Что значит имя? Роза пахнет розой,
Хоть розой назови ее, хоть нет.
• Шекспир "Ромео и Джульетта" (пер. Пастернака)

Данная статья не может служить поводом для выражения нетолерантности или дискриминации по какому-либо признаку.
В этой статье я расскажу о том, что несмотря на то, каким бы странным это не казалось для образованного человека, вероятность быть одинокой/одиноким зависит от имени. То есть, по сути, мы поговорим про любовь и отношения.
Это примерно все равно, что сказать: вероятность быть сбитым машиной, если тебя зовут Сережа, выше, чем если бы тебя звали Костя! Звучит довольно дико, не правда ли? Ну, как минимум, ненаучно. Однако социальные сети сделали возможным сравнительно просто проверить приведенное выше утверждение.
Подробно мы рассмотрим только девушек, а про мужчин поговорим в самом конце. Более того, я не ставлю своей целью установить причину происходящего или даже выдвинуть какую-то сколько угодно серьезную гипотезу, а хочу лишь рассказать о своих наблюдениях и фактах, которые можно измерить.
История
Все началось с того, что я поставил себе Тиндер и пролистал его до конца в солидном радиусе. То есть просмотрел довольно много профилей девушек. Через какое-то время я заметил, что среди всех имен девушек, некоторые встречаются несколько чаще, чем другие, но примерно в одинаковом объеме. Конкретно речь об именах Даша и Ксюша, причем я ни разу на тот момент не сделал ни один свайп вправо (то есть лайк) для девушек с таким именем. Я еще мог как-то себе объяснить, почему обратил внимание на девушек с именем Ксюша (допустим, припоминая свой собственный опыт), но про девушек с именем Даша я не знал практически ничего. Я также не очень много знал про распределение имен, но интуиция мне подсказывала, что что-то тут не так. Сама идея, как уже заметил, показалась мне крайне странной и ненаучной, но я ее запомнил. Когда на следующий раз я заметил аналогичный результат, то уже не выдержал. Подумал, что либо Тиндер знает что-то, чего не знаю я или мое предположение не так абсурдно и решил обратиться к статистике. Доступа к данным Тиндера у меня нет, и я решил заглянуть в те ресурсы, который мне доступны — а это Одноклассники (где я, собственно, и работаю) и открытые данные ВКонтакте.
Для начала нужна была хотя бы какая-то гипотеза, объясняющая неравномерность распределения имен в Тиндере (с поправкой на естественную частотность). Я предположил, что по каким-то причинам Даши и Ксюши более одиноки, чем другие девушки. Это звучит совершенно невероятно, и адекватный человек ожидает, что вопрос одиночества, как и любой подобный показатель, совершенно одинаково распределен среди людей независимо от их имени, знака зодиака и другой подобной ерунды. Для меня сама мысль о том, что может быть иначе, все еще казалась крамольной, сродни гомеопатии или астрологии.
В Одноклассниках статус отношений можно определить по типу связи в графе, и то, что меня интересовало — это супружеские связи и любовные отношения. Надо сказать, что не очень много людей явным образом отмечают соответствующее отношение. Однако даже первичный осмотр показал, что Даши действительно несколько выбиваются из обычной статистики, если ввести какое-нибудь среднее значение; с Ксюшами дела обстояли чуть лучше. Но моя первичная оценка не была очень аккуратной. В качестве показателя одиночества я просто поделил количество женщин в отношениях на количество всех женщин с таким именем. Но даже такой простой расчет указывал, что не все так гладко, как ожидалось.
Мне подумалось, что неплохо бы правильным образом нормализовать имена, и, может быть, не брать среднее значение, а просто сравнить разные имена между собой. К тому же мне очень хотелось понять, насколько это явление глобальное и не зависит от источника данных. Тут я, конечно, отправился на сайт ВКонтакте, где есть хороший поиск с учетом нормализации имен и можно получить выборку, просто кликая по выпадающим спискам, что я и сделал.
Анализ на основе данных ВК
Для начала зафиксируем список имен, он может быть произвольный. Но мы обязательно возьмем высокочастотные имена, такие как Анастасия, Екатерина, Елена, Мария и Наталья (более одного миллиона, по данным ВК). Чуть менее распространенные, такие как Дарья, Алина, Ксения и Александра (около 800 тыс). Также нужно взять что-то более экзотическое, пусть это будут Кира и Инесса. Ну и в качестве очень большой экзотики — Лейла.
Более того, есть известная проблема, что частотность имен меняется, какие-то имена всегда сравнительно популярны, а какие-то становятся популярными в небольшом диапазоне в несколько лет. Чтобы оценить влияние этого вопроса, мы рассмотрим три случая. Возьмем девушек в возрасте 20-35 и отдельно рассмотрим (интересный мне лично) возраст 28 и совсем юных 22 лет от роду. Я сознательно не стал работать со статусом "гражданский брак" (потому что его редко проставляют) и "все сложно" (потому что его смысл для меня все еще очень туманный), ну или "помолвлена" (все-таки мы не в той стране живем, где это имеет какой-то вес), поэтому ограничился только рассмотрением наиболее употребительных вариантов, которые выступают в качестве названия колонок в нашем небольшом датасете: married, relationship, love, single и searching. Также мы найдем сколько их всего — all. В каждой колонке будет находится количество девушек с нужным именем в таком статусе. Разумеется, мы тут сразу должны сделать оговорку, связанную с именем Ксения. Дело в том, что Ксюшами зовут также и девушек с именем Оксана, так что этот вопрос требует более кропотливой работы и мы вернемся к нему потом.
Давайте определимся, как будем считать одиноких девушек. Для начала введем следующий первый коэффициент, назовем его просто v:
v = (single + searching) / allт.е. мы просто берем всех незамужних и всех, кто в активном поиске и делим на всех с таким именем. Но это только один способ, можно построить также дополнение к тем, кто имеет какие-то отношения:
u = 1 - (married + love + relationship) / allтаким образом это доля тех, кто не состоит в отношениях, и она включает в себя долю, которую характеризует число v.
Вот тут я поступлю немного нечестно, но это позволит сократить объем статьи существенным образом. Оказывается, что куда интереснее рассматривать некоторую функцию q = f(v, u) или даже от большего числа параметров в качестве интегрального показателя одиночества. Из соображений простоты и здравого смысла в качестве такой функции мы просто возьмем среднее арифметическое:
q = (u + v) / 2Еще интересно, насколько девушки с данным именем вообще склонны что-либо писать о своих отношениях – назовем эту величину w:
w = (single + searching + married + love + relationship) / allИ еще надо бы отнормировать активно ищущих (это примерно то же, что и v, только мы не учитываем тех, кто имеет статус незамужем):
a = searching / allДавайте посмотрим, что у нас получилось.
Девушки 20-35
Ниже представлена таблица с вычисленными значениями для данных ВК.

Любой здравый человек предполагает увидеть примерно одно и то же значение v и u в пределах какой-то небольшой погрешности, но никак не шкалу от 0.125 до 0.226 для случая с v! В таблице строки отсортированы по q (на самом деле, все потому, что сортировка по q дает более стабильные результаты, чем по v и u). Если более конкретно, то девушки с именем Кира статистически существенно более одиноки, чем девушки с именем Наталья. Таким образом, чем выше значение v, u или q — тем более одиноки девушки с данным именем.
Вообще такое наблюдение контринтуитивно, так быть не должно, и можно подумать, что мы сделали что-то настолько неверно, что ожидаемые примерно одинаковые значения v разошлись так сильно.
Существенное различие между верхней частью таблицы и нижней очевидно. Первое, что приходит на ум, – наверное, распределение имен в таком большом возрастном диапазоне имеет какие-то существенные пики, и они повлияли на общую картину — все-таки 15 лет. То есть можно было бы предположить, что если бы мы взяли какой-то один возраст, то ситуация была бы принципиально другой. Давайте так и поступим, и посмотрим, что же будет, если мы возьмем только девушек 28 лет.
Девушки 28 лет
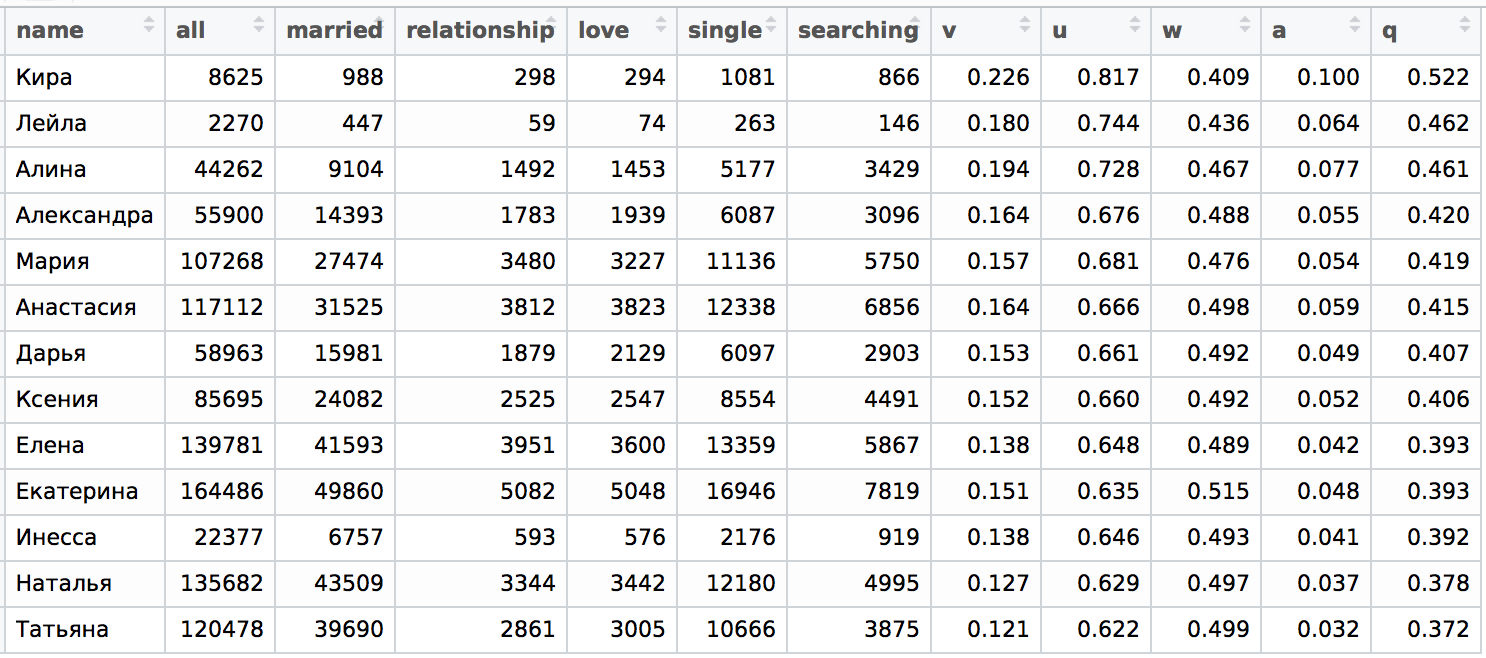
Надо сказать, что ситуация не изменилась в качественном смысле по сравнению с выборкой 20-35 лет, т.е. здесь мы также видим существенное различие между верхней и нижней частью таблицы. Структура верхней и нижней части таблицы по больше части совпадают, лишь средняя часть изменилась значительно.
Таким образом мы можем констатировать, что девушки 20-35 лет в совокупности и девушки 28 лет в отношениях ведут себя похожим образом в пределах своего имени!
Здесь мы вряд ли так легко можем поставить вопрос о связи одиночества с частотой имени. Но ничего очевидного здесь точно нет. В следующих разделах мы денормализуем имена и рассмотрим этот вопрос более подробно.
Ну это же девушки 28 лет, т.е. примерно средний возраст в нашем изначальном диапазоне, скажите вы! А что же собственно происходит с более молодыми особами, ну, скажем, в 22 года? Давайте посмотрим.
Очень юные особы 22 лет
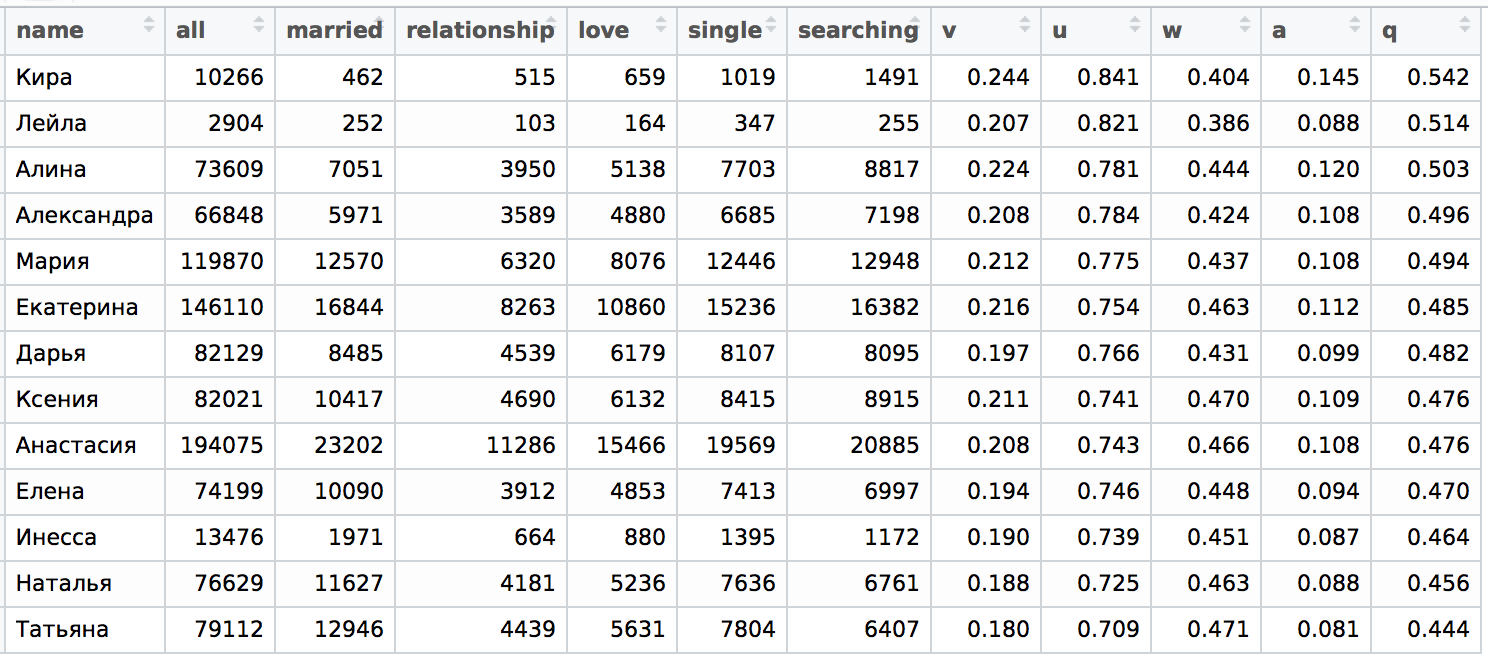
Вот это уже интереснее, здесь все тоже самое, что в случае 28 лет, только лишь поменялись местами Екатерина и Анастасия. Вся остальная структура таблицы оказалась прежней (напоминаю, мы сортируем по показателю q).
Статистика по регионам
Следующее, что нужно проверить — это что происходит с регионами. Вдруг там все иначе? В данном случае нужен был какой-то компромисс в виду того, что есть редкие имена, и я предпочел произвести расчет для возрастов 20-35, чтобы точно хватило данных.
Начнем с Санкт-Петербурга:
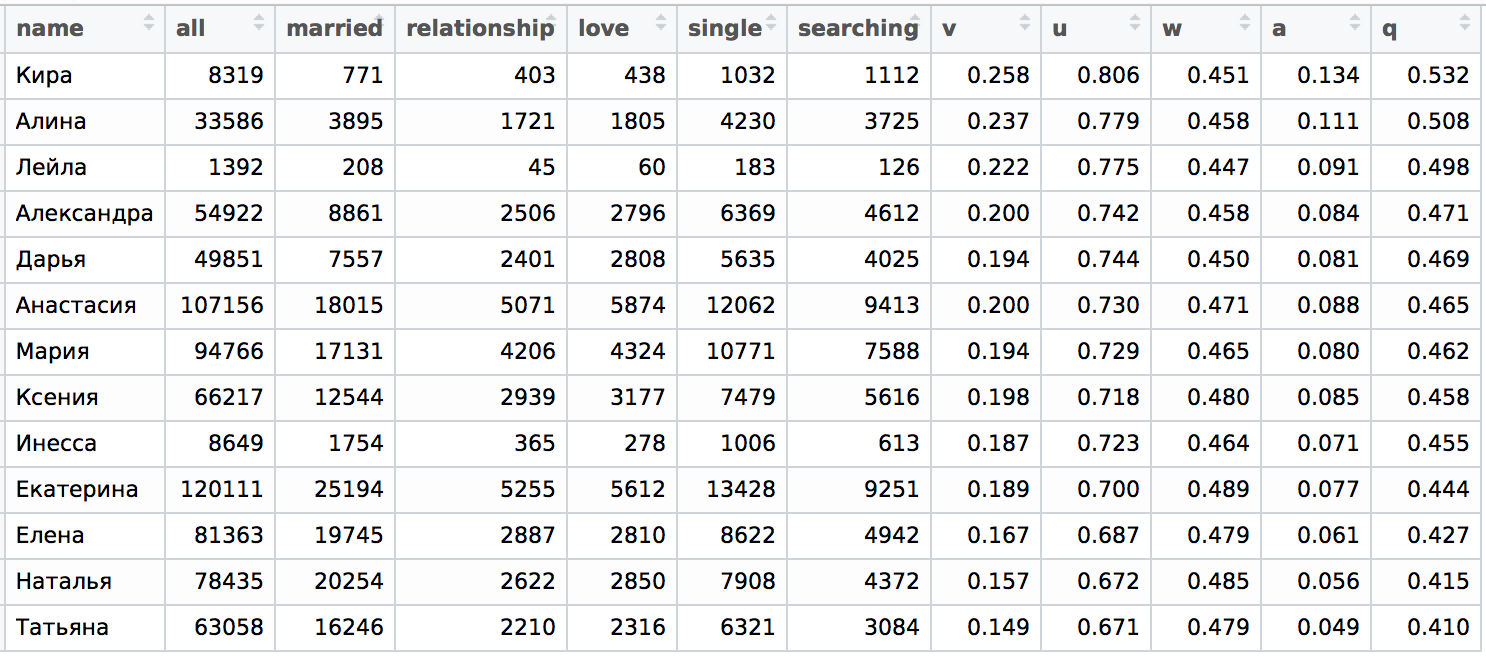
Как можно было ожидать, в Москве ситуация очень похожая за одним существенным исключением – девушки с именем Инесса куда более одиноки, чем девушки с именем Анастасия, тогда как в Санкт-Петербурге ситуация ровно обратная:
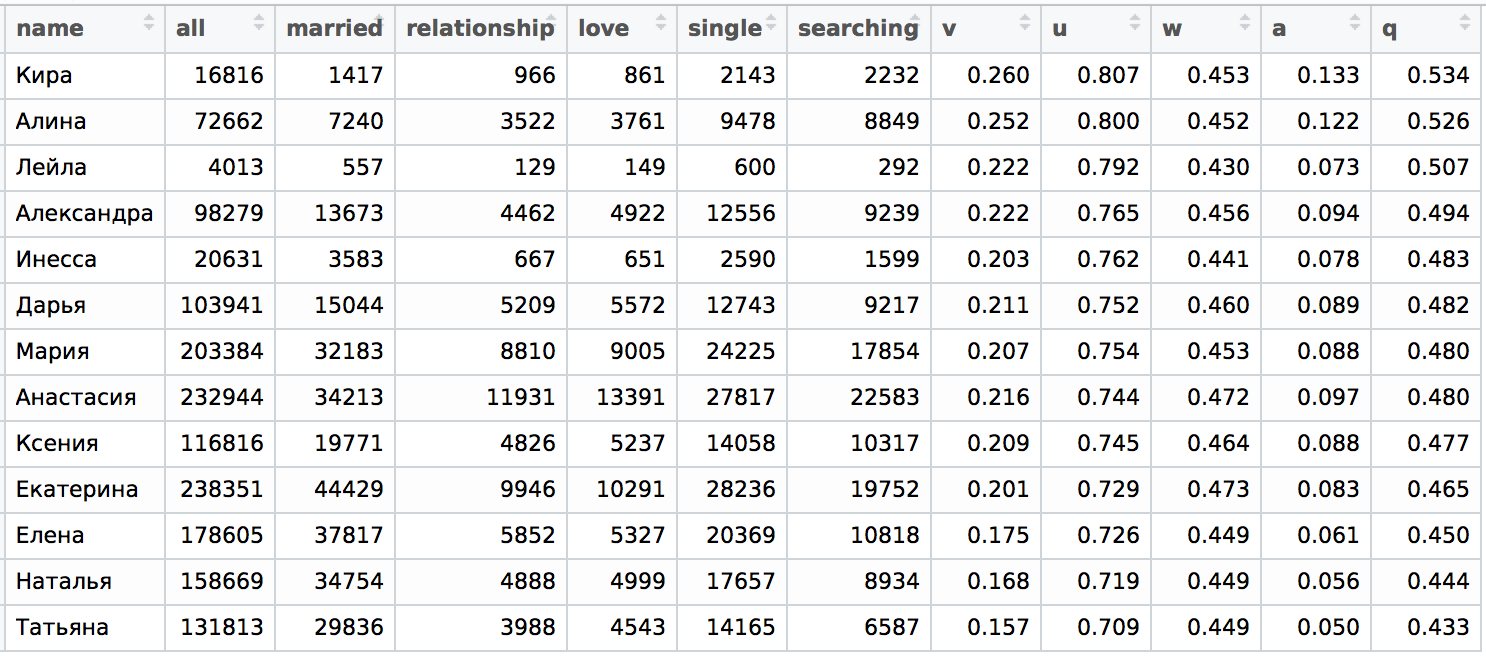
Теперь заглянем на Урал в город Екатеринбург. Как видно, верхняя и нижняя часть также совпадают с Москвой, причем, если поменять местами Марию и Инессу — то будет просто тоже самое:

Напоследок посмотрим на Новосибирск. Причем, если, как мы уже видели, Екатеринбург больше похож на Москву, то Новосибирск – на Санкт-Петербург, также с небольшими отличиями. К сожалению, статистики по имени Лейла явно не хватает, но сейчас мы не будем обращать на это внимание, нам достаточно иметь качественную картину:

Здесь, наверное, все, мы убедились, что общая структура таблиц сохраняется с небольшими изменениями в зависимости от регионов. Таким образом мы можем говорить, что распределение имен по показателю одиночества не зависит существенно от возраста и региона. Про регион нужно сделать оговорку — города выбраны так, чтобы между ними не было каких-то существенных культурных или религиозных различий.
Все было бы здорово, но хотелось бы иметь другой источник, который подтвердит или опровергнет соответствующее распределение.
Анализ на основе данных Одноклассников
В данном случае возьмем сэмпл примерно в 10 млн. пользователей и попытаемся для него посчитать то, что мы делали для случая ВК. С одной стороны, мы возьмем меньше (но вполне достаточно данных), с другой стороны, для этих данных мы можем много чего посчитать дополнительно. Как я упоминал, процесс установки статуса отношений в ОК принципиально отличается, и данных здесь будет меньше, потому учитывается здесь только статус замужества и любовных отношений. По правде сказать, примерно 80% статусов приходится на замужество.
Мы убедились в том, что можем спокойно использовать выборку за 20-35 лет как репрезентативную, потому что она практически неотличима от среза по конкретному возрасту и существенно не зависит от региона. Для всех таблиц мы берем только пользователей, у которых более 15 друзей, хотя это не оказывает какого-то существенного влияния на порядок имен после сортировки, однако существенно для вычисления количества друзей "в среднем".
Для начала попробуем понять, будет ли совпадать порядок сортировки в случае нормализации имен. Потом, с помощью более детального анализа мы разделим девушек с именем Ксения и Оксана, а также посмотрим, что происходит с уменьшительными формами имен.
Нормализованные и ненормализованные имена
В первой таблице представлен нормализованный случай, но мы не делаем нормализацию Оксана -> Ксения, но забегая немного вперед, могу сказать, что в этом нет необходимости.
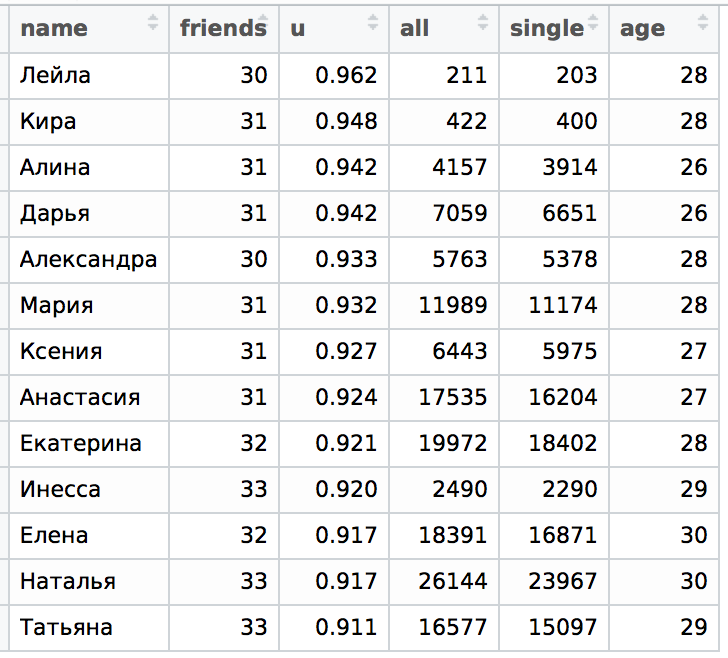
Общая структура таблицы соответствует данным из ВК с небольшими изменениями. Значение u здесь — аналог нашего u из данных ВК (это значение всегда велико, потому что статус в отношениях в ОК проставляют куда меньше людей). Более того, здесь нам удобно посчитать значение возраста "в среднем" в группе и количество друзей "в среднем". Возможно, что среднее значение возраста и влияет на сортировку, например, если нижняя часть таблицы старше. Тогда количество одиноких должно быть меньше. Но мы с вами лишь знаем, по данным ВК, что срезы по одному возрасту примерно одинаковы. На самом деле тех данных, что мы видели, явно не хватает. Хотелось бы удостовериться, что средний возраст в группе и частота имени не оказывают сильного действия.
Более того, даже при разной механике установки статуса — распределения совпадают. На самом деле можно было спокойно округлить до второго знака, но суть от этого не меняется, потому что мы понимаем, что можно перемещать имена внутри части таблицы, не меняя качественную оценку, а именно она нам важна в первую очередь.
Для этого давайте добавим несколько низкочастотных имен, например, Лия и Ася (очень редкие), Снежана, Анжела, Диана и Лилия (просто низкочастотные), а также несколько недостающих высокочастотных (Анна, Ольга) и денормализуем имена (но уменьшительные варианты пока брать не будем), разделив таким образом девушек с именем Ксения и Оксана, а также Инесса и Инна, хотя последнее и используется часто как сокращенный вариант для Инессы:
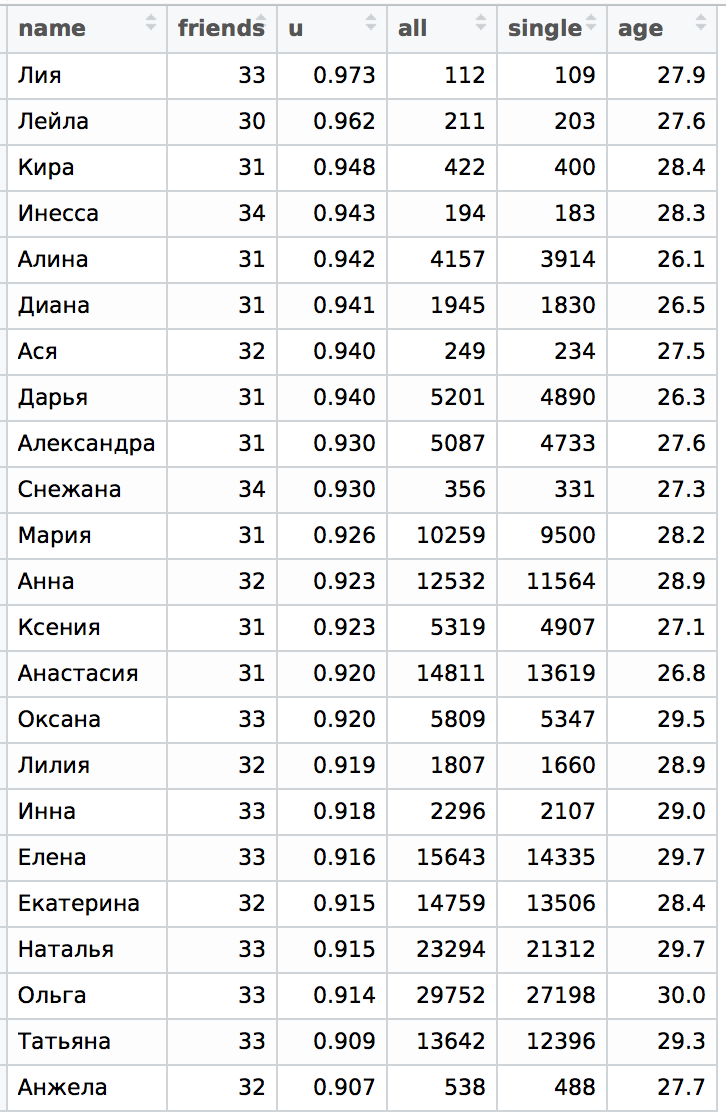
Видно, что имена Ксения и Оксана ведут себя примерно одинаково, находясь очень близко в таблице. А вот с именами Инна и Инесса все иначе. Несмотря на то, что имя Инна часто используется вместо имени Инесса и наоборот (что портит нам статистику по нормализованным именам), статистика по этим именам совершенно разная. Инна — это все-таки совершенно другое имя и для того, чтобы увидеть это в деталях зададимся вопросом, а что же будет происходить с уменьшительными именами и как будет выглядеть наша таблица.
Уменьшительные имена
Давайте рассмотрим нашу первую табличку в этом разделе. Я добавил по одному или несколько вариантов уменьшительных имен к основному списку (без Снежаны, Анжелы и других). Полученная картина очень интересна:
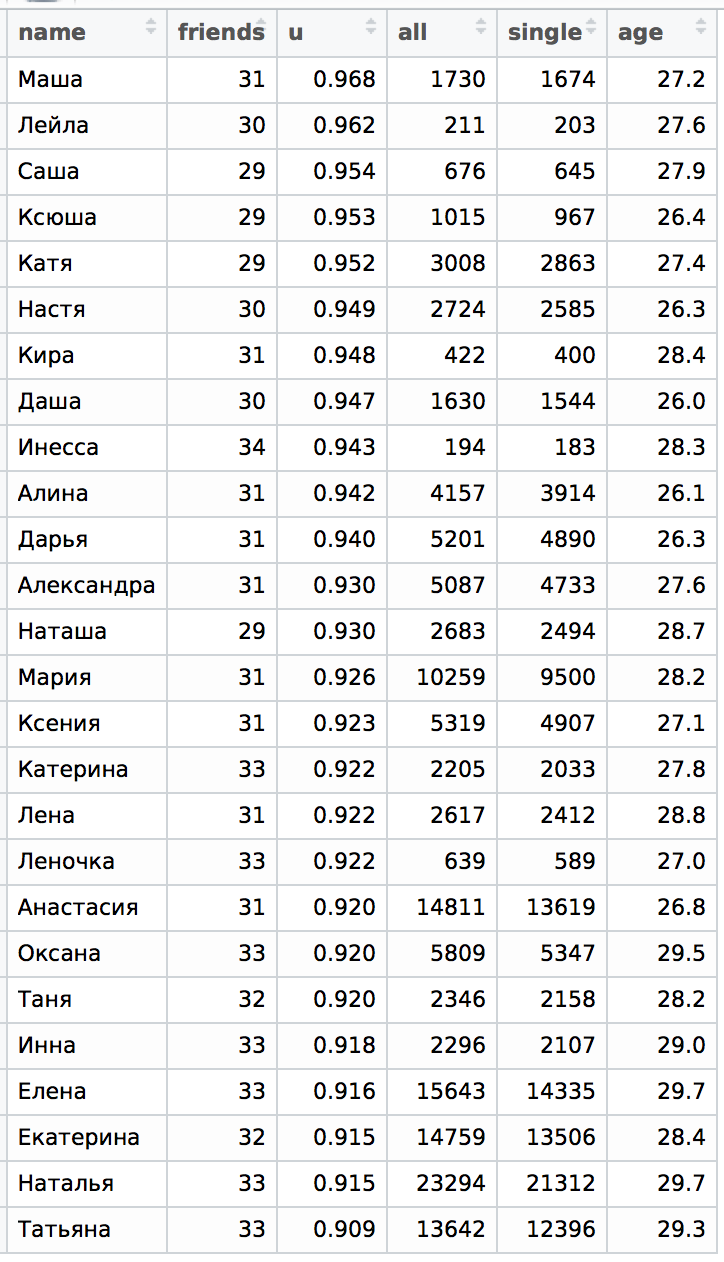
Сразу видно, что девушки с уменьшительными именами всегда, кроме случая Инна/Инесса, более одиноки. Собственно и ожидалось, что эта пара должна вести себя принципиально иначе. Из нашего предыдущего опыта нам известно, что имена Ксения и Оксана ведут себя одинаково, поэтому нам не важно, куда относить имя Ксюша. Наиболее близки со своими уменьшительными вариантами имена Елена и Дарья, все остальные очень далеко, особенно Екатерина и Мария. Кроме того, видно, что Маша, Саша, Ксюша и Катя оказались на самом верху таблицы.
Кроме качественной оценки этого вопроса, чего-то более определенного сказать нельзя. Но в этом случае, можно хотя бы высказать какую-то разумную гипотезу по поводу происхождения этой проблемы. Тут есть два основных варианта:
Возможно, дело в том, что девушки с уменьшительным вариантом имени просто моложе, а вероятность вступления в отношения зависит только от полной формы имени. Действительно видно, что с уменьшительными именами девушки "в среднем" моложе на год.
- Второй вариант тоже интересный, возможно, что именно те, кто уже замужем, ставит себе полное, а не уменьшительное имя. Или, наоборот, одинокие девушки предпочитают короткие варианты своего имени.
Достаточно трудно проверить вторую гипотезу, но можно проверить первую. Для этого нам нужно расширить наш маленький датасет, добавив к нему средние значения возраста для тех, кто точно замужем. Если разница среднего возраста и среднего возраста в замужестве будут сильно расходится для вариантов имени, это будет говорить в пользу первой гипотезы. Но при этом нужно понимать, что гипотезы не являются взаимоисключающими, скорее вторая может "включать" первую.
Из предыдущей таблицы также видно, что количество друзей "в среднем" примерно одинаково и никакой дополнительной информации с ходу не дает.
В новой таблице поля friend_ns и age_ns — это соответствующие значения "в среднем" для случая замужних девушек.
Также введем несколько синтетических полей:
delta_f = friends_ns - friends
delta_a = age_ns - ageкоторые показывают разницу показателей в случае замужних и соответствующих значений "в среднем". О правильной интерпретации выражения "в среднем" мы поговорим в разделе "Технические детали".

Для неодиноких девушек ситуация с друзьями "в среднем" совершенно иная, можно видеть существенный разброс значений, как показывает поле delta_f. На самом деле это может служить косвенным подтверждением гипотезы, предложенной Крисом Раддером. Он пишет, что крепость брака измеряется степенью ассимиляции каждого супруга в сеть связей другого. То есть существенное изменение количества друзей "в среднем" связано с ассимиляцией социального графа мужа/партнера.
Но вернемся пока к нашим гипотезам: как видно, что чем больше по абсолютному значению delta_a для короткого имени по сравнению с полным, тем выше находится в таблице короткое имя (по крайней мере качественно), что в какой-то степени подтверждает нашу первую гипотезу про влияние возраста "в среднем".
И пока ничто, кроме интуиции и здравого смысла, не указывает нам на вторую гипотезу.
Технические детали
Начнем с того, что нам конечно не всегда достаточно данных, как можно видеть из таблиц. Но качественная оценка нам все равно доступна. Мне не очень хотелось утруждать себя и вас детальными расчетами, потому что ситуация и так вполне на поверхности.
Но надо быть приличными людьми и немного поговорить об округлении (я уже говорил, что в случае OK, можно смело округлять до второго знака) и среднем значении.
Значения "в среднем"
До этого везде я использовал выражение "в среднем" только в кавычках. Рассмотрим к примеру возраст, который в некоторых таблицах я округлил до первого знака, чтобы было лучше видно. Можно ли говорить здесь про среднее значение? С одной стороны, нет каких-то выбросов, но вряд ли кто-то будет ожидать, что возраст всегда будет распределен нормально. Однако если взять, все те же имена Оксана и Ксения, которые ведут себя похожим образом и имеют одну и ту же короткую форму — Ксюша, можно увидеть, что "в среднем" Оксаны старше, чем Ксюши. Это связано с изменением популярности имени. Давайте взглянем на график для некоторых имен.

Эти графики не отражают в достаточной степени глобальное распределение имен по возрастам. Для этого их бы следовало отнормировать с учетом распределения возрастов в социальной сети, чего мы здесь делать не будем, нас скорее интересует локальная картина. Вот еще немного графиков для других имен:
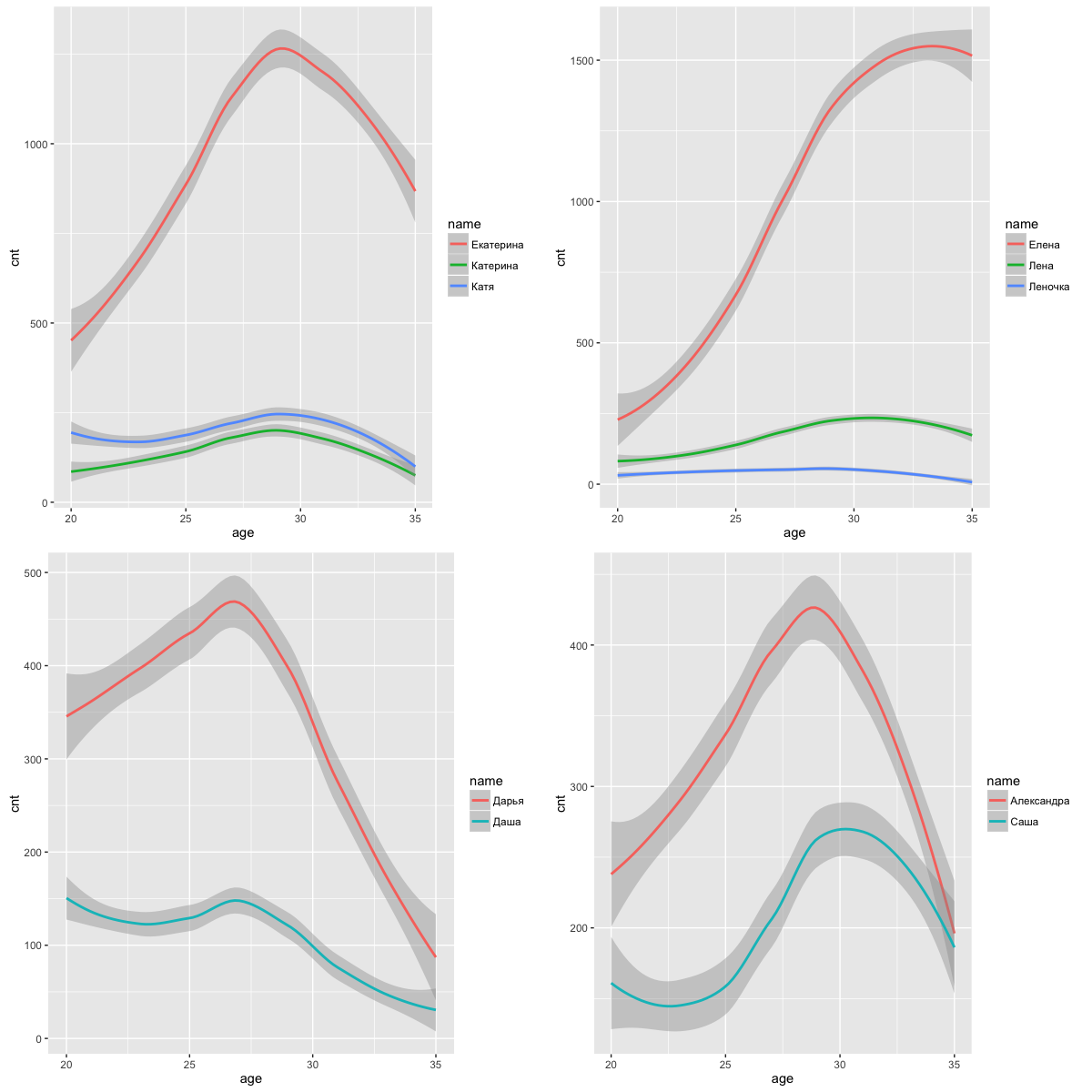
Однако мы не можем рассчитывать на распределение без сильных выбросов в случае количества друзей, поэтому в качестве "в среднем" подойдет медиана.
Погрешность
Я округлил в таблицах из ВК до третьего знака значения для q. Насколько это вообще корректно? Для проверки я сделал измерение еще раз, но через полторы недели. Результат представлен в следующей таблице:

Как можно видеть, сравнив с первой таблицей, совпадает не просто сортировка, но и значение q, кроме случая с именем Дарья. Как выяснилось, по какой-то причине ВК в поиске показывает иногда меньшее число, при отсутствии фильтров. В этот раз я это заметил, потому что начал с Дарьи (как и в прошлый) и общее число девушек с таким именем оказалось даже немного меньше, чем в прошлый раз. Поэтому я сделал еще несколько замеров. Таким образом есть основания полагать, что значение для этого имени в последней таблице более достоверно, хотя общая картина полностью сохраняется и для предыдущего замера.
Так как нам важна прежде всего качественная оценка ситуации, проделывать все тоже самое с данными из OK большого смысла нет и, для экономии времени и места, мы это опустим.
Сухой остаток и заключение
Что же мы узнали? Несмотря на абсолютную неправдоподобность самой идеи, неравномерность распределения в зависимости от имени можно подтвердить, более того, распределение имен не зависит от частоты имени, региона (в разумных пределах) или источника данных. Если совсем сухо: имя — это фича.
Я здесь не буду пытаться построить модель или выдвинуть гипотезы, которые бы как-то описывали полученные результаты. Однако замечу, что данные, полученные для имени Лейла и Лия вполне ожидаемые. Потому что первое имя "арабского происхождения" и девушки с таким именем вероятно являются носителями культурной традиции, которая отличается от культурной традиции девушек с "более традиционными русскими именами". А имя Лия "очень широко распространено среди евреев" и, вероятно, также несет в себе некоторые культурные особенности.
Но, в общем случае, я пока не могу предложить никакую сколь угодно состоятельную теорию, которая бы могла объяснить наблюдаемые результаты.
Даже можно сделать разные поправки на то, что не у всех статус выставлен и выставлен правильно (соответствует действительности), но в любом случае, рассуждения приводят к тому, что различия связаны с поведенческими особенностями имени. Таким образом, в худшем случае, мы имеем следующей вывод: в зависимости от имени девушки ведут себя по-разному.
Было бы очень интересно получить обратную связь от социологов, психологов и специалистов по ономастике в этом вопросе.
Мы также приглашаем к сотрудничеству специалистов по анализу данных и социальных сетей в рамках нашего проекта Лаборатории по анализу данных.
Мне бы конечно не хотелось, чтобы результатом такого рода наблюдений стала ситуация вроде следующей: вы приходите в банк, а ставка по вашему кредиту выше, потому вы ну скажем Петя, а не Вася.
И чтобы уж было совсем интересно, напоследок посмотрим, что там происходит с мужскими именами. Возьмем данные ВК для мужчин 20-35 лет.
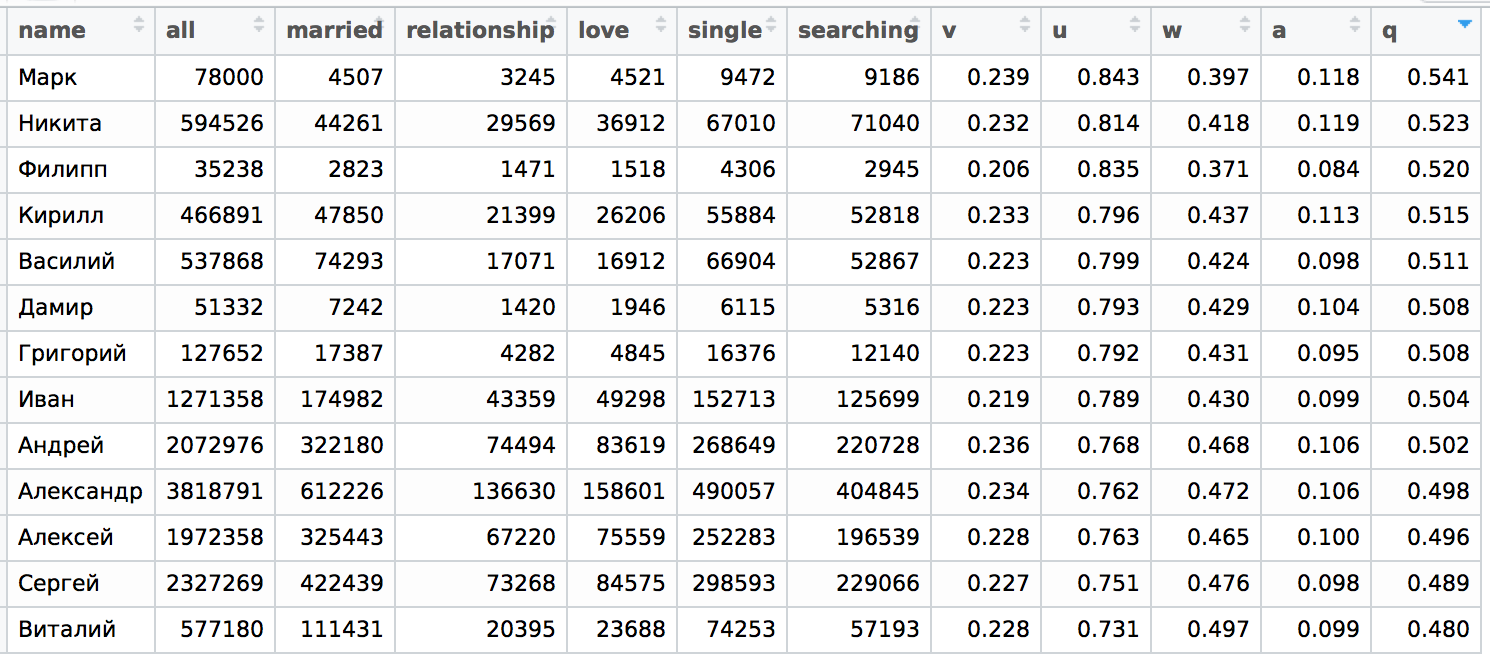
Я здесь также сортировал по q, однако ситуация с мужчинами "менее стабильная", потому что если сортировать по v, то люди с именем Виталий будут куда более одиноки, чем при сортировке по q.
В статье нет анализа показателей w и a, но вы можете сами поразмышлять на эту тему.
В заключении я бы хотел поблагодарить всех тех, кто был хоть как-то причастен к моей работе. Огромное спасибо Филиппу Федчину, Никите Павленко, Сергею Товмасяну и многим другим.
iCpu
Я правильно понимаю, у вас не учитываются «возможные дубликаты»? Ну, то есть, люди, которые пролюбили один или несколько своих аккаунтов. Не учитываются боты и прочие непотребства?
Я не хочу сказать, что ваша выборка не репрезентативна — я не знаю. Но такой шум имеет место быть, и его влияние достаточно значимо. Простейший сценарий, копируем имена из какого-нить сервиса для беременных, закидываем по рандому, в статусе пишем стандартную фигню «холост\не замужем\всё сложно» («в поиске» для «утешных» спамботов), «пастофарианец» и тп. Генерируем 10 000 аккаунтов — и вот у вас 50 холостых Наташ и 50 холостых Лейл, что даёт влияние в 0,0005 и 0,003 от общего числа соответственно. И что-то мне подсказывает, что таких аккаунтов не 10 000, и даже не 100 000, и что для непопулярных имён их влияние становится статистически значимым.
marsermd
Да, интересный вопрос.
khud Автор
Сюжет с ботами известен, я его сознательное не упомянул, мне хотелось собрать фидбек от разных людей. Это безусловно требует дальнейшего исследования. Хотя одинаковое распределение в двух социальных сетях с довольно разной пользовательской структурой даже при таком случае маловероятно. В любом случае полностью отвергать влияние этого вопроса я не готов.
iCpu
Я бы не сказал, что есть основания считать, что ОК, ВК и FB будут иметь сильно разные пользовательские структуры. Примерно одинаковые правила регистрации, равноценный функционал +-дельта. Без углублённого изучения с сопоставлением пользователей всех соцсетей сложно делать такие далёкие выводы.
ilya_pu
Существенность различий между ОК, ВК и FB можно и проверить, способы есть. В плане ботов — честно говоря, даже не знаю, как их можно выявлять, поскольку ну очень много таковых развелось в последнее время… причём ботоводы используют огромное количество разных стратегий. Например, видел бота, который постил себе на стену каждые 4 — 5 часов в течение полугода (и плевать, что «по графику» — это в три часа ночи с воскресенья на понедельник), другие боты работают по-другому… К сожалению, зачастую бывает, что вот видишь, что это бот к тебе в друзья напрашивается, но доказать невозможно… какие-то косвенные признаки есть, но не более того… вот бы написать программу, которая будет считать вероятность того, что под личиной конкретного пользователя «скрывается» бот… тогда это было бы не только интересно, но и практически полезно…
По поводу женских имён… Женщины чаще склонны не указывать имя или указывать другое имя, плюс к этому могут, даже будучи в браке, написать «в активном поиске» (для парней такое поведение влечёт за собой более серьёзные последствия)… Опять же, если возьмёте газеты бесплатных объявлений, то увидите, что в разделе «знакомства» более чем у 50% девушек имя начинается с буквы «а»… понятно, что подобный фактор в социальных сетях играет весьма малую роль, но, возможно, с выбором имени на странице в соцсети тоже что-то нечисто… В общем, все эти моменты требуют дальнейшего исследования, а так — конечно, хотелось бы увидеть ещё и техническую сторону (как собиралась и обрабатывалась информация).
iCpu
balexa
Смотрите на граф друзей. У реальных людей четко видны кластера в графе — школа, институт, друзья по спортивной секции и т.д. У ботов же как правило друзья никак не связаны друг с другом.
ilya_pu
С одной стороны, да, а с другой стороны — сам знаю множество примеров, когда люди (живые, реальные люди, никакие не боты) добавляли в друзья первых попавшихся — ботов, спамеров и иже с ними, а когда я задавал такому реальному человеку, знает ли он, кто это у него в друзьях числится, то получал ответ «без понятия», при этом бот так и оставался «другом»… И потом, это тоже можно обойти, отправляя запросы на добавление в друзья тем, кто уже подтвердил дружбу с ботом… То есть пройти по тому же графу другого пользователя — и постараться добавить к себе его друзей… По этому признаку бот станет неотличим от реального человека…
marsermd
Это прекрасно! Поздравляю с первой публикацией на хабре:)
ildarz
"Отсутствие причинной связи между явлениями, хотя корреляционная связь между ними установлена, называется ложной корреляцией." (с) экономико-математический словарь
spmbt
> Действительно видно, что с уменьшительными именами девушки «в среднем» моложе на год.
Какой ужас — называясь уменьшительным именем, ты сокращаешь среднюю продолжительность жизни. Статистика не даст соврать!
slonoslon
Я навскидку вижу следующие гипотезы, объясняющие этот феномен:
1. Выдуманные имена (про это уже писали выше). Причем тут много вариантов может быть — не только боты. Кому-то может не нравиться паспортное имя, кто-то может скрываться от родных и знакомых, кто-то может вести двойную жизнь (один аккаунт в отношениях, другой — в активном поиске) и т.п. И вполне вероятно, что склонность писать выдуманное имя коррелирует одновременно с большей редкостью имени и с более одиноким статусом аккаунта. (Как предельный вариант — девушка, предлагающая интимные услуги за деньги и ищущая клиентов в соцсети, практически никогда не поставит в профиле настоящее имя и практически всегда будет 'в активном поиске' или около того.)
2. Влияние семьи. Обладатели редких имен могут быть представителями этнических меньшинств (про это в статье есть) со своими культурными особенностями. А могут быть детьми, выросшими в семье, где родители предпочитают давать редкие имена — чтобы дети выделялись, например. Возможно, родительское послание «выделяйся», столь явно переданное, тоже коррелирует с одиночеством.
synedra
Кстати, да, тоже хотел заметить насчёт редких имён в качестве вымышленных. В наборе данных из одноклассников среди «одиноких» доминируют всякие Инессы, Алины и Дианы. Я, может быть, придираюсь, но ни про единую Инессу, которую реально по паспорту так зовут, я в рассматриваемом поколении даже не слышал. Алину и Асю лично знаю, но по одной на всё множество ~сверстниц, с которыми я IRL хоть как-то контактировал. Учитывая, что датасет там, как я понял, крошечный, одних только рабочих аккаунтов проституток хватит на то, чтобы вывести экзотические имена в топ.
Думаю, это можно исправить, если взять частотность имён в соответствующей когорте по данным переписи, сравнить с частотностью в ваших данных и сделать поправку на overrepresented (простите уж, забыл, как оно по-русски) имена.
TimsTims
Это здорово вы так пару миллионов проституток накрутили)
markmariner
В защиту теории о ботах, вторых аккаунтах и аккаунтах проституток говорит и то, что различия в вычисляемых значениях для мужчин гораздо меньше.
Sosiska
Можно также отфильтровать ботов с помощью анализа данных)
Wedmer
Как показывает личный опыт, боты чаще всего представляются персоной женского пола. Это чисто психологический аспект, как мне кажется.
К моей жене боты-мужики как то в друзья не ломятся.
Сейчас в тренде создание тысяч левых аккаунтов для различных накруток, продвижений и прочего.
antarx
Отличная статья!
Теперь можно наконец показать по данным VK и Одноклассников, под какой звездой рождаются семейно успешные люди, и как между собой совместимы знаки зодиака!
Sosiska
Ещё это может говорить о том, что женщины чаще забывают пароли и их компьютеры чаще заражаются вирусами.
haldagan
Давайте скорректируем ваше заявление: «Статус 'не в отношениях', выставленный пользователем в социальной сети некоторым образом коррелирует с именем, которое указал этот пользователь в этой социальной сети».
Пользователь социальной сети по-хорошему не может быть строчкой в вашей статистике до тех пор, пока вы не удостоверились, что пользователь указал свое реальное имя и свой реальный статус если ваша цель — проверить изначально заявленную вами гипотезу.
khud Автор
В предположении «белого» и/или незначительного шума от фейковых статусов и пользователей что-то сказать наверное можно.
haldagan
Речь не просто о шуме, а о несоответствии собираемых данных и проверяемой теории.
Тезис из вашей статьи:
Собранная статистика:
Если Вы знаете некое научное исследование с выводом наподобие «в 99% публично доступных аккаунтов в социальных сетях указаны достоверные личные данные и статус отношений» — поделитесь ссылкой на статью. Я признаю свою неправоту и соглашусь, что этот один процент можно считать шумом и не обращать на него внимания.
23derevo
Понятно, что мы говорим не о реальных статусах, а об указанных в соцсетях. Под одеяло к людям из выборки никто не заглядывал.
haldagan
Из чего понятно?
Из вот этого вот:
Я делаю вывод, что по достоверности автор приравнивает заполнение анкеты в социальной сети к анонимному опросу.
khud Автор
К вопросу о ботах и проститутках. Тут наверное надо сказать, что данные для ВК и ОК собирались совершенно разным образом. Если в случае ВК все делалось через пользовательский интерфейс, т.е. можно предположить, что пользователи в выдаче — это пользователи, которые прошли спам фильтр. В случае OK данные обрабатывались в Hadoop без использования данных антиспама. Нужно более детальное исследование этого вопроса, но это говорит нам в пользу того, что вес ботов и им подобных здесь не так высок.
Centimo
Не хочу показаться поклонником астрологии и гомеопатии, но лично у меня такие результаты не вызывают удивления. По моему личному опыту, у людей с одинаковыми именами есть определённые сходства.
0xd34df00d
Можно предложить вполне рациональную гипотезу ассоциаций с образами из культурного контекста. Анна — так Каренина, Алла — так Пугачева, Валерия — так Новодворская.
ainoneko
Валерия — может быть и просто Валерией (которая на самом деле Анна).
veveve
Нет, не зависит. Одиночество коррелирует с именем, но не зависит от него. «Зависит» и «коррелирует» — это разные вещи, как уже выше писали.
[ источник ]
khud Автор
Все правильно, конечно, с точки зрения вопроса зависимости и корреляции в общем случае, но в этом конкретном случае именно вероятность зависит, что на самом деле означает корреляцию. Это скорее лингвистическая небрежность. Более того, можно точно указать направление этой «зависимости»: имя дается при рождении (обычно). Остается конечно возможность наличия третьего фактора, который связан как-то с этими двумя. Это может быть все что угодно, пусть это будут яблоки (к примеру), есть корреляция между количеством съеденных яблок и одиночеством, но также есть корреляция между именем и сколько девушка ест яблок. То есть конкретная девушка с этим именем может яблоки не есть, но вот в среднем все будет так, как выглядит. Но это приведет нас к той же проблеме – корреляция между яблоками и именем, т.е. «хрен редьки не слаще».
zetroot
Очень милое исследование! К всей вышеприведённой критике, хочу добавить, что автор не указал полученный p-уровень значимости результатов, т.е. насколько значимы полученные различия для групп?
Frolenarzt
Независимо от того какие можно сделать выводы — очень интересно, спасибо!

Вспомнился сайт паразитных корреляций: www.tylervigen.com/spurious-correlations
Например, так выглядит распределение по годам людей утонувших в бассейне и количеством фильмов в которых снимался Николас Кейдж:
logiciel
Было бы интересно исследовать возраст, к примеру, после 45, когда создание фейковых аккаунтов становится гораздо более редким явлением.
khud Автор
Трудно сказать, на сколько это правда. Но можно будет попробовать.
Sabiko
Бросается в глаза, что победители хит-парада как среди мужских, так и среди женских полных имён — не сокращаются.
Если сложить это с довольно достоверной теорией, что одинокие/в поиске предпочитают использовать уменьшительную версию своего имени, и из каких-то имён эти множества убраны, а из каких-то нет — то разница может возникать как раз из-за вариантов имени.
Надо для каждого паспортного имени прибавить все его версии и считать для каждого набора вкупе, тогда разброс скорее всего сильно уменьшится.
khud Автор
Про несократимые имена тоже заметил особенность. Теория тоже имеет место быть, правда на сколько она верна сказать пока трудно. Поэтому тут как раз рассмотрены случаи для нормализованного случая как для ВК, так и для ОК.
alexandershelupinin
классика по теме — Павел Флоренский, «Имена»
maxis42
Было бы неплохо написать доверительные интервалы для среднего. Рассчитать p-values. И сделать поправку на множественную проверку гипотез.
для статистики абсолютно ничего не значат.А то заявления вроде
khud Автор
С одной стороны есть несколько качественных аргументов в пользу статистической значимости. Например, сохранение сортировки в таблицах для OK и ВК. С другой стороны, если взять случайную выборку в 100 имен (с достаточным количеством статистики), чтобы не быть обвиненным в cherry picking, сделать permutation имен с учетом частотности и посмотреть что вышло, мы получим p-value = 0.000256 для теста Манна-Уитни. На счет моего заявления, то это не имеет отношения к статистики, это просто контринтуитивно. Эта статья не в научный журнал все-таки, поэтому я могу позволить себе некоторую вольность, пожалуй.
alexmcs
Могу сделать вброс про один фактор, который наверняка имеет место с Ксюшами) В 90х была популярна песня Апиной «Ксюша, юбочка из плюша») Полагаю, что это отчасти повлияло на выбор имен, даваемых девочкам)
khud Автор
Это вряд ли влияет на картину «в целом», но на распределение имен, что на графиках влиять может.
sim0nsays
эээ, а не может быть просто, что выбросы происходят на более редких именах и все? Тупо статистически, у имен с меньшим количеством людей разброс средних больше, поэтому и в вверху, и внизу — более редкие имена, а популярные — в середине.