
Дин Помело [Dean Pomerleau] всё ещё помнит, как ему впервые пришлось столкнуться с проблемой «чёрного ящика». В 1991 году он делал одну из первых попыток в той области, которая сейчас изучается всеми, кто пытается создать робомобиль: обучение компьютера вождению.
А это означало, что нужно сесть за руль специально подготовленного Хамви (армейского вседорожника), и покататься по улицам города. Так рассказывает об этом Помело, в ту пору бывший аспирантом по робототехнике в Университете Карнеги-Меллон. Вместе с ним катался и компьютер, запрограммированный следить через камеру, интерпретировать происходящее на дороге и запоминать все движения водителя. Помело надеялся, что машина в итоге построит достаточно ассоциаций для самостоятельного вождения.
За каждую поездку Помело тренировал систему несколько минут, а затем давал ей порулить самостоятельно. Всё вроде бы шло хорошо – пока однажды Хамви, подъехав к мосту, не повернул внезапно в сторону. Человеку удалось избежать аварии, только быстро схватив руль и вернув управление.
В лаборатории Помело попробовал разобраться в ошибке компьютера. «Одной из задач моей научной работы было вскрыть 'чёрный ящик' и разобраться, о чём он думал»,- поясняет он. Но как? Он запрограммировал компьютер как «нейросеть» – тип искусственного интеллекта, имитирующий работу мозга, обещавший быть лучше стандартных алгоритмов в обработке сложных ситуаций, связанных с реальным миром. К сожалению, такие сети непрозрачны так же, как и настоящий мозг. Они не хранят всё изученное в аккуратном блоке памяти, а вместо этого размазывают информацию так, что её очень сложно расшифровать. Только после широкого спектра тестов реакции софта на различные входные параметры, Помело обнаружил проблему: сеть использовала траву по краям дорог для определения направлений, и поэтому появление моста её смутило.
Через 25 лет расшифровка чёрных ящиков стала экспоненциально сложнее, при одновременном возрастании срочности этой задачи. Произошёл взрывной рост сложности и распространенности технологий. Помело, на полставки обучающий робототехнике в Карнеги-Меллон, описывает его давнюю систему как «нейросеть для бедных», по сравнению с огромными нейросетями, реализуемыми на современных машинах. Техника глубокого обучения (ГО), в которой сети тренируются на архивах из «больших данных», находит разные коммерческие применения, от робомобилей до рекомендаций продуктов на сайтах, сделанных на основе истории просмотров.
Технология обещает стать повсеместно распространённой и в науке. Будущие радиообсерватории будут использовать ГО для поиска значимых сигналов в массивах данных, которые иначе и не разгребёшь. Детекторы гравитационных волн будут использовать их для понимания и устранения мелких шумов. Издатели будут использовать их для фильтрации и пометки миллионов исследовательских работ и книг. Некоторые считают, что в итоге компьютеры при помощи ГО смогут продемонстрировать воображение и творческие способности. «Можно будет просто закинуть в машину данные, и она вернёт вам законы природы»,- говорит Жан-Рох Влиман [Jean-Roch Vlimant], физик из Калифорнийского технологического института.
Но такие прорывы сделают проблему чёрного ящика ещё более острой. Как именно машина находит значимые сигналы? Как можно быть уверенным, что её выводы верны? Насколько люди должны доверять глубокому обучению? «Думаю, что с этими алгоритмами мы вынуждены уступать»,- говорит специалист по робототехнике Ход Липсон [Hod Lipson] из Колумбийского университета в Нью-Йорке. Он сравнивает ситуацию со встречей с разумными инопланетянами, глаза которых видят не только красный, зелёный и голубой, но и четвёртый цвет. По его словам, людям будет очень сложно понять, как эти инопланетяне видят мир, а им – объяснить это нам. У компьютеров будут те же проблемы с объяснением своих решений, говорит он. «В какой-то момент это начнёт напоминать попытки объяснить Шекспира собаке».
Встретив такие проблемы, исследователи ИИ реагируют так же, как Помело – вскрывают чёрный ящик и выполняют действия, напоминающие неврологию, для понимания работы сетей. Ответы не интуитивные, говорит Винчезо Инноченте [Vincenzo Innocente], физик из ЦЕРН, первым применивший ИИ в своей области. «Как учёный я не удовлетворён простым умением отличать собак от кошек. Учёный должен иметь возможность сказать: разница в том-то и в том-то».
Хорошая поездка
Первая нейросеть была создана в начале 1950-х, почти сразу после появления компьютеров, способных работать по нужным алгоритмам. Идея в том, чтобы эмулировать работу небольших счётных модулей – нейронов – расположенных слоями и соединённых с цифровыми «синапсами». Каждый модуль в нижнем слое принимает внешние данные, например, пиксели картинки, затем распространяет эту информацию вверх некоторым из модулей следующего слоя. Каждый модуль во втором слое интегрирует входные данные от первого слоя по простому математическому правилу, и передаёт результат далее. В итоге верхний слой выдаёт ответ – например, относит исходное изображение к «кошкам» или «собакам».
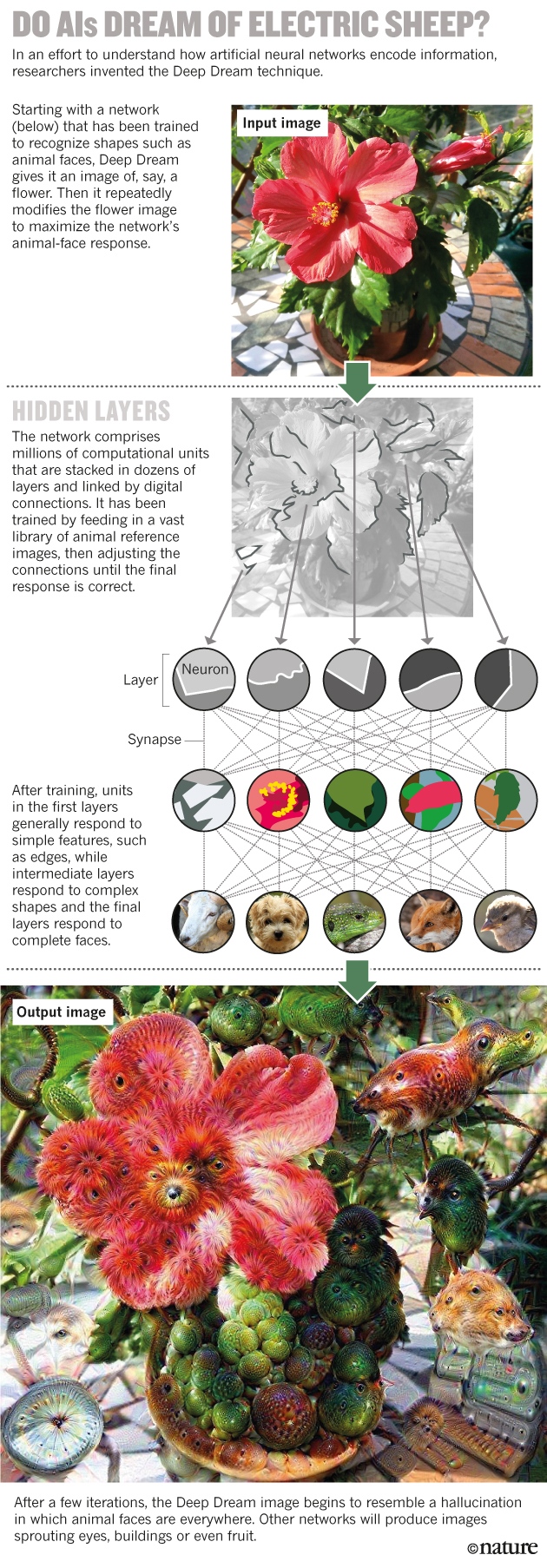
Снятся ли ИИ электроовцы? Технология «Глубокий сон» (Deep Dream) даёт в качестве входных данных для нейросети, натренированной на распознавание лиц, изображение, допустим, цветка – а затем последовательно меняет его, чтобы получить максимальный отклик от нейросети.
После тренировки первый слой сети в среднем реагирует на простые формы вроде границ, средние – на сложные формы, а последний уже работает с лицами целиком.
Результат работы Deep Dream напоминает галлюцинацию.
Возможности таких сетей проистекают из их способности обучаться. Обучаясь на начальном наборе данных с заданными правильными ответами, они постепенно улучшают свои характеристики, подстраивая влияние всех связей, чтобы выдавать правильные результаты. Процесс эмулирует обучение мозга, усиливающего и ослабляющего синапсы, и даёт на выходе сеть, способную классифицировать данные, изначально не входившие в тренировочный набор.
Возможность обучения соблазняла физиков из ЦЕРН в 1990-х годах, когда они одними из первых приспосабливали большие нейросети к работе на науку. Нейросети сильно помогли в реконструкции траекторий субатомной шрапнели, разлетающейся в стороны при столкновениях частиц на Большом адронном коллайдере.
Эта форма обучения также является причиной того, что информация очень сильно размазана по сети: как и в мозгу, её память закодирована в силе различных соединений, а не хранится в определённых местах, как в привычной базе данных. «Где в вашем мозгу хранится первая цифра вашего телефонного номера? Возможно, в наборе синапсов, возможно, недалеко от остальных цифр»,- говорит Пьер Балди [Pierre Baldi], специалист по машинному обучению (МО) из Калифорнийского университета. Но там нет определённой последовательности битов, кодирующих номер. В результате, как говорит специалист по информатике Джефф Клюн [Jeff Clune] из Вайомингского университета, «хоть мы и создаём эти сети, мы можем понять их не лучше, чем человеческий мозг».
Для учёных, работающих с большими данными, это значит, что ГО нужно использовать осторожно. Андреа Ведальди [Andrea Vedaldi], специалист по информатике из Оксфордского университета поясняет: представьте, что в будущем нейросеть натренируют на маммограммах, на которых будет отмечено, появился ли у исследуемых женщин рак груди. После этого, допустим, что ткани некоей здоровой женщины покажутся машине подверженными заболеванию. «Нейросеть может обучиться распознавать онкомаркеры – те, о которых мы не знаем, но которые могут предсказывать рак».
Но если машина не сможет объяснить, как она это определяет, то, по словам Ведальди, для врачей и пациентов это станет серьёзной дилеммой. Женщине и так нелегко подвергнуться превентивному удалению грудной железы из-за наличия генетических особенностей, которые могут привести к возникновению рака. И сделать такой выбор будет ещё сложнее, поскольку будет даже неизвестно, что это за фактор – даже если предсказания машины окажутся точными.
«Проблема в том, что знания встраиваются в сеть, а не в нас»,- говорит Майкл Тайка [Michael Tyka], биофизик и программист Google. «Поняли ли мы что-нибудь? Нет – это сеть поняла».
Несколько групп учёных занялись проблемой чёрного ящика в 2012 году. Команда под руководством Джоффри Хинтона [Geoffrey Hinton], специалиста по МО из Торонтского университета, участвовала в соревновании по компьютерному зрению, и впервые продемонстрировала, что применение ГО для классификации фотографий из базы данных, содержащей 1,2 миллиона изображений, превзошла любой другой подход с использованием ИИ.
Разбираясь в том, как это возможно, группа Ведальди взяла алгоритмы Хинтона, предназначенные для улучшения нейросети, и прогнала их задом наперёд. Вместо обучения сети на правильную интерпретацию ответа, команда взяла предварительно натренированные сети и попыталась воссоздать картинки, благодаря которым они тренировались. Это помогло исследователям определить, как машина представляет некоторые особенности – всё было так, будто они спрашивали некую гипотетическую нейросеть, предсказывающую рак, «Какая часть маммограммы натолкнула тебя на отметку о риске рака?».
В прошлом году Тайка и его коллеги из Google использовали похожий подход. Их алгоритм, который они назвали Deep Dream, начинает с картинки, допустим, цветка, и изменяет её так, чтобы улучшить отклик определённого нейрона верхнего уровня. Если нейрону нравится отмечать изображения, допустим, птиц, то изменённая картинка начнёт показывать птиц везде. Итоговые картинки напоминают видения под LSD, где птицы видны в лицах, зданиях и много где ещё. «Думаю, что это очень похоже на галлюцинацию»,- говорит Тайка, являющийся ещё и художником. Когда он с коллегами увидел потенциал алгоритма в творческой области, они решили сделать его свободным для скачивания. Уже через несколько дней эта тема стала вирусной.
Используя техники, максимизирующие выдачу любого нейрона, а не только одного из верхних, команда Клюна в 2014 году обнаружила, что проблема чёрного ящика может быть сложнее, чем казалась ранее. Нейросети очень легко обмануть при помощи картинок, воспринимаемых людьми как случайный шум или абстрактные узоры. К примеру, сеть может взять волнистые линии и решить, что это морская звезда, или перепутать чёрно-белые полоски со школьным автобусом. Более того, те же тенденции возникали и в сетях, натренированных на других наборах данных.
Исследователи предложили несколько вариантов решения проблемы с одурачиванием сетей, но общего решения пока не найдено. В реальных приложениях это может быть опасно. Один из пугающих сценариев, по мнению Клюна, состоит в том, что хакеры научаться пользоваться этими недостатками сетей. Они могут отправить робомобиль в рекламный щит, который тот примет за дорогу, или обмануть сканер сетчатки на входе в Белый дом. «Нужно засучить рукава и провести глубокие научные исследования с тем, чтобы сделать МО более надёжным и умным»,- заключает Клюн.
Такие проблемы заставили некоторых специалистов по информатике думать, что не стоит зацикливаться на одних только нейросетях. Зубин Гахрамани [Zoubin Ghahramani], исследователь МО в Кембриджском университете, говорит, что если ИИ должен давать ответы, которые людям легко интерпретировать, это приведёт к появлению «большого количества проблем, с которыми ГО не сможет помочь справиться». Один из довольно понятных научных подходов впервые был показан в 2009 году Липсоном и вычислительным биологом Майклом Шмидтом [Michael Schmidt], в то время работавшим в Корнеллском университете. Их алгоритм Eureqa продемонстрировал процесс переоткрытия законов ньютона путём наблюдения за простым механическим объектом – системой маятников – в движении.
Начав со случайной комбинации математических кирпичиков вроде +, -, синуса и косинуса, Eureqa методом проб и ошибок, схожим с дарвиновской эволюцией, меняет их, пока не приходит к описывающим данные формулам. Затем она предлагает эксперименты для проверки моделей. Одно из её преимуществ – простота, говорит Липсон. «У модели, выработанной Eureqa, обычно десяток параметров. У нейросети их миллионы».
На автопилоте
В прошлом году Гарахмани опубликовал алгоритм автоматизации работы учёного по данным, от сырых данных до готовой научной работы. Его софт Automatic Statistician, замечает тренды и аномалии в наборах данных и даёт заключение, включая подробное объяснение рассуждений. Эта прозрачность, по его словам, «совершенно критична» для применения в науке, но также важна и для коммерческого применения. К примеру, во многих странах банки, отказывающие в займах, по закону обязаны объяснить причину отказа – а это алгоритму ГО может быть не под силу.
Те же сомнения присущи и различным организациям, поясняет Элли Добсон [Ellie Dobson], директор по науке о данных в фирме Arundo Analytics в Осло. Если, допустим, в Британии что-то пойдёт не так из-за изменения базовой ставки, Банк Англии не может просто сказать «это всё из-за чёрного ящика».
Но, несмотря на все эти страхи, специалисты по информатике говорят, что попытки создать прозрачный ИИ должны быть дополнением к ГО, а не заменой этой технологии. Некоторые прозрачные техники могут хорошо работать в областях, уже описанных в виде набора абстрактных данных, но при этом не справляться с восприятием – процессом извлечения фактов из сырых данных.
В итоге, по их словам, сложные ответы, полученные благодаря МО, должны быть частью инструментария науки, поскольку реальный мир сложный. Для таких явлений, как погода или финансовый рынок, редукционистских, синтетических описаний может просто не существовать. «Есть вещи, которые нельзя описать словами»,- говорит Стефан Маллат [Stephane Mallat], математик-прикладник из парижской Политехнической школы. «Когда вы спрашиваете врача, почему он поставил такой диагноз, он опишет вам причины,- говорит он. – Но почему тогда нужно 20 лет, чтобы стать хорошим врачом? Потому что информацию получают не только лишь из книг».
По мнению Балди, учёный должен принять ГО и не сильно париться по поводу чёрных ящиков. У них ведь есть такой чёрный ящик в голове. «Вы постоянно используете мозг, вы всегда доверяете ему, и вы не понимаете, как он работает».
Комментарии (41)
dfgwer
22.10.2016 02:35Один из пугающих сценариев, по мнению Клюна, состоит в том, что хакеры научаться пользоваться этими недостатками сетей. Они могут отправить робомобиль в рекламный щит, который тот примет за дорогу
Это задача такой же сложности, как убедить человека, что дорога идет в рекламный щит и там нет препятствий.
Nubus
22.10.2016 03:35Ой, мало-ли вы видели автомобилей в зонах глубокой
жнепроезжей местности? Оптическая иллюзия, отвлекающий маневр, какая-то вспышка и привет кювет! Для железки на борту раздражители могут быть иного рода, но результат будет удручающий. Но только практика и обучение кровью и жертвами в данном случае покажет ошибки и именно это сейчас и пытаются ученые предотвратить эксперементируя с черным ящиком.dfgwer
22.10.2016 05:17-1Но нарисовать такой рекламный щит, в который въедет хотя бы 1% автомобилистов…

Fagot63
22.10.2016 12:22+1Легко. Берем картинку по эротичней и вуаля! Всплеск количества аварий возле этого щита. Проверено на практике.

Deosis
22.10.2016 12:52Первая ссылка в поиске: 3д картины. Обмануть зрение человека проще, чем вы думаете.

black_semargl
23.10.2016 01:34+1Наивно думать, что нейросети автопилота дадут нарабатывать опыт самостоятельно.
Так что в рекламный щит въедут 99% пользователей автопилота от v123.4.5 до v134.5.6

RusikR2D2
22.10.2016 06:58тут идея не в том, чтобы подсунуть ИИ фотореалистичную картинку, а в том, чтобы дать некую абстракцию, от которой ИИ «переклинит» и он будет действовать неадекватно. Наверное, можно сравнить с припадками людей при просмотре некоторых видео. И проблема (как и с этими людьми), что неизвестно, что вызовет такую реакцию до того момента, пока оно с этим не столкнется.
Кстати, картинка тоже может, наверное, как-то обмануть — что-то типа асфальтово-серой машины на фоне асфальта в контровом свете. или как в той истории с теслой, заехавшей под грузовик (вроде бы там тоже была проблема с цветом машины)
alexmay
22.10.2016 10:50Эпилепсия у нейронных сетей
staticlab
22.10.2016 12:36Если сеть будет с обратной связью, и информация распространяется по ней с некоторой частотой, то, по идее, может существовать такой входной поток данных, который войдёт в резонанс с сетью, и произойдёт её самовозбуждение. Почти как микрофонный эффект. То есть да, практически как эпилепсия у человека.
Dum_spiro_spero
22.10.2016 14:55Вставлю пятьдесят пять копеек.
Недообучение.
Не будем далеко ходить — возьмем мою сеть. Как-то когда моя сеть была плохообученной я направил авто в бетонный блок потому, что мне ПОКАЗАЛОСЬ, что это большой полиэтиленовый пакет. К счастью рядом был инструктор, он занервничал, вовремя остановил авто — и тут я гм… понял ошибку.
Далее — сложность нейросети может быть и недостатком.
Прошло много лет. Я еду ночью задумавшись о вечном, блик от чего-то принимаю за фары и резко дергаюсь вправо. К счастью никого там не было, да и на встречке не было.
Т.о. — моя нейросеть совершила типичные ошибки классификации.
— По поводу хороших врачей — я думаю все же, что экспертная система вполне может справиться с задачей просто в силу ограниченности информации которую может воспринять человек.
Пусть приходит человек с симптоматикой, задача — поставить диагноз и предложить лечение.
1. Опрос по симптоматике. Важный момент — распознать, что пациент говорит правду, уверен или неуверен в ответе.
2. Выдвижение гипотезы о диагнозе, уточнение опроса. Известный пример — симптом: боль в правом боку. Гипотеза — аппендицит. Уточнение — а болит когда нажимаем или когда отпускаем?
3. Связь диагноза с другими заболеваниями — здесь от врача требуется широта мышления.
4. Назначение лечения с учетом противопоказаний и пункта три.
Здесь могут начаться обратные связи. В результате схема приема лекарств может быть достаточно сложной.
Я думаю нейросети здесь не понадобятся — если мы имеем дело с известными заболеваниями.
А вот новую информацию типа у живущих на двадцатых этажах в течение двадцати лет повышен риск заболевания X — с помощью нейросетей найти видимо можно.
В общем я за кибермедицину обеими руками.
Но для этого надо создавать такую экспертную систему и у хороших врачей выспрашивать то, что составляет предмет их знаний и опыта. Не все захотят. )
Всем здоровья!
biseptol
22.10.2016 19:33+1Можно сильно «сбивать с толку» классификаторы, добавляя в картинку практически незаметный для человека шум. Для нас это две одинаковые картинки, для НС — совершенно разные.
https://arxiv.org/pdf/1412.1897v4.pdf
https://arxiv.org/pdf/1511.04599v3.pdf
vc9ufi
24.10.2016 14:40еще надо будет обмануть радары, подменить сервис обновления карт и в перспективе данные от других машин.


red75prim
22.10.2016 15:15+1По-моему, решение этой проблемы очевидно — если мы не можем разобраться как сеть решает задачу, то нужно добавить ещё одну сеть, которая будет решать эту задачу. Добавить сеть, которая будет учиться соотносить структуру весов связей (или структуру активаций) скрытых слоёв с описанием способа получения результата.
Естественно, то, что решение очевидно, не означает, что его легко реализовать. Тем более, что это решение можно назвать частью механизма самосознания, которое появилось у животных относительно недавно с эволюционной точки зрения. А значит представляет собой что-то более сложное, чем обучение соответствиям стимул-реакция, которым в основном занимаются существующие реализации нейросетей.

sumanai
22.10.2016 15:51> то нужно добавить ещё одну сеть, которая будет решать эту задачу.
А для расшифровки её данных нужна ещё одна сеть.
biseptol
22.10.2016 19:35Для начала надо найти НС, которую мы «не понимаем».
red75prim
22.10.2016 19:58Речь идёт не о понимании общих принципов работы глубоких нейросетей, а об определении того как конкретная обученная нейросеть принимает решения о классификации входных данных, и насколько релевантны используемые ею признаки.
biseptol
22.10.2016 20:04А я про это и говорю.
red75prim
22.10.2016 20:22И? Какие же методы есть для определения того, как конкретная сеть принимает решения?
Heatmaps? https://arxiv.org/abs/1509.06321
Так можно понять как сеть принимает решение по конкретной картинке, а не общую структуру используемых ей признаков.
biseptol
22.10.2016 23:09Не очень понимаю, что не устраивает в этом подходе. Если это CNN, вы можете визуализировать feature maps на каждом слое, т.е. уже понятно, что оно обучилось таким-то паттернам, что такие-то fm реагируют на складки одежды, такие-то на шерсть, такие-то на глаза, и проч. Это ли не «структура используемых ею признаков»?
red75prim
23.10.2016 10:14На не очень глубоких сверточных уровнях — да, можно посмотреть на что реагируют конкретные нейроны. А дальше, когда начинаются полносвязные слои, можно только догадываться.
Heatmaps это удобно, но ни фига не гарантирует, что рукописная тройка, сдвинутая на 3 пиксела, не распознается как 9.
Да, можно насемплить картинок, которые обеспечивают высокую активацию нейрона на глубоком уровне, и потом попытаться догадаться на что он реагирует. Но, опять-же, это только догадки.
Примерно то же происходит и в мозгу. С визуальными зонами V1-V4, неплохо разобрались, а что происходит дальше, понимает уже только сам мозг. По-своему.
biseptol
23.10.2016 16:02Да, можно насемплить картинок, которые обеспечивают высокую активацию нейрона на глубоком уровне, и потом попытаться догадаться на что он реагирует.
Или взять высокое значение у каждого отдельного нейрона, и вычислить градиенты далее вниз, до исходной картинки. Как минимум, для первого fc слоя должно сработать.
Но, опять-же, это только догадки.
А что будет не «догадками», по-вашему? Диалог на человеческом языке, чтобы мы могли задавать ей вопросы?red75prim
23.10.2016 16:55Или взять высокое значение у каждого отдельного нейрона, и вычислить градиенты далее вниз, до исходной картинки. Как минимум, для первого fc слоя должно сработать.
Получится мешанина из разных признаков, скорее всего.
А что будет не «догадками», по-вашему? Диалог на человеческом языке, чтобы мы могли задавать ей вопросы?
В идеале — да. Будет полезно для верификации. Кроме того, полученные высокоуровневые описания могут использоваться самой сетью для регуляризации, приближая её восприятие к человеческому.
biseptol
23.10.2016 17:16В идеале — да.
В таком случае, мы вообще живем в мире «догадок», и ни о чем не имеем ни малейшего представления. Даже не можем объяснить, как работает код на C++.
Yury_Reshetov
22.10.2016 15:15-1Попытки перевести математическую модель, заданную непрерывным счислением в пропозициональную (бинарную) логику, заведомо обречены на провал (дискретность слишком мала). Очевидное для компьютера, становится неочевидным для человеческого мышления.
Если ещё учесть, что человеческое мышление зачастую затрудняется разбираться в пропозициональной логике (не все в ней компетентны, не говоря о том, что наше мышление не рационально, а ассоциативно), то задача практически неразрешима, за исключением некоторых тривиальных случаев, используемых в качестве примитивных примеров, с целью проверки работоспособности алгоритмов машинного обучения (например, линейно-сепарабельные задачи).

kissarat
22.10.2016 15:15-2Какой ИИ? Это — фантазии прошлого века… Благодаря развития интернету и средств представления информации развивается общий интеллект, который, грубо говоря, может в может быть в конкретном устройстве лишь частично
biseptol
22.10.2016 19:28+1Что «видит» нейросеть, и как она «принимает решения», достаточно изучено, и автор пишет странные вещи:
К примеру, во многих странах банки, отказывающие в займах, по закону обязаны объяснить причину отказа – а это алгоритму ГО может быть не под силу
«something a deep-learning algorithm might not be able to do»
Т.е. этому «deep-learning algorithm» (это что вообще такое?) может быть «не под силу» «объяснить», как он принимает решения? Как автор себе это представляет? LSTM, которая генерит текст по весам/активациям нейронов?
Такое ощущение, что товарищ набрался знаний о NN из статеек в научпопе. Как он пробрался в Nature с таким качеством текста и уровнем погружения в тему — хороший вопрос к редакции.
pda0
На самом деле во всех этих статьях сквозит одна и та же проблема. ИИ учат без учителя. Причём настолько обще, что «он» для «себя» вырабатывает собственный язык (систему понятий), который мы не понимаем, а потом мы пытаемся задавать «ему» вопросы и удивляемся, что вместо разговора какая-то фигня выходит. Когда родители учат малыша, его направляют и поправляют. Вот это — одеяло, а вот это — занавеска. Не наоборот.
В случае же с ИИ на него просто вываливают две пачки фоток, одну с занавесками, а другую без. А потом подсовывают ещё фотку и просят сказать — есть ли там занавеска. Потом дебажат и удивляются от того, что под занавесками ИИ понимал батареи. Ну или как здесь — решил, что «ему» надо держаться границы травы и асфальта.
calx
Роль родителя состоит в том, чтобы научить ребёнка пользоваться общепринятыми названиями для идентификации занавески и одеяла. Отличать же занавеску от одеяла ребёнок учится сам, иначе не было бы и смысла ему говорить, что есть что.
pda0
Ну да, это называется речь. Позволяет разным интеллектам обмениваться информацией. Ставить друг другу задачи, понимать их условия и выдавать осмысленный ответ. Без этого современные нейронки не более чем маугли. Они могут справляться с задачей, но не понимают что именно мы от них хотим. В результате среди хорошей работы получаются глюки. Типа диван с леопардовой расцветкой опознаётся как леопард. Потому что человек думал, что учит отличать кошачьих, а нейросеть «нашла» для себя более простой знаменатель — характерные паттерны на шкуре. Или чём угодно другом.
trapwalker
Точно. И это говорит о том, что нейронные сети у нас довольно слаборазвиты. Эдакие смышленые мышки, которых удалось обучить простым трюкам, смысла которых они не понимают и не поймут, поскольку это уже за гранью их когнитивных способностей. Зато свои «лабиринтики» они будут щелкать как орешки, получше любого человека.
Mad__Max
Ну так используемые сейчас искусственные НС как количественно(по количеству нейронов и синапсов/весов связей), так и качественно (в плане сложности и уровня внутренней организации) даже до мозга примитивных мышек не дотягивают. Где-то на уровне между высшими насекомыми и мышами, причем ближе к насекомым. Больше производительность железа и моделирующих алгоритмов не позволяет использовать.
А от них почему-то неоправданно уже ожидают результатов сравнимых с человеческим мышлением.
Хотя это не «маугли» (полноценный мозг, но с дефицитом правильного обучения), а именно мышки — с которыми хоть в лепешку разбейся, а говорить, понимать речь или решать абстрактные сложные задачи никогда не научишь. Максимум как раз можно натренировать нескольким простым трюкам.
black_semargl
Ну тут несколько сложнее — НС можно учить например распознавать речь и не учить всему остальному без чего мышка минуты не проживёт.
Mad__Max
Ну да, только за счет того что весь электронный «мозг» можно в отличии от биологического выделить на решение только одной единственной узкой задачи и получается добиваться каких-то заметных результатов на такой слабой базе.
gkvert
А разве
это не обучение с учителем? Этим действием мы условному ребенку говорим: «Вот на этих фотографиях есть занавески, а на других может что-то и похожее на занавески, но это уже не занавески». А потом условному ребенку показываем новую картинку не из набора и спрашиваем усвоил ли он как выглядят занавески. Что б ИИ не перепутал случайно занавеску с батареей его конечно нужно дольше обучать и расказать про батареи :).
pda0
Это скорее не обучение с учителем, а обучение маугли с животным. Учитель бы вникал, разжёвывал и убеждался бы, что материал усваивается правильно. А это как мама-кошка притащила котёнку полузадушенного мыша.
Так что народ опять слишком оптимистично использует термины. Для нормального обучения придётся что-то другое придумывать. Например, обучение с наставником. :)
trapwalker
С наставником ничего принципиально не поменяется. Ну добавится еще парочка слоев в нейронную сеть, а выборка будет протегирована более детально, указывая обучающейся сети на больше признаков с учетом ее собственных предположений, то есть появится обратная связь. Это просто модификация архитектуры и учитель не сильно отличается от наставника по своей сути. Где-то в школах плохие учителя заставляют учеников зубрить и повторять, а где-то хорошие наставники стараются добиться понимания. Как определить «понимание» это или просто классификация по набору заученных признаков с полуинтуитивным многокритериальным выбором? Интуиция и рефлексы отличаются от построения внутренней модели НИКАК. Разве что сложностью и разнообразностью тестов адекватности этой модели или что там у интуиции вместо нее.
pda0
Ну, как минимум пример с занавесками из прошлой похожей статьи, где и правда с занавесками работали и для отладки создали мега инструмент, трассирующий работу сети и показывающий куда она «смотрит». Так вместо негатива радоваться надо было, теперь к обучающим алгоритмам, тому же обратному распространению ошибки можно гибкости добавлять, заставляя сеть «смотреть» в нужное место.
Уже прогресс, хотя бы уверенны будем, что обучая проверять на наличие занавесок, мы на занавески смотреть заставляем.
trapwalker
Так я об этом и говорил. Это лишь новый инструмент дрессировки или как ни назови этот процесс обучения. Результат один: имеем организм, реагирующий на занавески.
Не факт, кстати, что это хорошая идея: заставлять смотреть на занавески. Если сеть смотрела только на цветочки на занавесках — это лишь признак плохой обучающей выборки с малым разнообразием. В реальных задачах, особенно более сложных и менее явных даже для человека, например поиск онко-маркеров, бывает, наверно, даже полезно не лезть со своими подсказками. Может быть какой-то конгломерат нейронов обучится особенный тип малозаметных занавесок различать по кронштейну и муару тени. "Заставляя смотреть" можно нечаянно подавить такой нейрон.
Зато, вот, выяснять куда она смотрит для выявления новых знаний, закономерностей и уточнения моделей — это здорово.
pda0
Сеть там смотрела вообще не на окно, а как я и написал, под него, на батареи. (Реально, оказалась, что область окна не влияет на результат.) Т.е. обучающий думал, что учит определять занавески, а сеть обучилась на батареи. И, соответсвенно, человек думал, что спрашивает «есть ли тут занавески», а сеть «понимала» его вопрос, как «есть ли тут батареи». И с этой задачей неплохо справлялась.
black_semargl
Ребёнка можно спросить «а почему ты думаешь, что это занавеска?»
и если он ответит «потому что в цветочек» — упс…