37 секунд полета… бабах!
10 лет и 7 миллиардов долларов, потраченных на разработку.
Четыре полуторатонных спутника научной программы Cluster (изучение взаимодействия солнечного излучения с магнитным полем Земли) и ракета носитель Ariane 5 превратились в «конфети» 4 июня 1996 года.
А вину свалили на программистов.
Предыдущая модель — ракета Ariane 4 — успешно запускалась более 100 раз. Что пошло не так?
Чтобы штурмовать небеса, нужно хорошо знать язык Ада.

Досье
Ariane 5 («Ариан-5») — европейская одноразовая ракета-носитель, входит в семейство Ariane (первый запуск состоялся в 1979 г.). Используется для вывода на околоземную орбиту средних или тяжелых космических аппаратов, может одновременно запускать два-три спутника и попутно до восьми микроспутников.
История проекта
Создана в 1984-1995 гг. Европейским космическим агентством (ЕКА; ESA), основной разработчик — Национальный центр космических исследований Франции (CNES). Участниками программы являются 10 европейских стран, стоимость проекта — 7 млрд долларов США (46,2% — вклад Франции).
В создании ракеты принимали участие около тысячи промышленных фирм. Основной подрядчик — европейская компания Airbus Defence and Space («Эрбас дифенз энд спейс»; подразделение Airbus Group, «Эрбас груп», Париж). Маркетингом Ariane 5 на рынке космических услуг занимается французская компания Arianespace («Арианспейс»; Эври), с которой ЕКА подписало 25 ноября 1997 г. соответствующее соглашение.
Характеристики
Ariane 5 представляет собой двухступенчатую ракету-носитель тяжелого класса. Длина — 52-53 м, максимальный диаметр — 5,4 м, стартовая масса — 775-780 т (в зависимости от конфигурации).
Первая ступень оснащена жидкостным ракетным двигателем Vulcain 2 («Вулкан-2»; в первых трех модификациях ракеты использовался Vulcain), вторая — HM7B (для версии Ariane 5 ECA) или Aestus («Аэстус»; для Ariane 5 ES). Vulcain 2 и HM7B работают на смеси водорода и кислорода, производятся французской компанией Snecma («Снекма»; входит в группу Safran, «Сафран», Париж).
В Aestus используется долгохранимое топливо — тетраоксид азота и монометилгидразин. Двигатель разработан немецкой компанией Daimler Chrysler Aerospace AG (DASA, «ДАСА», Мюнхен).
Кроме того, к первой ступени крепятся два твердотопливных ускорителя (изготовитель — Europropulsion, «Европропелжн»; Сюрен, Франция; совместное предприятие группы Safran и итальянской фирмы Avio, «Авио»), которые обеспечивают более 90% тяги в начале пуска. В варианте Ariane 5 ES вторая ступень может отсутствовать при выводе полезной нагрузки на низкую опорную орбиту.

Бортовые компьютеры
www.ruag.com/space/products/digital-electronics-for-satellites-launchers/on-board-computers
Расследование
На следующий день после катастрофы Генеральный директор Европейского Космического Агенства (ESA) и Председатель Правления Французского Национального Центра по изучению Космоса (CNES) издали распоряжение об образовании независимой Комиссии по Расследованию обстоятельств и причин этого чрезвычайного происшествия, в которую вошли известные специалисты и ученые изо всех заинтересованных европейских стран.
13 июня 1996 г. Комиссия приступила к работе, а уже 19 июля был обнародован ее исчерпывающий доклад (PDF), который сразу же стал доступен в Сети.
У комиссии были данные телеметрии, траекторные данные, а также запись оптических наблюдений за ходом полета.
Взрыв произошел на высоте приблизительно 4 км, и осколки были рассеяны на площади около 12 кв. км. в саванне и болотах. Были заслушаны показания многочисленных специалистов и изучены производственная и эксплуатационная документации.

Технические подробности аварии
Положение и ориентация ракеты-носителя в пространстве измерялись Навигационной Системой (Inertial Reference Systems — IRS), составной частью которой является встроенный компьютер, вычисляющий углы и скорости на основе информации от бортовой Инерциальной Платформы, оборудованной лазерными гироскопами и акселерометрами. Данные от IRS передавались по специальной шине на Бортовой Компьютер (On-Board Computer — OBC), который обеспечивал необходимую для реализации программы полета информацию и непосредственно — через гидравлические и сервоприводы — управлял твердотопливными ускорителями и криогенным двигателем типа Вулкан (Vulkain).
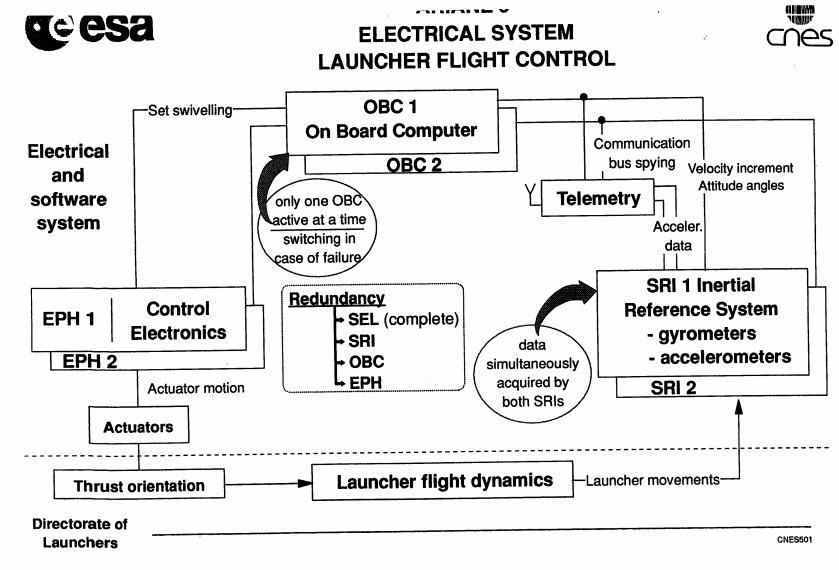
Для обеспечения надежности Системы Управления Полетом использовалось дублирование оборудования. Поэтому две системы IRS (одна — активная, другая — ее горячий резерв) с идентичным аппаратным и программным обеспечением функционировали параллельно. Как только бортовой компьютер OBC обнаруживал, что «активная» IRS вышла из штатного режима, он сразу же переключается на другую. Бортовых компьютеров тоже было два.
Значимые фазы развития процесса
За 7 минут до запланированного старта было зафиксировано нарушение «критерия видимости». Поэтому старт был перенесен на час.
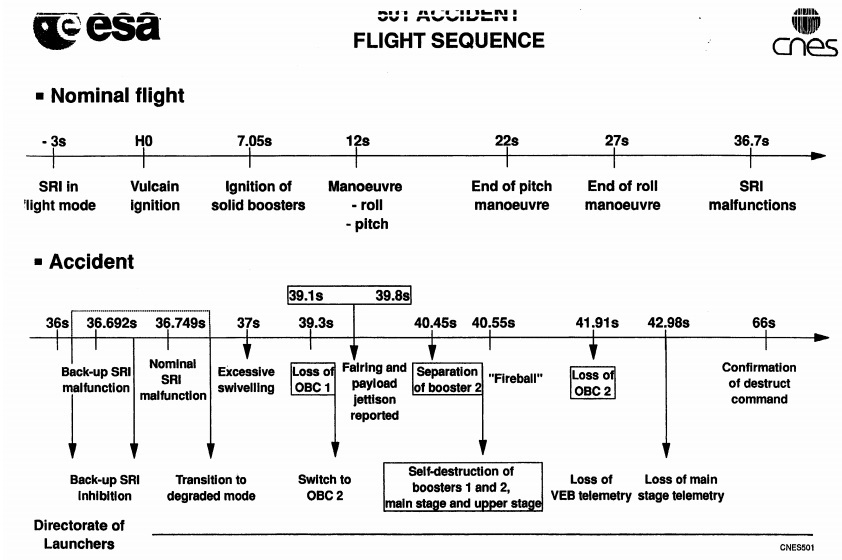
H0 = 9 час. 33 мин. 59 сек. местного времени «окно запуска» было вновь «поймано» и был, наконец, осуществлен сам запуск, который и происходил штатно вплоть до момента H0+37 секунд.
В последующие секунды произошло резкое отклонение ракеты от заданной траектории, что и закончилось взрывом.
В момент H0+39 секунд из-за высокой аэродинамической нагрузки вследствие превышения «углом атаки» критической величины на 20 градусов произошло отделение стартовых ускорителей ракеты от основной ее ступени, что и послужило основанием для включения Системы Автоподрыва ракеты.
Изменение угла атаки произошло по причине нештатного вращения сопел твердотопливных ускорителей, такое отклонение сопел ускорителей от правильной ориентации вызвала в момент H0 + 37 секунд команда, выданная Бортовым Компьютером на основе информации от активной Навигационной Системы (IRS 2).
Часть этой информации была в принципе некорректной: то, что интерпретировалось как полетные данные, на самом деле являлось диагностической информацией встроенного компьютера системы IRS 2.
Встроенный компьютер IRS 2 передал некорректные данные, потому что диагностировал нештатную ситуацию, «поймав» исключение (exception), выброшенное одним из модулей программного обеспечения.
При этом Бортовой Компьютер не мог переключиться на резервную систему IRS 1, так как она уже прекратила функционировать в течение предшествующего цикла (занявшего 72 миллисекунд) — по той же причине, что и IRS 2.
Исключение, «выброшенное» одной из программ IRS, явилось следствием выполнения преобразования данных из 64-разрядного формата с плавающей точкой в 16-разрядное целое со знаком, что привело к «Operand Error».
Ошибка произошла в компоненте ПО, предназначенном исключительно для выполнения «регулировки» Инерциальной Платформы. Причем этот программный модуль выдает значимые результаты только до момента H0+7 секунд отрыва ракеты со стартовой площадки. После того, как ракета взлетела, никакого влияния на полет функционирование данного модуля оказать не могло.
«Функция регулировки» действительно должна была (в соответствии с установленными для нее требованиями) действовать еще 50 секунд после инициации «полетного режима» на шине Навигационной Системы (момент H0-3 секунд), что она и делала.
Ошибка «Operand Error» произошла из-за неожиданно большой величины BH (Horizontal Bias — горизонтальный наклон), посчитанной внутренней функцией на основании величины «горизонтальной скорости», измеренной находящимися на Платформе датчиками.
Величина BH служила индикатором точности позиционирования Платформы. величина BH оказалась много больше, чем ожидалось потому, что траектория полета Ariane 5 на ранней стадии существенно отличалась от траектории полета Ariane 4 (где этот программный модуль использовался ранее), что и привело к значительно более высокой «горизонтальной скорости».
Финальным же действием, имевшим фатальные последствия, стало прекращение работы процессора. Соответственно, вся Навигационная Система перестала функционировать. Возобновить же ее действия оказалось технически невозможно.
Эту цепь событий удалось полностью воспроизвести с помощью компьютерного моделирования, что — вкупе с материалами других исследований и экспериментов — позволило заключить, что причины и обстоятельства катастрофы полностью выявлены.

Причины и истоки аварии
Первоначальное требование на продолжение выполнения операции регулировки после взлета ракеты было заложено более чем за 10 лет до рокового события, когда проектировались еще ранние модели серии Ariane.
При некотором маловероятном развитии событий взлет мог быть отменен буквально за несколько секунд до старта, например в промежутке H0-9 секунд, когда на IRS запускался «полетный режим», и H0-5 секунд, когда выдавалась команда на выполнение некоторых операций с ракетным оборудованием.
В случае неожиданной отмены взлета необходимо было быстро вернуться в режим «обратного отсчета» (countdown) — и при этом не повторять сначала все установочные операции, в том числе приведение к исходному положения Инерциальной Платформы (операция, требующая 45 мин. — время, за которое можно потерять «окно запуска»).
Было обосновано, что в случае события отмены старта период в 50 секунд после H0-9 будет достаточным для того, чтобы наземное оборудование смогло восстановить полный контроль за Инерциальной Платформой без потери информации — за это время Платформа прекратит начавшееся было перемещение, а соответствующий программный модуль всю информацию о ее состоянии зафиксирует, что поможет оперативно возвратить ее в исходное положение (это в случае, когда ракета продолжает находиться на месте старта). Однажды, в 1989 году, при старте под номером 33 ракеты Ariane 4, эта особенность была с успехом задействована.

Однако, Ariane 5, в отличие от предыдущей модели, имел уже принципиально другую дисциплину выполнения предполетных действий — настолько другую, что работа рокового программного модуля после времени старта вообще не имела смысла. Однако, модуль повторно использовался без каких-либо модификаций.
Язык АДА

Расследование показало, что в данном программном модуле присутствовало целых семь переменных, вовлеченных в операции преобразования типов. Оказалось, что разработчики проводили анализ всех операций, способных потенциально генерировать исключение, на уязвимость.
Это было их вполне сознательным решением добавить надлежащую защиту к четырем переменным, а три — включая BH — оставить незащищенными. Основанием для такого решения была уверенность в том, что для этих трех переменных возникновение ситуации переполнения невозможно в принципе.
Уверенность эта была подкреплена расчетами, показывающими, что ожидаемый диапазон физических полетных параметров, на основании которых определяются величины упомянутых переменных, таков, что к нежелательной ситуации привести не может. И это было верно — но для траектории, рассчитанной для модели Ariane 4.
А ракета нового поколения Ariane 5 стартовала по совсем другой траектории, для которой никаких оценок не выполнялось. Между тем она (вкупе с высоким начальным ускорением) была такова, что «горизонтальная скорость» превзошла расчетную (для Ariane 4) более чем в пять раз.
Защита для всех семи (включая BH) переменных не была обеспечена, потому что для компьютера IRS была продекларирована максимальная величина рабочей нагрузки в 80%. Разработчики должны были искать пути снижения излишних вычислительных издержек и они ослабили защиту там, где теоретически нежелательной ситуации возникнуть не могло. Когда же она возникла, то вступил в действие такой механизм обработки исключительной ситуации, который оказался совершенно неадекватным.
Этот механизм предусматривал следующие три основных действия.
- Информация о возникновении нештатной ситуации должна быть передана по шине на бортовой компьютер OBC.
- Параллельно она — вместе со всем контекстом — записывалась в перепрограммируемую память EEPROM (которую во время расследования удалось восстановить и прочесть ее содержимое).
- Работа процессора IRS должна была аварийно завершиться.
Последнее действие и оказалось фатальным — именно оно, случившееся в ситуации, которая на самом деле была нормальной (несмотря на сгенерированное из-за незащищенного переполнения программное исключение), и привело к катастрофе.

Выводы
Дефект на Ariane 5 не был вызван одной причиной. В ходе всей разработки и процессов тестирования существовало много стадий, на которых данный дефект мог быть выявлен.
- Программный модуль был повторно использован в новой среде, где условия функционирования отличались от требований программного модуля. Эти требования не были пересмотрены.
- Система выявила и распознала ошибку. К несчастью, спецификация механизма обработки ошибок была несоответственной и вызвала окончательное разрушение.
- Ошибочный модуль никогда должным образом не тестировался в новом окружении — ни на уровне оборудования, ни на уровне системной интеграции. Следовательно, ошибочность разработки и реализации не была обнаружена.

Из отчета комиссии:
Главной задачей при разработке Ariane 5 является уклон в сторону уменьшения случайной аварии. Возникшее исключение, объясняется не случайной аварией, но ошибкой конструкции. Исключение было обнаружено, но обработано неверно, поскольку была принята точка зрения, что программу следует рассматривать как правильную, пока не показано обратное. Комиссия придерживается противоположной точки зрения, что программное обеспечение нужно считать ошибочным, пока использование признанных в настоящее время наилучшими практических методов не продемонстрирует его правильность.
Счастливый конец

Несмотря на фэйл, построили еще 4 спутника Cluster II и вывели на орбиту на ракете Союз-У/Фрегат в 2000 году.
Авария при запуске привлекла внимание общественности, политиков и руководителей организаций к высоким рискам, связанным с использованием сложных вычислительных систем, что способствовало увеличению инвестирования в исследования, направленные на повышение надежности систем с особыми требованиями к безопасности. Последующий автоматический анализ кода Ariane (написан на Ada) стал первым случаем применения статического анализа в рамках крупного проекта с использованием методики абстрактной интерпретации.
Источники
- Отчет Ariane 501 — Presentation of Inquiry Board report
- Мэтт Тэллес, Юань Хсих — «Наука отладки»
- Class 25: Software Disasters
- Ariane 5 – Chronicle of a failure
- Мифы о безопасном ПО: уроки знаменитых катастроф
- Static Analysis and Verification of Aerospace Software by Abstract Interpretation
- ARIANE 5 — The Software Reliability Verification Process
- Safety in Software — now more important than ever
- ADA source code
Комментарии (94)

deniskreshikhin
16.08.2016 13:58+17Хм, если почитать статью, то ошибка у них была все-таки в системном проектировании и управлении качеством, а не в коде. Выход из строя какого-то модуля (программного или аппаратного) не должен приводить к отказу системы в целом. Ну и то что, исключение привело к отказу всей системы, говорит о том что тестирования влияния этого программного модуля в случае отказа на работоспособность всей системы в целом не проводилось

sebres
16.08.2016 16:31+2Хмм, в общем-то да, однако "выход из строя модуля не должен приводить к отказу системы в целом" тоже можно худо бедно програмно гарантировать:
-- Do_Some_Main_Thing -- -- function Do_Some_Main_Thing return ... is ... begin ... exception when Exception_1 | Exception_2 => -- возможные ожидаемые исключения ... when others => -- любые другие исключения (также анонимные) обрабатываются здесь Try_Recovery; end Do_Some_Main_Thing; -- Try_Recovery -- -- function Try_Recovery return ... is ... begin Notify_Engineer; -- неожиданное исключение ... ... -- пробуем чего-то-там восстановить, например exception when others => -- восстановить не удалось Notify_Engineer; Abandon_Call; raise Emergency_Program; end Try_Recovery;
Как правило в этом случае не критичные модули (как раз наш случай) либо уходят в "спячку" (если например реализовано event-driven) либо кидают уже ожидаемое исключение...
Грубо говоря если мне к примеру 10-й датчик высоты не сообщает текущее состояние, рассчитываем траекторию по средним значениям вычисляемым по другим параметрам для чрезвычайных ситуаций (emergency_program).
Соответственно три важных момента:
- в программе не должно быть блоков пробрасывающих неожиданное исключение наверх стека исполнения (от слова совсем);
- в идеале всегда должна быть соответствующая (или хотя бы какая-нибудь) реакция на исключение Emergency_Program;
- все модули должны быть оттестированы дополнительным бросанием неожиданного исключения (типа Test_Emergency_Unexpected_Error) из любой (т.е. каждой) функции.
А так-то да, неполное покрытие кода тестами — есть тикающая бомба замедленного действия. Таких программистов называют — подрывник...

AstarothAst
16.08.2016 16:34+3Насколько я понял в тех условиях, для которых программно-аппаратный комплекс создавался изначально, выход из строя этого модуля был невозможен, это было обосновано математически, и он сознательно не был защищен. Проблема возникла когда старая система была без тестирования перенесена в новое окружение, что и вызвало крах. Даже по нынешним временам со всеми паттернами, статанализами, и маниакальным защитным программированием, нет-нет, да что-нибудь грохнется при миграции, а это же были теплые и ламповые времнеа, когда каждый байт был на счету…

megazloj
16.08.2016 16:40Что-то мне кажется, что в космической индустрии и сейчас «теплые ламповые времена» и «каждый байт на счету»
AstarothAst
16.08.2016 16:55+1Но инструментарий все же побогаче.
megazloj
16.08.2016 17:06+2Однозначно, но все же к размеру кода относятся серьезно
AstarothAst
16.08.2016 17:10Я имел ввиду, что «тогда» возможности для тестирования всего и вся были куда более ограниченны, нежели сейчас, а так как и сейчас безбажная миграция/интеграция является скорее светлой мечтой, нежели обычным вторником, то говорить, что «тестирование влияния этого программного модуля в случае отказа на работоспособность всей системы в целом не проводилось», наверное, слишком самонадеянно. А может и не самонадеянно, черт его знает, кто там на чем решил сэкономить…
sebres
16.08.2016 16:43-2и он сознательно не был защищен
Глупость это и позерство...
а это же были теплые и ламповые времнеа, когда каждый байт был на счету…
Где? В ESA? На
спичкахтестовом покрытии экономить байты?AstarothAst
16.08.2016 16:55+5Глупость это и позерство...
В статье четко написано:
Основанием для такого решения была уверенность в том, что для этих трех переменных возникновение ситуации переполнения невозможно в принципе.
…
Уверенность эта была подкреплена расчетами, показывающими, что ...
Система писалась для условий, в которых защита данного кода была не нужна — по факту не нужна. В чем позерство и глупость? Задача решалась для определенных условий, и для них была решена. Проблемы возникли, когда систему стали использовать в условиях для нее не пригодных, что могло бы быть выявлено на стадии тестирования, но выявлено не было. Вот тут вот и глупость, и авось, и не профессионализм, и что угодно.sebres
16.08.2016 17:16-1Система писалась для условий, в которых защита данного кода была не нужна — по факту не нужна. В чем позерство и глупость? Задача решалась для определенных условий
А проверить эти условия? Хотя бы минимальный тест-кейс который Notify_Engineer или assert какой бросает,
нет, не слышал...
У нас с вами разный подход, ваш у системщиков называется "закладывать бомбы". Ибо читая по диагонали документацию, фразу "для определенных условий" можно тупо проглядеть, не понять правильно и т.д...
Тест же — он тест и есть — автоматически имеем BOOM на новых исходных параметрах (другая траектория, более высокая начальная скорость).
IMHO, косяк обоих. И разрабов модуля и конструктора его использующего...

5hr4M
16.08.2016 17:54+2В статье сказано, что это сознательный шаг, для снижение вычислительной нагрузки.
Просто пихать проверки на всё и вся — это паранойя :) Есть разумный баланс.
if ( cos(x) > 1 )…sebres
16.08.2016 18:56что это сознательный шаг, для снижение вычислительной нагрузки.
Testcases бегают в неурочное время, и хотя бы входящие параметры (ускорение, функции траекторий и т.д.) можно и нужно было покрыть.
Просто пихать проверки на всё и вся — это паранойя :) Есть разумный баланс.
Не в проектах стоимостью сотни мильенов вечнорастущих.
if ( cos(x) > 1 )…
Вот только не надо утрировать пжлста...

AndreyDmitriev
16.08.2016 19:45+1Ну на самом деле не всё так плохо в NASA, более того у них есть чему поучиться, даже несмотря на такую эпическую ошибку. Причём НАСА особо и не скрывает как ведётся разработка. Ну вот почитайте, к примеру NASA Software Safety Guidebook.
sebres
16.08.2016 20:07Всебы ничего, только это ESA ;)
И я не говорю, что все из вон рук плохо… Местами… Бывало… Да и сейчас еще...
AndreyDmitriev
16.08.2016 20:43Упс, а ведь я до сегодняшнего дня был уверен, что это был совместный проект, и НАСА там тоже руку приложило, собственно и в документе, что я выше ссылку дал, эта ракета упоминается. Спасибо за поправку.

BalinTomsk
17.08.2016 00:33+2НАСА сама делает ошибки похуже. Последний провал — метры в фунты забыли перевести.
Юнит тесты никто упорно не пишет

Lain_13
16.08.2016 20:43+3if ( cos(x) > 1 )…
Вот только не надо утрировать пжлста...
Вообще в случае с комплексными числами реально есть задача определить из чего может получиться косинус больше единицы. Так что и на такое можно наткнуться в каком-нибудь специализированном софте, поддерживающем работу с комплексными числами.
Не стоит забывать о том, что имелось требование выполнения кода в реальном времени. С современными процессорами мы, наверное, можем позволить себе обернуть в проверки буквально всё и вся, но у них железо этого не позволяло и время исполнения кода вылезало за жестко поставленные рамки. Пришлось пойти на компромисс, убрав проверки там, где значение просто не могло выйти за рамки, но условия эксплуатации изменились. Более того, весь этот модуль можно было вообще выключить сразу после запуска. Ошибка тут не в коде, а в том, что модуль был переиспользован как без надлежащего тестирования, так и без подгонки его под новые условия. Даже если бы его просто выключили после запуска за ненадобностью (а в новых условиях он реально не был нужен) всё пошло бы иначе и этой аварии не было бы.sebres
16.08.2016 21:32+1Не стоит забывать о том, что имелось требование выполнения кода в реальном времени.
Дык я не за то вовсе… На тестовом стенде — это очень редко обязательное условие… Это раз. Ну и два, начальные и пограничные условия использования модуля можно же проверить и не "в реальном времени".
Попытаюсь объяснить на пальцах:
Было (из вещей интересующих разраба):
- железка (модуль, контроллер и т.п.)
- дока, содержащая примеры кода (схемы, API, и т.п.)
В этом списке (по хорошему) отсутствует один пункт:
- test-cases (которые как минимум проверяют условия использования железки, т.е. те же траекторию, начальную скорость и т.д. и т.п.) Не путайте с real-time, т.е. чтобы "время исполнения кода не вылезало за жестко поставленные рамки"…
Т.е. его (тест) конечно же могли (и за отсутствием оного обязаны были) создать и ребята юзающие модуль, но…
Во первых IMHO — это не совсем комильфо…
Во вторых — для этого иногда нужно знать много больше, чем может потребоватся от юзаешего готовую железку...
Хотя как test-case обертка увеличивает время исполнения кода настолько, что он становится совсем неюзабелен — это то же нонсенс. Тогда получается что и API модуля нельзя использовать… чтобы значит "не вылезало за жестко поставленные рамки". Смысл в том модуле тогда?
Поэтому повторюсь: косяк обоих...
- у разрабов модуля нет тест-кейсов, как минимум проверяющих "условия использования"
- у разрабов, использующих готовый модуль, нет тест-кейсов, которые обязаны были словить как минимум это исключение на новых условиях (в реальном времени на тестовом стенде)...
Ну и сам "flow" немного странен, ибо как реагировать на неожиданные исключения
учат в школеесть азы изучения той же ada (и моветон забыть или наплевать на такое).
Принцип я коротко коментировал выше.
Lain_13
17.08.2016 03:31+1Возможно там были тест-кейсы, но код их успешно проходил так-как они специально не проверяли эту ошибку — по расчётам этого просто не могло быть! Тому, кто этот код писал, было прекрасно известно, что он выдаст ошибку на высоких скоростях, но их не должно было быть. И всё время, пока код использовался на проекте для которого он был разработан, проблемы не было. Смысл в том, что старый код переиспользовали на новом проекте без подгонки каких-либо тестов на любом этапе под параметры нового проекта. Я вообще сомневаюсь, что этот код кто-то трогал с тех пор. Классический такой легаси. Такое впечатление, что никто не удосужился собрать стенд и прогнать систему по симуляции запуска, подставляя на вход ожидаемые в реальном запуске параметры. А ведь в теории они должны были сделать как минимум это, причём ещё и не раз. Просто потому, что проблема всплыла бы на первой же симуляции.
deniskreshikhin
16.08.2016 17:42+2Не бывает такого что бы какой-то функциональный узел имел нулевую вероятность выхода из строя, поэтому сложно поверить что они это не учитывали.
Мне кажется ответ именно в том, что была неправильная обработка исключений на самом верхнем уровне. Т.е. даже если бы этот конкретный код работал корректно, не факт что некоторое другое исключение точно также не убило бы ракету.Lain_13
16.08.2016 21:01Если б этот модуль хоть кто-то удосужился бы протестировать с новыми входными данными это бы всплыло и было так или иначе исправлено. В том-то и дело, что с новыми данными этот модуль никто не тестировал в принципе и не важно хочется в это верить или нет, факт остаётся фактом — это было бы исправлено если бы хоть раз было проверено в новых условиях эксплуатации.

Portnov
16.08.2016 20:20ошибка у них была все-таки в системном проектировании и управлении качеством, а не в коде.
Не совсем так. Ошибка в коде, конечно, была (плохая обработка исключительной ситуации — это ошибка). Другое дело, что при современных подходах к коммерческой разработке ПО ошибки в коде принято рассматривать не как ОШИБКИ, а как допуски. Ну вот токарный станок делает шайбы с допуском в 0.1мм, а иногда получаются с допуском в 0.2мм — это никого не смущает, просто есть контроль качества и плохие шайбы выкидывают или допиливают напильником. Так же и с ошибками в коде: ну ладно, забыл программист на null проверить, подумаешь. Тестировщики нашли, программист поправил, продукт зарелизили, все довольны. Вот если тестировщики не нашли — вот это уже проблема: это значит что либо плохо тестировали, либо плохо объяснили тестировщикам требования, против которых надо тестировать, либо изначально требования не так сформулировали… короче да, с точки зрения современной софтверной индустрии — проблема в процессе / управлении качеством.
А вот какие подходы к управлению разработкой / управлению качеством в космической отрасли, тем более какими они были в бородатом 1996 — я не знаю; допускаю, что по меркам современной софтверной индустрии подходы дедовские, т.к. отрасль скорее всего очень консервативная. Если там, как в древнем софтостроении (или как в мелких стартапах сегодня) — «тестировщики? какие тестировщики?» — то ответственность за соответствие софта требованиям лежит только на программистах, т.к. больше просто не на ком.deniskreshikhin
16.08.2016 20:48Такие сложные системы проектируются по нисходящей (т.н. водопад). Т.е. изначально закладывается некоторая вероятность успешного запуска, допустим
1 - 1E-20. Т.к. обычно ни одно устройство такую надежность не имеет, то системные инженеры решают эту проблему путем дублирования, т.к. если некоторая цепь должна иметь надежность1 - 1E-20, то при дублировании уже достаточно~1 - 1E-10что вполне реализуемо. Соответственно разработчики конкретной цепи, модуля, функционального узла и т.д. должны укладываться в отведенный для них запас надежности.
То что выход одной подсистемы из строя повлек за собой автоматический выход из строя и дублирующей говорит о нарушении принципов проектирования и оценки надежности всей системы.


Wicron
16.08.2016 16:08+2Всё нормально, угробили кучу денег, допустив просчет в архитектуре, чтобы дали ещё.

TheShock
16.08.2016 16:09+10Однако, модуль повторно использовался без каких-либо модификаций.
Вот тебе и следствие идеологии «Работает — не трогай».sebres
16.08.2016 16:38+2Дык не столько плохо, что он использовался, сколько то, что не было common-теста в новой связке и с новыми исходными (другая траектория, более высокая начальная скорость)...
Детская ошибка-то, ей богу.
Varkus
16.08.2016 16:34-1Думаю пока ИИ не возьмётся за создание вычислительных систем, так и будут ошибки-аварии — человеческий фактор, в общем.
Никогда не понимал, как можно экономить на гвоздях в таких проектах, просто тупо перетаскивая модули из одной версии в другую.
Да как так вообще, из-за «васи пупкина», который обломился сверить ТТХ старой и новой платформы происходит «такое».
Кстати, не исключен вариант саботажа, т.е. эти спутники в принципе не должны были попасть на орбиту по 100500 причинам: экономические(выбить еще денег на следующий такой проект + увеличить бюджет на безопасность), политические(nocomment) и прочие.
firewind1
17.08.2016 14:06ИИ не устает, у ИИ нет рассеянности внимания, как у живого человека. Но почему Вы уверены, что все же ИИ не будет допускать ошибок из-за неправильно заложенных параметров при его создании?
Varkus
19.08.2016 14:48Потому что перед вводом в эксплуатацию ИИ можно прогнать через тесты со всеми мыслимыми и немыслимыми параметрами, да это время, да это деньги, но оно того стоит.
sbnur
16.08.2016 16:34Кажется этому почти не учат — анализу ошибок среды, то есть исполнению отлаженного кода в новой для него программно-технической среды.
Статья напомнила более печальные обстоятельства на Саяно-Шушенской станции, где система контроля не смогла отследить выход турбины в запредельные режимы и не закрыло задвижки, которые пришлось закрывать вручную.
Как сказал руководитель разработки системы контроля (воспроизвожу по памяти) — датчики вышли из строя и контроль прекратился.
При правильной работе автоматики последствия могли быть не такими катастрофичными
sim31r
16.08.2016 17:13Причина аварии там не в автоматике, не в программных ошибках
Было потеряно электропитание собственных нужд станции, в результате чего сброс аварийно-ремонтных затворов на водоприёмниках (с целью остановки поступления воды) персоналу станции пришлось производить вручную
Нужно было предусмотреть аварийное электроснабжение. Это хоть и электростанция, но иногда она превращается в потребителя, у которой каждый Ватт энергии на вес золота.
То же самое на Фукусиме
В момент землетрясения три работающих энергоблока были остановлены действием системы аварийной защиты, которая сработала в штатном режиме. Однако спустя час было прервано электроснабжение (в том числе и от резервных дизельных электростанций), предположительно из-за последовавшего за землетрясением цунами.
Электроснабжение необходимо для отвода остаточного тепловыделения реакторов, которое, согласно формуле Вэя — Вагнера, в первые секунды составляет около 6,5 % от уровня мощности до остановки, через час — примерно 1,4 %, через год — 0,023 %
…
С этого момента работа на площадке АЭС была сфокусирована на решении проблемы электроснабжения аварийных систем, для чего на станцию решили доставлять мобильные силовые установки
Наверное какой-то шаблон мышления, зачем электростанции внешнее питание? И не делают его, или формально к вопросу подходят.
Кажется этому почти не учат — анализу ошибок среды, то есть исполнению отлаженного кода в новой для него программно-технической среды.
Можно подумать где-то учат обратному — скпопиастил чужой год, вроде работает. Именно за это и ругают фреймворки с низким порогом вхождения. Человек имитирует труд профессионала, пока не натыкается на чреду глюков и не может разобраться с ними.mayorovp
16.08.2016 17:21Конкретно на Саяно-Шушенской с аварийным электроснабжением все было хорошо — ведь ЛЭП могут работать в обе стороны, такова их природа.
Автоматика не сработала просто потому что ее залило водой.
sbnur
16.08.2016 18:00Автоматика не сработала при выходе турбины на запредельный режим, и водой все залило именно из-за этого (вода пошла, когда турбину вырвало — что же в это время делала автоматика)
Кстати аварийное питание непричем — когда автоматика вырубилась, то задвижки можно было закрыть только сверху
MacIn
16.08.2016 17:34Нужно было предусмотреть аварийное электроснабжение. Это хоть и электростанция, но иногда она превращается в потребителя, у которой каждый Ватт энергии на вес золота.
Почти наверняка это есть. На наших АЭС есть аварийное питание «извне», здесь, на ГЭС тоже должно быть. Скорее, отключилось что-то в промежутке из-за воды.MasterDan
17.08.2016 14:03+1На АЭС тоже случаются факапы, коллега АСУшник с Кольской рассказывал, что в начале двухтысячных они из-за каскадного отключения потеряли всё питание для собственных нужд и реактор сутки расхолаживался внутренней циркуляцией воды, выдержал, проверили на практике надёжность пассивной защиты. После этого отключили от энергосистемы пару местных мелких ГЭС и подключили напрямую к АЭС.

4ebriking
16.08.2016 16:34ещё одной системной ошибкой было использование идентичных парных модулей — которые в одинаковых условиях и накрываются одинаково, что и произошло. с тех пор дублирующие системы. напр. в авиации — принципиально различны
megazloj
16.08.2016 16:42+1Можно тут по-подробнее? Разве в том же Boeing 737 навигационные системы и автопилот (1 и 2) по-разному работают?
4ebriking
16.08.2016 17:17+2Да, по-разному — от входных сигналов от датчиков и вплоть до исполнительных на мажорирующий элемент — полностью разные системы с разными хардом, логикой работы и софтом — всё разных производителей.
Навскидку нашлась примерно такая цитата:
«The Airbus and Boeing FBW computers design considerations for generic errors… The ELAC is produced by Thomson-CSF using Motorola 68010 processor, and the SEC is produced by SFENA/Aerospatiale using Intel 80186 processor»… Пробегало, что софт под них пишут тоже разные команды и категорически запрещён не только переход программистов из одной в другую, но даже неформальное общение (что бы не словить багу одинакового неправильного понимания какого-нибудь общего принципа)
Dimmov21
16.08.2016 16:34+6Чтобы штурмовать небеса, нужно хорошо знать язык Ада.
Спасибо за статью, хорошее настроение теперь обеспечено на весь оставшийся день.

VM390
16.08.2016 16:39Отличная исчерпывающая статья о проблеме в крупном проекте. Зря намекает Денис Решихин на ошибки в системном проектировании дизайна проекта. Конечно, никаких ошибок в дизайне изначально не было. Таких «детских просчетов» наши разработчики не допускают с печального старта в 1974 году, да и «у них» то-же. Всему виной дополнительным требования по загрузке компьютера на уровне 80% по мощности (хотя 100% загрузка бортового компьютера РН Ариан, в принципе тоже норма), из-за которых пришлось вводить ограничения на проверку параметров в коде. Плюс, грубая ошибка в использовании принципа «повторноиспользуемости кода», при отсутствии тестирования интеграции в условиях новых входных данных.
Анализ кода в этом случае ничего не даст. Ребята просто попытались «сэкономить деньги» на этапе тестирования, а не вышло.lingvo
16.08.2016 20:21+2Загрузка бортового компьютера, работающего в реальном времени на 100% — это очень плохая штука. Даже 80% — это очень много. Например у нас, в контроллерах, которые контролируют сотни мегаватт мощности, загрузка ядра процессора, имполняющего код в реальном времени не превышает 60%, а клиенты требуют вообще, чтобы было менее 50%.
VM390
17.08.2016 16:07+1Просто Вы не в курсе, что кроме Intel существуют другие аппаратные архитектуры, где загрузка почти 100% — это НОРМА, не приводящая к проблемам в эксплуатации. А Ваши клиенты правильно требуют снижения нагрузки на Intel-архитектуру, которая в большинстве случаев не должна превышать 35%, если речь идет о какой-то надежности.
MacIn
17.08.2016 17:56+2А Ваши клиенты правильно требуют снижения нагрузки на Intel-архитектуру, которая в большинстве случаев не должна превышать 35%, если речь идет о какой-то надежности.
Хе-хе, а о какой именно из Intel архитектур идет речь?VM390
18.08.2016 03:19Поймали на неточности определений. Речь идет о стандартной архитектуре компьютера х86 (IBM PC). Архитектура х86 весьма проста и незамысловата, где главная проблема и тормоз — общая шина и соответственно неудовлетворительный IO, которым, грубо говоря, управляет — CPU.
lingvo
18.08.2016 17:07+2Вы, похоже не понимаете, о чем я.
В системах реального времени одна и та же задача запускается циклически, например каждые 100мкс. Естественно, она должна выполниться за это время или быстрее. Загрузка процессора в этом случае определяется отношением времени фактического выполнения задачи к общему времени цикла. Т.е. если задача выполнится за 45µs, имеем 45% загрузки процессора. Оставшееся время обычно благодаря преемптивности отдается задачам низшего приоритета, или под non-realtime задачам.
Теперь предположим, что у вас есть задача, состоящая из куска кода АДА в статье. Рассмотрим ее с точки зрения зависимости времени выполнения этого куска кода от исходных данных.
Вы легко можете заметить, что если переменная L_M_BV_32 будет больше 32767, то в операции if присвоение произойдет после первого сравнения и программа пойдет дальше. Следующее сравнение elseif с -32676, а также операция после Else не будет выполнены вообще. Следовательно в этом случае общее время выполнения данного куска кода будет минимально.
Отлично. Мы посчитали загрузку проца, выполняя данный код с такими данными, а затем выбрали процессор, чтобы загрузка была почти 100%. И что мы имеем? В один прекрасный момент у нас другие исходные данные и в if не выполняется первое условие, не выполняется второе и мы заканчиваем в else, выполнив одно лишнее сравнение, да еще и функцию приведения вдобавок. В результате время, затраченное на выполнение этого куска кода будет в почти в два раза выше, чем мы рассчитывали. При 100%-ной оригинальной загрузке процессора, это приведет к Task Overrun — очень плохому эффекту и прощай реалтайм.
Это я к тому, что отследить и поймать самое длительное время выполнения задачи, даже прогнав ее со всеми возможными вариантами входных данных, не всегда представляется возможным, если у вас сотни тысяч строк кода и время выполнения еще зависит и от внутреннего состояния. Поэтому 100% загрузка процессора в real-time — это fail.VM390
18.08.2016 19:58+2Мне кажется, что это Вы неправильно поняли меня. Когда я говорю о загрузке процессора, я конечно имею ввиду загрузку компьютера, где кроме CPU есть оборудование которое влияет на общую загрузку компьютера, Можно подобрать некоторое кол-во задач, которое может привести к серьезной загрузки именно CPU — но это большая редкость, особенно для х86. При разнородных задачах загрузка х86 свыше 35% — это беда, дело не в CPU, дело в арбитраже шины, в IO, контроллерах и в более медленной памяти, наконец. А с учетом того, что именно CPU обрабатывает «медленные» запросы на IO, приводит к тому, что х86 обычно не используется в критических системах в ракетной, авиационной технике, на электростанциях, заводах по обогащению урана и т.д., во всяком случае у «них».
А «100%» не может быть бедой в архитектурах «без общей шины», (хотя в реальных системах уровень держат на уровне 80%), тк задачи в РВ имеют сложную систему приоритетов и безопасности, (не хочу вдаваться глубоко в суть архитектуры) и конечно «основная задача» выполняется с высоким уровнем и если ей будет не хватать ресурсов — то замедлится исполнение задач с низкими приоритетами (обычно, такая ситуация не возникает!)lingvo
18.08.2016 23:08+1Мда, далеко вы от реалтайма ушли.
Во первых смею заметить, что во встраиваемых системах задачи известны заранее. Также известны и характеристики железа — например частота выбоки АЦП или битность данных. Поэтому такой параметр, как загрузка периферии теряет смысл — конечно она загружена на 100%. Если какая нибудь шина I2C может работать на 1МГц, она будет работать на 1МГц. А если АЦП может выдавать данные на 200MSps, зачем сне его тактировать на 100MSPs? Если я так буду делать, значит выбор АЦП не правильный.VM390
19.08.2016 16:28+2Странно, Вы вроде бы с турбинами работаете с критическими приложениями, а так поверхностно подходите к пониманию загрузки компьютера. Может быть у Вас на каждый АЦП отдельно РС-шка стоит (гротеск!), тогда Вам меня не понять. Я говорю о бортовых системах, которые должны надежно исполнять несколько критических приложений параллельно, при этом гарантированно исполнять свою задачу. Чтобы исключить дальнейшие споры, я опишу несколько преимуществ бортовых вычислителей:
* CPU вообще не занимается операциями ввода-вывода (поэтому и может работать при 100% загрузке), соответственно не нормируется и спокойно расширяется линейка устройств ввода-вывода, которая может быть добавлена в систему без upgrade центральных процессоров (Телеметрия, Логи, АЦП, спецустройства, ...) Таким образом гарантируется высочайшая пропускная способность бортовой вычислительной системы.
* Отсутствуют накладные расходы ОС на переключение контекста процессора, более того, если кол-во задач не превышает 32, то переключение контекста отсутствует полностью.
* Реализация части функций ОС — аппаратурой
Есть масса других особенностей, выгодно отличающихся от архитектуры х86 в части надежности и безопасности. Подобные вычислители работают со времен Space Shuttle и Бурана и отлично работают.

Jef239
18.08.2016 19:41+2Требование загрузки в 80% — это требование резерва мощности CPU на случай, если какой-то модуль потребует больше вычислений. Дело не в архитектуре, а в том, что заранее предусматривается, что может быть проблема, из-за которой некий модуль жрать CPU. А доказать, что таких ситуаций быть не может — сложнее, чем оставить резерв.
sim31r
16.08.2016 16:40Интересна форма бортовых компьютеров, чистая функциональность без всяких графических интерфейсов, лампочек, кнопочек. Круглые разъемы напоминают чем-то советскую технику. И применены разъемы DB-9 (как в COM портах) без всяких заморочек, как простые и надежные. Правда позолоченные, не бытовой вариант.

maisvendoo
16.08.2016 23:42+2Советская / не советская тут не причем. Есть определенные требования к разъемным соединениям по условиям работы (в данном случае наверняка виброустойчивость, герметичность и т.д.) Спроектированные в соответствии с заданными требованиями разъем будет выглядеть примерно одинакова в не зависимости от страны и её технологических традиций.
Похожие круглые разъемы используются на современных российских электровозах, в частности сам подключал во время испытаний чем-то похожим БВД-У на 2ЭС4К
vadimr
16.08.2016 17:11+1Сам изначальный подход неправильный. Даже если траектория ракеты Ариан 4 такова, что углы не могут принимать некорректных значений, то всегда может отказать датчик углов или связь с ним, и получиться белиберда. Если уж хотелось сэкономить процессорное время, то надо было просто блокировать исключительную ситуацию по переполнению, благо, язык Ада это позволяет.

DenimTornado
16.08.2016 17:22Кого-то зашибло обломками? Если нет, то всё-таки не «На следующий день после катастрофы», а «На следующий день после АВАРИИ».

3draven
16.08.2016 18:51-4Я когда писал для платежной систем одной проксю для переноса платежей в другую систему, тоже шибко боялся ошибиться :) В день налички мешок собирался в каждой точке и легко можно было пролететь отдав клиенту миллион вместо тысячи. Причем у наших конкурентов ошибка возникла и к терминалам оплаты их фирмы выстроились очереди из «прочухавших» клиентов. Как потом программиста пытали, могу только догадываться. Причем заказчикам даже в таком деле все равно надо «что бы все было готово ВНЕЗАПНО!»… идиоты не догадывались, что одна ошибочка и они потеряют миллионы. Потому, я немного подзаработав балгополучно свалил.
theemfs
16.08.2016 20:50а что за платёжная система?
3draven
16.08.2016 20:55Так я и сказал :) При мне там косяков не было, после меня не знаю. Это было еще в начале двухтысячных, когда все только начиналось. Сейчас там наверное штат в сто человек и тестирование по полгода :) Что до конкурентов, то конкуренты были… тоже не скажу кто, но их сегодня все знают.

perfect_genius
16.08.2016 19:53Взрыв произошёл ведь «умышленный», защитный? Т.е. автоматика уничтожила ракету?

Dolios
16.08.2016 19:56Основной подрядчик — европейская компания Airbus Defence and Space («Эрбас дифенз энд спейс»; подразделение Airbus Group, «Эрбас груп», Париж).
Airbus Group до недавнего времени называлась EADS. И в описываемые времена ни той ни другой не существовало.
old_bear
16.08.2016 20:22Объясните мне глупому одну простую штуку.
Что мешало прогнать это самое моделирование работы системы с заранее известными параметрами выхода на орбиту ДО того, как запускать ракету?Varkus
16.08.2016 21:12+1Очень верный вопрос, я тоже в недоумении: ведь технари заранее знали приблизительные параметры полёта, а значит они были бы добавлены в «эмулятор» внешних данных для компьютера ракеты, а он бы уже на тестах вышел в exception.
Тем более параметры бокового движения платформы были превышены в 5!!! раз, а не на какую-то там погрешность.
Я свои функции тестирую не только на неверные входные данные(вместо ожидаемых данных сыплю в них «мусор»), но и на количество переменных переданных при вызове, мало ли что.
«Тестер» был написан лишь однажды, теперь только подкручиваю шаблон валидных выходных данных и «натравливаю» его на нужную функцию, а он уже сам с ней по всякому развлекается. Мне остаётся лишь смотреть логи эксепшенов.
Такой подход ой как не раз спасал.old_bear
16.08.2016 21:37+1Думаю, что параметры конкретно этого пуска знали довольно точно. :)
Я понимаю, что написать симулятор данных с датчиков не самая простая задача. Я понимаю, что в 1996 году возможности компьютеров были существенно скромнее. Но блин, не прогнать симуляцию для первого (!) пуска ракеты стоимостью 100500 мильёнов (с) — это просто за гранью в моём скромном понимании.
P.S. Тоже активно использую unit test-ы.sim31r
16.08.2016 21:50Справедливости ради цена не 100500, а минимальная, чуть выше стоимости ракеты, можно считать тестовым запуском с недорогим, сравнительно, спутником.
Дорогой провал вот, цена ошибки почти 7 миллиардов, в 20(!) раз больше, может спутник еще доберется (но не факт): из последних сил на орбитуold_bear
16.08.2016 22:02Ну всё же вряд ли ракета была настолько бесплатна по сравнению со стоимостью какого-то количества человеко-месяцев программистов и какого-то количества машино-дней подходящей вычислительной системы.
Впрочем, я системы такой сложности не проектировал и могу недооценивать сложность её тестирования.
4ebriking
17.08.2016 08:47+1При первом запуске «Энергии» ситуация была очень похожа, отделались тем, что накрылась не вся ракета, а только спутник (100-тонный аппарат, хоть и спрятанный по псевдоним «габаритно-массовый макет». Один из основателей «тихоокеанской группировки спутников») — гуглить «перевертон», лучше сразу на «Буран.ру».
Jesus05
17.08.2016 14:06Может у меня какой-то другой гугл, но гугление чисто «перевертон» дало много совсем не того. (нужное нашел но по запросу «перевертон спутник»)
4ebriking
17.08.2016 17:45Да, к гуглу голову.sys часто надо применять, есть такое дело.
http://www.google.ru/search?q=%D0%BF%D0%B5%D1%80%D0%B5%D0%B2%D0%B5%D1%80%D1%82%D0%BE%D0%BD+site%3Aburan.ru
justhabrauser
16.08.2016 22:46-1Попробую, например.
Вы хотите получить прогнать _все_ возможные варианты событий при воздействии _всех_ случайных факторов (как внутренних, так и внешних) в любом мыслимом и немыслимом диапазоне — и получить на выходе 100%-ную вероятность успеха?
Предлагаю Вам оценить вероятность прихода завтра на работу и возвращения домой живым и невредимым с точностью 5%. С учетом всех возможных и невозможных помех (начиная от бокового ветра, заканчивая внезапной сменой правительства).
Потом добавьте туда то, что Вы передвигаетесь на Формула-1 в Бангладеше на максимальной (для вашего автомобиля) скорости.
Что там Ваше численное моделирование показало, ну-ка, ну-ка?..sim31r
16.08.2016 23:52вероятность прихода завтра на работу и возвращения домой живым и невредимым с точностью 5%
Вероятность смерти 0.1% в год, для среднего возраста. В год для оценки риска 5% вероятность 1:50, в день 1:18250.
передвигаетесь на Формула-1 в Бангладеше на максимальной (для вашего автомобиля) скорости
1:1? Не надо нарушать ПДД, это опасно.
Varkus
17.08.2016 13:48-5В цифровой технике проще: ниже нулей и единиц опускаться смысла нет. А 0 и 1 это и есть все мыслимые и не мыслимые комбинации, которые можно подать на вход функции, остаётся варьировать их длиной и последовательностью.
Разве что не забывать проверять тип данных: int, bool, string, char, vector, real, double и т.д., дабы избежать сюрпризов с преобразованием. Хотя в начале функции можно любой тип приводить к нужному, далее смотреть валидность этих данных, а затем с ними работать.
В моей интерпретации не возможно просчитать, по моему, всего 2 момента:
— физическое разрушение области памяти(хотя ничего не мешает даже аппаратно контролировать её целостность)
— когда другая функция получает в распоряжение память исходной функции.
< Что там Ваше численное моделирование показало, ну-ка, ну-ка?..
Думаю такая компания как Гугл(или IBM со своим Watson) уже давно «сканируют» всю историю человечества на предмет все возможных вариантов продолжения ситуации при схожих условиях.
Когда-то думали, что компьютеры не смогут «нормально» играть шахматы, затем «пал» Го и т.д.
— Siri, какова вероятность, что я вечером вернусь домой целым?
— Анализирую:
> статистику преступлений на пути Вашего маршрута дом-работа
> статистику аварийности на данном участке дороги
> техсостояние автомобиля
> техсостояние автомобилей в вашем городе, чьи данные доступны
> Вашу медкарту
> медкарты жителей города
> погодные условия
> количество метеоритов и комет в околоземном пространстве
> политическую ситуацию в стране и мире
> техсостояние самолётов, что будут в небе над вашим маршрутом и офисом
> короч, еще 100500 млярдов данных
и мой ответ…
42
Кстати в каком-то городе в США уже активно и успешно тестируют систему предсказаний мест преступлений!
И это работает, как Вам такой анализ?sebres
17.08.2016 14:07+4В цифровой технике проще: ниже нулей и единиц опускаться смысла нет. А 0 и 1 это и есть все мыслимые и не мыслимые комбинации
Да ну? Все оказывается так просто… А мы то дурни мучаемся!

grossws
19.08.2016 04:28Кто-то недавно задвигал про то, что за счёт конечности памяти можно рассматривать программу + память как конечный автомат, посчитать все возможные исходы и просто решить задачу останова (на конечной памяти). Осталось представить пространство состояний и возможных переходов xD
Varkus
19.08.2016 14:55-1Судя по минусам моего комментария выше — вариант просчитать все возможные комбинации это в принципе не посильная задача для вычислительных систем, вот минусующие и мучаются.
Хоть бы еще кто, кроме sebres, озвучил, что с моим мнением не так.lingvo
19.08.2016 18:06Вы забываете, что ваш анализ не включает в себя состояние системы, которую вы анализируете. Т.е. одной последовательности единиц и нулей на входе недостаточно — один раз вы подали 1,3,8, а в другой раз 8,1,3 и в результате ваша система будет иметь совершенно разные состояния, и подача следующего воздействия будет иметь совершенно разный результат. Даже время воздействия имеет смысл.
Поэтому прогнать все варианты физически невозможно даже для Ариан 5( не забываем, что дело было в 1996 году).Varkus
19.08.2016 21:35-2Спасибо большое за разъяснение, не сарказм.
Но я по прежнему с Вами не соглашусь, когда на вход системы вместе с валидными данными сыпется мусор, в конечном счете через систему пройдут все возможные вариации событий.
Да их число огромно, да это займёт ооочень много времени если бортПК медленный, но учитывая стоимость программы, оно того стоит.
Да и потом, сколько таких случаев после 96 года было?
— марсоход(не помню какой, ссылки не нашёл), женщина-программист, перед «паковкой» этого марсохода в ракету забыла затереть флэш память данных нулями, произошёл сбой программы уже на марсе, кое-как чудом оживили.
— здесь была статья про спутник, перед отправкой которого забыли отключить «писать отладку на флэш», в итоге когда место закончилось спутник затих.
И при нынешнем подходе такие истории еще впереди, а жаль.

ophermit
16.08.2016 23:10[Dan Simmons mode]
Не иначе, как происки ИскИнов. Теперь будет принято однозначное решение, дабы исключить «человеческий фактор».
[/Dan Simmons mode].
P.S.
Чтобы штурмовать небеса, нужно хорошо знать язык Ада.
Как ни крути. Спасибо за отличную статью, и за шикарную цитату, конечно!
movEAX
17.08.2016 00:15Этот случай с Ariane 5 упоминается кстати в одной интересной статье: overused code reuse
dmitry_ch
17.08.2016 16:07Я-то подумал, что софт РН прогнали через PVS, и нашли еще больше багов, чем ставшие причиной подрыва ракеты. Нет, увы, надежда не сбылась :)
А от PVS не ожидал обзоров ради обзора. Пост отличный, спору нет, но и ситуация не раз описывалась, и случай довольно старый.


Nick_Shl
17.08.2016 21:05+2Ракета, спутники… все это железо. Ошибка в Therac 25 куда опаснее и интереснее.

megazloj
Спасибо за статью