Сейчас есть много сервисов, которые позволяют извлекать некоторую информацию из текстов, например именованные сущности, такие как имена людей, названия организаций, названия мест, даты, что позволяет решать некоторые интересные задачи. Но намного больше интересных задач остается за скобками.
Что если нужны названия товаров, причем не всех, а каких-то определенных? Или мы хотим интерпретировать команды для мобильного приложения? Разделить адрес на название улицы, дома, города? Как насчет выделить важные факты из обращения клиента в службу поддержки: «Я возмущен качеством обслуживания в вашей компании. Не так давно, я заказывал ноутбук, но менеджер разговаривал некорректно и сказал, что товар закончился». Сегодня я расскажу о новом сервисе позволяющим решать широкий круг задач извлечения информации из текста. Этот сервис мы только что открыли для публичного доступа.
Что нужно для работы примеров из этой статьи: В статье в основном рассмотрено решение для .NET Framework на С#. Подойдет также любой язык для .NET Framework или mono. Из других языков обратится к web-API тоже можно, но готовых библиотек пока нет, поэтому код запросов придется писать вручную. Это не сложно, но здесь я пока не буду объяснять подробно как это сделать, чтобы не потерять главную мысль. Понадобится также доступ в Интернет и открытый порт 8080. Еще нужно будет зарегистрироваться, чтобы получить бесплатный ключ. Кажется, в основном все.
Как организована эта статья: Вначале объясняется задача, на примере которой будет показана работа API. Далее приводится код. Потом рассказано немного теории, как работает система изнутри, и в конце рассказано о ограничениях текущей версии, и том, в каких случаях эта система будет полезной, а когда нет.
Разбираем задачу: В качестве примера, возьмем задачу извлечения названий товаров из текста. Т.е. «Купить лазерный принтер Canon I-SENSIS i6500 в магазине товаров для офиса». Найти упоминания товаров бывает нужно для анализа информации о товарах и ценах в интернете, или системы, показывающей товарные объявления на основании содержимого страницы. Ну и для разных других целей.
Может показаться, что задача простая и решить ее ничего не стоит. Например, для некоторых групп товаров, особенно с английскими названиями можно попробовать написать регулярные выражения, выделяющие названия товаров из текста. Но такой метод не позволит отличить, например «Купить HTC One” (модель телефона) от „телефоны Samsung Apple Nokia” (просто перечисление производителей), что нередко встречается. Совсем не помогут регулярные выражения, если нужны товары, которые называются по русски, например «продается холодильник атлант 500» — совершенно не ясно, где начинается название.
Поэтому мы попробуем научить компьютер отличать название товара от прочего текста на основании некоторого количества примеров. Основным плюсом этого подхода является то, что не придется самим придумывать алгоритм, а минусом — необходимость вручную создать примеры для обучения.
Как должны выглядеть примеры? Допустим у нас есть такое предложение: «Купить Samsung Galaxy S4 в магазине «Наши телефоны». Разделим его на отдельные слова, и представим в виде колонки. Затем, напротив названий товаров напишем слово “Product”:
Таким образом, мы сформулировали задачу — определить является ли слово частью названия товара, или нет. После обучения на примерах мы сможем просто подать на вход модели текст в виде левой колонки и получить на выходе правую колонку. Кажется, что все достаточно просто.
На практике главная сложность — разметить вручную достаточное количество примеров для обучения. Чем больше примеров — тем лучше будет работать модель. Закономерный вопрос — а сколько примеров „достаточно много“? Все зависит от задачи — чем сложнее задача, тем больше нужно данных. В целом, обычно требуется от 400 до 4000 примеров вхождения нужного элемента. Что касается затрат времени, то по нашему опыту, трех дней работы по аннотации примеров в ряде случаем достаточно для целей создания работоспособного прототипа, хотя в более сложных ситуациях это время может существенно возрасти.
Для этой статьи мы приготовили уже размеченный учебный набор здесь. Учебный набор в данном случае создан из заголовков веб-страниц, поэтому полученная модель будет хорошо работать именно с заголовками. Позже я объясню, как можно улучшить качество распознавания в других текстах, но пока сосредоточимся на основной идее.
Весь набор данных нужно разделить на две части — train – на этой части будет обучаться модель, и test – на этой части будет проверятся результат работы алгоритма (в нашем учебном наборе уже есть два файла). Оба файла есть в комплекте, и их можно открыть Блокнотом или другим текстовым редактором, чтобы посмотреть структуру.
Далее нужно зарегистрироваться, что позволит получить бесплатный API ключ, и загрузить библиотеку функций (некоторые браузеры могут запросить подтверждение, т.к. архив содержит dll библиотеку). Для C# необходимо будет создать консольное приложение и подключить к проекту Meanotek.NeuText.Cloud.dll
Теперь пишем программу. Сначала создаем новую модель, дав ей при этом имя. Имя должно быть уникальным среди всех ваших моделей, потому что по нему модель будет впоследствии идентифицироваться и содержать только латинские буквы и цифры:
Далее загружаем данные и ставим модель в очередь задач:
TrainModel() приостанавливает программу до окончания обучения. Вообще это необязательно (т. к. может занимать 10-20 минут) и программа может заниматься в это время другими делами и просто проверять статус процесса обучения. Чтобы не останавливать программу, можно использовать метод TrainModelAsync(). Если в процессе работы TrainModel() программу закроют, или произойдет ошибка соединения с сетью, то на сервере модель все равно создаться, т. к. сама программа ставит модель в очередь и ничего кроме ожидания в это время не делает. При следующем запуске программы состояние модели можно будет проверить функцией Model.GetStatus().
После того как обучение закончено, мы можем вывести на экран результаты проверки по тестовой выборке:
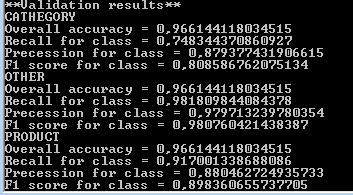
Для каждого вида извлекаемых выражений (категория, продукт) вычисляется ряд значений, характеризующих качество работы системы. Recall – это отношение числа выражений (например названий товаров), найденных алгоритмом к общему числу выражений, найденных человеком. Precession – доля правильно найденных выражений среди всех обнаруженных. F1 – собирательный критерий качества работы алгоритма, который объединяет precession и recall вместе. Чем эта величина ближе к 1.0, тем лучше. Я не буду здесь подробнее объяснять смысл всех этих метрик, а интересующемуся читателю предлагаю прочитать эту статью, где, на мой взгляд, все рассмотрено хорошо и детально.
Отмечу только, для сравнения, что широко используемый метод условно-случайных полей (Conditional random fields) с признаками в виде слов и биграмм в окне из 5 слов, дает на этой выборке F1 по названиям товаров 86.2, а по категориям — 79.5.
Теперь попробуем подать на вход новый пример:
Теория (и философия): Проблема извлечения различных выражений из текста имеет длинную историю, и для ее решения существует много специальных инструментов. Но нам хотелось сделать очень простое для использования решение, которое не требовало бы серьезных специальных навыков, обходилось без ручной настройки, работало на относительно небольших выборках и при этом годилось бы для широкого круга задач. Тогда создание новых моделей извлечения данных из текста, а, следовательно, и новых приложений, стало бы доступно для индивидуальных разработчиков и небольших компаний, которые смогли бы сами определять, какие аналитические средства требуются их бизнесу.
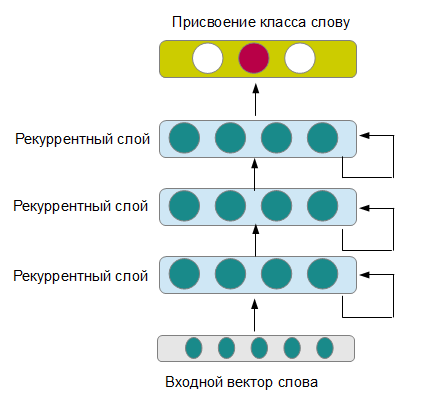
Для этого требовалось прежде всего избавится от ручного подбора признаков, грамматических анализаторов и всевозможных словарей терминов, подбираемых под конкретные задачи, не потеряв сильно в качестве. Одна из моделей, которая позволяет это сделать — глубокие рекуррентные нейронные сети (см рисунок). Рекуррентная сеть последовательно получает на вход новые слова из предложения, при этом сохраняя память о предыдущих состояниях. На выходе нейронная сеть выдает класс, к которому принадлежит данное слово. Несколько последовательных слоев формируют все более абстрактные понимания предложения, работая на разных временных диапазонах (правда, это происходит, если все настроено правильно, иначе можно получить просто сильно переобученную нейронную сеть).
Из исследований известно, что такая модель может извлекать сложные выражения из английских текстов, в том числе делать разметку семантических ролей и анализ тональности. При этом результаты не уступают, а часто даже превосходят показатели всех других известных методов. Правда, каждая работа использовала свою несколько отличающуюся архитектуру, и оптимальные параметры отличались для разных задач.
Поэтому мы провели большую работу, проверив несколько десятков различных моделей на 18 тестовых коллекциях английских и русских текстов, в результате чего удалось найти наиболее оптимальную модель нейронной сети и способ представления входных слов, так чтобы результаты были высокими на разнообразных задачах.
Правда в итоге, модель, выбранная для API является компромиссом между скоростью и точностью работы, хотя ее результате все-же достаточно хороши, они не лучшее их возможного. Но зато, при необходимости результаты отдельных задач можно за счет этого повысить, подключив более медленную модель.
Когда это может быть полезно возможности и ограничения реализации: Мы подготовили небольшую табличку, которая показывает, в каких случаях наше API может принести вам пользу, каких результатов можно ждать, а каких — не стоит.
Ну и наконец, об ограничениях бесплатного API ключа. На момент написания данной статьи ограничения касаются объема обучающей выборки (до 240 тыс. символов текста, не включая метки классов), количества одновременно работающих разных моделей (до 2 шт) и числа запросов (42 тыс. символов в день). Этого должно быть достаточно для разработки, тестирования большинства приложений, для личного использования, а также для живой работы не сильно загруженных систем.
Что если нужны названия товаров, причем не всех, а каких-то определенных? Или мы хотим интерпретировать команды для мобильного приложения? Разделить адрес на название улицы, дома, города? Как насчет выделить важные факты из обращения клиента в службу поддержки: «Я возмущен качеством обслуживания в вашей компании. Не так давно, я заказывал ноутбук, но менеджер разговаривал некорректно и сказал, что товар закончился». Сегодня я расскажу о новом сервисе позволяющим решать широкий круг задач извлечения информации из текста. Этот сервис мы только что открыли для публичного доступа.
Что нужно для работы примеров из этой статьи: В статье в основном рассмотрено решение для .NET Framework на С#. Подойдет также любой язык для .NET Framework или mono. Из других языков обратится к web-API тоже можно, но готовых библиотек пока нет, поэтому код запросов придется писать вручную. Это не сложно, но здесь я пока не буду объяснять подробно как это сделать, чтобы не потерять главную мысль. Понадобится также доступ в Интернет и открытый порт 8080. Еще нужно будет зарегистрироваться, чтобы получить бесплатный ключ. Кажется, в основном все.
Как организована эта статья: Вначале объясняется задача, на примере которой будет показана работа API. Далее приводится код. Потом рассказано немного теории, как работает система изнутри, и в конце рассказано о ограничениях текущей версии, и том, в каких случаях эта система будет полезной, а когда нет.
Разбираем задачу: В качестве примера, возьмем задачу извлечения названий товаров из текста. Т.е. «Купить лазерный принтер Canon I-SENSIS i6500 в магазине товаров для офиса». Найти упоминания товаров бывает нужно для анализа информации о товарах и ценах в интернете, или системы, показывающей товарные объявления на основании содержимого страницы. Ну и для разных других целей.
Может показаться, что задача простая и решить ее ничего не стоит. Например, для некоторых групп товаров, особенно с английскими названиями можно попробовать написать регулярные выражения, выделяющие названия товаров из текста. Но такой метод не позволит отличить, например «Купить HTC One” (модель телефона) от „телефоны Samsung Apple Nokia” (просто перечисление производителей), что нередко встречается. Совсем не помогут регулярные выражения, если нужны товары, которые называются по русски, например «продается холодильник атлант 500» — совершенно не ясно, где начинается название.
Поэтому мы попробуем научить компьютер отличать название товара от прочего текста на основании некоторого количества примеров. Основным плюсом этого подхода является то, что не придется самим придумывать алгоритм, а минусом — необходимость вручную создать примеры для обучения.
Как должны выглядеть примеры? Допустим у нас есть такое предложение: «Купить Samsung Galaxy S4 в магазине «Наши телефоны». Разделим его на отдельные слова, и представим в виде колонки. Затем, напротив названий товаров напишем слово “Product”:
| Купить | |
| Samsung | PRODUCT |
| Galaxy | PRODUCT |
| S4 | PRODUCT |
| в | |
| нашем | |
| магазине | |
| <STOP> | |
| Также | |
| ... |
Таким образом, мы сформулировали задачу — определить является ли слово частью названия товара, или нет. После обучения на примерах мы сможем просто подать на вход модели текст в виде левой колонки и получить на выходе правую колонку. Кажется, что все достаточно просто.
На практике главная сложность — разметить вручную достаточное количество примеров для обучения. Чем больше примеров — тем лучше будет работать модель. Закономерный вопрос — а сколько примеров „достаточно много“? Все зависит от задачи — чем сложнее задача, тем больше нужно данных. В целом, обычно требуется от 400 до 4000 примеров вхождения нужного элемента. Что касается затрат времени, то по нашему опыту, трех дней работы по аннотации примеров в ряде случаем достаточно для целей создания работоспособного прототипа, хотя в более сложных ситуациях это время может существенно возрасти.
Для этой статьи мы приготовили уже размеченный учебный набор здесь. Учебный набор в данном случае создан из заголовков веб-страниц, поэтому полученная модель будет хорошо работать именно с заголовками. Позже я объясню, как можно улучшить качество распознавания в других текстах, но пока сосредоточимся на основной идее.
Весь набор данных нужно разделить на две части — train – на этой части будет обучаться модель, и test – на этой части будет проверятся результат работы алгоритма (в нашем учебном наборе уже есть два файла). Оба файла есть в комплекте, и их можно открыть Блокнотом или другим текстовым редактором, чтобы посмотреть структуру.
Далее нужно зарегистрироваться, что позволит получить бесплатный API ключ, и загрузить библиотеку функций (некоторые браузеры могут запросить подтверждение, т.к. архив содержит dll библиотеку). Для C# необходимо будет создать консольное приложение и подключить к проекту Meanotek.NeuText.Cloud.dll
Теперь пишем программу. Сначала создаем новую модель, дав ей при этом имя. Имя должно быть уникальным среди всех ваших моделей, потому что по нему модель будет впоследствии идентифицироваться и содержать только латинские буквы и цифры:
using Meanotek.NeuText.Cloud;
Model MyModel = new Model("Ваш api ключ","ProductTitles");
MyModel.CreateModel();
Далее загружаем данные и ставим модель в очередь задач:
System.Console.WriteLine("Загружаем обучающие данные");
MyModel.UploadTrainData("products_train.txt");
System.Console.WriteLine("Загружаем проверочные данные");
MyModel.UploadTestData ("products_dev.txt");
System.Console.WriteLine("Обучение модели");
MyModel.TrainModel();
TrainModel() приостанавливает программу до окончания обучения. Вообще это необязательно (т. к. может занимать 10-20 минут) и программа может заниматься в это время другими делами и просто проверять статус процесса обучения. Чтобы не останавливать программу, можно использовать метод TrainModelAsync(). Если в процессе работы TrainModel() программу закроют, или произойдет ошибка соединения с сетью, то на сервере модель все равно создаться, т. к. сама программа ставит модель в очередь и ничего кроме ожидания в это время не делает. При следующем запуске программы состояние модели можно будет проверить функцией Model.GetStatus().
После того как обучение закончено, мы можем вывести на экран результаты проверки по тестовой выборке:
Console.WriteLine(MyModel.GetValidationResults());

Для каждого вида извлекаемых выражений (категория, продукт) вычисляется ряд значений, характеризующих качество работы системы. Recall – это отношение числа выражений (например названий товаров), найденных алгоритмом к общему числу выражений, найденных человеком. Precession – доля правильно найденных выражений среди всех обнаруженных. F1 – собирательный критерий качества работы алгоритма, который объединяет precession и recall вместе. Чем эта величина ближе к 1.0, тем лучше. Я не буду здесь подробнее объяснять смысл всех этих метрик, а интересующемуся читателю предлагаю прочитать эту статью, где, на мой взгляд, все рассмотрено хорошо и детально.
Отмечу только, для сравнения, что широко используемый метод условно-случайных полей (Conditional random fields) с признаками в виде слов и биграмм в окне из 5 слов, дает на этой выборке F1 по названиям товаров 86.2, а по категориям — 79.5.
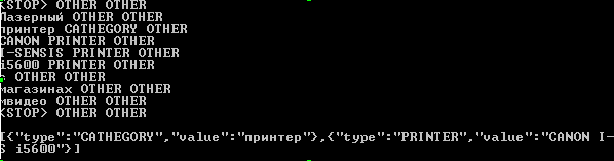
Теперь попробуем подать на вход новый пример:
string result_raw = MyModel.GetPredictionsRaw ("Лазерный принтер CANON I-SENSIS i5600 в магазинах мвидео");
string result = MyModel.GetPredictionsJson ("Лазерный принтер CANON I-SENSIS i5600 в магазинах мвидео");
Console.WriteLine(result_raw);
Console.WriteLine(result);

Теория (и философия): Проблема извлечения различных выражений из текста имеет длинную историю, и для ее решения существует много специальных инструментов. Но нам хотелось сделать очень простое для использования решение, которое не требовало бы серьезных специальных навыков, обходилось без ручной настройки, работало на относительно небольших выборках и при этом годилось бы для широкого круга задач. Тогда создание новых моделей извлечения данных из текста, а, следовательно, и новых приложений, стало бы доступно для индивидуальных разработчиков и небольших компаний, которые смогли бы сами определять, какие аналитические средства требуются их бизнесу.
Для этого требовалось прежде всего избавится от ручного подбора признаков, грамматических анализаторов и всевозможных словарей терминов, подбираемых под конкретные задачи, не потеряв сильно в качестве. Одна из моделей, которая позволяет это сделать — глубокие рекуррентные нейронные сети (см рисунок). Рекуррентная сеть последовательно получает на вход новые слова из предложения, при этом сохраняя память о предыдущих состояниях. На выходе нейронная сеть выдает класс, к которому принадлежит данное слово. Несколько последовательных слоев формируют все более абстрактные понимания предложения, работая на разных временных диапазонах (правда, это происходит, если все настроено правильно, иначе можно получить просто сильно переобученную нейронную сеть).

Из исследований известно, что такая модель может извлекать сложные выражения из английских текстов, в том числе делать разметку семантических ролей и анализ тональности. При этом результаты не уступают, а часто даже превосходят показатели всех других известных методов. Правда, каждая работа использовала свою несколько отличающуюся архитектуру, и оптимальные параметры отличались для разных задач.
Поэтому мы провели большую работу, проверив несколько десятков различных моделей на 18 тестовых коллекциях английских и русских текстов, в результате чего удалось найти наиболее оптимальную модель нейронной сети и способ представления входных слов, так чтобы результаты были высокими на разнообразных задачах.
Правда в итоге, модель, выбранная для API является компромиссом между скоростью и точностью работы, хотя ее результате все-же достаточно хороши, они не лучшее их возможного. Но зато, при необходимости результаты отдельных задач можно за счет этого повысить, подключив более медленную модель.
Когда это может быть полезно возможности и ограничения реализации: Мы подготовили небольшую табличку, которая показывает, в каких случаях наше API может принести вам пользу, каких результатов можно ждать, а каких — не стоит.
| Когда будет полезно |
Когда не будет полезно |
| Если вы хотите создавать приложения со средствами понимания текстов, но не знакомы с теорией анализаторов языка или имеете мало опыта. Мы постарались сделать так, чтобы система создавала конкурентоспособные модели без ручной настройки. |
Вы эксперт в компьютерной лингвистике и хотите улучшить качество решения задачи, на которой работаете уже 5 лет. Мы не гарантируем, что нынешняя реализация превзойдет все специализированные решения. |
| Вы решаете специфическую задачу извлечения информации из текста, для которой нет готового API (т. е. не просто найти имена людей, организаций, даты и географические локации). Нашу систему можно обучить для разных задач. |
Для вашей задачи уже есть специализированное решение, например готовое API распознавания именованных сущностей. Скорее всего использовать готовое решение будет вам проще, если вы уверены, что ваши потребности полностью удовлетворяются |
| Вы ограничены в бюджете и доступных ресурсах, и не хотите заниматься в дальнейшем поддержкой и разработкой собственного анализатора языка. Мы следим за новыми исследованиями и сами внедряем современные алгоритмы, поэтому со временем качество работы системы, спроектированной на нашем API будет возрастать без дополнительных затрат |
У вас есть собственная команда специалистов, которая занимается постоянным поддержанием и разработкой анализатора языка. |
| Вы хотите сэкономить место на диске или вычислительные ресурсы для конечного приложения. Можно сэкономить от 5 до 100 mb места на целевом устройстве, что может быть важно для мобильных приложений. Можно легко установить функции анализа в веб-приложения, которые находятся на VPS начального уровня или shared-хостингах. |
Память и ресурсы процессора доступны в неограниченных количествах |
Ну и наконец, об ограничениях бесплатного API ключа. На момент написания данной статьи ограничения касаются объема обучающей выборки (до 240 тыс. символов текста, не включая метки классов), количества одновременно работающих разных моделей (до 2 шт) и числа запросов (42 тыс. символов в день). Этого должно быть достаточно для разработки, тестирования большинства приложений, для личного использования, а также для живой работы не сильно загруженных систем.