
Сегодня компьютерные программы начинают заменять бухгалтеров, продавцов, переводчиков и даже журналистов. Согласно докладу ООН, вскоре роботы займут 2/3 имеющихся рабочих мест в развивающихся странах. Насколько правдивы фантастические фильмы и можно ли уже сейчас говорить о полноценном развитии искусственного интеллекта?
Для того, чтобы ответить на этот вопрос, отследим развитие главных функций ИИ — аналитической, коммуникативной и творческой — в России и за рубежом. Подраздел науки об искусственном интеллекте, задачей которого является «обучить» компьютер «мыслить» (а значит, анализировать данные, выявлять скрытые закономерности и решать на основе них сложные задачи) называется машинным обучением (machine learning). Без преувеличения, эти исследования находятся на «переднем краю» науки, работы в данном направлении ведут крупнейшие и наиболее технологически развитые корпорации мира (включая Google, Microsoft и IBM). Разрабатываемые ими сервисы, такие как Google Predictions API, Microsoft Azure и IBM Watson позволяют создавать модели знаний на основе больших структурированных данных.

Рисунок 2. Эволюция информации в интернете.
Важно отметить, что алгоритмы обработки данных в подобных сервисах не запрограммированы жестко, они могут самостоятельно выявлять закономерности и делать определенные выводы. MIT Technology Review включил машинное обучение на основе полученных результатов (reinforcement learning, когда программа проводит эксперименты и «учится» на своих ошибках) в топ-10 самых прогрессивных, прорывных технологий 2017 года.
Уже сейчас IBM Watson диагностирует рак с точностью в несколько раз превышающей опытных врачей-диагностов. Экспоненциальный рост вычислительной техники (представлен на графике) демонстрирует ускоренное развитие возможностей подобных систем. Также следует отметить, что несмотря на свою технологическую сложность, эти программы имеют простой и дружелюбный интерфейс, что позволяет использовать их любому пользователю.
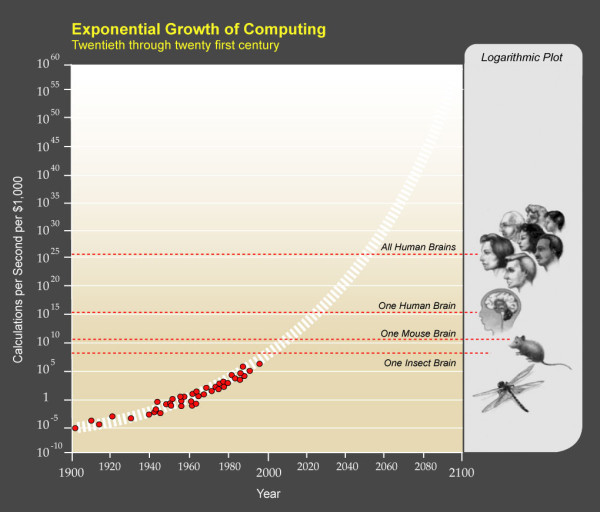
Рисунок 3. Экспоненциальный рост вычислительных возможностей (по Реймонду Курцвейлу).
Подобные системы развиваются и в России. Так, руководитель роботехнического центра Сколково Альберт Ефимов сообщил о разработке системы «Соцмедика», которая, по замыслу создателей, должна стать «реальным конкурентом» вышеупомянутому проекту Watson.
Другая российская разработка — платформа Brain2 компании “Когнитивные системы” — концентрируется на быстрой обработке bigdata в нейромодели знаний для систем ИИ. К примеру, нейромодель для оценки стоимости недвижимости (House Prices), обученная по 79 параметрам 1461 объектов недвижимости, способна предсказать стоимость объекта с незначительной ошибкой (RMSE=0,42), что равнозначно оценке опытного эксперта по недвижимости. При этом на обучение модели ушло всего 20 минут. Для сравнения, у опытного программиста-математика на решение подобной задачи с применением лучшей бесплатной библиотеки для машинного обучения Keras (TensorFlow) уйдет не менее 30 часов, а результат будет незначительно лучше (RMSE ? 0,32).

При значительной разнице в финансировании проектов, отечественные разработки не уступают, а где-то даже превосходят зарубежные аналоги. Так модель созданная в сервисе Google Prediction, для решения уже упомянутой задачи House Prices от Kaggle (сервиса для проведения конкурсов среди специалистов по машинному обучению) показывает RMSE = 7000, что в десятки тысяч раз хуже чем в Brain2.
Другие российские проекты в сфере ИИ обозначены на карте:
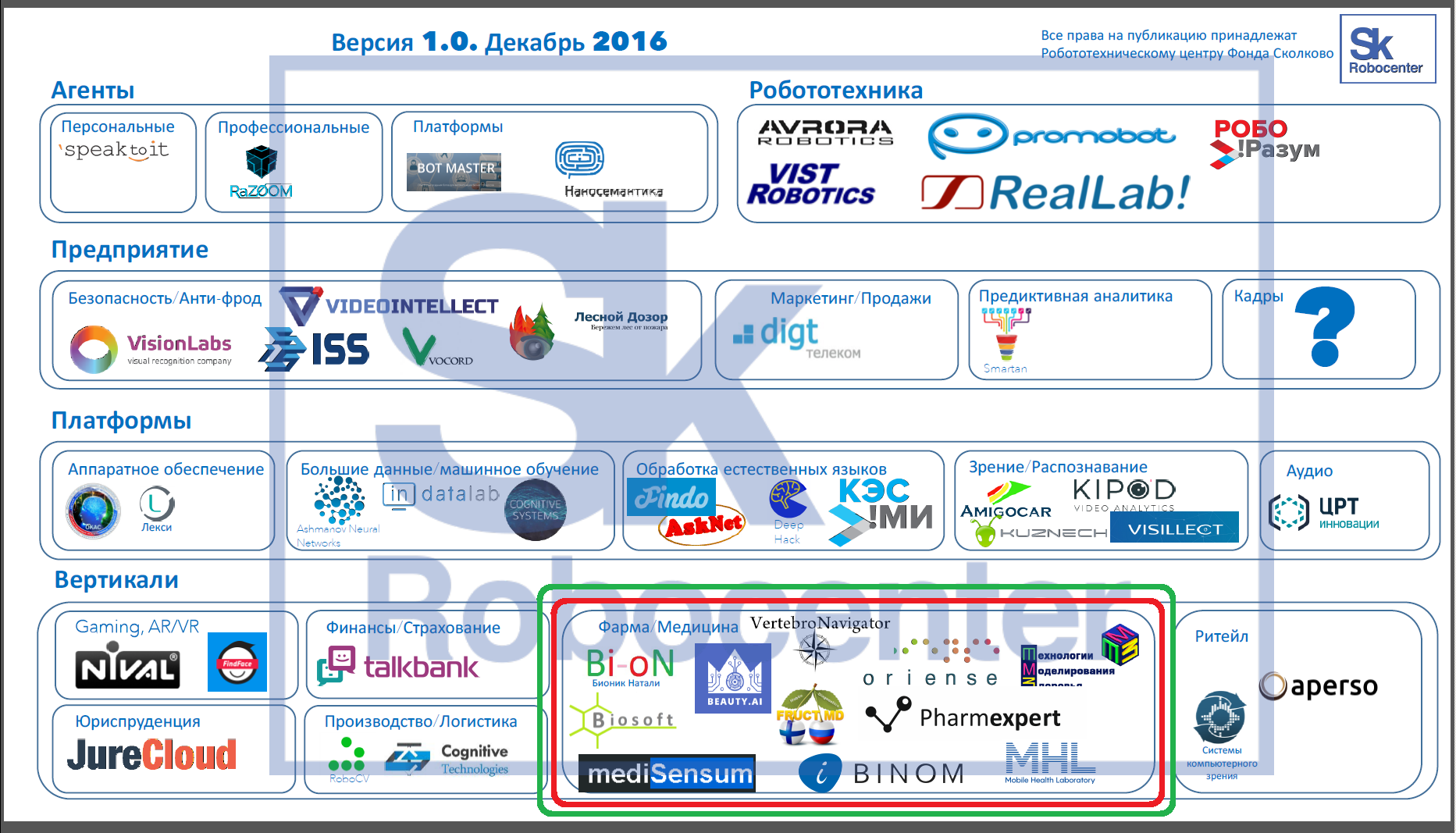
Рисунок 4. Карта российского ИИ.
И все же, развитие аналитической функции машин — не новость, но насколько современный ИИ способен коммуницировать с человеком? Самый известный пример такой коммуникации — помощники Siri и Google Assistant, установленные на устройствах Apple и Android соответственно. Обе эти программы значительно продвинулись в распознавании естественной речи и выполнении мелких поручений (написать сообщение, сделать заметку), но при этом не научились синтезировать собственные ответы на вопросы, поскольку и Siri, и Google Assistant могут отвечать — «зачитывая» найденные предложения. Выпущенная компанией Amazon в 2014 году Alexa работает чуть сложнее — синтезирует ответ на базе готовых шаблонов. Наконец, наиболее продвинутой технологией на данный момент обладает китайский робот Сяо Нань, известный тем, что написал статью на 300 иероглифов за 1 секунду. Примеры текста, синтезированного программой, приведены далее: «В первом квартале прогноз доходов от Apple над Уолл-стрит»; «Индекс потребительских цен августе выросли на 2% рекордно высокого уровня 12 месяцев»; «Анжу Мяньян 4,3 землетрясение произошло», «Олимпийские игры, настольный теннис женщин в одиночном четвертьфинале Дин Нин (Китай) 4: 0 легко вырезать круглый».
Безусловно, Сяо Нань пока не сможет заменить человека — журналиста: налицо проблемы со связностью текста, кроме того, Сяо Нань не умеет брать интервью и задавать дополнительные вопросы. Тем не менее, данный проект — один из немногих, где робот находит и синтезирует произвольный текст без явного шаблона.
А что же у нас? Банальное сравнение рейтинга на основе оценок десятков тысяч пользователей Google Play показывает, что созданный отечественными разработчиками голосовой помощник «Дуся» не уступает тому же Google Assistant. Ограничение «Дуси» такое же, как и у других голосовых помощников — программа выдает только готовые ответы на заданные вопросы (хотя, система Дуси позволяет создавать собственные функции с помощью написания скриптов, что принципиально не меняет функционал программы, но несколько расширяет область применения). Синтезировать же собственные ответы на вопросы умеет вышеупомянутый Brain2.

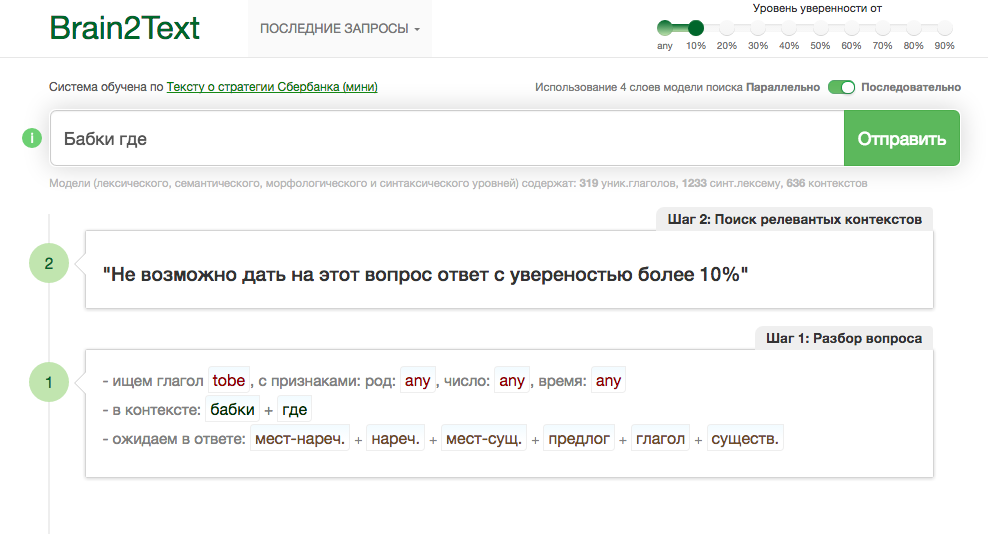
Например, разработанная на основе текста стратегии «Сбербанка» нейромодель (а точнее 7 многослойных нейробайесовых моделей со структурой FuzzyArt) способна осуществлять поиск релевантных запросу лексем и синтезировать из них ответ в виде предложения. Такая модель может быть использована в качестве «умного» чат-бота-помощника, причем точность подбора слов для ответов системы составляет 0,86, а правильность синтезирования ответа из выбранных слов достигает 0,91.

Рисунок 5. Модель Brain2Text.
В последние годы активно развиваются не только аналитическая и коммуникативная, но и творческая функция машинного разума. Самая сложная из них — это осмысленная поэзия. Из достижений можно выделить совместный проект Google и Университетов Стэнфорда и Массачусетса по обучению ИИ написанию стихотворений. Один из полученных результатов выглядит следующим образом:
there is no one else in the world.
there is no one else in sight.
they were the only ones who mattered.
they were the only ones left.
he had to be with me. she had to be with him.
i had to do this. i wanted to kill him.
i started to cry. i turned to him.
Не отстают и отечественные разработчики. Так, сотрудники «Яндекса» Алексей Тихонов и Иван Ямщиков выпустили альбом «Нейронная оборона», состоящий из песен и стихотворений, написанных роботом. Созданный ими алгоритм написал тексты в стиле Егора Летова, основателя группы «Гражданская оборона», а Тихонов и Ямщиков исполнили их. Альбом начинается со слов: «В ожидании чудес, невозможных чудес».
Другой российский проект «Пушкин» компании «Когнитивные системы» ставит своей целью научить ИИ сочинять стихотворения в стиле солнца русской поэзии (катрены 4-х стопным ямбом). Для этого разработаны модели по определению и подбору рифм, ударения в слове, ведутся работы над моделью смысловых ассоциаций по группе слов и комбинациям текста.
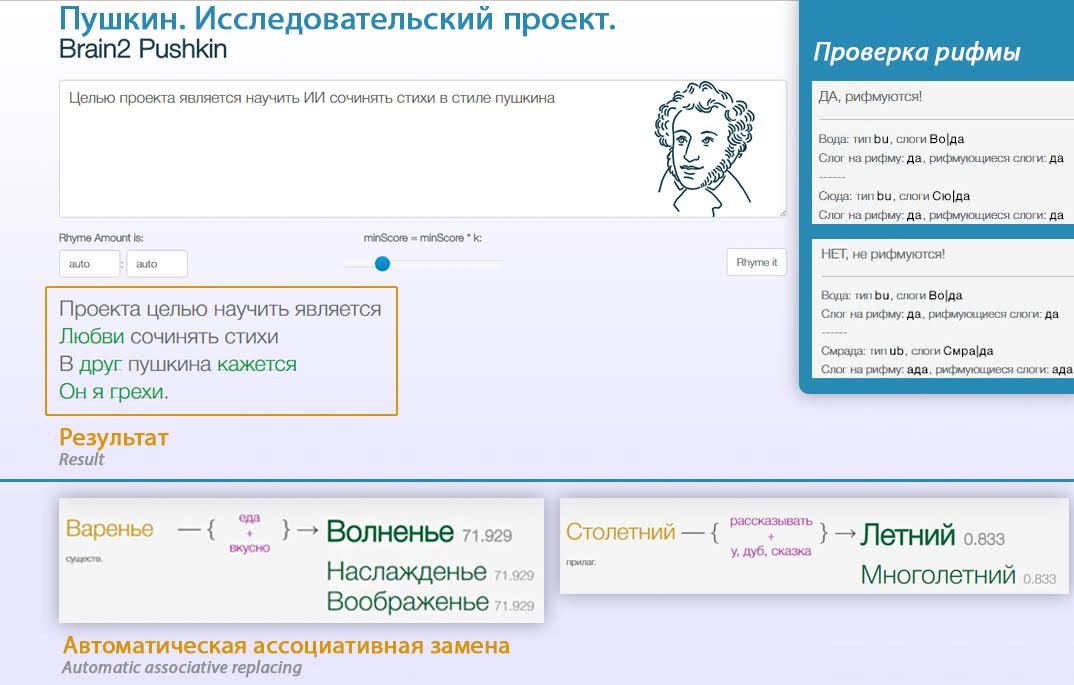
Рисунок 6. Проект «Пушкин».
Возможно, уже завтра мы будем жить в новом мире. В мире, где программы будут решать сложные задачи — водить машины, строить дома, проводить диагностику и хирургические операции — все это под нашим контролем при поддержании живого диалога человека и машины. Сможет ли Россия занять достойное место в этом новом мире? Время покажет. Одно можно сказать точно: стартовые позиции в «марафоне искусственного интеллекта» у нашей страны неплохие.
Ссылки:
1) Robots threaten up to two thirds of developing country jobs, but could be an opportunity too // UNCTAD.
2) 10 Breakthrough Techonlogies 2017 // MIT Technology Review.
3) Е. Кончаловская: Чьи рабочие места к 2030 году могут забрать компьютеры и роботы? // Портал TheQuestion.
4) Резидент Сколково поможет врачам не ошибаться // Полит.ру
5) Робот-журналист Сяо Нань написал дебютную статью за секунду // Портал «Вести».
6) Маленький Юг // Southern Metropolis Daily.
7) Google AI project writes poetry which could make a Vogon proud // The Guardian.
8) Нейронная оборона // Яндекс музыка.
Комментарии (50)

RiseOfDeath
28.03.2017 12:36+9А потом новости будут про коррупцию среди ИИ-чиновников, которые брали взятки процессорным временем и оперативкой.
upd.
Блин, промахнулся мимо нужной ветки.

AleCC
28.03.2017 13:07+8Если же русским (или российским — с недавнего времени озаботился данным, можно сказать философским вопросом) и удастся что либо разработать, способное конкурировать с мировым сообществом, то продадут в тот же США 100% как и любые разработки, вместе с разработчиками. Россия никогда не была в состоянии пожать плоды своих изобретений, да и не к чему они когда правительство думает о том повысить ли пенсию на 50 рублей или нет. Искусственный интеллект не для нашей реальности.

FirExpl
28.03.2017 13:45+1Вот для людей с нашим менталитетом ИИ как раз в самый раз)
Поставить его во главе правительства, чтобы он (оно?) принимал единоличные решения на благо государства и все будут только за. А где-нибудь в США народ возмущаться будет в такой ситуации :)Endimeon
28.03.2017 13:50+2А как же «Суровость закона компенсируется необязательностью его выполнения» (с)? Тогда уж и робокопов с ИИ нужно.
jex
28.03.2017 14:45А где-нибудь в США народ возмущаться будет в такой ситуации
И зря. Для государства лучше придерживаться одной, но взвешенной позиции, одного направления. Выборы важнее для разрыва коррупционных связей и создания конкуренции. У ИИ таких проблем не должно быть.
ЗЫ да, я понимаю что коммент выше был в шутливой форме, но тема интересная)LennoxRize
28.03.2017 15:42+1Верно говорите, но реальность, вернее, человеческая природа вносит коррективы. Так то в идеальном мире коммунизм вообще будет лучшей формой устройства общества.
nidheg666
28.03.2017 16:28-1сначала погугли что такое коммунизм. ничего что коммунизм это отрицание всякой частной собственности.
LennoxRize
28.03.2017 17:32У меня сразу пара вопросов: причем тут частная собственность? С чего бы мне сходу что-то гуглить по совету левого рандома, который даже свою позицию пока не сформулировал?
nidheg666
28.03.2017 17:54-1позиция проста — коммуннизм несостоятелен даже как идея. грезят о нём только те, кто даже толком не знают что он означает.
LennoxRize
28.03.2017 20:05Поскольку это недостотачно явно следовало из моего первого коммента, то поясняю: я не мечтаю о коммунизме и сам резкий антикоммунист. Я просто менее категоричен в оценках. Коммунизм вполне состоятелен как идея построения утопии. Но именно как «идея» и именно «утопии». Реализовать его на практике невозможно по огромному количеству причин, и человеческая природа, то есть психика — одна из них.

sticks
29.03.2017 08:26коммунизм это отрицание всякой частной собственности
Это откуда такие выводы? Всегда считал, что коммунизм — это общественная собственность на средства производства.
lexa1980
29.03.2017 15:21а без частной собственности счастья не видать?
знаю многих кто был более счастлив в СССР чем сейчас.
хотя там частная собственность была сильно ограничена.
любая частная собственность это автоматическое деление на классы. богатый — бедный.
богатых много не бывает :)

Sormovich
29.03.2017 12:51+1«Вот для людей с нашим менталитетом ИИ как раз в самый раз)
Поставить его во главе правительства, чтобы он (оно?) принимал единоличные решения на благо государства и все будут только за. А где-нибудь в США народ возмущаться будет в такой ситуации :)»
Сальвадор Альенде пытался, наняв Стаффорда Бира. Проект «Киберсин». В результате в Чили к власти пришёл Пиночет.
«Мозг фирмы»
http://www.rulit.me/author/bir-stafford/mozg-firmy-download-free-58096.html
Проект Киберсин
http://biofile.ru/his/30045.html

AndyKorg
28.03.2017 14:14+2Много-много раз читал
«При значительной разнице в финансировании проектов, отечественные разработки не уступают, а где-то даже превосходят зарубежные аналоги»
и десять и двадцать лет назад. Могу ошибаться, но вот так на вскидку кроме Яндекса не могу вспомнить проектов вышедших на мировой рынок.
Отсюда вывод: Хотя «стартовые позиции в «марафоне искусственного интеллекта» у нашей страны неплохие, но „значительная разница в финансировании проектов“ приведут либо к миграции проектов за рубеж, либо к тихому умиранию.
APLe
28.03.2017 14:43Можно более старые отечественные разработки вспомнить, вроде БЭСМ-6. На мировой рынок они не вышли из-за железного занавеса, но были более чем конкурентоспособны.
Хотя количество таких разработок удручающе малО, да.
river-fall
28.03.2017 16:22Да и Яндекс в основном знают как компанию, вирусно распространяющую свой Яндекс.бар

EvilArcher
28.03.2017 14:29+3Какой-то наивный вопрос вынесен в заголовок статьи. Ответ на него, естественно, «Нет».
Вот, если его переформулировать так: «могут ли выходцы из России стать лидерами в «марафоне искусственного интеллекта»». Тогда ответ будет «Да». В России можно найти таланты, но работать и развивать ИИ в этой стране им не получится.LonelyCruiser
28.03.2017 17:32Да, если вдруг что нибудь и появится, то охотники за головами быстренько выследят и вывезут голову, это придумавшую в теплые края (финансово).

BelBES
28.03.2017 17:12+6Что это было?
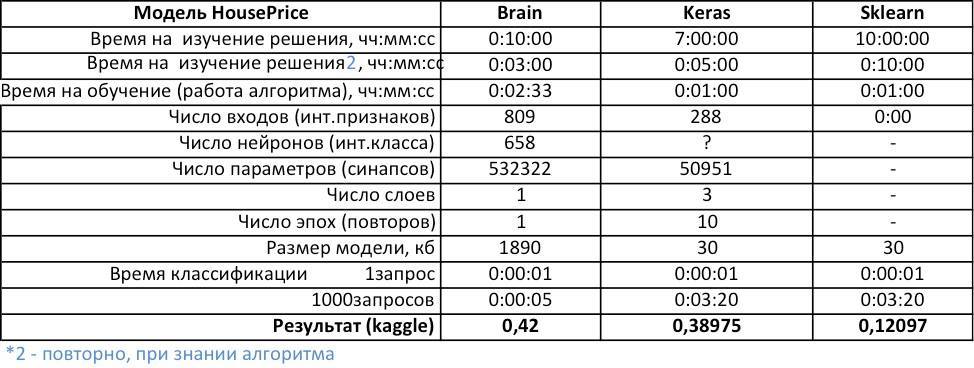
Другая российская разработка — платформа Brain2 компании “Когнитивные системы” — концентрируется на быстрой обработке bigdata в нейромодели знаний для систем ИИ. К примеру, нейромодель для оценки стоимости недвижимости (House Prices), обученная по 79 параметрам 1461 объектов недвижимости, способна предсказать стоимость объекта с незначительной ошибкой (RMSE=0,42), что равнозначно оценке опытного эксперта по недвижимости. При этом на обучение модели ушло всего 20 минут. Для сравнения, у опытного программиста-математика на решение подобной задачи с применением лучшей бесплатной библиотеки для машинного обучения Keras (TensorFlow) уйдет не менее 30 часов, а результат будет незначительно лучше (RMSE ? 0,32).
Почему автор сравнивает облачный сервис и фреймворк?
1) Сравнивайте тогда уж Brain2 с Google ML Cloud или MS Azure ML.
2) В рекламной презентации показывать результаты на MNIST'е в районе 81% точности и c местом во 2-й тысяче лидерборда
MNIST leaderboard Cognitive Systems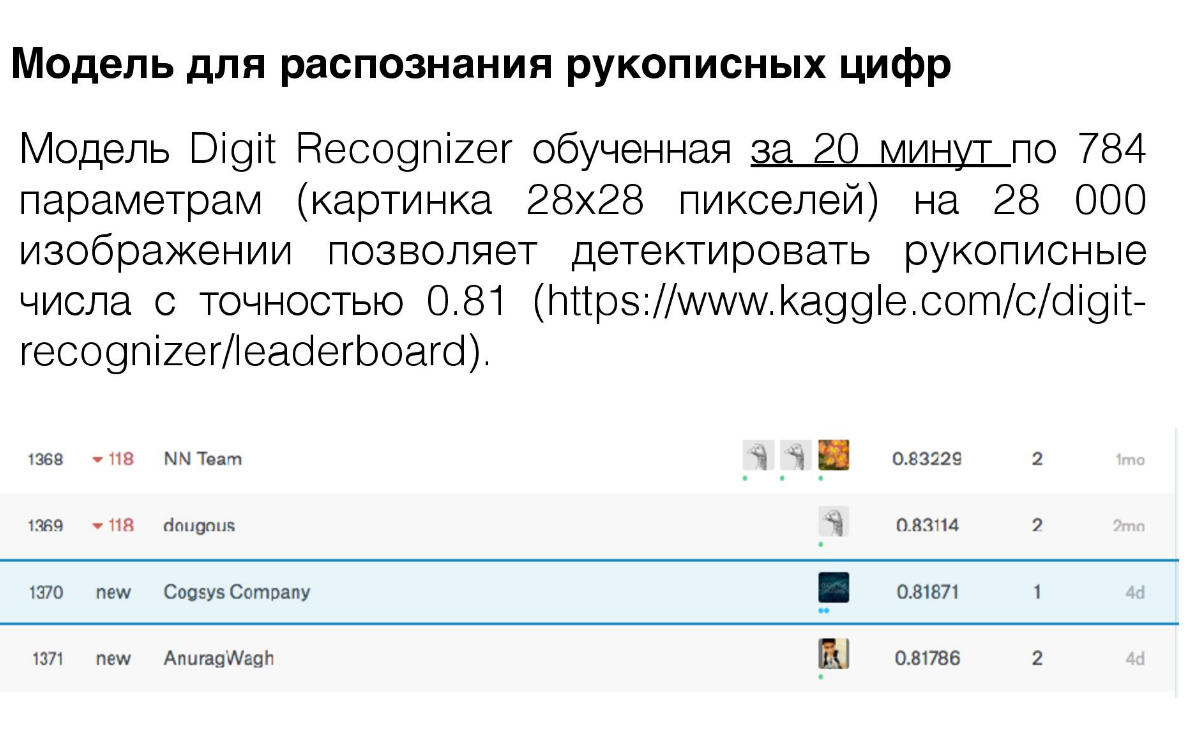

MagisterLudi
28.03.2017 19:39-1Я пренаправил вопросы разрабам, они ответили:
Сравнивать надо сравнимое. Для оценки надо взять как минимум 2 параметра – удобство и результат (пока отбросим стоимость).
Мы протестировали основные сервисы
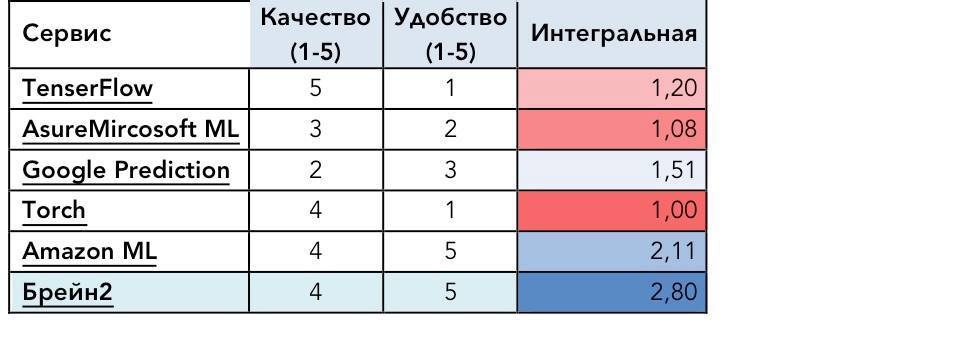
Google ML – это по сути TensorFlow с возможностью использовать ресурсы Google, отсюда и следует, что он для рядового пользователя также не удобен как TensorFlow, хотя конечно очень удобен для программиста. Поэтому, его оценку у него такая же как у TensorFlow.
Правильнее посмотреть другой сервис Google, который мы упомянули:
Так модель созданная в сервисе Google Prediction, для решения уже упомянутой задачи House Prices от Kaggle (сервиса для проведения конкурсов среди специалистов по машинному обучению) показывает RMSE = 7000, что в десятки тысяч раз хуже чем в Brain2.
Задачу MINST как представленная в виде демо в сервисе он решает хорошо – 0,92 точность, но вот другие, которые мы пытались решить увы не может.
2) В рекламной презентации показывать результаты на MNIST'е в районе 81% точности и c местом во 2-й тысяче лидерборда
Оценка должна быть справедливой, наш результат — за 2 минуты во 2-ой тысячи лидеров.
То есть мы не старались особо решать эту задачу «hello world», стать лидерами и тп.
Но мы специально потратили время, чтобы сравнения были объективными
В Google Prediction, со всем чтобы разобраться ушло 30минут, c MS Azure вечность, не хватило сил разбираться с весьма сложным интерфейсом. А вот Amazon порадовал, удобно и хороший результат.
Им не стыдно за свой сервис?
3) Что за бред про 30 часов работы опытного программиста-математика?
Другую задачку с House Prices, решили решать с использованием Кeras(theano) (for TensorFlow), на то чтобы разобраться с возможными решениями часов и выбрать лучшие по данным публикаций ушло примерно 13, подготовить данные (номализовать) обучить и протестировать ушло примерно 17 часов. А результат (0,32) полученный не многим лучше чем у Brain2 (0,42) где все создание моделей автоматизированно и заняло 30 минут!
Есть в лидерборде и варианты с результатом 0.0, но если почитать внимательнее будет понятно, что там была обнаружена уязвимость к выявлению, какие значения в test были неверно классифицированы/спрогнозированы.
Еще забавляет, что на их сайте, русская версия от английской отличается только языком меню, весь контент не зависимо от выбранного языка будет на русском языке.
Да, правда, но так ли это важно…
Отчего, Вы не обратили внимание, на то решение, над которым мы очень много работали Brain2Text. И то, что решения для синтеза предложения из слов пока ни у кого из лидеров рынка не представлено, не говоря об синтезе ответа?
P.S. Научная публикация по решению Brain2Text будет опубликована на arxiv.org месяца через 3BelBES
28.03.2017 20:57+6Спасибо за ответы:-)
Хотя объем бреда, по моему, только увеличился:
Сравнивать надо сравнимое. Для оценки надо взять как минимум 2 параметра – удобство и результат (пока отбросим стоимость).
Совершенно не понятно, какой смысл вкладывается в критерий "Результат"… вроде как на любом из представленых фреймворков можно любую модель реализовать...
Задачу MINST как представленная в виде демо в сервисе он решает хорошо – 0,92 точность, но вот другие, которые мы пытались решить увы не может.
92% — это очень плохо. Тупая сетка из пары сверточных и полносвязных слоев натренируется до 97%… а 92 — это даже хуже, чем описаный мной пару лет назад unsupervised метод, дайющий 96%.
Оценка должна быть справедливой, наш результат — за 2 минуты во 2-ой тысячи лидеров.
2 минуты тренировки? Лень проверять, но LeNet на моей не самой топовой GPU тренируется 1-2 минуты до тех 97%.
Другую задачку с House Prices, решили решать с использованием Кeras(theano) (for TensorFlow), на то чтобы разобраться с возможными решениями часов и выбрать лучшие по данным публикаций ушло примерно 13, подготовить данные (номализовать) обучить и протестировать ушло примерно 17 часов. А результат (0,32) полученный не многим лучше чем у Brain2 (0,42) где все создание моделей автоматизированно и заняло 30 минут!
Даже не знаю что сказать:) Может стоит сначала изучать инструмент, а потом им пользоваться...
Отчего, Вы не обратили внимание, на то решение, над которым мы очень много работали Brain2Text. И то, что решения для синтеза предложения из слов пока ни у кого из лидеров рынка не представлено, не говоря об синтезе ответа?
А Siri то как работает?) Ну и там всякие цепочки LSTM'ов и все такое проче...
Никого не хочу обидеть, или оскорбить, но чет какой-то фэйспалм это всё :(
BelBES
28.03.2017 23:33+5Чтобы не быть голословным, забенчмаркал MNIST.
Вот такая сетка:
def LeNet5(x): net = tf.reshape(x, [-1, 28, 28, 1]) with tf.variable_scope("conv1"): net = layers.conv2d_relu(net, [5, 5, 1, 20], [20]) net = layers.maxpool2d(net) net = tf.contrib.layers.batch_norm(net) with tf.variable_scope("conv2"): net = layers.conv2d_relu(net, [5, 5, 20, 50], [50]) net = layers.maxpool2d(net) net = tf.contrib.layers.batch_norm(net) fc_size = int(net.get_shape()[1] * net.get_shape()[2] * net.get_shape()[3]) net = tf.reshape(net, [-1, fc_size]) with tf.variable_scope("fc1"): net = layers.inner_product(net, [fc_size, 500]) net = tf.contrib.layers.batch_norm(net) net = tf.nn.relu(net) with tf.variable_scope("fc2"): net = layers.inner_product(net, [500, 10]) return net
За 500 итераций сходится к 99% точности. Время тренировки: 50 секунд на GTX980Ti...
BelBES
28.03.2017 23:37+2А при размере батча в 2048, за 20 секунд сошлось к тем-же цифрам...
MagisterLudi
29.03.2017 16:48-1Слово разработчикам:
«Сергей, спасибо, что пытаетесь вести конструктивный диалог. Дабы он был действительно конструктивным (и полезным читателям), необходимо, чтобы мы сравнивали решения в едином пространстве время-результат. Для этого давайте просто составим своеобразных акт сверки.

Время изучения вопроса, часов – время необходимое, чтобы посмотреть условия задачи, найти и реализовать решение.
С использованием Brain2, для типовых моделей – это значит — скачать данные и загрузить данные в систему Brain2, пометить что класс, а что признак, нажать кнопку «построить модель». Сервис Brain2 ставит задачу – дать возможность создавать нейромодели не программируя, в том числе, человеком, который вообще может не знать, что такое нейросети. Именно для этих целей мы протестировали работоспособность системы на MNIST и HousePrice. Мы не тратили вообще никакого времени, на предобработку и поиск «решения», лучшее решение, подбирала сама система Brain2. При этом мы не сомневаемся, в том, что потратив много больше времени чем 10 минут, могли бы достичь лучших результатов.
К примеру, сколько времени Вам понадобилось, чтобы отладить работу ESOINN для задачи MNIST (кстати интересный алгоритм). А много ли специалистов, кто может разобраться с подобным решением, а сколько стоимость часа специалиста такого уровня…
* Задача решаемая в Brain2Text. На основе естественного текста обучить модель(и) и создать алгоритм с их использованием для поиска набора ЛЕКСЕМ (унифицированных форм слов имеющих план содержания), из которых составить ответ на поставленный вопрос на естественном языке. Т.е. необходимо сначала понять какие слова относятся к ответу, а затем из них синтезировать предложение. Текст для обучения http://sb.brain2.online/files/cache/text_half.txt.
** У нас разработка Brain2Text потребовала 3 месяца для создания и отладки алгоритма и пяти многослойных моделей для возможности его работы: 2 – обработки вопроса, 1 – выбор слов, 1 – расстановки слов влево и вправо, 1 – правильного склонения слова слева и справа.
*** Точность определена, как число корректных предложении полученных на вопрос составленный из слов текста. Список 30 экспертных и 6000 технических вопросов для тестирования готовы предоставить.
Также, интересно получить ссылки на работы, где с применением LSTM составляют предложения из лемм (унифицированных слов) на русском языке. Если есть, то реальные примеры посмотреть как работает.
По поводу Siri, все же нам кажется она зачитывает найденные ответы из интернета, а не составляет их из «мешка слов». А ответы не из интернета выглядят как заготовленные формы с вариациями. В модели Brain2Text нет самого текста или шаблонов ответа, только связи слов!
P.S. Спасибо за найденные опечатки и сотрудничество.
supersonic_snail
29.03.2017 18:24+1Таблицы вы показываете очень странные — во-первых, почему это вы ставите конкуренту результат 0.96, если он 0.99? Я только что перепроверил (ну мало ли что) — таки 0.99.
Во-вторых, время на изучение не имеет значения вообще от слова совсем. ML на данный момент не черный ящик, а уж тем более нейронные сети, так что надо учить хотя бы основы. А то, что на какой-то задаче можно за вменяемое время получить результат автоматически, означает, что задача настолько простая, что она даже не стоит рассмотрения. Как конкретный пример — попробуйте хотя бы cifar10, и покажите, что выйдет. Я сомневаюсь, что вы вообще получите там вменяемый результат, разве что у вас есть заточенные под задачу предобученные алгоритмы.
В-третьих, в самой первой таблице у Amazon ML оценки 4 и 5, а интегральная 2.1, а у брейн2 4 и 5 и интегральная 2.8. Как так? Разве что вы не показали какой-то столбец, но тогда какой-вообще смысл так что-то сравнивать?
BelBES
29.03.2017 21:50+11) Были уже всякие RapidMiner'ы и прочие тулы для автоматического построения моделей… у всех есть один главный недостаток: когда мы получили какую-то модель, а результат не можем объяснить, то смысла от этой модели никакого:
- Вот получили мы 99% точности… а это точно хорошо, или это жуткий оверфит + плохая тестовая база? А если оверфит, то почему? Недостаточно данных для тренировки, плохие фичи, или слишком большая модель, которая умудрилась запомнить все образы?
- А если ничего путного не натренировалось, то почему? Плохая тренировочная база, или может быть мы пытаемся линейно разделить данные, которые так просто не разделишь… а может быть у нас половина фич — это шум, который все портит? И т.д. и т.п.
И вот тут мы приходим к тому, что человек, который как умная обезьянка тычет по кнопкам, не понимая происходящего, может получить какой-то результат, но что с ним делать дальше — он не знает. Т.е. результат вроде бы есть, но на самом деле его нет.
Ну а в случае этого Barin2, даже результат странный — 81% на MNIST'е говорит о том, что даже на простейших модельных задачах автоматически как-то все не очень круто работает. Как правильно пишут выше: а давайте возьмем cifar10 и попробуем на нем запустить ту-же задачу… скорей всего там все рассыпется.
А если инструмент позиционируется как продвинутый калькулятор, то его корректней сравнивать с Excel, а не tensorflow или torch.
2) Обработкой текста на практике я не занимался почти, т.ч. тут могу ошибаться и, возможно, решение Brain2Text — это что-то прорывное, хотя результаты работы не впечатляют от слова совсем. Но всякие чат-боты — это вроде-бы довольно горячая тема последних пары лет и их лепят все кому не лень. Гугл выдает десятки репозиториев с различными решениями на рекурентных сетях.
BelBES
28.03.2017 22:45+5Кстати, в табличках не правильно указаны названия TensorFlow и Azure… там разработчики — это точно не пара студентов первого курса?)
Просто как-то нескучными обоями повеяло...

Bas1l
28.03.2017 17:23Меня смущает, что автор ничего не пишет про исследования. Все коммерческие проекты—это же вершина айсберга. И даже в исследовательском отделе гугла и IBM многие ключевые люди из академии. Из университета Торонто, к примеру (достаточно посмотреть на то, откуда они публиковали статьи до того, как стали работать в гугле).

NoRegrets
28.03.2017 18:07+3Для развития нужны: изобретение/исследование, инвестиции, рынок сбыта.
И так сложилось, что если первое и может появится в России, то со вторым и третьим здесь все гораздо сложнее.BelBES
28.03.2017 21:10А что не так с Россией?
Есть, наприер, success story у авторов Prism: ребята вовремя уловили тренд, вложили денег в high load сервис, способный deep learning тянуть с минимальной задержкой и стали лидерами в области стилизации фотографий.
Ну или findface — крутые ребята, которые сначала на MegaFace победили, и продвигают свою технологию распознавания лиц.
Туда же и Yandex можно отнести, вот уж кто серьезно рисерчем занимается в России.
Ну и по мелочи есть еще куча компаний, кто по большей части на аутсорс делают решения на основе машинного обучения и прочего data science.
Имхо, были бы знания и идеи, а остальные вопросы в этой области решаемы, даже в России.
nidheg666
31.03.2017 14:58любой бизнес в россии является высоко — рисковым, за счёт коррупционной составляющей и нестабильной экономической ситуации. а высокорисковый бизнес требует больших расходов, менее привлекателен и следовательно реже инвестируется.
alexhott
28.03.2017 20:28-1одно но, пока все что называют ИИ это просто программа работающая по заданному алгоритму, способная по этому алгоритму анализировать огромное количество данных.
А саморазвития пока нету как такового.
А шансы у нас самые большие, только русский программер насинячившись до беспамятства может создать реальный ИИ.
st174
29.03.2017 15:23… вдруг представил, что происходит война человека и ИИ. и внезапно ИИ выбрал в качестве оружия юмор: сделал что-то очень смешное, на что ни один человек не смог адекватно отреагировать… невероятно?
Igor_34_rus
03.04.2017 14:34В стратегии
В экономиках Казахстана и Турции преобладают позитивные тенденции. ВВП Казахстана в 2012
году увеличился на 5,1%, в ближайшие годы ожидается сохранение достигнутых темпов роста.
Замедление ВВП Турции в 2012 году до 2,2%, вероятнее всего, является временным, в
последующие годы можно прогнозировать повышение темпов роста до 4%.
задаю вопросВВП Казахстана
темпы ВВП Казахстана
и прочих формулировках со словом казахстан, ответ всегда один:
есть замедление ввп турции в 2012 году до 2.2 проц вероятнее всего
Есть мнение, что ИИ хромает :)
Обычный парсер лучше отработает
QDeathNick
Жду, когда ИИ в президенты выдвинут.
fruit_cake
а потом при импичменте он будет расстреливать парламент из роботизированных танков
wOvAN
Надеюсь дадут АА выдвинуться в 2018-м, вместо ВВ
jex
Демо-версия — вполне сносная. Да и оттестировали уже хорошенько со всех сторон. Пора бы в продакшн.
Structure
Прочитал предвыборную программу АА и забыл про него.
wOvAN
Ну, что сказать, желаю вам провести ещё 17 лет под управлением ВВ
Structure
Выбирать дурачка, только потому что не устраивает ВВП? Как это умно.
Из его программы:
Раздадим всем денег и все станут богатыми! Гениальное решение. Про рост цен на жилье из-за роста спроса он и не знает.
Его программа состоит из бреда, уже сделанного, находящегося в процессе реформирования и т.д.
jex
Жётский оффтоп пошел.
Рост цен на жильё приведёт к появлению новых строительных компаний, что в итоге приведет к падению цен. По сути субсидирование ипотеки — это субсидирование строительных компаний. Никто не собирается раздать всем денег, чтобы все были богатыми. Но экономику подтолкнуть надо.
В тоже время при ВВ такое не будет работать: велики риски потерять бизнес, большие издержки на корупционной состовляющей.
SerhiyKhomin
Менталитет то передаться от создателей
Structure
А что такого Президент делает, что нужно заменять на слабый ИИ?
Тут скорее нужно почти все отдавать в руки частного бизнеса и контролировать с помощью суперкомпьютеров.
Прозрачность системы + обработка жалоб с помощью ИИ — вот что нужно.