Подход №1: По умолчанию
Самый простой способ заключается в том, чтобы полностью довериться механизму Entity Framework. Если создать пустой проект, а в нём – пустую модель данных, в которую добавить классы, на основании которых будет сгенерирована база данных, получится примерно следующее (инструмент — Visual Studio 2012):
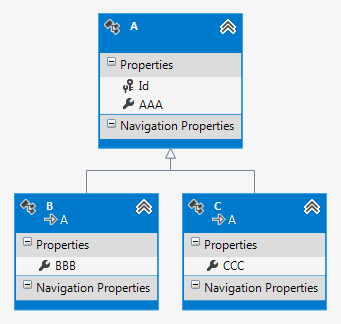
После создания в SQL Server будет находиться следующая модель данных:
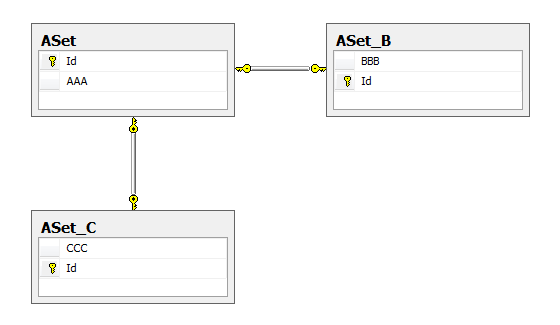
Что ж, весьма оптимально, надо признать. Единственное, что смущает – это специфичные имена таблиц. Вот соответствующие скрипты для создания таблиц базы данных, полученные с помощью инструмента «Tasks/Generate scripts»:
CREATE TABLE [dbo].[ASet](
[Id] [int] IDENTITY(1,1) NOT NULL,
[AAA] [nvarchar](max) NOT NULL,
CONSTRAINT [PK_ASet] PRIMARY KEY CLUSTERED
(
[Id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
CREATE TABLE [dbo].[ASet_C](
[CCC] [nvarchar](max) NOT NULL,
[Id] [int] NOT NULL,
CONSTRAINT [PK_ASet_C] PRIMARY KEY CLUSTERED
(
[Id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
CREATE TABLE [dbo].[ASet_B](
[BBB] [nvarchar](max) NOT NULL,
[Id] [int] NOT NULL,
CONSTRAINT [PK_ASet_B] PRIMARY KEY CLUSTERED
(
[Id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
ALTER TABLE [dbo].[ASet_C] WITH CHECK ADD CONSTRAINT [FK_C_inherits_A] FOREIGN KEY([Id]) REFERENCES [dbo].[ASet] ([Id]) ON DELETE CASCADE
ALTER TABLE [dbo].[ASet_C] CHECK CONSTRAINT [FK_C_inherits_A]
ALTER TABLE [dbo].[ASet_B] WITH CHECK ADD CONSTRAINT [FK_B_inherits_A] FOREIGN KEY([Id]) REFERENCES [dbo].[ASet] ([Id]) ON DELETE CASCADE
ALTER TABLE [dbo].[ASet_B] CHECK CONSTRAINT [FK_B_inherits_A]
Смущают в этом подходе только имена таблиц.
Подход №2: Classification
Этот способ показывает, как делали раньше, когда небо было выше, а динозавры ещё писали программы на фортране. (Признаться, мне казалось, что в эпоху MS SQL Server 2005 и Visual Studio 2008 я получил именно такой результат с помощью «Generate Database from Model» из Entity Framework.)
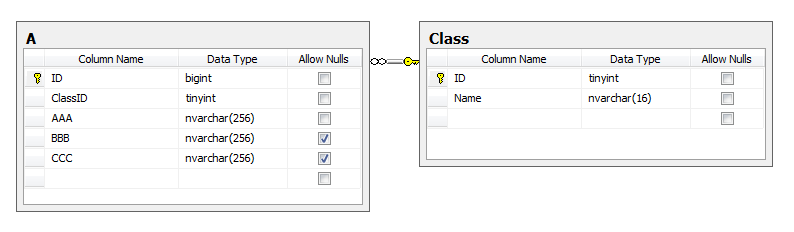
Скрипты и database-first модель данных я опущу, так как они достаточно тривиальны. Минус приведённого подхода очевиден. Как только у классов B и C вырастает количество столбцов, не относящихся к предку A (особенно, если это поля char[]-типа постоянного размера), то место на диске, занимаемое таблицей, начинает резко расти при том, что доля полезной информации в этом кладбище байт пропорционально сокращается. Нормализация? – не, не слышали… К сожалению, в силу исторических причин (например, для поддержания обратной совместимости), такие схемы всё ещё встречаются в крупных enterprise-проектах, разработка которых ведётся на протяжении нескольких лет. Но в новых разработках так поступать явно не стоит. Пожалуйста…
Подход №3: Polymorphic View
Создание view над таблицами, имеющими одинаковые поля, в коде может быть представлено с помощью интерфейса (представление view в коде) и реализующих его классов (представление таблицы в коде). Плюсов два. Первый состоит в том, нет таких проблем с неэффективным использованием дискового пространства, как в предыдущем подходе. Второй: можно использовать индексы и прочие штучки, ускоряющие выгрузку данных из базы. Минус – код для SQL-запросов на выборку и добавление данных писать придётся ручками. Вот, например, код выборки из такого view:
CREATE VIEW [A] AS SELECT * FROM (
SELECT [AID] AS ID, 1 AS [ClassID], [AAA] FROM [B]
UNION ALL
SELECT [AID] AS ID, 2 AS [ClassID], [AAA] FROM [C]
) Q
Очевидно, что поля таблиц B и C такой запрос получить не позволяет. Можно в него засунуть ещё и получение этих самых столбцов BBB и CCC, в результате чего ответ с кучей NULL-ов станет сильно похож на вариант Classification:
CREATE VIEW [A] AS SELECT * FROM (
SELECT [AID] AS ID, 1 AS [ClassID], [AAA], [BBB], NULL AS [CCC] FROM [B]
UNION ALL
SELECT [AID] AS ID, 2 AS [ClassID], [AAA] , NULL AS [BBB], [CCC] FROM [C]
) Q
Подход №4: Иерархические таблицы
Лично моё двухколёсное педально-рулевое решение заключается в создании отдельной таблицы для каждого класса-потомка, которые будут связаны с таблицей класса-родителя связями «1-к-1».
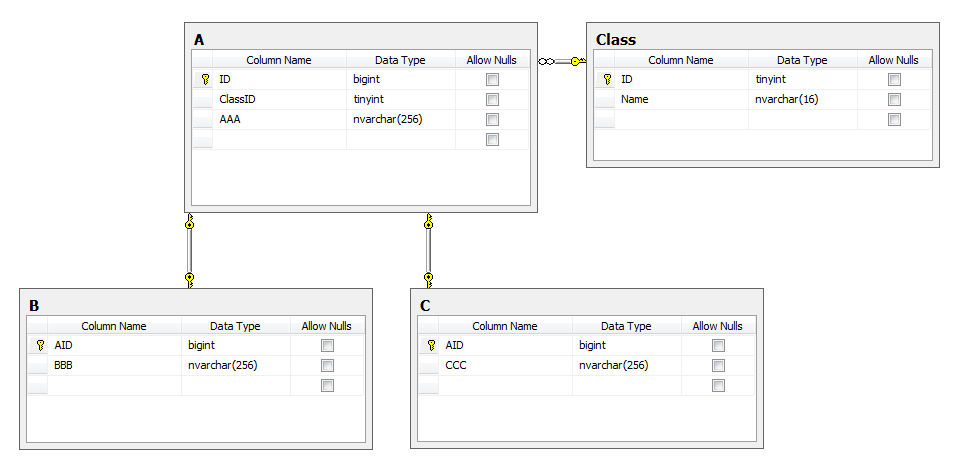
Очевидно, что поддерживать целостность такой схемы придётся с помощью триггеров, которые будут вырезать записи из родительской таблицы при удалении соответствующих детей (и наоборот) и контролировать добавление/редактирование записей, чтобы ребёнку из таблицы X соответствовала запись родителя с типом «X», а не, например, «Y».
Так как я люблю использовать в своих проектах Entity Framework, для создания соответствующей структуры классов мне приходится прилагать дополнительные усилия. Параллельно с классами из папки «Entity», куда попадает database-first сгенерированный код, имеется ещё папка «BusinessLogic», классы в которой имеют уже более внятные связи. Вот как делается код преобразования «Entity Framework > Business Logic» и «Business Logic > Entity Framework».
- Создаём интерфейс IA в папке «Entity».
public interface IA { A A { get; } EntityReference<A> AReference { get; } }
- Наследуем от него автосгенерированные классы B и C, лежащие в той же папке.
- Создаём enum с названием типа AClassEnum, в который переписываем фактически все строки из таблицы Class.
- В папке «BusinessLogic» создаём классы abstract A, B:A и C:A. (Кстати, делать A абстрактным не обязательно – просто у меня так получалось в силу требований.)
- Пишем примерно следующее:
public abstract class A { public long ID { get; set; } public abstract ClassEnum Class { get; } public string AAA { get; set; } protected A() { } protected A(Entity.IA a) { if (!a.AReference.IsLoaded) { a.AReference.Load(MergeOption.NoTracking /*внимание – эта опция не обязательна и зависит от вашей модели данных*/); } if (a.A.ClassID != (byte) Class) { throw new Exception("Class type {0} instead of {1}!", a.A.Class, (ClassEnum) a.A.ClassID)); } ID = a.A.ID; } public Entity. A CreateA() { return new Entity.A { ClassID = (byte) Class, }; } } public class B : A { public string BBB { get; set; } public override ClassEnum Class { get { return ClassEnum.B; } } public B() : base() { } public B(Entity.B b) : base(b) { BBB = b.BBB; } public override Entity.B ToEntity() { return new Entity.B { A = CreateA(), BBB = BBB, }; } } // аналогично для класса C
Преимущества по сравнению с:
- … подходом по умолчанию – более красивые имена таблиц
- … таблицей «классификации» – меньший объём данных
- … вьюшкой – всё красиво импортируется в Entity Framework
Понятно, что предложенный подход ни разу не является «золотой пулей». Тем более при том, что метод «по умолчанию» отрабатывает настолько хорошо. Но я думаю, что он может-таки кому-нибудь пригодиться в каких-либо специфических обстоятельствах.
Комментарии (17)

Nikita_Danilov
27.02.2017 13:11Хорошая подробная статья, интересно с точки зрения реализации, спасибо. Тем не менее встречный вопрос — а давало ли какие-либо преимущества натягивание ООП модели на реляционную БД?
Ни в коем разе не повторяюсь комментариям выше, именно хочу узнать каков профит получился. Последние тенденции вроде активно призывают минимизировать наследование, а уж внедрять его в реляционные БД совсем выглядит чужеродным.
lair
27.02.2017 13:15Тем не менее встречный вопрос — а давало ли какие-либо преимущества натягивание ООП модели на реляционную БД?
Это стандартное обсуждение в сторону использования-ORM-вообще. И на него есть стандартный же ответ: чем ближе модель, с которой работает программист, к его (программиста) идеальной модели, тем этому программисту легче работать. Соответственно, если где-то есть идеальный инструмент, который позволяет навалять в коде ОО-модель с интерфейсами и наследованием, а потом эффективно слить ее в БД и строить по ней запросы — программист будет тратить меньше времени на эту инфраструктуру и больше на собственно бизнес-задачи.

courage_andrey
27.02.2017 13:31а давало ли какие-либо преимущества натягивание ООП модели на реляционную БД?
Проект представлял из себя многокомпонентную систему, в которой доступ к данным быстро и без головной боли делался с помощью Entity Framework («быстро» было очень важно). Всех всё устраивало. Так как с самого начала было понятно, что разработка и сопровождение растянутся на 5+ лет, то структуру данных решено было делать максимально простой и прозрачной, чтобы уменьшить головную боль себе и коллегам, которые приступят к доработке спустя пару лет. То есть, максимально использовать принцип KISS, в том числе и заставить таблицы в БД соответствовать классам уровней бизнес-логики (их было 3, если я ничего не путаю).
хочу узнать каков профит получился.
Одни люди смогли быстро разработать и внедрить первую очередь продукта, а другие спустя пару лет не проклинали первых, когда сели за дальнейшую доработку проекта.
тенденции вроде активно призывают минимизировать наследование
Наследование — не более чем инструмент. Есть места, где он уместен, и есть, где он выглядит как седло на корове. Естественно, не все проекты, над которыми я работал, активно использовали наследование. Если сейчас в силу каких-либо новшеств становится всё больше проектов, где наследование скорее вредит, то вполне естественно, что его будут использовать меньше. И я его не буду пихать куда угодно просто в силу какой-то извращённой любви. Если я шутки ради (ну и в качестве курсового проекта, чего греха таить) написал (сильно упрощая) полиморфный вирус на T-SQL, это ни разу не означает, что T-SQL — это идеальный язык для написания полиморфных вирусов. Каждому инструменту — своё место на полке.
lair
А что такое ""правильное" ООП-наследование"?
Дайте я угадаю, вы используете model-first, не code-first?
Зачем вам в этой схеме дискриминатор? А без дискриминатора это та же первая схема, только с нормальными именами таблиц, и называется это table-per-type.
И уж точно нет никакого смысла делать дискриминатор отдельной таблицей.
courage_andrey
Да, в 4-х enterprise-проектах с Entity Framework использовался именно model-first.
Поясню:
1) Совсем без дискриминатора делать не вариант, потому что иногда приходится читать просто таблицу A. А как узнать «класс» записей в ней без дополнительных join-ов?
2) Дискриминатор и триггеры позволяют избежать ситуации, когда одной записи в таблице А соответствуют записи сразу в нескольких дочерних таблицах (например, B, C и F). Это вполне может быть некоторым оригинальным архитектурным решением, но с точки зрения ООП такая ситуация является ошибкой (если быть более точным, то это подмена наследования композицией).
3) В большом проекте отдельная таблица дискриминатора может использоваться для тестов. Пример из реального проекта: тест проверял, чтобы всем классам из структуры были проставлены корректные атрибуты (DataContact, использовавшийся WCF, и прочие, поддерживавшие инфраструктуру), перечисление (ClassEnum в тексте статьи) содержало все необходимые значения из базы и наоборот, а таблицы в БД соответствовали классам уровня Business Logic.
lair
(del)
lair
Это же не имеет никакого отношения к ООП.
Что "все это"? Структура таблиц не может подчиняться логике ООП, потому что это таблицы. Остаются классы. И что же вы имеете в виду?
Это называется table-per-hierarchy, и, на самом деле, никак ООП не противоречит.
То есть исключительно из соображений производительности? И тут немедленно возникает вопрос: а как в случае вашего решения EF строит запрос? У вас именно наследование (и вы убедили EF объединить дискриминаторы и TPT), или референсы?
Ну и да, теперь у вас две параллельных структуры классов (для хранения и для бизнес-логики). Что у них с областями видимости и применения?
Для этого не нужна таблица дискриминатора. Для этого, прямо скажем, вообще дискриминатор не нужен, для этого достаточно прочитать метаданные из модели и сопоставить их с БД.
courage_andrey
М-м-м, чем пахнет? По-моему, священной войной. Структура таблиц в БД может как соответствовать структуре классов на одном из уровней, так и не соответствовать. Я подчёркиваю: в статье я перечислил подходы, с помощью которых одно умышленно пыталось быть приведённым в соответствие со вторым в разных проектах (и разных организациях) на протяжении 10 лет. Причин так делать тоже было много и разных, в том числе навязанных дядьками предпенсионного возраста с другой половины глобуса.
Я наблюдал и больше, чем две параллельные структуры для одного и того же набора сущностей одновременно. Всё определяется требованиями.lair
Неа, пахнет некорректно сформулированной задачей.
Сначала вы пишете, что "Я имею в виду, что структура классов должна более-менее соответствовать структуре таблиц, и всё это должно подчиняться логике ООП", а потом вы пишете, что "причины навязаны". Так вот, есть большая разница между "я так делаю, потому что этого требует ООП" и "я так делаю, потому что этого требуют условия ТЗ, которые мне неподконтрольны".
… и за эти десять лет никто не попробовал взять другой инструмент, у которого нет описанных вами проблем?
Вот я и говорю: давайте определимся с требованиями. Вы говорите, что у вас есть требование, чтобы структура БД соответствовала структуре классов. Допустим. Каких классов? Судя по всему — доменной модели. Допустим (вы поправляйте, если не так). БД должна напрямую отображаться на доменные классы или через промежуточную структуру (то, что вы называете entity-классами)? Промежуточная структура разрешена или обязательна? Какие требования к этой промежуточной структуре (именование, наследование)? Какие требования на отображение доменных классов на промежуточную структуру (передача изменений, формирование запросов)? Какие операции на какой структуре совершаются?
Понимаете ли, между решениями "БД отображена напрямую на домен" и "БД отображена на DTO, которые отображены на домен" есть фундаментальная архитектурная разница, а вы легко и непринужденно в третьем решении подменили одно на другое.
courage_andrey
Попробую ответить покороче. Эта статья есть суммирование тех подходов, которые использовались для максимально близкого и простого сопряжения ООП, EF и SQL на примерно пяти совершенно разных проектах, разрабатывавшихся разными командами на протяжении примерно десяти лет. И требования там тоже разные были. И DTO был, и без него тоже обходились. Другими словами, я рассказал про цвета и формы ручек молотков, которыми мы забивали гвозди, (и, чего греха таить, иногда даже шурупы с болтами). И я очень не хочу спорить на тему того, что десять лет назад мне нужно было всё это делать отвёрткой, включая забивание гвоздей и закручивание гаек.
lair
Ну значит ваши выводы в конце статьи неверны: вы сравниваете решения разных задач.
courage_andrey
Тогда я предлагаю Вам, как очевидно более умному и опытному, сформулировать более точные выводы, которые больше подошли бы для этой статьи.
lair
А нет там выводов. "Такую-то задачу мы решали так-то, такую-то задачу мы решали так-то". И это, кстати, соответствует вашему же утверждению "Эта статья есть суммирование тех подходов". Чтобы можно было делать выводы, нужно решать одну и ту же задачу разными средствами и сравнивать их.
courage_andrey
Задача, озвученная в первом предложении:
Потом перечислены четыре подхода, как это делалось, со словами «плюс данного подхода» и «минус данного подхода». Последний (мой собственный) подход сравнивается с остальными (более общепринятыми).
Заключение:
Одна задача, разные способы, сравнение. Что ещё надо? Ах да, флейм впустую развести забыл! Ан нет, всё нормально, комментаторы за меня справятся.
lair
Обсудили же: непонятно, что такое "модель данных, которая содержит в себе "правильное" наследование".
Надо не забыть указать, что последний способ не будет работать без промежуточной модели. После чего немедленно возникает вопрос: ваша "модель данных" из вашей задачи — это промежуточная модель или доменная? Если промежуточная, то задача не решена. Если доменная, то есть фундаментальная разница в доступных операциях на этой модели, которая в ваших плюсах-минусах не учтена.