
Ранний Micron DRAM, ёмкость 1 Мбит
RAM (random access memory, запоминающее устройство с произвольным доступом) присутствует в любой компьютерной системе, от небольших встроенных контроллеров до промышленных серверов. Данные хранятся в SRAM (статической RAM) или DRAM (динамической RAM), пока процессор работает с ними. С падением цен на RAM модель перемещения данных между RAM и постоянным местом хранения данных может исчезнуть.
RAM сильно подвержена влиянию колебаний рынка, но в долгосрочной перспективе её стоимость идёт вниз. В 2000 году гигабайт памяти стоил более $1000, а сейчас – всего $5. Это позволяет вообразить совершенно другую архитектуру системы.
Базы данных обычно хранятся на дисках, откуда нужная информация считывается при необходимости в память, после чего обрабатывается. Обычно считается, что объём памяти в системе на несколько порядков меньше объёма дисков – например, гигабайты против терабайтов. Но с увеличением объёмов памяти становится эффективнее загружать больше данных в память, уменьшая количество чтений и записей. С уменьшением стоимости RAM становится возможным загружать базы данных в память целиком, проводить операции над ними и записывать их обратно. Сейчас мы уже подошли к точке, в которой некоторые базы не записываются обратно на диск, и постоянно висят в памяти.

Мегабитный чип от Carl Zeiss

До 1975 года RAM была памятью на магнитных сердечниках

4-мегабитный чип EPROM, стираемый при помощи ультрафиолета, направляемого через окошко

Кучка современных DRAM
Скорости доступа к памяти измеряются в наносекундах, а время доступа к диску измеряется в миллисекундах – то есть, память получается в миллион раз быстрее. Скорость передачи данных в памяти, конечно, не в миллион раз быстрее – это гигабайты в секунду против нескольких сотен мегабайт в секунду для быстрого харда – но, по крайней мере, скорость RAM превосходит скорость накопителей на порядок.
В реальном мире различия не такие серьёзные, но чтение данных с диска в RAM и запись их обратно – серьёзное узкое место, а также поле для появления ошибок. Исчезновение этого шага ведёт к упрощению инструкций, увеличению простоты и эффективности.
С падением цен на RAM в больших компаниях и дата-центрах становится популярным обеспечивать сервера терабайтами памяти. Но кроме размера, базу данных в памяти обычно не хочется держать по соображениям надёжности. RAM теряет содержимое при отключении энергии или компрометации системы. С этими проблемами сталкиваются при попытке соответствовать стандарту надёжности баз данных ACID (atomicity, consistency, isolation, durability – Атомарность, Согласованность, Изолированность, Долговечность).
Проблем можно избежать при помощи слепков и логов. Так же, как можно делать резервные копии БД с дисков, БД в памяти можно копировать в хранилище. Создание слепков мешает другим процессам читать данные, поэтому частота контрольных точек – это компромисс между быстродействием и надёжностью. А это, в свою очередь, можно сгладить записью транзакций, или журналированием, записывающим изменения данных так, что позднее состояние можно воссоздать из ранней копии. Но всё же, когда БД полностью находится в памяти, некий процент избыточности теряется.
Программы для управления БД, находящихся в памяти (IMDBS), позволяют создавать гибридные системы, в которых некоторые таблицы БД находятся в памяти, а другие живут на диске. Это лучше кэширования, и удобно в тех случаях, когда бессмысленно держать всю БД в памяти.
БД могут быть сжатыми, особенно в системах со столбцами, хранящими таблицы в виде наборов столбцов, а не строк. Большинство технологий сжатия предпочитают, чтобы соседние данные были одного типа, а столбцы в таблицах почти всегда содержат данные одного типа. И хотя сжатие подразумевает увеличение нагрузки на вычисления, хранение столбцов хорошо подходит для сложных запросов в очень больших наборах данных – поэтому в них заинтересованы пользователи «большие данные» и учёные.
На больших масштабах компании вроде Google перешли на RAM, чтобы большое количество поисковых запросов обрабатывалось с приемлемой скоростью. Здесь также появляются проблемы обеспечения доступа к большим объёмам памяти, поскольку количество RAM, подсоединяемое к одной материнской плате, ограничено, а организация общего доступа приводит к появлению дополнительных задержек.
Жизнь после RAM
Но нельзя гарантировать, что работа с данными в памяти – это будущее обработки данных. Альтернативный метод – использование энергонезависимой RAM (non-volatile RAM, NVRAM), знакомой пользователям в виде SSD, предлагающих совместимую с дисковыми системами архитектуру. Сейчас они работают на флэш-памяти NAND, предлагающей высокие по сравнению с механическими жёсткими дисками скорости чтения и записи. Но у неё есть свои проблемы. Флэш-памяти требуются относительно высокие напряжения для записи данных, и она постепенно вырождается, с чем призваны бороться особые алгоритмы, приводящие к постепенному замедлению работы.

Стоимость памяти и накопителей от времени (долларов за Мегабайт)
Как видно из графика, со временем стоимость накопителей уменьшается примерно так же, как и стоимость RAM. Уменьшающаяся стоимость SSD привела к их распространению в дата-центрах и на рабочих местах, но пока непонятно, какое у этой технологии будущее. В исследовании от Google, опубликованном в феврале 2016 года, на основе шести лет использования был сделан вывод, что флэш-память гораздо менее надёжна, чем жёсткие диски – например, она выдаёт неисправимые ошибки – хотя ей и требуются более редкие замены. А SSD для корпоративного применения не отличаются по качеству от потребительских вариантов.
Но уже появляются новые типы NVRAM. Ферроэлектрическая RAM (FRAM) когда-то должна была стать заменой RAM и флэшек в мобильных устройствах, но сейчас внимание переключилось на магниторезистивную RAM (MRAM). По скоростям она приближается к RAM, а задержка доступа к ней составляет 50 наносекунд – это медленнее, чем 10 нс у DRAM, но в 1000 раз быстрее, чем микросекунды у NAND.
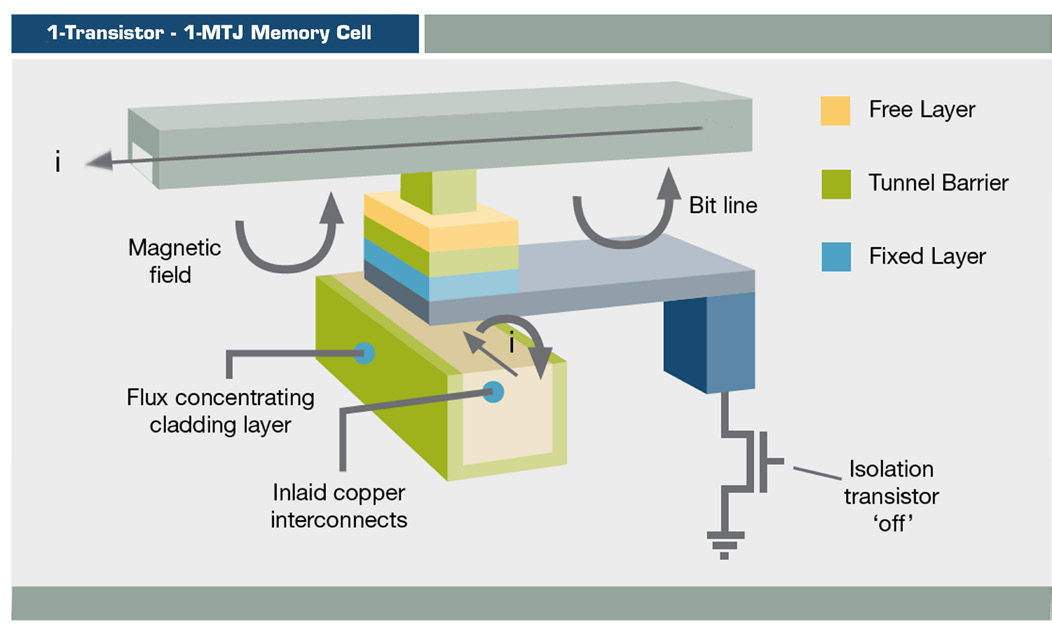
Схема MRAM
MRAM хранит информацию при помощи магнитной ориентации, а не электрического заряда, используя тонкоплёночную структуру и магнитный туннельный переход. MRAM с переключением уже используется в таких продуктах, как массивы хранения данных EqualLogic от Dell, но пока лишь для журналирования.
MRAM с передачей спина (ST-MRAM) использует более сложную структуру, в потенциале допускающую увеличение плотности. Сейчас на рынок её выводит Everspin, недавно вышедшая на NASDAQ под кодом MRAM. Другие фирмы, исследующие эту возможность — Crocus, Micron, Qualcomm, Samsung, Spin Transfer Technologies (STT) и Toshiba.

Память 3D XPoint

Два чипа 3D XPoint по 128 ГБ

Диаграмма для Intel/Micron 3D XPoint
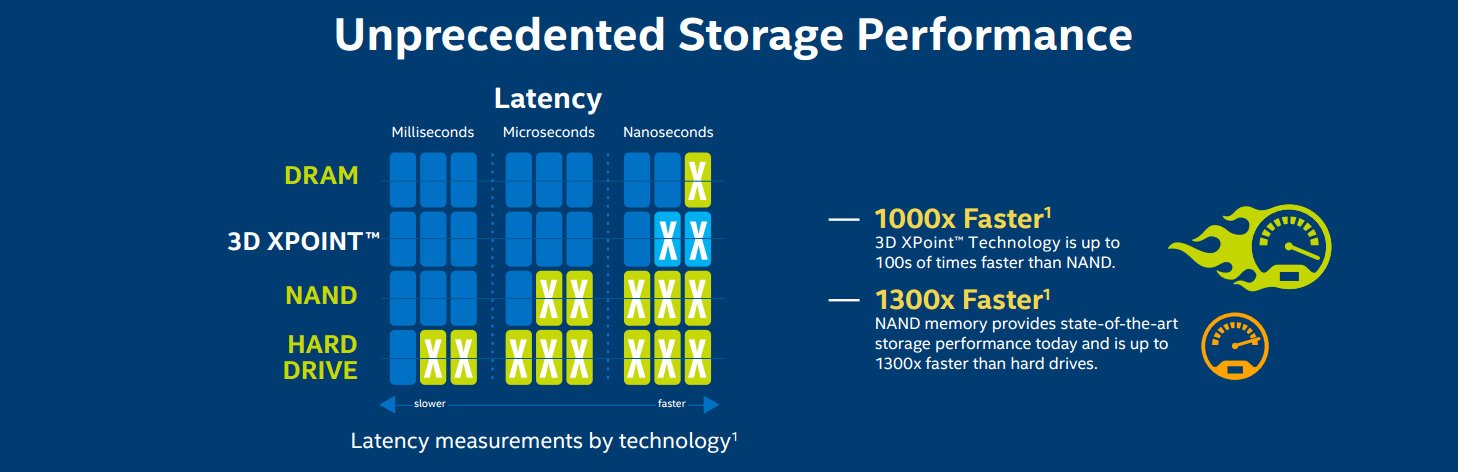
Сравнение скоростей
А в это время Intel работает с Micron над разновидностью NVRAM под названием 3D XPoint (произносится «кросспоинт»). Эта форма памяти с изменением фазового состояния (PCM), известная как резистивная RAM (ReRAM), впервые была обнародована в 2015-м. «3D» означает возможность многослойного построения памяти. Intel считает, что XPoint может работать в 1000 раз быстрее, чем NAND, и быть в 10 раз более ёмкой, хотя недавно эти заявления слегка уменьшились. Ожидается, что цена будет в промежутке между флэш-памятью и DRAM. Из-за этого она вряд ли приживётся в домах, но на большом масштабе она может заменить RAM и SSD.
IBM также работает над памятью с изменением фазового состояния. Как и у Intel, их технология основана на халькогенидном стекле, используемом в перезаписываемых оптических носителях. Используя электричество для преобразования материала из аморфного состояния в одно из трёх кристаллических, компания похваляется прорывом в ёмкости, который позволит сделать стоимость памяти ниже, чем у DRAM.
RAM-гонка повлияет на все уровни развития компьютеров. Увеличение памяти с 8 до 16 ГБ на десктопах конечных потребителей позволит ускорить многозадачность и повысить эффективность требовательных к памяти программ.
В ультрабуках SSD уже являются нормой, а растущие ёмкости уже делают их кандидатами для замены жёстких дисков. Следующее поколение трёхмерной NAND (V-NAND, вертикальной) обещает большую эффективность и плотность записи. Samsung предсказывает, что к 2020 году появятся SSD для конечных пользователей на 512 Гб по цене сегодняшнего терабайтного винта.
Для среднего бизнеса и научных заведений больше дешёвой RAM означает улучшение аналитики при помощи данных, находящихся в памяти – если софт будет поспевать за этим. SAP HANA – база данных, содержащаяся в памяти, платформа для широкого применения облачных и местных решений, позволяющая уже не очень крупным компаниям работать с большими данными. Схожие БД есть и у IBM с Oracle.
RAM демократизирует технологии – техника дешевеет, и разница между крупными и мелкими организациями стирается.

Дата-центр Google со сделанными под заказ серверами

Суперкомпьютер Sequoia


Суперкомпьютер Sunway TaihuLight, быстрейший компьютер в мире, 93 петафлопс

Titan, быстрейший суперкомпьютер США

Дата-центр EcoPod HP
Последний по порядку, но не по значимости, пункт – потребность в памяти суперкомпьютеров. Быстрейший на сегодня китайский СК Sunway TaihuLight содержит 1 300 ТБ DDR3 DRAM, что относительно немного для его скорости в 93 петафлопс (квадриллион операций с плавающей запятой в секунду). В частности из-за этого его энергопотребление составляет всего 15,3 МВт, но это может стать и ограничивающим фактором.
Теперь все стремятся к приставке экзафлопсам, или к 1000 петафлопсов. Японский компьютер post-K, разрабатываемый Riken и Fujitsu, будет готов к 2020 году и будет содержать Hybrid Memory Cube от Micron – многослойная реализация DRAM, и возможно также будет использовать 3D XPoint NVRAM. Европейский проект NEXTGenIO в Эдинбургском суперкомпьютерном центре намеревается достичь экзафлопсов к 2022 году, также с использованием 3D XPoint.
В США Exascale Computing Project, разрабатываемый в рамках инициативы NSCI, к 2023 году должен представить аж два суперкомпьютера подобного быстродействия. Их архитектура ещё прорабатывается, но поскольку быстродействие и энергоэффективность находятся в приоритете, RAM будет играть в нём центральную роль.
Комментарии (37)

Sleepwalker_ua
19.10.2016 18:05+2Эхх… вот смотрю и думаю, когда ж станет простому обывателю склепать RAM-диск гигов на 200-300 и не задумываться при этом о продаже почки\печени… Современные г… простите, криворукие кодеры умудряются даже примитивные программы иной раз сделать через такие извращения, что вешается далеко не самый древний комп, и именно на обращениях к постоянной памяти, и даже SSD, увы, не всегда спасает (ибо ресурс, блин..)

amartology
19.10.2016 18:07+3" Intel считает, что XPoint может работать в 1000 раз быстрее, чем NAND, и быть в 10 раз более ёмкой, хотя недавно эти заявления слегка уменьшились."
СЛЕГКА — это в 4 раза быстрее вместо обещанной 1000 тысячи раз, и существенно дороже. Я бы сказал, что Intel и Micron крупно облажались и теперь пытаются замаскировать провал.




pda0
19.10.2016 22:58Да, дешёвая память это приятно. Хотя буквально давеча думал, что объём памяти практически перестал быть значимым. Скорость памяти настолько отстала, что теперь является бутылочным горлышком. Сделай сейчас процессор на 40 GHz и он не будет в 10 раз быстрее. Так, процентов на 5-10. Но стоит разогнать память в 10 раз, как скорость работы программ возрастёт на порядок.

l27_0_0_1
20.10.2016 05:16-1Эта статья на ~62% состоит из картинок, причем зачастую абсолютно безполезных. Вы это серьёзно?
fivehouse
20.10.2016 09:17+1С уменьшением стоимости RAM становится возможным загружать базы данных в память целиком, проводить операции над ними и записывать их обратно
Прекрасное мнение человека не совсем представляющего себе что такое БД и что такое надежность хранения. Основная задача БД это сохранение данных успешно выполнившихся транзакций при ЛЮБЫХ обстоятельствах (вероятно, кроме прямого разрушения оборудования хранения, и то даже тут есть всякие удаленные кластера и т.п.). Загрузив данные в память и столкнувшись kernel panic, выходом из строя материнской платы, незапуском генератора при незапланированной длительности отключения электроэнергии, перегревом серверной и серверов при выходе из строя системы охлаждения и еще десятком событий, БД в RAM столкнется с потерей транзакций. Иногда одной транзакции бывает достаточно для существенных потерь бизнеса.KostaArnorsky
20.10.2016 12:50+1Как по мне, как раз ваш комментарий — пример воинствующего невежества. Такие БД мало того, что существуют немало лет и вовсю используются, они уже получили признание. Например, как аналитические БД, или для data mining, позволяя выполнять запросы с недостижимыми для традиционных БД скоростями. Причем исходные данные могут хранится как раз в традиционных БД, обычных файлах, whatever. Большинство из них не обеспечивают ACID, потому что это никому и не нужно — загрузили данные, покрутили так и сяк, построили отчеты и забыли. Хотя многие обеспечивают, и вы получете real-time аналитику и надежность традиционных БД. Многие являются надстройками над традиционными БД. Существуют даже облачные сервисы, которые позволяют вам использовать подобное решение с повременной оплатой, можно, например, построить квартальный отчет и не покупать сотни гигабайт памяти. И с удешевлением оперативной памяти in-memory database и in-memory data grid стали серьезной угрозой аналитическим massively parallel processing БД, таким, как Teradata.
DrPass
20.10.2016 14:57+1Вообще, даже современные OLTP СУБД по-возможности максимально кешируют данные в памяти, и если есть возможность целиком затянуть БД в ОЗУ, они именно так и делают. Это, конечно, не отменяет необходимости писать на диск журнал транзакций сразу же по мере их выполнения. А в OLAP это вообще общепринято.
xuexi
Насколько я понимаю, рост объёмов RAM и появление персистентности этой самой RAM приведёт к отмиранию понятия Файл, ведь всё можно будет хранить непосредственно в виде программных объектов. Мало кто готов к такой смене парадигмы.
DrPass
Понятие «файл» связано не с особенностями внешней памяти, а с необходимостью как-то идентифицировать архивные данные. Думаю, со сменой носителя эта парадигма не поменяется. Она естественна для восприятия, в отличии от более сложных структур.
xuexi
Я говорю про файл как массив байтов, про навигацию по графам, файловый путь и его формы речи не было.
kAIST
Сколько читаю про это, никак не могу уловить суть. С парадигмой файловой системы и файлов вроде как избавились в iOS. Хотя внутри оно все тоже самое осталось.
Вот пример такой. Сфотографировал я фотографию, скопировал на компьютер, отрадактировал и отправил другу. Как обойтись без «файлов» и что значит программные объекты? Какие проблемы это решает, кроме накладных расходов на сериализацию и десериализацию?
xuexi
Можно объяснить это так: файл, как концепция, был введён для того, чтобы хранить, идентифицировать и передавать куски данных в энергонезависимой памяти. Почему назвали «файл» есть много легенд, мне кажется, наиболее верно объясняет ситуацию легенда про картотеку перфокарт, которые были сгруппированы по папкам, то, что сейчас офисные работники называют «файл для бумаг».
Так вот, если разобраться, что такое файл, окажется, что изначально это прямая копия куска (блока) энергозависимой памяти. Если представить, зачем это было нужно, можно понять, что блоки содержали осмысленную информацию, в общем случае, эта информация представляла собой данные, понятные программам. Непосредственные данные, которые обрабатывал процессор в памяти, грузил в регистры и так далее. В общем-то, если посмотреть на файл подкачки, можно понять, чем были файлы изначально.
Сначала это были байты, потом группы байт — числа, потом цепочки чисел, и наконец группы чисел и не чисел, объединенные смыслом. Если посмотреть с современной точки зрения — это и были объекты, структуры, массивы, ссылки, в общем случае, программные объекты, с которыми работает пользовательский код.
Недавно была статья про первый форматы MS Office, так там писали, что по сути файлы .doc это дампы сишных структур, копия информации из рантайма.
Так вот теперь представим, что память в 21-м веке наконец-то стала вся быстрая и энергонезависимая. Сама концепция файлов просто теряет смысл. Объекты в памяти остаются объектами в памяти. Не исчезают, пока пользователь их не удалит или сборщик мусора не вычистит. То есть, функция хранения реализована без файлов.
Функция идентификации так же может быть реализована без понятия файлов, ведь в первую очередь, мы идентифицируем объекты, для них даже есть понятие identity, по содержимому или по идентификатору, или по адресу. А то, что все привыкли называть «файловой системой» на деле является способом адресации в древовидной структуре. Не самой совершенной, кстати. XPath тоже такую функцию выполняет, например. А ведь есть и совсем иные альтернативы, типа системы тэгов.
Остаётся третья функция: передача. Конечно, логично передавать объекты в сериализованном виде (проблемы у этого способа были с самого начала), или в виде дампа памяти, как делали MS. Но сейчас есть много путей передачи содержимого не в виде файлов. Фактически, любая передача данных, как могут рассказать связисты, не основывается на общепринятом понятии файла, тут возможно подходит слово «сообщение», так как помимо пользовательских данных, то есть того, что все называют файлом, есть метаинформация о данных, информация о канале данных, специфичное потоковое разбиение данных.
В целом, вот основные доводы в пользу отказа от понятия файла вместе с отказом от концепции носителей данных, которая и привела к появлению понятия файла.
Кстати, сеть IPFS, с которой мне довелось поработать <https://habrahabr.ru/post/310554/>, тоже изначально никак не связана с понятием файла, оно было введено позже, и, на мой взгляд, в результате получился аналог object-relational impedance mismatch, но уже для объектов/блоков и «файлов». Но люди привыкли к файлам, это надо признать
Hellsy22
Тут нужны какие-то аргументы, все-таки.
Совершенно не важно, как организована передача данных — там много уровней вложенности, важно что именно пользователь получает в итоге. Если постоянно хранимый контейнер с нужными данными и каким-то адресом для доступа/поиска — то это и есть файл. А как организована файловая система — дело десятое.
xuexi
Когда Youtube шлёт блоки данных моему браузеру мне совершенно не нужна концепция файла. Как и во многих других кейсах.
> Какое это имеет отношение к современным реалиям?
Байты из RAM до сих пор надо где-то хранить, пока электрики разруливают проблемы.
> Если постоянно хранимый контейнер с нужными данными и каким-то адресом для доступа/поиска — то это и есть файл.
Это и есть объект, а как организована коллекция объектов — дело десятое. Может, связный список, может, хэш-массив «мои документы».
xuexi
Тут ещё можно порассуждать, к чему более удобно применять понятие версионности, к объектам или к их сериализованным проекциям. Мета-информация, полиморфизм, иммутабельность, связка понятий, которая давно присутствует в программах и присуща объектам далеко не полностью возможна даже в современных ФС.
Короче, всё что я хочу сказать, появление в ИТ понятия «файл» тащит за собой целый куст последствий, которые как бы есть, и все привыкли, и все знают, а то, что известно, как правило, никто не хочет понимать. И так известно, чего там копаться, воду лить. И так сойдёт.
Hellsy22
Ramdrive и tmpfs смотрят на это утверждение с сомнением. Swapfs с вами согласен, но с файлами у него как-то не задалось.
Память процесса должна быть освобождена при завершении процесса и по-умолчанию недоступна ни для кого кроме самого процесса. Файл же обычно не уничтожается по завершению процесса и может быть доступен многим процессам. Отсюда и различие в уровнях организации доступа — в современных FS у файла могут быть сложные иерархически наследуемые права на доступ в самых разнообразных вариантах. Эти права могут включать в себя отдельных пользователей, группы пользователей или любые другие сущности. Помимо прав у файла есть и разнообразные атрибуты, например, его содержимое может храниться в сжатом или зашифрованном виде, а при удалении будет произведена перезапись содержимого. Добавьте сверху сложную систему журналирования и защиты от порчи данных, снапшоты, логические тома, объединяющие разные носители, порой даже на разных машинах.
Процессам же все эти навороты для большинства объектов не очень-то нужны, достаточно просто свободного блока памяти. Тем не менее, как только дело доходит до хранения и сложных структур и работы с ними, то мы получаем примерный аналог специализированной файловой системы — многие СУБД тоже имеют иерархическую и наследуемую систему разграничения прав доступа, защиту от повреждения данных и т.д.
akastargazer
Можно вас попросить пояснить ход вашей мысли, а то я не совсем понял эту цепочку:
1) вам сообщили, что файл «изначально это прямая копия куска (блока) энергозависимой памяти»
2) вы это отрицаете: «Какое это имеет отношение к современным реалиям?»
3) вам поясняют, что «Байты из RAM до сих пор надо где-то хранить»
4) вы усиливаете своё отрицание примером «Ramdrive и tmpfs смотрят на это утверждение с сомнением.»
И тут же пишете «Тем не менее, как только дело доходит до хранения и сложных структур и работы с ними»
То есть, вы сначала отвергаете утверждение, что файлы нужны для _хранения_ (подчёркиваю — хранения) байтов, и тут же утверждаете то же самое.
Как это у вас получается? Может, я чего-то не так понял?
Hellsy22
Некоторые байты из RAM и «прямая копия куска памяти» — это не одно и то же. Мне это представляется настолько очевидным, что я не посчитал нужным это подчеркивать.
Что же до tmpfs — это пример использования файлов в ситуациях, когда нет необходимости постоянного хранения. Следуя вашей цепочке рассуждений такого феномена вообще не должно было существовать.
DrPass
> мне совершенно не нужна концепция файла
Ну как это не нужна? Вы работаете с конкретным именованным ресурсом. На «человеческом» уровне вы это воспринимаете как видеоролик с названием. Тот же файл.
На уровне видехостинга это… какой-то целостный объект с атрибутами в их хранилище данных. Тот же файл. Потом он сериализуется и по кускам приходит в броузер, который тоже собирает этот же видеоролик у себя в кэше, чтобы воспроизвести.
По сути, ничего, кроме среды хранения, не меняется. Пока данные являются внутренними для приложения, они могут иметь любую «физическую» структуру. Но как только возникает потребность их передавать из песочницы одного приложения в песочницу другого, сразу же возникает и потребность в каком-то переносимом контейнере, с идентификатором и атрибутами. И опять же таки, это тот самый файл.
kAIST
Как всегда много воды (не конкретно про Вас, а вообще в подобных рассуждениях на эту тему) и никакой конкретики.
Со времен появления этой идеи, многое изменилось. Компьютеры стали не «вещью в себе», а устройствами, которые активно обмениваются информацией с внешним миром.
Я могу написать приложение, которое хранит в оперативке какие то свои данные и она будет хранить, пока оно будет работать. Представим себе, что оно будет работать вечно, и совсем не волнует сколько отъест оперативки. Ну вот работает приложение, я работают с этими данными. И тут мне захотелось отправить эти данные куда то еще. Способ отправки не важен, это может быть, например, сокет. Как отправлять то будем? Сериализовывать? Если да, то мы опять же возвращаемся к концепции «файлов»
xuexi
> Как всегда много воды
Это ещё мало, всего один комментарий. Я думаю, аккуратный разбор популярных определений слова «файл» займёт не одну статью.
> мы опять же возвращаемся к концепции «файлов»
В случае с сокетом, скорее, поток. Да почти всегда это будет поток данных. Я не зря упомянул связистов, кстати. Ну, разве что мы повезём грузовик жёстких дисков, да и то, все они могут хранить непосредственно дамп памяти, вместе со снэпшотами софта и прочего.
В любом случае, если мы хотим подвести некое обобщённое понятие под всё это, то понятие объекта подходит лучше хотя бы в силу большего количества охватываемой реальности и оторванности от исторического понятия «файл».
*nix-экосистеме в случае сдвига парадигмы придётся тяжелее всего, наверное.
kAIST
Вы кажется сути не уловили.
Пример: веб сервер сформировал html страницу и через сокет передал ее в браузер. Браузер отрендерил ее и показал. Браузер мог это сделать и из файла на диске либо загрузив через сокет, да собственно это не важно. Что поменяется при вашей парадигме?
Что есть программные объекты?
xuexi
Вы приводите пример, в котором файлы не используются, а потом спрашиваете, что изменится когда файлы исчезнут. Ответ: в данном примере ничего не изменится.
Кажется, это вы суть не улавливаете, не первый раз уже. Почитайте про файлы, потом про ООП (например), потом про API работы с файлами в том же юниксе. Потом поговорим, а то воинствующее профанство, поощряемое плюсами уже давно надоело.
kAIST
Зачем вы меня посылаете почитать про ООП, API доступа к файлам, если я и так это знаю и программирую под linux? Давайте конкретики.
Берем «html документ», который представляет из себя набор байтов и сохраняем его не в файловую систему, а в виде записи в какую нибудь базу данных, которая все хранит исключительно в RAM. Программа соответственно читает это дело «с оперативки». Теперь это соответствует вашей концепции?
DrPass
> В любом случае, если мы хотим подвести некое обобщённое понятие под всё это
… а кто эти «мы»? Мы вот тут не хотим придумывать ещё какое-то новое обобщенное понятие. Существующих обобщённых понятий с лихвой хватает для определения того, что у нас есть. Вы хотите придумать одно название, такого себе абстрактного франкенштейна, под которое подвести и файлы, и сетевые пакеты? Зачем?
AxisPod
Ну почему же, может наконец-то файловые системы заменятся на реляционные или документо-ориентированные бд.
Hellsy22
Отличная идея! В конце-концов надо же как-то угробить высвободившиеся ресурсы, чтобы сохранить уровень дискомфорта пользователя от подтормаживания системы.
AxisPod
С ресурсами соглашусь, будет затрачиваться больше. Но при чём тут дискомфорт? Или вы думаете, что рядовому пользователю нужно прям давать работу через SQL? А вот в плане выборки, поиска и т.д. работать будет куда удобнее. Можно спокойно накидать фильмам и музыке жанры в связке один ко многим и затем спокойно выбирать без всякого шаманства и каши в файловой системе. Удобства наоборот добавится. Почитайте хотя бы про закрытую WinFS.
Hellsy22
Я же написал: «сохранить уровень дискомфорта пользователя от подтормаживания системы»
kAIST
И что собственно это даст?
Sirikid
Smalltalk и Lisp давно уже готовы
orcy
Вспоминается Palm OS на которой не было файлов и соответствующего API, а память устройства была устроена как набор записей. Не помню правда что там было со сбросом памяти — возможно если полностью разрядить аккумулятор вся память очищалась, но это устройство тогда предполагали частую синхронизацию с ПК, так что постоянно бэкапилось. API для файлов появилось только после добавление sd-карт и внедрялось постепенно.
На мой взгляд без файлов все равно будет довольно трудно. На хабре вроде были статьи посвященные возможной архитектуре системы где нет диска, а все хранится на огромном персистентном массиве RAM.
quwy
При отключении питания происходил total recall, но гораздо интереснее там было устроено хранение прграмм и библиотек. Они лежали прямо в ОЗУ в виде готовых к работе дампов и запуск приложения представлял собой просто передачу управления на нужный адрес. То есть не было не только исполняемых файлов, но и процесса загрузки как такового. А отсутствие защиты памяти открывало широчайшие возможности по перехвату любого вызова любой библиотеки и патчингу исполняемого кода.
beeruser
IBM такие системы выпускает уже десятилетия как.
Почитайте про OS/400 и потомков
https://en.wikipedia.org/wiki/Single-level_store
«In the i5/OS, the operating system believes it has access to an almost unlimited storage array of 'real memory' (i.e., primary storage).… The operating system simply places an object at an address in its memory space.»