Одной из важных технологий любой серьезной системы мониторинга сетей является метод обнаружения связей сетевых элементов на 2-м и 3-м уровне модели OSI.

С точки зрения алгоритмов эта задача является одной из самых интересных встреченных нами во время разработки нашей системы.
Мы решили немного поделиться нашим опытом, чтобы вы могли представить, каким образом красивый граф связей между узлами появляется на дэшбордах вашей системы мониторинга.
Топология сети — это способ описания конфигурации сети, схема расположения и соединения сетевых устройств. Мы будем рассматривать TCP/IP сеть, основу которой образуют сетевые устройства трёх типов: коммутаторы, маршрутизаторы и конечные станции. Мы также будем предполагать, что сетевые устройства, коммутаторы и маршрутизаторы, предоставляют открытый интерфейс для опроса по SNMP.
Для описания топологии удобно рассматривать OSI-модель сети как многоэтажное здание в основе которого лежит фундамент — это физический уровень, а этажи образуют канальный и сетевой уровни, каждый последующий уровень надстраивает здание и таким образом обеспечивает целостность и функциональность всей конструкции. Задача всего здания обеспечить его жителей, то есть различные приложения, связью друг с другом.
В Network Manager реализован алгоритм поиска связей между разнородными устройствами, поддерживающие различные протоколы конфигурации топологии сети, протокол связующего дерева (STP, Spanning Tree Protocol), протоколы LLDP (Link Layer Discovery Protocol) и CDP (Cisco Discovery Protocol). Архитектура программной системы позволяет реализовать поддержку новых протоколов для обнаружения как связей на 2-м и 3-м уровне модели OSI, так и любых других логических связей между элементами ИТ-инфраструктуры.
На канальном уровне связи между устройствами называются связями второго уровня (или L2-связи). Они могут быть заданы указанием пары портов двух непосредственно связанных коммутаторов, или коммутатора и конечной станции, или коммутатора и маршрутизатора.
Коммутаторы поддерживают динамическую таблицу переадресации (AFT, address forwarding table), хранящую соответствие MAC адреса узла порту коммутатора. Эта информация доступна через динамические таблицы доступные по SNMP в BRIDGE-MIB коммутатора (dot1dBasePortTable, dot1dTpFdbTable).
Будем говорить, что коммутатор видит на данном порту данное сетевое устройство, если в его динамической таблице переадресации содержится запись, которая указывает перенаправлять дейтаграммы предназначенные этому сетевому устройству через данный порт.
Для коммутатора с поддержкой базы данных BRIDGE-MIB можно, считывая dot1dBasePortTable, определить соответствие между номером интерфейса и номером порта, а доступные интерфейсы определяются базой данных MIB-II (таблица ifTable). Это позволяет единым образом рассматривать данные о связях 2-го и 3-го уровня.
Для хранения промежуточных результатов в Network Manager используется топологическая база данных, которая предоставляет общий интерфейс для работы с графом сети и его специализациями, предназначенными для работы на канальном и сетевом уровнях.
Автоматическое определение топологии сети разбивается на две фазы: сбор данных и их последующий анализ. Данные с сетевых устройств собираются в топологической базе данных, с помощью SNMP запросов к базам данных сетевых устройств, и определяются типы устройств и их сетевые интерфейсы.

На втором этапе, происходит анализ доступных данных по выбранным протоколам определения топологии сети, для реализации алгоритмов используются доступные в Интернет сети статьи 1, 2 и 5.

Сложность определения топологии разнородной сети состоит в том, что таблицы переадресации коммутаторов динамические, хранят запись соответствия МАС адреса назначения и соответствующего ему порта некоторое ограниченное время, заданное в конфигурации устройства и в общем случае, на момент исследования не все сетевые устройства обменялись дейтаграммами и как результат маршрутизаторы не могут иметь полной информации о всех доступных сетевых устройствах и их связях. Кроме того, во многих корпоративных сетях встречаются неуправляемые коммутаторы, а некоторые коммутаторы могут быть не подключены к системе мониторинга или некорректно поддерживать нужные SNMP MIBы. Однако, если существует сетевое устройство, видимое на всех коммутаторах сети, то по неполным таблицам переадресации можно однозначно восстановить конфигурацию сети (3).
Разнородность сети также влияет на интерпретацию данных полученных от коммутаторов, на которых настроена поддержка протоколов LLDP и CDP, потому что для их корректной работы необходимо, чтобы все ближайшие сетевые устройства поддерживали или LLDP, или CDP протокол. В итоге, информация, полученная из этих протоколов даёт лишь возможность заключить, что два данных сетевых устройства видят друг друга на определённых портах, но не даёт возможности непосредственно определить их как ближайших «соседей».
Алгоритм поиска топологии разнородной сети, реализованный в AggreGate Network Manager, в первую очередь определяет связи между коммутаторами. Общую суть алгоритма можно описать следующим образом:
Рассмотрим два коммутатора «А» и «Б», расположенные в одной подсети. Если коммутатор «А» видит на порту «а» коммутатор «Б», а коммутатор «Б» видит на порту «б» коммутатор «А» и в их таблицах нет другого сетевого устройства, которое одновременно видимо на портах «а» и «б», то коммутаторы «А» и «Б» соединены напрямую на канальном уровне (см. 1, 3 и 5). После нахождения связи мы убираем соответствующие ей интерфейсы из кэша таблиц форвардинга и продолжаем анализ оставшейся в таблицах информации, постепенно находя методом исключения остальные связи.
На следующем этапе определяются возможные связи между коммутаторами и конечными станциями. Для этого используется поиск ближайшего коммутатора: если коммутатор видит на данном порту конечную станцию и на том же самом порту он видит другой коммутатор, то, при отсутствие сетевых концентраторов, данный коммутатор не может быть ближайшим (см. 4). С другой стороны, если коммутатор на исследуемом порту видит только одну конечную станцию, то этот коммутатор и станция ближайшие соседи в нашей сети.
С топологией IP-уровня (L3) дела обстоят значительно проще. Линки 3-го уровня достаточно легко определяются по таблицам маршрутизации (ipRouteTable), также доступным по SNMP.
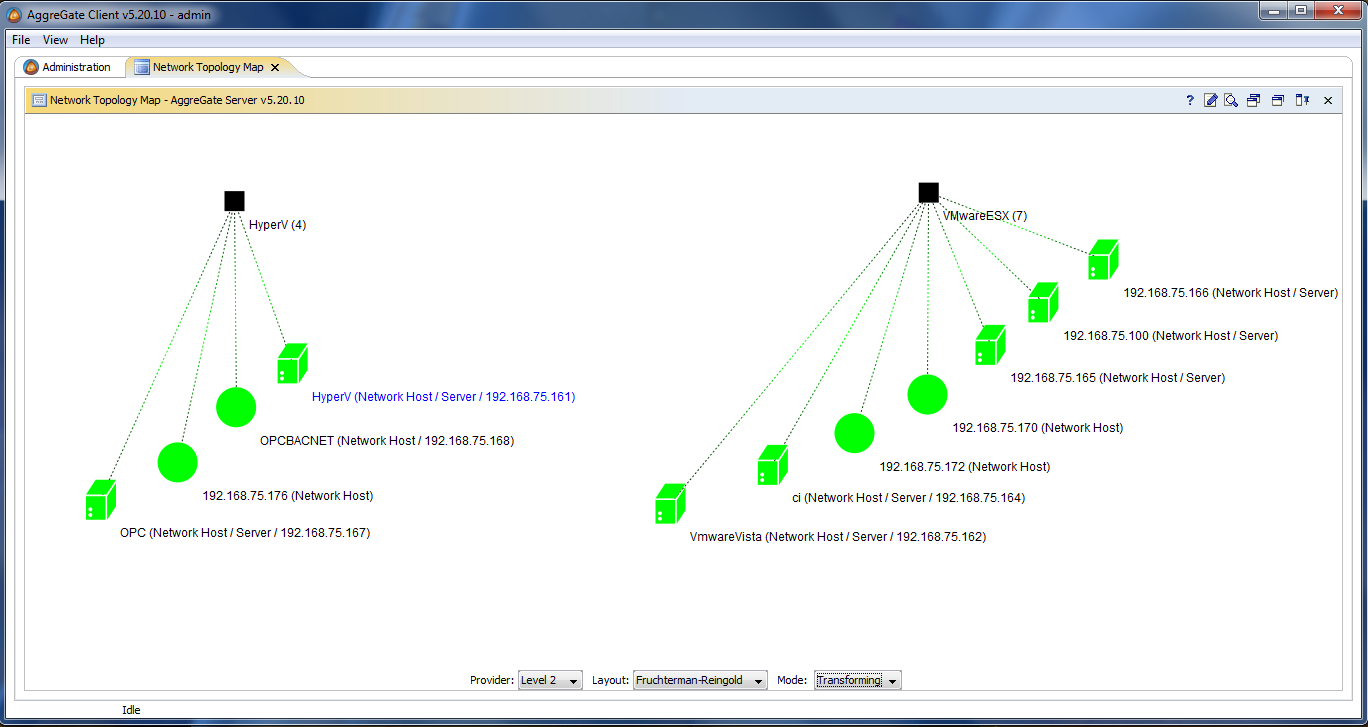
Понимая, что универсальность нашего продукта заставит нас в будущем иметь дело с самыми разными видами топологии, мы спроектировали визуальный компонент «граф топологии» таким образом, чтобы он мог работать с произвольными таблицами, содержащими описания узлов и ребер графа топологии. И, как обычно, при наличии инструмента быстро нашлись ему новые применения:

Все технологии, описанные в данной статье, протестированы и внедрены в нашем продукте AggreGate Network Manager. Работа алгоритмов определения связей в условиях недостаточности данных (не все коммутаторы и маршрутизаторы подключены по SNMP, некорректная поддержка нужных MIBов и т.д.) далеко не тривиальна, поэтому мы и по сей день продолжаем совершенствовать их.
Что почитать по теме:

С точки зрения алгоритмов эта задача является одной из самых интересных встреченных нами во время разработки нашей системы.
Мы решили немного поделиться нашим опытом, чтобы вы могли представить, каким образом красивый граф связей между узлами появляется на дэшбордах вашей системы мониторинга.
Топология сети — это способ описания конфигурации сети, схема расположения и соединения сетевых устройств. Мы будем рассматривать TCP/IP сеть, основу которой образуют сетевые устройства трёх типов: коммутаторы, маршрутизаторы и конечные станции. Мы также будем предполагать, что сетевые устройства, коммутаторы и маршрутизаторы, предоставляют открытый интерфейс для опроса по SNMP.
Для описания топологии удобно рассматривать OSI-модель сети как многоэтажное здание в основе которого лежит фундамент — это физический уровень, а этажи образуют канальный и сетевой уровни, каждый последующий уровень надстраивает здание и таким образом обеспечивает целостность и функциональность всей конструкции. Задача всего здания обеспечить его жителей, то есть различные приложения, связью друг с другом.
В Network Manager реализован алгоритм поиска связей между разнородными устройствами, поддерживающие различные протоколы конфигурации топологии сети, протокол связующего дерева (STP, Spanning Tree Protocol), протоколы LLDP (Link Layer Discovery Protocol) и CDP (Cisco Discovery Protocol). Архитектура программной системы позволяет реализовать поддержку новых протоколов для обнаружения как связей на 2-м и 3-м уровне модели OSI, так и любых других логических связей между элементами ИТ-инфраструктуры.
На канальном уровне связи между устройствами называются связями второго уровня (или L2-связи). Они могут быть заданы указанием пары портов двух непосредственно связанных коммутаторов, или коммутатора и конечной станции, или коммутатора и маршрутизатора.
Коммутаторы поддерживают динамическую таблицу переадресации (AFT, address forwarding table), хранящую соответствие MAC адреса узла порту коммутатора. Эта информация доступна через динамические таблицы доступные по SNMP в BRIDGE-MIB коммутатора (dot1dBasePortTable, dot1dTpFdbTable).
Будем говорить, что коммутатор видит на данном порту данное сетевое устройство, если в его динамической таблице переадресации содержится запись, которая указывает перенаправлять дейтаграммы предназначенные этому сетевому устройству через данный порт.
Для коммутатора с поддержкой базы данных BRIDGE-MIB можно, считывая dot1dBasePortTable, определить соответствие между номером интерфейса и номером порта, а доступные интерфейсы определяются базой данных MIB-II (таблица ifTable). Это позволяет единым образом рассматривать данные о связях 2-го и 3-го уровня.
Для хранения промежуточных результатов в Network Manager используется топологическая база данных, которая предоставляет общий интерфейс для работы с графом сети и его специализациями, предназначенными для работы на канальном и сетевом уровнях.
Автоматическое определение топологии сети разбивается на две фазы: сбор данных и их последующий анализ. Данные с сетевых устройств собираются в топологической базе данных, с помощью SNMP запросов к базам данных сетевых устройств, и определяются типы устройств и их сетевые интерфейсы.

На втором этапе, происходит анализ доступных данных по выбранным протоколам определения топологии сети, для реализации алгоритмов используются доступные в Интернет сети статьи 1, 2 и 5.

Сложность определения топологии разнородной сети состоит в том, что таблицы переадресации коммутаторов динамические, хранят запись соответствия МАС адреса назначения и соответствующего ему порта некоторое ограниченное время, заданное в конфигурации устройства и в общем случае, на момент исследования не все сетевые устройства обменялись дейтаграммами и как результат маршрутизаторы не могут иметь полной информации о всех доступных сетевых устройствах и их связях. Кроме того, во многих корпоративных сетях встречаются неуправляемые коммутаторы, а некоторые коммутаторы могут быть не подключены к системе мониторинга или некорректно поддерживать нужные SNMP MIBы. Однако, если существует сетевое устройство, видимое на всех коммутаторах сети, то по неполным таблицам переадресации можно однозначно восстановить конфигурацию сети (3).
Разнородность сети также влияет на интерпретацию данных полученных от коммутаторов, на которых настроена поддержка протоколов LLDP и CDP, потому что для их корректной работы необходимо, чтобы все ближайшие сетевые устройства поддерживали или LLDP, или CDP протокол. В итоге, информация, полученная из этих протоколов даёт лишь возможность заключить, что два данных сетевых устройства видят друг друга на определённых портах, но не даёт возможности непосредственно определить их как ближайших «соседей».
Алгоритм поиска топологии разнородной сети, реализованный в AggreGate Network Manager, в первую очередь определяет связи между коммутаторами. Общую суть алгоритма можно описать следующим образом:
Рассмотрим два коммутатора «А» и «Б», расположенные в одной подсети. Если коммутатор «А» видит на порту «а» коммутатор «Б», а коммутатор «Б» видит на порту «б» коммутатор «А» и в их таблицах нет другого сетевого устройства, которое одновременно видимо на портах «а» и «б», то коммутаторы «А» и «Б» соединены напрямую на канальном уровне (см. 1, 3 и 5). После нахождения связи мы убираем соответствующие ей интерфейсы из кэша таблиц форвардинга и продолжаем анализ оставшейся в таблицах информации, постепенно находя методом исключения остальные связи.
На следующем этапе определяются возможные связи между коммутаторами и конечными станциями. Для этого используется поиск ближайшего коммутатора: если коммутатор видит на данном порту конечную станцию и на том же самом порту он видит другой коммутатор, то, при отсутствие сетевых концентраторов, данный коммутатор не может быть ближайшим (см. 4). С другой стороны, если коммутатор на исследуемом порту видит только одну конечную станцию, то этот коммутатор и станция ближайшие соседи в нашей сети.
С топологией IP-уровня (L3) дела обстоят значительно проще. Линки 3-го уровня достаточно легко определяются по таблицам маршрутизации (ipRouteTable), также доступным по SNMP.
Понимая, что универсальность нашего продукта заставит нас в будущем иметь дело с самыми разными видами топологии, мы спроектировали визуальный компонент «граф топологии» таким образом, чтобы он мог работать с произвольными таблицами, содержащими описания узлов и ребер графа топологии. И, как обычно, при наличии инструмента быстро нашлись ему новые применения:
- Топология маршрутов EIGRP, OSPF, BPG и т.п.
- Визуализация путей в облаке MPLS
- SDH/PDH топология
- Визуализация связей между гипервизорами и работающими на них виртуальными машинами
- Добавленные вручную parent-child связи между узлами
- Граф зависимости компонентов ИТ-сервиса от элементов инфраструктуры


Все технологии, описанные в данной статье, протестированы и внедрены в нашем продукте AggreGate Network Manager. Работа алгоритмов определения связей в условиях недостаточности данных (не все коммутаторы и маршрутизаторы подключены по SNMP, некорректная поддержка нужных MIBов и т.д.) далеко не тривиальна, поэтому мы и по сей день продолжаем совершенствовать их.
Что почитать по теме:
- Topology Discovery in Heterogeneous IP Networks: The NetInventory System. Y.Breitbart, M.Garofalakis, B. Jai, C.Martin, R.Rastogi, and A.Silberschatz IEEE/ACM TRANSACTIONS ON NETWORKING, VOL. 12, NO. 3, JUNE 2004
- Layer-2 Path Discovery Using Spanning Tree MIBs. David T. Stott, Avaya Labs Research, Avaya Inc., Basking Ridge, NJ, Tech. Rep
- Finding Ethernet-Type Network Topology is Not Easy. H. Gobjuka, Y. Breitbart, Technical Report: TR-KSU-CS-2007-03, Kent State University, 2007.
- Автоматическое определение и описание сетевой инфраструктуры суперкомпьютеров. В. Воеводин, К. Стефанов, Вычислительные Методы и Программирование. 2014. Т. 15
- IP Network Topology Discovery Using SNMP. Suman Pandey, Mi-Jung Choi, Sung-Joo Lee, James W. Hong, Dept. of Computer Science and Engineering, POSTECH, Korea

AlexBin
Поделюсь нашим опытом (ISP):
В виду отсутствия LLDP на всех устройствах доступа и вообще каких-либо дискавери-протоколов, определяем физические связи руками. Таким образом мы поддерживаем актуальную базу ребер графа. Затем на основе этих ребер строится неориентированный беспетельный мультиграф (мульти — потому что между двумя устройствами может быть больше одной физической линки). На базе этих алгоритмов работает часть системы мониторинга (определение аплинков, предотвращение логических L2 петель, автоматическая прокладка вланов)
Используем SNMP, Telnet, HTTP для управления и контроля (некоторые девайсы настолько старые, что имеют функции, доступные только по веб-интерфейсу).
Таблицу ребер корректируем всякими алгоритмами, помечающие явно неверные связи. Очень грустим, что нет LLDP.
Теперь по статье:
>>> «Рассмотрим два коммутатора «А» и «Б», расположенные в одной подсети. Если коммутатор «А» видит на порту «а» коммутатор «Б», а коммутатор «Б» видит на порту «б» коммутатор «А» и в их таблицах нет другого сетевого устройства, которое одновременно видимо на портах «а» и «б», то коммутаторы «А» и «Б» соединены напрямую на канальном уровне „
Разве это так? По-моему, это утверждение будет верно, если каждый коммутатор пытался получить доступ к другому коммутатору, после чего в FDB-таблице закешируется запись о соседе. Если же они занимаются коммутацией другого сегмента, но при этом сами живут в отдельном сегменте (общий управляющий сегмент для обоих коммутаторов), то в FDB таблице не должны храниться мак-адреса друг друга в общем случае. На этом алгоритме я и пытался релаизовать автоматический поиск ребер графа, но столкнулся с тем, что это утверждение не всегда верно. Возможно Ваш метод работает в виду постоянной работы всяких дискавери-протоколов, которые действительно пытаются постоянно искать соседей, что поддерживает записи друг о друге в таблице мак-адресов.
Sonic1980 Автор
А вы сами разрабатывали всю логику обнаружения топологии? Если все это делалось для одной конкретной сети, то усилия впечатляют! Можете рассказать, какие алгоритмы используете для обнаружения неверных связей?
По поводу замечания про алгоритм. Конечно, в его описании мы «срезали углы», чтобы было понятнее. Я попросил разработчиков модуля топологии прокомментировать: Согласны, что это утверждение верно, только в предположении полноты таблиц переадресации на коммутаторах «А» и «Б». Свойство полноты означает, что таблицы содержат все узлы подсети, которым могут быть доставлены пакеты через порты «а» и «б» коммутаторов «А» и «Б», соответственно. Поэтому, если они не соединены напрямую, то существует путь по которому пакеты маршрутизируются из «А» порта «а» в «Б» и из «Б» порта «б» в «А», но так как сеть не содержит циклов, то эти пути будут совпадать и любой промежуточный коммутатор «В» будет виден коммутатором «А» на порту «а» и коммутатором «Б» на порту «б», но тогда рассмотренное нами необходимое условие не выполняется.
В алгоритме автоматического поиска топологии второго уровня мы ставили задачу правильно определить возможные связи между коммутаторами исключив ложные, есть возможность добавить дополнительные связи при необходимости. При неполных таблицах ложные связи можно исключить рассматривая окружение коммутаторов, а именно, так называемое, сквозное множество на порту «а» коммутатора «А» и соответственно, порту «б» коммутатора «Б», это множество всех известных узлов полученных на всех портах коммутатора за исключением выбранного порта. Так вот, если сквозные множества на порту «а» и «б», соответственно, имеют общие узлы, то коммутаторы не могут быть соединены напрямую через порты «а» и «б, при условии, что они находятся в одной подсети.
В целом, конечно, работа модуля обнаружения топологии намного сложнее, чем его краткое описание в статье. Задача статьи — просто рассказать тем, кто не занимался вопросом всерьез, как в целом устроено определение топологии. А ссылочки на статьи мы привели, чтобы те, кто заинтересовался, смогли изучить тему поподробнее.
AlexBin
> А вы сами разрабатывали всю логику обнаружения топологии?
Дык, я и говорю, в виду отсутствия полного покрытия всех моделей дискавери-протоколами, нет у нас системы обнаружения. То есть соединили патчкордом два девайса, добавили логическую связь в систему руками, а уже дальше автоматика управления/мониторинга. И кстати, я хотел именно на таком же как у Вас алгоритме делать обнаружение, прежде чем столкнулся с описанной ранее проблемой. А наткнулся я на нее, когда некий тестовый девайс стоял в разрыве между двумя другими девайсами, которые ничего о нем не знали, хотя трафик общения между ними шел именно через него.
> какие алгоритмы используете для обнаружения неверных связей?
Эти алгоритмы не универсальны, опираются на канальную инфраструктуру конкретно нашей сети. Например, если система видит живой порт с mng-вланом и маком на порту, но при этом логической связи нет, тут явно кто-то забыл добавить логическую связь. Или если видим связь между портами, на которых полное расхождение вланов и маков, значит явно связь неверная.
Sonic1980 Автор
У нас, кстати, в алгоритме реализовано обнаружение хабов и неуправляемых коммутаторов в случаях, когда через них идет более двух линков. Сами они в топологии не рисуются (т.к. неизвестно, сколько там этих хабов стоит), но линки, идущие через них, особым образом помечаются.