Данные, которые собирает AppMetrica, можно заставить работать как угодно, а не только для аналитики. Они позволяют автоматизировать множество процессов, прямо или косвенно связанных с поведением пользователей. О том, как настроить выгрузку, что за данные можно использовать и какие подводные камни встретились при разработке Logs API, рассказал разработчик Николай Волосатов.
— Меня зовут Николай Волосатов, я работаю в отделе мобильной разработки Яндекса. В частности, разрабатываю iOS SDK AppMetrica. Работаю более трех лет.
Сегодня я расскажу про некую функциональность, о которой, возможно, вы еще не слышали или слышали, но ни разу не пользовались, даже если у вас интегрирована AppMetrica. Сервис называется Logs API, он позволяет выгружать неагрегированные данные. Я расскажу, чем он может быть полезен, как его можно использовать, все, что нужно знать об этом продукте. Еще расскажу про то, с чем я столкнулся, разрабатывая инструмент для автоматизации работы с данными API, какие есть тонкости, трудности, что стоит за всем этим. Я пытаюсь заинтересовать вас как в самом продукте, так и в некоторых его особенностях, о которых расскажу.
AppMetrica — универсальный аналитический инструмент для ваших мобильных приложений. Позволяет делать анализ от установок и рекламных кампаний до крашлогов, вот это все. Представлен также в виде SDK для всех основных платформ: iOS, Android, Windows Phone. И также — в виде плагинов для Unity, Cordova и Xamarin.
Подробнее останавливаться на самом SDK не могу, но на нашем сайте вы можете посмотреть документацию и другие доклады, мы и на Cубботниках рассказываем про данный продукт. Можете поизучать — возможно, в ваших мобильных приложениях это может быть полезно.
Сегодня поговорим про, возможно, малоизвестную возможность нашего продукта — выгрузку неагрегированных данных. Что это такое? Все данные, собираемые нашим сервисом, мы используем у себя для построения отчетов на вебе, красиво, чтобы можно смотреть, следить за тенденциями, за тем, как работает приложение. Но также мы позволяем все эти данные выгружать в том неагрегированном виде, в котором они у нас хранятся, и отдавать их вам для каких-то ваших нужд.
Какие данные можно использовать? В первую очередь, информацию о рекламных кампаниях. Пользователь кликает по ссылкам, переходит в стор, устанавливает ваше приложение, вся эта информация у нас есть, ее вы можете использовать, например, для анализа эффективности рекламных кампаний, для интеграции с внутренними сервисами по установке целей, по мониторингам. Можете расширять информацию о том, как именно и откуда устанавливают ваше приложение, что работает эффективно. Плюс информация о том, новая это установка или переустановка приложения.
Более широкое применение — у информации о событиях, которые вы отправляете к нам в коде приложения и дальше можете анализировать на вебе.
В совокупности с началом пользовательских сессий, когда пользователь начал работать с приложением, открыл его в первый раз или развернул после тайм-аута сессии, все эти данные будут удобны для анализа поведения пользователя внутри приложения, для анализа того, как он ходит по экранам, где задерживается, как эффективно это приводит к продажам. Воронки продаж. Вся эта информация, помимо того, что может быть использована вами, может быть полезна для ваших партнеров, через которых вы делаете рекламные кампании.
Также интересной возможностью является выгрузка крашей и ошибок. Тут тоже есть простор для творчества — например, проинтегрироваться с вашим issue tracker, с вашими корпоративными мессенджерами, слать нотификации в Slack. В случае новых крашей вы можете эту информацию собрать, завести тикет, раз в неделю писать туда отчеты о том, сколько случилось крашей. И когда краш исправлен, в ваши интеграции также придет нотификация.
Помимо этого, можно выгружать информацию, необходимую для отправки пуш-нотификаций вашего приложения. Наш сервис позволяет слать пуши по всем сегментам, по которым наша SDK может отфильтровать пользователей. Но если вам этого мало или у вас очень специфичные вкусы в плане отправки пушей, вы можете отправить их сами, делать отправку самостоятельно.
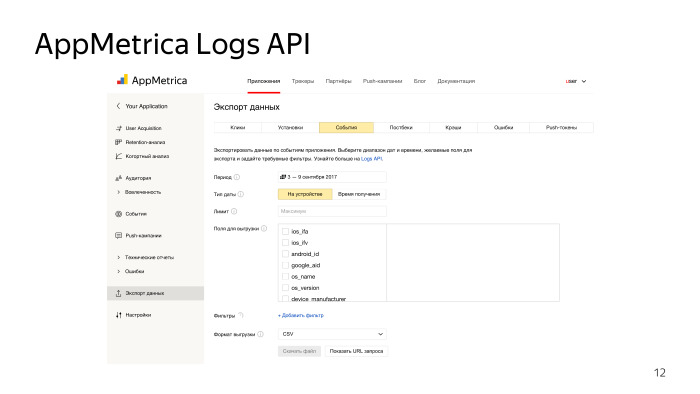
Интерфейс выгрузки предельно прост. Им может пользоваться человек, далекий не только от разработки, но и вообще от работы с компьютером. Простой сайт, наша веб-морда от метрики, экспорт данных, тип данных, формат, какие данные вам нужны, временной интервал, поля, фильтры. Поддерживаются форматы выгрузки СSV и JSON. Нажимаете «Сформировать данные», ждете, пока пройдет очередь обработки данных. Ответ будет сформирован, получаете обычный файл.
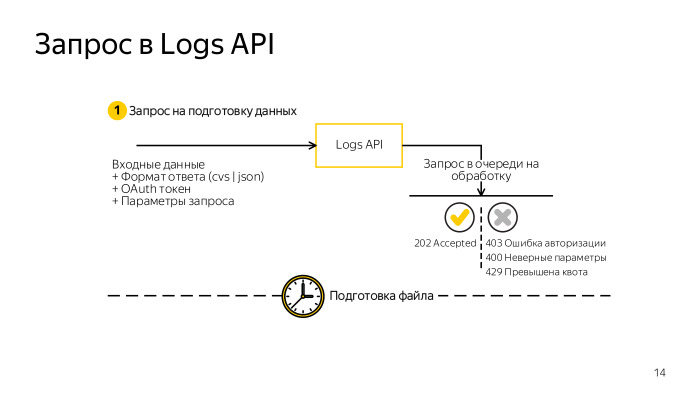
Что под капотом? Запросы, если вы решите делать через терминал, предельно просты. Вы формируете обычный GET-запрос к нашему сервису. Для этого требуется авторизационный токен, простой OAuth-токен и все те же поля: какие данные, фильтры, филды, столбцы вам нужны. Делаете запрос, получаете код ответа HTTP 202. Если все хорошо, запрос поставлен в очередь, то теперь вы будете получать 202 на каждый запрос, пока данные формируются. Или же какой-то ответ с кодом ошибки: 403 — ошибки авторизации, 200 — неверно сформирован запрос, если поля принадлежат не тем данным, 239 — превышена квота.
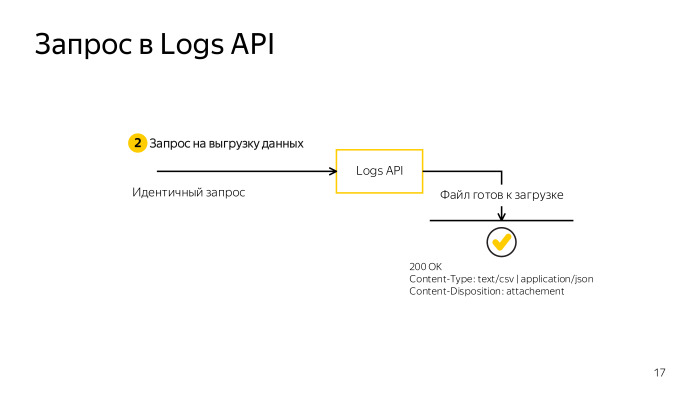
Параллельно можно делать три запроса на одно приложение. Если у вас не одно приложение, вы можете делать больше запросов. Размер выгружаемых данных не должен превышать 5 ГБ. В совокупности с тем, что вы можете еще превысить лимит по времени, надо научиться как-то разбивать запрос, сокращать выборку. Но если вам нужно получить большие данные и вы не можете что-то отфильтровать или сделать меньше полей, на помощь приходит возможность просто разбить запрос на несколько частей. Два новых параметра, parts_count и part_number. По одному итерируете и выгружаете весь набор данных. Когда ответ сформирован сервером, вы получите 200 и, в теле ответа, все необходимые данные.
Выглядит просто, давайте попробуем автоматизировать. Скорее всего автоматизировать необходимо, когда вы разрабатываете расширение аналитики, будь то воронки продаж или анализ крашей.
Скорее всего, это будет состоять из трех частей. Вам нужна база данных, куда вы будете складывать выгружаемые данные, сам скрипт выгрузки и интерфейс. Если это какая-то аналитика, то веб-интерфейс. Если интеграция с мессенджерами или issue tracker — виртуальный интерфейс продукта, куда вы шлете отчеты и, конечно, запросы к базе.
В скрипте выгрузки, который я реализовывал, я решил использовать в качестве БД то, что логичнее всего использовать. То, что используется у нас на бэкенде. Это база данных ClickHouse, про которую, возможно, вы уже где-то слышали. Возможно, даже используете, возможн, о в продакшене. Замечательная БД, разработанная для хранения какой-то аналитики, частых событий, используется в том числе в ЦЕРНе. БД позволяет делать поразительно быстрые запросы на вставку, на селекты, на выборку данных, при этом работает распределенно.
У нас данные пусть не такие большие, за один раз всего 5 ГБ, но если вы будете выгружать годами такую статистику, в конце концов вам потребуется ускорение для построения отчетов. Следующее, что нужно: интерфейс и построение запросов к нему. Об этом готовится статья, выйдет на Хабре от Марии Мансуровой miptgirl, которая разрабатывала инструмент по тем самым воронкам продаж.
Сегодня мы больше остановимся на выгрузке, на нюансах, связанных с обновлением загрузки данных такого рода. Пройдемся по проблемам, с которыми можно столкнуться в ходе разработки интерфейса автоматизации.
Первое, с чем мы столкнулись, это большие объемы данных. В 2017 году называть 5 ГБ большими объемами — кощунство, но поймите, разрабатывая скрипт для выгрузки, вы подразумеваете, что он будет работать в минимальном окружении, будь то минимальный инстанс на Amazon или машинка у вас в гараже. Вам требуется, чтобы все влезало в оперативную память, нигде не проседало. А если на той же машинке будет еще ClickHouse крутиться, вы столкнетесь с проблемами и не сможете 5 ГБ за раз вставить в базу.
Надо научиться разбивать данные, которые мы получаем. Выгружать мы будем CSV, он потоковый, его можно бить на строки. Вручную это делать достаточно сложно. Тот, кто писал написать парсер CSV, понимает, что не так просто, по new line не разбить.
Мы будем пользоваться pandas, скрипт написан на Python. Кто работал с данными на Python — знает эту библиотеку. Метод read CSV — достаточно гибкий для такого рода проблем.

Это кусок кода, который отвечает за разбитие большого запроса на части. На вход подается стрим из сети, от нашего API, поток, и на выход мы получаем итератор с чанками по n строк. Предельно просто: мы сократили объем оперативной памяти, который нужен за раз.
Следующая проблема — обновление данных. Здесь надо посмотреть, какие по своей структуре и природе данные отдает наш сервис.
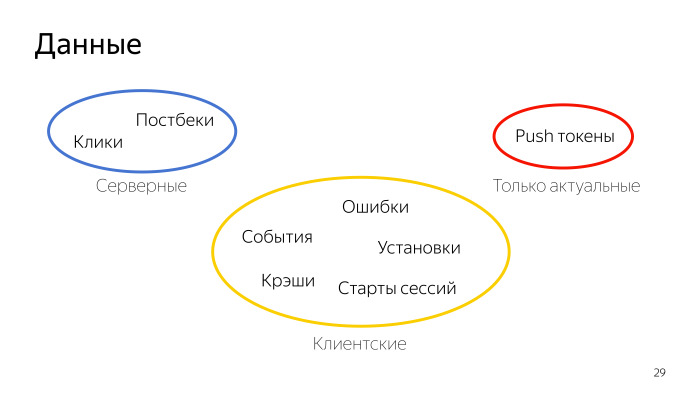
Их можно разбить на несколько групп по временному характеру. Первое — серверные данные, которые генерируются на сервере и там же хранятся. Они претерпевают минимальную задержку. Событие случилось, клик случился, и его можно выгрузить через Logs API.
Отдельно находятся пуш-токены. Мы не храним и не отдаем исторические данные по ним, нельзя выгрузить пуш-токены за три недели назад. Они только актуальные выдаются, они тут на особых правах.
И — значительная часть ответов от Logs API приходит от клиента, от мобильного приложения, что логично, это мобильная аналитика. Здесь мы сталкиваемся с проблемой, что клиентские данные могут приходить с задержкой. Задержка может составлять до семи дней. Данные могут доходить и позже, но не будут отдаваться в Logs API, уже считаются устаревшими. Это связано с тем, что у пользователя не всегда есть интернет, не всегда мы отправляем события прямо сразу, чтобы экономить и ресурсы девайса, и трафик — потому что где-то в запросе есть служебная информация. Все это складывается в то, что придется обновлять данные и держать в голове, что данные старше недели мы считаем архивными. Они больше не будут меняться, но текущая неделя — проблемные данные, их нужно обновлять, и они будут дополняться за последние 7 дней.

Если вспомним, что мы пользуемся ClickHouse, то обновлять данные не так просто. База ClickHouse не рассчитана на то, что данные как-то будут изменяться. Эта особенность всех устраивает, потому что данные рассчитаны на аналитику. Там никаких изменений быть не должно.

Первое решение, которое нам пришло в голову: делать выгрузку в отдельную таблицу. Допустим, выгружаем по одному дню в отдельную таблицу, дальше строим diff с данными, которые у нас есть, и добавляем его в продакшен-базу, которую мы выгрузили.
Такое решение работает. На небольших данных оно работает даже достаточно быстро. Но если подумать, сколько данных можно выгружать годами, то потом запрос на построение разницы между тем, что мы скачали и тем, что есть, будет занимать существенное время. ClickHouse на такое не готов, это решение плохо масшабируется, если вы будете делать такую большую БД, и оно в принципе проблемное.
На помощь приходит сам ClickHouse, который предоставляет интересную возможность: будем выгружать данные следующим образом — каждый день из последних семи будем выгружать в отдельную таблицу. Все данные старше семи дней будем складывать в отдельную архивную таблицу и в случае обновления будем скидывать туда те таблицы, которые больше обновляться не будут.
Чтобы с этим было удобно работать, у ClickHouse есть замечательная виртуальная таблица, имеющая движок merge-таблицы. Это виртуальная таблица, которая будет где-то у себя при запросах делать union всех данных из таблиц, основываясь на регулярном выражении. Нам даже не нужно будет пересоздавать эту таблицу— она будет подхватывать новые и изменяющиеся таблицы автоматически.
Теперь чтобы обновить один день, нам достаточно выкинуть таблицу, которую мы считаем устаревшей, и загрузить заново. В случае, когда таблица больше не обновляется, мы скидываем все данные old и тоже ее удаляем. Теперь ClickHouse доволен. Это решение отлично масштабируется и не требует сложных запросов на вставку данных.
Можем идти к следующим проблемам. Следующий вопрос был с сохранением состояния. Это может показаться тривиальным, но в ходе разработки инструмента требовалось постоянно держать в голове, что скрипт должен работать правильно, не должен пропускать данные, дублировать, и при этом все должно работать достаточно быстро, не перегружать весь мир в случае проблем.
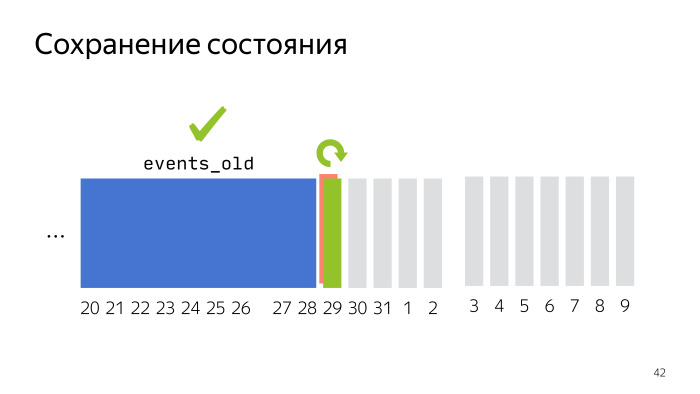
Вот пример, когда мы выгрузили несколько месяцев и осталось совсем чуть-чуть, больше недели. Мы выгружаем очередной день, что-то пошло не так. Чтобы не перегружать все месяцы, на которые мы делали запросы, достаточно каждый следующий день всегда выгружать в отдельную временную таблицу. Так у нас старые данные останутся в сохранности, и при перезапуске скрипта — будь то сетевой скрипт или машинка упала — вы не получите дублирования, а удалите таблицу, которая не догрузилась, и заново ее загрузите.
Постоянно требовалось держать в голове, что в случае обновления данных, добавления, первой выгрузки и инициализации требовалось всегда оставаться в консистентном состоянии. Далее требовалось сконвертировать и сгенерировать некоторые поля. И здесь не то чтобы Logs API нас обманывает или не отдает какие-то данные. Просто он не отдает то, что мы и так уже знаем — в частности, два генерируемых поля: AppID, идентификатор приложения, у которого мы сейчас получаем данные, и время, когда мы их получаем.

Это информация, которую мы и так знаем. Нам не нужно ее заново доставать из Logs API, достаточно просто докинуть в ходе обработки данных.
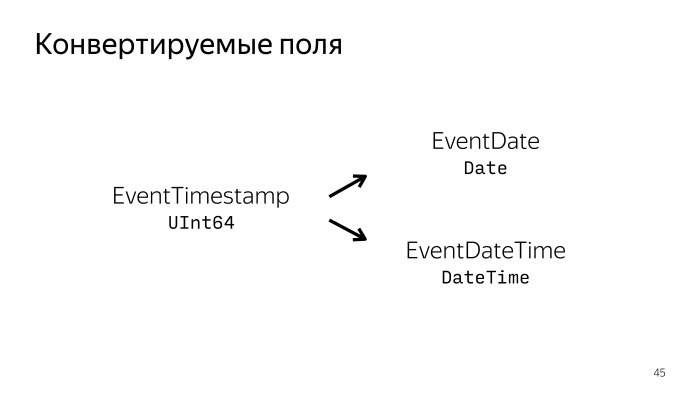
Для многих полей дата может быть как в строковом формате, так и в Unix Time. Чтобы не выгружать ее в разных форматах, можно, например, выгружать всегда Unix Time и генерировать два новых поля с нативным для ClickHouse форматом Date и DateTime. И жить с этими данными. В принципе, не надо будет выгружать лишних данных, экономить трафик.
Чтобы удобно это все поставлять, можно воспользоваться Docker — инструментом, позволяющим прятать приложение в некий контейнер, изолированный от других контейнеров и другого окружения хостовой машинки. При этом в нем может работать на Ubuntu 17.04, а Windows или macOS. И приложению будет все равно, оно будет работать правильно.
Чтобы начать работать с Docker и начать поставлять свое приложение в контейнере, достаточно создать Dockerfile.

Кто работал с Docker — узнает почти стандартный для Python Dockerfile, который также используется в образе ONBUILD. Структура файлов простая. Вы говорите, на базе какого образа вы хотите это сделать. В частности, мы хотим, чтобы здесь был Python 3.6.2. Потом создаем нужное окружение, нужные директории, импортируем все зависимости через pip requirements, указываем, где у нас будут храниться персистентные данные, необходимые для сохранения состояния, и как запускать скрипт. Все.
Далее, после некоторых манипуляций, все можно будет запускать двумя командами. Для начала — запустить ClickHouse, это вообще простая команда.
Затем нужно будет запустить скрипт выгрузки, указать скрипту, где находится ClickHouse, подлинковать его к его контейнеру. Это авторизационный токен, список идентификаторов приложений, которые вы хотите выгружать, и все. После этого, когда вы запустите две команды, у вас начнется выгрузка данных за последний месяц по всем данным, которые есть. Все это можно настраивать, но это минимальный набор того, что нужно сделать.

Также можно упростить эти две команды, если добавить файл для инструментов docker-compose, который позволяет поднимать сразу несколько контейнеров, как-то связанных друг с другом. Мы указываем то, что нам нужно: как поднимается ClickHouse, как поднимается скрипт выгрузки. Указываем, что они должны друг о друге знать, а точнее — указываем скрипт выгрузки ClickHouse. Указываем, какие данные будут персистентными, где они хранятся. В данном примере вы не указываете токен и список приложений, а передаете их через переменное окружение. Таким образом вы сможете поднять все одной командой, указав в качестве переменных окружения те данные, которые требуются, авторизационный токен и список приложений, а также docker-compose up –d. Вот и все, что нужно, чтобы начать пользоваться скриптом. Это просто. Он уже есть в open source.
Как все происходило? Это такой pet project, совсем не основной проект. Просто моя инициатива, возможность попрактиковаться в Python, посмотреть, как можно работать с данными. Занял примерно месяц работы, 64 коммита, полторы тысячи строк. Вроде и не сильно мало для простого скрипта выгрузки.

Все данные есть на нашем GitHub и появятся в документации к нашему продукту. Если вы вдруг пользуетесь AppMetrica и хотели бы расширить возможности аналитики, которые мы предоставляем, своими специфичными вкусами — попробуйте поднять, поиграться с данными. Возможно, и вы для себя откроете что-то интересное.
Резюмирую. Я объяснил, что такое Logs API, привел пример того, как им удобно пользоваться, для каких целей, и рассказал про нюансы выгрузки Logs API, которые можно экстраполировать на выгрузку обновляющихся данных из сети вообще. Пишите, если останутся вопросы. Спасибо!
— Меня зовут Николай Волосатов, я работаю в отделе мобильной разработки Яндекса. В частности, разрабатываю iOS SDK AppMetrica. Работаю более трех лет.
Сегодня я расскажу про некую функциональность, о которой, возможно, вы еще не слышали или слышали, но ни разу не пользовались, даже если у вас интегрирована AppMetrica. Сервис называется Logs API, он позволяет выгружать неагрегированные данные. Я расскажу, чем он может быть полезен, как его можно использовать, все, что нужно знать об этом продукте. Еще расскажу про то, с чем я столкнулся, разрабатывая инструмент для автоматизации работы с данными API, какие есть тонкости, трудности, что стоит за всем этим. Я пытаюсь заинтересовать вас как в самом продукте, так и в некоторых его особенностях, о которых расскажу.
AppMetrica — универсальный аналитический инструмент для ваших мобильных приложений. Позволяет делать анализ от установок и рекламных кампаний до крашлогов, вот это все. Представлен также в виде SDK для всех основных платформ: iOS, Android, Windows Phone. И также — в виде плагинов для Unity, Cordova и Xamarin.
Подробнее останавливаться на самом SDK не могу, но на нашем сайте вы можете посмотреть документацию и другие доклады, мы и на Cубботниках рассказываем про данный продукт. Можете поизучать — возможно, в ваших мобильных приложениях это может быть полезно.
Сегодня поговорим про, возможно, малоизвестную возможность нашего продукта — выгрузку неагрегированных данных. Что это такое? Все данные, собираемые нашим сервисом, мы используем у себя для построения отчетов на вебе, красиво, чтобы можно смотреть, следить за тенденциями, за тем, как работает приложение. Но также мы позволяем все эти данные выгружать в том неагрегированном виде, в котором они у нас хранятся, и отдавать их вам для каких-то ваших нужд.
Какие данные можно использовать? В первую очередь, информацию о рекламных кампаниях. Пользователь кликает по ссылкам, переходит в стор, устанавливает ваше приложение, вся эта информация у нас есть, ее вы можете использовать, например, для анализа эффективности рекламных кампаний, для интеграции с внутренними сервисами по установке целей, по мониторингам. Можете расширять информацию о том, как именно и откуда устанавливают ваше приложение, что работает эффективно. Плюс информация о том, новая это установка или переустановка приложения.
Более широкое применение — у информации о событиях, которые вы отправляете к нам в коде приложения и дальше можете анализировать на вебе.
В совокупности с началом пользовательских сессий, когда пользователь начал работать с приложением, открыл его в первый раз или развернул после тайм-аута сессии, все эти данные будут удобны для анализа поведения пользователя внутри приложения, для анализа того, как он ходит по экранам, где задерживается, как эффективно это приводит к продажам. Воронки продаж. Вся эта информация, помимо того, что может быть использована вами, может быть полезна для ваших партнеров, через которых вы делаете рекламные кампании.
Также интересной возможностью является выгрузка крашей и ошибок. Тут тоже есть простор для творчества — например, проинтегрироваться с вашим issue tracker, с вашими корпоративными мессенджерами, слать нотификации в Slack. В случае новых крашей вы можете эту информацию собрать, завести тикет, раз в неделю писать туда отчеты о том, сколько случилось крашей. И когда краш исправлен, в ваши интеграции также придет нотификация.
Помимо этого, можно выгружать информацию, необходимую для отправки пуш-нотификаций вашего приложения. Наш сервис позволяет слать пуши по всем сегментам, по которым наша SDK может отфильтровать пользователей. Но если вам этого мало или у вас очень специфичные вкусы в плане отправки пушей, вы можете отправить их сами, делать отправку самостоятельно.
Интерфейс выгрузки предельно прост. Им может пользоваться человек, далекий не только от разработки, но и вообще от работы с компьютером. Простой сайт, наша веб-морда от метрики, экспорт данных, тип данных, формат, какие данные вам нужны, временной интервал, поля, фильтры. Поддерживаются форматы выгрузки СSV и JSON. Нажимаете «Сформировать данные», ждете, пока пройдет очередь обработки данных. Ответ будет сформирован, получаете обычный файл.
Что под капотом? Запросы, если вы решите делать через терминал, предельно просты. Вы формируете обычный GET-запрос к нашему сервису. Для этого требуется авторизационный токен, простой OAuth-токен и все те же поля: какие данные, фильтры, филды, столбцы вам нужны. Делаете запрос, получаете код ответа HTTP 202. Если все хорошо, запрос поставлен в очередь, то теперь вы будете получать 202 на каждый запрос, пока данные формируются. Или же какой-то ответ с кодом ошибки: 403 — ошибки авторизации, 200 — неверно сформирован запрос, если поля принадлежат не тем данным, 239 — превышена квота.
Параллельно можно делать три запроса на одно приложение. Если у вас не одно приложение, вы можете делать больше запросов. Размер выгружаемых данных не должен превышать 5 ГБ. В совокупности с тем, что вы можете еще превысить лимит по времени, надо научиться как-то разбивать запрос, сокращать выборку. Но если вам нужно получить большие данные и вы не можете что-то отфильтровать или сделать меньше полей, на помощь приходит возможность просто разбить запрос на несколько частей. Два новых параметра, parts_count и part_number. По одному итерируете и выгружаете весь набор данных. Когда ответ сформирован сервером, вы получите 200 и, в теле ответа, все необходимые данные.
Выглядит просто, давайте попробуем автоматизировать. Скорее всего автоматизировать необходимо, когда вы разрабатываете расширение аналитики, будь то воронки продаж или анализ крашей.
Скорее всего, это будет состоять из трех частей. Вам нужна база данных, куда вы будете складывать выгружаемые данные, сам скрипт выгрузки и интерфейс. Если это какая-то аналитика, то веб-интерфейс. Если интеграция с мессенджерами или issue tracker — виртуальный интерфейс продукта, куда вы шлете отчеты и, конечно, запросы к базе.
В скрипте выгрузки, который я реализовывал, я решил использовать в качестве БД то, что логичнее всего использовать. То, что используется у нас на бэкенде. Это база данных ClickHouse, про которую, возможно, вы уже где-то слышали. Возможно, даже используете, возможн, о в продакшене. Замечательная БД, разработанная для хранения какой-то аналитики, частых событий, используется в том числе в ЦЕРНе. БД позволяет делать поразительно быстрые запросы на вставку, на селекты, на выборку данных, при этом работает распределенно.
У нас данные пусть не такие большие, за один раз всего 5 ГБ, но если вы будете выгружать годами такую статистику, в конце концов вам потребуется ускорение для построения отчетов. Следующее, что нужно: интерфейс и построение запросов к нему. Об этом готовится статья, выйдет на Хабре от Марии Мансуровой miptgirl, которая разрабатывала инструмент по тем самым воронкам продаж.
Сегодня мы больше остановимся на выгрузке, на нюансах, связанных с обновлением загрузки данных такого рода. Пройдемся по проблемам, с которыми можно столкнуться в ходе разработки интерфейса автоматизации.
Первое, с чем мы столкнулись, это большие объемы данных. В 2017 году называть 5 ГБ большими объемами — кощунство, но поймите, разрабатывая скрипт для выгрузки, вы подразумеваете, что он будет работать в минимальном окружении, будь то минимальный инстанс на Amazon или машинка у вас в гараже. Вам требуется, чтобы все влезало в оперативную память, нигде не проседало. А если на той же машинке будет еще ClickHouse крутиться, вы столкнетесь с проблемами и не сможете 5 ГБ за раз вставить в базу.
Надо научиться разбивать данные, которые мы получаем. Выгружать мы будем CSV, он потоковый, его можно бить на строки. Вручную это делать достаточно сложно. Тот, кто писал написать парсер CSV, понимает, что не так просто, по new line не разбить.
Мы будем пользоваться pandas, скрипт написан на Python. Кто работал с данными на Python — знает эту библиотеку. Метод read CSV — достаточно гибкий для такого рода проблем.
Это кусок кода, который отвечает за разбитие большого запроса на части. На вход подается стрим из сети, от нашего API, поток, и на выход мы получаем итератор с чанками по n строк. Предельно просто: мы сократили объем оперативной памяти, который нужен за раз.
Следующая проблема — обновление данных. Здесь надо посмотреть, какие по своей структуре и природе данные отдает наш сервис.
Их можно разбить на несколько групп по временному характеру. Первое — серверные данные, которые генерируются на сервере и там же хранятся. Они претерпевают минимальную задержку. Событие случилось, клик случился, и его можно выгрузить через Logs API.
Отдельно находятся пуш-токены. Мы не храним и не отдаем исторические данные по ним, нельзя выгрузить пуш-токены за три недели назад. Они только актуальные выдаются, они тут на особых правах.
И — значительная часть ответов от Logs API приходит от клиента, от мобильного приложения, что логично, это мобильная аналитика. Здесь мы сталкиваемся с проблемой, что клиентские данные могут приходить с задержкой. Задержка может составлять до семи дней. Данные могут доходить и позже, но не будут отдаваться в Logs API, уже считаются устаревшими. Это связано с тем, что у пользователя не всегда есть интернет, не всегда мы отправляем события прямо сразу, чтобы экономить и ресурсы девайса, и трафик — потому что где-то в запросе есть служебная информация. Все это складывается в то, что придется обновлять данные и держать в голове, что данные старше недели мы считаем архивными. Они больше не будут меняться, но текущая неделя — проблемные данные, их нужно обновлять, и они будут дополняться за последние 7 дней.
Если вспомним, что мы пользуемся ClickHouse, то обновлять данные не так просто. База ClickHouse не рассчитана на то, что данные как-то будут изменяться. Эта особенность всех устраивает, потому что данные рассчитаны на аналитику. Там никаких изменений быть не должно.
Первое решение, которое нам пришло в голову: делать выгрузку в отдельную таблицу. Допустим, выгружаем по одному дню в отдельную таблицу, дальше строим diff с данными, которые у нас есть, и добавляем его в продакшен-базу, которую мы выгрузили.
Такое решение работает. На небольших данных оно работает даже достаточно быстро. Но если подумать, сколько данных можно выгружать годами, то потом запрос на построение разницы между тем, что мы скачали и тем, что есть, будет занимать существенное время. ClickHouse на такое не готов, это решение плохо масшабируется, если вы будете делать такую большую БД, и оно в принципе проблемное.
На помощь приходит сам ClickHouse, который предоставляет интересную возможность: будем выгружать данные следующим образом — каждый день из последних семи будем выгружать в отдельную таблицу. Все данные старше семи дней будем складывать в отдельную архивную таблицу и в случае обновления будем скидывать туда те таблицы, которые больше обновляться не будут.
Чтобы с этим было удобно работать, у ClickHouse есть замечательная виртуальная таблица, имеющая движок merge-таблицы. Это виртуальная таблица, которая будет где-то у себя при запросах делать union всех данных из таблиц, основываясь на регулярном выражении. Нам даже не нужно будет пересоздавать эту таблицу— она будет подхватывать новые и изменяющиеся таблицы автоматически.
Теперь чтобы обновить один день, нам достаточно выкинуть таблицу, которую мы считаем устаревшей, и загрузить заново. В случае, когда таблица больше не обновляется, мы скидываем все данные old и тоже ее удаляем. Теперь ClickHouse доволен. Это решение отлично масштабируется и не требует сложных запросов на вставку данных.
Можем идти к следующим проблемам. Следующий вопрос был с сохранением состояния. Это может показаться тривиальным, но в ходе разработки инструмента требовалось постоянно держать в голове, что скрипт должен работать правильно, не должен пропускать данные, дублировать, и при этом все должно работать достаточно быстро, не перегружать весь мир в случае проблем.
Вот пример, когда мы выгрузили несколько месяцев и осталось совсем чуть-чуть, больше недели. Мы выгружаем очередной день, что-то пошло не так. Чтобы не перегружать все месяцы, на которые мы делали запросы, достаточно каждый следующий день всегда выгружать в отдельную временную таблицу. Так у нас старые данные останутся в сохранности, и при перезапуске скрипта — будь то сетевой скрипт или машинка упала — вы не получите дублирования, а удалите таблицу, которая не догрузилась, и заново ее загрузите.
Постоянно требовалось держать в голове, что в случае обновления данных, добавления, первой выгрузки и инициализации требовалось всегда оставаться в консистентном состоянии. Далее требовалось сконвертировать и сгенерировать некоторые поля. И здесь не то чтобы Logs API нас обманывает или не отдает какие-то данные. Просто он не отдает то, что мы и так уже знаем — в частности, два генерируемых поля: AppID, идентификатор приложения, у которого мы сейчас получаем данные, и время, когда мы их получаем.
Это информация, которую мы и так знаем. Нам не нужно ее заново доставать из Logs API, достаточно просто докинуть в ходе обработки данных.
Для многих полей дата может быть как в строковом формате, так и в Unix Time. Чтобы не выгружать ее в разных форматах, можно, например, выгружать всегда Unix Time и генерировать два новых поля с нативным для ClickHouse форматом Date и DateTime. И жить с этими данными. В принципе, не надо будет выгружать лишних данных, экономить трафик.
Чтобы удобно это все поставлять, можно воспользоваться Docker — инструментом, позволяющим прятать приложение в некий контейнер, изолированный от других контейнеров и другого окружения хостовой машинки. При этом в нем может работать на Ubuntu 17.04, а Windows или macOS. И приложению будет все равно, оно будет работать правильно.
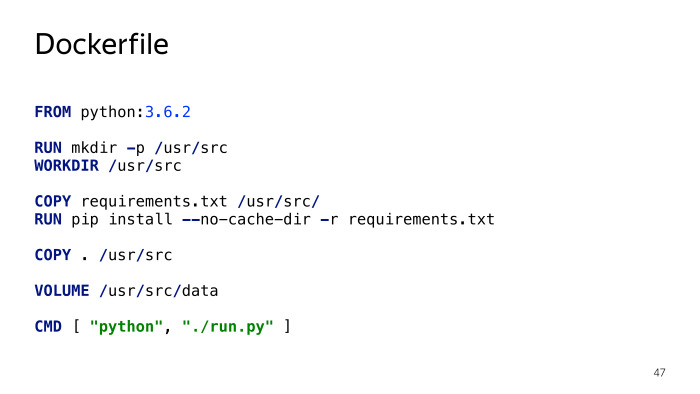
Чтобы начать работать с Docker и начать поставлять свое приложение в контейнере, достаточно создать Dockerfile.
Кто работал с Docker — узнает почти стандартный для Python Dockerfile, который также используется в образе ONBUILD. Структура файлов простая. Вы говорите, на базе какого образа вы хотите это сделать. В частности, мы хотим, чтобы здесь был Python 3.6.2. Потом создаем нужное окружение, нужные директории, импортируем все зависимости через pip requirements, указываем, где у нас будут храниться персистентные данные, необходимые для сохранения состояния, и как запускать скрипт. Все.
Далее, после некоторых манипуляций, все можно будет запускать двумя командами. Для начала — запустить ClickHouse, это вообще простая команда.
Затем нужно будет запустить скрипт выгрузки, указать скрипту, где находится ClickHouse, подлинковать его к его контейнеру. Это авторизационный токен, список идентификаторов приложений, которые вы хотите выгружать, и все. После этого, когда вы запустите две команды, у вас начнется выгрузка данных за последний месяц по всем данным, которые есть. Все это можно настраивать, но это минимальный набор того, что нужно сделать.
Также можно упростить эти две команды, если добавить файл для инструментов docker-compose, который позволяет поднимать сразу несколько контейнеров, как-то связанных друг с другом. Мы указываем то, что нам нужно: как поднимается ClickHouse, как поднимается скрипт выгрузки. Указываем, что они должны друг о друге знать, а точнее — указываем скрипт выгрузки ClickHouse. Указываем, какие данные будут персистентными, где они хранятся. В данном примере вы не указываете токен и список приложений, а передаете их через переменное окружение. Таким образом вы сможете поднять все одной командой, указав в качестве переменных окружения те данные, которые требуются, авторизационный токен и список приложений, а также docker-compose up –d. Вот и все, что нужно, чтобы начать пользоваться скриптом. Это просто. Он уже есть в open source.
Как все происходило? Это такой pet project, совсем не основной проект. Просто моя инициатива, возможность попрактиковаться в Python, посмотреть, как можно работать с данными. Занял примерно месяц работы, 64 коммита, полторы тысячи строк. Вроде и не сильно мало для простого скрипта выгрузки.
Все данные есть на нашем GitHub и появятся в документации к нашему продукту. Если вы вдруг пользуетесь AppMetrica и хотели бы расширить возможности аналитики, которые мы предоставляем, своими специфичными вкусами — попробуйте поднять, поиграться с данными. Возможно, и вы для себя откроете что-то интересное.
Резюмирую. Я объяснил, что такое Logs API, привел пример того, как им удобно пользоваться, для каких целей, и рассказал про нюансы выгрузки Logs API, которые можно экстраполировать на выгрузку обновляющихся данных из сети вообще. Пишите, если останутся вопросы. Спасибо!