openCV делает копию, но это не страшно — копируется только само базовое изображение, а дальше передает уже массивы numpy которые уже можно разбить без копирования. Там для этого используется некоторый хак и недокументированные методы, так что все сложно.