
Изменения курса рубля два года назад заставили нас задуматься о способах снижения стоимости железа для Почты Mail.Ru. Нам понадобилось уменьшить количество закупаемого железа и цену за хостинг. Чтобы найти, где сэкономить, давайте посмотрим, из чего состоит почта.

Индексы и тела писем составляют 15 % объёма, файлы — 85 %. Место для оптимизаций надо искать в файлах (аттачах в письмах). На тот момент у нас не была реализована дедупликация файлов; по нашим оценкам, она может дать экономию в 36 % всего объёма почты: многим пользователям приходят одинаковые письма (рассылки социальных сетей с картинками, магазинов с прайсами и т.д.). В этом посте я расскажу про реализацию такой системы, сделанной под руководством PSIAlt.
Хранилище метаинформации
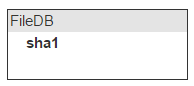
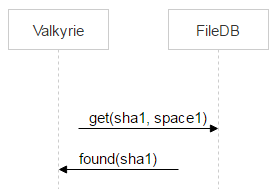
Есть поток файлов, и надо быстро понимать, дублируется файл или нет. Простое решение — давать им имена, которые генерируются на основе содержимого файла. Мы используем sha1. Изначальное имя файла хранится в самом письме, поэтому о нём заботиться не надо.
Мы получили письмо, достали файлы, посчитали от содержимого sha1 и значение вычисления добавили в письмо. Это необходимо, чтобы при отдаче письма легко найти его файлы в нашем будущем хранилище.
Теперь зальём туда файл. Нам интересно спросить у хранилища: есть ли у тебя файл с sha1? Это значит, что надо все sha1 хранить в памяти. Назовём место для хранения fileDB.
Один и тот же файл может быть в разных письмах; значит, будем вести счётчик количества писем с таким файлом.
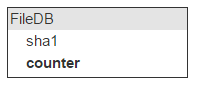
При добавлении файла счётчик увеличивается. Около 40 % файлов удаляется. Соответственно, при удалении письма, в котором есть файлы, залитые в облако, надо уменьшать счётчик. Если он достигает 0 — файл можно удалить.
Тут мы встречаем первую сложность: информация о письме (индексы) находится в одной системе, а о файле — в другой. Это может привести к ошибке, например:
- Приходит запрос на удаление письма.
- Система поднимает индексы письма.
- Видит, что есть файлы (sha1).
- Посылает запрос на удаление файла.
- Происходит сбой, и письмо не удаляется.
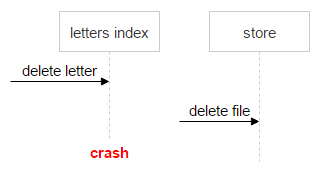
В этом случае письмо осталось в системе, а счётчик уменьшился на единицу. Когда второй раз придёт удаление этого письма — мы ещё раз уменьшим счётчик и получим проблему. Файл может быть ещё в одном письме, а счётчик у него нулевой.
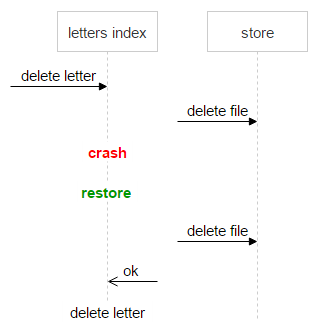
Важно не потерять данные. Нельзя допустить ситуацию, когда пользователь открывает письмо, а файла там нет. При этом хранить на дисках немного лишних файлов не проблема. Достаточно иметь механизм, который однозначно покажет, корректно или нет счётчик свёлся к нулю. Для этого мы завели ещё одно поле — magic.
Алгоритм простой. В письме вместе с sha1 от файла мы генерируем и сохраняем ещё одно произвольное число. Все запросы на заливку или удаление файла делаем с этим числом. Если пришёл запрос на заливку, то к хранимому magic прибавляем это число. Если на удаление — отнимаем.
Таким образом, если все письма корректное количество раз увеличили и уменьшили счётчик, то magic тоже будет равен нулю. Если он отличен от нуля — удалять файл нельзя.
Давайте рассмотрим это на примере. Есть файл sha1. Он залит один раз, и при заливке письмо сгенерировало для него случайное число (magic), равное 345.

Теперь приходит ещё одно письмо с таким же файлом. Оно генерирует свой magic (123) и заливает файл. Новый magic суммируется со старым, а счётчик увеличивается на единицу. В результате в FileDB magic для sha1 стал равен 468, а counter — 2.

Пользователь удаляет второе письмо. Из текущего magic вычитается magic, запомненный во втором письме, counter уменьшается на единицу.
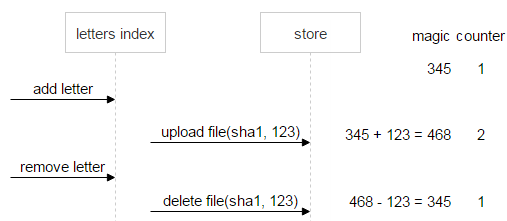
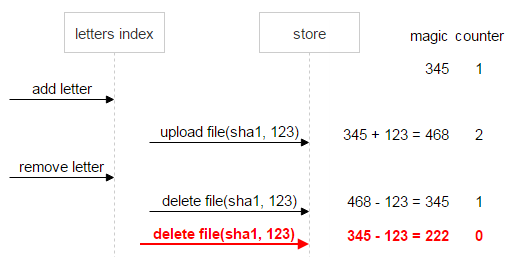
Сначала рассмотрим ситуацию, когда всё идёт хорошо. Пользователь удаляет первое письмо. Тогда magic и counter станут равны нулю. Значит, данные консистентны, можно удалять файл.

Теперь предположим, что что-то пошло не так: первое письмо отправило две команды на удаление. Counter (0) говорит о том, что ссылок на файл не осталось, однако magic (222) сигнализирует о проблеме: файл удалять нельзя, пока данные не приведены к консистентному состоянию.
Давайте докрутим ситуацию до конца и предположим, что и первое письмо удалено. В этом случае magic (–123) по-прежнему говорит о неконсистентности данных.
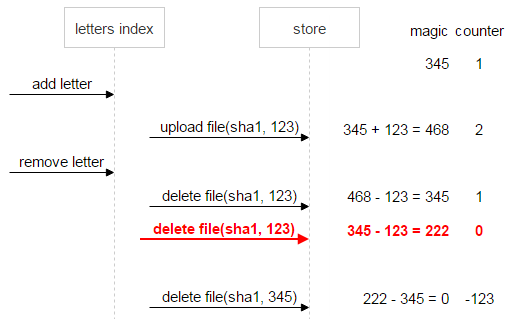
Для надёжности сразу же, как только счётчик стал равен нулю, а magic — нет (в нашем случае это magic = 222, counter = 0), файлу выставляется флаг «не удалять». Так что даже если после множества добавлений и удалений по дикому стечению обстоятельств magic и counter сравняются с нулём, мы всё равно будем знать, что файл проблемный и удалять его нельзя.
Вернёмся к FileDB. У любой сущности есть некоторые флаги. Планируете вы или нет, но они понадобятся. Например, вам надо пометить файл как неудаляемый.
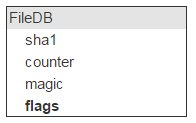
У нас есть все свойства файла, кроме главного: где он физически лежит. Это место идентифицирует сервер (IP) и диск. Таких серверов с диском должно быть два.
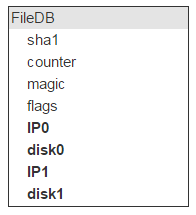
Но на одном диске лежит много файлов (в нашем случае — около 2 000 000). Значит, у этих записей в FileDB в качестве места хранения будут одни и те же пары дисков. Так что хранить эту инфу в FileDB расточительно. Выносим её в отдельную таблицу, а в FileDB оставляем ID для указания на запись в новой таблице.
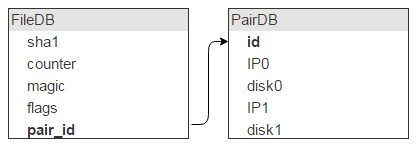
Думаю, очевидно, что, помимо такого описания пары, нужно ещё поле flags. Забегая вперед, скажу: во флагах лежит информация о том, что диски сейчас залочены, например один вылетел и второй копируется, поэтому ничего нового на них писать нельзя.

Также нам надо знать количество свободного места на каждом диске. Добавляем эти поля в таблицу.

Чтобы всё работало быстро, FileDB и PairDB должны быть в оперативной памяти. Возьмём Tarantool 1.5. Сразу скажу, что сейчас следует использовать последнюю версию. В FileDB пять полей (по 20, 4, 4, 4 и 4 байта), итого 36 байт данных. Ещё на каждую запись хранится header размером 16 байт плюс по 1 байту на длину каждого поля. Итого получается 57 байт на одну запись.

Tarantool позволяет задать в конфиге минимальный размер для аллокации, так что можно свести практически к нулю размер накладных расходов по памяти. Мы будем аллоцировать ровно столько, сколько надо под одну запись. У нас 12 000 000 000 файлов.
(57 * 12 * 10^9) / (1024^3) = 637 GbНо это не всё, нам нужен индекс по полю sha1. А это ещё 12 байт на запись.
(12 * 12 * 10^9) / (1024^3) = 179 GbИтого получается около 800 Gb оперативной памяти. Но не забываем про реплики, а это значит ? 2.

Если берём машины с 256 Gb оперативной памяти, то нам потребуется восемь машин.
Мы можем оценить размер PairDB. Но средний размер файла у нас 1 Мб и диски размером 1 Tb. Это позволяет хранить около 1 000 000 файлов на диске. Значит, нам надо около 28 000 дисков. Одна запись в PairDB описывает два диска, следовательно, в PairDB 14 000 записей. Это пренебрежимо мало по сравнению с FileDB.
Заливка файлов
Со структурой баз данных разобрались, теперь перейдем к АПИ для работы с системой. Вроде нужны методы upload и delete. Но вспомним о дедупликации: не исключено, что файл, который мы пытаемся залить, уже есть в хранилище. Нет смысла заливать его второй раз. Значит, потребуются такие методы:
- inc(sha1, magic) — увеличить счётчик. Если файла нет — вернуть ошибку. Вспоминаем, что ещё нам нужен magic. Это позволит защититься от неверных удалений файлов.
- upload(sha1, magic) — его следует вызывать, если inc вернул ошибку. Значит, такого файла нет и надо его залить.
- dec(sha1, magic) — вызывается, если пользователь удаляет письмо. Сначала мы уменьшаем счётчик.
- GET /sha1 — скачиваем файл просто по http.
Разберём, что происходит во время upload. Для демона, который реализует этот интерфейс, мы выбрали протокол iproto. Демоны должны масштабироваться на любое количество машин, поэтому не хранят состояние. К нам приходит по сокету запрос:

По имени команды мы знаем длину заголовка и считываем сначала его. Сейчас нам важна длина файла origin-len. Надо подобрать пару серверов для его заливки. Просто выкачиваем весь PairDB, там всего несколько тысяч записей. Далее применяем стандартный алгоритм выбора нужной пары. Составляем отрезок, длина которого равна сумме свободных мест всех пар, и случайно выбираем точку на отрезке. В какую пару попала точка на отрезке — та и выбрана.

Однако выбирать пару таким простым способом опасно. Представьте, что все диски заполнены на 90 % и вы добавили пустой диск. С огромной вероятностью все новые файлы будут литься на него. Чтобы избежать этой проблемы, нужно брать для построения общего отрезка не свободное место пары, а корень N-й степени от свободного места.
Пару выбрали, но наш демон потоковый, и если мы начали стримить файл на сторедж, то обратной дороги нет. Поэтому, прежде чем заливать реальный файл, вначале отправляем небольшой тестовый. Если заливка тестового файла прошла, тогда вычитаем из сокета filecontent и стримим его на сторедж. Если нет — выбираем другую пару. Sha1 можно считать на лету, поэтому его мы тоже проверяем сразу при заливке.
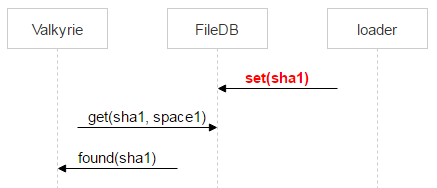
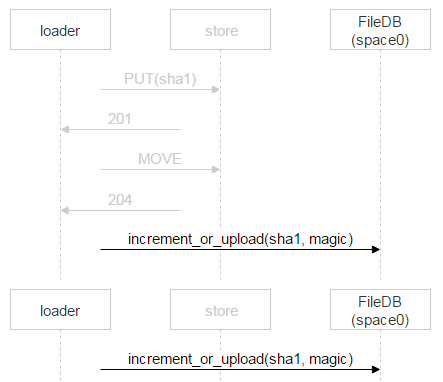
Рассмотрим теперь заливку файла от loader к выбранной паре дисков. На машинах с дисками мы подняли nginx и используем протокол webdav. Пришло письмо. В FileDB этого файла ещё нет, а значит, его надо через loader залить на пару дисков.
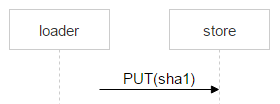
Но ничего не мешает ещё одному пользователю получить такое же письмо: предположим, у письма два адресата. В FileDB этого файла пока нет; значит, ещё один loader будет заливать точно такой же файл и может выбрать эту же пару.
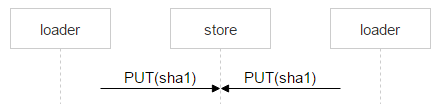
Скорее всего, nginx решит проблему корректно, но нам надо всё контролировать, поэтому сохраняем файл со сложным именем.
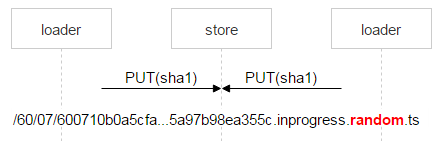
Красным выделена часть имени, в которой каждый loader пишет случайное число. Таким образом, два PUT не пересекаются и заливают разные файлы. Когда nginx ответил 201, loader делает атомарную операцию MOVE, указывая конечное имя файла.
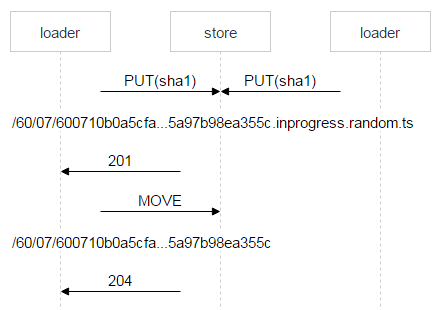
Когда второй loader дольёт свой файл и тоже сделает MOVE, файл перезапишется, но это один и тот же файл — проблем не будет. Когда он окажется на дисках, надо добавить запись в FileDB. Тарантул у нас разбит на два спейса. Пока мы используем только нулевой.

Однако вместо простого добавления записи о новом файле мы используем хранимую процедуру, которая либо увеличивает счётчик файла, либо добавляет запись о файле. Почему так? За время, когда loader проверил, что файла нет в FileDB, залил его и пошёл добавлять запись, кто-то другой уже мог залить этот файл и добавить запись. Выше мы рассматривали как раз такую ситуацию. У одного письма два получателя, и два loader’а стали его заливать. Когда второй закончит, он тоже пойдёт в FileDB.
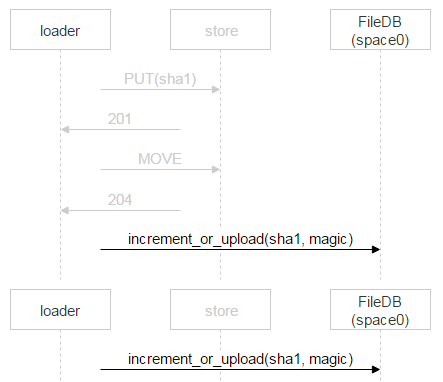
В этом случае второй loader просто инкрементирует счётчик.
Теперь перейдём к процедуре dec. Для нашей системы приоритетны две задачи — гарантированно записать файл на диск и быстро отдать его клиенту с диска. Физическое удаление файла генерирует нагрузку на диск и мешает первым двум задачам. Поэтому его мы переносим в офлайн. Сама процедура dec уменьшает счётчик. Если последний стал равен нулю, как и magic, то файл больше никому не нужен. Мы переносим запись о нём из space0 в space1 в тарантуле.
decrement (sha1, magic){
counter--
current_magic –= magic
if (counter == 0 && current_magic == 0){
move(sha1, space1)
}
}Valkyrie
На каждом сторадже у нас есть демон Valkyrie, который следит за целостностью и консистентностью данных, как раз он и работает со space1. Один диск — один инстанс демона. Демон перебирает файлы на диске один за другим и проверяет, если ли запись о файле в space1, иными словами — надо ли его удалить.
Но между переносом файла в space1 при выполнении операции dec() и обнаружением файла валькирией проходит время. Значит, между этими двумя событиями файл может быть залит ещё раз и опять оказаться в space0.
Поэтому Valkyrie сразу проверяет, не появился ли файл в space0. Если это случилось и pair_id записи указывает на пару дисков, с которой работает текущая валькирия, то удаляем запись из space1.
Если записи не оказалось, то файл — кандидат на удаление. Всё же между запросом в space0 и физическим удалением есть временной зазор. Стало быть, в этом зазоре опять же есть вероятность появления записи о файле в space0. Поэтому мы помещаем файл на карантин.

Вместо удаления файла переименовываем его, добавляя в имя deleted и timestamp. То есть физически мы удалим файл timestamp + какое-то время, указанное в конфиге. Если произошёл сбой и файл решили удалить по ошибке, то пользователь придёт за ним. Мы восстановим файл и исправим ошибку, не потеряв данные.
Теперь вспоминаем, что дисков два, на каждом работает своя Valkyrie. Валькирии никак не синхронизируются друг с другом. Возникает вопрос: когда удалять запись из space1?
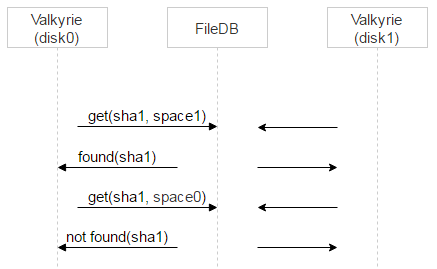
Делаем две вещи. Для начала назначаем для конкретного файла одну из Valkyrie мастером. Делается это очень просто: по первому биту из названия файла. Если он 0, то мастер — disk0, если 1, то мастер — disk1.

Теперь разнесём их по времени. Вспомним: когда запись о файле находится в space0, там есть поле magic для проверки консистентности. Когда мы переносим запись в space1, magic не нужен, поэтому запишем в него timestamp времени переноса в space1. Теперь Valkyrie master будет обрабатывать записи в space1 сразу, а slave будет добавлять к timestamp задержку и обрабатывать записи позже + удалять их из space1.
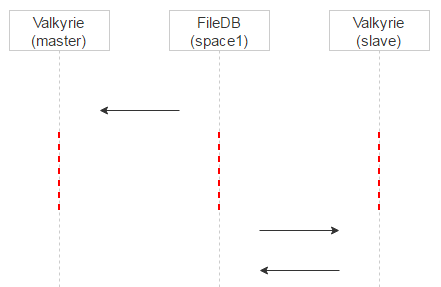
За счёт этого мы получаем ещё один плюс. Если на мастере файл ушёл в карантин по ошибке, то при запросе на мастер мы это увидим в логах и разберёмся. Клиент, который запрашивал файл, тем временем сфолбечится на slave, и пользователь получит файл.
Мы рассмотрели случай, когда Valkyrie находит на диске файл с именем sha1 и у этого файла (как кандидата на удаление) есть запись в space1. Давайте рассмотрим, какие ещё варианты возможны.
Пример. Файл есть на диске, но о нём нет записи в FileDB. Если в рассмотренном выше случае Valkyrie master по каким-то причинам некоторое время не работал, slave успел поместить файл на карантин и удалить запись из space1. В этом случае мы тоже ставим файл на карантин через sha1.deleted.ts.
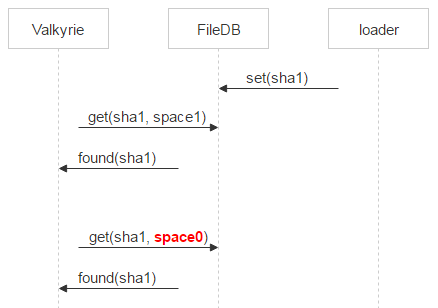
Ещё пример. Запись есть, но указывает на другую пару. Это может случиться при заливке файла, если одно письмо пришло двум адресатам. Давайте вспомним схему.
Что случится, если второй loader лил файл не на ту же пару дисков, что и первый? Он инкрементирует счётчик в space0, но на паре дисков, куда он лил, останутся мусорные файлы. Мы идём на эту пару и проверяем, что файлы читаются и совпадает sha1. Если всё ОК — то такие файлы можно сразу удалять.
Ещё Valkyrie может встретить файл на карантине. Если срок карантина истек, то файл удаляется.
Теперь Valkyrie натыкается на хороший файл. Его надо прочитать с диска и проверить на целостность, сравнить с sha1. Затем — сходить на другой диск из пары и выяснить, есть ли там файл. Для этого достаточно HEAD-запроса. Целостность файла проверит демон, запущенный на той машине. Если на текущей машине целостность файла нарушена, то он тут же загружается с другого диска. Если на том диске файл отсутствует, то заливаем его с текущего диска на второй.
Нам осталось рассмотреть последний кейс: проблемы с диском. После мониторинга админы понимают, что это случилось. Ставят диск в режим service (readonly) и на втором диске запускают процедуру размува. Все файлы со второго диска раскидываются по другим парам.
Результат
Вернёмся к началу. Наша почта выглядела так:

После переезда на новую схему мы сэкономили 18 Pb:

Почта стала занимать 32 Пб (25 % — индексы, 75 % — файлы). Освободившиеся 18 Пб позволили нам долгое время не покупать новое железо.
P.S. про sha1
Так как много вопросов в комментариях, допишу тут. На текущий момент нет известных, публично вычисленных примеров коллизии самого SHA-1. Есть примеры коллизии для инициализирующих векторов на функцию компрессии (SHA-1 freestart collision). Вероятность, что на 12млрд файлах произойдет случайная коллизия, менее 10^-38.
Но предположим, что такое возможно. В этом случае при запросе файла по sha1 мы проверим его соответствие размеру и crc32, которые запомнили в индексах конкретного письма при заливке. Т.е. файл мы отдадим, только если он был залит с этим письмом, или не отдадим ничего.
Комментарии (87)

astudent
06.12.2016 13:221) Почему вместо magic не использовать еще один счетчик?
2) Правильно ли я понял, что случайно перебирая sha1 пользователь может читать чужие файлы в почте?PSIAlt
06.12.2016 13:29+41) Именно случайный magic дает защиту от декремента «чужой» единицы счетчика. Если он у всех одинаковый — то желаемый эффект не достигается.
2) Во-первых, хеши соленые, так что его нельзя угадать. Во-вторых, перебирать — этож сколько вариантов? В третьих — снаружи вообще нет интерфейса, позволяющего взять файл по хешу. Туда ходит только библиотека доступа к storage, и только она внутри себя знает как работать с этим хешом.
AndrewSumin
06.12.2016 14:20Помимо того что публичного интерфейса нет, надо еще и авторизацию получить чтобы читать файлы другого ящика.

z3apa3a
06.12.2016 15:42+2sha-1 имеет длину 160 бит. При наличии 12 000 000 000 файлов, чтобы случайным перебором наткнуться на файл, надо перебрать порядка 10^38 (2^120) комбинаций.

dimabest
06.12.2016 14:09-1А что делать когда файлы разные, а sha1 одинаковый?
AndrewSumin
06.12.2016 14:09+1Приведите пример таких файлов.

catap
06.12.2016 14:55в сложном документе, например PDF или картинке, где лишние байты будут игнорироваться :) можно совершить атаку и подобрать мусор что бы два разных (по содержанию отображаемому пользователю) документа имели одинаковый хеш.
Мне кажется правильным как минимум держать размер (в байтах) файла, а лучше использовать две хеш функции для и размер, тем самым сводя вероятность коллизий совсем до минимума.
Например для md5 я с ходу нашел такую очень старую (~10 лет) работу: http://cryptography.hyperlink.cz/md5/MD5_collisions.pdfAndrewSumin
06.12.2016 14:57+2А примеры файлов дайте :)
catap
06.12.2016 15:00-2Давай я тебе лучше ссылку дам где находят коллизию для SHA1 за 76 шагов: https://marc-stevens.nl/research/sha1freestart/
:)
Но я согласен что если начать считать стоимость нахождения этой коллизии то это на amazon ec2, то это будет пара сотен тысяч долларов.AndrewSumin
06.12.2016 15:05Если я верно понял там оперируют бессмысленным набором бит?
В пару сотен тысяч долларов входит нахождение коллизий реальных файлов, фотографий или документов?
:)khim
07.12.2016 01:27Да, входит. Очень много форматов позволяют приписать чушь в конце — и при этом файл будет валидным.
Дальше, если соли нет, атака — тривиальна: посылаем документ, в котором даём банковские реквизиты для перевода денег куда-нибудь в оффшор с одного специально заведённый аккаунта на mail.ru на другой.
А настоящий документ (с той же sha1 суммой) — чуть позже уже тому, кто, собственно, должен перевести этих денег.
После чего эти временные аккаунты удаялем — и готово дело: mail.ru подменил реквизиты платёжки, потому деньги ушли неизветно куда.
Конечно человек, у которого есть такие деньги и который при этом пользуется ящиком на mail.ru — несколько странен, но… атака — вполне реальная.z3apa3a
07.12.2016 02:42+1Не совсем так. Вы описали chosen-prefix collision attack, в то время как сейчас для SHA-1 пока идет речь о возможности просто нахождения коллизии с теоретической оценкой сложности 2^80 вычислений. Для сравнения, для MD5 сейчас существуют алгоритмы нахождения коллизии за ~2^16 вычислений, в то время как для заданного префикса требуется ~2^50 вычислений.
z3apa3a
07.12.2016 02:56P.S. Ну и сама описанная атака на практике мало что дает атакующему — если он контролирует содержимое обоих писем, то что ему мешает сразу отправить подмененные реквизиты?
Проблема критична, например, в случае SSL, т.к. можно сделать два разных запроса на получение сертификата, и получить подпись, которая действительна для обоих. При этом например один запрос на свой домен, а другой на чужой, или один простого сертификата на имя домена, а во втором добавить роль удостоверяющего центра. Это как раз примеры, в которых использовались коллизии MD5.
PSIAlt
06.12.2016 16:27+3Размер есть в индексах. Также, там есть crc по другому алгоритму, который при заборе тоже сверяется. Сам забор письма, собирание его из разных частей, сверка консистентности, форматирование и много чего реализовано в отдельной либе/сервисе. Это довольно обширный топик тоже, поэтому мы его не затрагиваем пока.
В общем, теоретическая возможность коллизии все же есть, однако она теоретическая, еще не встречалась и легко обнаруживается при доступе к «подмененному» файлу. Также напомню, что хеш соленый не известно чем, если даже известно — то это еще надо подобрать чтобы все сошлось=)
homm
06.12.2016 17:53Спасибо за действительно хороший технический ответ. Было приятно прочитать, в отличии от ответов AndrewSumin
catap
06.12.2016 17:59Спасибо за корректный ответ, просто из статьи сложилось впечатление что вы проверяете только хеш.
AndrewSumin
06.12.2016 18:20В целом можно в статье добавить абзац и выйти за рамки системы хранения. Немного раскрыть тему проверки консистентности файла и письма в индексах самих писем.
catap
06.12.2016 18:22да, это было бы очень полезно и сняло бы вопросы подобные моим, просто сейчас создается ложное впечатление что тут большие проблемы.
Т.е. лучше просто дописать что уникальность обеспечивается не только sha1 хешем, но еще тем-то и тем-то и вероятность коллизий есть, но она теоретическая и вообще она вот-такая (и цифру какая она маленькая), а исходя из ограничение на максимальный размер письма/аттача она получается таки равна нулю :)AndrewSumin
06.12.2016 18:48Дописал.
catap
06.12.2016 19:29Т.е. файл мы отдадим, только если он был залит с этим письмом, или не отдадим ничего.
Ого.
shalomman
06.12.2016 14:56+2ну хеш коллизии никто не отменял.
Вероятность не большая даже на 12 лярдов файлов, но всеже.
Учитывая что уже были известны аттаки на sha1 хеш коллизии, то теоритически, имея файл, я могу методом чудо-перебора не дать ему быть послланным в будущем адресатам мэил.ру заняв его место файлом с идентичным хэшем.z3apa3a
06.12.2016 15:59+2На самом деле на текущий момент нет известных публично вычисленных примеров коллизии самого SHA-1, есть примеры коллизии для инициализирующих векторов на функцию компресии (SHA-1 freestart collision). Вероятность что на 12млрд файлах произойдет случайная коллизия менее 10^-38.
doloh88
06.12.2016 14:09Разберём, что происходит во время upload. Для демона, который реализует этот интерфейс...
Когда пользователь прикрепляет вложение к письму во фронтенде, файл загружается, но не сразу передается демону? Где-то кэшируется?
Всегда было интересно узнать, как реализуется задача по загрузки большого количества файлов. Например,
сервер, получающий файлы по http, потоковый? Для каждого соединения отдельный поток?AndrewSumin
06.12.2016 14:14Для заливки файлов во время написания у нас используется похожий механизм. Отдельный инстанс облака заточенный именно под написание письма, а не хранения.
Сам loader, как написано в статье потоковый. http сервер который принимает файлы от пользователя (nginx) не потоковый, но там мы не упираемся в ресурсы поэтому эту проблему не решали.

iit
06.12.2016 14:10Меня интересует вероятность коллизии — так как используеться sha1 она очень мала но все-же есть.
Были ли такие случаи, когда вместо договора человек при открытии письма получит открытку с котиками?AndrewSumin
06.12.2016 14:11+2Насколько мне известно с осмысленными файлами таких коллизий до сих пор не обнаружено, у вас есть пример?
Ziere
06.12.2016 19:03Что на счёт атаки дней рождения?
AndrewSumin
06.12.2016 19:04Дописал в конец статьи отдельный блок про sha1 раз тема такая популярная.
z3apa3a
06.12.2016 19:28Она не работает при такой большой разности множеств (2^34 vs 2^160). В статье о парадоксе есть табличка. Там к сожалению нет значений подохящих для SHA-1 (160 бит), на 128 битном хеше на 26 миллиардах файлов вероятность коллизии 10^-18.
Для 160-битного хэша и 12 миллиардов файлов можно оценить вероятность коллизии сверху примерно как 10^-38.z3apa3a
07.12.2016 00:29~10^-28 вероятность что произойдет хотя бы одна коллизия между любыми файлами. 10^-38 это коллизия для конкретного файла. Какого либо заметного влияния birthday paradox здесь нет.
iit
06.12.2016 23:33К сожалению примеров нет, но на всякий случай я бы сохранил еще mime файлов и размер. Но как уже выше проинформировал PSIAlt эти данные уже включены в crc и даже если случиться коллизия — это будет обнаружено и файл с приватной информацией будет доступен только из того письма, к которому он принадлежит.
HRT5
06.12.2016 14:11позволили нам долгое время не покупать новое железо
а какой рост хранимой информации за месяц? на сколько этого объема вам может хватить? были ведь просчеты
privatelv
06.12.2016 14:57Почта пользователя хранится на одном сервере на диске объединенном в райд 1?
privatelv
06.12.2016 15:04Простите, уточню. Если я правильно понял, то файлы раскладываются по двум дискам. Эти диски обязательно в двух разных ДЦ и зеркалируются ли они в райде?
AndrewSumin
06.12.2016 15:06+2Диски в разных подсетях. В рейде не заркалируются.
Enik_Benik
07.12.2016 19:08Скажите, а вообще наша почта и наши файлы в вашем облаке как то защищены от потери в случае программного или аппаратного сбоя? И, если да, то каким образом? Резервное копирование, какой-либо массив или что-то еще?
Волнует вопрос: делать ли локальный бэкап или хватит облака?AndrewSumin
07.12.2016 19:09+4Пол статьи про то как мы защищаемся от программного и аппаратного сбоя.
Все мои личные и рабочие письма и файлы находятся на наших серверах.

ANTPro
06.12.2016 15:10Судя по схеме у вас файл имеет в имени результат хэш функции еще до заливки на сервер в какой момент она расчитывается?
PSIAlt
06.12.2016 15:45До заливки в это облачко файл лежит в письме, которое естественно есть целиком у сервиса, который хочет положить письмо в ящик (например, MX). Соответственно, имея все письмо целиком он легко считает хеш каждого из его партов и может дать его вместе с телом файла.
tearexs
06.12.2016 15:27А что с форматами файлов? Если в основном это документы, текстовые файлы, то их дополнительно можно архивировать — высокий процент сжатия позволит еще более освободить диски

TITnet
06.12.2016 16:30Что будет, если magic два раза посчитается одним числом?
Имеем count: 2 и magic: 200 (100 на каждое письмо).
Происходит сбой и по первому письму приходит два раза команда на удаление.
Вычитаем из magic 100 дважды, соответственно, magic становится равным нуля. Как и count.
Файл удалён. Теперь он не доступен для второго письма.
Я не прав?PSIAlt
06.12.2016 16:47+2Все так. Максимальная вероятность такого события = p * 1/2^32, где p — вероятность ошибки при удалении. Если взять ее как 0.001(что явно много) то получается вероятность случайного удаления в таком случае ниже 2.3e-13. Но по факту она еще ниже, потому что в этой формуле не учитываются другие факторы, которые тоже уменьшают вероятность (например, что счетчик равен именно 2).
Также напомню что кроме этого уровня есть еще 3 уровня защиты от окончательной потери самого файла, но до них ни разу за 1.5 года не дошло (тфу-тфу) =)Ziere
06.12.2016 20:42Поделитесь тем, что представляют из себя эти три уровня?
PSIAlt
06.12.2016 21:58Описанные в статье (в разделе про валькирию) 2 вида карантина, плюс отложенное удаление на одной из пар. В случае чего — можно легко найти потерянный файл и закинуть обратно в облако с пометкой «не удалять», а потом устроить масштабные разборы полетов=) К счастью, пока не доводилось)
masterspline2
06.12.2016 19:12+1При создании новой записи для файла в FileDB (когда inc возвращает 1) можно было бы генерировать уникальный префикс и добавлять его к названию (и хранить в FileDB). В таком случае при удалении не нужен был бы сложный алгоритм проверок в Валькирии, потому что тот же самый файл заново создастся с другим именем (префиксом). Таким образом существенно упрощается алгоритм удаления файла, но придется всегда заливать файл на сервер, хотя, возможно, в редких случаях он там есть под другим именем (когда он еще не удален).
PSIAlt
06.12.2016 19:20Спасибо за комментарий, идея действительно хорошая. Признаюсь, она мне в голову не приходила=)
Однако тут есть 2 фактора: 1) мы бы все равно не убрали проверку RC в валькирии потому что существует вероятность и 2) реализация потребует дополнительного поля в filedb, а для 12млрд записей это довольно прилично по памяти.
Deosis
07.12.2016 07:21У вас в записи на длины полей, которые фиксированы и известны уходит около 10% (5 из 57) от длины записи. Можно ли исключить подобное?
PSIAlt
07.12.2016 09:35Их добавляет сам таранул для того чтобы уметь разобрать тапл на поля. По крайне мере в 1.5 так. Тут хотелось бы напомнить, что сам тарантул тоже должен уметь разбирать на поля т.к. работает с многими полями записей filedb на уровне луашек. Можно было бы это обойти, но тогда возникли бы вопросы по атомарности изменений в этих полях, так что я бы не стал=)
Ziere
06.12.2016 20:28А что всё-таки происходит с проблемными файлами? Они как-то дополнительно обрабатываются magic корректируется?
PSIAlt
06.12.2016 22:32+1Если кратко то пока никак не корректируется. Ставится флаг, что удалять нельзя.
В принципе, в планах есть приблизительно такой вариант: запомнить какой был counter&magic у таких хешей и начать обход по индексам. В результате обхода получаем какой должен быть counter&magic и обновляем их в filedb а-ля «compare and swap». Пока(тфутфу) таких «бессмертных файлов» особо и нет(по факту есть в тестовых ящиках) — задача не горит. Мы больше концентрируемся на том, чтобы они в этот разряд не попадали, т.к. любая подобная сверка — масштабная нежелательная операция. Так что на мой взгляд тут задача №1 — не давать попадать файлам в этот разряд и задача №2 — не сломать возможность сверки, если вдруг Вселенная восстанет против нас.=)
saslanov
06.12.2016 20:50По сути magic — это компактная замена списка обратных ссылок на письма, верно?
PSIAlt
06.12.2016 22:03Я бы не сказал. Скорее я бы назвал его вторым counter-ом, который инкрементится на неизвестную никому(кроме того, кто заинкрементил) величину.
saslanov
07.12.2016 00:00Ну получается что это неявный checksum тех, кто заинкрементил.
Т.е. можно тоже самое сделать имея явный списокPSIAlt
07.12.2016 00:41Да, можно было просто содержать список, грубо говоря email — id_письма — id_парта. И при декременте сверять с ним.
molec
07.12.2016 11:01Вот. Именно это первое и приходит в голову. И контроль проще в случае чего. И приходит же в голову очевидная проблема — огромные подсписки писем для «популярных» файлов. Но ведь тогда «популярные» можно просто помечать неудаляемыми и успокоиться. Почему-то же отказались от этой идеи и ввели довольно экзотический механизм?
PSIAlt
07.12.2016 12:59Ну если самих хешей 12млрд, а у каждого счетчик >=1, то сколько же таких записей будет?
Это затратно по ресурсам. Плюс еще есть такой фактор как консистентность: сейчас авторитетным источником для любого рода информации являются индексы писем. Если начать хранить обратные ссылки то рано или поздно возникнет ситуация, что информация не сходится, что тогда делать?molec
07.12.2016 13:59Грубо прикинул — стандартное решение подкинуло бы пару-тройку ТБ к объему базы, которую предполагается хранить в оперативке. Более чем довод. Статье очень не хватает обоснований принятых решений, чтобы было понятно, зачем все именно так, и почему это относительно безопасно.


Jabher
1. т.е. оркестратор для того, чтобы выполнять атомарные операции на серверах оказалось делать менее выгодно, чем делать решение с magic-числами?
2. в каком диапазоне генерируется magic, рассматривали ли вариант «только простые числа» для него?
3. считали ли вероятность отказа при создании этого алгоритма из-за событий малой вероятности?
AndrewSumin
1. А как конкретно оркестратор решит поставленную проблему и сколько для этого понадобится железа?
2. Это не принципиально поле все равно переполняется
3. Считали, огромное количество нулей после запятой
zirix
а почему нельзя сначала удалить письмо, а потом удалять файл?
PSIAlt
Разве где-то сказано что можно наоборот?
Пока письмо у пользователя в списке писем есть — все его части должны быть доступны, иначе не поймут=)
zirix
Если в counter было 1. И при удалении письма произошел сбой, то письмо останется без файла.
Если файл удалять(уменьшать counter) после того как письмо успешно удалено, то такой ситуации не возникнет.
И magic не нужн.
Magic может понадобиться если планируется возможный откат базы писем при котором вернутся удаленные письма.
Этот момент можно было упомянуть, иначе ваше решение выглядит не очень понятно.
Loki3000
В статье рассмотрен вариант: файл прикреплен к двум письмам (counter=2), при удалении первого письма произошел сбой и запрос на удаление файла ушел дважды. Письмо-то при этом удалилось… и счетчик обнулился… вот только файл не знает что он должен быть еще и в другом письме. Именно эту проблему и решает magic.
PSIAlt
> Если файл удалять(уменьшать counter) после того как письмо успешно удалено
Это иллюзия. Если во время сброса dirtypages возникнет ошибка, либо допустим машина перезагрузится — письмо потом «удалится» еще раз. Эта ситуация по сути и есть «откат базы», мейджик защищает от нее в том числе.
> при удалении письма произошел сбой, то письмо останется без файла
В обычной ситуации — да, но не в нашем случае=) Дело в том, что декремент не завязан на само действие пользователя (удаление письма). Удалив письмо — пользователь и никто другой его больше не увидит. Однако двойной декремент прийти в теории может, вот именно этот риск и страхуется. Это если очень вкратце, на самом деле индексы писем — очень большая и важная подсистема почты, о ней я надеюсь сможем рассказать отдельно и более детально, там много интересностей.
Shrizt
Обходное решение интересное, но неужели нет возможности сделать четкий контроль по удалению? Какие ситуации ведут к двойному уменьшению count?
Какой процент таких проблемных файлов накопился сейчас в системе? Например если оценить это в % от всех транзакций?
Защиту от коллизий sha1 вообще не стали делать? Всмысле — то что стащить чужой файл не получится — я понял из апдейта поста. А если коллизия произойдет — то файл в новом письме просто не сохранится?
PSIAlt
К сожалению, железо несовершенно и разработчики тоже. Как ни крути — будут баги программные, хардварные и разные ситуации. Наивно надеятся, что багов не будет, как бы вы не были аккуратны. При большой нагрузке ошибки будут, причем самые неожиданные. В этом ключе существует только 2 варианта: counter умеет ошибаться с бОльшую сторону, либо в меньшую. Конечно, лучше первое=) Процент неудаляемых файлов реально очень мал (<0.001%).
Небольшой перечень ситуаций, ведущих к ошибкам в counter:
— Ребут сервера
— Отказ диска
— Сетевая проблема (запрос на уменьшение дошел, а ответ на этот запрос — нет)
— Перегруз сервера filedb (запрос будет исполнен, но уже после таймаута)
— Баги (вклюючая segfault в любой части этой системы)
— Затуп в диск при логировании в async приложении приведет к таймаутам
— Наверняка еще 100500 кейсов, которые я сейчас не вижу
А как можно «защитить» sha1 от коллизий? Есть проверка, что это именно тот sha1, который был в письме (путем подсчета еще одной контрольной суммы). А защититься в полном смысле я думаю нельзя. Так что да, файл в новом письме не сохранится, в этом случае мы будем первыми в мире, кто найдет такой коллизию=) Пока на 12млрд хешей такого не произошло, по подсчетам z3apa3a этого не произойдет, пока хранилище не увеличится еще в 1e20 раз. Так что реально нет причин полагать, что такая проблема есть фактически.
P.S. Интересно вот что: ваши вопросы натолкнули меня на мысль) Почему так много вопросов про коллизии и так мало про счетчик? А ведь вероятность ошибиться в счетчике в результате бага и железной проблемы в миллиарды раз выше, чем вероятность коллизии. Перефразирую: есть сотни реальных(вероятность >1e1000) кейсов, когда счетчик разойдется и ни одного прецедента с коллизией.
z3apa3a
Magic не используется в нормальном режиме работы, это решение на случай сбоя, примерно такое же, как зеркалирование. Сбои происходят относительно редко. Вероятность коллизии для 32-битного счетчика на много порядков меньше вероятности, что два диска с данными на которых хранятся две копии одного файла выйдут из строя с интервалом не более минуты и обе копии файла будут гарантированно утеряны, не смотря на зеркалирование в разных датацентрах. Еще больше вероятность утери информации из-за действий пользователя. Вероятность отказа есть всегда, ее нельзя свести к нулю, ее можно свести к допустимому уровню. Эта технология не пригодна для хранения информации стоимостью миллиард долларов за файл (возможно, она может быть доработана до такого уровня, но такой задачи нет), но она вполне пригодна для хранения корпоративной и пользовательской переписки и корпоративных и пользовательских данных, т.к. она заведомо надежней чем RAID 1 или 5 в корпоративном сервере и уж тем более, чем незеркалированный диск в домашнем компьютере.
Shrizt
Спасибо за подробный ответ!
Рад что натолкнул на новые мысли :)
А если коллизию вы найдете, а файл не сохранится — как будете предъявлять миру? :)
Надо однако, если sha1 один, а размеры или crc разные — срочно емейлить оба файла в Книгу Гинесса! Ну или мне, я то уж донесу весть миру! Надеюсь файлы окажутся с приличным содержимым :)))
AndrewSumin
Емайлить файлы мы не будем. Это пользовательские данные и они принадлежат пользователям ))
khim
Коллизии — это борьба с саботажем. Статистика тут не работает. Вернее работает как в XKCD. Или как Перельмановский батальон солдат
PSIAlt
Нет, раз уж опять про коллизии, давайте окончательно разделим 2 кейса:
1. Случайное совпадение — об этом см пост выше. Гораздо вероятнее, что вы допустите ошибку и все разломается до того, как возникнет шанс на такой случай.
2. Саботаж (направленная атака). Статистика тут действительно не работает, однако: 1)хеш соленый 2) хеш наружу не отдается никогда 3)атакуемый хеш не известен 4) сложно подобрать подходящий атакуемому хешу файл 5) еще сложнее — если он соленый 6) еще сложнее — если он неизвестно как соленый 7) подобрав саботажную коллизию (в чем я категорически сомневаюсь с учетом вышесказанного) остается вопрос — в файле будут данные или мусор? 8) Если мусор то такой «саботаж» отклоняется за 5минут отправкой ссылки в любое другое хранилище документа, либо его изменением.
Обобщая все вопросы в комментариях про коллизии я для себя выводы сделал. Все слышали про теоретическую возможность; никто не делал ни единого верного шага на предмет как это сделать(и я тоже). Так что простите великодушно, я уже все что мог на эту тему написал.
Frozik
На счет п.2 я так полагаю спрашивали, когда magic_number_1 = n * magic_number_2 (и мы возвращаемся к ситуации, для которой вводили magic)
z3apa3a
Для этого надо, чтобы сбой на одном письме произошел n раз.
SkidanovAlex
Нет, ну тогда counter будет -n+1, а не ноль.
По простому двумя файлами сложно сломать magic, тремя файлами уже можно достаточно просто (magic = 7, 11, 15, второй файл удаляется три раза, magic и counter нули).
PSIAlt
В вашем примере чтобы такое произошло, нужно чтобы при заданном magic2 значения magic1 и magic3 были вполне конкретные (возможны варианты, но их множество очень ограничено). Выходит, что вероятность этого события сопоставима с 1/ (2^32 * 2^32)