Все начиналось довольно обыденно… Зачитывался Рихтером и усиленно штудировал Шилдта. Думал, что буду заниматься разработкой под .NET, но судьба на первом месяце работы распорядилась иначе. Один из сотрудников неожиданно покинул проект и во вновь образовавшуюся дыру докинули свежего людского материала. Именно тогда и началось мое знакомство с SQL Server.
С тех пор прошло чуть меньше 6 лет и вспомнить можно многое…
Про бывшего клиента Джозефа из Англии, который переосмыслил жизнь, за время отпуска в Таиланде, и в моем скайпе стал подписываться Жозефиной. Про веселых соседей по офису, с которыми приходилось сидеть в одной комнате: один страдал от аллергии на свежий воздух, а другой маялся от неразделенной любви к С++ дополняя это аллергией на солнечный свет. Один раз по команде свыше пришлось на время стать Александром отцом двух детей, чтобы изображать из себя обросшего скилами сениора по JS.
Но самый лютый треш, наверное, связан с историей про резиновую утку-пищалку. Один коллега снимал ею стресс и, однажды, в порыве эмоций, отгрыз ей голову. С тех пор уточка потеряла прежний лоск и вскоре была заменена на мячик, который он пытался иногда грызть… увы, уже безуспешно.
К чему это было рассказано? Если хотите посвятить свою жизнь работе с базами данных, то первое чему нужно научиться… так это стрессоустойчивости. Второе – это взять на вооружение несколько правил при написании запросов на T-SQL, которые многие из начинающих разработчиков не знают или попросту игнорируют, а потом сидят и ломают голову… почему что-то не работает?
1. Data Types
Самое основное, с чего начинается большинство проблем при работе с SQL Server — это неправильный выбор типов данных. Возьмем гипотетический пример с двумя идентичными по своей сути таблицами:
DECLARE @Employees1 TABLE (
EmployeeID BIGINT PRIMARY KEY
, IsMale VARCHAR(3)
, BirthDate VARCHAR(20)
)
INSERT INTO @Employees1
VALUES (123, 'YES', '2012-09-01')DECLARE @Employees2 TABLE (
EmployeeID INT PRIMARY KEY
, IsMale BIT
, BirthDate DATE
)
INSERT INTO @Employees2
VALUES (123, 1, '2012-09-01')Выполним запрос и посмотрим в чем разница:
DECLARE @BirthDate DATE = '2012-09-01'
SELECT * FROM @Employees1 WHERE BirthDate = @BirthDate
SELECT * FROM @Employees2 WHERE BirthDate = @BirthDate
В первом случае, типы данных более избыточные, чем могли бы быть. Зачем хранить битовый признак как строку YES/NO? Зачем хранить дату как строку? Зачем BIGINT по таблице с сотрудниками? Чем простой INT не подошел?
Это плохо по нескольким причинам: таблицы будут занимать больше места на диске, нужно больше страниц прочитать с диска и больше страниц разместить в BufferPool чтобы оперировать этими данными. Кроме того, могут быть и еще серьезные проблемы с производительностью — вопросительный знак об этом легко намекает, но об этом поговорим позже.
2. *
Часто приходилось встречать «картину маслом»: из таблицы берутся все данные, а потом на клиенте через DataReader выбираются только те столбцы, которые реально нужны. Это крайне не эффективно, поэтому лучше не использовать подобной практики:
USE AdventureWorks2014
GO
SET STATISTICS TIME, IO ON
SELECT *
FROM Person.Person
SELECT BusinessEntityID
, FirstName
, MiddleName
, LastName
FROM Person.Person
SET STATISTICS TIME, IO OFFРазница будет и во времени выполнении запроса и в том, что будет возможность сделать меньше логических чтений за счет покрывающего индекса:
Table 'Person'. Scan count 1, logical reads 3819, physical reads 3, ...
SQL Server Execution Times:
CPU time = 31 ms, elapsed time = 1235 ms.
Table 'Person'. Scan count 1, logical reads 109, physical reads 1, ...
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 227 ms.3. Alias
Создадим таблицу:
USE AdventureWorks2014
GO
IF OBJECT_ID('Sales.UserCurrency') IS NOT NULL
DROP TABLE Sales.UserCurrency
GO
CREATE TABLE Sales.UserCurrency (
CurrencyCode NCHAR(3) PRIMARY KEY
)
INSERT INTO Sales.UserCurrency
VALUES ('USD')Предположим у нас есть запрос, который возвращает количество идентичных строк в обоих таблицах:
SELECT COUNT_BIG(*)
FROM Sales.Currency
WHERE CurrencyCode IN (
SELECT CurrencyCode
FROM Sales.UserCurrency
)И все будет работать, как мы ожидаем, до тех пор, пока кто-то не захочет переименовать столбец в таблице Sales.UserCurrency:
EXEC sys.sp_rename 'Sales.UserCurrency.CurrencyCode', 'Code', 'COLUMN'Выполним запрос и увидим, что возвращается не 1 строка, а все которые есть в Sales.Currency. При построении плана выполнения SQL Server на этапе биндинга посмотрит на столбцы Sales.UserCurrency не найдет там CurrencyCode и подумает что этот столбец относится к таблице Sales.Currency после чего оптимизатор условие CurrencyCode = CurrencyCode отбросит.
Мораль — используйте алиасы:
SELECT COUNT_BIG(*)
FROM Sales.Currency c
WHERE c.CurrencyCode IN (
SELECT u.CurrencyCode
FROM Sales.UserCurrency u
)4. Column order
Предположим у нас есть какая-то таблица:
IF OBJECT_ID('dbo.DatePeriod') IS NOT NULL
DROP TABLE dbo.DatePeriod
GO
CREATE TABLE dbo.DatePeriod (
StartDate DATE
, EndDate DATE
)И данные в нее мы всегда вставляем из того предположения, что мы знаем как по порядку располагаются столбцы:
INSERT INTO dbo.DatePeriod
SELECT '2015-01-01', '2015-01-31'Потом в один прекрасный момент, кто-то поменяет порядок столбцов:
CREATE TABLE dbo.DatePeriod (
EndDate DATE
, StartDate DATE
)И данные будут уже вставляться не в те столбцы в которые ожидает разработчик. Поэтому всегда рекомендуется явно указывать столбцы в конструкции INSERT:
INSERT INTO dbo.DatePeriod (StartDate, EndDate)
SELECT '2015-01-01', '2015-01-31'Есть еще один интересный пример:
SELECT TOP(1) *
FROM dbo.DatePeriod
ORDER BY 2 DESCПо какому столбцу будет идти сортировка? А все зависит от текущего порядка в таблице. Если кто-то его изменит, то и запрос будет выводить не то что мы ожидаем.
5. NOT IN vs NULL
Бесспорный лидер среди вопросов на собеседовании Junior DB Developer — конструкция NOT IN.
Например, нужно написать пару запросов: вернуть все записи из первой таблицы, которых нет во второй и наоборот. Очень часто начинающие разработчики не заморачиваются и используют IN и NOT IN:
DECLARE @t1 TABLE (t1 INT, UNIQUE CLUSTERED(t1))
INSERT INTO @t1 VALUES (1), (2)
DECLARE @t2 TABLE (t2 INT, UNIQUE CLUSTERED(t2))
INSERT INTO @t2 VALUES (1)
SELECT *
FROM @t1
WHERE t1 NOT IN (SELECT t2 FROM @t2)
SELECT *
FROM @t1
WHERE t1 IN (SELECT t2 FROM @t2)Первый запрос вернул нам двойку, второй — единицу. Давайте теперь во вторую таблицу добавим еще одно значение — NULL:
INSERT INTO @t2 VALUES (1), (NULL)При выполнении запроса с NOT IN мы не получим никаких результатов. Неужели какая-то магия вмешалась — IN работает, а NOT IN отказывается. Это первое, что нужно «понять и простить» при работе с SQL Server, который при операции сравнения руководствуется третичной логикой: TRUE, FALSE, UNKNOWN.
При выполнении SQL Server интерпретирует условие IN:
a IN (1, NULL) == a=1 OR a=NULLNOT IN:
a NOT IN (1, NULL) == a<>1 AND a<>NULLПри сравнении любого значения с NULL возвращается UNKNOWN. 1=NULL, NULL=NULL. Результат будет один — UNKNOWN. А поскольку у нас в условии используется оператор AND, то все выражение вернет неопределенное значение и в результате будет пусто.
Написано немного скучно. Но важно понимать, что такая ситуация встречается достаточно часто. Например, раньше столбец был объявлен как NOT NULL, потом какой-то добрый человек разрешил записывать в нее NULL значение. Итог: у клиента перестает работать отчет после того, как в таблицу попадет хотя бы одно NULL значение.
Что делать? Можно явно отбрасывать NULL значения:
SELECT *
FROM @t1
WHERE t1 NOT IN (
SELECT t2
FROM @t2
WHERE t2 IS NOT NULL
)Можно использовать EXCEPT:
SELECT * FROM @t1
EXCEPT
SELECT * FROM @t2Если нет желания много думать, то проще использовать NOT EXISTS:
SELECT *
FROM @t1
WHERE NOT EXISTS(
SELECT 1
FROM @t2
WHERE t1 = t2
)Какой вариант запроса более оптимальный? Предпочтительнее выглядит последний вариант с NOT EXISTS, который генерирует более оптимальный predicate pushdown оператор при доступе к данным из второй таблицы.
Вообще с NULL значениями много приколов. Можно поиграться с такими вот запросами:
USE AdventureWorks2014
GO
SELECT COUNT_BIG(*)
FROM Production.Product
SELECT COUNT_BIG(*)
FROM Production.Product
WHERE Color = 'Grey'
SELECT COUNT_BIG(*)
FROM Production.Product
WHERE Color <> 'Grey'и не получить ожидаемого результата только потому, что для NULL значений предусмотрены отдельные операторы сравнения:
SELECT COUNT_BIG(*)
FROM Production.Product
WHERE Color IS NULL
SELECT COUNT_BIG(*)
FROM Production.Product
WHERE Color IS NOT NULLЕще курьезнее выглядит ситуация с CHECK констрейнтами:
IF OBJECT_ID('tempdb.dbo.#temp') IS NOT NULL
DROP TABLE #temp
GO
CREATE TABLE #temp (
Color VARCHAR(15) --NULL
, CONSTRAINT CK CHECK (Color IN ('Black', 'White'))
)Мы создаем таблицу в которую разрешаем записывать только белые и черные цвета:
INSERT INTO #temp VALUES ('Black')(1 row(s) affected)Все работает как мы ожидаем:
INSERT INTO #temp VALUES ('Red')The INSERT statement conflicted with the CHECK constraint...
The statement has been terminated.Но давайте вставим NULL:
INSERT INTO #temp VALUES (NULL)(1 row(s) affected)Наш CHECK констрейнт не сработал, потому что для записи достаточно условия NOT FALSE, т.е. и TRUE и UNKNOWN подходят за милую душу. Есть несколько вариантов обойти эту особенность поведения: явно объявлять столбец как NOT NULL либо учитывать NULL в ограничении.
6. Date format
Еще часто спотыкаются на различных нюансах с типами данных. Например, нужно получить текущее время. Выполнили функцию GETDATE:
SELECT GETDATE()Скопировали результат, вставили его в запрос как есть и убрали время:
SELECT *
FROM sys.objects
WHERE create_date < '2016-11-14'Корректно ли так делать?
Дата задается строковой константой, и в некоторой степени SQL Server позволяет вольности при ее написании:
SET LANGUAGE English
SET DATEFORMAT DMY
DECLARE @d1 DATETIME = '05/12/2016'
, @d2 DATETIME = '2016/12/05'
, @d3 DATETIME = '2016-12-05'
, @d4 DATETIME = '05-dec-2016'
SELECT @d1, @d2, @d3, @d4Все значения практически везде однозначно интерпретируются:
----------- ----------- ----------- -----------
2016-12-05 2016-05-12 2016-05-12 2016-12-05 И это не будет приводить к проблемам до тех пор, пока запрос с такой бизнес-логикой не начнут выполнять на другом сервере, на котором настройки могут отличаться:
SET DATEFORMAT MDY
DECLARE @d1 DATETIME = '05/12/2016'
, @d2 DATETIME = '2016/12/05'
, @d3 DATETIME = '2016-12-05'
, @d4 DATETIME = '05-dec-2016'
SELECT @d1, @d2, @d3, @d4Все эти варианты могут привести к неверному толкованию даты:
----------- ----------- ----------- -----------
2016-05-12 2016-12-05 2016-12-05 2016-12-05 Более того, подобный код может привести к ошибке как явной так и скрытой. Например, нам нужно вставить данные в таблицу. На тестовом сервере все прекрасно работает:
DECLARE @t TABLE (a DATETIME)
INSERT INTO @t VALUES ('05/13/2016')А у клиента, из-за разницы в настройках сервера, вот такой запрос будет приводить к проблемам:
DECLARE @t TABLE (a DATETIME)
SET DATEFORMAT DMY
INSERT INTO @t VALUES ('05/13/2016')Msg 242, Level 16, State 3, Line 28
The conversion of a varchar data type to a datetime data type resulted in an out-of-range value.Так в каком же формате задавать константы для дат? Давайте посмотрим на еще один пример:
SET DATEFORMAT YMD
SET LANGUAGE English
DECLARE @d1 DATETIME = '2016/01/12'
, @d2 DATETIME = '2016-01-12'
, @d3 DATETIME = '12-jan-2016'
, @d4 DATETIME = '20160112'
SELECT @d1, @d2, @d3, @d4
GO
SET LANGUAGE Deutsch
DECLARE @d1 DATETIME = '2016/01/12'
, @d2 DATETIME = '2016-01-12'
, @d3 DATETIME = '12-jan-2016'
, @d4 DATETIME = '20160112'
SELECT @d1, @d2, @d3, @d4В зависимости от установленного языка, константы также могут по-разному интерпретироваться:
----------- ----------- ----------- -----------
2016-01-12 2016-01-12 2016-01-12 2016-01-12
----------- ----------- ----------- -----------
2016-12-01 2016-12-01 2016-01-12 2016-01-12 И напрашивается вывод использовать последние два варианта. Сразу скажу, что явно задавать месяц — это хорошая возможность наткнуться на «же не манж па сис жур» ошибку:
SET LANGUAGE French
DECLARE @d DATETIME = '12-jan-2016'Msg 241, Level 16, State 1, Line 29
Echec de la conversion de la date et/ou de l'heure a partir d'une chaine de caracteres.Итого — остается последний вариант. Если хотите, чтобы константы с датами однозначно толковались в системе вне зависимости от настроек и фазы Луны, то указывайте их в формате YYYYMMDD без всяких тильд, кавычек и слешей.
Еще стоит обратить внимание на различие в поведении некоторых типов данных:
SET LANGUAGE English
SET DATEFORMAT YMD
DECLARE @d1 DATE = '2016-01-12'
, @d2 DATETIME = '2016-01-12'
SELECT @d1, @d2
GO
SET LANGUAGE Deutsch
SET DATEFORMAT DMY
DECLARE @d1 DATE = '2016-01-12'
, @d2 DATETIME = '2016-01-12'
SELECT @d1, @d2В отличии от DATETIME, тип DATE корректно интерпретируется при различных настройках на сервере:
---------- ----------
2016-01-12 2016-01-12
---------- ----------
2016-01-12 2016-12-01Но нужно ли держать этот нюанс в голове? Вряд ли. Главное помните, что задавать даты нужно в формате YYYYMMDD и не будет никаких проблем.
7. Date filter
Далее рассмотрим, как фильтровать эффективно данные. Почему-то на DATETIME/DATE столбцы приходится наибольшее число костылей, так что с этого типа данных мы и начнем:
USE AdventureWorks2014
GO
UPDATE TOP(1) dbo.DatabaseLog
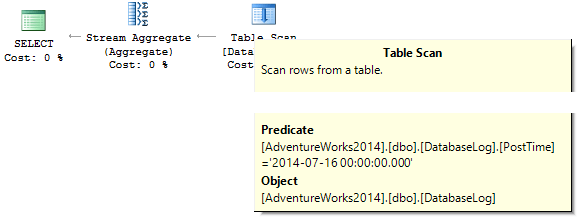
SET PostTime = '20140716 12:12:12'Теперь попробуем узнать, сколько строк вернет запрос за определенный день:
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE PostTime = '20140716'Запрос вернет 0. Почему? При построении плана SQL Server пытается преобразовать строковую константу к типу данных столбца, по которому идет фильтрация:
Создадим индекс:
CREATE NONCLUSTERED INDEX IX_PostTime ON dbo.DatabaseLog (PostTime)Есть правильные и неправильные варианты вывести требуемые данные. Например, обрезать время:
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE CONVERT(CHAR(8), PostTime, 112) = '20140716'
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE CAST(PostTime AS DATE) = '20140716'Или задать диапазон:
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE PostTime BETWEEN '20140716' AND '20140716 23:59:59.997'
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE PostTime >= '20140716' AND PostTime < '20140717'Именно последние два запроса более правильные с точки зрения оптимизации. И дело в том, что все преобразования и вычисления на индексных столбцах, по которым идет поиск, может резко снижать производительность и увеличивать логические чтения (первый и последние три варианта запроса):
Table 'DatabaseLog'. Scan count 1, logical reads 7, ...
Table 'DatabaseLog'. Scan count 1, logical reads 2, ...Поле PostTime ранее не входило в индекс, и особого эффекта от использования «правильного» подхода при фильтрации мы бы не смогли увидеть. Другое дело, когда нам нужно вывести данные за месяц. Чего только не приходилось видеть:
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE CONVERT(CHAR(8), PostTime, 112) LIKE '201407%'
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE DATEPART(YEAR, PostTime) = 2014
AND DATEPART(MONTH, PostTime) = 7
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE YEAR(PostTime) = 2014
AND MONTH(PostTime) = 7
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE EOMONTH(PostTime) = '20140731'
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE PostTime >= '20140701' AND PostTime < '20140801'И опять же, последний вариант более приемлем, чем все остальные:

Кроме того, всегда можно сделать вычисляемое поле и создать на его основе индекс:
IF COL_LENGTH('dbo.DatabaseLog', 'MonthLastDay') IS NOT NULL
ALTER TABLE dbo.DatabaseLog DROP COLUMN MonthLastDay
GO
ALTER TABLE dbo.DatabaseLog
ADD MonthLastDay AS EOMONTH(PostTime) --PERSISTED
GO
CREATE INDEX IX_MonthLastDay ON dbo.DatabaseLog (MonthLastDay)В сравнении с прошлым запросом разница в логических чтениях будет существенная (если мы говорим про большие таблицы):
SET STATISTICS IO ON
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE PostTime >= '20140701' AND PostTime < '20140801'
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE MonthLastDay = '20140731'
SET STATISTICS IO OFFTable 'DatabaseLog'. Scan count 1, logical reads 7, ...
Table 'DatabaseLog'. Scan count 1, logical reads 3, ...8. Сalculation
Как я уже говорил, любые вычисления на индексных полях снижают производительность и приводят к увеличению логических чтений:
USE AdventureWorks2014
GO
SET STATISTICS IO ON
SELECT BusinessEntityID
FROM Person.Person
WHERE BusinessEntityID * 2 = 10000
SELECT BusinessEntityID
FROM Person.Person
WHERE BusinessEntityID = 2500 * 2
SELECT BusinessEntityID
FROM Person.Person
WHERE BusinessEntityID = 5000Table 'Person'. Scan count 1, logical reads 67, ...
Table 'Person'. Scan count 0, logical reads 3, ...Если взглянуть на планы выполнения, то в первом случае SQL Server приходится выполнить IndexScan:
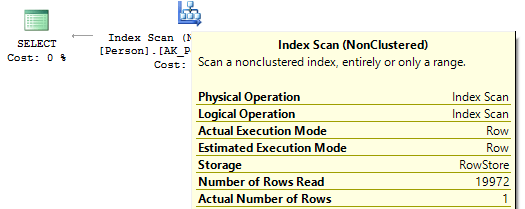
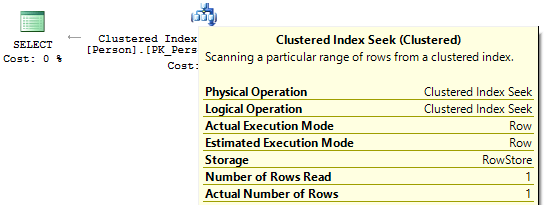
Во втором и третьем случае, когда вычисления на индексном поле, нет мы увидим IndexSeek:
9. Convert implicit
Для начала посмотрим на эти два запроса, которые фильтруют по одному и тому же значению:
USE AdventureWorks2014
GO
SELECT BusinessEntityID, NationalIDNumber
FROM HumanResources.Employee
WHERE NationalIDNumber = 30845
SELECT BusinessEntityID, NationalIDNumber
FROM HumanResources.Employee
WHERE NationalIDNumber = '30845'Если посмотреть на планы выполнения:
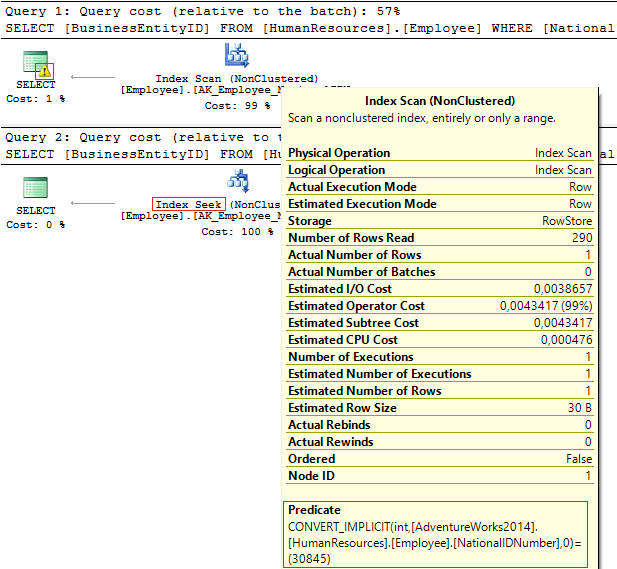
В первом случае — предупреждение и IndexScan, во втором — IndexSeek:
Table 'Employee'. Scan count 1, logical reads 4, ...
Table 'Employee'. Scan count 0, logical reads 2, ...Что произошло? Столбец NationalIDNumber имеет тип данных NVARCHAR(15). Константу, по значению которой необходимо отфильтровать данные, мы передаем как INT и в итоге получаем неявное преобразование типов, которое может снижать производительность. Такое очень часто происходит, когда кто-то меняет тип данных на столбце, но при этом запросы остаются прежними.
Однако, важно понимать, что не только проблемы с производительностью нас могут поджидать. Неявное преобразование типов может приводить к ошибкам на этапе выполнения. Например, раньше поле PostalCode было числовым, потом пришло указание сверху, что почтовый код может содержать буквы. Тип данных поменяли, но как только вставится буквенный почтовый код, то старый запрос уже не будет работать:
SELECT AddressID
FROM Person.[Address]
WHERE PostalCode = 92700
SELECT AddressID
FROM Person.[Address]
WHERE PostalCode = '92700'Msg 245, Level 16, State 1, Line 16
Conversion failed when converting the nvarchar value 'K4B 1S2' to data type int.Еще интереснее, когда на проекте используется EntityFramework, который все строковые поля по умолчанию интерпретирует как Unicode:
SELECT CustomerID, AccountNumber
FROM Sales.Customer
WHERE AccountNumber = N'AW00000009'
SELECT CustomerID, AccountNumber
FROM Sales.Customer
WHERE AccountNumber = 'AW00000009'И в итоге у нас генерируются не совсем оптимальные запросы:
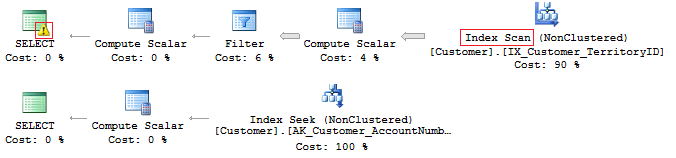
Решение проблемы достаточно простое — нужно контролировать, чтобы типы данных при сравнении совпадали.
10. LIKE & Suppressed index
Даже когда у вас есть покрывающий индекс, еще не факт что он будет эффективно использоваться. Например, нам нужно вывести все строки, которые начинаются с…
USE AdventureWorks2014
GO
SET STATISTICS IO ON
SELECT AddressLine1
FROM Person.[Address]
WHERE SUBSTRING(AddressLine1, 1, 3) = '100'
SELECT AddressLine1
FROM Person.[Address]
WHERE LEFT(AddressLine1, 3) = '100'
SELECT AddressLine1
FROM Person.[Address]
WHERE CAST(AddressLine1 AS CHAR(3)) = '100'
SELECT AddressLine1
FROM Person.[Address]
WHERE AddressLine1 LIKE '100%'Мы получим такие логические чтения:
Table 'Address'. Scan count 1, logical reads 216, ...
Table 'Address'. Scan count 1, logical reads 216, ...
Table 'Address'. Scan count 1, logical reads 216, ...
Table 'Address'. Scan count 1, logical reads 4, ...Планы выполнения, по которым быстро можно найти победителя:
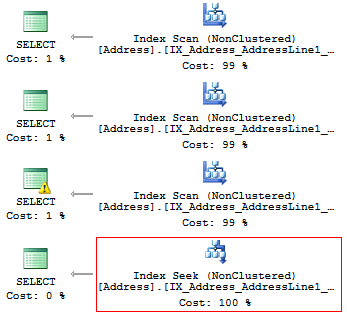
Результат является итогом, о чем мы так долго говорили до этого. Если есть индекс, то на нем не должно быть никаких вычислений и преобразований типов, функций и прочего. Только тогда он будет эффективно использоваться SQL Server.
Но что если нужно найти все вхождения подстроки в строку? Это задачка уже явно интереснее:
SELECT AddressLine1
FROM Person.[Address]
WHERE AddressLine1 LIKE '%100%'Но сначала нам нужно узнать много чего занимательного про строки и их свойства.
11. Unicode vs ANSI
Первое, что нужно помнить — строки бывают UNICODE и ANSI. Для первых предусмотрены типы данных NVARCHAR/NCHAR (по 2 байта на символ — увы UTF8 не завезли). Для хранения ANSI строк — VARCHAR/CHAR (1 байт — 1 символ). Есть еще TEXT/NTEXT, но про них лучше забыть изначально (потому что при их использовании можно существенно снизить производительность).
И вроде бы на этом можно было закончить, но нет…
Если в запросе задается юникодная константа, то перед ней нужно обязательно ставить символ N. Чтобы показать разницу, достаточно простого запроса:
SELECT '?? ANSI'
, N'?? UNICODE'------- ------------
?? ANSI ?? UNICODEЕсли не указывать N перед константой, то SQL Server будет пытаться искать подходящий символ в ANSI кодировке. Если не найдет, то подставит знак вопроса.
12. COLLATE
Вспомнился один очень интересный пример, который любят спрашивать при собеседовании на позицию Middle/Senior DB Developer. Вернет ли данные следующий запрос?
DECLARE @a NCHAR(1) = 'Ё'
, @b NCHAR(1) = 'Ф'
SELECT @a, @b
WHERE @a = @bИ да… и нет… Тут как повезет. Обычно я так отвечаю.
Почему такой неоднозначный ответ? Во-первых, перед строковым константами не стоит N, поэтому они будут толковаться как ANSI. Второе — очень многое зависит от текущего COLLATE, который является набором правил при сортировки и сравнении строковых данных.
USE [master]
GO
IF DB_ID('test') IS NOT NULL BEGIN
ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE test
END
GO
CREATE DATABASE test COLLATE Latin1_General_100_CI_AS
GO
USE test
GO
DECLARE @a NCHAR(1) = 'Ё'
, @b NCHAR(1) = 'Ф'
SELECT @a, @b
WHERE @a = @bПри таком COLLATE вместо кириллицы мы получим знаки вопросов, потому что символы знака вопроса равны между собой:
---- ----
? ?Стоит нам поменять COLLATE на какой-нибудь другой:
ALTER DATABASE test COLLATE Cyrillic_General_100_CI_ASИ запрос уже не вернет ничего, потому что кириллица будет правильно интерпретироваться.
Поэтому мораль тут простая: если строковая константа должна принимать UNICODE, то не надо лениться ставить N перед ней. Есть еще и обратная сторона медали, когда N лепиться везде, где можно, и оптимизатору приходится выполнять преобразования типов, которые, как я уже говорил, приводят к неоптимальным планам выполнения (это было показано выше).
Что еще я забыл упомянуть про строки? Еще один хороший вопрос из цикла «давайте проведем собеседование»:
DECLARE
@a VARCHAR(10) = 'TEXT'
, @b VARCHAR(10) = 'text'
SELECT IIF(@a = @b, 'TRUE', 'FALSE')Эти строки равны? И да… и нет… Опять ответил бы я. Если мы хотим однозначного сравнения, то нужно явно указывать COLLATE:
DECLARE
@a VARCHAR(10) = 'TEXT'
, @b VARCHAR(10) = 'text'
SELECT IIF(@a COLLATE Latin1_General_CS_AS = @b COLLATE Latin1_General_CS_AS, 'TRUE', 'FALSE')Потому что COLLATE могут быть как регистрозависимыми (CS), так и не учитывать регистр (CI) при сравнении и сортировке строк. Разные COLLATE у клиента и на тестовой базе — это потенциальный источник не только логических ошибок в бизнес-логике.
Еще веселее, когда COLLATE между целевой базой и tempdb не совпадают. Создадим базу с COLLATE, отличным от дефолтного:
USE [master]
GO
IF DB_ID('test') IS NOT NULL BEGIN
ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE test
END
GO
CREATE DATABASE test COLLATE Albanian_100_CS_AS
GO
USE test
GO
CREATE TABLE t (c CHAR(1))
INSERT INTO t VALUES ('a')
GO
IF OBJECT_ID('tempdb.dbo.#t1') IS NOT NULL
DROP TABLE #t1
IF OBJECT_ID('tempdb.dbo.#t2') IS NOT NULL
DROP TABLE #t2
IF OBJECT_ID('tempdb.dbo.#t3') IS NOT NULL
DROP TABLE #t3
GO
CREATE TABLE #t1 (c CHAR(1))
INSERT INTO #t1 VALUES ('a')
CREATE TABLE #t2 (c CHAR(1) COLLATE database_default)
INSERT INTO #t2 VALUES ('a')
SELECT c = CAST('a' AS CHAR(1))
INTO #t3
DECLARE @t TABLE (c VARCHAR(100))
INSERT INTO @t VALUES ('a')
SELECT 'tempdb', DATABASEPROPERTYEX('tempdb', 'collation')
UNION ALL
SELECT 'test', DATABASEPROPERTYEX(DB_NAME(), 'collation')
UNION ALL
SELECT 't', SQL_VARIANT_PROPERTY(c, 'collation') FROM t
UNION ALL
SELECT '#t1', SQL_VARIANT_PROPERTY(c, 'collation') FROM #t1
UNION ALL
SELECT '#t2', SQL_VARIANT_PROPERTY(c, 'collation') FROM #t2
UNION ALL
SELECT '#t3', SQL_VARIANT_PROPERTY(c, 'collation') FROM #t3
UNION ALL
SELECT '@t', SQL_VARIANT_PROPERTY(c, 'collation') FROM @tПри создании таблицы COLLATE наследуется от базы данных. Единственное отличие — для первой временной таблицы, для которой мы явно определяем структуру без указания COLLATE. В этом случае она наследует COLLATE от базы tempdb.
------ --------------------------
tempdb Cyrillic_General_CI_AS
test Albanian_100_CS_AS
t Albanian_100_CS_AS
#t1 Cyrillic_General_CI_AS
#t2 Albanian_100_CS_AS
#t3 Albanian_100_CS_AS
@t Albanian_100_CS_ASСейчас остановимся на нашем примере с #t1, потому что если COLLATE не совпадают — это может привести к потенциальным проблемам.
Например, данные не будут правильно фильтроваться из-за того, что COLLATE может не учитывать регистр:
SELECT *
FROM #t1
WHERE c = 'A'Либо SQL Server будет ругаться на невозможность соединения таблиц из-за различающихся COLLATE:
SELECT *
FROM #t1
JOIN t ON [#t1].c = t.cПоследний пример очень часто встречается. На тестовом сервере все идеально, а когда развернули бэкап на сервере клиента, то получаем ошибку:
Msg 468, Level 16, State 9, Line 93
Cannot resolve the collation conflict between "Albanian_100_CS_AS" and "Cyrillic_General_CI_AS" in the equal to operation.После чего приходится везде делать костыли:
SELECT *
FROM #t1
JOIN t ON [#t1].c = t.c COLLATE database_default13. BINARY COLLATE
Теперь, когда «ложка дегтя» пройдена, посмотрим, как можно использовать COLLATE с пользой для себя. Помните пример про поиск подстроки в строке?
SELECT AddressLine1
FROM Person.[Address]
WHERE AddressLine1 LIKE '%100%'Данный запрос можно существенно оптимизировать и сократить время его выполнения.
Но для того, чтобы была видна разница, нам нужно сгенерировать большую таблицу:
USE [master]
GO
IF DB_ID('test') IS NOT NULL BEGIN
ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE test
END
GO
CREATE DATABASE test COLLATE Latin1_General_100_CS_AS
GO
ALTER DATABASE test MODIFY FILE (NAME = N'test', SIZE = 64MB)
GO
ALTER DATABASE test MODIFY FILE (NAME = N'test_log', SIZE = 64MB)
GO
USE test
GO
CREATE TABLE t (
ansi VARCHAR(100) NOT NULL
, unicod NVARCHAR(100) NOT NULL
)
GO
;WITH
E1(N) AS (
SELECT * FROM (
VALUES
(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1)
) t(N)
),
E2(N) AS (SELECT 1 FROM E1 a, E1 b),
E4(N) AS (SELECT 1 FROM E2 a, E2 b),
E8(N) AS (SELECT 1 FROM E4 a, E4 b)
INSERT INTO t
SELECT v, v
FROM (
SELECT TOP(50000) v = REPLACE(CAST(NEWID() AS VARCHAR(36)) + CAST(NEWID() AS VARCHAR(36)), '-', '')
FROM E8
) tСоздадим вычисляемые столбцы с бинарными COLLATE, не забыв при этом создать индексы:
ALTER TABLE t
ADD ansi_bin AS UPPER(ansi) COLLATE Latin1_General_100_Bin2
ALTER TABLE t
ADD unicod_bin AS UPPER(unicod) COLLATE Latin1_General_100_BIN2
CREATE NONCLUSTERED INDEX ansi ON t (ansi)
CREATE NONCLUSTERED INDEX unicod ON t (unicod)
CREATE NONCLUSTERED INDEX ansi_bin ON t (ansi_bin)
CREATE NONCLUSTERED INDEX unicod_bin ON t (unicod_bin)Выполняем фильтрацию:
SET STATISTICS TIME, IO ON
SELECT COUNT_BIG(*)
FROM t
WHERE ansi LIKE '%AB%'
SELECT COUNT_BIG(*)
FROM t
WHERE unicod LIKE '%AB%'
SELECT COUNT_BIG(*)
FROM t
WHERE ansi_bin LIKE '%AB%' --COLLATE Latin1_General_100_BIN2
SELECT COUNT_BIG(*)
FROM t
WHERE unicod_bin LIKE '%AB%' --COLLATE Latin1_General_100_BIN2
SET STATISTICS TIME, IO OFFИ можем увидеть результаты выполнения, которые приятно удивят:
SQL Server Execution Times:
CPU time = 350 ms, elapsed time = 354 ms.
SQL Server Execution Times:
CPU time = 335 ms, elapsed time = 355 ms.
SQL Server Execution Times:
CPU time = 16 ms, elapsed time = 18 ms.
SQL Server Execution Times:
CPU time = 17 ms, elapsed time = 18 ms.Вся суть в том, что поиск на основе бинарного сравнения происходит намного быстрее, и если нужно часто и быстро искать вхождение строк, то данные можно хранить с COLLATE, которые заканчивается на BIN. Единственное, что нужно помнить все бинарные COLLATE регистрозависимые при сравнении.
14. Code style
Стиль написания кода — это строго индивидуальное, но, чтобы не вносить хаос в разработку, все уже давно придерживаются тех или иных правил. Самое парадоксальное, что за все время работы я не видел ни одного вменяемого свода правил при написании запросов. Все их пишут по принципу: «главное, чтобы работало». Хотя потом рискуют хорошо хлебнуть при разворачивании базы на сервере клиента.
Давайте создадим отдельную базу и таблицу в ней:
USE [master]
GO
IF DB_ID('test') IS NOT NULL BEGIN
ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE test
END
GO
CREATE DATABASE test COLLATE Latin1_General_CI_AS
GO
USE test
GO
CREATE TABLE dbo.Employee (EmployeeID INT PRIMARY KEY)и напишем такой запрос:
select employeeid from employeeРаботает? Теперь попробуйте поменять COLLATE на какой-нибудь регистрозависимый:
ALTER DATABASE test COLLATE Latin1_General_CS_AIИ попробуем повторно выполнить запрос:
Msg 208, Level 16, State 1, Line 19
Invalid object name 'employee'.Оптимизатор использует правила текущего COLLATE при построении плана выполнения. Точнее, на этапе биндинга, когда производится проверка на существование таблиц, колонок и других объектов и сопоставление каждого объекта синтаксического дерева с реальным объектом системного каталога.
Если хочется генерировать ручками запросы, которые будут везде работать, то нужно всегда придерживаться правильного регистра в именах объектов, которые используются в запросе.
Еще интереснее обстоят дела с переменными…
Для них COLLATE наследуются от базы master. Поэтому нужно соблюдать правильный регистр при работе с переменными:
SELECT DATABASEPROPERTYEX('master', 'collation')
DECLARE @EmpID INT = 1
SELECT @empidТо ошибки скорее всего не будет:
-----------------------
Cyrillic_General_CI_AS
-----------
1При этом на другом сервере ошибка в регистре может дать о себе знать:
--------------------------
Latin1_General_CS_ASMsg 137, Level 15, State 2, Line 4
Must declare the scalar variable "@empid".15. [var]char
Не секрет, что есть строчные типы данных с фиксированной (CHAR, NCHAR) и переменной длиной (VARCHAR, NVARCHAR):
DECLARE @a CHAR(20) = 'text'
, @b VARCHAR(20) = 'text'
SELECT LEN(@a)
, LEN(@b)
, DATALENGTH(@a)
, DATALENGTH(@b)
, '"' + @a + '"'
, '"' + @b + '"'
SELECT [a = b] = IIF(@a = @b, 'TRUE', 'FALSE')
, [b = a] = IIF(@b = @a, 'TRUE', 'FALSE')
, [a LIKE b] = IIF(@a LIKE @b, 'TRUE', 'FALSE')
, [b LIKE a] = IIF(@b LIKE @a, 'TRUE', 'FALSE')Если строка имеет фиксированную длину скажем в 20 символов, но в нее записали только 4, то в этом случае SQL Server автоматически добавит 16 пробелов справа (при этом обратите внимание функции LEN и DATALENGTH ведут себя по-разному):
--- --- ---- ---- ---------------------- ----------------------
4 4 20 4 "text " "text"Кроме того, важно понимать — при сравнении строк через равно пробелы справа не учитываются:
a = b b = a a LIKE b b LIKE a
----- ----- -------- --------
TRUE TRUE TRUE FALSEДругое дело оператор LIKE:
SELECT 1
WHERE 'a ' LIKE 'a'
SELECT 1
WHERE 'a' LIKE 'a ' -- !!!
SELECT 1
WHERE 'a' LIKE 'a'
SELECT 1
WHERE 'a' LIKE 'a%'Пробелы у правого операнда всегда учитываются при сравнении.
16. Data length
Нужно всегда указывать размерность типа, чтобы не натыкаться на подобного рода грабли:
DECLARE @a DECIMAL
, @b VARCHAR(10) = '0.1'
, @c SQL_VARIANT
SELECT @a = @b
, @c = @a
SELECT @a
, @c
, SQL_VARIANT_PROPERTY(@c,'BaseType')
, SQL_VARIANT_PROPERTY(@c,'Precision')
, SQL_VARIANT_PROPERTY(@c,'Scale')В чем суть данной проблемы? Явно не указали размерность типа и вместо дробного значения получаем «вроде целое»:
---- ---- ---------- ----- -----
0 0 decimal 18 0Со строками все еще веселее:
DECLARE @t1 VARCHAR(MAX) = '123456789_123456789_123456789_123456789_'
DECLARE @t2 VARCHAR = @t1
SELECT LEN(@t1)
, @t1
, LEN(@t2)
, @t2
, LEN(CONVERT(VARCHAR, @t1))
, LEN(CAST(@t1 AS VARCHAR))Если явно не указывается размерность, то у строки длина будет 1 символ:
----- ------------------------------------------ ---- ---- ---- ----
40 123456789_123456789_123456789_123456789_ 1 1 30 30При этом поведение преобразовании типов имеет свою особенность: не указали размерность в CAST/CONVERT, то браться будут первые 30 символов.
17. ISNULL vs COALESCE
Что еще потенциально интересного можно показать? Есть две функции: ISNULL и COALESCE. С одной стороны все просто — если первый оператор NULL, то вернуть второй оператор или следующий, если мы говорим про COALESCE. С другой стороны, есть коварное различие между ними.
Что вернут эти функции?
DECLARE @a CHAR(1) = NULL
SELECT ISNULL(@a, 'NULL'), COALESCE(@a, 'NULL')
DECLARE @i INT = NULL
SELECT ISNULL(@i, 7.1), COALESCE(@i, 7.1)Ответ и вправду не очень очевидный:
---- ----
N NULL
---- ----
7 7.1Почему? Функция ISNULL преобразует к наименьшему типу из двух операндов. COALESCE преобразует к наибольшему типу. Вот мы и получаем такую радость, над которой я в первый раз очень долго просидел в попытках понять, «что не так».
С точки зрения производительности, ISNULL будет немного быстрее отрабатывать в ряде случае, COALESCE же раскладывается в CASE WHEN оператор о котором поговорим ниже.
18. Math
Еще интереснее, когда сталкиваешься с математикой на SQL Server. Вроде бы разницы не должно быть:
SELECT 1 / 3
SELECT 1.0 / 3Но по факту оказывается, что разница есть — все зависит от того, какие данные участвуют в запросе. Если целочисленные, то и результат будет целочисленным:
-----------
0
-----------
0.333333Еще интересный пример, который часто встречается на собеседованиях в том или ином виде:
SELECT COUNT(*)
, COUNT(1)
, COUNT(val)
, COUNT(DISTINCT val)
, SUM(val)
, SUM(DISTINCT val)
FROM (
VALUES (1), (2), (2), (NULL), (NULL)
) t (val)
SELECT AVG(val)
, SUM(val) / COUNT(val)
, AVG(val * 1.)
, AVG(CAST(val AS FLOAT))
FROM (
VALUES (1), (2), (2), (NULL), (NULL)
) t (val)Что вернет запрос? COUNT(*)/COUNT(1) вернет общее число строк. COUNT по столбцу вернет количество не NULL строк. Если добавить DISTINCT, то количество уникальных значений, которые не NULL.
Интереснее с подсчетом среднего. Операция AVG раскладывается оптимизатором на SUM и COUNT. И тут мы вспомним про пример выше — при подсчете среднего не будут учитываться NULL. Кроме того, если значения целочисленные, то какой будет результат? Целочисленный. Об этом часто забывают.
19. UNION vs UNION ALL
Тут все просто: если мы знаем, что данные не пересекаются, и нас не волнуют дубликаты, то, с точки зрения производительности, предпочтительнее использовать UNION ALL. Если нужно убрать дублирование, то смело используем UNION.
Например, в случае когда дубликатов точно не будет лучше использовать UNION ALL:
SELECT [object_id]
FROM sys.system_objects
UNION
SELECT [object_id]
FROM sys.objects
SELECT [object_id]
FROM sys.system_objects
UNION ALL
SELECT [object_id]
FROM sys.objects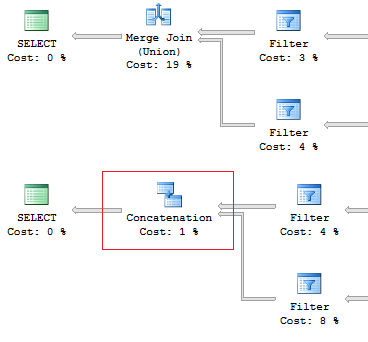
Еще важно знать об интересном различии между этими двумя конструкциями: оператор UNION выполняется параллельно, а UNION ALL — последовательно. И это не относится к параллельным планам, просто это такая особенность доступа к данным, которая может помочь при оптимизации.
Предположим, нам нужно вернуть 1 строку, исходя из разного набора условий:
DECLARE @AddressLine NVARCHAR(60)
SET @AddressLine = '4775 Kentucky Dr.'
SELECT TOP(1) AddressID
FROM Person.[Address]
WHERE AddressLine1 = @AddressLine
OR AddressLine2 = @AddressLineТогда за счет использования OR в условии у нас будет IndexScan:

Table 'Address'. Scan count 1, logical reads 90, ...Перепишем запрос с использованием UNION ALL:
SELECT TOP(1) AddressID
FROM (
SELECT TOP(1) AddressID
FROM Person.[Address]
WHERE AddressLine1 = @AddressLine
UNION ALL
SELECT TOP(1) AddressID
FROM Person.[Address]
WHERE AddressLine2 = @AddressLine
) tПосле выполнения первого подзапроса, SQL Server смотрит, что вернулась 1 строка, которой достаточно, чтобы вернуть результат, и далее не продолжает искать по второму условию:
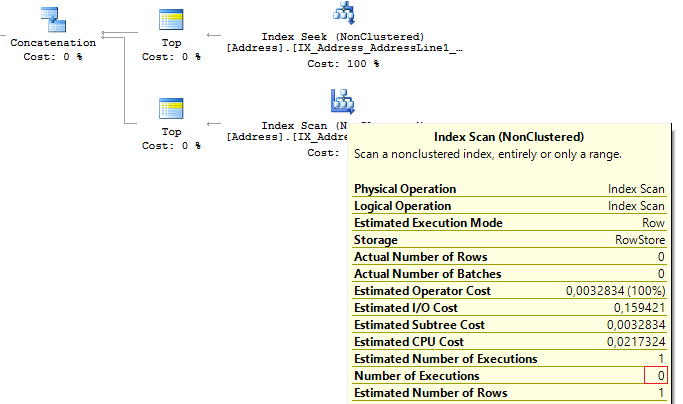
Table 'Worktable'. Scan count 0, logical reads 0, ...
Table 'Address'. Scan count 1, logical reads 3, ...20. Re-read
Очень часто доводилось видеть ситуацию, когда данные можно вытащить с помощью одного JOIN при этом в запросе гордилось куча подзапросов:
USE AdventureWorks2014
GO
SET STATISTICS IO ON
SELECT e.BusinessEntityID
, (
SELECT p.LastName
FROM Person.Person p
WHERE e.BusinessEntityID = p.BusinessEntityID
)
, (
SELECT p.FirstName
FROM Person.Person p
WHERE e.BusinessEntityID = p.BusinessEntityID
)
FROM HumanResources.Employee e
SELECT e.BusinessEntityID
, p.LastName
, p.FirstName
FROM HumanResources.Employee e
JOIN Person.Person p ON e.BusinessEntityID = p.BusinessEntityIDВедь чем меньше идет лишних обращений к таблице — тем меньше логических чтений:
Table 'Person'. Scan count 0, logical reads 1776, ...
Table 'Employee'. Scan count 1, logical reads 2, ...
Table 'Person'. Scan count 0, logical reads 888, ...
Table 'Employee'. Scan count 1, logical reads 2, ...21. SubQuery
Предыдущий пример весьма показательный, потому что будет работать только если связь между таблицами один-к-одному.
Давайте предположим что раньше между таблицами Person.Person и Sales.SalesPersonQuotaHistory была такая связь, получалось что для одного сотрудника существовала максимум одна запись по размеру квоты.
USE AdventureWorks2014
GO
SET STATISTICS IO ON
SELECT p.BusinessEntityID
, (
SELECT s.SalesQuota
FROM Sales.SalesPersonQuotaHistory s
WHERE s.BusinessEntityID = p.BusinessEntityID
)
FROM Person.Person pНа сервере клиента может быть по-другому и тогда этот запрос приведет к такой ошибке:
Msg 512, Level 16, State 1, Line 6
Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <= , >, >= or when the subquery is used as an expression.Как решаются подобные проблемы?
Добавляется TOP(1) и ORDER BY, и проблема ушла. Однако не все так просто, как может показаться. Использование операции TOP заставляет оптимизатор форсировать использование IndexSeek. К таким же последствиям приводит использованием OUTER/CROSS APPLY вместе с TOP:
SELECT p.BusinessEntityID
, (
SELECT TOP(1) s.SalesQuota
FROM Sales.SalesPersonQuotaHistory s
WHERE s.BusinessEntityID = p.BusinessEntityID
ORDER BY s.QuotaDate DESC
)
FROM Person.Person p
SELECT p.BusinessEntityID
, t.SalesQuota
FROM Person.Person p
OUTER APPLY (
SELECT TOP(1) s.SalesQuota
FROM Sales.SalesPersonQuotaHistory s
WHERE s.BusinessEntityID = p.BusinessEntityID
ORDER BY s.QuotaDate DESC
) tПри их выполнении будет возникать одна и та же проблема — множественные IndexSeek операции:

Table 'SalesPersonQuotaHistory'. Scan count 19972, logical reads 39944, ...
Table 'Person'. Scan count 1, logical reads 67, ...Вооружившись оконной функцией, перепишем запрос:
SELECT p.BusinessEntityID
, t.SalesQuota
FROM Person.Person p
LEFT JOIN (
SELECT s.BusinessEntityID
, s.SalesQuota
, RowNum = ROW_NUMBER() OVER (PARTITION BY s.BusinessEntityID ORDER BY s.QuotaDate DESC)
FROM Sales.SalesPersonQuotaHistory s
) t ON p.BusinessEntityID = t.BusinessEntityID
AND t.RowNum = 1И посмотрим что изменилось:

Table 'Person'. Scan count 1, logical reads 67, ...
Table 'SalesPersonQuotaHistory'. Scan count 1, logical reads 4, ...22. CASE WHEN
Что можно сказать про данную конструкцию языка? Она часто используется и имеет несколько не очень очевидных особенностей, про которые нужно знать. Вне зависимости от того как мы написали оператор CASE WHEN:
USE AdventureWorks2014
GO
SELECT BusinessEntityID
, Gender
, Gender =
CASE Gender
WHEN 'M' THEN 'Male'
WHEN 'F' THEN 'Female'
ELSE 'Unknown'
END
FROM HumanResources.EmployeeSQL Server будет раскладывать выражение до такого вида:
SELECT BusinessEntityID
, Gender
, Gender =
CASE
WHEN Gender = 'M' THEN 'Male'
WHEN Gender = 'F' THEN 'Female'
ELSE 'Unknown'
END
FROM HumanResources.EmployeeВ этом и заключается главная проблема — каждое условие будет последовательно выполняться до тех пор пока одно из них не вернет TRUE либо бы не дойдем до блока ELSE.
Давайте покажу, проблему более наглядно. Для этого создадим скалярную функцию, которая будет возвращать правую часть почтового адреса:
IF OBJECT_ID('dbo.GetMailUrl') IS NOT NULL
DROP FUNCTION dbo.GetMailUrl
GO
CREATE FUNCTION dbo.GetMailUrl
(
@Email NVARCHAR(50)
)
RETURNS NVARCHAR(50)
AS BEGIN
RETURN SUBSTRING(@Email, CHARINDEX('@', @Email) + 1, LEN(@Email))
ENDНастроим SQL Profiler на отображение событий SQL:StmtStarting / SP:StmtCompleted (если хочется сделать этого с помощью XEvents: sp_statement_starting / sp_statement_completed).
Выполним запрос:
SELECT TOP(10) EmailAddressID
, EmailAddress
, CASE dbo.GetMailUrl(EmailAddress)
--WHEN 'microsoft.com' THEN 'Microsoft'
WHEN 'adventure-works.com' THEN 'AdventureWorks'
END
FROM Person.EmailAddressФункция выполнится 10 раз. Теперь уберем комментарий с условия выше:
SELECT TOP(10) EmailAddressID
, EmailAddress
, CASE dbo.GetMailUrl(EmailAddress)
WHEN 'microsoft.com' THEN 'Microsoft'
WHEN 'adventure-works.com' THEN 'AdventureWorks'
END
FROM Person.EmailAddressФункция выполнится уже 20 раз. Суть в том, что выражение в CASE не обязательно быть функцией. Это может быть какой-то сложный расчет. За счет того, что CASE раскладывается — это может привести к многократному вычислению одних и тех же операторов.
Бороться с этим можно с помощью вложенных запросов:
SELECT EmailAddressID
, EmailAddress
, CASE MailUrl
WHEN 'microsoft.com' THEN 'Microsoft'
WHEN 'adventure-works.com' THEN 'AdventureWorks'
END
FROM (
SELECT TOP(10) EmailAddressID
, EmailAddress
, MailUrl = dbo.GetMailUrl(EmailAddress)
FROM Person.EmailAddress
) tФункция выполнится 10 раз.
Кроме того, нужно стараться не нагружать CASE оператор дубликатами:
SELECT DISTINCT
CASE
WHEN Gender = 'M' THEN 'Male'
WHEN Gender = 'M' THEN '...'
WHEN Gender = 'M' THEN '......'
WHEN Gender = 'F' THEN 'Female'
WHEN Gender = 'F' THEN '...'
ELSE 'Unknown'
END
FROM HumanResources.EmployeeХоть выражения в CASE и вычисляется последовательно (именно в том порядке как мы написали). В некоторых случаях этот оператор будет выполняться SQL Server с агрегированных функций:
DECLARE @i INT = 1
SELECT
CASE WHEN @i = 1
THEN 1
ELSE 1/0
END
GO
DECLARE @i INT = 1
SELECT
CASE WHEN @i = 1
THEN 1
ELSE MIN(1/0)
END23. Scalar func
Специально для любителей ООП — не используйте скалярные функции в запросах на T-SQL, которые оперируют большим числом строк.
Вот пример из жизни, которым я когда-то страдал, когда еще не знал о потенциальных минусах скалярных функций:
USE AdventureWorks2014
GO
UPDATE TOP(1) Person.[Address]
SET AddressLine2 = AddressLine1
GO
IF OBJECT_ID('dbo.isEqual') IS NOT NULL
DROP FUNCTION dbo.isEqual
GO
CREATE FUNCTION dbo.isEqual
(
@val1 NVARCHAR(100),
@val2 NVARCHAR(100)
)
RETURNS BIT
AS BEGIN
RETURN
CASE WHEN (@val1 IS NULL AND @val2 IS NULL) OR @val1 = @val2
THEN 1
ELSE 0
END
ENDЗапросы возвращают идентичные данные:
SET STATISTICS TIME ON
SELECT AddressID, AddressLine1, AddressLine2
FROM Person.[Address]
WHERE dbo.IsEqual(AddressLine1, AddressLine2) = 1
SELECT AddressID, AddressLine1, AddressLine2
FROM Person.[Address]
WHERE (AddressLine1 IS NULL AND AddressLine2 IS NULL)
OR AddressLine1 = AddressLine2
SELECT AddressID, AddressLine1, AddressLine2
FROM Person.[Address]
WHERE AddressLine1 = ISNULL(AddressLine2, '')
SET STATISTICS TIME OFFНо за счет, того что каждый вызов скалярной функции ресурсоемкий, получаем вот такую разницу:
SQL Server Execution Times:
CPU time = 63 ms, elapsed time = 57 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 1 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 1 ms.Кроме того, использование скалярных функций в запросе мешает SQL Server строить параллельные планы выполнения, что при больших объёмах данных может существенно подкосить производительность.
Во всех ли случаях скалярные функции — это зло? Нет. Можно создать функцию с опцией SCHEMABINDING и не использовать входящих параметров:
IF OBJECT_ID('dbo.GetPI') IS NOT NULL
DROP FUNCTION dbo.GetPI
GO
CREATE FUNCTION dbo.GetPI ()
RETURNS FLOAT
WITH SCHEMABINDING
AS BEGIN
RETURN PI()
END
GO
SELECT dbo.GetPI()
FROM Sales.CurrencyВ таком случае, функция будет считаться детерминированной и выполняться ровно 1 раз.
24. VIEWs
Кто-то любит представления… кто-то нет. Навязывать мнение не использовать вью – себе дороже, но знать про несколько особенностей при работе с ними нужно обязательно.
Создаем тестовую таблицу и вью на основе нее:
IF OBJECT_ID('dbo.tbl', 'U') IS NOT NULL
DROP TABLE dbo.tbl
GO
CREATE TABLE dbo.tbl (a INT, b INT)
GO
INSERT INTO dbo.tbl VALUES (0, 1)
GO
IF OBJECT_ID('dbo.vw_tbl', 'V') IS NOT NULL
DROP VIEW dbo.vw_tbl
GO
CREATE VIEW dbo.vw_tbl
AS
SELECT * FROM dbo.tbl
GO
SELECT * FROM dbo.vw_tblЗначения возвращаются правильно:
a b
----------- -----------
0 1Теперь добавим новый столбец в таблицу и пробуем опять вычитать данные из вью:
ALTER TABLE dbo.tbl
ADD c INT NOT NULL DEFAULT 2
GO
SELECT * FROM dbo.vw_tblПолучим тот же результат:
a b
----------- -----------
0 1А все потому, что нужно либо явно задавать столбцы, либо рекомпилировать скриптовый объект:
EXEC sys.sp_refreshview @viewname = N'dbo.vw_tbl'
GO
SELECT * FROM dbo.vw_tblчтобы получить правильный результат:
a b c
----------- ----------- -----------
0 1 2При прямом обращении к таблице подобного прикола не будет.
Есть любители в одном запросе соединить все данные и обернуть это все в одном вью. За примером далеко ходить не будем, и посмотрим на «хороший паттерн» из AdventureWorks:
ALTER VIEW HumanResources.vEmployee
AS
SELECT e.BusinessEntityID
, p.Title
, p.FirstName
, p.MiddleName
, p.LastName
, p.Suffix
, e.JobTitle
, pp.PhoneNumber
, pnt.[Name] AS PhoneNumberType
, ea.EmailAddress
, p.EmailPromotion
, a.AddressLine1
, a.AddressLine2
, a.City
, sp.[Name] AS StateProvinceName
, a.PostalCode
, cr.[Name] AS CountryRegionName
, p.AdditionalContactInfo
FROM HumanResources.Employee e
JOIN Person.Person p ON p.BusinessEntityID = e.BusinessEntityID
JOIN Person.BusinessEntityAddress bea ON bea.BusinessEntityID = e.BusinessEntityID
JOIN Person.[Address] a ON a.AddressID = bea.AddressID
JOIN Person.StateProvince sp ON sp.StateProvinceID = a.StateProvinceID
JOIN Person.CountryRegion cr ON cr.CountryRegionCode = sp.CountryRegionCode
LEFT JOIN Person.PersonPhone pp ON pp.BusinessEntityID = p.BusinessEntityID
LEFT JOIN Person.PhoneNumberType pnt ON pp.PhoneNumberTypeID = pnt.PhoneNumberTypeID
LEFT JOIN Person.EmailAddress ea ON p.BusinessEntityID = ea.BusinessEntityIDА теперь вопрос… что если мне нужно получить не всю информацию, а только ее часть? Например, вернуть имя и фамилию работников:
SELECT BusinessEntityID
, FirstName
, LastName
FROM HumanResources.vEmployee
SELECT p.BusinessEntityID
, p.FirstName
, p.LastName
FROM Person.Person p
WHERE p.BusinessEntityID IN (
SELECT e.BusinessEntityID
FROM HumanResources.Employee e
)Посмотрим на план выполнения в случае использования вью:

Table 'EmailAddress'. Scan count 290, logical reads 640, ...
Table 'PersonPhone'. Scan count 290, logical reads 636, ...
Table 'BusinessEntityAddress'. Scan count 290, logical reads 636, ...
Table 'Person'. Scan count 0, logical reads 897, ...
Table 'Employee'. Scan count 1, logical reads 2, ...и сравним с запросом, который мы осмысленно написали ручками:

Table 'Person'. Scan count 0, logical reads 897, ...
Table 'Employee'. Scan count 1, logical reads 2, ...Оптимизатор в SQL Server сделали весьма умным и на этапе упрощения дерева операторов, при построении плана выполнения, он умеет отбрасывать неиспользуемые соединения.
Однако эффективно делать он может это не всегда. Иногда ему мешает отсутствие валидного внешнего ключа между таблицами, когда нет возможности проверить «а повлияет ли соединение на результат выборки». Или, например, когда соединение идет по более чем одному полю… ну не умеет некоторых вещей оптимизатор, но это же не повод нагружать его лишней работой.
25. CURSORs
При работе с SQL Server запомните одну истину — не используйте курсоры для итерационной модификации данных. Это не Oracle!
Часто можно встретить такой вот код:
DECLARE @BusinessEntityID INT
DECLARE cur CURSOR FOR
SELECT BusinessEntityID
FROM HumanResources.Employee
OPEN cur
FETCH NEXT FROM cur INTO @BusinessEntityID
WHILE @@FETCH_STATUS = 0 BEGIN
UPDATE HumanResources.Employee
SET VacationHours = 0
WHERE BusinessEntityID = @BusinessEntityID
FETCH NEXT FROM cur INTO @BusinessEntityID
END
CLOSE cur
DEALLOCATE curЭтот код можно переписать вот так:
UPDATE HumanResources.Employee
SET VacationHours = 0
WHERE VacationHours <> 0Приводить время выполнения и число логических чтений не стоит, но поверьте, разница действительно есть. Как вариант, просто расскажу про недавний пример из жизни. Встретил скрипт, в котором было два вложенных курсора. При выполнении данный код приводил к таймауту на клиенте, а всего он выполнялся примерно 38 секунд. Выбросил из запроса первый курсор и запрос стал выполняться 600мс. Выкинул второй курсор — 200мс.
Курсоры на SQL Server — зло!
26. STRING_CONCAT
Все что было выше — это далеко не верх того идиотизма, с которым можно столкнуться при работе. Пробовали склеивать несколько строк в одну?
Я бы конечно мог посоветовать использовать функцию STRING_CONCAT, если бы она была… На дворе 2016 год, а отдельной функции для конкатенации строк, в SQL Server так и не добавили. Нужно же как-то выходить из положения?
Создадим тестовую таблицу:
IF OBJECT_ID('tempdb.dbo.#t') IS NOT NULL
DROP TABLE #t
GO
CREATE TABLE #t (i CHAR(1))
INSERT INTO #t
VALUES ('1'), ('2'), ('3')и начнем с моего «любимца» — конкатенация строк через присваивание значений в переменную:
DECLARE @txt VARCHAR(50) = ''
SELECT @txt += i
FROM #t
SELECT @txt--------
123Все работает, но сам MS намекает, что данные способ недокументированный, и никто не застрахован от такого результата:
DECLARE @txt VARCHAR(50) = ''
SELECT @txt += i
FROM #t
ORDER BY LEN(i)
SELECT @txt--------
3Скажу честно, сам в первый раз долго разбирался, почему у меня отчет по бухгалтерской проводке только последнюю строку показывает. После этого прикола было много еще чего: CLR, UPDATE, временные таблицы, рекурсия, циклы… и это все чтобы склеить строки.
На практике, в 90% случаев достаточно использовать XML:
SELECT [text()] = i
FROM #t
FOR XML PATH('')--------
123Однако и тут нас может поджидать пара нюансов. Во-первых, очень часто необходимо склеить строки в разрезе каких-то данных, а не все в одно:
SELECT [name], STUFF((
SELECT ', ' + c.[name]
FROM sys.columns c
WHERE c.[object_id] = t.[object_id]
FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, '')
FROM sys.objects t
WHERE t.[type] = 'U'------------------------ ------------------------------------
ScrapReason ScrapReasonID, Name, ModifiedDate
Shift ShiftID, Name, StartTime, EndTimeПри этом крайне желательно избегать использования XML метода для парсинга, поскольку он очень ресурсоемкий:
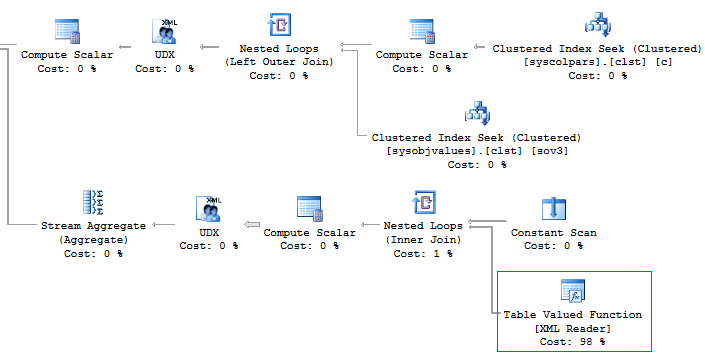
Его можно сделать менее затратным:
SELECT [name], STUFF((
SELECT ', ' + c.[name]
FROM sys.columns c
WHERE c.[object_id] = t.[object_id]
FOR XML PATH(''), TYPE).value('(./text())[1]', 'NVARCHAR(MAX)'), 1, 2, '')
FROM sys.objects t
WHERE t.[type] = 'U'Но сути это кардинально не изменит. Теперь пробуем не использовать метод value:
SELECT t.name
, STUFF((
SELECT ', ' + c.name
FROM sys.columns c
WHERE c.[object_id] = t.[object_id]
FOR XML PATH('')), 1, 2, '')
FROM sys.objects t
WHERE t.[type] = 'U'
И такой вариант будет работать хорошо и быстро, если не одно «но». Попробуйте выполнить вот такой запрос:
SELECT t.name
, STUFF((
SELECT ', ' + CHAR(13) + c.name
FROM sys.columns c
WHERE c.[object_id] = t.[object_id]
FOR XML PATH('')), 1, 2, '')
FROM sys.objects t
WHERE t.[type] = 'U'Если в строках встречаются спецсимволы, вроде табуляции, перевода строки и прочее, то мы будем получать не совсем корректные результаты.
В итоге у нас два варианта: если спецсимволов нет, то использовать вариант запроса без метода value, в противном случае обратить внимание на более ресурсоемкий план с value('(./text())[1]'....
27. SQL Injection
Проще всего показать проблему с sql injection, чем описать ее на словах. Предположим есть у нас такой код:
DECLARE @param VARCHAR(MAX)
SET @param = 1
DECLARE @SQL NVARCHAR(MAX)
SET @SQL = 'SELECT TOP(5) name FROM sys.objects WHERE schema_id = ' + @param
PRINT @SQL
EXEC (@SQL)Сформируется вот такой запрос:
SELECT TOP(5) name FROM sys.objects WHERE schema_id = 1Если перед выполнением дописать к параметру что-то лишнее:
SET @param = '1; select ''hack'''то запрос будет уже такой:
SELECT TOP(5) name FROM sys.objects WHERE schema_id = 1; select 'hack'Это и есть атака, известная как sql injection, когда вместе с запросом можно будет выполнить что-то «лишнее». Тут как повезет — лишь бы прав хватило :)
Если в коде запрос формируется с помощью String.Format (или вручную), то это потенциальное место, где может возникнуть проблема с sql injection:
using (SqlConnection conn = new SqlConnection())
{
conn.ConnectionString = @"Server=.;Database=AdventureWorks2014;Trusted_Connection=true";
conn.Open();
SqlCommand command = new SqlCommand(
string.Format("SELECT TOP(5) name FROM sys.objects WHERE schema_id = {0}", value), conn);
using (SqlDataReader reader = command.ExecuteReader())
{
while (reader.Read()) {}
}
}Другое дело, когда используется sp_executesql и параметры:
DECLARE @param VARCHAR(MAX)
SET @param = '1; select ''hack'''
DECLARE @SQL NVARCHAR(MAX)
SET @SQL = 'SELECT TOP(5) name FROM sys.objects WHERE schema_id = @schema_id'
PRINT @SQL
EXEC sys.sp_executesql @SQL
, N'@schema_id INT'
, @schema_id = @paramВ таком случае, дописать к параметру что-то лишнее уже не выйдет.
В коде это будет выглядеть так:
using (SqlConnection conn = new SqlConnection())
{
conn.ConnectionString = @"Server=.;Database=AdventureWorks2014;Trusted_Connection=true";
conn.Open();
SqlCommand command = new SqlCommand(
"SELECT TOP(5) name FROM sys.objects WHERE schema_id = @schema_id", conn);
command.Parameters.Add(new SqlParameter("schema_id", value));
...
}Теперь точно нужно сделать паузу, иначе материал рискует стать нечитабельным…
Краткие итоги по 38 страницам текста расположенного выше
Работа с базой данных — это не всегда сырок моцарелла и смузи после 8-часового дня. Есть много аспектов, на которые нужно обращать внимание при написании запросов на T-SQL. Тут я попытался собрать часть граблей, на которые сам в свое время наступал.
Безусловно, это не исчерпывающий список «подводных камней» при работе с SQL Server, но все же я надеюсь, что данный материал будет кому-то полезным. В дальнейшем я постараюсь по мере сил пополнять этот пост новыми примерами.
Если будут вопросы, конструктивные предложения и разумная критика, то все контакты в профиле.
Видео
Читать всю эту информацию весьма утомительно, поэтому для любителей «послушать» уже давно готово видео на канале russianVC: Вредные советы для новичков. Видео отличается от поста отсутствием нескольких примеров и тем, что сейчас я не состою в штате фирмы о которой упоминал на видео.
Что осталось за бортом?
Изначально планировать подробно написать про различия между временными таблицами и табличными переменными. В итоге решил оформить это в отдельный пост, который ожидает своего завершения в январе.
Кроме того, хотел бегло рассказать про parameter sniffing, но лучше не изобретать велосипед и привести ссылку на отличный пост от Дмитрия Пилюгина: Медленно в приложении, быстро в SSMS.
Ближайшие мероприятия
В 26 ноября в Днепре будет проходить SQL Saturday 2016 Dnepr (#sqlsatdnipro) — однодневный бесплатный тренинг для разработчиков и тех кто хочет узнать что-то новое по SQL Server. Будет куча спикеров и интересных докладов. Предварительное расписание можно посмотреть тут.
Комментарии (40)

jobgemws
14.11.2016 21:39+4Отличная статья-завтра проголосую, сегодня заряда нет(
Еще добавлю, что не нужно делать фиктивных обновлений.
Часто вижу приложение, которое делает фиктивное обновление каких-либо строк. В результате чего напрягает стандартную репликацию. И еще хуже-когда при сохранении удаляются строки и добавляются новые (при этом таблица реплецируема). Видел такие разработки на C++ и C#. И еще неоптимально, когда в качестве первичного ключа берут ГУИД, которым никто пользоваться не будет. Нет чтобы взять ту же дату вставки например с каким-нибудь полем-уж явно чаще использоваться будет и в сортировках в том числе.

andreishe
15.11.2016 01:53+1Я правильно понимаю, что такой вариант конкатенации строк так же может не работать:
DECLARE @a VARCHAR(max) = NULL; WITH a AS ( SELECT 1 AS a UNION ALL SELECT 2 AS a UNION ALL SELECT 3 AS a ) SELECT @a = COALESCE(@a + ',', '') + CAST(a AS VARCHAR) FROM a SELECT @a
?
AlanDenton
15.11.2016 08:14И да… и нет… это все зависит от оптимизатора. Например, наши примеры работать будут, но MS не гарантирует этого поведения всегда (именно поэтому не рекомендуется так делать):
DECLARE @a VARCHAR(MAX) ;WITH E1(N) AS ( SELECT * FROM ( VALUES ('1'),('1'),('1'),('1'),('1'), ('1'),('1'),('1'),('1'),('1') ) t(N) ), E2(N) AS (SELECT '1' FROM E1 a, E1 b), E4(N) AS (SELECT '1' FROM E2 a, E2 b) SELECT @a = COALESCE(@a + ',', '') + N FROM E4 ORDER BY LEN(N) SELECT @a
Увы хорошее репро у меня было только одно, что я привел в статье.

akzhan
15.11.2016 05:27Большая часть статьи из разряда "а как иначе?".
Но обычно так думаешь уже постфактум :)
Так что плюсую.
Kalata
15.11.2016 07:19MS SQL Server 2005 не поддерживает формат Date, поэтому, к сожалению, параграф 6 не применить на практике.
AlanDenton
15.11.2016 08:04+1То что на 2005 нету типа DATE еще не говорит о том, что эта версия себя как-то по особенному ведет. Там тоже нужно следить за форматом строковой константы для даты. Или Вы имели ввиду какой-то отдельный случай?
Все что я описал сохраняет актуальность с 2005 версии и по 2016 (за мелкими исключениями, потому что кое где планы выполнения будут другими).Kalata
15.11.2016 08:51+1Не совсем корректно, конечно, прокомментировал, параграф 6 можно и нужно применять на практике, с оговоркой про Date. Совет про YYYYMMDD работает и в версии 2005.

npocmu
15.11.2016 07:20+4Функция ISNULL преобразует к наименьшему типу из двух операндов. COALESCE преобразует к наибольшему типу.
ISNULL преобразует к типу первого операнда.
ISNULL позволяет сбросить признак nullable с колонки (бывает нужно при создании видов или временных таблиц).
COALESCE позволяет указывать много аргументов.
Добавление в копилку полезных приемов:
Создавать временные таблицы желательно без явного указания типов, путем копирования типов нужных полей из таблиц с которыми собираемся в дальнейшем работать. Например:
SELECT e.BusinessEntityID
, p.FirstName
, p.MiddleName
, p.LastName
INTO #TmpTable
FROM HumanResources.Employee e
JOIN Person.Person p ON p.BusinessEntityID = e.BusinessEntityID
WHERE 0=1
Получаем пустую временную таблицу с колонками нужных типов. И, если в будущем размерность какого-либо поля изменится, код переписывать не придется.
Хинт1. конструкт NULLIF(column,column) as column позволяет писать в колонку временной таблицы NULL, даже если в исходной NULL не допустим.
Хинт2. конструкт column+0 AS column позволяет снять признак IDENTITY с колонки

BalinTomsk
15.11.2016 09:29---Зачем BIGINT по таблице с сотрудниками?
Я бы больше сказал — только guid. Иначе когда приложение выростет до уровня Enterprise и вам придется настраивать Peer-To-Peer репликацию а то и вставлять гуиды из серверов приложения — все эти инты в дизайне встанут боком.AlanDenton
15.11.2016 09:34Ситуации бывают разные. Например, у меня пару проектов уровня Enterprise крутились на экспресс версии SQL Server 2014. Ни секционирования, ни колумсторов… в дополнении ограничен гигом оперативы и медленным диском. Так чтобы все «помещялось» в BufferPool такие заморочки с типами данных как раз были бы не лишними.
mayorovp
15.11.2016 09:46Да здравствует распухание кластерного индекса из-за вставок в рандомных местах? :)
Существуют приложения, которые никогда не вырастут до того уровня, где требуется merge-репликация.
mayorovp
15.11.2016 09:38+1Некоторые советы тут бесполезные.
Про даты — надо не искать "универсальный" формат даты, а указать нужные настройки для соединения. А еще лучше — использовать параметризованные запросы и вообще не указывать даты в строковых литералах.
Про NULL в (NOT) IN. Необходимость выполнить такой запрос по атрибуту, не являющемуся первичным ключом — говорит о том, что схему БД забыли перевести в третью нормальную форму. Не надо так делать.
- Кстати, где совет использовать третью нормальную форму?
… а лучше всего использовать ORM и не мучаться с "сырыми" запросами.
Долго ждал, но так и не увидел случаев, когда действительно стоит слезть с ORM на уровень ниже. А их два:
передача на сервер действительно больших массивов данных. Решение — делаем хранимую процедуру, которая принимает табличный параметр. На стороне ADO.NET передаем в качестве параметра в запрос DataTable.
- быстрый подсчет агрегатов через индексированные (они же материализованные) представления. Классический пример — баланс аккаунта можно считать как сумму изменений баланса по журналу операций.
Для "старших" редакций само наличие индексированного представления ускорит запросы, в которую используются подсчитанные агрегаты. Для "младших" (Express/Developer Edition) — надо делать выборку именно из индексированного представления, указав
with(noexpand). Удобно создавать второе представление, которое делаетselect * from ... with (noexpand)— его можно завести в ORM как read-only таблицу.AlanDenton
15.11.2016 09:47Если про даты еще ладно… у каждого проекта свои особенности. Но вот с NOT NULL приколом сталкивался регулярно, когда старые базы саппортил. Знать об этом надо!
… а лучше всего использовать ORM и не мучаться с «сырыми» запросами.
Вот тут не согласен. Зачем так категорично? :)
Относительно индексированных представлений… OLTP или DW? Их не всегда выгодно применять. Там много приколов, особенно когда присутствует неслабая OLTP нагрузка.
mayorovp
15.11.2016 10:42В OLTP: тут вопрос в том, требуется ли агрегат в процессе обработки поступающей транзакции. Если требуется — то хочешь-не хочешь, а придется где-то его хранить и оперативно обновлять. Если не требуется — то зачем он вообще нужен?
В DW: нет никаких препятствий для создания стольких индексированных представлений, сколько хочется.
vlivyur
16.11.2016 14:16+1Так не только из твоего приложения запросы к БД будут, иногда ещё и сам запросы пишешь в SSMS и тут уж от строки в дате не отвертеться.
Qtuzof
15.11.2016 09:56Добавьте в начале оглавление с ссылками на места в статье. Хотел показать человеку один пункт, потратил пару минут чтобы его найти.

minamoto
16.11.2016 13:11+2Держите оглавление:
$('.post__title').after('<div class="directory"><h1>Содержание</h1></div>');$('h5').each(function(index) {$(this).attr('id', 'h5_' + index); $('.directory').append('<br/><a href="#h5_' + index + '">' + $('h5')[index].innerText + '</a>');})
Nitrelios
15.11.2016 09:56Я бы конечно мог посоветовать использовать функцию STRING_CONCAT, если бы она была… На дворе 2016 год, а отдельной функции для конкатенации строк, в SQL Server так и не добавили
А как же функция CONCAT? Появилась в MS SQL Server 2012
Статейка хорошая! автору спасибо.AlanDenton
15.11.2016 09:58Имелось ввиду конкатенация строк, а не столбцов.
Nitrelios
15.11.2016 10:09А что мешает строки ей конкатенировать? Из вашего же примера:
DECLARE @txt VARCHAR(50) = '' SELECT @txt = CONCAT(@txt, i) FROM #t SELECT @txt
mayorovp
15.11.2016 10:44+1Invoking CLR User-Defined Aggregate Functions
Прямо в документации — реализация конкатенирующей агрегатной функции для примера...

silvercaptain
20.11.2016 11:50Уже не актуально… в 2016 они таки это побороли :)
https://msdn.microsoft.com/en-us/library/mt790580.aspxAlanDenton
20.11.2016 12:56По поводу актуальности можно поспорить… vNext не относится к 2016-му. На последней версии SQL Server 2016 SP1 (13.0.4001.0) вот такое мы получим:
Msg 195, Level 15, State 10, Line 4
'STRING_AGG' is not a recognized built-in function name.
Хотя к слову, крайне советую ознакомиться с изменениями в новом SP1 для 2016-го.
В Express, Standart редакциях можно наконец-то использовать секционирование и columnstore индексы. С небольшими оговорками конечно, но все равно круто :)silvercaptain
20.11.2016 15:50Имелся в виду год, а не версия :)
проверял, работает на этой:
Microsoft SQL Server vNext (CTP1) — 14.0.1.246 (X64)
Nov 1 2016 23:24:39
Copyright © Microsoft Corporation
on Linux (CentOS Linux 7 (Core))
Dimano
15.11.2016 11:14+1Касательно 21 пункта, как насчёт варианта с сэлфджойном?
SELECT p.BusinessEntityID, s.SalesQuota FROM Person.Person p LEFT JOIN Sales.SalesPersonQuotaHistory s LEFT JOIN Sales.SalesPersonQuotaHistory s1 ON s1.BusinessEntityID = s.BusinessEntityID AND s1.QuotaDate > s.QuotaDate ON s.BusinessEntityID = p.BusinessEntityID AND s1.[Первичный ключ] IS NULL
Сейчас не могу сам проверить.Dimano
16.11.2016 10:29+2Сам и проверил. self join лучше чем вариант с TOP 1, но проигрывает оконной функции, базы AdventureWorks2014 у меня нет, проверил на своих данных, эксперимент не чистый так как там есть и другие соединения но тем не менее. Во всех случаях беру результаты второго подряд запроса.
TOP 24.69s
self join 13.33s
ROW_NUMBER 7.05s
Спасибо за статью!
periskop
15.11.2016 18:35+1Спасибо за статью! Сначала читал и никак не мог вспомнить, где же это было. Потом вспомнил, что было все в докладе, подумал: «Ай, как нехорошо, все из доклада взял, а автора не упомянул», — и только потом догадался проверить, что автор тот же.
Кстати, ссылка на доклад Сергея: https://www.youtube.com/watch?v=C1I5v1xxJv4. В том же канале есть видео со всех прошлых встреч Russian Virtual Chapter.
osh4
15.11.2016 18:35Спасибо за статью! Хорошая ревизия уже известного, но и нового узнал еще больше.
Небольшое замечание:
SUBSTRING(@Email, CHARINDEX('@', Email) + 1, LEN(@Email))
3й параметр должен быть LEN(@Email)-CHARINDEX('@', Email), моя «любимая» ошибка кстати при работе с substring.osh4
15.11.2016 19:07+1Упс, посыпаю голову пеплом. Удивительно, но работает и в вашем варианте. Причем, работает одинаково хорошо с varchar, char, даже если выходит за границы строки. Почему такое возможно?
minamoto
16.11.2016 12:46+2Потому что функция «глупая», но «умная». «Глупая» — потому что нет возможности опустить этот параметр, показав, что мы хотим получить все до конца строки. «Умная», потому что если оставшихся символов больше, чем есть в строке, функция не упадет, а вернет все оставшиеся символы. С таким же успехом туда можно поместить максимальное значение int — функция все равно не будет падать, а будет возвращать данные.
Это поведение описано в документации:
If the sum of start and length is greater than the number of characters in expression, the whole value expression beginning at start is returned.

heleo
16.11.2016 19:16А что если для пятого пункта написать отбор через JOIN (LEFT JOIN)?
minamoto
17.11.2016 10:19+1Можно так сделать, конечно, но, думаю, в данном случае смысл был именно показать особенности конструкции IN/NOT IN применительно к NULL-овым значениям.
heleo
18.11.2016 01:27Я собственно почему спросил: что выгодней применить в таком случае?
minamoto
18.11.2016 11:14Так можно посчитать.
Репро:
Заголовок спойлераDECLARE @t1 TABLE (t1 INT, UNIQUE CLUSTERED(t1)) INSERT INTO @t1 VALUES (1), (2) DECLARE @t2 TABLE (t2 INT, UNIQUE CLUSTERED(t2)) INSERT INTO @t2 VALUES (1), (NULL) set statistics io on SELECT * FROM @t1 WHERE t1 NOT IN ( SELECT t2 FROM @t2 WHERE t2 IS NOT NULL ) SELECT * FROM @t1 EXCEPT SELECT * FROM @t2 SELECT * FROM @t1 WHERE NOT EXISTS( SELECT 1 FROM @t2 WHERE t1 = t2 ) select t_1.* from @t1 t_1 left join @t2 t_2 on t1 = t2 where t2 is null
x893
Насчет CURSOR не совсем согласен. Не все операции можно сделать при помощи T-SQL. Иногда жизнь требует более сложных алгоритмов обработки — напрмер сделать процедуру.
AlanDenton
Поддерживаю Ваше мнение. Но все же старался донести мысль, что чаще всего курсоры применяют там где они не нужны. Если не брать во внимание административных задач и совсем древних версий (вроде SQL Server 2005), то я раза два-три вынужденно использовал курсоры и они задачу решали намного быстрее.
x893
2005 не такой уж древний. Вот если SQL Server 6.
Раньше был продукт у QuestSoftware — FrogLight, рисовал такие зеленые Dashboard и мерял жизнь SQL в реальном времени. В том числе и запросы. Очень удобная была программа. Потом когда Dell купил их — и TOAD и остальные полезняшки как то пропали.
rinnaatt
сейчас этот продукт называется SpotLight
vlivyur
Да, особенно с таким ужасным примером. Честно, я не видел чтоб так делали и сам так не делал. Хотя и сам был новичком, который sql ни разу не видел и сразу макнули в него, и вокруг всегда было много новичков. Хотя вот динамический sql там, где обычным можно — видел.
Вот если б там ещё б добавили к курсору fast_forward, static, read_only, forward_only в комбинациях и всё это сравнили с циклом по временным таблицам (время исполнения, чтение/запись), то да, было б интересно. Есть ещё задачи, когда одним запросом дорого по времени (сервера или разработчика), а с циклом быстрее/понятнее.