
Kubernetes требует, чтобы каждый контейнер в кластере имел уникальный, маршрутизируемый IP. Kubernetes не назначает IP-адреса сам, оставляя эту задачу сторонним решениям.
Цель этого исследования — найти решение с наименьшими задержками, наибольшей пропускной способностью и самой небольшой стоимостью настройки. Поскольку наша нагрузка зависит от задержек, мы измеряем задержки высоких перцентилей при достаточно активной сетевой нагрузке. В частности, мы сфокусировались на производительности в районе 30-50 процентов от максимальной нагрузки, поскольку это лучше всего отражает типовые ситуации для неперегруженных систем.
Варианты
Docker с --net=host
Наша образцовая инсталляция. Все другие варианты сравнивались с ней.
Опция
--net=host означает, что контейнеры наследуют IP-адреса своих хост-машин, т.е. сетевой контейнеризации нет.Отсутствие сетевой контейнеризации априори обеспечивает лучшую производительность, чем наличие любой реализации — по этой причине мы использовали данную инсталляцию как эталон.
Flannel
Flannel — решение виртуальной сети, поддержкой которого занимается проект CoreOS. Хорошо проверенное и готовое к production, поэтому стоимость внедрения минимальна.
Когда вы добавляете машину с flannel в кластер, flannel делает три вещи:
- Присваивает новой машине подсеть с помощью etcd.
- Создаёт виртуальный интерфейс моста на машине (
docker0 bridge). - Настраивает бэкенд пересылки пакетов:
aws-vpc— регистрирует подсеть машины в таблице экземпляров Amazon AWS. Количество записей в этой таблице ограничено 50, т.е. вы не можете иметь более 50 машин в кластере, если используете flannel сaws-vpc. Вдобавок, этот бэкенд работает только с Amazon AWS;host-gw— создаёт IP-маршруты до подсетей через IP-адреса удалённой машины. Требует прямой L2-связности между хостами, на которых запущен flannel;vxlan— создаёт виртуальный интерфейс VXLAN.
Поскольку flannel использует интерфейс моста для пересылки пакетов, каждый пакет проходит через два сетевых стека, когда отправляется из одного контейнера в другой.
IPvlan
IPvlan — драйвер в ядре Linux, позволяющий создавать виртуальные интерфейсы с уникальными IP-адресами без необходимости в использовании интерфейса моста.
Для назначения IP-адреса контейнеру с помощью IPvlan требуется:
- Создать контейнер вообще без сетевого интерфейса.
- Создать интерфейс ipvlan в стандартном сетевом пространстве имён.
- Переместить интерфейс в сетевое пространство имён контейнера.
IPvlan — относительно новое решение, поэтому пока нет готовых инструментов для автоматизации этого процесса. Таким образом, деплой IPvlan на множестве машин и контейнеров усложняется, то есть стоимость внедрения высока. Однако IPvlan не требует интерфейса моста и пересылает пакеты напрямую из NIC в виртуальный интерфейс, поэтому мы ожидали лучшей производительности, чем у flannel.
Сценарий тестирования нагрузки
Для каждого варианта мы проделали следующие шаги:
- Настроили сеть на двух физических машинах.
- Запустили tcpkali в контейнере на одной машине, настроив её на отправку запросов с постоянной скоростью.
- Запустили nginx в контейнере на другой машине, настроив его на ответ с файлом фиксированного размера.
- Сняли системные метрики и результаты работы tcpkali.
Мы запускали этот тест с разными количеством запросов: от 50 000 до 450 000 запросов в секунду (RPS).
Для каждого запроса nginx отвечал статическим файлом фиксированного размера: 350 байт (содержимое в 100 байт и заголовки в 250 байт) или 4 килобайта.
Результаты
- IPvlan продемонстрировал наименьшую задержку и наилучшую максимальную пропускную способность. Flannel с
host-gwиaws-vpcследует за ним с близкими показателями, при этомhost-gwпроявил себя лучше под максимальной нагрузкой. - Flannel с
vxlanпоказал худшие результаты во всех тестах. Однако мы подозреваем, что его исключительно плохой перцентиль 99,999 вызван багом. - Результаты для 4-килобайтного ответа похожи на случай с 350 байтами, но есть два заметных отличия:
- максимальный показатель RPS значительно ниже, поскольку для 4-килобайтных ответов потребовалось всего ?270 тысяч RPS для полной загрузки 10-гигабитной NIC;
- IPvlan гораздо ближе к
--net=hostпри приближении к лимиту пропускной способности.
Наш текущий выбор — flannel с
host-gw. У него мало зависимостей (в частности, не требуется AWS или новая версия ядра Linux), он прост в установке по сравнению с IPvlan и предлагает достаточную производительностью. IPvlan — наш запасной вариант. Если в какой-то момент flannel получит поддержку IPvlan, мы перейдём на такой вариант.Несмотря на то, что производительность
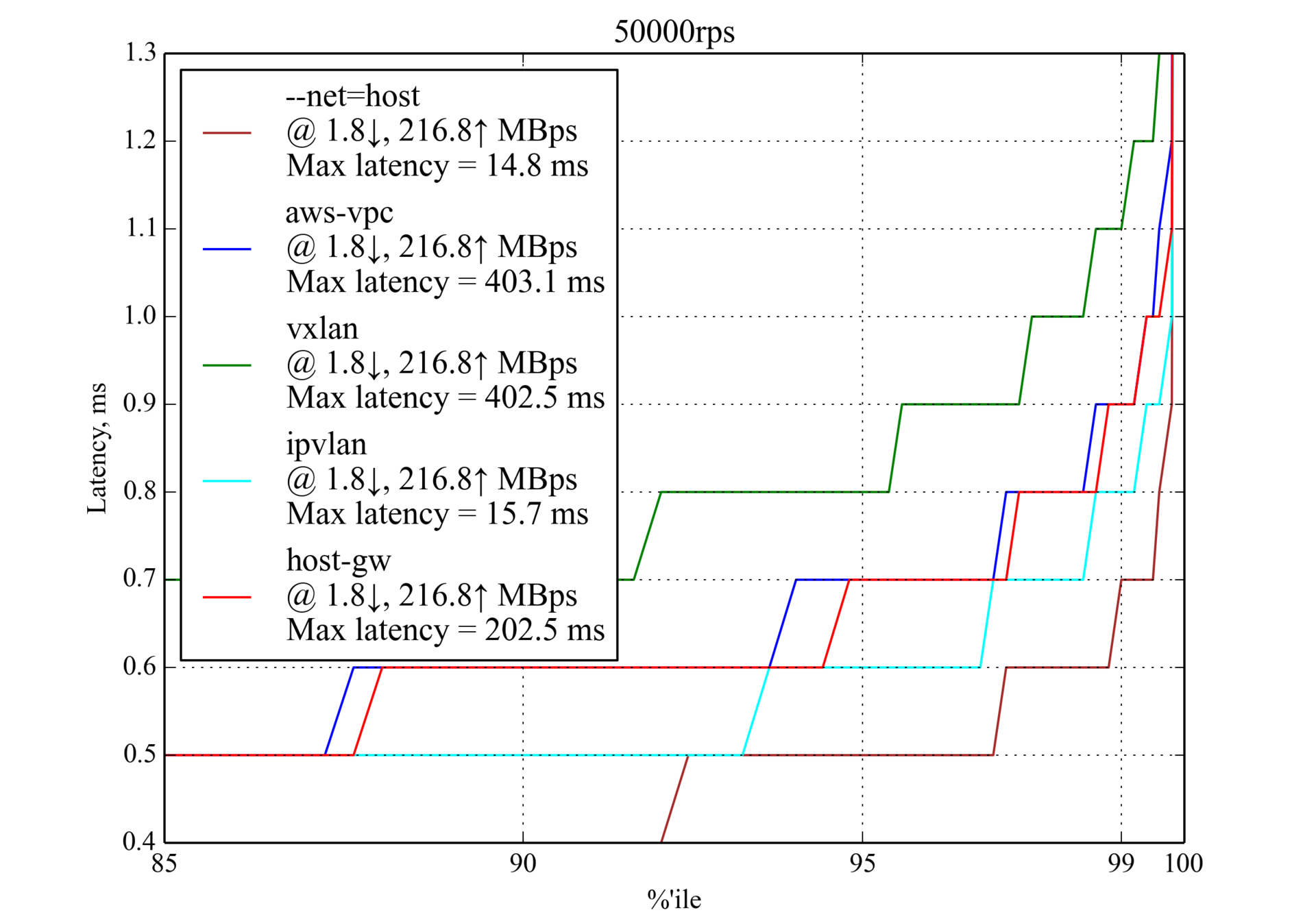
aws-vpc оказалось немного лучше host-gw, ограничение в 50 машин и факт жёсткой привязки к Amazon AWS стали для нас решающими факторами.50 000 RPS, 350 байт

На 50 000 запросах в секунду все кандидаты продемонстрировали приемлемую производительность. Уже можно заметить основной тренд: IPvlan показывает лучшие результаты,
host-gw и aws-vpc следуют за ним, а vxlan — худший.150 000 RPS, 350 байт

Перцентили задержки на 150 000 RPS (?30 % от максимального RPS), мс
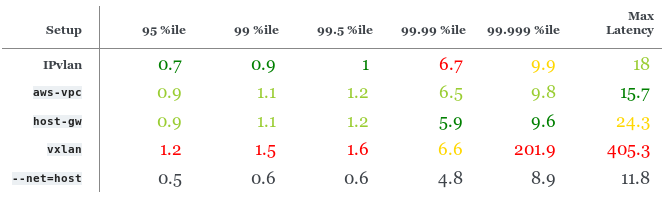
IPvlan немного лучше, чем
host-gw и aws-vpc, однако у него худший перцентиль 99,99. У host-gw немного лучшая производительность, чем у aws-vpc.250 000 RPS, 350 байт
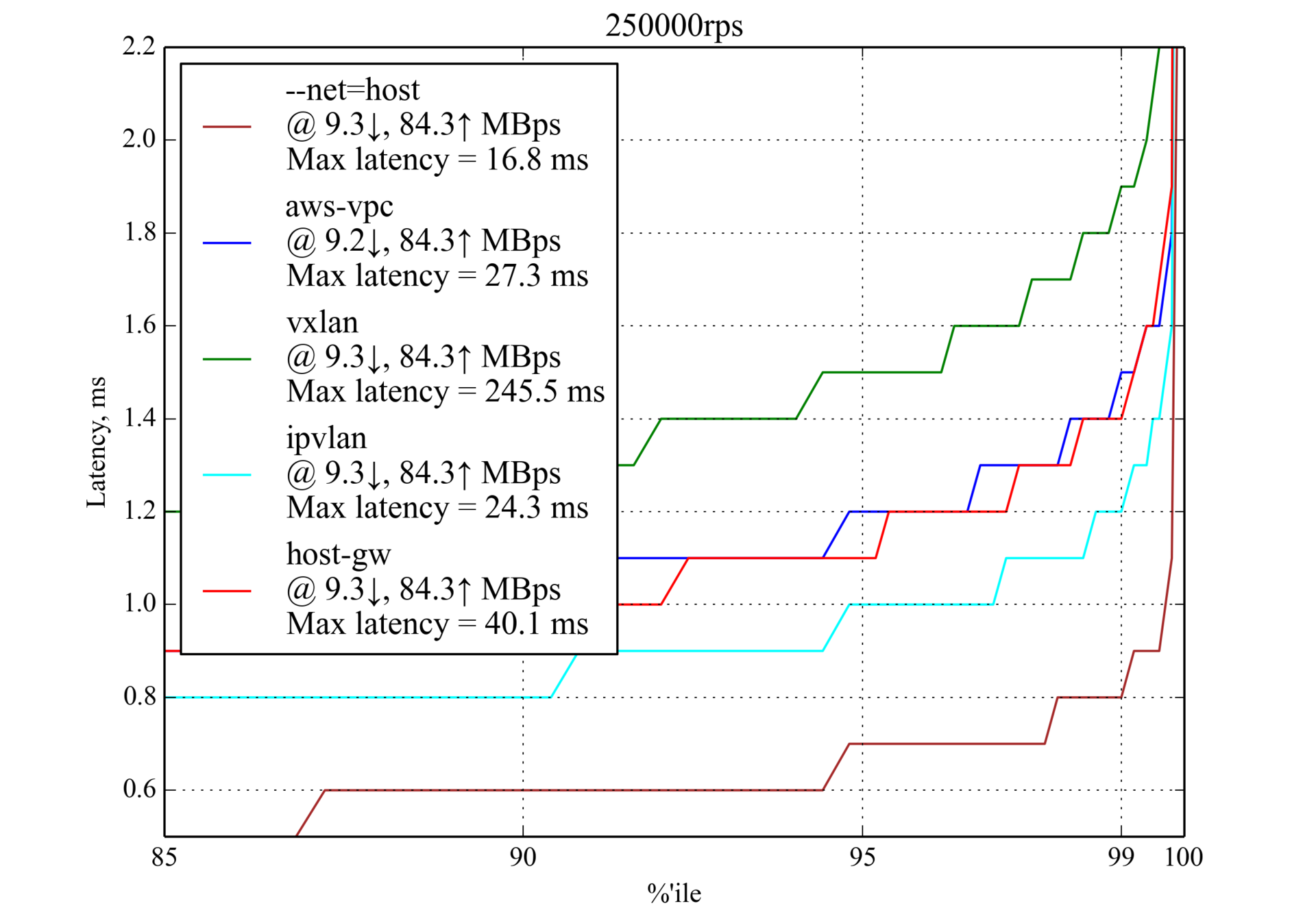
Предполагается, что такая нагрузка является обычной для production, поэтому результаты в особенности важны.
Перцентили задержки на 250 000 RPS (?50 % от максимального RPS), мс
IPvlan снова показывает лучшую производительность, но у
aws-vpc лучший результат в перцентилях 99,99 и 99,999. host-gw превосходит aws-vpc в перцентилях 95 и 99.350 000 RPS, 350 байт

В большинстве случаев задержка близка к результатам для 250 000 RPS (350 байт), однако она стремительно растёт после перцентиля 99,5, что означает приближение к максимальному RPS.
450 000 RPS, 350 байт


Интересно, что
host-gw показывает гораздо лучшую производительность, чем aws-vpc: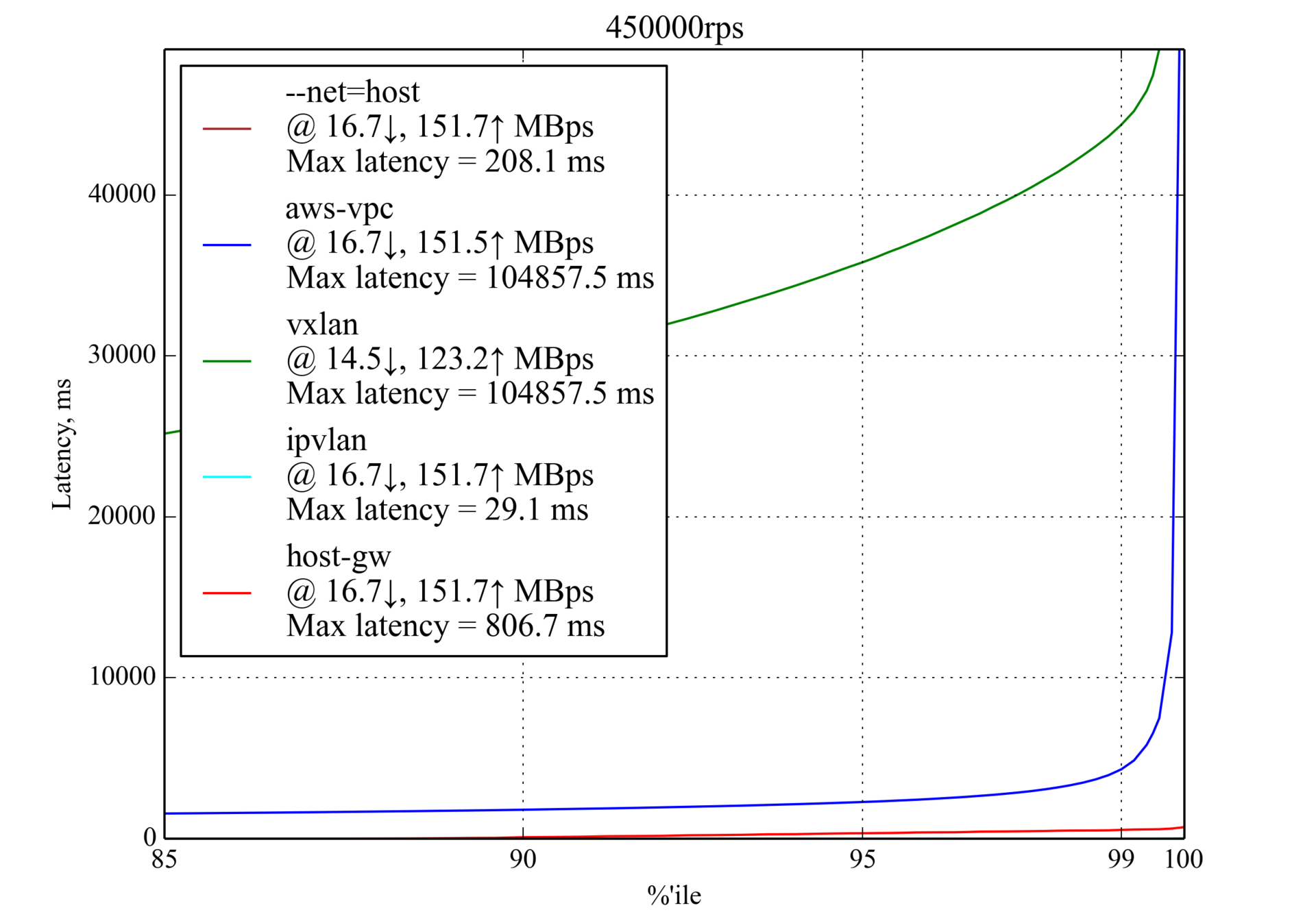
500 000 RPS, 350 байт
При нагрузке в 500 000 RPS только IPvlan всё ещё работает и даже превосходит
--net=host, однако задержка столь высока, что мы не можем назвать её допустимой для приложений, которые чувствительны к задержкам.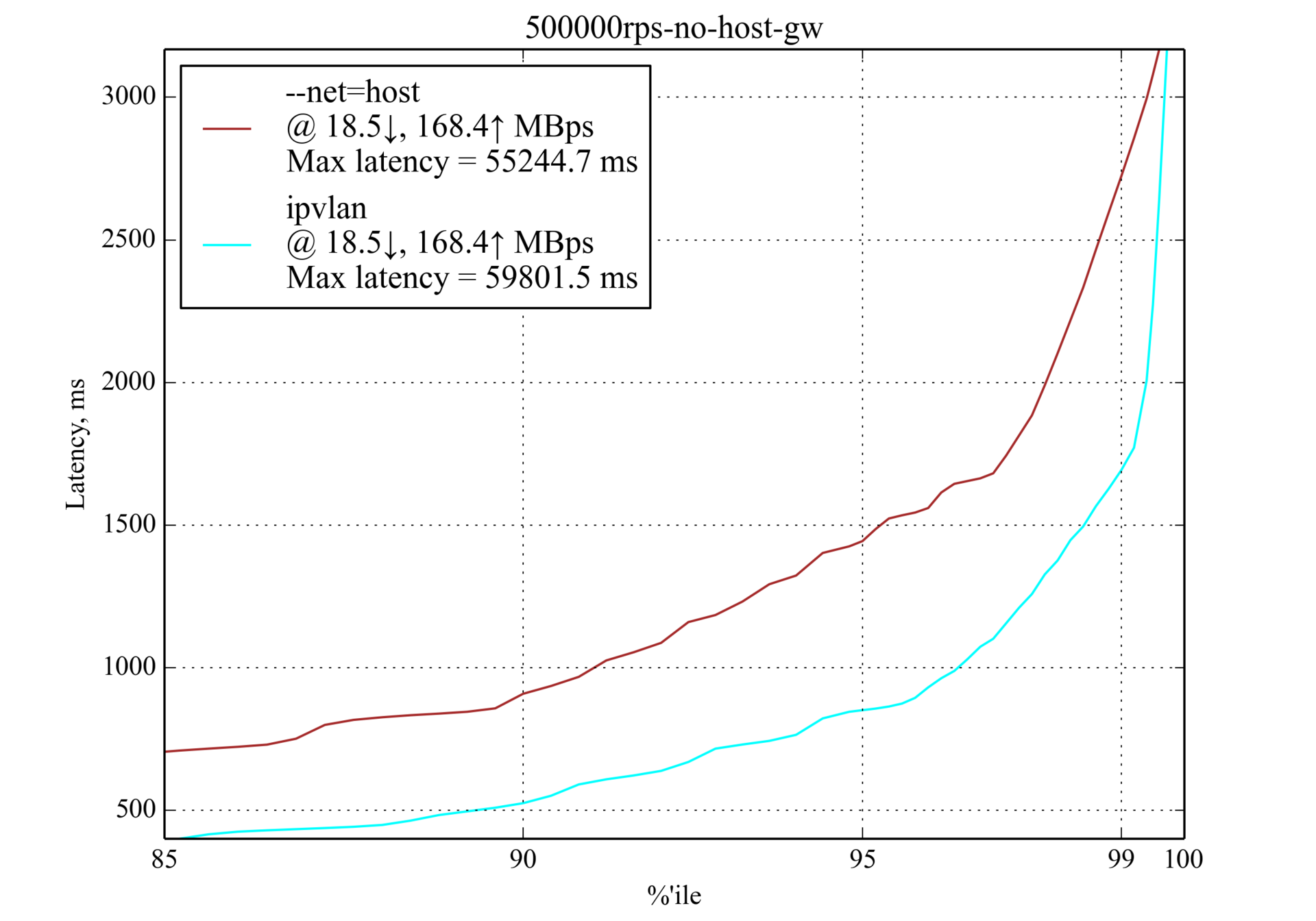
50 000 RPS, 4 килобайта
Большие результаты запросов (4 килобайта против тестируемых ранее 350 байт) приводят к большей сетевой нагрузке, однако список лидеров практически не меняется:
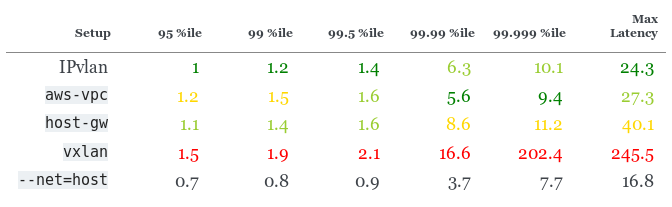
Перцентили задержки на 50 000 RPS (?20 % от максимального RPS), мс

150 000 RPS, 4 килобайта

У
host-gw на удивление плохой перцентиль 99,999, однако он всё ещё показывает хорошие результаты для меньших перцентилей.Перцентили задержки на 150 000 RPS (?60 % от максимального RPS), мс

250 000 RPS, 4 килобайта
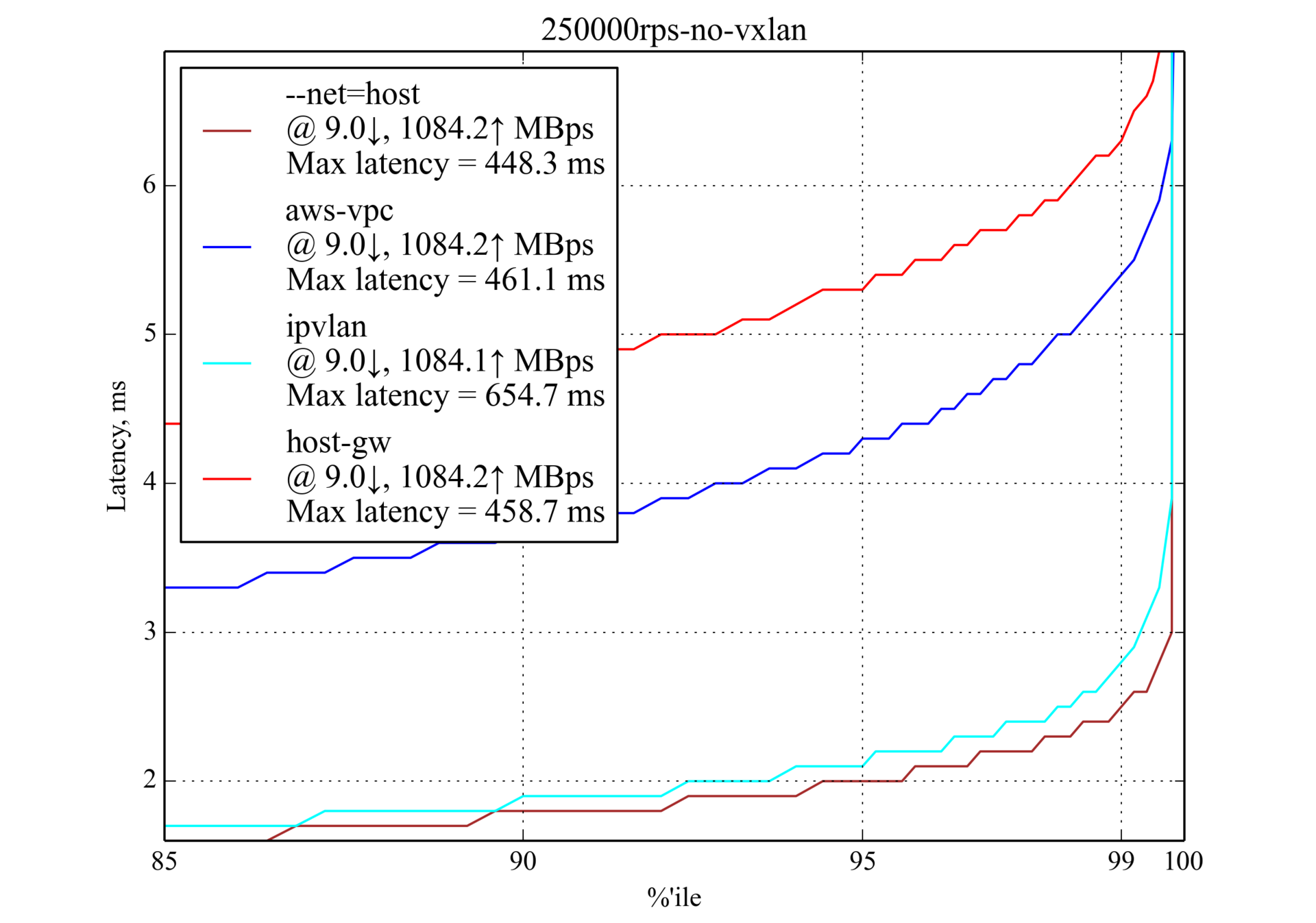
Это максимальный RPS с большим ответом (4 Кб).
aws-vpc значительно превосходит host-gw в отличие от случая с небольшим ответом (350 байт).Vxlan был снова исключён из графика.Окружение для тестирования
Основы
Для лучшего понимания этой статьи и воспроизведения нашего тестового окружения необходимо быть знакомым с основами высокой производительности.
В этих статьях содержится полезная информация по этой теме:
- How to receive a million packets per second от CloudFlare;
- How to achieve low latency with 10Gbps Ethernet от CloudFlare;
- Scaling in the Linux Networking Stack из документации по ядру Linux.
Машины
- Мы использовали два экземпляра c4.8xlarge в Amazon AWS EC2 с CentOS 7.
- На обоих машинах включена enhanced networking.
- Каждая машина — NUMA с 2 процессорами, у каждого процессора по 9 ядер, у каждого ядра по 2 потока (hyperthreads), что обеспечивает эффективный запуск 36 потоков на каждой машине.
- У каждой машины по сетевой карте 10Gbps (NIC) и 60 Гб оперативной памяти.
- Для поддержки enhanced networking и IPvlan мы установили ядро Linux 4.3.0 с драйвером Intel ixgbevf.
Конфигурация
Современные NIC используют Receive Side Scaling (RSS) через многочисленные линии запроса прерывания (IRQ). EC2 предлагает только две такие линии в виртуализированном окружении, поэтому мы протестировали несколько конфигураций с RSS и Receive Packet Steering (RPS) и пришли к следующим настройкам, отчасти рекомендованным документацией по ядру Linux:
- IRQ. Первое ядро каждого из двух узлов NUMA настроено на получение прерываний из NIC. Чтобы сопоставить CPU с узлом NUMA, используется
lscpu:
$ lscpu | grep NUMA NUMA node(s): 2 NUMA node0 CPU(s): 0-8,18-26 NUMA node1 CPU(s): 9-17,27-35
Эта настройка выполняется записью0и9в/proc/irq/<num>/smp_affinity_list, где номера IRQ получаются черезgrep eth0 /proc/interrupts:
$ echo 0 > /proc/irq/265/smp_affinity_list $ echo 9 > /proc/irq/266/smp_affinity_list
- Receive Packet Steering (RPS). Было протестировано несколько комбинаций для RPS. Чтобы уменьшить задержку, мы разгрузили процессоры от обработки IRQ, используя только CPU под номерами 1–8 и 10–17. В отличие от
smp_affinityв IRQ, у sysfs-файлаrps_cpusнет постфикса_list, поэтому для перечисления CPU, которым RPS может направлять трафик, используются битовые маски (подробнее см. Linux kernel documentation: RPS Configuration):
$ echo "00000000,0003fdfe" > /sys/class/net/eth0/queues/rx-0/rps_cpus $ echo "00000000,0003fdfe" > /sys/class/net/eth0/queues/rx-1/rps_cpus
- Transmit Packet Steering (XPS). Все процессоры NUMA 0 (включая HyperThreading, т.е. CPU под номерами 0—8, 18—26) были настроены на tx-0, а процессоры NUMA 1 (9—17, 27—37) — на tx-1 (подробнее см. Linux kernel documentation: XPS Configuration):
$ echo "00000000,07fc01ff" > /sys/class/net/eth0/queues/tx-0/xps_cpus $ echo "0000000f,f803fe00" > /sys/class/net/eth0/queues/tx-1/xps_cpus
- Receive Flow Steering (RFS). Мы планировали использовать 60 тысяч постоянных подключений, а официальная документация рекомендует округлить это количество до ближайшей степени двойки:
$ echo 65536 > /proc/sys/net/core/rps_sock_flow_entries $ echo 32768 > /sys/class/net/eth0/queues/rx-0/rps_flow_cnt $ echo 32768 > /sys/class/net/eth0/queues/rx-1/rps_flow_cnt
- Nginx. Nginx использовал 18 рабочих процессов, у каждого — свой CPU (0—17). Это настраивается с помощью
worker_cpu_affinity:
workers 18; worker_cpu_affinity 1 10 100 1000 10000 ...;
- Tcpkali. У Tcpkali нет встроенной поддержки привязки к конкретным CPU. Чтобы использовать RFS, мы запускали tcpkali в
tasksetи настроили планировщик для редкого переназначения потоков:
$ echo 10000000 > /proc/sys/kernel/sched_migration_cost_ns $ taskset -ac 0-17 tcpkali --threads 18 ...
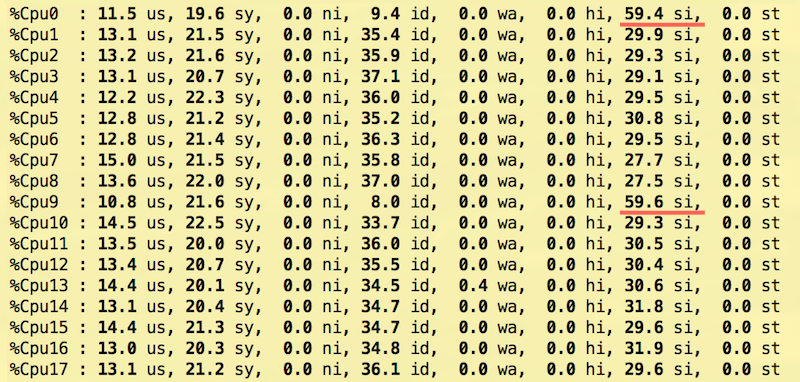
Такая конфигурация позволила равномерно распределить нагрузку на прерывания по ядрам процессора и добиться лучшей пропускной способности с сохранением той же задержки, что и в других опробованных конфигурациях.
Ядра 0 и 9 обслуживают только прерывания сетевых карт (NIC) и не работают с пакетами, но они остаются самыми занятыми:
Также был использовал tuned от Red Hat с включённым профилем network-latency.
Для минимизации влияния nf_conntrack были добавлены правила NOTRACK.
Конфигурация sysctl была настроена на поддержку большого количества TCP-подключений:
fs.file-max = 1024000
net.ipv4.ip_local_port_range = "2000 65535"
net.ipv4.tcp_max_tw_buckets = 2000000
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_fin_timeout = 10
net.ipv4.tcp_slow_start_after_idle = 0
net.ipv4.tcp_low_latency = 1От переводчика: Большое спасибо коллегам из Machine Zone, Inc за проведённое тестирование! Оно помогло нам, поэтому мы захотели поделиться им и с другими.
P.S. Возможно, вас также заинтересует наша статья «Container Networking Interface (CNI) — сетевой интерфейс и стандарт для Linux-контейнеров».
Комментарии (5)

Deroy
06.07.2017 12:39+3а как же другие решения на базе CNI, помимо flannel? например weave net или calico? и ещё пара других что упомянуты на просторах мануалов по настройке сети для kubernetes? их совсем не рассматривали или есть какая то объективная причина почему они были исключены?
многие из них утверждают что они «быстрее» чем flannel, вот и хотелось бы узнать насколько это правда…
список тут https://kubernetes.io/docs/concepts/cluster-administration/networking/
shurup
06.07.2017 13:36+1Многое из списка мы сами упоминали в статье про CNI. Но этот материал — перевод: тестировали не мы сами, а Machine Zone, причём уже больше года назад. Как известно, в мире Kubernetes всё очень динамично… Нам на сейчас этих данных хватило. Благо, авторы достаточно подробно описали своё окружение для тестирования, так что при желании можно воспроизвести с другими решениями: нужно только это самое желание (и время, конечно).

boombick
06.07.2017 15:54flannel плох тем, что он нестабильный. После падения он переподнимается и разадет другие айпишники, соответственно теряем связность Pod-to-Pod. Мы сейчас используем для нетворкинга внутри кубера свое решение на BGP
neumeika
06.07.2017 22:44а можно узнать, чем создаёте интерфейсы? macvlan/ipvlan? DHCP докерный, али один на все вланы?
У вас один влан на все хосты? Хотя это маловероятно, уж больно большой броадкаст тогда нужен.
o_serega
Наконец-то хорошая статья!